まずはじめに
この記事はDMM WEBCAMP アドベントカレンダー7日目の記事です。
今回は超入門編ということで、機械学習を全くやったことないけど始めてみたい方を対象に作成しました。
ざっくりと機械学習について分かって、基本的な単純パーセプトロンの実装までとりあえずやってみるというのが目的なので、機械学習等の説明についてはすごくざっくり書いています(1つ1つちゃんと書いたらめちゃくちゃ長くなります)。より詳しく知りたい方はぜひ調べてみてください。
また、今回はwindows10での環境構築を紹介しています。
Qiita初投稿で伝わりづらい部分や誤って認識している部分ががありましたら、コメントでご指摘いただけると幸いです。
Overview
機械学習について大まかな説明
Pythonのインストール
Minicondaのインストール
単純パーセプトロンの実装(ニューラルネットワーク)
機械学習について大まかな説明
機械学習とは
前から向かってくる人が散歩で何か動物を連れているとします。
その動物が何なのか(犬?猫?)、また、その犬種 or 猫種は何なのか、主に目で見て判断していると思います。
他には、「コツッ、コツッ、コツッ...」と音が聞こえてきたとします。
その聞こえている音は足音か、拍手の音か、それとも時計の針の音なのかを主に耳で判断していると思います。
このように人間は普段生活している中で、今までの経験をもとにあらゆるものを判断しています。
それを同じくコンピュータにもさせるために機械学習があります。
コンピュータに学習を繰り返しさせ、高い精度で判断できるようになることで、未知のデータに対して結果を予測できるようになります。
機械学習の種類
機械学習の方法は大きく、教師なしの機械学習、教師ありの機械学習の2つに分けられます。
教師なしの機械学習
教師ありの機械学習との最大の違いは正解データのない学習ということです。1000個データがあった場合、すべてを訓練データとして扱います。主にクラスタリングがなされ、共通する特徴を元にグループ分けをします。実装方法として有名なのはK-Means法です。今回教師なしの機械学習についてこれ以上触れないですが、興味のある方はぜひ調べてみてください。
教師ありの機械学習
教師なしの機械学習とは違い、正解データのある学習法です。同じようにデータが1000個あったとして、例えば700個を訓練データ、300個を正解データのように訓練データと正解データに分けて学習を繰り返します。
その中でも、今回はニューラルネットワーク、ディープラーニングについて触れていきます。
ニューラルネットワーク
人間の脳内の神経細胞のモデルを元にして考えられた学習方法です。神経細胞は複数連なっていて、隣接する神経細胞のシナプスから入力を受け取り、隣の神経細胞へと情報を伝えていきます。そういった具合でニューラルネットワークは、入力層と出力層に分けられ、入力層の重みの合計が一定以上の場合、出力層に値が入る仕組みです。今回はこのニューラルネットワークを実装するプログラムを作成します。
ディープラーニング
ざっくり言うとニューラルネットワークを何層にも組み込み、複雑化したのがディープラーニングです。昨年のDMM WEBCAMP アドベントカレンダーの「超初心者向け。ディープラーニングと機械学習の違い」という記事で、機械学習と比較してディープラーニングについて書かれていたので、こちらもぜび参考にしてください。
ざっくりとした説明が続きましたが、説明については以上です。なんとなくでも機械学習がどのようなものなのかを分かっていただけたでしょうか。では、さっそく機械学習のための環境構築をしていきます。
Pythonのインストール
なんと言っても、まずはPythonのインストールからです。
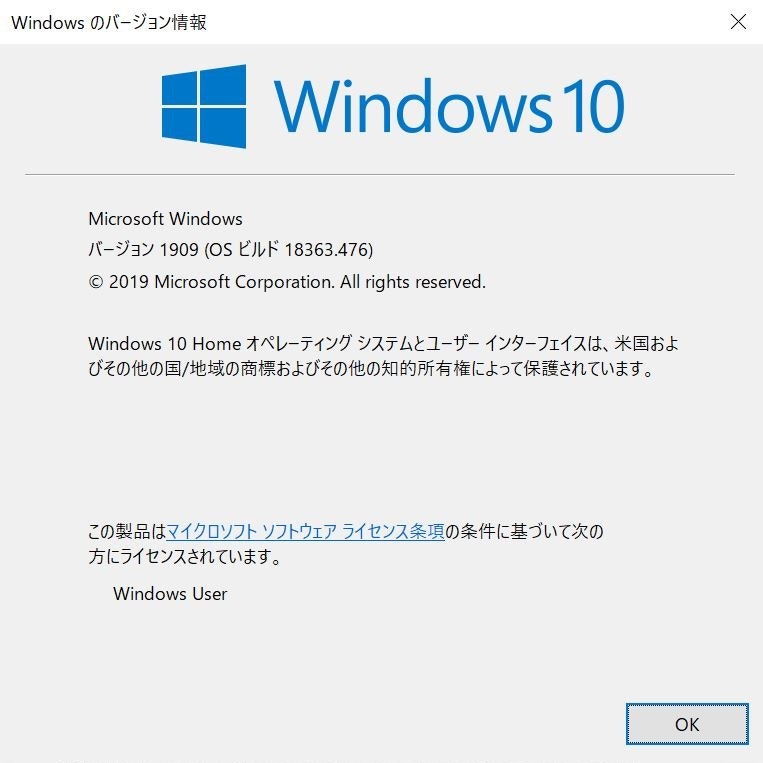
windowsのバージョン確認
と、その前に、windowsのバージョンが最新であることを確認してください。2019年12月時点での最新バージョンはバージョン1909です。最新バージョンでない場合は、最新バージョンに更新しておくことをお勧めします。
Pythonのインストール
https://www.python.orgにアクセスし、アクセスしたページの真ん中くらいにあるDownloadにあるLatest: Python (Vision)をクリックします。2019年12月時点でのPythonの最新版はPython 3.8.0です。
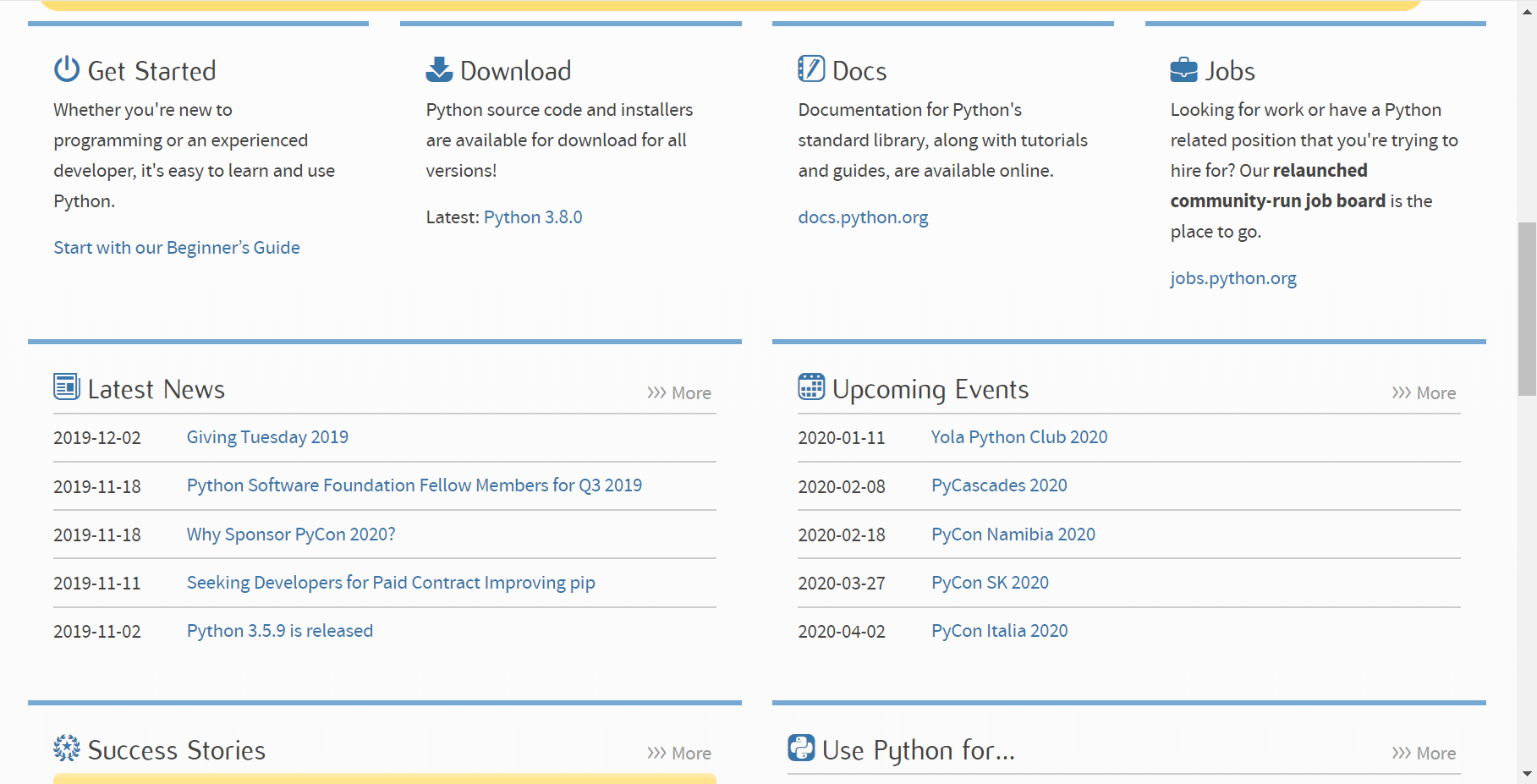
遷移先のページの下の方にある、FilesからWindows x86-64 executable installerをクリックし、Pythonインストーラをダウンロードします。
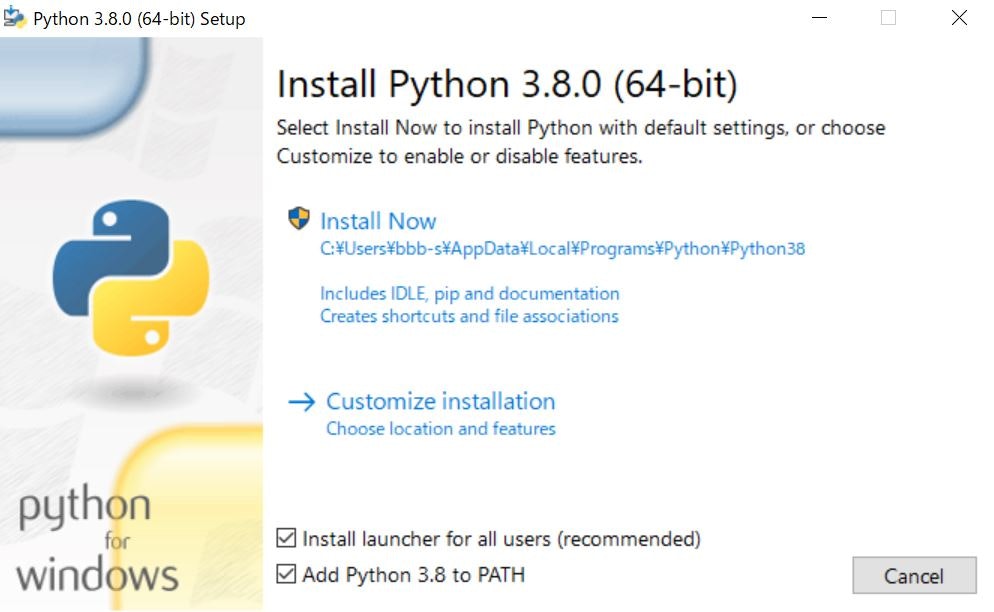
ダウンロードしたインストーラを起動し、add Python (Virsion) to PATHにチェックを入れてからインストールを始めてください。こうすることで、コマンドプロンプト上でPythonを起動させることができるようになります。必要ないと思えば、チェックを付けないままインストールを開始してください。
インストールの完了を知らせるこのページでdisable path length limitが表示されている場合、選択することでファイルパスの長さの制限を解除することができます。画像は、以前にPythonをインストールしたときに制限を解除しているので表示されていません。
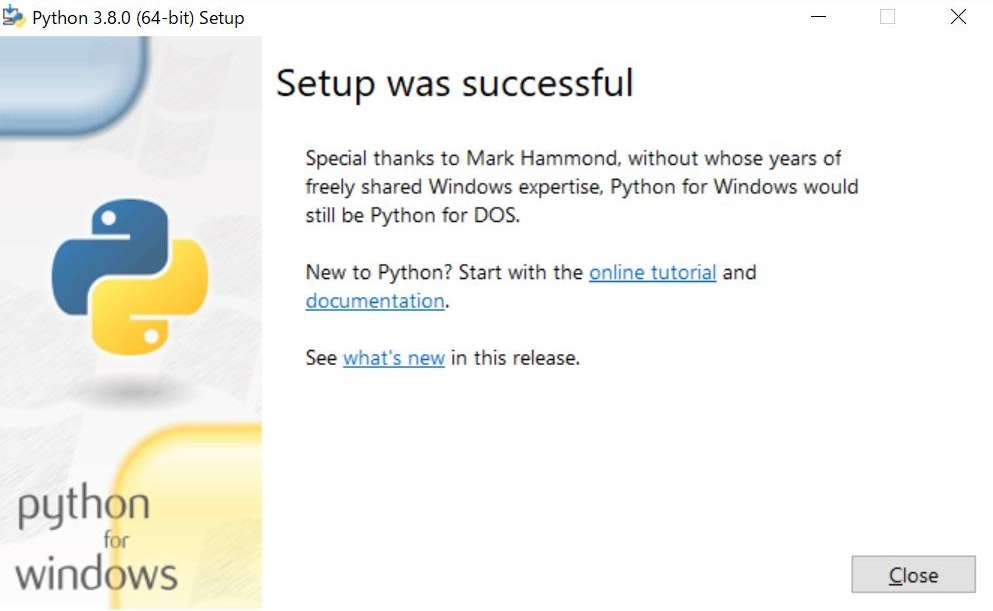
Pythonのインストールはこれで完了です。windowsのスタートメニューでIDLEと打ち込み、選択し起動したプログラムでコードを入力していくことができます。なので、Sublime Text 3や、Visual Stdio CodeのようなテキストエディタがなくてもPythonプログラムの作成は簡単にできます。
Pythonのプログラムを全く書いたことない方は、単純パーセプトロンを実装する前に少し触っておくといいと思います。CやJavaを普段書いている人なら少ない記述でやりたいことが表現できるので、簡単に理解できると思います。
Minicondaのインストール
Minicondaとは
MinicondaはCondaというオープンソースな管理システムから提供されているシステムの1つです。もう1つMinicondaと似たAnacondaというものがあるのですが、基本的に同じもので、Anacondaのインストールにはかなり大きなファイルが必要なので、そのうち最低限必要な機能だけにしたものがMinicondaです。Anaconda ⊆ Minicondaみたいなイメージです。
Python + Minicondaを使用することでデータ解析をより便利に進めることができます。
Minicondaのインストール
Miniconda — Conda documentationにアクセスしてMinicondaのインストーラをダウンロードします。Windows installerのうち、最新版のPythonのMiniconda3 Windows 64-bitを選択しダウンロードします。
今回はPython 3.8のMinicondaがないですが、Python 3.7のMinicondaで問題ありません。
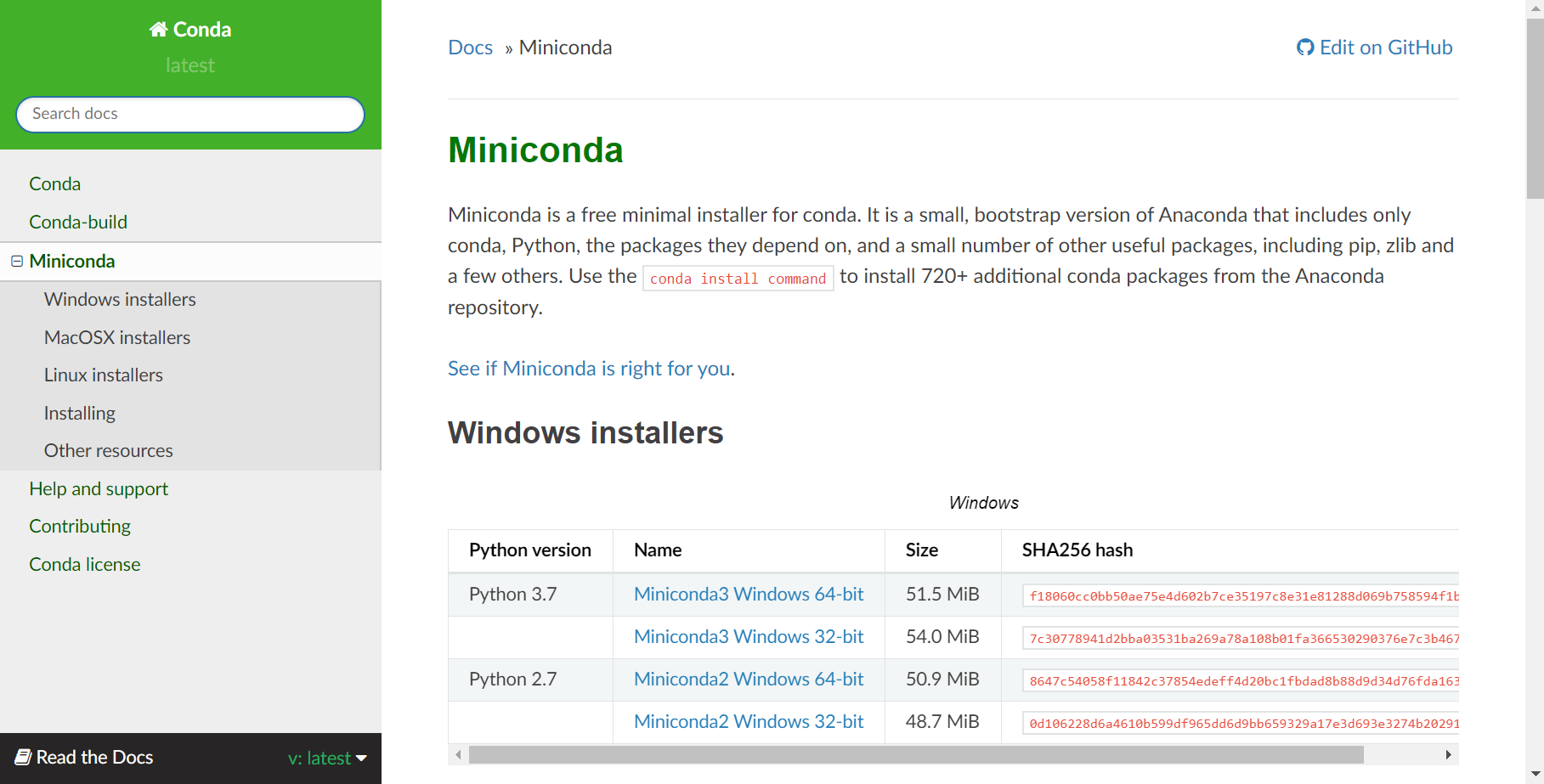
ダウンロードしたインストーラを起動し、 Next -> I Agree を選択した後、**Just Me(recommended)**のラジオボタンが選択されていることを確認してから次に進んでください。
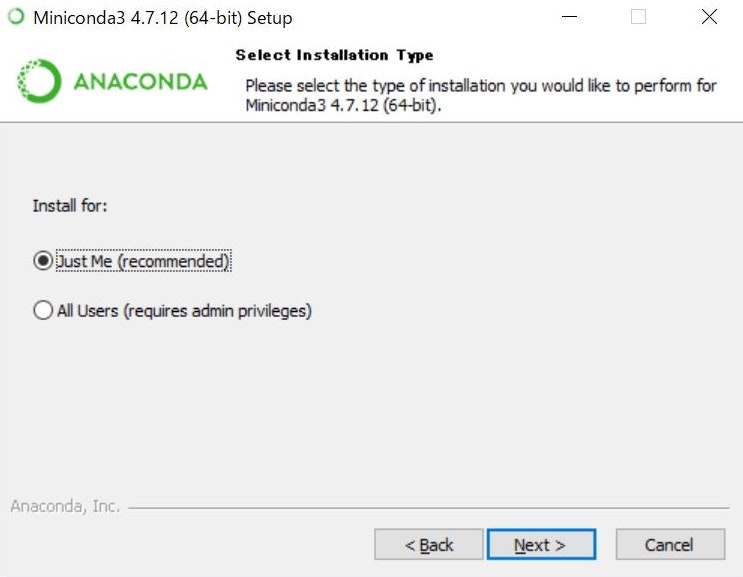
次の画面で表示されるDestination Folderは、変更すると面倒なことになりかねないので、特に変更せずに次の画面に進むことをお勧めします。
Advanced installation Optionsの画面ではデフォルトのPythonのバージョンを3.7に固定する、Register Aaconda as my default Python 3.7のチェックを外してからインストールを開始してください。
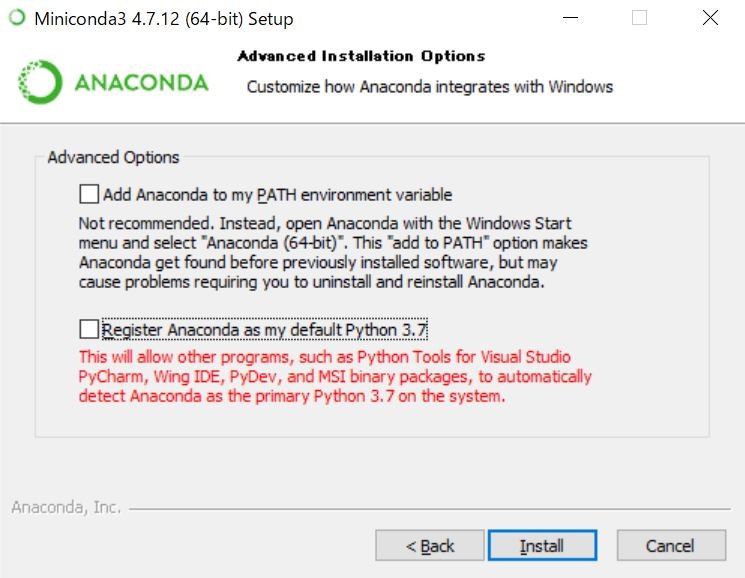
インストール完了後に出てくるこの画面では2つともチェックを外してからインストーラを終了させてください。
仮想環境の構築
windowsのスタートボタンからAnaconda Promptを起動させましょう。インストールしたのはMinicondaですが、先に述べたようにAnacondaのうち、最低限の機能だけを搭載したのがMinicondaなので表記はAnacondaとなっています。以下のコマンドを入力し、環境構築を進めます。
インストールしたcondaのアップデート
conda update conda -y
>conda update conda -y
Collecting package metadata (current_repodata.json): done
Solving environment: done
# All requested packages already installed.
このように出てれば問題ありません。
2019年12月時点ではPython 3.8に対応したMinicondaがないため、AnacondaPromptではPythonは3.7バージョンで対応しています。が、問題はほとんどないです。
conda listで確認することができます。
>conda list
# packages in environment at C:\Users\ユーザ名\Miniconda3:
#
# Name Version Build Channel
asn1crypto 1.2.0 py37_0
ca-certificates 2019.11.27 0
・・・
python 3.7.4 h5263a28_0
仮想環境の作成
環境名は自由ですが、今回はNN_sampleで進めていきます。Python3.8がインストールされてることでのバージョン違いで起きる不具合をなくすため、Pythonのバージョンを3.7.4に指定して仮想環境を作成します。
途中で出てくる**Proceed ([y]/n)?**は、yを入力し、Enterを押してください。
conda create -n NN_sample python=3.7.4
>conda create -n NN_sample python=3.7.4
Collecting package metadata (current_repodata.json): done
Solving environment: done
## Package Plan ##
environment location: C:\Users\ユーザ名\Miniconda3\envs\NN_sample
Proceed ([y]/n)? y
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate NN_sample
#
# To deactivate an active environment, use
#
# $ conda deactivate
仮想環境を起動させます。activate 環境名で起動させることができます。起動に成功すると、**(base)が(環境名)**に変わります。
(base) C:\Users\ユーザ名>activate NN_sample
(NN_sample) C:\Users\ユーザ名>
必要なライブラリの追加
Cでいう#include <~.h>、Javaでいうimport java.io.~ができるように仮想環境内に必要なライブラリを追加していきます。仮想環境を起動させた状態で進めてください。
今回インストールするのは以下の5つです。
- Jupyter Lab
- NumPy
- matplotlib
- TensorFlow
- Keras
jupyter labは、今回インストールする他と違って、ライブラリではなく、データを確認しながらコードをかけるWebツールのような、テキストエディタのようなものです。以前まではjupyter notebookが主流でしたが、最近は傾向的にもjupyter labを使っているイメージです。jupyter labをインストールするには以下のコマンドを入力します。
>conda install -c conda-forge jupyterlab
必要なライブラリをインストールしていきます。それぞれのライブラリの説明は割愛しますが、最低限、単純パーセプトロンを実装するのにどれも必要なものです。
>conda install numpy matplotlib tensorflow keras
他にもライブラリはたくさんあり、今後どんな機械学習をするのにも使うであろうライブラリを数個だけ書いておきます。
- Python Imaging Library
- SciPy
- pandas
- NetWorkX(機械学習というよりはグラフアルゴリズムなど)
仮想環境含め、環境構築は以上です。
単純パーセプトロンの実装
ようやくここまで来ました。jupyter labで単純パーセプトロンを実装するプログラムを作成していきます。その前に、またざっくりと単純パーセプトロンについて説明します。
単純パーセプトロンとは
先に述べている通り、単純パーセプトロンはニューラルネットワークの一種です。したがって、入力層と出力層に分かれていて、入力層の合計が一定値を超えると出力層に情報が伝えられます。単純パーセプトロンは複数入力で単一の出力をします。
各入力層の重みをW1, W2, ..., Wxとして、入力層に関係しない重みをθとしたとき、それぞれの入力値と重みを掛け合わせたものの合計とθの和が0より大きければ1、そうでなければ0を出力します。モデルで書くと以下のようになります。
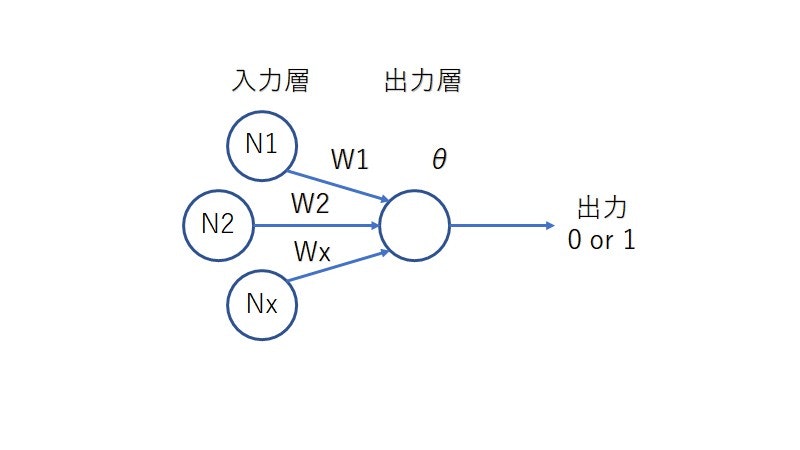
数式で書くと、
N₁ × W₁ + N₂ × W₂ + ... + Nx × Wx + θ > 0
となります。また左辺について整理していくと、
\frac{N₁}{N₂} × W₁ + W₂ + \frac{θ}{N₂} = 0 \\
W₂ = (- \frac{N₁}{N₂}) × W₁ + (- \frac{θ}{N₂})
分かりづらいので、変数を変えると
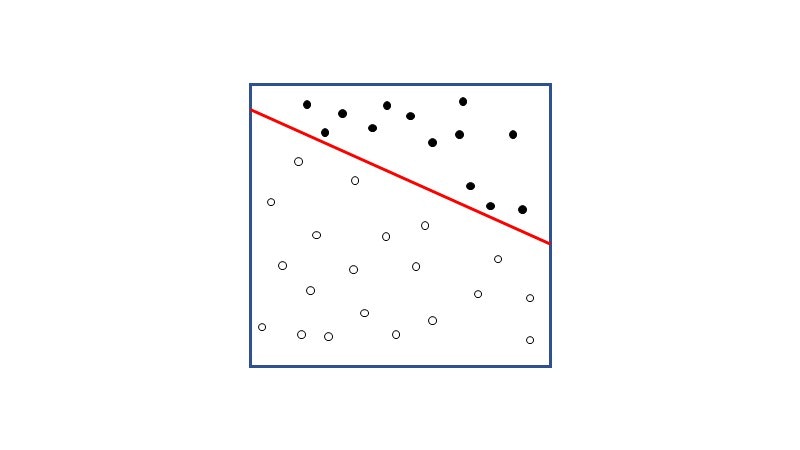
y = a × x + b
と、直線であることが分かります。つまり、単純パーセプトロンでは入力値、出力値の結果から以下のように二分割にするような直線を引くことができます。
単純パーセプトロンについてのざっくりとした説明は以上です。こちらもなんとなく分かっていただけたでしょうか。今回は二入力のAND関数に対しての二分割するようなプログラムを作成します。AND関数は二入力とも1の場合は1を、それ以外は0を出力します。従って、以下のように分割ことが予測されます。
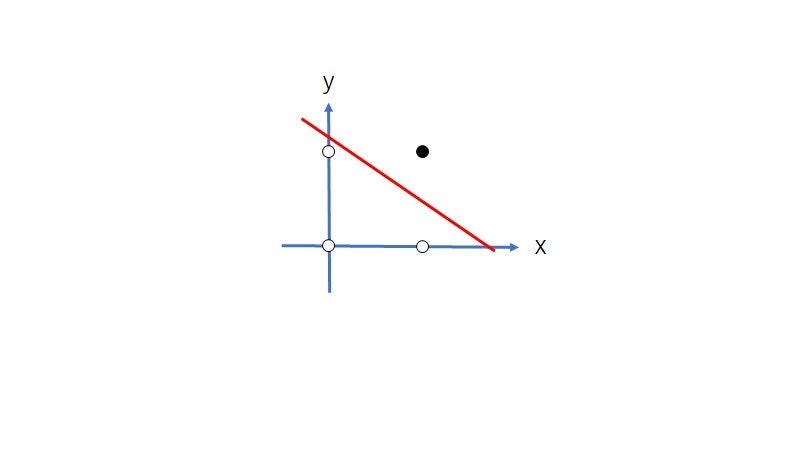
事前準備
cdコマンドで作業用フォルダに移動してからjupyter labを起動させましょう。今回はDocuments/sample下で行います。
(base) C:\Users\ユーザ名>cd Documents
# sampleフォルダの作成
(base) C:\Users\ユーザ名\Documents>mkdir sample
(base) C:\Users\ユーザ名\Documents>cd sample
(base) C:\Users\ユーザ名\Documents\sample>activate NN_sample
(NN_sample) C:\Users\ユーザ名\Documents\sample>
Jupyter Labの起動
jupyter labはjupyter labと入力するだけでjupyter labは起動し、webブラウザが立ち上がります。立ち上がらないときはjupyter lab実行後、出てくる文章の1番最後に書いてあるURLをコピーしてブラウザでアクセスします。
(NN_sample) C:\Users\ユーザ名\Documents\フォルダ名>jupyter lab
[I 20:43:50.910 LabApp] JupyterLab extension loaded from C:\Users\ユーザ名\Miniconda3\envs\環境名\lib\site-packages\jupyterlab
・・・
Or copy and paste one of these URLs:
http://localhost:8888/?token=43ed3a669bd4da587fa6febf75f3e38b0f7de64916e96648
or http://127.0.0.1:8888/?token=43ed3a669bd4da587fa6febf75f3e38b0f7de64916e96648
ノートブックの作成
どんな作成の仕方でも問題ないのですが、jupyter labの左上から、File -> New -> Notebookを選択して新しくノートブックを作成します。選択後に出てくるSelect Kernelはpython 3のままで問題ないです。
作られたノートブックでは、コードはセルに分け、セルごとにcode、Markdown、Rawを選ぶことができます。適切にセル分けすることができれば、プログラムのうち必要な部分だけを実行させることができます。shift + Enterで各セルを実行させることができます。
コード作成
必要なライブラリのインポート
まずは必要なライブラリのインストールをします。import ライブラリ名 あるいは import ライブラリ名 as プログラム内で使う名前で記述していきます。
import numpy as np
import matplotlib.pyplot as plt
import os
import csv
from keras.models import Sequential
from keras.layers import Dense, Activation
環境変数の定義
コード内で使う変数をここで定義します。今回は短いコードですが、特に機械学習では学習回数や指定ファイルを変更する機会は多く、一度に定義することでこのセルを編集すればプログラム内のすべてで適用することができます。
CSVFILE = 'data.csv'
GRIDFILE = 'grid.csv'
header = ['x', 'y', 'class']
body = [
[0, 0, 0],
[1, 0, 0],
[0, 1, 0],
[1, 1, 1]
]
csvファイルの作成
後にモデルになるAdd関数をcsvファイルに書き込んでいきます。また学習後のグラフを描画するために必要なグリッドを作成するためのcsvファイルも作成します。本質的な部分ではないので読み飛ばしてもらって問題ないです。
csvファイルの作成だけなので基本的にこのセルの実行は1回だけで問題ありません。
# CSVFILEの名前のcsvファイルがあれば削除
if os.path.exists(CSVFILE):
os.unlink(CSVFILE)
if os.path.exists(GRIDFILE):
os.unlink(GRIDFILE)
# ファイルへの書き込み
# with open(扱いたいファイル名, モード(w: 書き込み)) as 変数名:
with open(CSVFILE, 'w') as v:
writer = csv.writer(v)
writer.writerow(header)
writer.writerows(body)
with open(GRIDFILE, 'w') as v:
x = float(0)
y = float(0)
writer = csv.writer(v)
writer.writerow([x, y])
pre_x = x
pre_y = y
for _ in range(0, 20):
pre_y += 0.05
writer.writerow([round(pre_x, 4), round(pre_y, 4)])
for _ in range(0, 20):
pre_y = y
pre_x += 0.05
for _ in range(0, 21):
writer.writerow([round(pre_x, 4), round(pre_y, 4)])
pre_y += 0.05
csvファイルの読み込み
学習を行う際に必要となるデータをcsvファイルを抽出します。python独特のスライスを使って抽出します。抽出の仕方はスライス以外にもpandasを使ってDataflame型として取り出すことも可能ですが、今回はndarray型が必要となるのでスライスで抽出します。スライスもまだまだ知っておくべき要素があるので、こちらなどを参考に学んでください。
# CSVFILEを、1行目を飛ばして、','で区切り、ndarray型で変数dataに格納
data = np.loadtxt(CSVFILE, delimiter=',', skiprows=1)
# dataのうち、最後の列以外を抜き出す
ip_train = data[:, :-1]
# [[0. 0.]
# [1. 0.]
# [0. 1.]
# [1. 1.]]
# dataのうち、最後の列を取り出す
class_train = data[:, -1]
# [0. 0. 0. 1.]
学習の実行
Warningが出た際は、特に問題はないですが、もう一度実行してください。
- Sequential()
学習のためのコンストラクタを生成します。したがって、Sequential()を格納した変数.add(...)でレイヤーを追加していくことができます。
もちろん、Sequential([Dense(...), Activation(...)])のようにレイヤーも含め、一度に記述することもできます。
- add(Dense(...))
先ほども述べたように学習のためのコンストラクタにレイヤーを追加していきます。今回は活性化関数はsigmoid、ニューロンの数は1、入力値は2です。
活性化関数とは、今回の場合、N₁ × W₁ + N₂ × W₂ + ... + Nx × Wx + θ がどのようにして出力層に伝えられるかを決めるものです。他にもsoftmaxやreluなどがあります。
- compile(...)
compileでは詳細な学習の設定をします。学習において最小化させたい損失関数はbinary_crossentropy、学習と関係なく性能を評価する評価関数はaccuracy、最適化法をsgdに設定します。
- fit(...)
ここで学習が実行されます。テストモデル、エポック数、バッチサイズを指定します。
# ニューラルネットワークのコンストラクタの生成
model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid')) # Dense(層のニューロンの数, 入力の次元数, 活性化関数)
# 学習の設定 .compile(損失関数, 最適化法, 評価関数)
model.compile(loss='binary_crossentropy', optimizer='sgd', metrics=['accuracy'])
# 学習の実行
fg = model.fit(ip_train, class_train, epochs=1000, batch_size=1)
# Train on 4 samples
# Epoch 1/1000
# 4/4 [==============================] - 1s 137ms/sample - loss: 0.7022 - acc: 0.7500
# Epoch 2/1000
# 4/4 [==============================] - 0s 5ms/sample - loss: 0.7004 - acc: 0.7500
# Epoch 3/1000
# 4/4 [==============================] - 0s 5ms/sample - loss: 0.6987 - acc: 0.7500
# ・・・
# Epoch 999/1000
# 4/4 [==============================] - 0s 4ms/sample - loss: 0.2649 - acc: 1.0000
# Epoch 1000/1000
# 4/4 [==============================] - 0s 3ms/sample - loss: 0.2647 - acc: 1.0000
グラフの描画
学習が完了したので、predict()を使って境界線を予測し、結果をmatplotlibを使って表示させたいと思います。今回もスライスを使って必要なデータを抽出し表示させます。他には特にコード中で詳しく説明する部分はないのでコードを見てもらえればと思います。
t1 = ip_train[ class_train==1 ]
t0 = ip_train[ class_train==0 ]
# 教師信号が1の点のx座標の配列
t1_x = t1[:, 0]
# 教師信号が1の点のy座標の配列
t1_y = t1[:, 1]
t0_x = t0[:, 0]
t0_y = t0[:, 1]
# ','区切りでGRIDFILEを読み込み
g = np.loadtxt(GRIDFILE, delimiter=',')
# 学習の結果から境界線を予測
pred_g = model.predict(g)[:, 0]
# 予測値が1の点の配列
g1 = g[ pred_g >= 0.5 ]
# 予測値が0の点の配列
g0 = g[ pred_g < 0.5 ]
# 予測値が1の点のx座標の配列
g1_x = g1[:, 0]
# 予測値が1の点のy座標の配列
g1_y = g1[:, 1]
g0_x = g0[:, 0]
g0_y = g0[:, 1]
plt.scatter(t1_x, t1_y, marker='o', facecolor='black', s=100)
plt.scatter(t0_x, t0_y, marker='o', facecolor='white', edgecolor='black', s=100)
plt.scatter(g1_x, g1_y, marker='o', facecolor='black', s=20)
plt.scatter(g0_x, g0_y, marker='o', facecolor='white', edgecolor='black', s=20)
plt.show()

実行すると、線は表示できてないですが、期待していたような分類ができたと思います。黒〇が出力結果1とみなされた部分、白〇が出力結果0とみなされた部分です。以上で実装まで含め終了です。
最後に
1番基本的な単純パーセプトロンの実装までざっくりと行ってきました。繰り返しになりますが、ざっくりと機械学習について分かって、基本的な単純パーセプトロンの実装までとりあえずやってみるというのがこの記事の目的なので、機械学習を始めるきっかけになればと思っています。
より複雑化すると画像に写っているものの判別や、音声データの識別もできるようになります。是非調べて実装してみてください。
また、今回参加させてもらっているDMM WEBCAMP アドベントカレンダーでは、先輩のメンターさんや社員さんがもっとすごい記事を書いています。興味のあるものがありましたら、ぜひご覧ください。
参考ページ
機械学習関連
一から始める機械学習(機械学習概要)
教師あり学習と教師なし学習の違いについて- AI人工知能テクノロジー -
ディープラーニング- これだけは知っておきたい3つのこと -
scikit-learn でクラスタ分析 (K-means 法) – Python でデータサイエンス
Python関連
Miniconda関連
Miniconda 利用ノート — 読書ノート v1.5dev - プレハブ小屋
WindowsにMinicondaインストール(2018年) - Qiita
【初心者向け】Anacondaで仮想環境を作ってみる - Qiita
JupyterLabのすゝめ - Qiita
パーセプロトン関連
一番簡単な単純パーセプトロンについて - AI人工知能テクノロジー
Keras / Tensorflowで始めるディープラーニング入門 - Qiita
多層パーセプトロンの実装 - Pythonと機械学習