はじめに
私は今まで、Pythonを使ってデータの可視化ツールを作成してきました。
いくつかはQiitaにも投稿しましたが、記事やコードが分散していて分かりづらいと感じたので、全機能をまとめて「seaborn-analyzer」としてライブラリ化し、概要を本記事にまとめました!
**「実際のデータ分析を通じて欲しいと思った機能」**を詰め込んだので、実務で役立つ機能がいくつもあるかと思います。
ぜひご活用頂ければと思います
構成
本ツールは以下のクラスからなります。
使用法の詳細は、「使用法リンク」中の各記事、および後述の「各機能の解説」をご参照ください
| クラス名 | パッケージ名 | 概要 | 使用法リンク |
|---|---|---|---|
| CustomPairPlot | custom_pair_plot.py | 散布図行列と相関係数行列を同時に表示 | リンク |
| hist | custom_hist_plot.py | ヒストグラムと各種分布のフィッティング | リンク |
| classplot | custom_class_plot.py | 分類境界およびクラス確率の表示 | リンク |
| regplot | custom_reg_plot.py | 相関・回帰分析の散布図・ヒートマップ表示 | リンク |
おすすめ機能
個人的に使用頻度の高い機能を紹介します
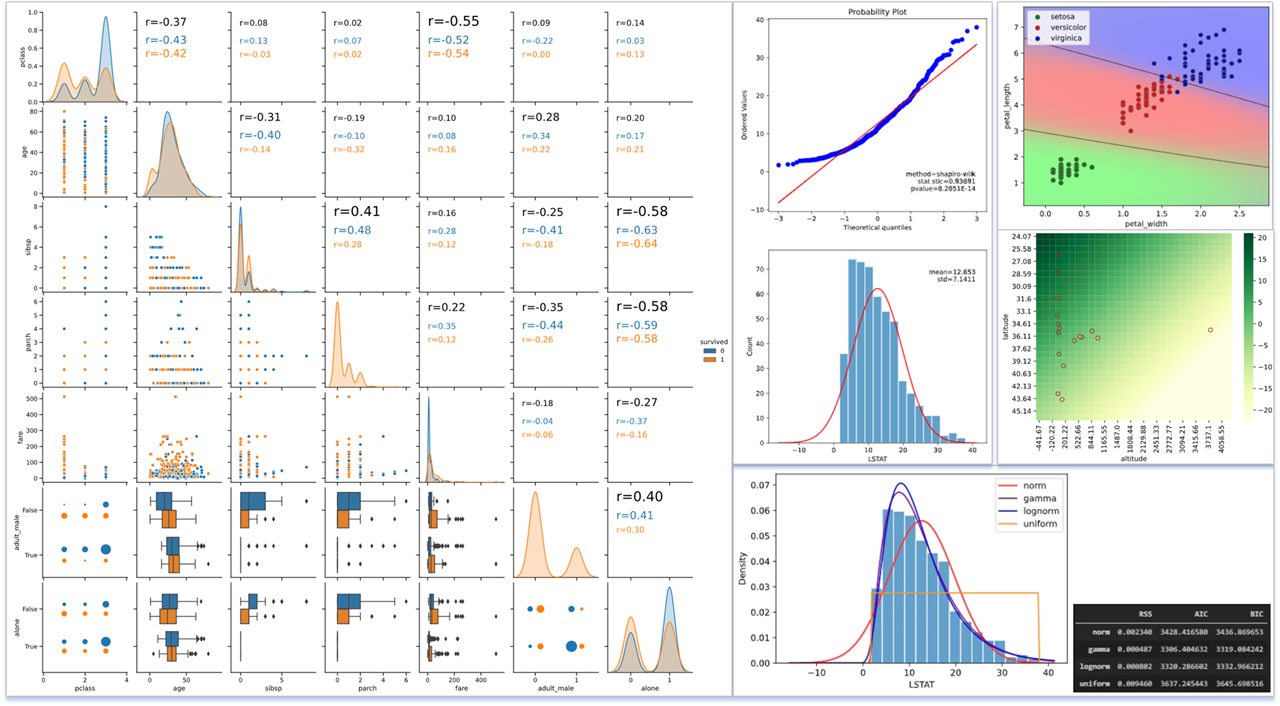
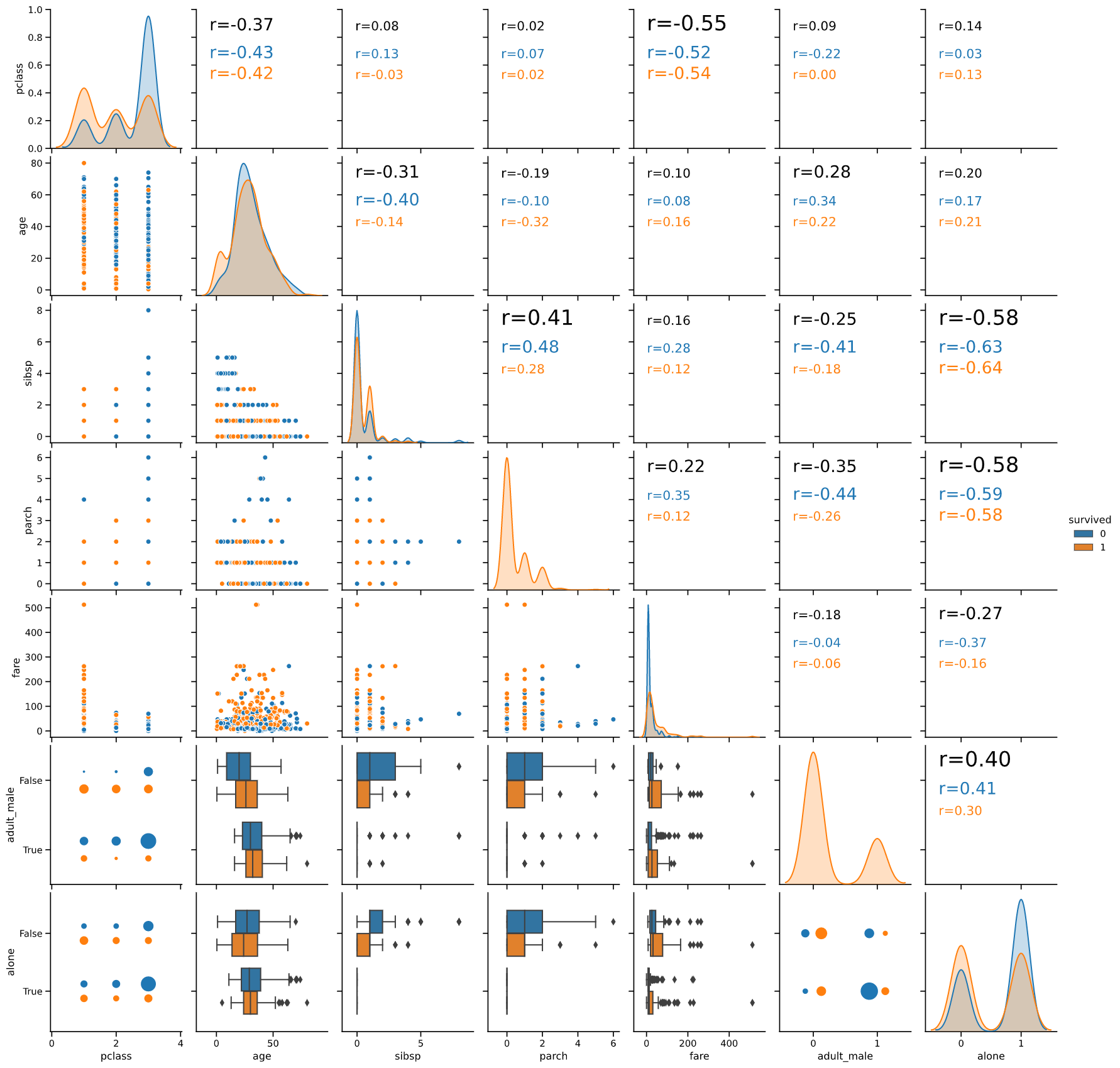
おすすめ1:CustomPairPlot.pairanalyzer
相関係数と散布図行列を一括表示します。
分析の初期段階でデータを一括で可視化したいときにオススメです。
Rのggplot2ではほぼ同様の図が出力可能ですが、なぜかPythonには同様のツールがなかったので、作成しました。
散布図では表示が重なり見辛い離散変数は、自動で箱ひげ図とバブルチャートに変更する機能も追加しています。
from seaborn_analyzer import CustomPairPlot
import seaborn as sns
titanic = sns.load_dataset("titanic")
cp = CustomPairPlot()
cp.pairanalyzer(titanic, hue='survived')
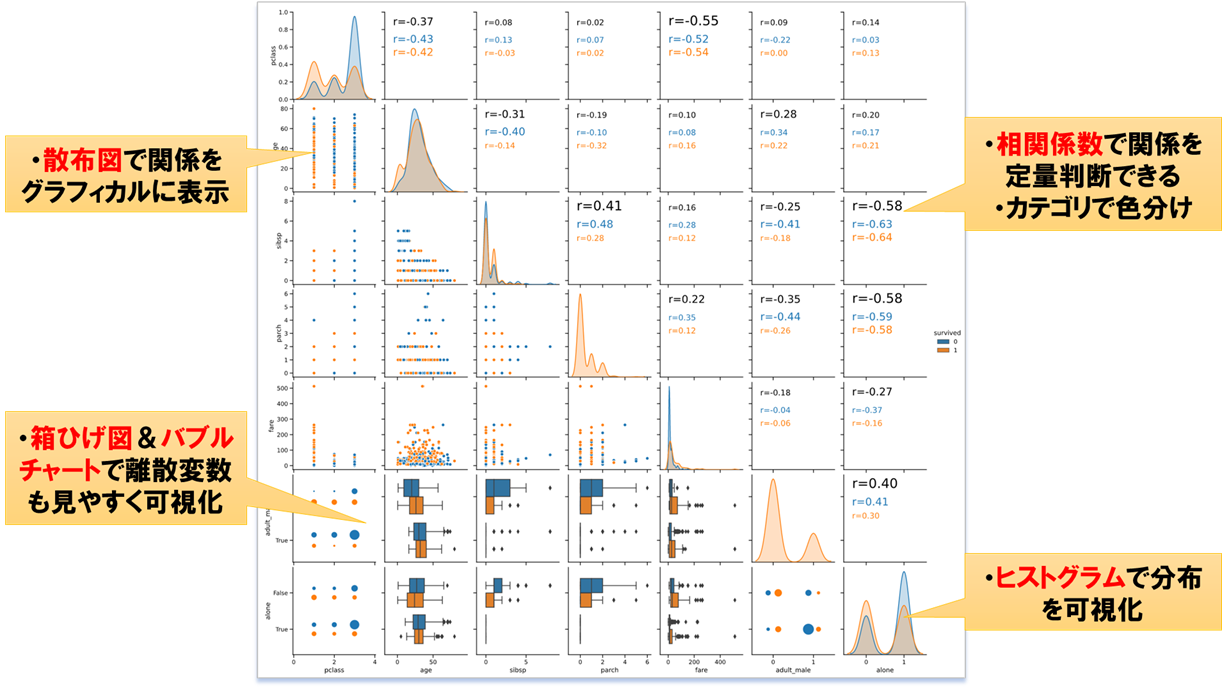
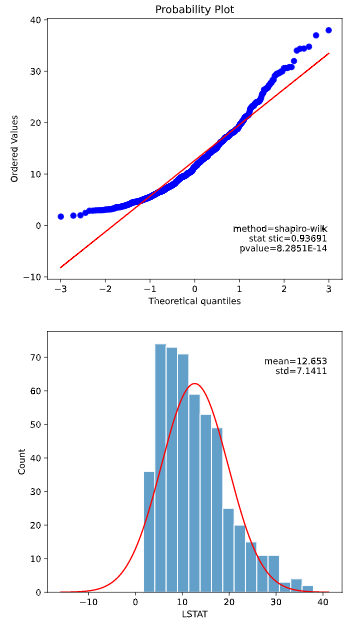
おすすめ2:hist.plot_normality
正規性検定の結果をヒストグラムとともに表示します
正規分布かどうかの判断は曖昧な判定となりがちですが、
定量的な裏付けを付けたい時にオススメです
from seaborn_analyzer import hist
from sklearn.datasets import load_boston
import pandas as pd
df = pd.DataFrame(load_boston().data, columns= load_boston().feature_names)
hist.plot_normality(df, x='LSTAT', norm_hist=False, rounddigit=5)
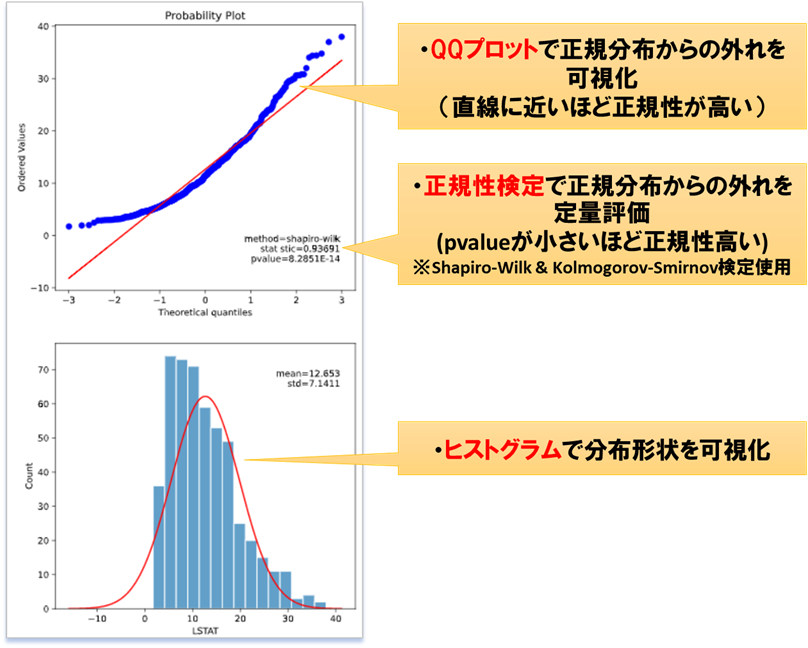
おすすめ3:regplot.linearplot
相関係数、P値、回帰式を同時算出し、散布図と一緒に表示します。。
頑張ればExcelでも算出できる簡単な指標ですが、
全てを同時算出してくれるツールは意外とありません。
多くの情報を1枚の図に集約できるので、ループ実行して多くの変数の相関関係を定量的かつ効率的に見たい時にオススメです
from seaborn_analyzer import regplot
import seaborn as sns
iris = sns.load_dataset("iris")
regplot.linear_plot(x='petal_length', y='sepal_length', data=iris)
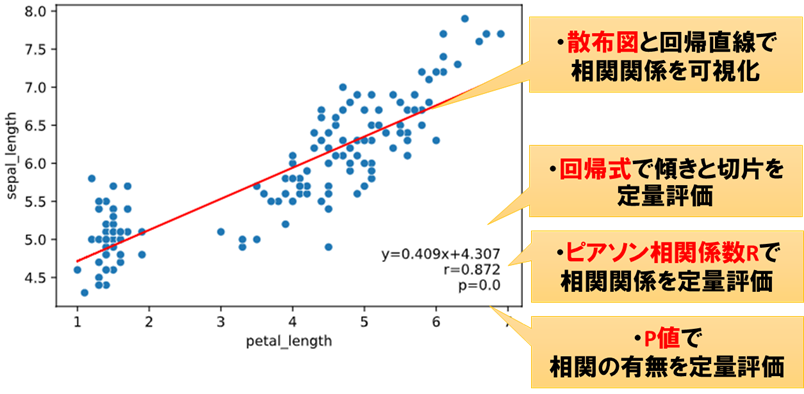
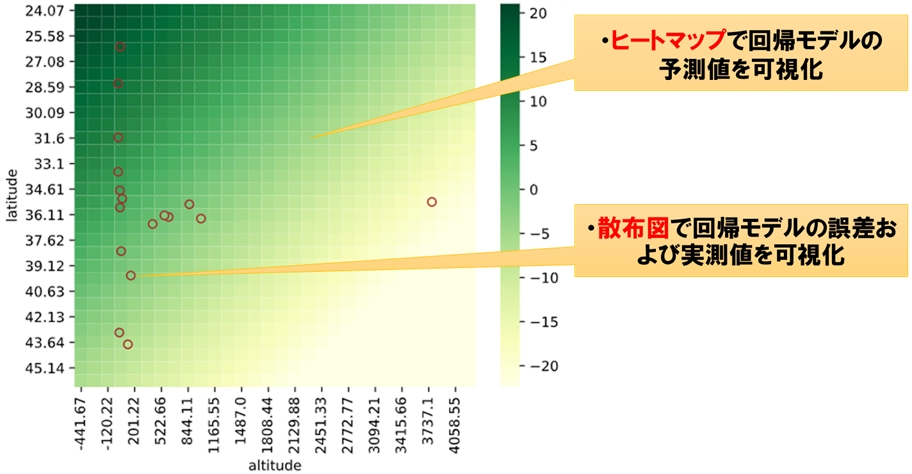
おすすめ4:regplot.regression_heat_plot
説明変数が2次元以上の回帰モデルは可視化が難しいですが、
このメソッドを使えば4次元までならそれなりに直感的な可視化が可能となります。
import pandas as pd
from sklearn.linear_model import LinearRegression
from seaborn_analyzer import regplot
df_temp = pd.read_csv(f'./sample_data/temp_pressure.csv')
regplot.regression_heat_plot(LinearRegression(), x=['altitude', 'latitude'], y='temperature', data=df_temp)
import pandas as pd
from sklearn.linear_model import LinearRegression
from seaborn_analyzer import regplot
df = pd.read_csv(f'./sample_data/osaka_metropolis_english.csv')
regplot.regression_heat_plot(LinearRegression(), x=['2_between_30to60', '3_male_ratio', '5_household_member', 'latitude'],
y='approval_rate', data=df,
pair_sigmarange = 0.5, rounddigit_x1=3, rounddigit_x2=3)

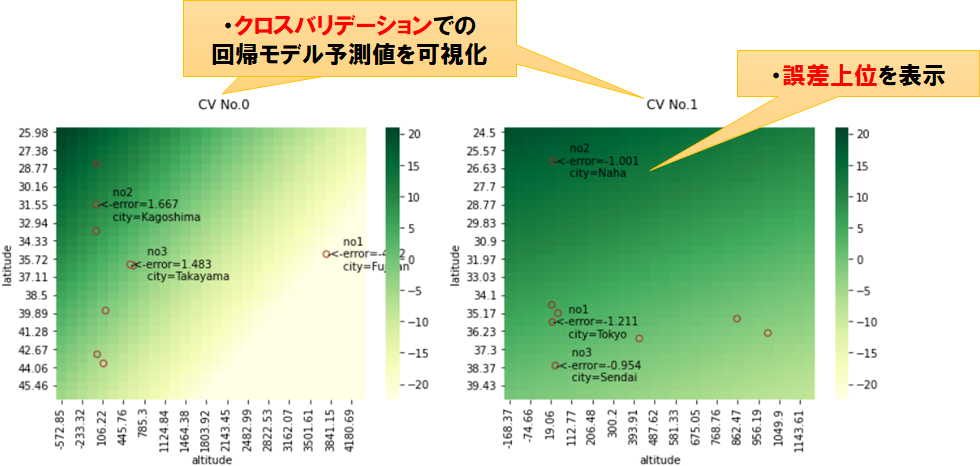
また、クロスバリデーションの可視化や誤差上位の表示など、モデルの傾向把握に便利な機能を多数実装しています。詳細はこちらの記事を参照ください
import pandas as pd
from sklearn.linear_model import LinearRegression
from seaborn_analyzer import regplot
df_temp = pd.read_csv(f'./sample_data/temp_pressure.csv')
regplot.regression_heat_plot(LinearRegression(), cv=2, display_cv_indices=[0, 1], rank_number=3, rank_col='city',
x=['altitude', 'latitude'], y='temperature', data=df_temp)
必要要件
- Python >=3.6
- Numpy >=1.20.3
- Pandas >=1.2.4
- Matplotlib >=3.3.4
- Seaborn >=0.11.0 (最新版の0.11.1ではバグがあるので、0.11.0を使用してください)
- Scipy >=1.6.3
- Scikit-learn >=0.24.2
インストール方法
pipからインストールできます。
$ pip install seaborn-analyzer
各機能の解説
クラスおよびメソッドごとに機能と引数を解説します
CustomPairPlotクラス (custom_pair_plot.py)
散布図行列と相関係数行列を同時に表示します。
1個のクラス「CustomPairPlot」からなります
・CustomPairPlotクラス内のメソッド一覧
| メソッド名 | 機能 |
|---|---|
| pairanalyzer | 散布図行列と相関係数行列を同時に表示します |
pairanalyzerメソッド
実行例
from seaborn_analyzer import CustomPairPlot
import seaborn as sns
titanic = sns.load_dataset("titanic")
cp = CustomPairPlot()
cp.pairanalyzer(titanic, hue='survived')
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| data | 必須 | pd.DataFrame | - | 入力データ |
| hue | オプション | str | None | 色分けに指定するカラム名 (Noneなら色分けなし) |
| palette | オプション | str | None | hueによる色分け用のカラーパレット |
| vars | オプション | list[str] | None | グラフ化するカラム名 (Noneなら全ての数値型&Boolean型の列を使用) |
| lowerkind | オプション | str | 'boxscatter' | 左下に表示するグラフ種類 ('boxscatter', 'scatter', or 'reg') |
| diag_kind | オプション | str | 'kde' | 対角に表示するグラフ種類 ('kde' or 'hist') |
| markers | オプション | str or list[str] | None | hueで色分けしたデータの散布図プロット形状 |
| height | オプション | float | 2.5 | グラフ1個の高さ |
| aspect | オプション | float | 1 | グラフ1個の縦横比 |
| dropna | オプション | bool | True | seaborn.PairGridのdropna引数 |
| lower_kws | オプション | dict | {} | seaborn.PairGrid.map_lowerの引数 |
| diag_kws | オプション | dict | {} | seaborn.PairGrid.map_diag引数 |
| grid_kws | オプション | dict | {} | seaborn.PairGridの上記以外の引数 |
CustomPairPlotクラス使用法詳細
こちらの記事にまとめました
https://qiita.com/c60evaporator/items/20f11b6ee965cec48570
histクラス (custom_hist_plot.py)
ヒストグラム表示および各種分布のフィッティングを実行します。
・histクラス内のメソッド一覧
| メソッド名 | 機能 |
|---|---|
| plot_normality | 正規性検定とQQプロット |
| fit_dist | 各種分布のフィッティングと、評価指標(RSS, AIC, BIC)の算出 |
plot_normalityメソッド
実行例
from seaborn_analyzer import hist
from sklearn.datasets import load_boston
import pandas as pd
df = pd.DataFrame(load_boston().data, columns= load_boston().feature_names)
hist.plot_normality(df, x='LSTAT', norm_hist=False, rounddigit=5)
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| data | 必須 | pd.DataFrame, pd.Series, or pd.ndarray | - | 入力データ |
| x | オプション | str | None | ヒストグラム作成対象のカラム名 (dataがpd.DataFrameのときは必須) |
| hue | オプション | str | None | 色分けに指定するカラム名 (Noneなら色分けなし) |
| binwidth | オプション | float | None | ビンの幅 (binsと共存不可) |
| bins | オプション | int | 'auto' | ビンの数 (bin_widthと共存不可、'auto'ならスタージェスの公式で自動決定) |
| norm_hist | オプション | bool | False | ヒストグラムを面積1となるよう正規化するか? |
| sigmarange | オプション | float | 4 | フィッティング線の表示範囲 (標準偏差の何倍まで表示するか指定) |
| linesplit | オプション | float | 200 | フィッティング線の分割数 (カクカクしたら増やす) |
| rounddigit | オプション | int | 5 | 表示指標の小数丸め桁数 |
| hist_kws | オプション | dict | {} | matplotlib.axes.Axes.histに渡す引数 |
| subplot_kws | オプション | dict | {} | matplotlib.pyplot.subplotsに渡す引数 |
fit_distメソッド
実行例
from seaborn_analyzer import hist
from sklearn.datasets import load_boston
import pandas as pd
import matplotlib.pyplot as plt
from scipy import stats
df = pd.DataFrame(load_boston().data, columns= load_boston().feature_names)
all_params, all_scores = hist.fit_dist(df, x='LSTAT', dist=['norm', 'gamma', 'lognorm', 'uniform'])
df_scores = pd.DataFrame(all_scores).T
df_scores
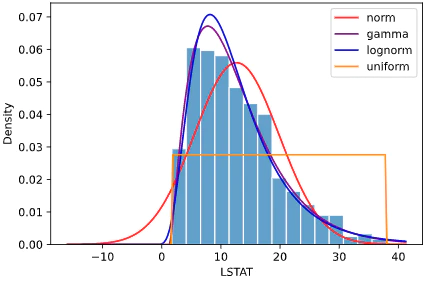
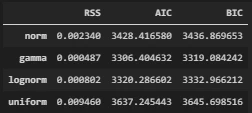
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| data | 必須 | pd.DataFrame, pd.Series, or pd.ndarray | - | 入力データ |
| x | オプション | str | None | ヒストグラム作成対象のカラム名 (dataがpd.DataFrameのときは必須) |
| hue | オプション | str | None | 色分けに指定するカラム名 (Noneなら色分けなし) |
| binwidth | オプション | float | None | ビンの幅 (binsと共存不可) |
| bins | オプション | int | 'auto' | ビンの数 (bin_widthと共存不可、'auto'ならスタージェスの公式で自動決定) |
| norm_hist | オプション | bool | False | ヒストグラムを面積1となるよう正規化するか? |
| sigmarange | オプション | float | 4 | フィッティング線の表示範囲 (標準偏差の何倍まで表示するか指定) |
| linesplit | オプション | float | 200 | フィッティング線の分割数 (カクカクしたら増やす) |
| dist | オプション | str or list[str] | 'norm' | 分布の種類 ('norm', 'lognorm', 'gamma', 't', 'expon', 'uniform', 'chi2', 'weibull') |
| ax | オプション | matplotlib.axes.Axes | None | 表示対象のax (Noneならmatplotlib.pyplot.plotで1枚ごとにプロット) |
| linecolor | オプション | str or list[str] | 'red' | フィッティング線の色指定 (listで複数指定可) |
| floc | オプション | float | None | フィッティング時のX方向オフセット (Noneなら指定なし(weibullとexponは0)) |
| hist_kws | オプション | dict | {} | matplotlib.axes.Axes.histに渡す引数 |
histクラス使用法詳細
こちらの記事にまとめました
https://qiita.com/c60evaporator/items/fc531aff0cdbafac0f42
classplotクラス
分類の決定境界およびクラス確率の表示を実行します。
Scikit-Learn APIに対応した分類モデル (例: XGBoostパッケージのXGBoostClassifierクラス)が表示対象となります
・classplotクラス内のメソッド一覧
| メソッド名 | 機能 |
|---|---|
| class_separator_plot | 決定境界プロット |
| class_proba_plot | クラス確率プロット |
class_separator_plotメソッド
実行例
import seaborn as sns
from sklearn.svm import SVC
from seaborn_analyzer import classplot
iris = sns.load_dataset("iris")
clf= SVC()
classplot.class_separator_plot(clf, ['petal_width', 'petal_length'], 'species', iris)
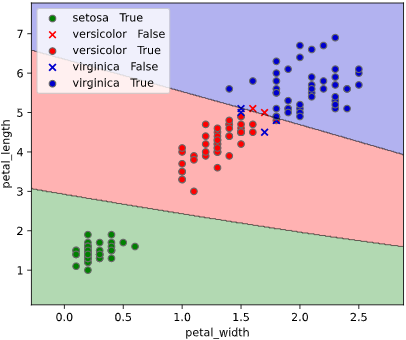
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| clf | 必須 | Scikit-learn API | - | 表示対象の分類モデル |
| x | 必須 | list[str] | - | 説明変数に指定するカラム名 |
| y | 必須 | str | - | 目的変数に指定するカラム名 |
| data | 必須 | pd.DataFrame | - | 入力データ |
| x_chart | オプション | list[str] | None | 説明変数のうちグラフ表示対象のカラム名 |
| pair_sigmarange | オプション | float | 1.5 | グラフ非使用変数の分割範囲 |
| pair_sigmainterval | オプション | float | 0.5 | グラフ非使用変数の1枚あたり表示範囲 |
| chart_extendsigma | オプション | float | 0.5 | グラフ縦軸横軸の表示拡張範囲 |
| chart_scale | オプション | int | 1 | グラフの描画倍率 |
| plot_scatter | オプション | str | 'true' | 散布図の描画種類 |
| rounddigit_x3 | オプション | int | 2 | グラフ非使用軸の小数丸め桁数 |
| scatter_colors | オプション | list[str] | None | クラスごとのプロット色のリスト |
| true_marker | オプション | str | None | 正解クラスの散布図プロット形状 |
| false_marker | オプション | str | None | 不正解クラスの散布図プロット形状 |
| cv | オプション | int or sklearn.model _selection.* | None | クロスバリデーション分割法 (Noneのとき学習データから指標算出、int入力時はkFoldで分割) |
| cv_seed | オプション | int | 42 | クロスバリデーションの乱数シード |
| cv_group | オプション | str | None | GroupKFold,LeaveOneGroupOutのグルーピング対象カラム名 |
| display_cv_indices | オプション | int | 0 | 表示対象のクロスバリデーション番号 |
| clf_params | オプション | dict | None | 分類モデルに渡すパラメータ |
| fit_params | オプション | dict | None | 学習時のパラメータ |
| subplot_kws | オプション | dict | None | matplotlib.pyplot.subplotsに渡す引数 |
| contourf_kws | オプション | dict | None | グラフ表示用のmatplotlib.pyplot.contourfに渡す引数 |
| scatter_kws | オプション | dict | None | 散布図用のmatplotlib.pyplot.scatterに渡す引数 |
class_proba_plotメソッド
実行例
import seaborn as sns
from sklearn.svm import SVC
from seaborn_analyzer import classplot
iris = sns.load_dataset("iris")
clf= SVC()
classplot.class_proba_plot(clf, ['petal_width', 'petal_length'], 'species', iris,
proba_type='imshow')
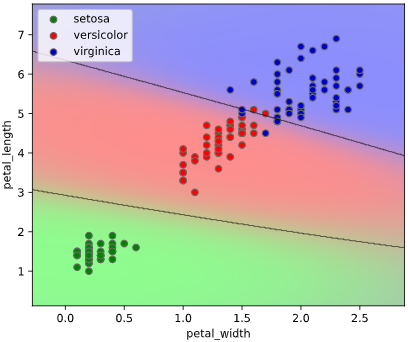
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| clf | 必須 | Scikit-learn API | - | 表示対象の分類モデル |
| x | 必須 | list[str] | - | 説明変数に指定するカラム名 |
| y | 必須 | str | - | 目的変数に指定するカラム名 |
| data | 必須 | pd.DataFrame | - | 入力データ |
| x_chart | オプション | list[str] | None | 説明変数のうちグラフ表示対象のカラム名 |
| pair_sigmarange | オプション | float | 1.5 | グラフ非使用変数の分割範囲 |
| pair_sigmainterval | オプション | float | 0.5 | グラフ非使用変数の1枚あたり表示範囲 |
| chart_extendsigma | オプション | float | 0.5 | グラフ縦軸横軸の表示拡張範囲 |
| chart_scale | オプション | int | 1 | グラフの描画倍率 |
| plot_scatter | オプション | str | 'true' | 散布図の描画種類 |
| rounddigit_x3 | オプション | int | 2 | グラフ非使用軸の小数丸め桁数 |
| scatter_colors | オプション | list[str] | None | クラスごとのプロット色のリスト |
| true_marker | オプション | str | None | 正解クラスの散布図プロット形状 |
| false_marker | オプション | str | None | 不正解クラスの散布図プロット形状 |
| cv | オプション | int or sklearn.model _selection.* | None | クロスバリデーション分割法 (Noneのとき学習データから指標算出、int入力時はkFoldで分割) |
| cv_seed | オプション | int | 42 | クロスバリデーションの乱数シード |
| cv_group | オプション | str | None | GroupKFold, LeaveOneGroupOutのグルーピング対象カラム名 |
| display_cv_indices | オプション | int | 0 | 表示対象のクロスバリデーション番号 |
| clf_params | オプション | dict | None | 分類モデルに渡すパラメータ |
| fit_params | オプション | dict | None | 学習時のパラメータ |
| subplot_kws | オプション | dict | None | matplotlib.pyplot.subplotsに渡す引数 |
| contourf_kws | オプション | dict | None | proba_type='contour'のときmatplotlib.pyplot.contourf、 proba_type='contour'のときcontour)に渡す引数 |
| scatter_kws | オプション | dict | None | 散布図用のmatplotlib.pyplot.scatterに渡す引数 |
| plot_border | オプション | bool | True | 決定境界線の描画有無 |
| proba_class | オプション | str or list[str] | None | 確率表示対象のクラス名 |
| proba_cmap_dict | オプション | dict[str, str] | None | クラス確率図のカラーマップ(クラス名とcolormapをdict指定) |
| proba_type | オプション | str | 'contourf' | クラス確率図の描画種類 (等高線'contourf', 'contour', or RGB画像'imshow') |
| imshow_kws | オプション | dict | None | proba_type='imshow'のときmatplotlib.pyplot.imshowに渡す引数 |
classplotクラス使用法詳細
こちらの記事にまとめました
https://qiita.com/c60evaporator/items/43866a42e09daebb5cc0
regplotクラス
相関・回帰分析の散布図・ヒートマップ表示を実行します。
Scikit-Learn APIに対応した回帰モデル (例: XGBoostパッケージのXGBoostRegressorクラス)が表示対象となります
・regplotクラス内のメソッド一覧
| メソッド名 | 機能 |
|---|---|
| linear_plot | ピアソン相関係数とP値を散布図と共に表示 |
| regression_pred_true | 予測値vs実測値プロット |
| regression_plot_1d | 1次元説明変数で回帰線表示 |
| regression_heat_plot | 2~4次元説明変数で回帰予測値をヒートマップ表示 |
linear_plotメソッド
実行例
from seaborn_analyzer import regplot
import seaborn as sns
iris = sns.load_dataset("iris")
regplot.linear_plot(x='petal_length', y='sepal_length', data=iris)
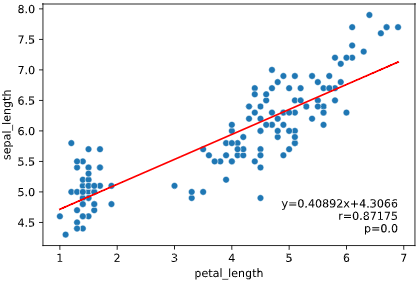
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| x | 必須 | str | - | 横軸に指定するカラム名 |
| y | 必須 | str | - | 縦軸に指定するカラム名 |
| data | 必須 | pd.DataFrame | - | 入力データ |
| ax | オプション | matplotlib.axes.Axes | None | 表示対象のAxes (Noneならmatplotlib.pyplot.plotで1枚ごとにプロット) |
| hue | オプション | str | None | 色分けに指定するカラム名 |
| linecolor | オプション | str | 'red' | 回帰直線の色 |
| rounddigit | オプション | int | 5 | 表示指標の小数丸め桁数 |
| plot_scores | オプション | bool | True | 回帰式、ピアソンの相関係数およびp値の表示有無 |
| scatter_kws | オプション | dict | None | seaborn.scatterplotに渡す引数 |
regression_pred_trueメソッド
実行例
import pandas as pd
from seaborn_analyzer import regplot
import seaborn as sns
from sklearn.linear_model import LinearRegression
df_temp = pd.read_csv(f'./sample_data/temp_pressure.csv')
regplot.regression_pred_true(LinearRegression(), x=['altitude', 'latitude'], y='temperature', data=df_temp)
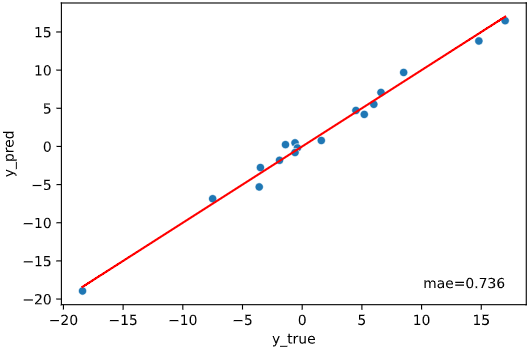
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| estimator | 必須 | Scikit-learn API | - | 表示対象の回帰モデル |
| x | 必須 | list[str] | - | 説明変数に指定するカラム名のリスト |
| y | 必須 | str | - | 目的変数に指定するカラム名 |
| data | 必須 | pd.DataFrame | - | 入力データ |
| hue | オプション | str | None | 色分けに指定するカラム名 |
| linecolor | オプション | str | 'red' | 予測値=実測値の線の色 |
| rounddigit | オプション | int | 3 | 表示指標の小数丸め桁数 |
| rank_number | オプション | int | None | 誤差上位何番目までを文字表示するか |
| rank_col | オプション | str | None | 誤差上位と一緒に表示するフィールド名 |
| scores | オプション | str or list[str] | 'mae' | 文字表示する評価指標を指定 ('r2', 'mae', 'rmse', 'rmsle', or 'max_error') |
| cv_stats | オプション | str | 'mean' | クロスバリデーション時に表示する評価指標統計値 ('mean', 'median', 'max', or 'min') |
| cv | オプション | int or sklearn.model _selection.* | None | クロスバリデーション分割法 (Noneのとき学習データから指標算出、int入力時はkFoldで分割) |
| cv_seed | オプション | int | 42 | クロスバリデーションの乱数シード |
| estimator_params | オプション | dict | None | 回帰モデルに渡すパラメータ |
| fit_params | オプション | dict | None | 学習時のパラメータをdict指定 |
| subplot_kws | オプション | dict | None | matplotlib.pyplot.subplotsに渡す引数 |
| scatter_kws | オプション | dict | None | seaborn.scatterplotに渡す引数 |
regression_plot_1dメソッド
実行例
from seaborn_analyzer import regplot
import seaborn as sns
from sklearn.svm import SVR
iris = sns.load_dataset("iris")
regplot.regression_plot_1d(SVR(), x='petal_length', y='sepal_length', data=iris)
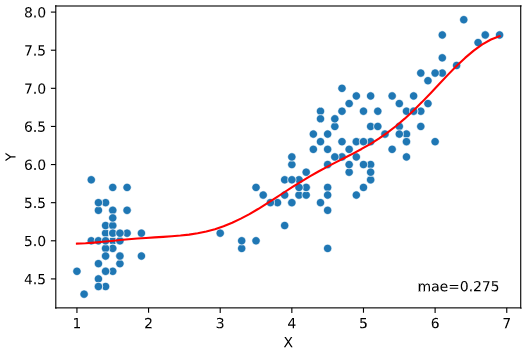
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| estimator | 必須 | Scikit-learn API | - | 表示対象の回帰モデル |
| x | 必須 | str | - | 説明変数に指定するカラム名 |
| y | 必須 | str | - | 目的変数に指定するカラム名 |
| data | 必須 | pd.DataFrame | - | 入力するデータ(Pandasのデータフレーム) |
| hue | オプション | str | None | 色分けに指定するカラム名 |
| linecolor | オプション | str | 'red' | 予測値=実測値の線の色 |
| rounddigit | オプション | int | 3 | 表示指標の小数丸め桁数 |
| rank_number | オプション | int | None | 誤差上位何番目までを文字表示するか |
| rank_col | オプション | str | None | 誤差上位と一緒に表示するフィールド名 |
| scores | オプション | str or list[str] | 'mae' | 文字表示する評価指標を指定 ('r2', 'mae', 'rmse', 'rmsle', or 'max_error') |
| cv_stats | オプション | str | 'mean' | クロスバリデーション時に表示する評価指標統計値 ('mean', 'median', 'max', or 'min') |
| cv | オプション | int or sklearn.model _selection.* | None | クロスバリデーション分割法 (Noneのとき学習データから指標算出、int入力時はkFoldで分割) |
| cv_seed | オプション | int | 42 | クロスバリデーションの乱数シード |
| estimator_params | オプション | dict | None | 回帰モデルに渡すパラメータ |
| fit_params | オプション | dict | None | 学習時のパラメータをdict指定 |
| subplot_kws | オプション | dict | None | matplotlib.pyplot.subplotsに渡す引数 |
| scatter_kws | オプション | dict | None | seaborn.scatterplotに渡す引数 |
regression_heat_plotメソッド
実行例
import pandas as pd
from sklearn.linear_model import LinearRegression
from seaborn_analyzer import regplot
df_temp = pd.read_csv(f'./sample_data/temp_pressure.csv')
regplot.regression_heat_plot(LinearRegression(), x=['altitude', 'latitude'], y='temperature', data=df_temp)
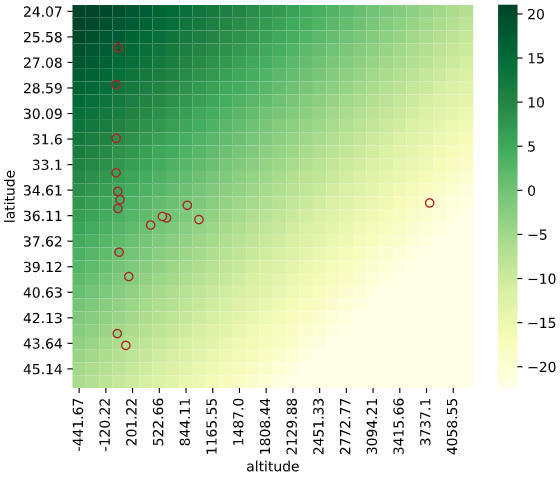
引数一覧
| 引数名 | 必須引数orオプション | 型 | デフォルト値 | 内容 |
|---|---|---|---|---|
| estimator | 必須 | Scikit-learn API | - | 表示対象の回帰モデル |
| x | 必須 | list[str] | - | 説明変数に指定するカラム名のリスト |
| y | 必須 | str | - | 目的変数に指定するカラム名 |
| data | 必須 | pd.DataFrame | - | 入力データ |
| x_heat | オプション | list[str] | None | 説明変数のうちヒートマップ表示対象のカラム名 |
| scatter_hue | オプション | str | None | 散布図色分け指定カラム名 (plot_scatter='hue'時のみ有効) |
| pair_sigmarange | オプション | float | 1.5 | ヒートマップ非使用変数の分割範囲 |
| pair_sigmainterval | オプション | float | 0.5 | ヒートマップ非使用変数の1枚あたり表示範囲 |
| heat_extendsigma | オプション | float | 0.5 | ヒートマップ縦軸横軸の表示拡張範囲 |
| heat_division | オプション | int | 30 | ヒートマップ縦軸横軸の解像度 |
| value_extendsigma | オプション | float | 0.5 | ヒートマップの色分け最大最小値拡張範囲 |
| plot_scatter | オプション | str | 'true' | 散布図の描画種類 |
| rounddigit_rank | オプション | int | 3 | 誤差上位表示の小数丸め桁数 |
| rounddigit_x1 | オプション | int | 2 | ヒートマップ横軸の小数丸め桁数 |
| rounddigit_x2 | オプション | int | 2 | ヒートマップ縦軸の小数丸め桁数 |
| rounddigit_x3 | オプション | int | 2 | ヒートマップ非使用軸の小数丸め桁数 |
| rank_number | オプション | int | None | 誤差上位何番目までを文字表示するか |
| rank_col | オプション | str | None | 誤差上位と一緒に表示するフィールド名 |
| cv | オプション | int or sklearn.model _selection.* | None | クロスバリデーション分割法 (Noneのとき学習データから指標算出、int入力時はkFoldで分割) |
| cv_seed | オプション | int | 42 | クロスバリデーションの乱数シード |
| display_cv_indices | オプション | int | 0 | 表示対象のクロスバリデーション番号 |
| estimator_params | オプション | dict | None | 回帰モデルに渡すパラメータ |
| fit_params | オプション | dict | None | 学習時のパラメータをdict指定 |
| subplot_kws | オプション | dict | None | matplotlib.pyplot.subplotsに渡す引数 |
| heat_kws | オプション | dict | None | ヒートマップ用のseaborn.heatmapに渡す引数 |
| scatter_kws | オプション | dict | None | 散布図用のmatplotlib.pyplot.scatterに渡す引数 |
regplotクラス使用法詳細
こちらの記事にまとめました
https://qiita.com/c60evaporator/items/c930c822b527f62796ee
おわりに
データ分析をしていれば、これらの機能がいずれ使える場面があるかと思うので、ぜひ活用いただければと思います。
もしこのツールを良いと思われたら、**GitHubにStar**頂けるとありがたいです!
