こんにちわ。NTTドコモ サービスイノベーション部の川嶋です。
この記事はAdvent Calendar 2020 NTTドコモ R&D 控え室、3日目の記事です。
今日はKDD Cup 2020 ML Track 1 Task 1の上位チーム(1位、6位)の手法を紹介します。6位のチームの手法の解説は同じ部署の橋本くんに書いてもらいました。
なお、ここではタスクの概要の説明などは省略しているため、本記事をご覧になる前にその1とその2をご一読いただくことをおすすめします。
1位のチーム:「WinnieTheBest」のソリューション
概要
1位のチームは以下の2つのネットワークを利用して課題を解いています。
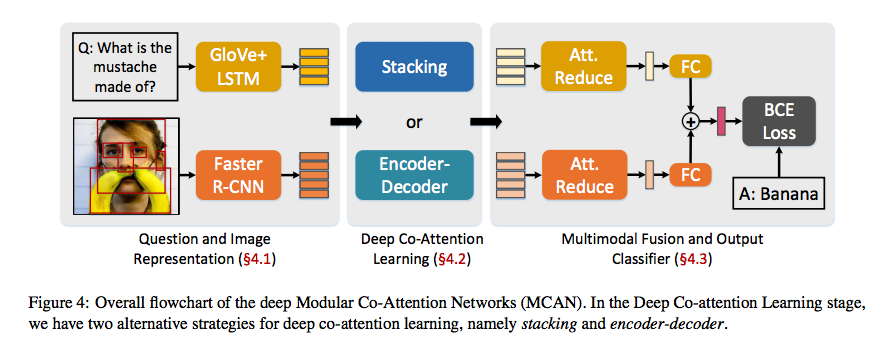
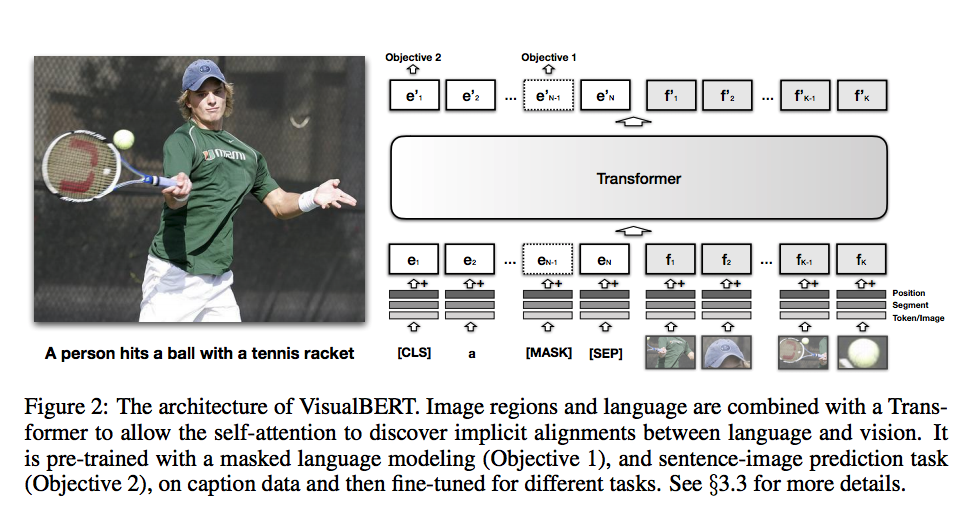
いずれもVisual Question AnsweringやVisual Commonsense Reasoningなどの画像、文章の2種類の情報を扱うタスクを解く時に使われているネットワークです。画像中のオブジェクトとクエリーのキーワードの関連性を学習できるモデルとなっています。
本コンペで1位のチームが使用したソースコードは以下で公開されています。
https://github.com/steven95421/KDD_WinnieTheBest
解法
以下では前処理から後処理にかけて実施された手法/処理を列挙していきます。
ちなみに1位のチームのスコアは以下の通りです。
- testA 0.785
- testB 0.848
私たちのチームはtestA,Bでスコアがほとんど変わらなかったのに対して、1位のチームはかなりスコアを伸ばしてきていて想定外に差がつけられてしまいました。。。
前処理
- 画像
- Box feature
- オリジナルの画像特徴量に6次元の特徴量をconcat
- 最初の4次元は[0, 1]に正規化したbboxの座標
- 残りの2次元は正規化された面積とアスペクト比
- オリジナルの画像特徴量に6次元の特徴量をconcat
- Label feature
- 32次元(全32クラス)のlabel featureをconcat
- Box feature
- テキスト
- 文法が正しくないクエリをフィルタリングし、より正確な文法に修正
具体的には以下のように悪影響を与えそうな単語を事前に除去しています。
- 文法が正しくないクエリをフィルタリングし、より正確な文法に修正
trash = {'!', '$', "'ll", "'s", ',', '&', ':', 'and', 'cut', 'is', 'are', 'was'}
trash_replace = ['"hey siri, play some', 'however, ', 'yin and yang, ',
'shopping mall/']
# xには"boys cartoon slippers"のようなクエリーがそのまま渡されています。
def process(x):
tmp = x.split()
if tmp[0] in trash: x = ' '.join(tmp[1:])
if tmp[0][0] == '-': x = x[1:]
for tr in trash_replace:
x = x.replace(tr, '')
return x
モデル
MCANとVisualBERTの2つのモデルを使用しています。各モデルの詳細は原著をご確認ください。
- MCAN
- MCANはディープにカスケード接続されたMCAレイヤーから構成されています。
- MCAレイヤーはself-attention(SA)ユニットとguided-attention(GA)ユニットと呼ばれる2つのアテンションユニットをモジュール化したもので、スケーリングされた内積アテンションを利用しています。複数のMCA層で画像とクエリーの特徴を徐々に洗練させるようになっています。
- 元論文からの拡張内容は以下の2つ
- 単語埋め込み部分をRoBERTaに置き換え
- 画像とテキストの2つの平坦化特徴を加えるのではなく、2つの平坦化特徴をconcatしています。さらに、2つの平坦化特徴の乗算とマンハッタン距離を追加で結合
- MCANはディープにカスケード接続されたMCAレイヤーから構成されています。
- VisualBERT
- 画像とクエリー間の暗黙的なアライメントを学習するSAを可能とするために、画像とクエリーがTransformerに結合されています。私たちのチームが使用したVilBERTと同様にBERTに似たアーキテクチャを使用しています。一方でVilBERTは画像とクエリーでそれぞれ別のTransformerを持っていますが、VisualBERTは共通のものを利用するためパラメータ数が半分になっています。
- 元論文とは異なり、画像とクエリーの特徴を分離するために[SEP]トークンを用いたtoken_type_ids埋め込みを使用しています。(と言っているが元論文でも[SEP]トークンを使用しているような。。。)
学習手順
-
Negative Sampling
- positive:negative = 1:10(私たちのチームより負例の数がかなり多いですね。)
- valid.tsvからクエリーの候補は通常似たような単語を持っていることを発見し、positiveクエリーと同じ単語を共有しているクエリーをnegativeクエリーとして高い確率でサンプリングするようにしています。(Negative SamplingではいかにSemi-hard negative、hard negativeなクエリーを抽出するかが肝になると思います。私たちのチームではpositive、negativeクエリーのbert特徴量のユークリッド距離を基に抽出する方法も試しましたが、単純にランダムに抽出したクエリーを使用した方がスコアが高くなりました。)
- 同じクエリに複数のproductが対応している事があるので、一つのqueryにn個のproductが紐づいている場合、それぞれのproductに対してk個のnegative sample productを用意しています。
- 以下の方法で、n*k個のnegativeなproduct idを生成する
- 一つのqueryに対して(ターゲットクエリー)、topK個の似たqueryをnegative sampleを作るための候補クエリー(negativeクエリー候補)として用意する
- ターゲットクエリーに対応するn個のproductについて、それぞれ1つのnegativeクエリーを前述のtopK個のnegativeクエリー候補からサンプリングする
- n個のnegativeクエリが生成されたが、各ネガティブクエリには複数のproduct idが対応する
→ 一つのnegativeクエリーに対して1つのproduct idをランダムに選択する - 2と3を回繰り返す
※topK > nである必要があり、実装上はtopK = 3*nで実装。また、k=10
-
学習パラメータとスケジュール
-
学習率:1e-5
-
バッチサイズ:64
-
損失関数:Focal Loss
import torch.nn as nn import torch.nn.functional as F class FocalLoss(nn.Module): def __init__(self, alpha=1, gamma=2, logits=False, reduce=True): super(FocalLoss, self).__init__() self.alpha = alpha self.gamma = gamma self.logits = logits self.reduce = reduce def forward(self, inputs, targets): if self.logits: BCE_loss = F.binary_cross_entropy_with_logits(inputs, targets, reduce=False) else: BCE_loss = F.binary_cross_entropy(inputs, targets, reduce=False) pt = torch.exp(-BCE_loss) F_loss = self.alpha * (1-pt)**self.gamma * BCE_loss if self.reduce: return torch.mean(F_loss) else: return F_loss -
最適化手法:AdamW
-
scheduler:Sine Wave with Linear Warmup
- 学習率を線形に減衰させると、学習の最後の数epochの間にパフォーマンスが落ちるが、スケジューラーを正弦波にすることで安定的にスコアが増加することを発見しています。
- num_warmup_steps:num_training_steps*0.1
- num_cycles:6
- amplitude:0.3
import math from torch.optim.lr_scheduler import LambdaLR def custom_schedule(optimizer, num_warmup_steps, num_training_steps, num_cycles=0.5, amplitude=0.1, last_epoch=-1): def lr_lambda(current_step): if current_step < num_warmup_steps: return float(current_step) / float(max(1, num_warmup_steps)) progress = 2.0 * math.pi * float(num_cycles) * float(current_step-num_warmup_steps) / float(max(1, num_training_steps-num_warmup_steps)) linear = float(num_training_steps-current_step) / float(max(1, num_training_steps-num_warmup_steps)) return abs(linear + math.sin(progress)*linear*amplitude) return LambdaLR(optimizer, lr_lambda, last_epoch)(私の勉強不足ですが、周期関数を用いて学習率を減衰させる方法を初めて知りました、、、)
-
後処理
- valid.tsvを用いた分類器の再訓練
- 参加者が唯一持っているground truthであるvalid.tsvを利用する。
- 埋め込みを上記で学習したモデルから抽出し、0/1で分類器を学習させる。
- 分類器にはLightGBMを採用。(パラメータは全てデフォルト)
- アンサンブル
- MCAN55個、VisualBERT14個の合計69個のモデルの予測値を単純に加算している。
川嶋の所感
チームによって使用するネットワークや着眼点が様々なので、コンペ中だけでなく終了してからも学びが多かったです。上位チームはデータをよく観察していないと思いつかないような前処理・後処理が実装されており、そこでも差がついたように感じました。また、どのチームもトライアンドエラーでDeepなネットワークを様々な条件で学習させてモデルを作成しており、単に技術力が高いだけでなく潤沢なマンパワー・マシンパワーに恵まれていることが伺えます。(私たちのチームもV100 10枚をフル活用していました。)私はデータ分析系のコンペに参加したのが初めてだったこともあり、とてもいい経験になりました。来年も参加してさらに上位に食い込めるように頑張ります!
6位のチーム: 「WST」のソリューション
NTTドコモ サービスイノベーション部の橋本(@dcm_hashimotom)です。
以下では、ドコモ (NDCG@5: 0.770)より順位がひとつ上である、6位のチーム「WST」の解法 (NDCG@5: 0.787)を紹介します。
彼らのソリューションのプログラムとレポートは下記のリポジトリで公開されておりますので、興味ある方は合わせてご確認いただければと思います。
https://github.com/onealwj/KDD-Cup-2020-MultimodalitiesRecall
ざっくりいうと
6位のソリューションではVisual Semantic Reasoning Network(VRSN)3を拡張したモデルを用いて課題を解いております。
VSRNは「Visual Semantic Reasoning for Image-Text Matching」という論文で提案されており、Graph Convolutional Network(GCN) による関係推論を用いた画像-テキストのマッチング問題を解くモデルです。今回のタスクとは親和性が高いモデルとなっております。
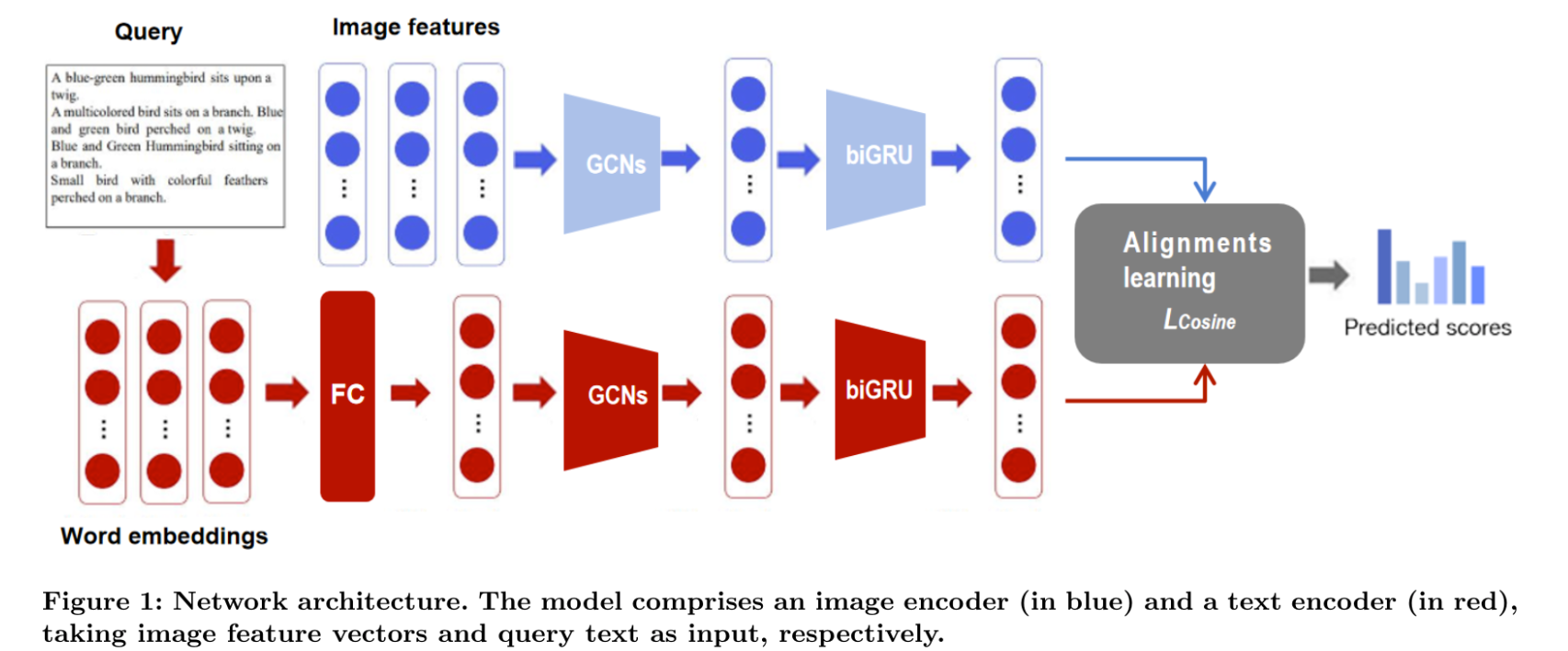
学習の流れとしては下記のようになっております。
- 画像: GCNを用いてbbox間の関係性を考慮したベクトル表現を獲得し、biGRUを用いて画像全体の表現を得る。
- テキスト(入力クエリ): 同様にGCNを単語間の関係を考慮したベクトル表現を獲得し、biGRUを用いてクエリ全体の表現を得る。
- 最後のLoss関数で、テキストと画像がマッチするペアはベクトルが近く、マッチしないペアは遠くなるように学習する。
解法
以下では前処理から後処理にかけて実施された手法/処理を列挙していきます。
特徴量前処理
- 画像
- データセットで与えられているためとくに実施せず
- テキスト
- text concatenation
- データセットのなかに"long-sleeve summer shirt", "summer long-sleeve shirt"のように同じ意味のクエリだが,語順が異なるクエリを確認.
- 語順をランダムに変えてみたが,学習に影響はないことを確認.
- validateとtestのタイミングでoriginal queryと語順を変えたものをconcat して対応
- data augumentation
- "< unk >" で単語の一部をマスクを実施
- 翻訳の補正
- forest style と sen departmentは実は同じ意味.senは"森"の中国語読み.二つは同じ意味なので,forest styleに統一.
- stopwords
- 数字,冠詞,代名詞,句読点などを削除
- word2vec
- KDD2020 train and valid query set をword2vecで学習
- text concatenation
モデル
-
Visual Semantic Reasoning for Image-Text Matching(VSRN) を拡張したモデルを採用
-
拡張内容は下記の5つであると主張。
-
- image encoder : GCN region relationship reasoning module を multi head GCN region relationship reasoning moduleに
-
- text encoder: GRUからmulti head GCN region relationship reasoning module (image encoderと同じ構成になる)
-
- image encoder : GCNの前の FC層を除去
-
- image feature : global image featureを採用 (boxの平均のベクトルを末尾に追加する処理)
-
- loss : cross-modal Cosine Loss を採用
-
-
画像
- 4つのmult-head multi-head region relationship reasoning module (GCN)
- 複数のbboxを定義 (今回はデータセットで与えられている)
- bboxごとにベクトルを結合
- global image feature
- 全bboxの平均を計算し末尾に結合
- sorted box
- bboxの順序をxの小さい順にソート
- global image feature
- 各bboxをノード、エッジに関係度合いを持つようなグラフを設定しGCNに入力 (完全グラフになる)
- bboxごとの関係を考慮したベクトルが出力
- 1つのbi-GRU
- bboxごとのベクトルを時系列として入力
- 画像内のすべてのbbox考慮した特徴量表現を算出
- 最後の内部表現(メモリセル)を最終ベクトルとして出力
- オリジナルのVRSNにあるFC-layerは除去
- 4つのmult-head multi-head region relationship reasoning module (GCN)
-
テキスト
- Word Embedding
- KDD2020 train and valid query setをword2vecで学習
- 1つの FC
- 4つのmult-head multi-head region relationship reasoning module (GCN)
- 変換された単語ベクトルを結合 (単語数xベクトル次元数)
- 単語ベクトルをノード、エッジに関係度合いを持つようなグラフを設定しGCNに入力
- 単語ごとの関係を考慮したベクトルが出力
- 1つの bi-GRU
- 単語ごとののベクトルを時系列としてに入力
- 最後の内部表現(メモリセル)を最終ベクトルとして出力
- Word Embedding
学習
-
Under sampling
- classごとにsample数が異なる不均衡データなので、学習データの中でclassのサンプル数に応じた比率でdropするロジックを実装
- サンプル数が多いほどdrop比率は多くなる形。
- 詳細なアルゴリズムがテクニカルレポート内で紹介されております。
-
最適化手法: Adam
-
パラメータ
- エポック数 7
- 学習率
- 0.0002 4エポック
- 0.00002 3エポック
- バッチサイズ 128
-
損失関数
後処理
- Fine tune
- 1つのミニバッチに同じプロダクトのクエリがくるように学習
- これにより同じプロダクトのクエリの違いをよりよく学習させることがねらいとのこと。
- パラメータ
- エポック数 6
- 学習率 0.00002
- バッチサイズ 128
- アンサンブル
- 6つの異なるシードでモデルを作成し、結果を平均を計算
- Re-ranking
-
Re-ranking Person Re-identification with k-reciprocal Encodingを実施
- 距離が近いランキングをより厳密に再計算
- 本手法については DeNAの解説資料が参考になるかと思います。
-
Re-ranking Person Re-identification with k-reciprocal Encodingを実施
橋本の所感
データの観察と前処理の大切さを改めて確認しました。前処理における「翻訳の補正」ですが、中国語ユーザに有利で逆に面白かったですね。また、損失関数や、Re-rankingの手法など、モデル以外の部分についても有効なテクニックを採用していたのが印象的でした。
普段の業務ではテーブルデータを扱っており、画像/テキストのデータについての知見が未熟でしたが、コンペ参加/サーベイを通して様々なテクニックを知ることができました。今回はシンプルなFCNNを実装してましたが、今後はよりドメインに沿ったモデルの検討/実装をしていきたいと思います。