kaggleを始めたのはいいけど何をしたらいいのか分からない。
こちらの記事をかなりもとにしています。【Kaggleでタイタニックの生存者を予測をしてSubmitしてみた】
kaggle初心者はこちらの記事も参考になります
ゆるキャン△を見てキャンプしたいみたいなノリで機械学習を始めたはいいけれども何をしたらいいのか分からない。そんなレベルで初心者の私がおすすめされたのがkaggle。機械学習で一番困るであろうデータセットが豊富にあり、一連のデータの処理や学習などの先達がいるのでとても良い。とても良いが、
登録したはいいけど何をしたらいいか分からない!!
初心者はkernelを読もうと言われるが、そもそもデータの性質が分からないカーネルを読んでも仕方ない。Forkしてコードを走らせるだけなの? ……と思っていた私が初めてsubmit(提出)したので書いてみる。
前述の記事のほとんど焼き増しになるが、kaggleを始める人の一助となればうれしい。
そんなことよりSubmitだぁ!!
kaggleにはcompetitionsというのがある。テンプレ説明にはcompetitionsに参加すると期限までに学習結果を提出して順位に応じて実績や、場合によっては賞金がもらえると書かれている。
とはいえ、kaggleには別に期限も賞金もない所謂"練習"のようなcompetitionsもある。この場合、データセットと提出形式と、submit(結果を提出)した際の順位や実績が見られるのでとても有意義である。練習用なので初心者や復習、ゆっくりやりたいけど順位も気になるようないろいろなスタイルで挑めるのでとても良い。
今回はtatinicのコンペに参加してみたので手順を書いていく。練習コンペである。
OverviewとRulesとData
そのままずばり概要、ルール、データセットである。スクショで説明する。

kaggleのcompetitionsに参加する場合、上のタブのCompetitionsからコンペ一覧が見られる。その中から自分の気になるコンペのページに行く。コンペのページをクリックすると上のようにコンペの詳細ページが見られる。
その中で、Overview(概要)を読んで面白そうだと思ったら参加するとよい。その際、読まなくてはいけないのがRulesである。ここにはデータの扱いの規定や各種締め切り、その他のコンペのルールが書いてある。よく読もう。
Dataタブに飛ぶとそのコンペで提供されるデータの形式が見られる。画像認識とか分からないのにデータに画像があっても困るのでここも確認するとよい。
以上の手順を終えてコンペに参加すると決めたら、タブ欄の一番右の青枠に「Join Competition」があるのでクリックする。その時、Rulesに同意するか求められるので了承すれば同意する。そうすれば「Join Competition」が上の画像のように「Submit Predictions」に変わる。
Dataのダウンロードもできるようになるのでlocalでコードを書くか、kernelを用いて書いてもよい。データの性質もルールも分かったので、そのコンペで公開されている他の人のkernelも参考になるだろう。
あとは個々人のスタイルでコードを書いて学習・予測データを提出(Submit)するだけである。
Submit手順(titanic)
Submitの方法はいくつかあるが、今回はcsvを出力してアップロードしたのでその方法を説明する。「Submit Predictions」で次のページに行く。

前述のDataタブに提出の形式が書かれているのでその形式に沿った学習結果のファイルを出力して上のページでSubmitする。ファイルをD&D、Describe submissionはGitHubのコミットコメントみたいなものなので適当に何かを書く。「Make Submission」して終わり。
順位の確認
SubmitするとLeaderboardタブで自分の順位が表示される。

スコアは0.76076で8197番目。これを見て工夫するもよし、別のコンペに参加するもよし。
コード
コードは以下の記事にあるコード(GitHub)を全面的に参考にしている。(以下、引用元)
【Kaggleでタイタニックの生存者を予測をしてSubmitしてみた】
といっても写経してSubmitしてもしょうがないので学習部分は当然自分で書く。ただし、前処理のcsvファイルを扱うためのpandasや相関関数をヒートマップで表すseabornの使い方はとても参考になった。
一方で、引用元では使っていないデータも使ってみたり、引用元ではscikit-leranのSVMを用いているが、私は現在kerasしか使えないのでsoftmaxで分類している。
前処理
引用元と2つほど異なる処理をしている。
1つは年齢の欠損値を0で埋めるのではなくrandom関数で乱数で埋めた。しかし、コードではいつの乱数で全部の欠損値を埋めているのであまり効果はない。欠損値ごとに別の乱数で埋めた行列を用意してpandasでコラムを付け足すコードや、欠損値のあるデータセットだけを抜き出して別の学習にかける方法もあったが書いてる途中では思いつかなった。
2つ目は"Cabin"の情報を捨てずに情報がある・ないの2値の形で保持した。というのも、乗客が乗っていた客室が分かる・分からないも情報になるかと思ったからだ。
該当部分のコードがこちら。
import random
# まずはNaNをfillna()関数で埋める
df["Age"]=df["Age"].fillna(random.random()*100)
df["Cabin"]=df["Cabin"].fillna(0)
# pd.to_numericでエラーを指定することで数字に変換できないものをNaNにした後、1で埋める。
df["Cabin"]=pd.to_numeric(df["Cabin"], errors="coeres")
df["Cabin"]=df["Cabin"].fillna(1)
Cabinの文字列情報を1に変換するうまい方法を探したが、to_numeric関数でエラーを指定すると数値以外の型が全てNaNになるので、あとはfillna(1)で埋める。
学習
学習はkerasの3層NN、出力層はsoftmax。活性関数はrelu、層の数はテキトー。
import keras
import tensorflow as tf
model=keras.Sequential([
keras.layers.Dense(10, activation=tf.nn.relu, input_dim=8),
keras.layers.Dense(2, activation=tf.nn.softmax),
])
model.compile(optimizer=tf.train.AdamOptimizer(),\
loss="sparse_categorical_crossentropy",\
metrics=["accuracy"])
print(model.summary())
epochs=200
fit=model.fit(train_features, train_labels, epochs=epochs, validation_split=0.3)
plt.figure(figsize=(10,10))
plt.xlim(0,epochs)
plt.ylim(0, 1)
plt.plot(fit.history['loss'], label="loss of training")
plt.plot(fit.history['acc'], label="acc of training")
plt.plot(fit.history['val_acc'], label="acc of evaluate")
epochsの数を大きめにして、データの30%をvalidationに回して評価してみる。
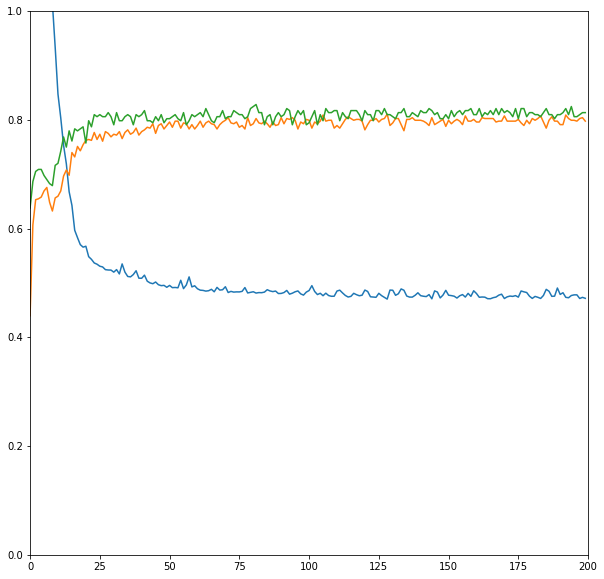 意外と過学習が起きていない。テストデータでaccuracyは0.8程度。
意外と過学習が起きていない。テストデータでaccuracyは0.8程度。
このモデルを使ってテストデータの乗客の生存/死亡を予測して提出する。出力は0と1のint型で提出。
結果
再掲になるが、提出するとこのような画面で自分の順位とスコアが確認できる。この学習結果では0.76076。実はこの前にepochs=50で適当に提出したのがあるので、0.75119から上がったよ!みたいなコメントが出ている。
これから様々観点からこのモデルを改良してもいいが、私的にはひと段落と言ったところである。様々なデータの処理が学べるが、これ以上頑張ってもtitanicの予想のための学習に先鋭化しすぎて、汎化の乏しさがあるからだ。
それより少し画像認識関連のCNNに興味があるのでMNISTのデータセットでもやろうかと思っている。もしくはコンペではないデータセットの学習も面白そうだ。
所感
というわけでkaggleにSubmitした話であるが、私自身kaggleでどうすればいいのか分からなかったので引用元の記事やコード、そしてなによりとにかくSubmitしてみてkaggleの仕組みを理解できたのが大きい。とりあえずSubmitしてみれば、そのテーマのモデルの改良、他の人のカーネル、周辺分野の他のデータセットなどがとても価値のある興味の対象になるので、よい。
kaggle初心者はとりあえずSubmitしてから考えてみよう!!別に誰の迷惑にもならないし!!
付記
今回、コードが引用元をforkして前処理と学習を書き直しただけのおんぶにだっこなので最後にGitHubのページをこっそり置いておく。"titanic_by_keras"が私のコードである。