scikit-learnのアルゴリズム・チートシートで紹介されている手法を全て実装し、解説してみました。
注釈
本記事シリーズの内容は、さらに丁寧に記載を加え、書籍「AIエンジニアを目指す人のための機械学習入門 実装しながらアルゴリズムの流れを学ぶ」
として、出版いたしました。

概要
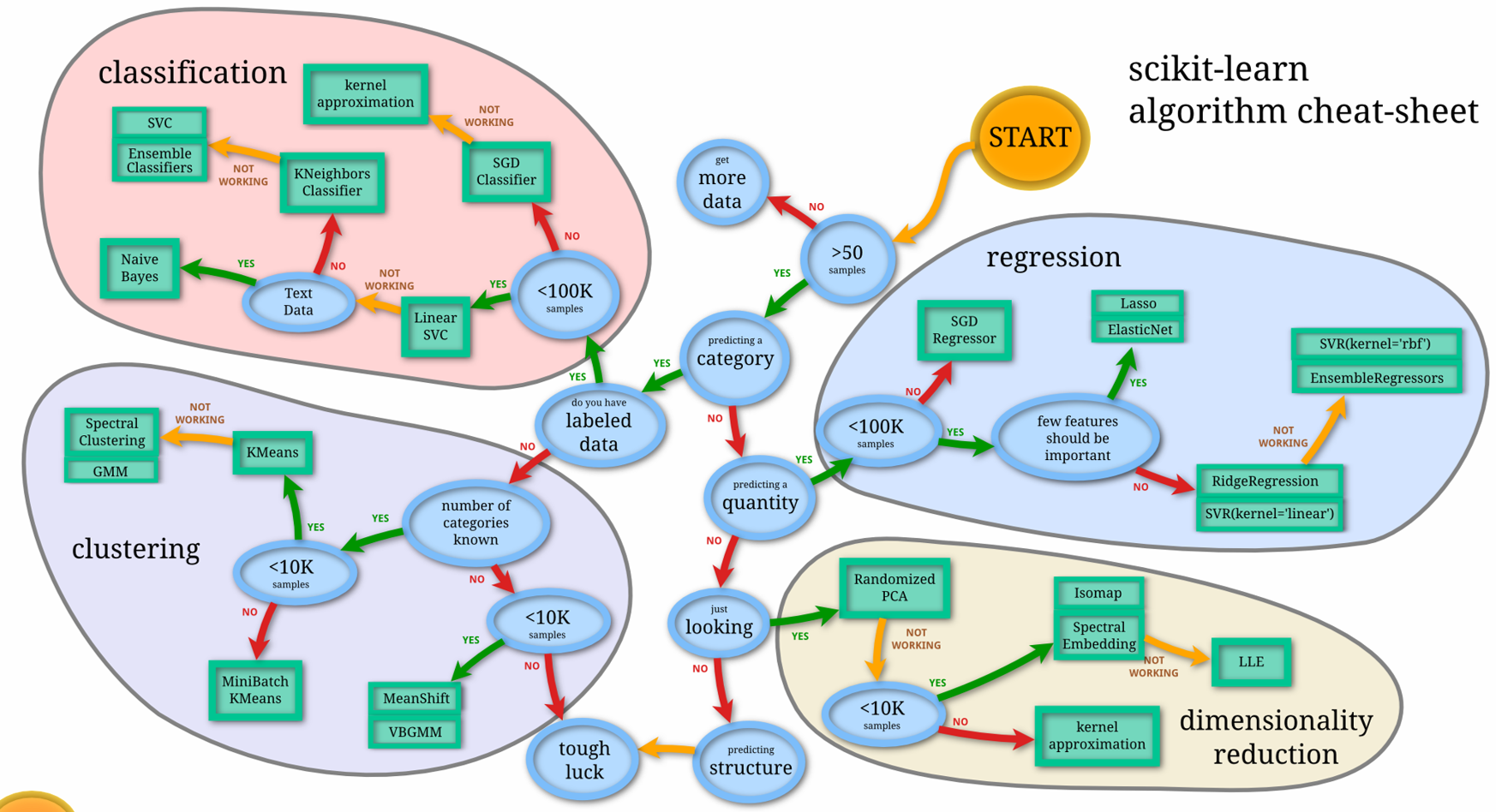
【対象者】機械学習を使用したい方、初心者向けの機械学習本を読んで少し実装してみた方
scikit-learnの説明は英語で分かりにくいし、実装例もシンプルでなくて、よく分からんという方
【得られるもの】模擬データを用いて、各手法を使用したミニマム・シンプルなプログラムが実装できるようになります。
アルゴリズムの詳細な数式は理解できませんが、だいたい何をやりたいのか、意図と心、エッセンスが分かります。
アルゴリズムマップの手法をひとつずつ実装・解説します。
コード全部載せるのは大変なので、各内容の詳細はブログに掲載しております。
詳細な数式を掲載しているのではなく、初学者がエッセンスをつかめるような説明を目指して記事を執筆しました。
クラス分類問題・教師あり学習
まずはじめにWindows PCにJupyter Notebookとscikit-learnを導入し、Pythonで機械学習する環境を整えます。
そして、「大規模なデータ」の線形なクラス分類手法であるSGD(stochastic gradient descent)というアルゴリズムを実装・解説します。
模擬データとしては、有名なワインの分類データを使用します。
ワインの色や成分から、ブドウの品種を分類します。
SGD|Python、scikit-learnで機械学習を実装
大規模なデータの非線形なクラス分類手法であるカーネル近似を実装・解説します。
模擬データとしては、XORの関係を持つデータを使用します。
通常のSGDでは、うまく分類できないですが、カーネル近似を使用することでうまくいくことを紹介します。
カーネル近似|Python、scikit-learnで機械学習を実装
データの線形なクラス分類手法であるLinear SVC(SVM classification)を実装・解説します。
SVMの心や、通常の誤差を用いるSGDなどとの違いを説明します。
模擬データとしては、ワインの分類を使用します。
Linear SVC|Python、scikit-learnで機械学習を実装
データの非線形なクラス分類手法であるk近傍法を実装・解説します。
模擬データとしては、XORの分類を使用します。
k近傍法|Python、scikit-learnで機械学習を実装
データの非線形なクラス分類手法であるkernel SVCを実装・解説します。
模擬データとしては、XORの分類を使用します。
kernel SVC|Python、scikit-learnで機械学習を実装
データの非線形なクラス分類手法であるEnsemble Classificationを実装・解説します。
ここではランダムフォレストをベースとします。
模擬データとしては、XORの分類を使用します。
Ensemble Classification|Python、scikit-learnで機械学習を実装
ここまでは単純なデータを扱いましたが、次にテキストデータのクラス分類を行います。
ivedoorニュースコーパスの記事を使用し、ニュース記事のカテゴリーをナイーブベイズにより分類する手法を実装します。
テキストデータを扱ううえで重要な、形態素解析による分かち書き、BoW(Bag-of-Words)、ナイーブベイズを順番に実装・解説します。
また、ナイーブって日本語では”うぶ”という意味ですが、「うぶなベイズ」ってどういう意味なのかなども説明します。
ナイーブベイズ|Python、scikit-learnで機械学習を実装
以上でクラス分類の実装は終了ですが、各アルゴリズムを実装するさいに重要なハイパーパラメータをグリッドサーチと呼ばれる手法で決定する方法を実装・解説します。
ハイパーパラメータをグリッドサーチ|Python、scikit-learnで機械学習を実装
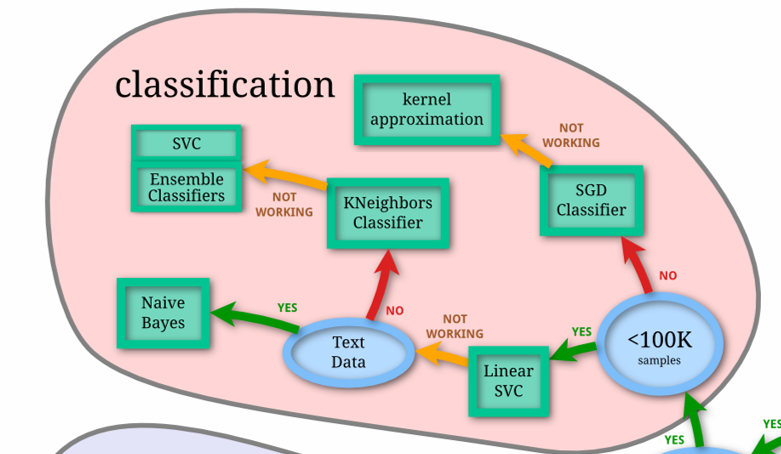
クラスタ分析・教師なし学習
つぎに教師なし学習であるクラスタ分析を行います。
まずはじめに、いくつのクラスタに分かれるのかが事前にわかっている状況でのクラスタ分析手法を紹介します。
基本的な手法であるKMeansを実装・解説します。
模擬データとしてはワインのデータを使用します。
ワインデータには教師ラベル(どの品種か)が本当はわかりますが、これがなかったとしたらどのようにクラスター分けされるのかを確認します。
KMeans|Python、scikit-learnで機械学習を実装
KMeansではうまくクラスタ分けできないような非線形な構造を持ったデータに対するクラスタ分けを行います。
ここではスペクトラルクラスタリングを実装・解説します。
模擬データとしてはムーンと呼ばれる三日月が2つあるデータを使用します。
KMeansではうまくクラスタ分けできず、スペクトラルクラスタリングで分けられることを確認します。
スペクトラルクラスタリング|Python、scikit-learnで機械学習を実装
非線形な構造を持ったデータに対するクラスタ分けである、GMM(Gaussian mixture models)を紹介します。
模擬データとしてはムーンを使用します。
GMM|Python、scikit-learnで機械学習を実装
つぎに、いくつのクラスタに分かれるのか分からない状況でのクラスタ分類を行います。
MeanShiftと呼ばれる手法を実装・解説します。
模擬データとしてはムーンを使用します。
MeanShift|Python、scikit-learnで機械学習を実装
VBGMM(Variational Bayesian Gaussian Mixture)と呼ばれる手法を実装・解説します。
模擬データとしてはワインのデータを使用します。
VBGMM|Python、scikit-learnで機械学習を実装
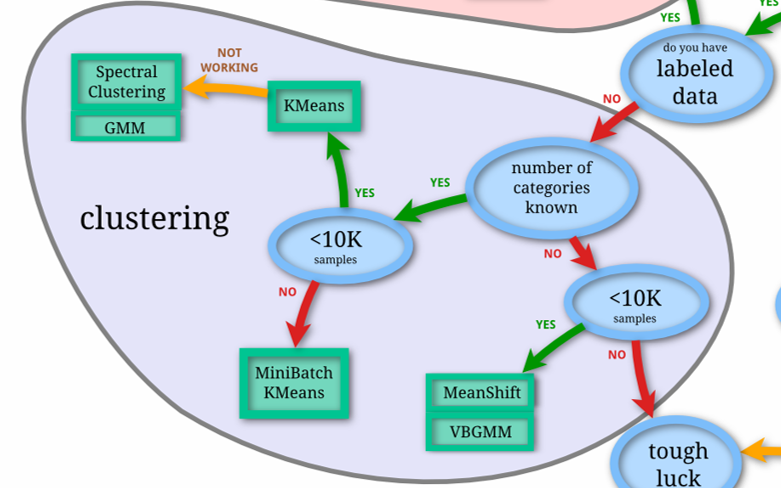
回帰分析
目的変数y(非説明変数)が連続値であるときに、説明変数xを用いてyを近似的に求める手法(回帰)を実装・解説します。
もっとも基本的なSGD回帰分析(stochastic gradient descent Regressor)を実装・解説します。
模擬データとしては、ボストン住宅価格と呼ばれるデータを使用します。
部屋数や大通りへの距離、地域の犯罪発生率など13次元の説明変数xから、住宅価格yを求める式を立てます。
SGD回帰|Python、scikit-learnで機械学習を実装
つぎに、説明変数xの一部が重要な場合の回帰分析を行います。
LASSO回帰を実装・解説します。
LASSO回帰はL1ノルムの正則化になります。
L1ノルムで正則化することで、一部の次元だけが重要視される点などを解説します。
模擬データとしては、ボストン住宅価格を使用します。
LASSO回帰|Python、scikit-learnで機械学習を実装
ElasticNet回帰を実装・解説します。
ElasticNet回帰はL1ノルムとL2ノルムの正則化を両方使用します。
模擬データとしては、ボストン住宅価格を使用します。
ElasticNet回帰|Python、scikit-learnで機械学習を実装
つぎに、説明変数xのすべてが重要な場合の回帰分析を行います。
説明変数xのすべてが重要な場合の回帰分析であるRidge回帰を実装・解説します。
Ridge回帰はL2ノルムの正則化を使用します。
L2ノルムで正則化することで、一部の次元だけが重要視されにくい点などを解説します。
模擬データとしては、ボストン住宅価格を使用します。
Ridge回帰|Python、scikit-learnで機械学習を実装
Linear SVR回帰を実装・解説します。
回帰分析にSVMを使用するイメージがわきませんが、どのように使用されているのかを解説します。
模擬データとしては、ボストン住宅価格を使用します。
Linear SVR回帰|Python、scikit-learnで機械学習を実装
ここまでは直線で近似してきました。つぎに、非線形な回帰分析を行います。
rbfカーネル(ガウスカーネル)を使用したSVR回帰を実装・解説します。
模擬データとしてはsin波を使用します。
SVR回帰|Python、scikit-learnで機械学習を実装
Ensemble Rigressorを使用した回帰分析を実装・解説します。
ここでは、決定木をベースとしたBaggingRegressorを実装します。
模擬データとしてはsin波を使用します。
Ensemble Rigressor|Python、scikit-learnで機械学習を実装
データの次元圧縮
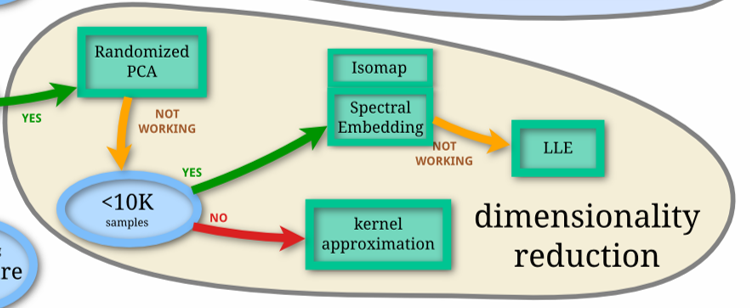
多次元データの次元を圧縮する手法を解説します。
もっとも基本的なPCAについて実装・解説します。
模擬データとしては、ボストン住宅価格を使用します。
PCA|Python、scikit-learnで機械学習を実装
つづいて非線形な構造をもつデータに対する次元圧縮手法を解説します。
カーネルトリックを利用した、Kernel-PCAを実装・解説します。
模擬データとしてはムーンデータを使用します。
ムーンは2次元データなので、次元は2次元のまま下がっていませんが、よりデータ構造が見やすいように新たな
軸が作られることを確認します。
カーネルPCA|Python、scikit-learnで機械学習を実装
SpectralEmbeddingによる次元圧縮を実装・解説します。
模擬データにはムーンデータを使用します。
SpectralEmbedding|Python、scikit-learnで機械学習を実装
多様体理論を利用したIsomapによる次元圧縮を実装・解説します。
多様体というとなんだか難しそうですが、要は何をしているのかを説明します。
模擬データにはムーンデータを使用します。
Isomap|Python、scikit-learnで機械学習を実装
多様体理論を利用したLLE(LocallyLinearEmbedding)による次元圧縮を実装・解説します。
模擬データにはムーンデータを使用します。
LLE(LocallyLinearEmbedding)|Python、scikit-learnで機械学習を実装
以上でscikit-learnのアルゴリズムチートマップの全実装・解説となります。
おまけ
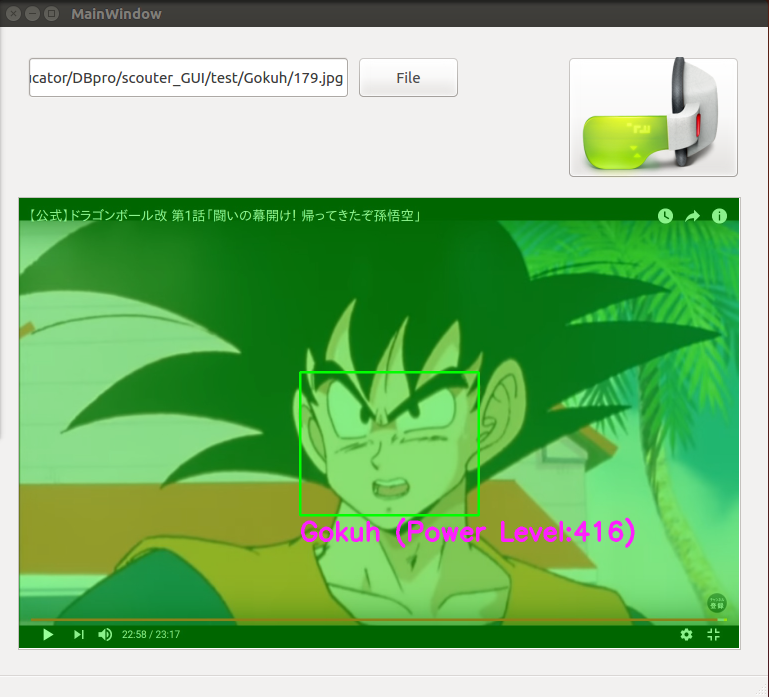
最後におまけとして、初めてディープラーニングを使用して、ドラゴンボールの画像識別を行ってみました。
ディープラーニングを使ってドラゴンボールZのスカウターっぽいのを作ってみた (Python, Chainer, dlib, PyQt)
以上となります。