はじめに
Redshift Spectrumは、S3を始めとした各種ストレージサービスに対して、Redshiftによるクエリを実現するサービスです。
ざっくり言うと、「S3に保存したCSV等のデータにRedshiftでクエリ実行できるサービス」と呼べ、両者、すなわちデータレイクとDWHの良いとこ取りをできるサービスと呼べるでしょう。
一方で比較的新しいサービスである事から、日本語の記事は充実しているとは言えない状況です。そこで今回、その操作法を簡潔にまとめたいと思います。
Redshift Spectrumの特徴
Redshift Spectrumを利用するメリットとして、Redshiftを既に利用しているのであれば既存のクエリ等の資産を活用できることが挙げられます。また類似サービスである(共にAWS Glueデータカタログを通じてS3にアクセスする)Amazon Athenaと比較して、高負荷時の安定性に分があるようです。
また、DWHであるRedshiftとの使い分けですが、こちらの記事で述べられているように、
- 大容量で参照頻度の少ないテーブル: Redshift Spectrumに移行
- 参照頻度の多いテーブル: ETL等の過去の資産活用やパフォーマンスの観点から、引き続きRedshiftのテーブルを使用
と使い分けると良さそうです。
なおRedshift Spectrumとその他のS3へのクエリサービス(データレイクサービス)との比較は、以下の記事を参照ください
前準備
Redshift Spectrumを使用するために必要な環境を構築します。
使用するデータ
本記事では、こちらの記事で取得したIoTデータを、年ごとにフォルダ分けし、月ごとにCSVファイルにまとめて以下のフォルダ構成 (プレフィックス)でS3バケットに格納して使用します。
なお、Redshift Spectrumでは後ほど作成するRedshiftクラスターとS3バケットを同じリージョンに設置する必要があるのでご注意ください。
実際の使用時は、好きなCSVファイルやテキストファイルをバケット内に格納してください。ただし詳細はパーティションの項で解説しますが、Redshift Spectrumを使用するS3バケットは年、月、日、時のように時間を表すフォルダで分けると都合が良いです。
バケット名
└──sensors
└──per_month
├─2020
│ ├─202008.csv
│ :
│ └─202012.csv
├─2021
│ ├─202101.csv
│ :
│ └─202012.csv
└─2022
├─202101.csv
:
└─202008.csv
コンソールでの表示例
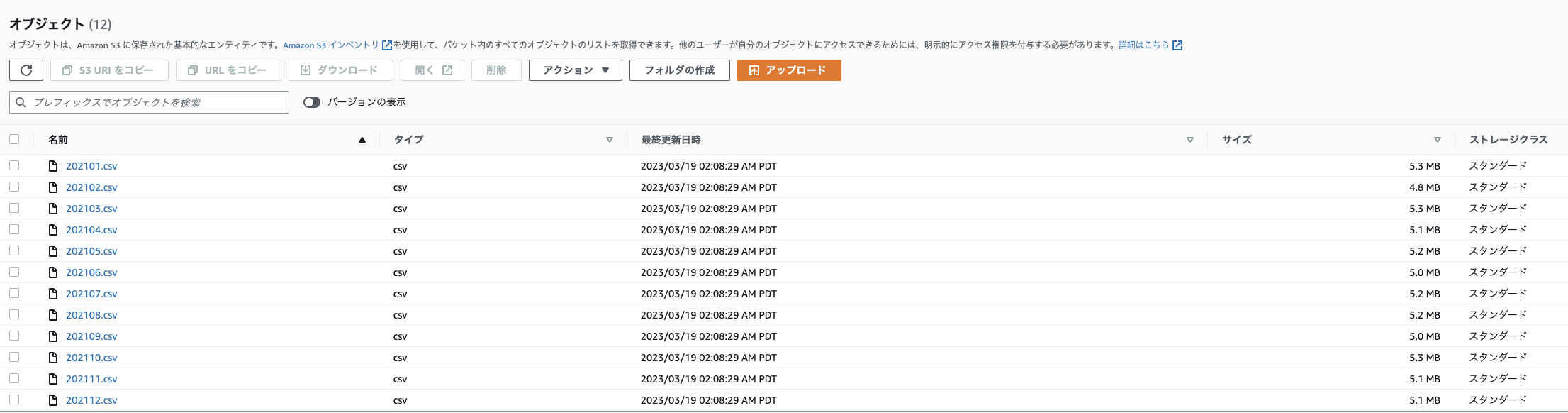
CSVファイルの中身は以下のようになっています (参考)
_id,Date_Master,Date_ScanStart,no01_DeviceName,no01_Date,no01_Temperature,no01_Humidity,no01_Light,no01_Human_last,no01_HumanMotion,no01_TempSetting,no01_AirconMode,no01_AirVolume,no01_AirDirection,no01_AirconPower,no01_CumulativeEnergy,no01_Watt,no02_DeviceName,no02_Date,no02_Temperature,no02_Humidity,no02_Light,no02_Pressure,no02_Noise,no02_eTVOC,no02_eCO2,no03_DeviceName,no03_Date,no03_Temperature,no03_Humidity,no04_DeviceName,no04_Date,no04_Temperature,no04_Humidity,no05_DeviceName,no05_Date,no05_Temperature,no05_Humidity,no05_Light,no05_UV,no05_Pressure,no05_Noise,no05_BatteryVoltage,no06_DeviceName,no06_Date,no06_Temperature,no06_Humidity,no07_DeviceName,no07_Date,no07_Temperature,no07_Humidity,no07_BatteryVoltage,no08_DeviceName,no08_Date,no08_HumanLast,no08_HumanMotion,_partition
5f359f60de55bc0802637080,2020-08-14 05:15:00.000,2020-08-14 05:15:03.891,Nature_Remo_1,2020-08-14 05:15:06.167,28.2,64.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.17,548.0,Omron_USB_1,2020-08-14 05:15:07.093,27.48,71.54,111,1005.229,58.29,289,1650,Inkbird_IBSTH1_1,2020-08-14 05:15:10.068,27.91,68.21,Inkbird_IBSTH1_2,2020-08-14 05:15:12.706,31.49,63.15,Omron_BAG_1,2020-08-14 05:15:17.748,32.18,62.48,6.0,0.01,1006.3,39.8,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:15:21.384,26.53,75.28,SwitchBot_Thermo_1,2020-08-14 05:15:26.413,31.7,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:15:28.835,2020-08-13T20:14:14.000Z,1,Project HomeIoT
5f35a09092376c3d5d76612c,2020-08-14 05:20:00.000,2020-08-14 05:20:04.054,Nature_Remo_1,2020-08-14 05:20:06.294,28.2,62.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.22,360.0,Omron_USB_1,2020-08-14 05:20:07.249,27.45,68.86,108,1005.284,46.18,280,1638,Inkbird_IBSTH1_1,2020-08-14 05:20:12.872,27.93,66.46,Inkbird_IBSTH1_2,2020-08-14 05:20:17.417,31.4,63.06,Omron_BAG_1,2020-08-14 05:20:22.446,32.24,62.63,13.0,0.02,1006.3,38.61,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:20:25.224,26.51,74.69,SwitchBot_Thermo_1,2020-08-14 05:20:30.252,31.9,64.0,100.0,Sony_MeshHuman_1,2020-08-14 05:20:32.635,2020-08-13T20:20:14.000Z,1,Project HomeIoT
5f35a1ba291e40c5ea258ee3,2020-08-14 05:25:00.000,2020-08-14 05:25:04.460,Nature_Remo_1,2020-08-14 05:25:06.701,28.2,64.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.25,580.0,Omron_USB_1,2020-08-14 05:25:07.458,27.32,70.51,106,1005.352,44.38,259,1615,Inkbird_IBSTH1_1,2020-08-14 05:25:09.629,27.95,68.14,Inkbird_IBSTH1_2,2020-08-14 05:25:11.219,31.4,62.94,Omron_BAG_1,2020-08-14 05:25:21.290,32.15,62.87,25.0,0.03,1006.3,39.02,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:25:23.063,26.53,73.39,SwitchBot_Thermo_1,2020-08-14 05:25:28.090,31.8,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:25:30.343,2020-08-13T20:24:14.000Z,1,Project HomeIoT
5f35a2e24098c6e9f618daa4,2020-08-14 05:30:00.000,2020-08-14 05:30:03.594,Nature_Remo_1,2020-08-14 05:30:05.794,28.2,64.0,143.0,2020-08-13T20:08:42Z,0.0,28.0,cool,1,auto,power-on,2957.29,428.0,Omron_USB_1,2020-08-14 05:30:06.555,27.25,73.02,106,1005.377,43.66,265,1623,Inkbird_IBSTH1_1,2020-08-14 05:30:09.387,27.92,68.94,Inkbird_IBSTH1_2,2020-08-14 05:30:12.162,31.49,62.93,Omron_BAG_1,2020-08-14 05:30:17.203,32.14,62.77,32.0,0.02,1006.5,39.22,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:30:18.825,26.53,75.26,SwitchBot_Thermo_1,2020-08-14 05:30:23.865,31.7,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:30:26.573,2020-08-13T20:30:15.000Z,1,Project HomeIoT
5f35a41a90393b85364a6c71,2020-08-14 05:35:00.000,2020-08-14 05:35:04.370,Nature_Remo_1,2020-08-14 05:35:06.617,28.2,64.0,143.0,2020-08-13T20:34:01Z,1.0,28.0,cool,1,auto,power-on,2957.32,456.0,Omron_USB_1,2020-08-14 05:35:07.443,27.45,74.21,104,1005.468,57.8,244,1598,Inkbird_IBSTH1_1,2020-08-14 05:35:10.129,28.07,69.8,Inkbird_IBSTH1_2,2020-08-14 05:35:12.960,31.47,62.75,Omron_BAG_1,2020-08-14 05:35:18.000,32.06,62.93,48.0,0.02,1006.6,39.22,2.96,Inkbird_IBSTH1mini_1,2020-08-14 05:35:25.717,26.62,76.67,SwitchBot_Thermo_1,2020-08-14 05:35:35.787,31.7,65.0,100.0,Sony_MeshHuman_1,2020-08-14 05:35:38.204,2020-08-13T20:34:15.000Z,1,Project HomeIoT
:
アクセス権限の付与(1. コンソール操作用)
Redshift Spectrumを使用するためには、適切なアクセス権限をIAMで作成して付与する必要があります。
注意点として、Redshift Spectrumでは以下の2種類の権限を別個に作成する必要があります
- コンソール操作用
- Redshiftクラスタへのアタッチ用
本節では「1. Redshift Spcetrumの操作用」について解説するので、「2. Redshiftクラスタへのアタッチ用」は後の節を参照してください
IAMポリシーの作成
コンソールには、以下2種類のポリシーを付与します
A. Redshift自体の操作権限: 既存のAmazonRedshiftFullAccessポリシーを使用
B. Redshiftクラスターに「2. Redshiftクラスタへのアタッチ用」ロールをアタッチする権限
このうちBに相当する権限はデフォルトのポリシー(AWS管理ポリシー)には存在しないので、こちらと同様の手順でPassRoleToRedshiftポリシーとして自作します
まずは必要なデータソース(S3およびGlue)へのアクセス権限を持ったIAMポリシーを作成します
管理者ユーザーでログインして、コンソールからIAM画面に入り、
左側のタブから「ポリシー」→「ポリシーの作成」をクリックします

「JSON」タブをクリックし、JSONでの編集モードに入ります

以下のようなポリシーを記述します
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowPassRoleOnlyRedshift",
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:aws:iam::アカウントIDの12桁数字:role/*",
"Condition": {
"StringEquals": {
"iam:PassedToService": "redshift.amazonaws.com"
}
}
},
{
"Sid": "AllowListRoles",
"Effect": "Allow",
"Action": "iam:ListRoles",
"Resource": "*"
}
]
}
名前と説明を記載し、「ポリシーの作成」をクリックすれば作成完了です。
IAMユーザーの作成
上記ポリシーを付与するためのIAMユーザを作成します。
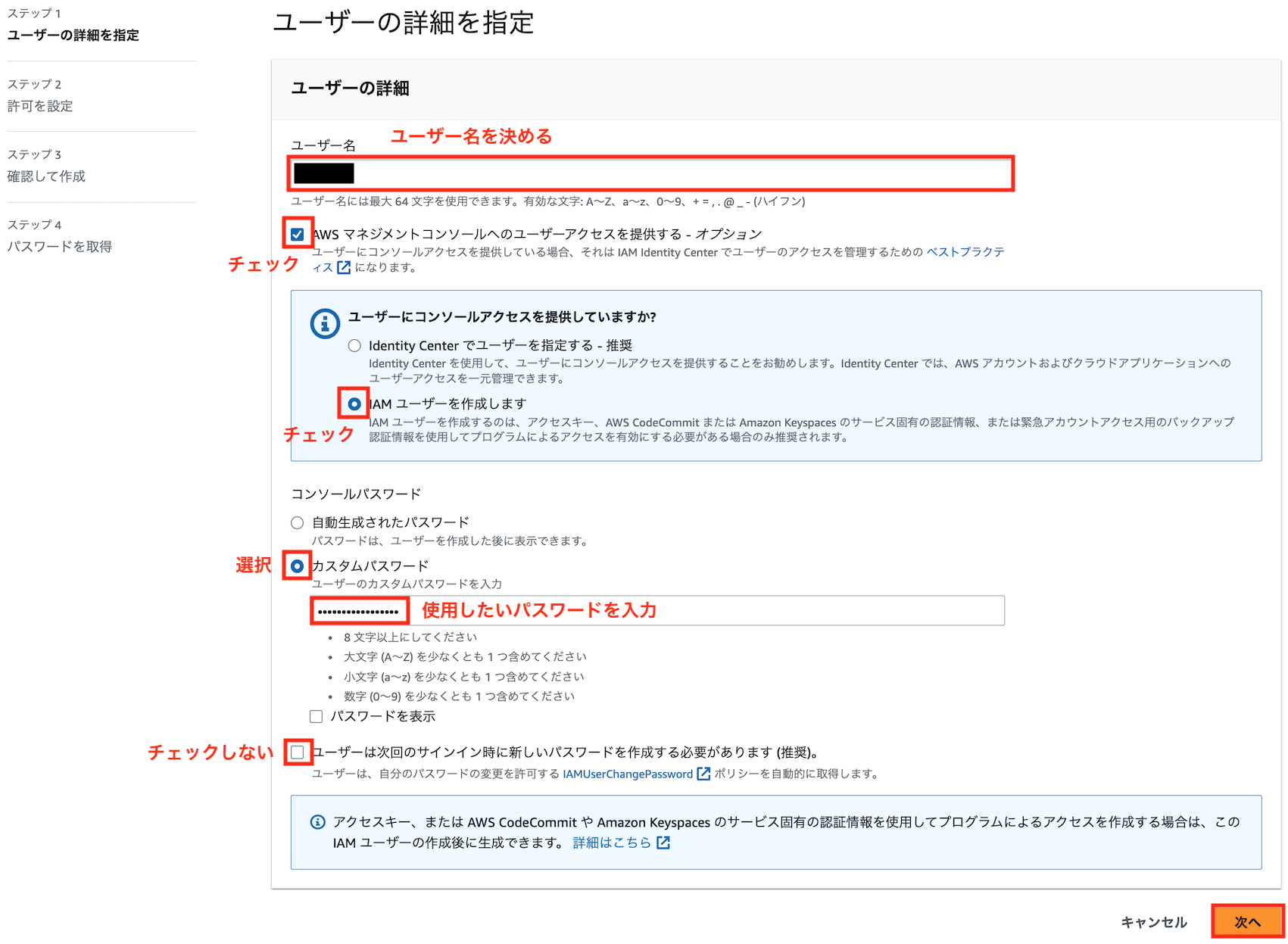
管理者ユーザーでログインして、コンソールからIAM → ユーザーと進み、「ユーザを追加」をクリックします

好きなユーザ名とパスワードを入力し、以下のようにユーザーを作成します
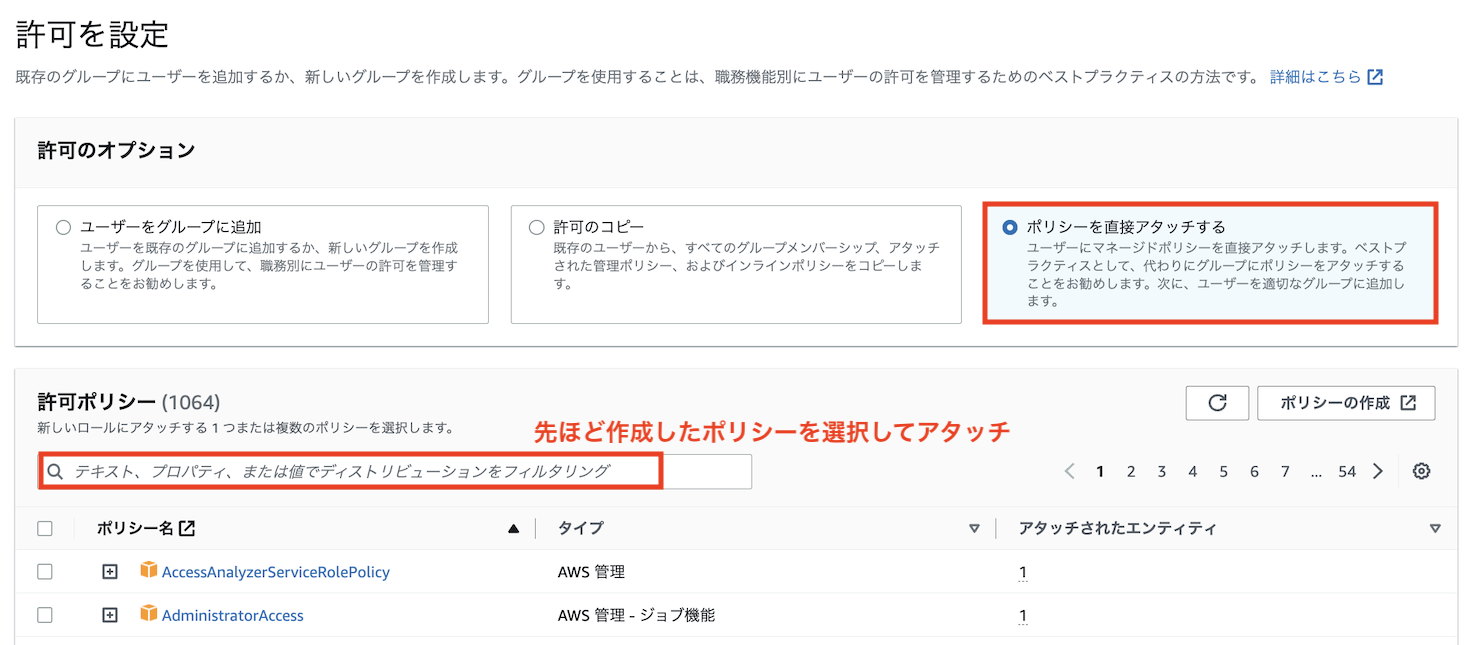
先ほど作成したPassRoleToRedshiftポリシーおよび既存のAmazonRedshiftFullAccessポリシーをアタッチします
(後述のPython SDKからのアクセスを使用する場合は、EC2やVPCの操作も必要となるのでAmazonEC2FullAccessポリシーもアタッチしてください)
このユーザーでログインすることで、コンソールからRedshift Spectrumの設定に必要な操作が可能となります。
(大人数で運用する場合はユーザーに直接ポリシーをアタッチするよりもグループを使用するのが望ましいので、こちらをご参照ください)
アクセス権限の付与(2. Redshiftクラスタへのアタッチ用)
IAMポリシーの作成
まずは必要なデータソース(S3およびGlue)へのアクセス権限を持ったIAMポリシーを作成します
管理者ユーザーでログインして、コンソールからIAM画面に入り、
左側のタブから「ポリシー」→「ポリシーの作成」をクリックします
「JSON」タブをクリックし、JSONでの編集モードに入ります
以下のようなポリシーを記述します
(例えば、RedshiftSpectrumPolicyというポリシー名を付けます。"Resource"の部分を"*"から対象のバケットのみに絞るとセキュリティ強度がさらに強まりますが、利便性とのバランスで判断してください)
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListMultipartUploadParts",
"s3:ListBucket",
"s3:ListBucketMultipartUploads"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"glue:CreateDatabase",
"glue:DeleteDatabase",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:UpdateDatabase",
"glue:CreateTable",
"glue:DeleteTable",
"glue:BatchDeleteTable",
"glue:UpdateTable",
"glue:GetTable",
"glue:GetTables",
"glue:BatchCreatePartition",
"glue:CreatePartition",
"glue:DeletePartition",
"glue:BatchDeletePartition",
"glue:UpdatePartition",
"glue:GetPartition",
"glue:GetPartitions",
"glue:BatchGetPartition"
],
"Resource": [
"*"
]
}
]
}
名前と説明を記載し、「ポリシーの作成」をクリックすれば作成完了です。
ロールの作成
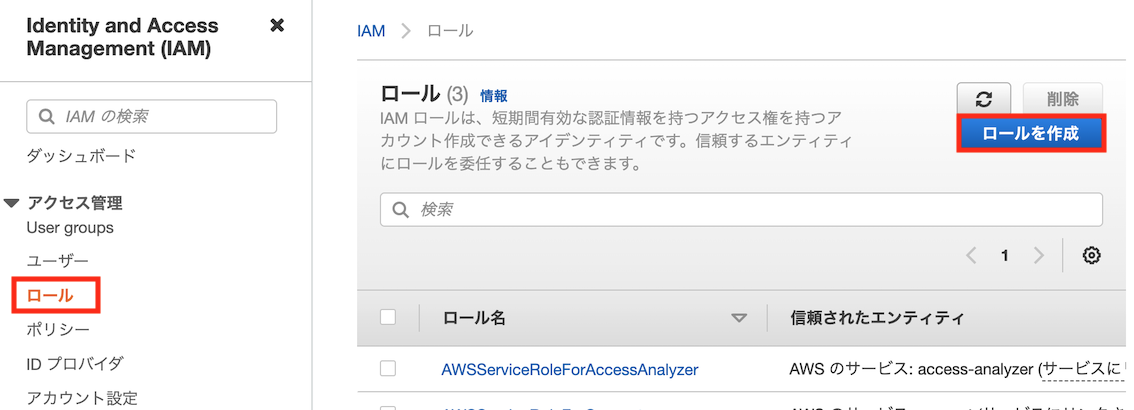
Redshift Spectrum用のロール(後ほどRedshiftクラスタにアタッチ)を作成します。
IAMの左側のタブから「ロール」 → 「ロールを作成」をクリックします
- 信頼されたエンティティタイプ: AWSのサービス
- ユースケース: Redshift → Redshift - Customizable
を選択します。
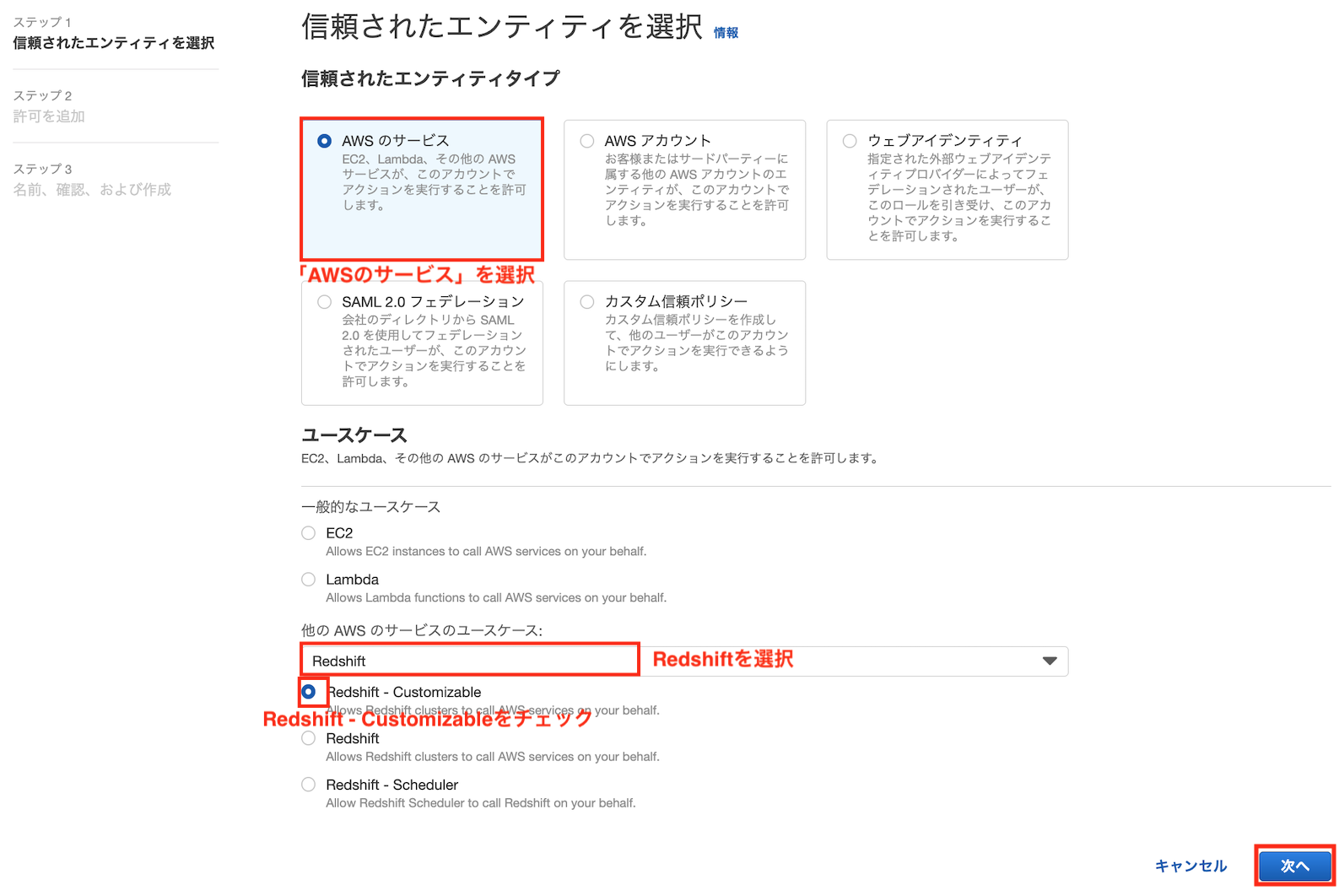
先ほど作成したRedshiftSpectrumPolicyをチェックして「次へ」を押します

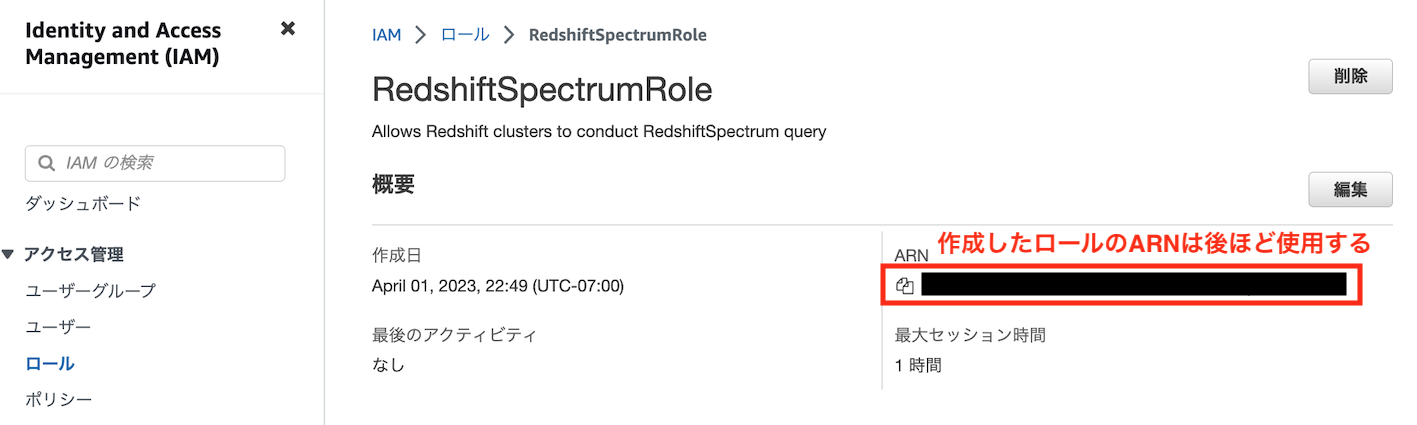
ロール名と説明を記載し、「ロールを作成」をクリックするとロールの作成が完了します

なお、以下の作成したロールのARNは後ほど使用するので、どこから閲覧できるのかを覚えておいてください
Redshift Spectrumの使用法
Redshift Spectrumは、コンソール、およびDB操作用のライブラリ(Pythonの場合Psycopg2やredshift_connector)を利用してS3内のデータをクエリする事ができます。
本記事では、このうち使用頻度が高いと思われるコンソール、Pythonライブラリ(redshift_connector)による操作方法を紹介します。
具体的には以下の手順でクエリを実行します
ステップ1: Amazon Redshiftクラスターの作成
ステップ2: IAMロールをクラスターと関連付ける
ステップ3: 外部スキーマと外部テーブルを作成する
ステップ4: Amazon S3のデータにクエリを実行する
コンソールからの使用法
コンソールからRedshift Spectrumを使用するためには、まず以下リンクからRedshiftコンソールを開きます(AWSコンソールから"Redshift"と検索して移動してもOKです)
ステップ1: Amazon Redshiftクラスターの作成
Redshift Spectrumを使用するためには、まずクエリの実行基盤(EC2のようなコンピューティングを行う計算資源)となる「Redshiftクラスタ」を作成する必要があります。
左側ナビゲーションペインの「クラスター」タブ→「クラスターを作成」をクリックします
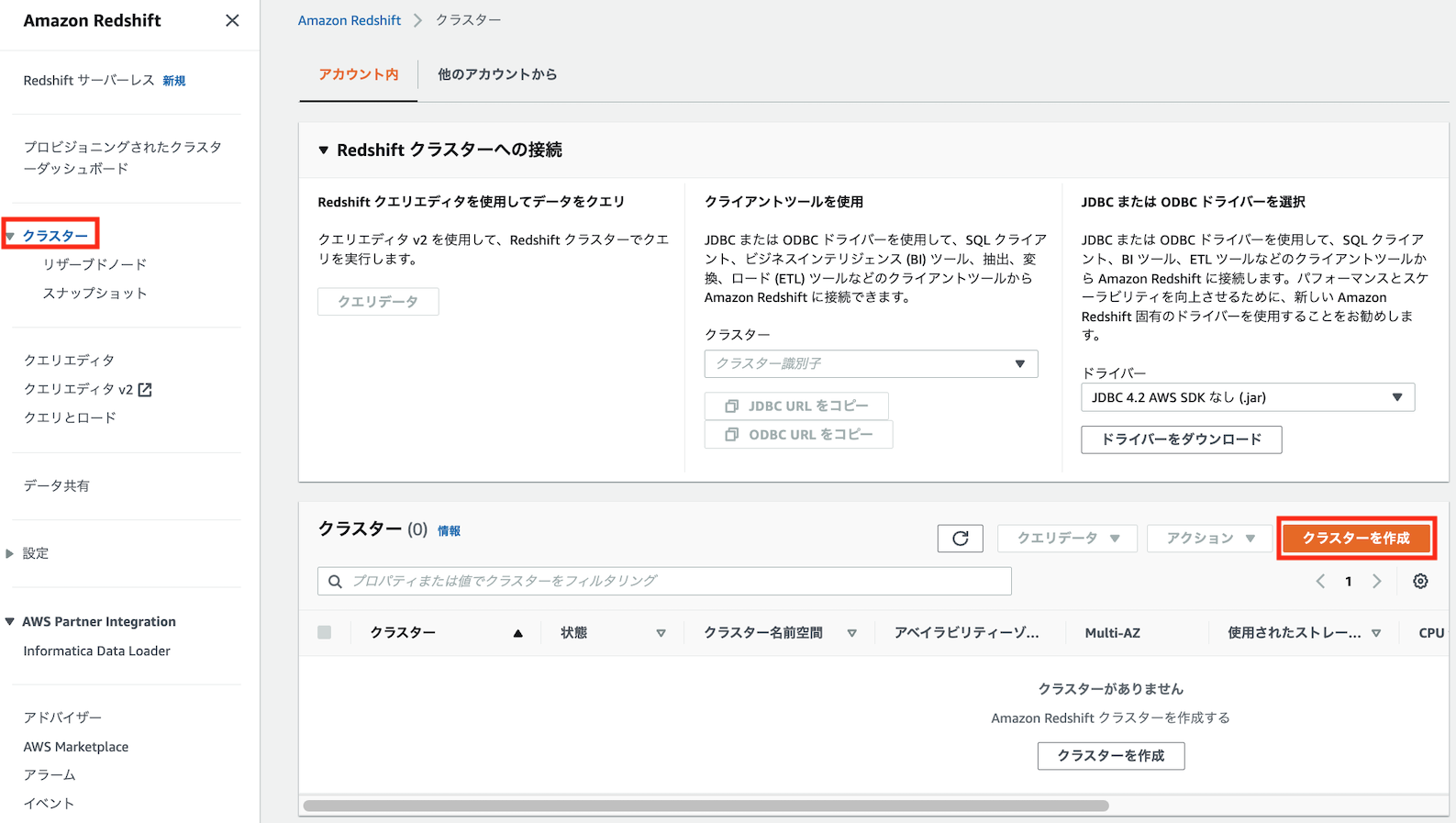
以下のようにクラスターの設定を入力し、「クラスターを作成」をクリックします


以下のノード料金を見ると分かりますが、最安のdc2.largeの1ノードでも3万円/月以上の維持費が掛かるので、クラスターを作ったまま放置しないようご注意ください

※Redshiftクラスターのネットワーク設定
VPC外にあるAthenaはIAMの権限でアクセス制御を行っていましたが、RedshiftクラスターはVPCの中に設置されるため、適切なネットワーク設定をしなければアクセスできません。
特に後述のPython等のスクリプトからの操作時は、スクリプトが動いているPCまたはAWS内のリソース(EC2やLambda等)からRedshiftクラスタにアクセスできるよう、VPCを適切に設定する必要があります。
VPC設定の詳細は以下の記事を参照下さい
クラスター作成時にVPC設定を変更するには、以下のように「追加設定」の「デフォルトを使用」をOFFにし、「ネットワークとセキュリティ」をクリックします

また、ここでグレーアウトされていて選択できないVPCも存在しますが、これはVPCにクラスターサブネットグルプが紐付けられていない事が原因です。以下を参考にサブネットグループを作成してください
ステップ2: IAMロールをクラスターと関連付ける
アクセス権限の付与で作成したIAMロールをクラスターに付与します。
作成したクラスターをチェックしたのち、「アクション」→「IAMロールの管理」とクリックします

先ほど「2. Redshiftクラスタへのアタッチ用」として作成したRedshiftSpectrumRoleロールを選択し、「IAMロールを関連付ける」をクリックしてロールをアタッチしたのち、「変更を保存」をクリックします

ステップ3: 外部スキーマと外部テーブルの作成
RedshiftとS3を紐づけるための、外部スキーマと外部テーブルを作成します。
デフォルトデータベース名の確認
まずデフォルトのデータベース名を確認するため、作成したクラスターを以下のように確認します

以下の「データベース名」に記載されている名称をメモします

基本的にはdevとなっているはずです
データベースの作成
次にRedshift Spectrumに使用するデータベースを作成します。
「クエリエディタ」を以下のように開き、「データベースに接続」をクリックします
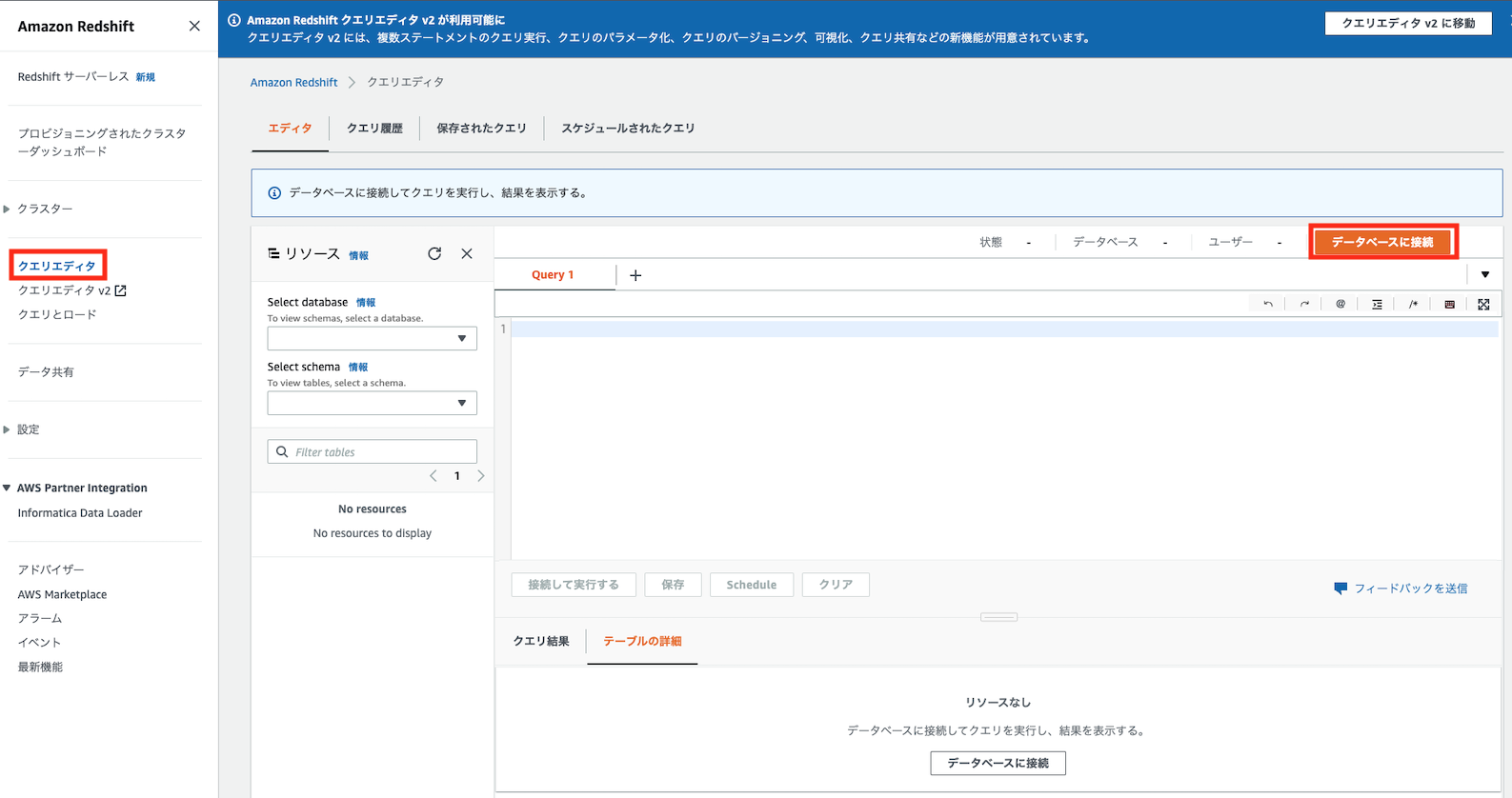
以下のようにデフォルトデータベース名を管理者ユーザー名を入力し、「接続」をクリックします

クエリエディタに戻り、以下のようにデフォルトデータベースを選択します

クエリエディタの以下の赤枠部分に、
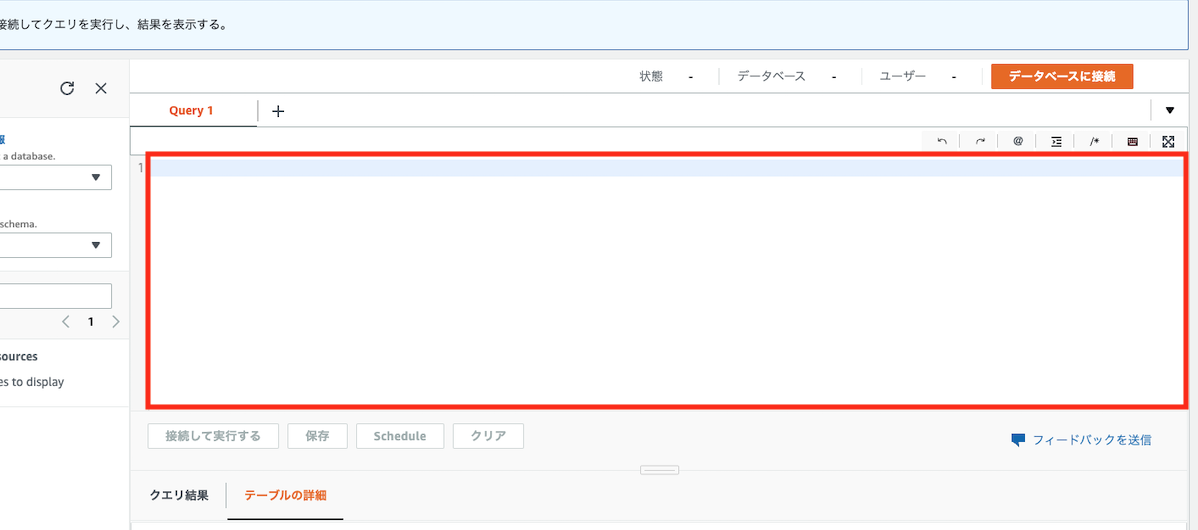
以下のようなクエリ文を記載して、「実行する」をクリックします
create database 好きなデータベース名
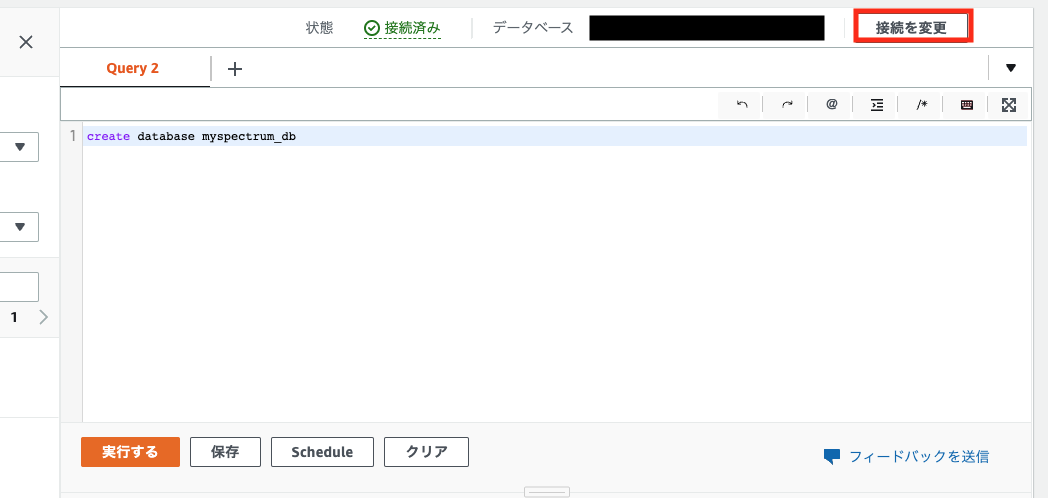
以下の「接続を変更」をクリックし、作成したデータベース名と管理者ユーザー名を入力して「接続」をクリックします
外部スキーマの作成
クエリエディタで以下のクエリ文を実行し、外部スキーマを作成します。
create external schema myspectrum_schema
from data catalog
database '作成したデータベース名'
iam_role '先ほど控えたRedshiftSpectrumRoleロールのARN'
create external database if not exists;
※上記のmyspectrum_schemaがスキーマ名に相当するので、適宜変更してください。
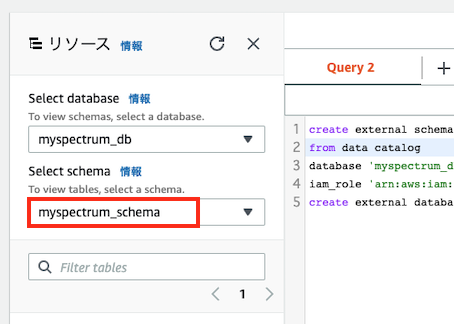
以下のように「リソース」の「Select schema」で作成したスキーマを選択します
外部テーブルの作成
S3バケットとRedshift Spectrumを結び付けるための「テーブル」を作成します。
テーブルと結びつくのは基本的にS3バケット内のフォルダ(プレフィックス)となり、テーブルを作成すればフォルダ内のファイル全てに一括でクエリを実行する事ができます。
クエリエディタから以下のようなコマンドを実行することで、テーブルを作成できます。
create external table スキーマ名.テーブル名(
カラム名1 型名1,
カラム名2 型名2,
:
中略
:
)
row format delimited
fields terminated by 'フィールドの区切り文字'
lines terminated by 'レコードの改行文字'
stored as ファイル形式
location 's3://バケット名/プレフィックス/'
table properties (各種プロパティを記載);
指定できる型の種類やファイル形式、プロパティ等の詳細は、こちらの公式ドキュメントを参照ください。
例えば、先ほど紹介したサンプルバケットのper_monthフォルダをテーブルの作成対象とする場合、フィールドの区切り文字は','(カンマ)、レコードの改行文字は'\n'、プレフィックスはsensors/per_month/となるので、以下のようなコマンドでテーブルを作成できます。
(テーブル名は"sample_table1"とします。また必ずしもファイル内の全ての列名を指定する必要はなく、一部の列のみ指定する事もできるので、今回はno01の列のみ選択します)
create external table myspectrum_schema.sample_table1(
_id varchar(100),
Date_Master timestamp,
Date_ScanStart timestamp,
no01_DeviceName varchar(100),
no01_Date timestamp,
no01_Temperature real,
no01_Humidity real,
no01_Light real,
no01_Human_last varchar(100),
no01_HumanMotion real,
no01_TempSetting real,
no01_AirconMode varchar(100),
no01_AirVolume varchar(100),
no01_AirDirection varchar(100),
no01_AirconPower varchar(100),
no01_CumulativeEnergy real,
no01_Watt real
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
location 's3://バケット名/sensors/per_month/'
table properties ('skip.header.line.count'='1');
※よくある注意点
-
row format delimitedの部分は、直後にlines terminated byとlines terminated byを記述することで区切り文字を指定します。row format serdeとするとより複雑な指定も可能になるので、詳細は公式ドキュメントを参照ください - フィールドの区切り文字がタブの場合、
fields terminated by '\t'と指定します。 -
table properties ('skip.header.line.count'='1')は、1行目をヘッダ行として読み飛ばすことを表します。1行目がヘッダ行でない場合は削除してください - CSVやtxtファイルの場合
stored as textfileを、Parquetファイルの場合、stored as PARQUETを指定してください
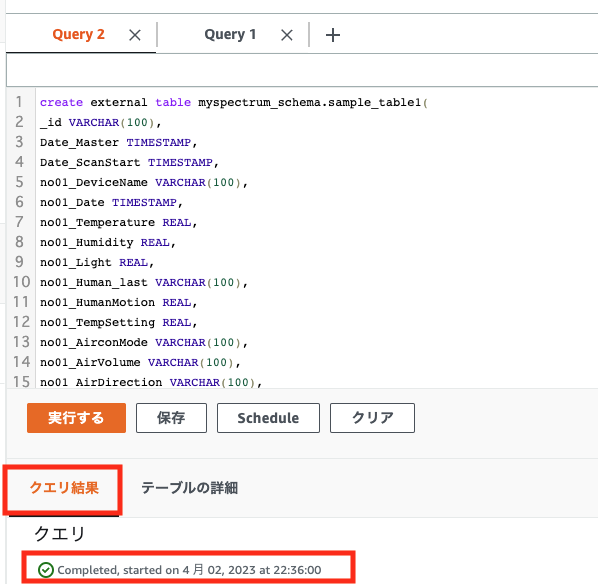
作成がうまくいくと、以下のように「クエリ結果」にCompletedと表示されます
上記でクエリを実行する準備は完了ですが、Redshiftの操作に管理者ユーザー(IAMのAdministratorユーザーではなくデータベースの管理者ユーザーです)を使用しており、セキュリティ的に強固とは言えない状況なので、適宜CREATE USERクエリでユーザーを作成し、GRANTで必要な権限を付与してください。
ステップ4: Amazon S3のデータにクエリを実行する
ここまでで前準備が完了し、ここから実際にクエリを実行してS3からデータを取得する事ができます。
プラス (+) 記号をクリックして新しいクエリタブを開き、クエリペインに好きなSQL文を打ちます。例えば全ての列を取得したい場合は、以下のようにアスタリスク(*)を使用します(データ数が多い場合、料金に注意してください)
select * from スキーマ名.テーブル名
実行例
select * from myspectrum_schema.sample_table1;
実行結果
_id,date_master,date_scanstart,no01_devicename,no01_date,no01_temperature,no01_humidity,no01_light,no01_human_last,no01_humanmotion,no01_tempsetting,no01_airconmode,no01_airvolume,no01_airdirection,no01_airconpower,no01_cumulativeenergy,no01_watt
61cf1b102f31e88b3f5b52ec,2022-01-01 00:00:00,2022-01-01 00:00:03.903,Nature_Remo_1,2022-01-01 00:00:05.675,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.91015625,160
61cf1c3d62228317200da710,2022-01-01 00:05:00,2022-01-01 00:05:03.759,Nature_Remo_1,2022-01-01 00:05:05.55,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.919921875,164
61cf1d695b33f11da52488c9,2022-01-01 00:10:00,2022-01-01 00:10:04.195,Nature_Remo_1,2022-01-01 00:10:06.021,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.93017578125,104
61cf1e98ba1ed7ee918b34df,2022-01-01 00:15:00,2022-01-01 00:15:04.267,Nature_Remo_1,2022-01-01 00:15:06.084,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.93994140625,104
61cf1fbd0e1be80d78b28300,2022-01-01 00:20:00,2022-01-01 00:20:03.691,Nature_Remo_1,2022-01-01 00:20:05.483,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.9501953125,108
61cf20f5d8b9f629c41a30db,2022-01-01 00:25:00,2022-01-01 00:25:04.099,Nature_Remo_1,2022-01-01 00:25:05.908,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.9599609375,112
61cf2216d5a7b17f7c09f1d5,2022-01-01 00:30:00,2022-01-01 00:30:04.163,Nature_Remo_1,2022-01-01 00:30:05.952,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.97021484375,108
61cf23491bd95b0313e124ff,2022-01-01 00:35:00,2022-01-01 00:35:03.699,Nature_Remo_1,2022-01-01 00:35:05.448,11.600000381469727,29,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.97998046875,104
61cf247136ac51ab9d9e630e,2022-01-01 00:40:00,2022-01-01 00:40:03.719,Nature_Remo_1,2022-01-01 00:40:05.516,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5962.990234375,108
61cf259db6405e0b8211a79d,2022-01-01 00:45:00,2022-01-01 00:45:03.907,Nature_Remo_1,2022-01-01 00:45:05.682,14,32,8,2021-12-28T00:19:41Z,0,22,warm,auto,auto,power-off,5963,112
:
Redshift Spectrumのクエリの文法は基本的にRedshiftに準拠するので、詳細は以下のSQLコマンドを参照ください
ここではいくつかの例を紹介します。
列に対してフィルタを指定したい場合は、以下のようにWHERE文を使用できます
select Date_Master, no01_Temperature, no01_AirconPower from myspectrum_schema.sample_table1
where no01_Temperature > 28.5 and no01_AirconPower = 'power-on'
date_master,no01_temperature,no01_airconpower
2020-08-14 13:35:00,30,power-on
2020-08-14 13:40:00,30,power-on
2020-08-14 13:45:00,30,power-on
2020-08-14 13:50:00,30,power-on
2020-08-14 13:55:00,29.400001525878906,power-on
:
ORDER BYやGROUP BYによる集計も可能です
select Date_Master, no01_Temperature, no01_AirconPower from myspectrum_schema.sample_table1
where no01_Temperature > 28.5 AND no01_AirconPower = 'power-on'
order by Date_Master
date_master,no01_temperature,no01_airconpower
2020-08-14 13:35:00,30,power-on
2020-08-14 13:40:00,30,power-on
2020-08-14 13:45:00,30,power-on
2020-08-14 13:50:00,30,power-on
2020-08-14 13:55:00,29.400001525878906,power-on
select no01_AirconPower, avg(no01_Temperature) from myspectrum_schema.sample_table1
group by no01_AirconPower
no01_airconpower,avg
,
power-on_maybe,26.0373967091073
power-off,22.986347120465346
power-on,24.321050247798734
Python SDKからの使用法
Redshiftは代表的なRDBMSであるPostgreSQLがベースとなったDBのため、多くのPythonのDB操作用パッケージ、例えばPsycopg2やSQLAlchemy等で操作する事が可能です。
よってRedshiftの基盤を用いるRedshift Spectrumも。多くのDB操作用パッケージからの接続が可能です。
本記事では、以下の公式ドキュメントで紹介されているAmazon Redshift Pythonコネクタ(redshift_connector)を通じてRedshift Spectrumを操作する方法を紹介します
PythonからRedshift Spectrumを操作するためには、事前にコンソールから「ステップ1. Amazon Redshiftクラスターの作成」「ステップ2: IAMロールをクラスターと関連付ける」「ステップ3: 外部スキーマと外部テーブルを作成する」を実行しておく必要があります。
PythonによるRedshift接続のための前準備
上記に加えて、以下の前準備も必要となります。
- Amazon Redshift Pythonコネクタのインストール
- Redshiftクラスタへのネットワーク疎通確保
- ホスト情報とポート番号の確認
それぞれ解説します
Amazon Redshift Pythonコネクタのインストール
Amazon Redshift Pythonコネクタ(redshift_connector)をインストールします。
pipを使用する場合、以下コマンドでインストールできます
pip install redshift_connector
condaを使用する場合、以下コマンドでインストールできます
conda install -c conda-forge redshift_connector
Redshiftクラスタへのネットワーク疎通確保
Redshiftクラスターのネットワーク設定で前述したように、RedshiftクラスタはVPCの中に設置されるため、そのままでは外部から接続できません。
Pythonスクリプトが動いているPCまたはAWS内のリソース(EC2やLambda等)からアクセスできるよう、クラスター作成時のVPCの設定を変更する必要があります。
今回は、Redshiftクラスターと同じVPC内にEC2インスタンスを作成し、そこでPythonスクリプトを動作させる事とします。
最低限必要なアクセス許可として、以下のようにRedshiftクラスタの所属するセキュリティグループに、EC2インスタンスの所属するセキュリティグループからのRedshift用ポートへの通信許可を追加します。
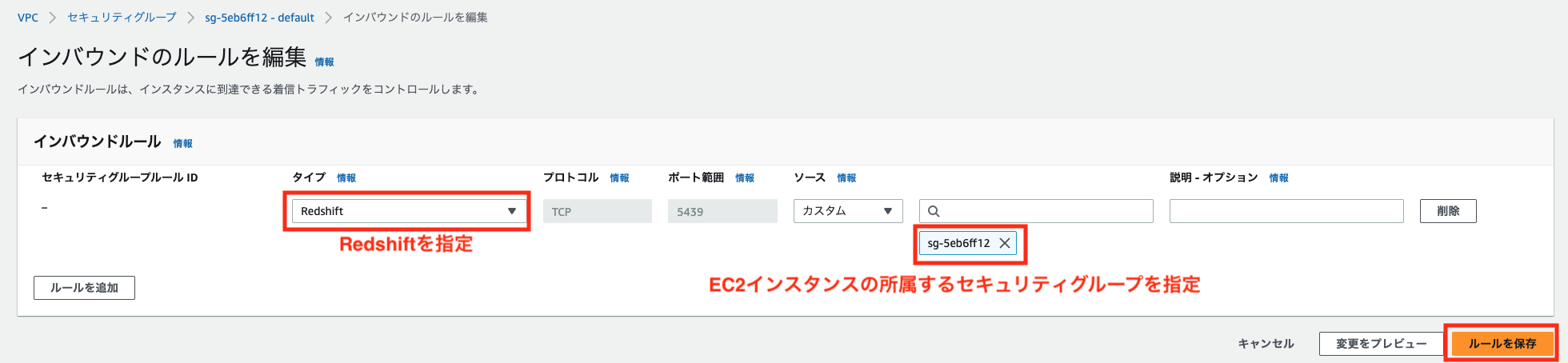
その他のVPC設定は、以下の記事をご参照ください。
ホスト情報とポート番号の確認
接続に必要なホスト情報を以下のように確認します
以下の「エンドポイント」に記載されている名称をメモします。

例えばexamplecluster.abc123xyz789.us-west-1.redshift.amazonaws.com:5439/devと記載されていた場合、
-
examplecluster.abc123xyz789.us-west-1.redshift.amazonaws.comの部分がホスト -
5439の部分がポート番号
を表します。
(devの部分はデフォルトのデータベース名を表しますが、これは使用せずに実際に接続するデータベース名を指定します)
なお、"JDBC URL"、"ODBC URL"に記載されている情報も、接続するツールに応じて使用する事があります。
スクリプト例
ここまででPythonからRedshift Spectrumに接続する準備が整いました。
ここから以下の手順でクエリを実行し、Pythonスクリプト内にデータを取得します。
- Redshiftクラスターに接続
-
conn.cursor()メソッドでcursorオブジェクトを作成 -
cursor.execute()メソッドでクエリの実行 -
cursor.fetch_dataframe()メソッドでPandas DataFrameに実行結果を変換
下の例では、コンソールでの実行例と同じクエリを実行してPandasのデータフレームに変換しています。
import redshift_connector
HOST = 'ホスト名' # 先ほど確認したホスト名
PORT = ポート番号 # 先ほど確認したポート番号(int型)
DATABASE = 'データベース名' # コンソールで作成したデータベース名
USER = '使用するデータベースのユーザー名'
PASSWOR = '使用するユーザーのパスワード'
SCHEMA_NAME = '外部スキーマ名' # コンソールで作成した外部スキーマ名
TABLE_NAME = '外部テーブル名' # コンソールで作成した外部テーブル名
COLNAMES = ['Date_Master', 'no01_Temperature', 'no01_AirconPower'] # クエリ取得対象の列名
# SQLクエリを記述
QUERY = f"select {','.join(COLNAMES)} from {SCHEMA_NAME}.{TABLE_NAME} where no01_Temperature > 28.5 and no01_AirconPower = 'power-on'"
# 1. Redshiftクラスターに接続
conn = redshift_connector.connect(
host=HOST,
port=PORT,
database=DATABASE,
user=USER,
password=PASSWORD
)
# 2. cursorオブジェクトを作成
cursor = conn.cursor()
# 3. クエリの実行
cursor.execute(QUERY)
# 4. Pandas DataFrameに実行結果を変換
result = cursor.fetch_dataframe()
print(result)
date_master no01_temperature no01_airconpower
0 2020-08-14 13:35:00 30.000000 power-on
1 2020-08-14 13:40:00 30.000000 power-on
2 2020-08-14 13:45:00 30.000000 power-on
3 2020-08-14 13:50:00 30.000000 power-on
4 2020-08-14 13:55:00 29.400002 power-on
:
実行してみると分かりますが、クエリ結果の行数が多い(数千行以上)場合、Athenaより高速に動作するので、一定規模以上のS3へのクエリをPythonスクリプトから実行したい場合、Redshift Spectrumはおすすめです。
Redshift Spectrumの高速化
Redshift Spectrumの速度パフォーマンス向上には、以下の公式ベストプラクティスが参考になります
Redshift Spectrumの料金
Redshift Spectrumの料金は、以下の公式サイトに記載されています。
2023年4月現在、東京リージョンでは以下のような料金となっています。
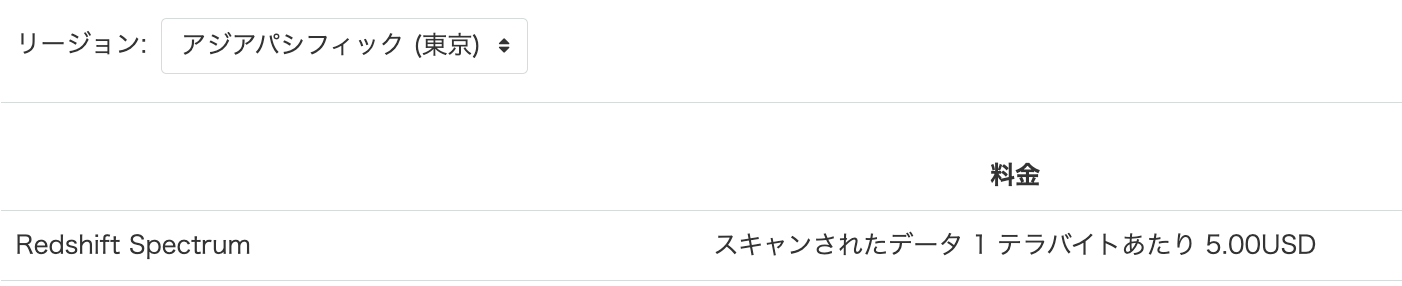
クエリ自体の実行料金はAthenaとほぼ同額ですが、前述のように高額のRedshiftクラスタ料金(連続起動した場合最低で3万円/月)が乗るため、継続利用する際はご注意下さい。
Redshift Spectrumのコスト削減施策
Redshift Spectrumのコストを削減するには、以下の公式ベストプラクティスが参考になります
基本的にはAthenaと同様に、
1. データの圧縮
2. 分割(パーティション分割)
3. 列形式への変換
を行うと、この「スキャンされたデータ」のサイズを減らすことができます。
またベストプラクティスに記載されているように、
4. 同時実行スケーリング機能を使用して動的にクラスタ数を制御する
5. Redshift Spectrumのコストコントロール機能で使用量をモニタリングおよび制御する
もコストコントロールにおいて有効です。
それぞれ解説します。
コスト削減施策1: データの圧縮
S3に保存するデータを圧縮形式(GZIP等)にすると、スキャン対象のデータサイズを減らす事ができ、コスト削減に繋がります。
コスト削減施策2: パーティション分割
データを Apache Hive スタイルでパーティション分割することで、スキャン対象のデータサイズを減らす事ができ、パフォーマンス向上&コスト削減に繋がります。
パーティションの分割単位として、一般的には年、月、日、時間等の時系列がよく用いられます。
こちらの記事のAthenaではHiveフォーマットを考慮したファイル構成としていればパーティションの分割を半自動化できますが、Redshift Spectrumにはこのような半自動化機能は見当たらず、基本的には手動でパーティションを追加する必要がありそうです。
このケースの注意点として、パーティションの分割単位を表すフォルダが存在する必要があります。すなわち、S3へのデータの蓄積段階で月ごとや日ごとにフォルダを分けておく必要があります。
例えば先ほどのテーブル作成において、年フォルダごとにパーティションを分割したい場合、
create external table myspectrum_schema.sample_table1(
_id varchar(100),
Date_Master timestamp,
Date_ScanStart timestamp,
no01_DeviceName varchar(100),
no01_Date timestamp,
no01_Temperature real,
no01_Humidity real,
no01_Light real,
no01_Human_last varchar(100),
no01_HumanMotion real,
no01_TempSetting real,
no01_AirconMode varchar(100),
no01_AirVolume varchar(100),
no01_AirDirection varchar(100),
no01_AirconPower varchar(100),
no01_CumulativeEnergy real,
no01_Watt real
)
partitioned by (partition_year integer(10))
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
location 's3://バケット名/sensors/per_month/'
table properties ('skip.header.line.count'='1');
というように、partitioned by (パーティション列名 型名)で指定します(パーティション列名は好きな新規列名を指定します)
テーブルが作成されたら、パーティション追加のために以下のクエリも実行する必要があります
alter table myspectrum_schema.sample_table1 add partition(partition_year='2020')
location 's3://iot-backup-data/sensors/per_month/2020/'
partition(partition_year='2021')
location 's3://iot-backup-data/sensors/per_month/2021/'
partition(partition_year='2022')
location 's3://iot-backup-data/sensors/per_month/2022/'
上記クエリを全てのパーティションについて手動実行する必要があるので、日毎に分割する場合のように分割数が多いケースでは骨が折れます(先ほどのPython SDK等を使ってクエリの実行を自動化すると良いでしょう)
以下のように、パーティション列名でwhere文を実行することで、スキャン対象のデータサイズを削減する事ができます
select * from myspectrum_schema.sample_table1
where partition_year='2022'
パーティション分割の詳細は以下の公式ドキュメントを参照ください。
コスト削減施策3: データの列形式への変換
S3に保存するデータをCSVではなく列指向のParquet形式にすると、SELECT文で指定した列のみが「スキャンされたデータ」に、クエリの工夫次第で大幅にコストを削減する事ができます。
列指向形式のデータでコスト(および処理時間)を削減したい場合、
select * from 外部スキーマ名.外部テーブル名
のようにアスタリスクで全列を取得するのではなく、
select 列名1, 列名2 from 外部スキーマ名.外部テーブル名
のように列名を具体的に指定し、必要な列のみを取得するようにしてください
また、CSV等をParquet形式に変換する方法は以下の公式ドキュメントを参照ください。
コスト削減施策4: 同時実行スケーリング機能を使用して動的にクラスタ数を制御する
前述のように、Redshift Spectrumでは料金の多くを高額のクラスタ月額料金が占めます。よって起動するクラスタの数を必要最低限に保つことが、コスト削減に寄与します。
この要件を実現するため、クエリの実行数が多い時のみ一時的にクラスターを追加する、同時実行スケーリング機能(Concurrency Scaling)と呼ばれる機能が存在します。これにより普段は必要最低限のクラスターのみ起動しておき、必要な時のみ自動でクラスターを増やす事ができます。
同時実行スケーリングの詳細は以下の記事が分かりやすいです。
同時実行スケーリングは、以下のように「ワークロード管理」から設定する事ができます。


また同時実行スケーリングに使用制限を設け、使いすぎを防ぐこともできます。
スケーリングの使用制限は以下の手順で設定できます。

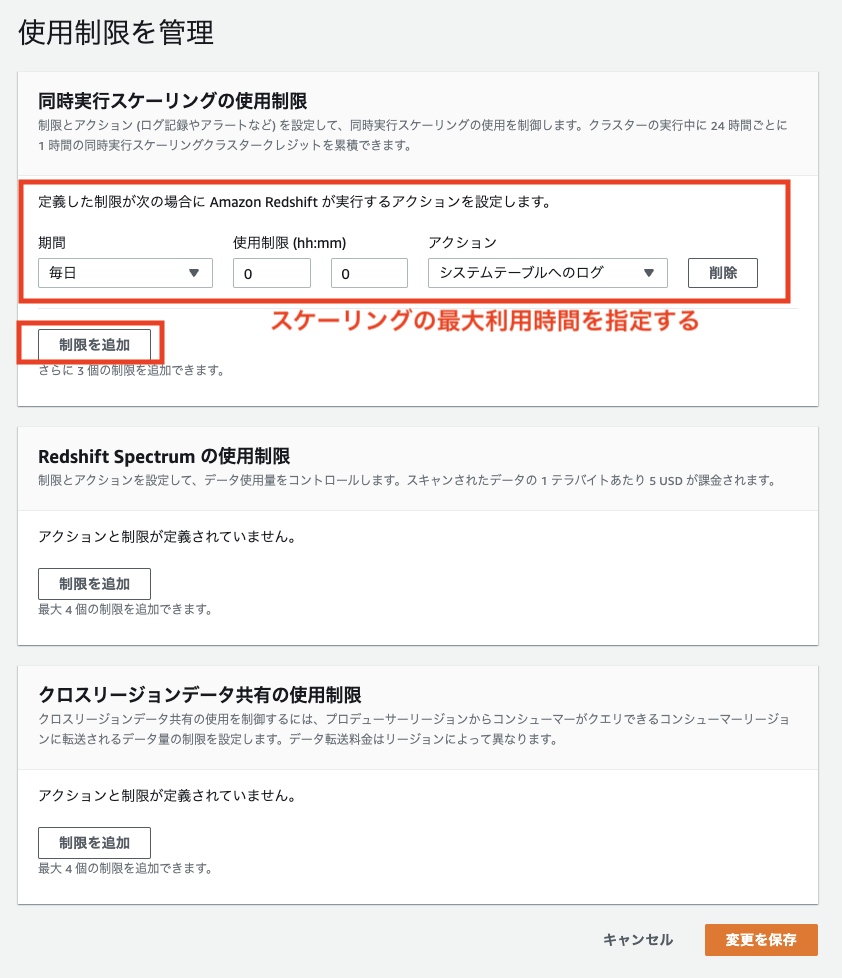
コスト削減施策5: Redshift Spectrumのコストコントロール機能で使用量をモニタリングおよび制御する
クエリの使用量が一定の容量に達したら、特定のアクション(SNSによるアラートの発報、ログの記録、機能の無効化)を実行する機能が存在します。
これにより、使いすぎに気づいたり防止したりする事ができます。
この機能は以下の「Redshift Spectrumの使用制限」から設定する事ができます。
