1. はじめに
テーマ「"やってはいけない” アンチパターンを共有しよう!」…色々とネタが思い当たります!
最近再び出会った、とある問題についてご紹介しようと思います。
2. それは画像の異常検知を解いていたときのこと…
画像の異常検知とは、正常な画像に対して異常な画像を検出して、例えば不良品の選別などに使う技術です。

図: MVTec ADウェブサイトより、緑 の正常サンプルに対する 赤 の異常サンプル例。
普通あまり「異常の画像」が発生しないので、「距離学習」という手法を使って「正常品じゃない度合い」を数値化して、この数値が大きいと「異常だ!」とみなす方法などがあります。
その一つ、記事「幾何変換を使った効果的な深層異常検知 (CNN画像分類モデル/教師なし/MVTec異常検知データセット)」で紹介した「DADGT」という略称の手法を試していたときのことです。
3. 学習〜やったね、AUC 98%!
私のリポジトリ github.com/daisukelab/image-anomaly-det にこのDADGTが実装してあり、MVTecADというデータセット(詳しくは記事「欠陥発見! MVTec異常検知データセットへの深層距離学習(Deep Metric Learning)応用」へ)のうち、適当なものとしてトランジスタの画像を異常診断させていました。

図: MVTec ADデータセットのトランジスタ例、左から正常・足曲がり・足欠け・ボディ欠け
このようなデータの内、正常なデータは「正常」、それ以外の様々な異常データは「異常」と診断したいのです。
この学習データ、2~300枚規模と小さくはありますが、学習を高速化するために、データを一旦小さくしてローカルSSDに保持します。
def make_resized_files(src_files, dest_folder, suffix, load_size):
"""リサイズしたファイルを生成。
Args:
src_files: 変換対象のファイルのリスト。
dest_folder: 変換先フォルダ(なければ作成する)。
suffix: 変換後のファイル形式の拡張子。
load_size: 変換後画像サイズの一辺。
"""
dest_folder = Path(dest_folder)
ensure_folder(dest_folder)
files = []
for file_name in src_files:
img = Image.open(file_name)
img = img.convert('RGB').resize((load_size, load_size))
new_file_name = dest_folder/f'{Path(file_name).stem}{suffix}'
img.save(new_file_name)
files.append(new_file_name)
return files
このような関数を使って、下記のように予め変換して temp/train に学習データ、 temp/test に評価データを置きました。
train_files = make_resized_files((ORG/'train/good').glob('*.png'), dest_folder='temp/train',
suffix='.jpg', load_size=params.load_size)
test_good = make_resized_files((ORG/'test/good').glob('*.png'), dest_folder='temp/test/good',
suffix='.jpg', load_size=params.load_size)
test_bend = make_resized_files((ORG/'test/bent_lead').glob('*.png'), dest_folder='temp/test/bend',
suffix='.png', load_size=params.load_size)
test_cut = make_resized_files((ORG/'test/cut_lead').glob('*.png'), dest_folder='temp/test/cut',
suffix='.png', load_size=params.load_size)
test_damaged = make_resized_files((ORG/'test/damaged_case').glob('*.png'), dest_folder='temp/test/damaged',
suffix='.png', load_size=params.load_size)
学習はこうやって簡単に行なえます。リポジトリにライブラリ化してあるものをそのまま利用しました。
train_dataset = params.ds_cls(file_list=train_files, load_size=params.load_size, crop_size=params.crop_size,
transform=ImageTransform(), random=True)
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=params.fit.batch_size, shuffle=True)
model = create_model(device, params.n_class, weight_file=None)
learner = TrainingScheme(device, model, params, train_files, params.ds_cls)
trainer = pl.Trainer(max_epochs=params.fit.epochs, gpus=torch.cuda.device_count(), show_progress_bar=False)
trainer.fit(learner)
手早く評価してみます。
test_files = test_good + test_bend + test_cut + test_damaged
labels = np.array([0] * len(test_good) + [1] * len(test_bend) + [1] * len(test_cut) + [1] * len(test_damaged))
auc, ns = GeoTfmEval.calc(device, learner, test_files, labels, params.n_class)
print(auc)
やったね、見事に__AUC=98%__。中々の性能です! ※ AUCはよく使われる評価指標。
0.9838888888888889
4. ところがいざ運用データでの評価は…
落ち着きを取り戻し、運用を模擬したデータで評価してみます。
test2_files = test2_good + test2_bend + test2_cut + test2_damaged
labels = np.array([0] * len(test2_good) + [1] * len(test2_bend) + [1] * len(test2_cut) + [1] * len(test2_damaged))
auc, ns = GeoTfmEval.calc(device, learner, test2_files, labels, params.n_class)
print(auc)
結果は何と…
0.7322222222222223
!? なぜでしょう。色々と試してみますが、モデルや学習コードに問題はありませんでした。
5. 原因はなんと…
原因はデータのフォーマットにありました。__98%に達したときの正常データはJPEG、異常データはPNG__だったので、その差が問題となっていたのです(※これまでのコードは発生当時の状況を再現させたものですが、実際に起こりました)。
そして__73%しか出ない時のデータは全てJPEGだった__のです。運用時は全てJPEGだろう、以下のように生成しました。
test2_good = make_resized_files((ORG/'test/good').glob('*.png'), dest_folder='temp/test2/good',
suffix='.jpg', load_size=params.load_size)
test2_bend = make_resized_files((ORG/'test/bent_lead').glob('*.png'), dest_folder='temp/test2/bend',
suffix='.jpg', load_size=params.load_size)
test2_cut = make_resized_files((ORG/'test/cut_lead').glob('*.png'), dest_folder='temp/test2/cut',
suffix='.jpg', load_size=params.load_size)
test2_damaged = make_resized_files((ORG/'test/damaged_case').glob('*.png'), dest_folder='temp/test2/damaged',
suffix='.jpg', load_size=params.load_size)
この問題、距離学習で特に出やすいと思います。解説したいと思いますが、まずDADGTの仕組みを見てみましょう。
5-1. DADGTでの異常の判定方法
DADGTでは、判定したい画像を入力するとデータ拡張を適用し、それぞれ「どんなデータ拡張を適用させたか」の確率を出力させます。
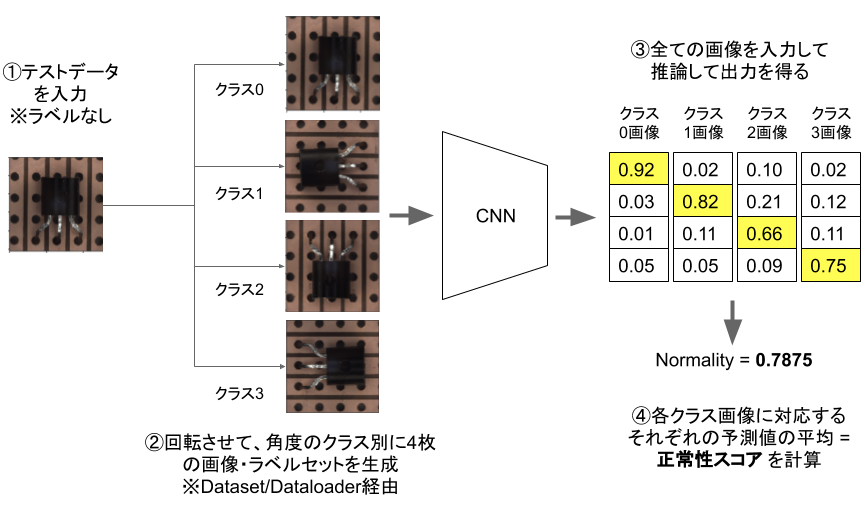
図: DADGTの推論フロー
この推論の確率が高くなるように学習するので、正常データを与えたらこの正常性スコアが高くなるはずです。
ここに、異常な画像を与えたらどうなるでしょうか。
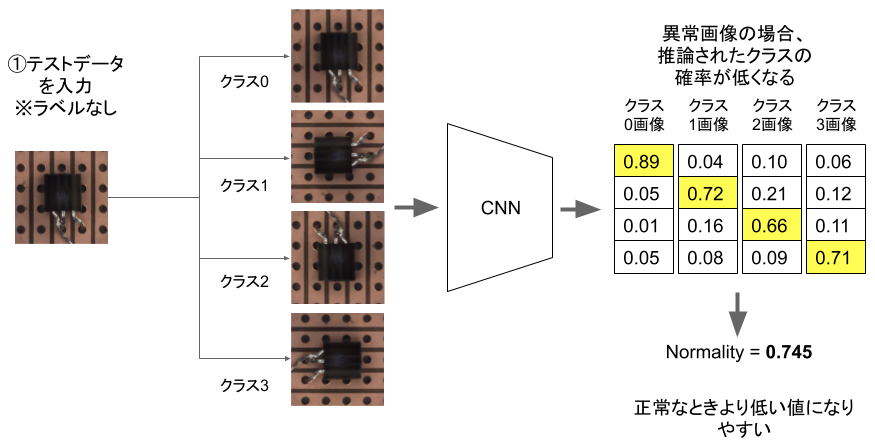
図: 異常画像に対するフロー例、少し推論確率が低くなる
学習したものと違いがあるので、確率が低く出るはずなんです。各データ拡張、ここでは90度・180度・270度回転それぞれを適用したときの確率を平均した値、その平均確率を「正常度」として取り扱うと、この数字が小さいものを「異常だ!」と判定できるという仕組みです。
5-2. なぜ問題になったのか
学習は全てJPEGデータに対して行われました。つまり「JPEGをよく知っている」モデルになりました。
-
開発の評価では、評価データとして「正常はJPEG、異常はPNG」で与えました。モデルは「PNGのなめらかさ、これ知らない、確率低くする」としてしまったのです(お気持ちを考えるとおそらく…)。
「JPEGは正常品の正常度 > PNGは異常品の正常度」となりやすい状況が発生してしまったのです。
-
運用の評価では、「正常も異常も全部JPEG」で与えると、モデルは「どれも見たことある…確率高めで」としてしまいます。
**「正常品の正常度 ≧ 異常品の正常度」**くらいにマイルドになり、「どっちもどっちやな」と異常判定できない状況が増えたというわけです。
5-3. 更に実験してみる
全部PNGだったらどうなったでしょうか。
o_test_good = list((ORG/'test/good').glob('*.png'))
o_test_bend = list((ORG/'test/bent_lead').glob('*.png'))
o_test_cut = list((ORG/'test/cut_lead').glob('*.png'))
o_test_damaged = list((ORG/'test/damaged_case').glob('*.png'))
test_files = o_test_good + o_test_bend + o_test_cut + o_test_damaged
labels = np.array([0] * len(o_test_good) + [1] * len(o_test_bend) + [1] * len(o_test_cut) + [1] * len(o_test_damaged))
auc, ns = GeoTfmEval.calc(device, learner, test_files, labels, params.n_class)
print(auc)
思い切ってオリジナルファイルを与えてみます。 ※ パイプラインのtransformでリサイズしています。
0.6633333333333333
更に悪いAUC…JPEGしか学習したことがないので、PNGオンリーにすると、更にモデルは混乱してしまったようです…
…というのは、実はとあるパラメーターのとき起こった一例です。
この例、私の環境で再現可能、かつ最も極端な例をご紹介しました。
ところが、他のパラメーターではもっとタチが悪い形で現れます…。
6. 微妙に発見が難しいケース
タチが悪いとは「気づけないくらい微妙に現れてしまう」ケースです。
問題があそこにある、でも気づけない。残念な性能劣化が放置されてしまう、そんなケースをみてみましょう。
SIZE = 64
params.fit.lr = 0.0003
元々上のようなパラメーターを、このくらい変えました。
SIZE = 256 # 画像サイズの一辺
params.fit.lr = 0.003 # 学習率
すると、結果はそれぞれこのようになりました。
| フェーズ | AUC |
|---|---|
| a. 開発評価時 | 0.9002777777777778 |
| b. 運用評価時(全てJPEG) | 0.8947222222222222 |
| c. 運用評価時(全てPNG) | 0.8733333333333334 |
bで微妙に性能が落ち、cでは無視できないくらい落ちています。でも、現場だと「何故か落ちるんですよね」ぐらいでスルーすることもあり得ると思います。
「テスト環境はデータ分布が違うみたいですね」などともっともらしいことを言ってしまうかもしれません。
7. アンチパターンを掘り下げる
以上から、この記事でのアンチパターンを一旦このようにしたいと思います。
アンチパターン: 画像データのフォーマットが一貫していない
学習を高速化したいなどの都合などで、一旦変換することなどはしょっちゅうあると思います。その時のフォーマットにも気をつけたほうが良さそうです。
でもこれ、本当の原因でしょうか?
実は、よく学習できているときは、発生しにくい問題だと経験しています。
本当の、もっともっと一般化したアンチパターンは、
もっと一般化したアンチパターン: モデルを学習させる帰納バイアスが弱い
ではないかと思います。
8. ホントのアンチパターン
この「帰納バイアス」を「動機づけ」と言い換えてもいいと思います。
言い換えたアンチパターン: モデルを学習させる「動機づけ」が弱い
今回の真因、直接的には
JPEGの特徴に反応して、分類確率が高くなるモデルが学習された
ことです。本当に学習させたいのは、
画像が正常であることを特徴づける、トランジスターの各形状から分類確率を出力させたい
のではないでしょうか。なので、今回のDADGTの使い方で仮定した
「画像を回転させて4通りのうちどの回転なのかを当てる」問題設定が弱いのでは??
これがそもそもの原因ではないかと思います。
このくらい簡単ならば、トランジスターの一部しか見なくていいし、画像の見えないくらい小さなJPEGの圧縮伸張で現れるパターンを手がかりに判断してもいいわけです。

9. まとめ
簡単な題材のときMNISTの分類で正解率99%、やった! と喜んで、そのまま仕事終了… とても危険ですね。
機械学習モデルが何を学んでいるか、ブラックボックス的になるケースが多いと思います。特に今回のように深層学習を使うとなおさらでしょう。使える検証方法・指標はできるだけ使いたいものです。今回のようなCNNの場合、例えば以下のような確認方法があります。
- 例えばDataRobot社では、画像の埋め込みが適切にばらついているか、GradCAMのようなヒートマップでの可視化をツールとして用意しています。
- Stanford大学のコースcs231nの資料「Visualizing what ConvNets learn」では、第一層のフィルターを可視化することに言及されています。 "Notice that the first-layer weights are very nice and smooth, indicating nicely converged network."
また、JPEG圧縮パターンを学習させないために、データ拡張のツールとして下記も使えます。
本当に、気をつけたいですね…。
ご紹介したコードを収めたノートブックはこちらに公開しています。
免責事項 ※ひとつめのノートブックは乱数依存性が強く、再現しないと思います。パラメーターをいじると、ひょっとしたら再現できるものが見つかるかもしれません。
・DataRobot社ブログ「Identifying Leakage in Computer Vision on Medical Images」より引用、
「この図では、2つの明らかなグループに分かれていることが分かります。これはレッドフラグです。この図は、2つのクラスに分けるのがとても容易だということを表しています。」

図: 同ブログより、画像の埋め込みを二次元空間上に可視化した様子。簡単すぎて不審だということです。
免責事項 ※ 同社と関わりがあるわけではありません ※
・記事「欠陥発見! MVTec異常検知データセットへの深層距離学習(Deep Metric Learning)応用」より、ヒートマップを可視化した様子。

図: 異常検知の推論を行ったときのヒートマップ。足に注目している様子が確認できる。
・cs231nの資料「Visualizing what ConvNets learn」より。

図: AlexNetの第一層フィルタを可視化。学習がうまく行った場合スムースなフィルタが得られるとのこと。
P.S. 今回ご紹介した問題、数年前に自分自身で一度、最近技術展開していてまた一度遭遇しました。きっと色んな所で起こっている問題ではないでしょうか…
P.S. 更にいうと、プライベートな「少量しか用意できず構図も決まっていて簡単なデータ」で生じやすい印象です…