この記事はAdvent Calendar 2020 NTTドコモ R&D 控え室、2日目の記事です。
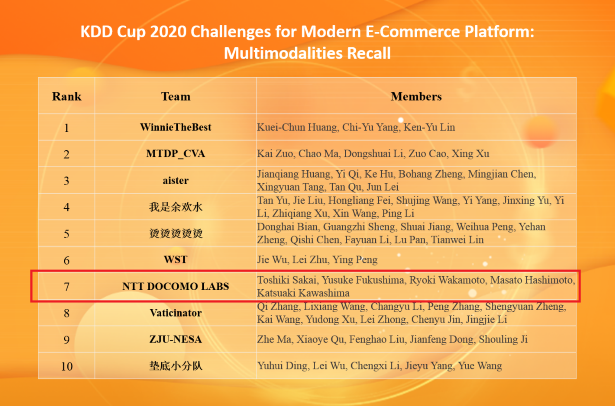
ドコモR&DはAI・データサイエンス分野での実力向上のために、世界最高レベルのデータ分析コンペであるKDD Cupに参加しおり、なんと今年は私たちのチームがで7位入賞を果たしました!
しかしせっかくKDD Cupに入賞したのに、同僚のチームが他の課題で3位や4位をたたき出して、日陰者になってしまった...
そんな悔しさをぶつけるべく、私たちのチームがどのような過程で/どのような手法で入賞を果たしたのか、紹介したいと思います。
チームメンバーがKDD Cupへの初参加レポートも掲載しておりますので、合わせてご覧ください。
本記事は、NTTドコモ サービスイノベーション部の酒井が担当いたします。
概要
複雑なものからシンプルなものまで、3つのモデルを様々なepochでアンサンブルすることで、高精度を達成!
- モデルA: BERTを画像と文章に拡張したVilBERT
- モデルB: クエリ文中の単語と、画像中の物体のクラス名を、同じようにembeddingして扱うネットワーク
- モデルC: シンプルなFully Connectなネットワーク
コンペ課題
検索クエリに対して複数の候補が像が与えられた時、関連性の高い候補画像を選ぶという課題でした。
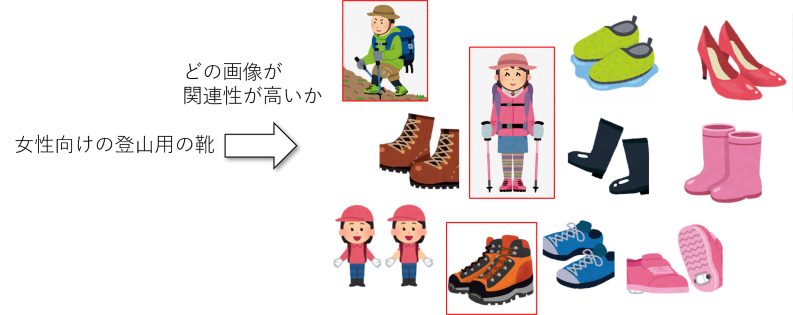
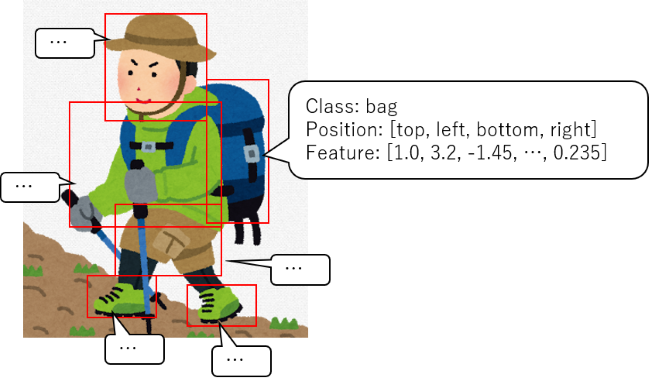
画像は、画像データとしてではなく、画像から物体を抽出したBounding Boxの位置、クラス、画像特徴量で与えられています。
この課題の難しさ: 可変長のデータ
画像、検索クエリ共に特徴が固定長のベクトルとして与えらえるのではなく、以下のような可変長のデータでした。
- 画像は、一枚の画像に対する特徴ではなく、Bounding Boxの情報として与えられる
- Bounding Boxの数は、画像によって異なる
- クエリも、単語ではなく文
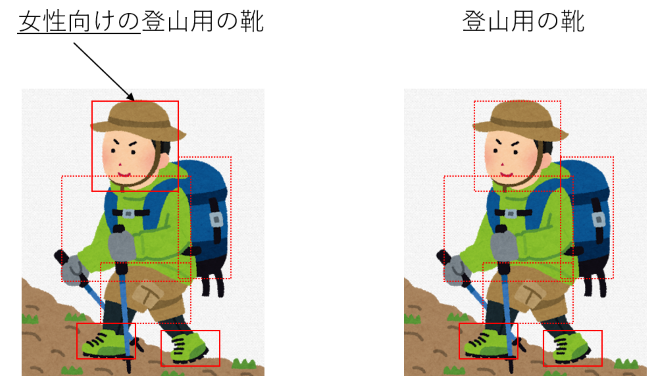
よって、クエリと画像のそれぞれの特徴を、何らかの方法で、縮約した上で、画像と文の対応関係を計算する必要があります。
この時、単純に文の中だけで縮約する(BERTを使って文を特徴量に変換したり)、画像の特徴だけで縮約する(Bounding boxの特徴を平均を取るなど)といった方法がまず考えられます。
しかし、文中の単語、画像中の物体は、それぞれ対応しており、その対応関係に応じて重要度が変化すると考えられることから、より複雑な処理が必要となります。
提案手法開発の流れ
コンペの開始当初から、複数モデルを作ってアンサンブルすることは、ほぼ決まっていました。
アンサンブルは、複数のモデルの出力結果を組み合わせて、最終的な推定結果を作ることで、各モデルの弱点を補ってより精度の良い予測をすることができる手法です。コンペに参加する上で、アンサンブルは必須のテクニックだと思います。
アンサンブルするモデルは、以下のような取り組みから生まれました。
1. 特徴を取捨選択して、シンプルなモデルから試していく
たぶん、コンペとかに参加する際に、最初に取るべき策だと思います。チームメンバーのほとんどは、ここから手をつけました。
- 本課題はデータ数が多く、可変長の特徴を扱わないといけないので、データを上手く扱う事が重要
- 経験に基づいてどの特徴が効きそうか考えつつ、try & errorで良い方法を選んでいく
2. ベースライン的な手法を改良していく
1が落ち着いて来た段階で、1を試していたメンバーがこちらに移ってきました。
- コンペに参加していると運営や、他の参加者がベースライン的な、ある程度精度の出る手法を公開してくれることがある
- ベースラインの手法を独自の改良を加えることで差異化を図る
3. タスクの構成にあった複雑なモデルを試す
私はこちらから入って検討を進めました。面白そうだったので。
- 最初から複雑なモデル+GPUで殴って解決
- データが十分にあるときは、高精度のモデルができる可能性が高いと思う
- 精度が出始めるまでに時間がかかることが多いと思う(今回も、なかなか学習が上手くいかなかった)
- 学習に大量の計算リソースが必要なので、GPUを如何に準備するのかも課題
3つのモデル
提案手法では、最終的に3つのモデルを採用し、アンサンブルを行いました。
各モデルは、画像1枚のBounding boxの特徴と、検索クエリを入力として受け取り、当該画像と検索クエリの関連性が高いのか、0-1のスコアで出力します。
この章では3つのモデルを解説していこうと思います。
モデルA: VilBERT
前述の3の流れで採用したモデルです。
3の流れで複雑なモデルを試す際、一からモデルを作るのは大変なので、近い課題から使えそうなモデルがないか探してくるのが常套手段かなと思います。
今回の課題は、以下のように解釈しました。
- 単語からの画像検索に近そう
- クエリの各単語が画像中の特定のBounding boxに対応しそうなので、単語とBounding boxの間の関係を学習できそうな手法として、"Attention"が必要そう
- 入力が単語ではなく文なので、言語処理で高精度のモデルを採用した方がよさそう
そこで以下のような単語で検索をかけ、良さそうなモデルを探しました。
- image retrieval
- attention
- transformer
言語界隈では、最近はTransformerベースの手法を使うのがメジャーですね。結果見つけたのが、ViLBERTです。
ViLBERTは、名前の通り、機械翻訳等の言語処理で使われるBERTを、VisionとLanguageの複合課題に適用できるように拡張したものです。
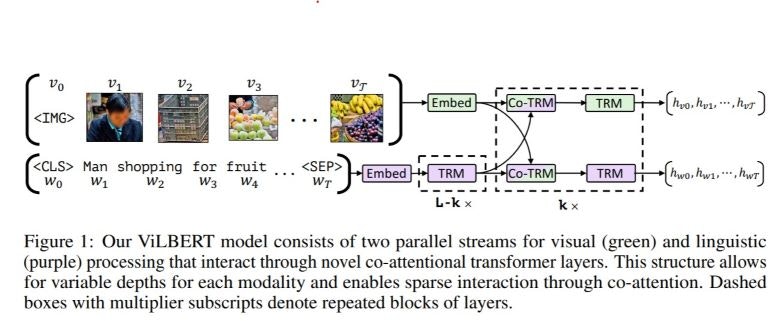
以下に、ViLBERTの概念図を示します(本章では、特に断りのない限り前述の論文からの引用です)。
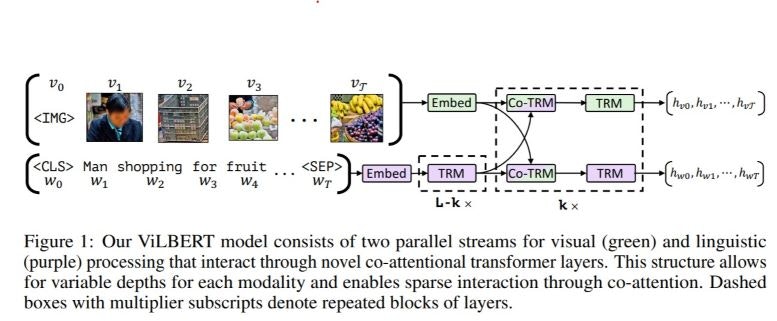
ViLBERTにおけるターゲット
ViLBERTは、画像のBounding boxの特徴と、文章を入力とし、以下のような課題を解くことができます。
- Visual Question Answering:ある画像とその画像に関する質問を提示されたときに,正しい答えを導き出すタスク
- Visual Commonsense Reasoning:ある画像とその画像に関する質問を提示されたときに,正しい答えと、その理由を導き出すタスク
- Image Retrieval: 入力文に対して適した画像を検索する
- RefCOCO+: 入力文が表す物体を画像中から探す
画像中のbounding boxを利用するタスクを対象としている点で、本課題のターゲットと親和性が高いです。
TransformerとCo-Attention layer
また、ViLBERTはTransformerを拡張した注意機構を採用し、入力文と入力画像のbounding boxとの対応関係を学習することができます。
Transformerは機械翻訳などの言語処理で広く使われるネットワーク構造で、Self Attentionによる注意機構を持っています。
Transformerは、文を構成する単語の列を入力として受け取り、これをSelf Attentionを用いて処理することにより、入力文中の各単語が、入力文中の他の単語にどの程度関連するかを学習することができます。
Self Attentionに関しては、Kaggleの記事やこちらのQiita記事が詳しいです。

(上図はThe Illustrated Transformerより)
ViLBERTでは、この注意機構を、画像中の各Bounding boxが入力文中のどの単語に関連するか、およびその逆を学習する形に拡張します。
まず、ViLBERTでは、文中の単語列と、画像のBounding Boxの列をそれぞれ入力として受け取ります。
それぞれを別のストリームで処理するのですが、途中で注意機構がストリーム間でAttentionをかけることで、単語とBounding boxの関連を学習します。
以下に、通常のtransformerの注意機構と、ViLBERTの注意機構を示します。
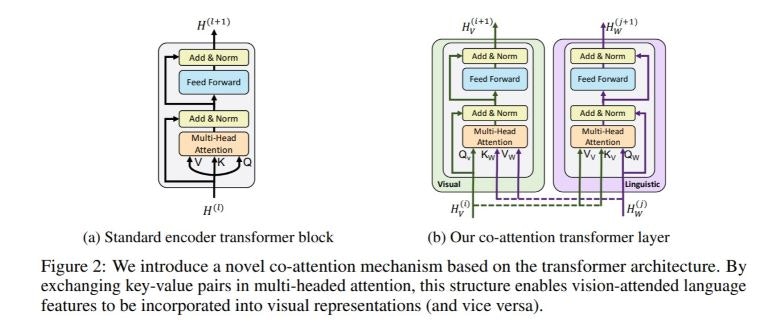
通常のtransformerでは、入力自身がAttentionのK, V, QとなることでSelf Attentionを実現していますが、ViLBERTでは、KとVが他方のストリームから供給されることで、画像情報と言語情報との間でのCo-attentionを実現しています。
モデルB: クエリ文中の単語と、画像中の物体のクラス名を、同じようにembeddingして扱うネットワーク
前述の2の流れで採用したモデルです。KDDCupのForumにて、以下のようなモデルを共有したチームがあり、それを元に変更を加えました。
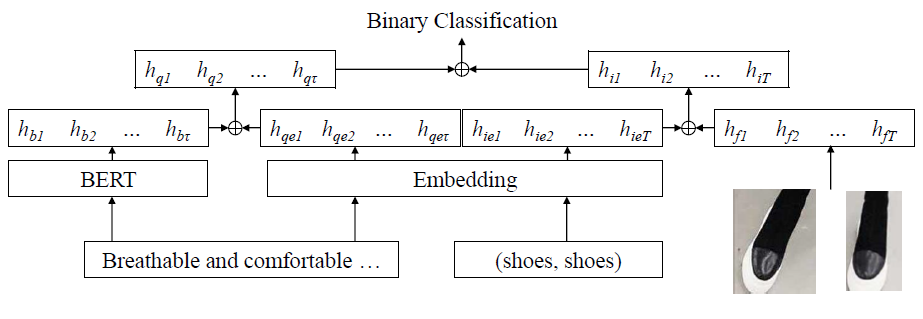
本モデルは、画像のBounding boxにクラスラベルが与えられている事に着目しています。
これを言語処理用の単語として扱い、検索クエリ中の単語と、クラスラベルを同じEmbedding層で特徴量に変換しています。
また、検索クエリはBERTで、画像特徴量は画像のポジションの情報と併せてそれぞれ特徴量化し、先ほどのembedの結果得られた特徴量と結合して、クエリの特徴と画像の特徴を生成しています。
最後に、クエリの特徴と画像の特徴の組み合わせが正しいか否かを判定する分類器を学習することで最終的な判定結果を得ています。
モデルC: シンプルなFully Connectなネットワーク
前述の1の流れで採用したモデルです。画像特徴量は各Bounding boxの特徴の平均を取ることでクエリは、BERTを使って固定長のベクトルに変換して利用しています。
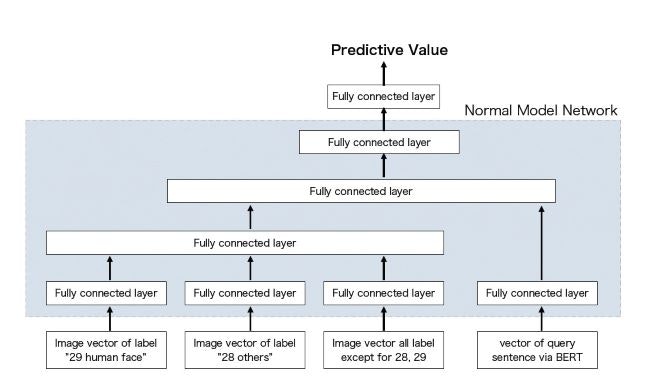
工夫した点は、画像特徴を縮約する際に、全ての特徴を平均するのではなく、Bounding boxのクラスラベルごとに縮約を行った点です。この課題の難しさの章でも書いた通り、本課題ではクエリを構成する単語と、画像中のBounding boxとの対応関係が重要となります。otherのカテゴリは、本当に雑多なBounding boxが入っている事、男性向け/女性向け/子供向けなど、人の顔に着目して判定する必要があるクエリが存在することから、これらのカテゴリの特徴量が残るよう、別々に縮約する事としました。
アンサンブル
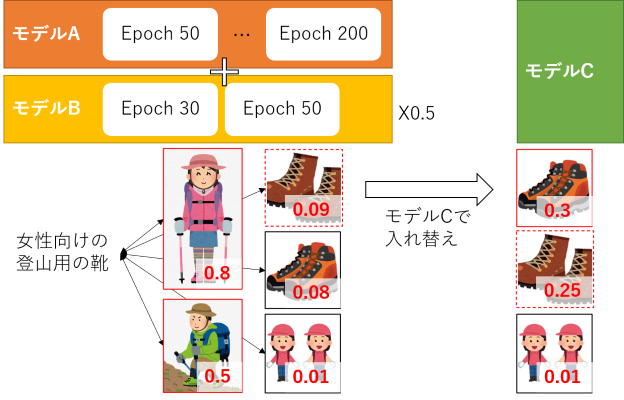
上記3つのモデルの学習がうまく行くようになってくると、学習の各epochでvalidationデータの評価結果が結構変わる事がわかってきました。そこで、アンサンブルする際に複数のモデルだけでなく、epochでアンサンブルする事になりました。
前述のモデルAとモデルBから、異なるepochの合計23個のモデルを抽出し、各モデルの推定値の和を取ることで、アンサンブル後のスコアを得ました。
スコアの和を取るにあたっては、モデルBのスコアに0.5をかけた上で加算しました。これは、モデルBの精度がモデルAに比べて低かったためです。
また、上記のアンサンブルで得られた各画像のスコアについて、スコアが0.1以下のものがあった場合には、モデルCでハイスコアだった候補画像と切り替える処理を行いました。モデルCの精度が、モデルA, Bに対して低かったため、補助的に利用した形です。
結果
上記のモデル、アンサンブルにより、NDCG@5で0.770を達成し、7位入賞を果たしました。
感想
大量のデータで大規模なDeep Learningモデル学習させることが、データ分析コンペでも必須なのだなと感じました。今回、ViLBERTはV100x4使って学習しても、数日学習にかかり...GPUも大量に使えないとコンペで上に上がるのが難しい、厳しい時代になった気がします。
私は普段画像処理/動画処理がターゲットに開発を行っており、Transformerは触ったことがなかったのですが、本コンペを通してTrasnformerの有効性を肌で感じることができました。ViLBERTは画像と文で相互にAttentionをかけるという、他のタスクにも使えそうなネットワークなので、今後より理解を深めたい&似た系統の他のネットワークも実装してみたいです。
明日は、チームメンバーが上位入賞手法の解説をしてくれますが、そちらも見越した反省点を。
- 単にモデル間でアンサンブルだけでなく、各モデルの様々なエポックのモデルをアンサンブルに入れるのが効果的
- より複雑なモデルを、たくさんアンサンブルする事でより精度上げられる
- データのクレンジング、データの特性に合わせた加工が十分できていなかった
KDDCupは最近中国の大学や企業が上位を独占する傾向が強いので、来年はぜひ皆様もご参加いただき、日本勢でKDD Cupを盛り上げていきましょう!