概要
Keras(Tensorflowバックグラウンド)を用いた画像認識の入門として、MNIST(手書き数字の画像データセット)で手書き文字の予測を行いました。
実装したコード(iPython Notebook)はこちら(Github)をご確認下さい。
- MNISTデータセット サンプル:

- 実装した

前提
Kerasとは
Kerasとは、Pythonで書かれたニューラルネットワークのライブラリです。
バックエンドとしてTensorFlow、CNTK、Theanoのライブラリを選択することができます。
人間にとって分かりやすい設計の為、初心者でも簡単に迅速なプロトタイピングが可能となっています。
日本語ドキュメントも充実しています。インストール方法は公式HPをご参照下さい。
インストール
Kerasに加え、今回バックエンドとして利用するTensorflowもインストールします。
pip install --upgrade tensorflow
pip install keras
2つのモデル記述方法
kerasでは、ネットワークの層(レイヤー)を記述する方法が2つあります。
Sequentialモデル
ネットワークを1列に積み重ねていく、シンプルな方法です。
- サンプルコード:
from keras.models import Sequential
from keras.layers import Dense, Activation
# モデルの作成
model = Sequential()
# モデルにレイヤーを積み上げていく
model.add(Dense(units=64, input_dim=100))
model.add(Activation('relu'))
model.add(Dense(units=10))
model.add(Activation('softmax'))
# 訓練プロセスの定義
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
# 訓練の実行
# (x_train, y_trainはNumpy行列の学習データ)
model.fit(x_train, y_train, epochs=5, batch_size=32)
# 予測の実行
classes = model.predict(x_test, batch_size=128)
Functional API
複雑なネットワークの記述が可能な方法です。
Sequentialモデルと異なり、複数の出力や共有レイヤーの定義等が可能となっています。
- サンプルコード:
from keras.layers import Input, Dense
from keras.models import Model
# インプットの定義
inputs = Input(shape=(784,))
# レイヤーの定義
nw = Dense(64, activation='relu')(inputs)
nw = Dense(64, activation='relu')(x)
predictions = Dense(10, activation='softmax')(x)
# モデルの定義(インプットとレイヤーを指定)
model = Model(inputs=inputs, outputs=predictions)
# 訓練プロセスの定義
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 訓練の実行
model.fit(data, labels)
# 予測の実行
classes = model.predict(x_test, batch_size=128)
実装
今回は、2種類のモデルをFunctional APIを用いて実装してみます。
1つは単純な全結合のみのモデル、もう1つはCNN(Convolution Neural Network:畳み込みニューラルネットワーク)のモデルです。
手書き文字の認識(1): 全結合層のみ
冗長な部分は省略して主要な部分のみ解説していきます。
ソースコードはこちら。
データセットのダウンロード
教師ラベル付けされた手書き文字をダウンロードします。
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
内容は10種類の数字の白黒画像(28x28)です。訓練データが60000枚、テストデータが10000枚となっております。
Kerasでは、MINIST以外にもいくつかのデータセットが提供されています。
画像データの前処理
ネットワークで扱う為に、訓練データを1次元配列に変換して、値を0から1の間に変換します。
また、教師データについてもone-hot表現(正解の要素を1として、他の要素を0にする表現)に変換します。
x_train = x_train.reshape(60000, 784).astype('float32') /255
x_test = x_test.reshape(10000, 784).astype('float32') /255
y_train = keras.utils.np_utils.to_categorical(y_train.astype('int32'),10)
y_test = keras.utils.np_utils.to_categorical(y_test.astype('int32'),10)
モデルの作成
全結合層3層のみのシンプルなモデルです。
Dropoutは、訓練時に一定確率で中間層を無視する関数です。過学習を防ぐために使用します。
inputs = Input(shape=(784,))
nw = Dense(512, activation='relu')(inputs)
nw = Dropout(.5)(nw)
nw = Dense(512, activation='relu')(nw)
nw = Dropout(.5)(nw)
predictions = Dense(10, activation='softmax')(nw)
訓練
epoch(学習の繰り返し単位)20回で訓練を行います。
history = model.fit(x_train, y_train, batch_size=128, epochs=20, verbose=1, validation_data=(x_test, y_test))
kerasでは、訓練を行うと自動でログを出力をしてくれます。
Train on 60000 samples, validate on 10000 samples
Epoch 1/20
60000/60000 [==============================] - 7s - loss: 0.3319 - acc: 0.8974 - val_loss: 0.1267 - val_acc: 0.9607
Epoch 2/20
60000/60000 [==============================] - 6s - loss: 0.1621 - acc: 0.9524 - val_loss: 0.0921 - val_acc: 0.9733
Epoch 3/20
60000/60000 [==============================] - 6s - loss: 0.1318 - acc: 0.9610 - val_loss: 0.0874 - val_acc: 0.9750
(中略)
Epoch 20/20
60000/60000 [==============================] - 6s - loss: 0.0722 - acc: 0.9823 - val_loss: 0.1083 - val_acc: 0.9817
結果の表示
-正答率:
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
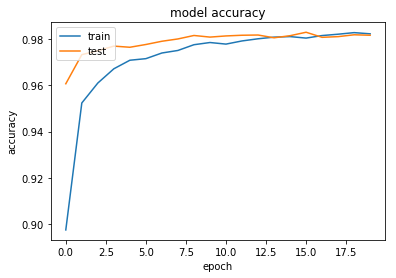
epochが2回目では95.24%、20回目では98.23%と高い認識精度が出ています。
- ロス関数:
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
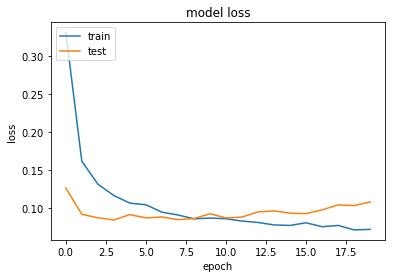
epochが10回以上の時点で過学習(overfitting)が起きていることが分かります。
手書き文字の認識(2): CNNモデル
同じデータに対して、CNNで画像認識を行います。
ソースコードはこちら。
画像データの前処理
kerasのバックエンドで使用するライブラリにより入力チャネルの順番が異なる為、条件分岐させて前処理を定義します。
if backend.image_data_format() == 'channels_first':
inputs = Input(shape=(1, 28, 28))
x_train = x_train.reshape(x_train.shape[0], 1, 28, 28).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], 1, 28, 28).astype('float32') / 255
else:
inputs = Input(shape=(28, 28, 1))
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1).astype('float32') / 255
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1).astype('float32') / 255
モデルの作成
# 2つの畳み込みレイヤー
conv1_1 = Conv2D(32, (3, 3), activation='relu', name='conv1_1')(inputs)
conv1_2 = Conv2D(64, (3, 3), activation='relu', name='conv1_2')(conv1_1)
# MaxPooling2D: pool_sizeの範囲で最も大きい値を次の層に渡す
pool1 = MaxPooling2D(pool_size=(2, 2), name='pool1')(conv1_2)
# Dropout: 訓練時に一定確率で中間層を無視する
nw = Dropout(.25)(pool1)
# Flatten: 2次元データを1次元に変換
nw = Flatten()(nw)
nw = Dense(128, activation='relu')(nw)
nw = Dropout(.5)(nw)
# 最終レイヤー(10クラスに分類)
predictions = Dense(10, activation='softmax')(nw)
# モデルの作成
model = Model(inputs=inputs, outputs=predictions)
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.Adadelta(), metrics=['accuracy'])
コールバックの定義
kerasでは、訓練中に実行可能な処理をコールバックとして定義できます。
今回は、以下のコールバックを定義します。
- ModelCheckpoint: epoch毎にweightデータを出力する処理
- TensorBoard: モデル等の可視化を行うTensorboard用のログ出力
cb_cp = keras.callbacks.ModelCheckpoint('./out/checkpoints/weights.{epoch:02d}-{val_loss:.2f}.hdf5', verbose=1, save_weights_only=True)
cb_tf = keras.callbacks.TensorBoard(log_dir='./out/tensorBoard', histogram_freq=0)
訓練の実施
epoch数10で実施します。
history = model.fit(x_train, y_train, batch_size=128, epochs=10, verbose=1, callbacks=[cb_cp, cb_tf], validation_data=(x_test, y_test))
結果の表示
Train on 60000 samples, validate on 10000 samples
Epoch 1/10
59904/60000 [============================>.] - ETA: 0s - loss: 0.3267 - acc: 0.9009Epoch 00000: saving model to ./out/checkpoints/weights.00-0.08.hdf5
60000/60000 [==============================] - 135s - loss: 0.3263 - acc: 0.9011 - val_loss: 0.0785 - val_acc: 0.9749
Epoch 2/10
59904/60000 [============================>.] - ETA: 0s - loss: 0.1132 - acc: 0.9671Epoch 00001: saving model to ./out/checkpoints/weights.01-0.06.hdf5
60000/60000 [==============================] - 131s - loss: 0.1131 - acc: 0.9671 - val_loss: 0.0580 - val_acc: 0.9811
Epoch 3/10
59904/60000 [============================>.] - ETA: 0s - loss: 0.0871 - acc: 0.9735Epoch 00002: saving model to ./out/checkpoints/weights.02-0.05.hdf5
60000/60000 [==============================] - 135s - loss: 0.0870 - acc: 0.9735 - val_loss: 0.0469 - val_acc: 0.9850
(中略)
Epoch 10/10
59904/60000 [============================>.] - ETA: 0s - loss: 0.0410 - acc: 0.9876Epoch 00009: saving model to ./out/checkpoints/weights.09-0.03.hdf5
60000/60000 [==============================] - 140s - loss: 0.0410 - acc: 0.9876 - val_loss: 0.0295 - val_acc: 0.9902
-
正答率:
epoch 1回目でも90.09%と高い精度が出ています。
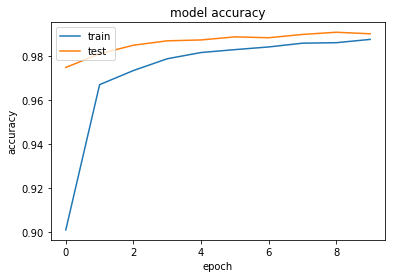
-
ロス関数:
汎化性能も、全結合層のみのモデルより良い結果となっています。
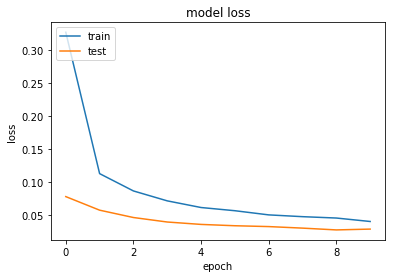
モデルの可視化
今回は、モデルの可視化にTensorboardを用います。
以下のコマンドで起動します。
コールバック処理にて出力したログを指定します。
tensorboard --logdir=./out/
以下のようにモデルの可視化ができました。
感想
今回はMNISTの手書き文字認識という比較的難易度の低い課題でしたので、シンプルなネットワークでも十分な精度で予測できました。
しかし、実際に物体検出などのより難易度の高い課題を解く場合、特徴検出を行う為にVGG16等の学習済モデルを利用することで、最初から精度の高い特徴検出を行うのが一般的となっています。
(実際に以前紹介したYOLOやSSDでもVGG16が使用されています)
次は、学習済モデルによるファインチューニングを行い独自課題の認識にもチャレンジしてみたいと思います。また、Tensorboardももっと色々な機能があるので使っていきたいと思います。