実行コード,内容,解説は以下のURLに記述.
jupyterのNotebook
https://github.com/spica831/kaggle_titanic/blob/master/titanic.ipynb
背景
Kaggleにある家の値段を推定するハッカソンに参加しましたが
pythonの使い方や解析方法の知識不足により時間内に解決することができなかったので,
そこでリベンジとしてタイタニックの生存者予測をおこないました.
https://www.kaggle.com/c/titanic
Kaggleで家の売値を予測する
House Prices: Advanced Regression Techniques
https://www.kaggle.com/c/house-prices-advanced-regression-techniques
結論からいいますとタイタニックの予測の正解率は0.7512でした.
手法
# 必要なパッケージをインポート
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
# 値の読み込み
df = pd.read_csv("./input/train.csv")
df
値を表示します.
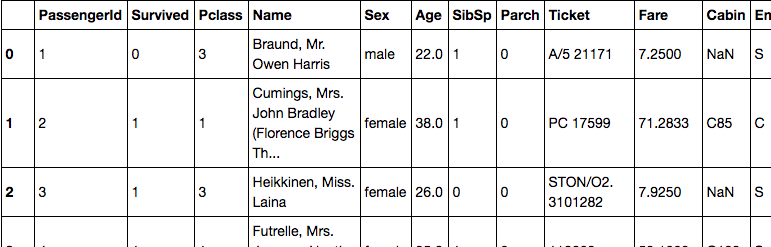
前処理
文字列の置換
見たところ,名や性別などで文字列がつかわれています.
このままでは解析に使えないので,性別(Sex)や乗船ランク?(Embarked)などは文字パターンが少ないためそれぞれ0, 1, 2など数値に置き換えた.
また,年齢(Age)は欠損値(NaN)をもつため全て0に置き換えた.
df.Embarked = df.Embarked.replace(['C', 'S', 'Q'], [0, 1, 2])
# df.Cabin = df.Cabin.replace('NaN', 0)
df.Sex = df.Sex.replace(['male', 'female'], [0, 1])
df.Age = df.Age.replace('NaN', 0)
カラム削除
Name や Ticket Cabinなど扱いづらいものはカラムごと削除をした.(痛い)
df.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
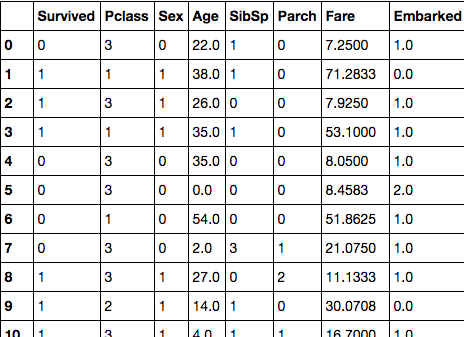
前処理の結果
すべて数値に置き換えることができた.
df
解析
相関係数
最初に相関係数を算出する
相関係数については以下のwikiを参照する
https://ja.wikipedia.org/wiki/%E7%9B%B8%E9%96%A2%E4%BF%82%E6%95%B0
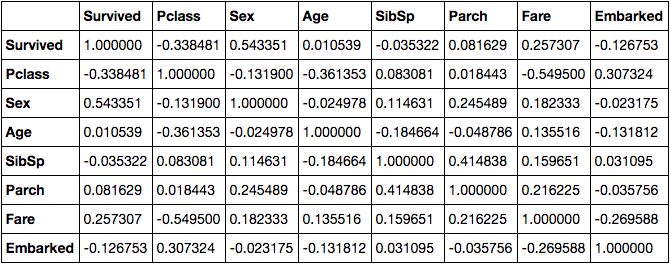
相関係数値
# 相関係数を算出
corrmat = df.corr()
corrmat
相関係数のヒートマップ
f, ax = plt.subplots(figsize=(12,9))
sns.heatmap(corrmat, vmax=.8, square=True)
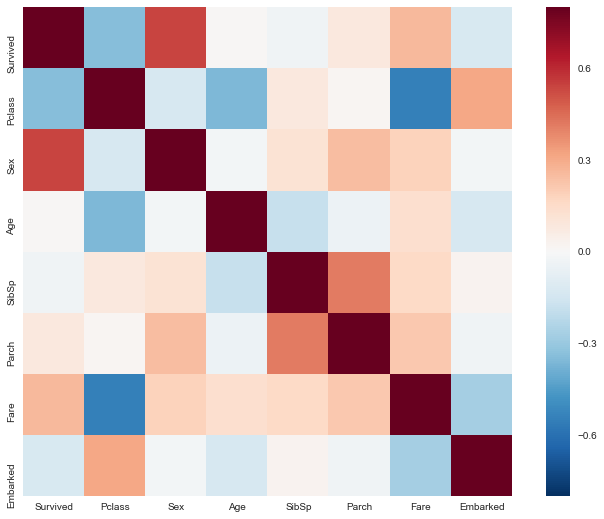
相関がみられることがわかった.
学習
学習前準備
答え(train_labelsここでいうSurvived)とパラメータ(train_featuresここでいうSurvived以外)に分ける
train_labels = df['Survived'].values
train_features = df
train_features.drop('Survived', axis=1, inplace=True)
train_features = train_features.values.astype(np.int64)
サポートベクターマシンで学習
最後に,scikit-learnにある線形SVMで2クラス分類の学習機を作成した.
(細かいパラメータは特には設定していない.がL1, L2正則化ぐらいは行っていた方がよかった)
from sklearn import svm
# Standard = svm.LinearSVC(C=1.0, intercept_scaling=1, multi_class=False , loss="l1", penalty="l2", dual=True)
svm = svm.LinearSVC()
svm.fit(train_features, train_labels)
テスト
今回算出するテスト値を読み込み
df_test = pd.read_csv("./input/test.csv")
事前準備
# 不要カラムの削除
df_test.drop(['PassengerId', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
# 文字列の数値置換
df_test.Embarked = df_test.Embarked.replace(['C', 'S', 'Q'], [0, 1, 2])
df_test.Sex = df_test.Sex.replace(['male', 'female'], [0, 1])
df_test.Age = df_test.Age.replace('NaN', 0)
# array値に変換
test_features = df_test.values.astype(np.int64)
SVMでクラス分類を行う.
y_test_pred = svm.predict(test_features)
最後に
Kaggleに提出できる形に変換する
# テスト値を再読み込みして,SVMでクラス分類したカラムを追加
df_out = pd.read_csv("./input/test.csv")
df_out["Survived"] = y_test_pred
# outputディレクトリに出力する
df_out[["PassengerId","Survived"]].to_csv("./output/submission.csv",index=False)
結果
冒頭にも記述しましたが,タイタニックの予測の正解率は0.7512でした.
ですが,2,3時間という短い時間で形にできてsubmitできたので満足でした.
改善すべき事
作成している中で改善すべき点は多くありました.
前処理
- 年齢(Age)はNaNを除いた事,NaNがある値の二つに分けて学習をすべきだった.
- ヒストグラムを見て,ガウス分布が左によっているようなものは対数をとってガウス分布に近づけるべきだった.(Courseraで Andrew先生もそう言ってました。)
- 値のホワイトニングをおこなってなかった.
- 大量に捨てた文字列の値を頑張って数値に変換すべきだった.特にCabinやTicketは捨てたくなかった.
分析
- 相関係数のみしかみていなかった.
分類機
- 値の正則化を行ってなかった
- 非線形SVMやその他の分類機を検討してなかった.
総括
短時間でアウトプットを出すことはできたので,目標は達成した.
しかし,少ない時間の中でいままで学んだことをすくに使い,最適な算出方法を出すには時間と経験がたりないことを深く認識した.