事業会社でデータサイエンティストをしているu++です。普段ははてなブログ1で、Kaggleや自然言語処理などデータ分析に関する記事を定期的に書いています。
Kaggleでは2019年に「PetFinder.my Adoption Prediction」2というコンペで優勝(チーム)し、「Santander Value Prediction Challenge」3というコンペで銀メダルを獲得(個人)しました。「Kaggle Master」と呼ばれる称号4を得ており、Kaggle内ランクは、約16万人中最高229位です5。
本記事では「Kaggleに登録したら次にやること」と題して、Kaggleに入門したい方に向けて次のようなコンテンツを掲載します。
- Kaggleの概要
- 環境構築不要な「Code(Notebook, Kernel)」の使い方
- 入門 10 Kernel
- まずはsubmit! 順位表に載ってみよう
- 全体像を把握! submitまでの処理の流れを見てみよう
- ここで差がつく! 仮説に基づいて新しい特徴量を作ってみよう
- 勾配ブースティングが最強?! いろいろな機械学習アルゴリズムを使ってみよう
- 機械学習アルゴリズムのお気持ち?! ハイパーパラメータを調整してみよう
- submitのその前に! 「Cross Validation」の大切さを知ろう
- 三人寄れば文殊の知恵! アンサンブルを体験しよう
- Titanicの先へ行く①! 複数テーブルを結合してみよう
- Titanicの先へ行く②! 画像データに触れてみよう
- Titanicの先へ行く③! テキストデータに触れてみよう
- メダルが獲得できる開催中のコンペティションに参加しよう
- さらなる学びのために
Kaggleの入門というと、チュートリアルとして用意されている「Titanic : Machine Learning from Disaster」6が有名です。本記事でも最初はTitanicを題材に話を進めます。しかし個人的には、メダルが獲得できる開催中のコンペティションに参加してこそ、歴戦の猛者たちと切磋琢磨することができ、学びや楽しみも大きいのではないかと感じています。
本記事を経て、少しでも多くの方が開催中のコンテストに参加してくださったら嬉しいです。なお本記事のタイトルは@drkenさんの競技プログラミング「AtCoder」入門記事7に倣いました。本記事執筆の背景はポエム要素を含むので、自身のはてなブログに掲載しました8。
Kaggleの概要
Kaggle9とは、主に機械学習モデルを構築するコンペティションのプラットフォームです。企業や研究機関などが提供するデータについて、世界中から集まる参加者が機械学習モデルの性能を競います。
下記の資料では、Kaggleとは何かが簡潔にまとめられています。最初にご覧いただくのがオススメです。
- 『PythonではじめるKaggleスタートブック』10
- Kaggleで描く成長戦略 〜個人編・組織編〜11
- Kaggleで変える日本の機械学習活用12
- 結局、Kagglerは何を必死にやっているのか?13
環境構築不要な「Code(Notebook, Kernel)」の使い方
Code(Notebook, Kernel)とは?
Kaggleには、Codeと呼ばれるブラウザ上の実行環境が用意されています。言語としては現在、Python3とRが対応しています。それぞれScript形式かNotebook形式を選択可能です。
Notebookには、機械学習モデルの構築に必要なさまざまなパッケージがあらかじめインストールされており、初心者がつまづきやすい環境構築が必要ありません。時間制限はありますが、GPUやTPUも使用可能です。一般的なノートパソコン以上の性能が自由に使える環境が整っています。
本記事では、このNotebookを用いたKaggle入門コンテンツを提供します。自分で手を動かしながらKaggleのエッセンスを学べるような10つのNotebookを用意しました。言語としてはPython3、形式はNotebookを選択します。
なおKaggleのCode環境は、以前「Kernel」「Notebook」などと呼ばれていました。以後の文中では「Code環境で作成できるNotebook」というように、実行環境(Code)と個別の実行ファイル(Notebook)という形で単語を使用します。タイトルや見出しなど一部の箇所では意図的にKernelやNotebookの表現を残している場合もあります。
Code環境の使い方
ここでは、Code環境の具体的な使い方を解説します。次の章にある「1. まずはsubmit! 順位表に載ってみよう」のリンクをクリックして、作業してみてください。
なお一連の操作動画をYouTubeに公開しています。適宜ご参照ください。
リンクを開いたら、まずは右上の「Copy and Edit」をクリックしてください。自分で編集できる画面に遷移します。Copy and EditしたNotebookは元のNotebookとは別物なので、自分の好き勝手に編集して問題ありません。
Notebookはいくつものセルに分割されています。セルには2種類あり、1つは説明文などを記述する「Markdown」、もう1つはPythonのコードを記述する「Code」です。次の図で言うと、上のセルがMarkdown、下のセルがCodeです。
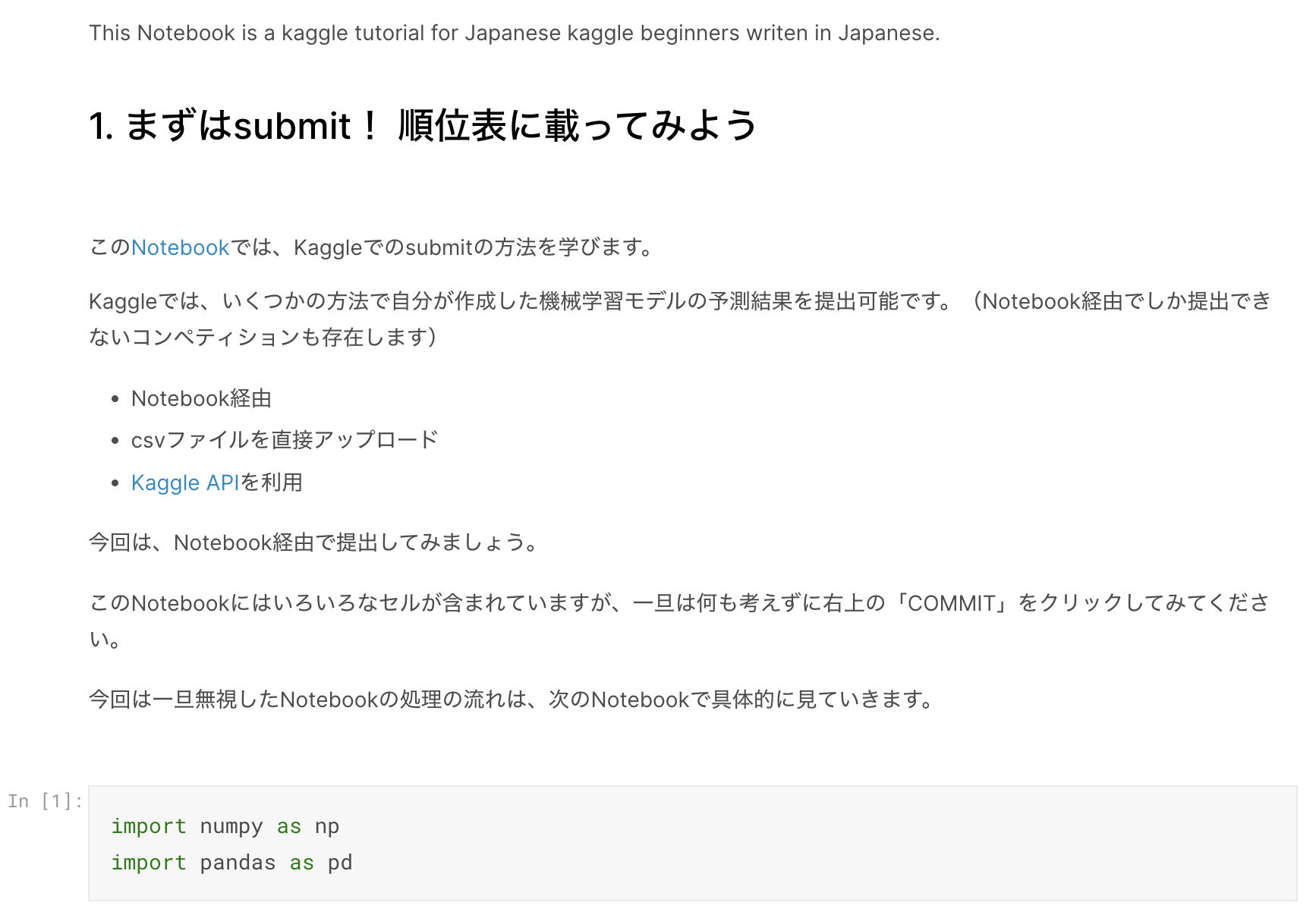
セルは自由に追加・削除ができます。新規追加は上の画像で出ている「+Code」「+Markdown」から、移動・削除はセルを選択した状態で出る右上のボタンから操作できます。
Codeセル内でSHIFT+ENTERすると、個々の単位でプログラムを実行できます。段階的にプログラムを処理できるので、個々のセルで何が起きているかが理解しやすいかと思います。
Notebookには「Public」「Private」という公開設定があります。私のNotebookは皆さんに使ってもらうために「Public」になっています。デフォルトは「Private」なので、意図的に操作しない限りは「Public」にはなりません。安心して自由に記述することが可能です。現在の公開設定は、保存後にアクセスできるNotebookページの「Settings」の「VISIBILITY」などから確認できます。
Notebookの操作方法やショートカットなどは、Jupyter Notebook14とほぼ同様です。さらなる便利な使い方の詳細が知りたい場合は「Jupyter Notebook 使い方」などで調べると良いでしょう。
入門 10 Kernel
ここでは、自分で手を動かしながらKaggleのエッセンスを学べるような10つのNotebookを掲載します。
本記事内では理論的な面を解説し、各テーマに対応するNotebookで実践していただく構成になっています。本記事を読むだけでも理解できるような構成にしていますが、ぜひNotebookを利用してご自身で操作してみてください。
1. まずはsubmit! 順位表に載ってみよう
このNotebookでは、Kaggleでの提出(submit)の方法を学びます。
Kaggleでは、いくつかの方法で自分が作成した機械学習モデルの予測結果を提出可能です(Notebook経由でしか提出できないコンペティションも存在します)。
- Notebook経由
- csvファイルを直接アップロード
- Kaggle API15を利用
今回は、Notebook経由で提出してみましょう。以降の一連の操作動画はYouTubeに公開しています。submitまでの流れを確認しながら操作してみてください。
無事にスコアが付くと、順位表に自分のアカウントが登場します。
このNotebookでは、Notebook経由で提出する方法を学びました。「Output」タブから「submission.csv」をダウンロードすることも可能なので、csvファイルを直接アップロードする方法も試してみてください。
なおKaggle APIを利用して提出する方法に興味があれば、こちらのブログ16などをご覧ください。
2. 全体像を把握! submitまでの処理の流れを見てみよう
このNotebookでは、前回は一旦無視したNotebookの処理の流れを具体的に見ていきます。ぜひ、実際に一番上からセルを実行しながら読み進めてみてください。
具体的な処理の流れは、次のようになっています。
- パッケージの読み込み
- データの読み込み
- 特徴量エンジニアリング
- 機械学習アルゴリズムの学習・予測
- 提出(submit)
パッケージの読み込み
import numpy as np
import pandas as pd
まずは、以降の処理で利用する「パッケージ」の読み込み(import)をします。パッケージを読み込むことで、標準では搭載されていない便利な機能を拡張して利用できます。
例えば次のセルで読み込む「numpy」17は数値計算に秀でたパッケージで、「pandas」18はTitanicのようなテーブル形式のデータを扱いやすいパッケージです。
パッケージの読み込みはどこで実施しても構いません(Script形式の場合は、冒頭が望ましいです)。
データの読み込み
ここでは、Kaggleから提供されたデータを読み込みます。
まずはどういうデータが用意されているかを確認しましょう。詳細はKaggleのコンペティションのページの「Data」タブに記載されています。
train = pd.read_csv('../input/titanic/train.csv')
test = pd.read_csv('../input/titanic/test.csv')
gender_submission = pd.read_csv('../input/titanic/gender_submission.csv')
- 「gender_submission.csv」は、提出のサンプルです。このファイルで提出ファイルの形式を確認できます。仮の予測として、女性のみが生存する(Survivedが1)という値が設定されています。
- 「train.csv」は機械学習の訓練用のデータです。これらのデータについてはTitanic号の乗客の性別・年齢などの属性情報と、その乗客に対応する生存したか否かの情報(Survived)が格納されています。
- 「test.csv」は、予測を実施するデータです。これらのデータについてはTitanic号の乗客の性別・年齢などの属性情報のみが格納されており、訓練用データの情報を基に予測値を算出することになります。
- 「train.csv」と比較すると、Survivedという列が存在しないと分かります。(この列があったら全て正解できてしまうので当然ですね)
これらは、Kaggleから提供された大元のデータです。
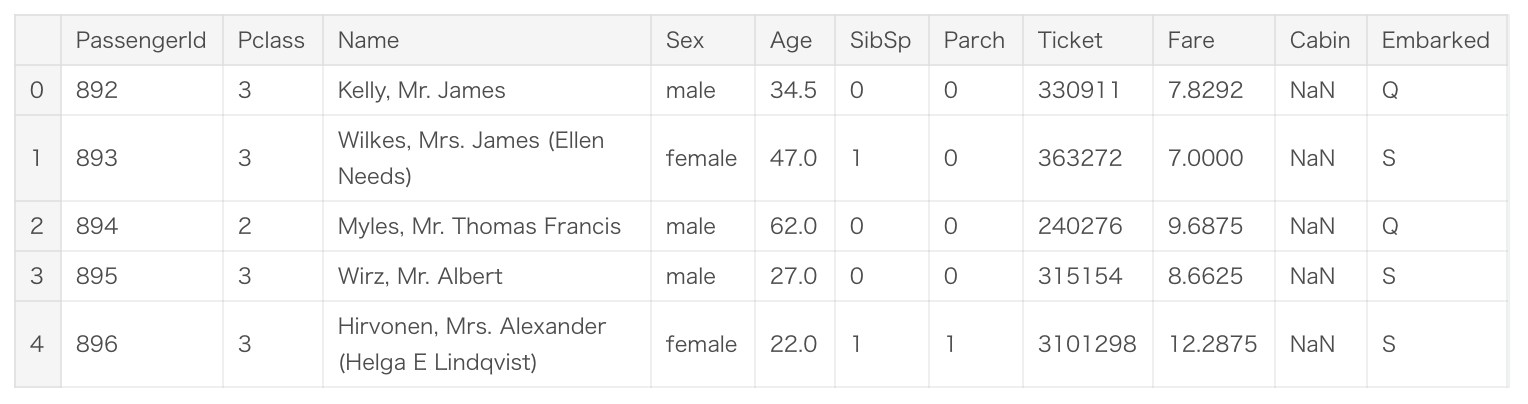
例えばNameやSexなどは文字列で格納されており、そのままでは機械学習アルゴリズムの入力にすることはできません。機械学習アルゴリズムが扱える数値の形式に変換していく必要があります。
NaNというのは、データの欠損です。こうした欠損値は、一部の機械学習アルゴリズムではそのまま扱うこともできますが、平均値や中央値など代表的な値で穴埋めする場合もあります。
特徴量エンジニアリング
次のような処理を「特徴量エンジニアリング」と呼びます。
- 読み込んだデータを機械学習アルゴリズムが扱える形に変換
- 既存のデータから、機械学習アルゴリズムが予測する上で有用な新しい特徴量を作成
前者について、例えばSexのmaleやfemaleをそれぞれ0と1に変換します。欠損を穴埋めする処理も行います。具体的な処理内容については、Notebookを参照ください。
後者については、次のNotebookで詳しく掘り下げていきます。
大元のデータから次のようなデータを作成するイメージになっています。

特徴量エンジニアリング後のデータを、より一般化して表現したのが、次の図です。
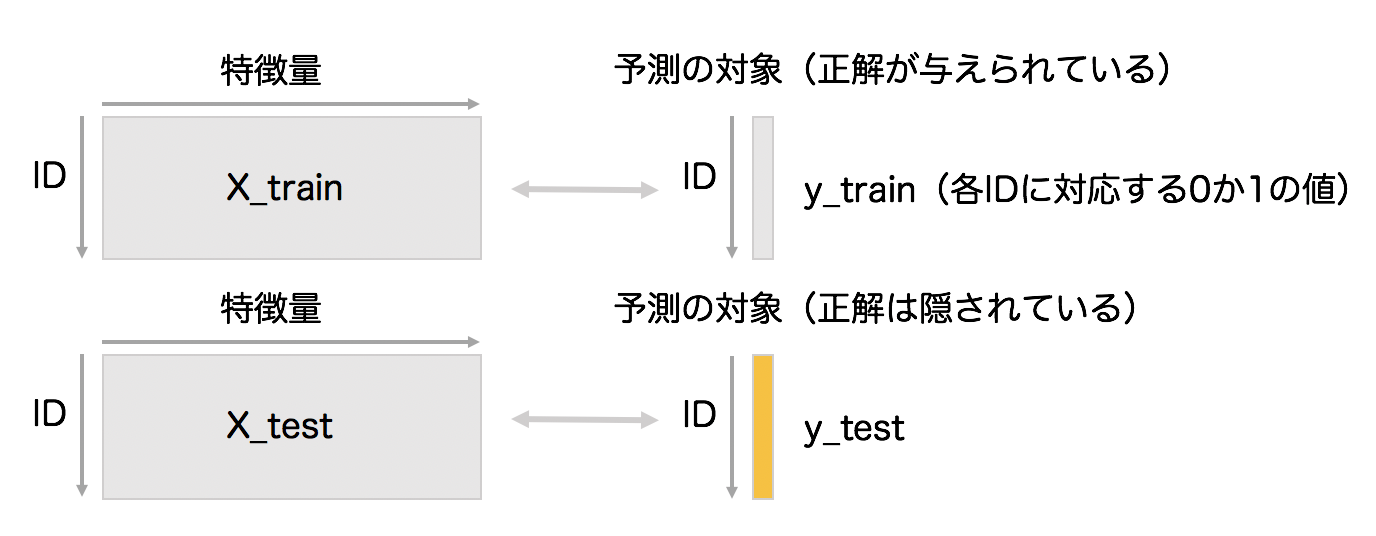
大元のデータから特徴量エンジニアリングを経て、X_train、y_train、X_testというデータの塊を作ります。大雑把に表現すると、X_trainとy_trainの対応関係を学習し、X_testに対応する(隠された)y_testの値を当てるという枠組みになっています。なおこのような仕組みを、機械学習の中でも特に「教師あり学習」と呼びます。
機械学習アルゴリズムの学習・予測
用意した特徴量と予測の対象のペアから、機械学習アルゴリズムを用いて予測器を学習させましょう。

from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(penalty='l2', solver='sag', random_state=0)
clf.fit(X_train, y_train)
ここでは「ロジスティック回帰」という機械学習アルゴリズムを利用します。
機械学習アルゴリズムの振る舞いはハイパーパラメータという値で制御されます。LogisticRegression の括弧内の値が該当します。ハイパーパラメータの調整方法については「5. 機械学習アルゴリズムのお気持ち?! ハイパーパラメータを調整してみよう」で詳しくみていきます。
学習を終えると、予測値が未知の特徴量(X_test)を与えて予測させることができます。
y_pred = clf.predict(X_test)
y_predには0か1の予測値が格納されています。
提出(submit)
最後に、Notebook経由で提出するために予測値を提出ファイルの形式に整えます。
sub = pd.DataFrame(pd.read_csv('../input/titanic/test.csv')['PassengerId'])
sub['Survived'] = list(map(int, y_pred))
sub.to_csv('submission.csv', index=False)
Kaggleの運営側はy_testの中身を把握しているので、y_testとy_predが比較され、自分の提出した予測値の性能がスコアとして返ってくる仕組みになっています。
このNotebookでは、提出に向けたKaggleでの処理の流れを追いました。
3. ここで差がつく! 仮説に基づいて新しい特徴量を作ってみよう
1つ目のNotebookでは、Code環境を用いてKaggleのコンペティションに提出して順位表に載る方法、2つ目のNotebookでは全体の処理の流れを解説しました。
3〜7つ目のNotebookでは、既存のNotebookに手を加えていきながら、スコアを上げていく方法を学んでいきます。ここで紹介する方法は、メダルが獲得できる開催中のコンペティションにも、ある程度は汎用的に使えるものだと思っています。「このような方法でスコアを上げているんだな〜」と知り、自分でコンペティションに参加していく際の道標になればと考えています。
このNotebookでは、特徴量エンジニアリングの部分で、スコアの向上を体験してみましょう。
さっそく特徴量エンジニアリングの解説を始めようかと思いますが、その前に前提的な話として、Kaggleに取り組む上で欠かせない「再現性」の話をします。
再現性の大切さ
「再現性がある」とは、何度実行しても同じ結果が得られることです。Kaggleで言うと、同一のスコアが得られると言い換えても良いでしょう。
再現性がないと、実行ごとに異なるスコアが得られてしまいます。今後、特徴量エンジニアリングなどでスコアの向上を試みても、予測モデルが改善されたか否かを正しく判断できなくなる問題が生じます。
実は、2つ目のNotebookには再現性がありません。その原因は、Ageという特徴量の欠損値を埋める際の乱数です。ここでは平均と標準偏差を考慮した乱数で欠損値を穴埋めしているのですが、この乱数は実行ごとに値が変わるようになってしまっています。
age_avg = data['Age'].mean()
age_std = data['Age'].std()
data['Age'].fillna(np.random.randint(age_avg - age_std, age_avg + age_std), inplace=True)
再現性を確保するためには、例えば次のような方法が考えられます。
- そもそも乱数を用いる部分を削除する
- 乱数のseedを与えて実行結果を固定する
Ageについては、そもそも乱数を用いるよりも、欠損していないデータの中央値を与えた方が筋の良い補完ができそうです。今回は中央値で補完するようにコードを改変します。
data['Age'].fillna(data['Age'].median(), inplace=True)
機械学習アルゴリズムの大半は乱数を利用するので、再現性を担保するためにはseedを設定しておかなければなりません。2つ目のNotebookを振り返ると、機械学習アルゴリズムのロジスティック回帰のハイパーパラメータとしてrandom_state=0を与え、seedを固定していました。seedは乱数生成のアルゴリズムの振る舞いを決める値です。
clf = LogisticRegression(penalty='l2', solver='sag', random_state=0)
このようにKaggleを進めていく際には、きちんと再現性が取れていることを随時確認していきましょう。なお、GPUを利用する場合など、どうしても再現性が担保できない場合もあります。またseedを固定して比較しても、あくまでそのseedの条件下での結果に過ぎない点には注意が必要です。seedを変えると異なる結果が得られる可能性もあります。
参考までに、KaggleのNotebookでは以下のように全ての乱数のseedを固定する関数が使われることもあります19。
def seed_everything(seed=1234):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
仮説から新しい特徴量を作る
ここでは、仮説と可視化から新しい特徴量を作る過程についてまとめます20。予測精度に寄与する新しい特徴量を作成するに当たっては、仮説と可視化を繰り返すサイクルが大切だと思っています。
- 予測精度に寄与しそうな仮説を立てる
- 可視化を実施する
- 予測精度に寄与する仮説を見つけるため
- 仮説が正しいかを検証するため
個々人や問題によって、どちらが起点になるかが変わってきます。
ケース1)ドメイン知識がある場合
例えば自分が詳しい、つまりドメイン知識を持っている分野の問題に取り組む場合、最初から仮説がいくつかあると思います。その場合は仮説を検証するような可視化を実施し、本当に予測精度に寄与するかを確認します。その可視化の結果によっては、改めて仮説を立てることになるかもしれません。
ケース2)ドメイン知識がない場合
ドメイン知識がない場合は、まずは仮説を立てるための探索的なデータ分析を実施することになるでしょう。いろいろな軸でデータを眺め、予測精度に寄与しそうな仮説を立てるのが目的になります。
ここでは、実際に新しい特徴量を作っていきましょう。例として探索的なデータ分析を実施した結果、ぼんやりと「一緒に乗船した家族の人数が多い方が、生存率が低そうだ」という仮説が得られた状況を考えます。
仮説が得られたので、次はこの仮説を検証するための可視化に移ります。FamilySizeという新しい行を作り、その大きさごとに生存したか否かを棒グラフにしました。
- Survived == 0: 死亡
- Survived == 1: 生存
import seaborn as sns
data['FamilySize'] = data['Parch'] + data['SibSp'] + 1
train['FamilySize'] = data['FamilySize'][:len(train)]
test['FamilySize'] = data['FamilySize'][len(train):]
sns.countplot(x='FamilySize', data=train, hue='Survived')
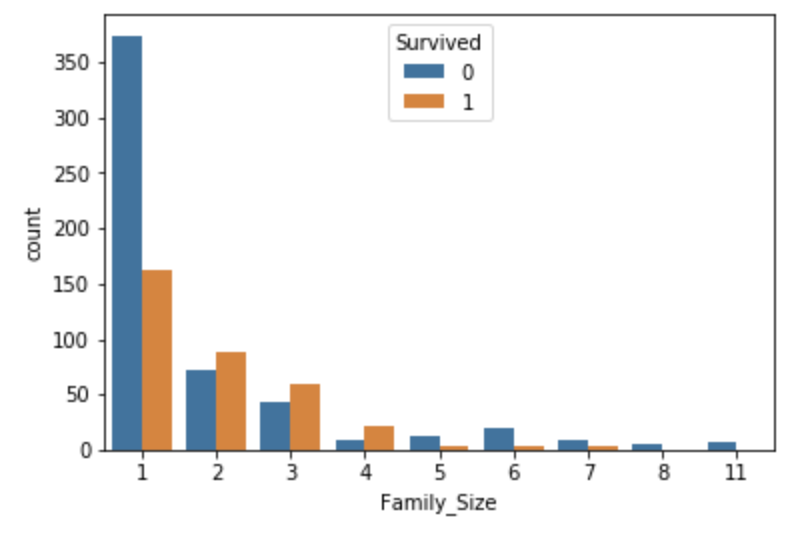
ここでFamilySizeが5以上の場合、死亡が生存を上回っており、生存率が低いことが分かります。
「一緒に乗船した家族の人数が多い方が、生存率が低そうだ」という(ぼんやりとした)仮説が、可視化を通じて「FamilySizeが5以上の場合、生存率が低いので、この特徴量は予測精度に寄与しそうだ」という確信を持った仮説に変わりました。
今回のFamilySizeのように仮説に基づいたいろいろな集計軸で分析をして可視化してみて、予測精度に寄与しそうな集計軸か否かを確認するというのは、有効なアプローチだと思います。
更に今回、可視化を通じて、それまで持っていなかった仮説(情報)を得ることもできました。
FamilySizeが1の人が圧倒的に多く、かつ生存率が低いということです。
このFamilySizeが1であるという特徴量も予測精度に寄与しそうなので、下記のように新しくIsAloneという特徴量を作成しました。
data['IsAlone'] = 0
data.loc[data['FamilySize'] == 1, 'IsAlone'] = 1
train['IsAlone'] = data['IsAlone'][:len(train)]
test['IsAlone'] = data['IsAlone'][len(train):]
このように仮説と可視化を繰り返すことで、既存のデータから機械学習アルゴリズムが予測する上で有用な新しい特徴量を探索していきましょう。
作成した特徴量が「有用」だったかを判断するには、例えば次の4パターンで学習した結果を提出する方法があります。提出した際のスコアを見ることで、特徴量の有用性をある程度確認可能です。
-
FamilySizeとIsAloneを加えた場合 -
FamilySizeのみを加えた場合 -
IsAloneのみを加えた場合 -
FamilySizeとIsAloneを加えていない場合
ここで「ある程度」としている理由については「6. submitのその前に! 「Cross Validation」の大切さを知ろう」で学びます。
特徴量エンジニアリングの技法を学ぶ
特徴量エンジニアリングを実施していく中で、一般にどのようなやり方があり得るのかの技法を学んでおくことは重要です。Kaggleにおける特徴量エンジニアリングについての個人的な所感については、以前にブログ記事21を書いています。
- 日本語の書籍としては『機械学習のための特徴量エンジニアリング』22があります。
- スライドでは「最近のKaggleに学ぶテーブルデータの特徴量エンジニアリング」23が詳しいです。
- 特徴量エンジニアリング以外の記述も豊富なブログ記事としては「【随時更新】Kaggleテーブルデータコンペできっと役立つTipsまとめ」24があります。
4. 勾配ブースティングが最強?! いろいろな機械学習アルゴリズムを使ってみよう
これまでは機械学習アルゴリズムとして、ロジスティック回帰を採用していました。
このNotebookでは、いろいろな機械学習アルゴリズムを使ってみましょう。これまでロジスティック回帰を使っていた部分を差し替えて学習・予測を実行してみたいと思います。
ロジスティック回帰の実装に利用していたsklearnというパッケージは入出力のインタフェースが統一されており、手軽に機械学習アルゴリズムを変更できます。実際にいくつか試してみましょう。
また最近のKaggleのコンペティションで上位陣が利用している機械学習アルゴリズムとしては、勾配ブースティングやニューラルネットワークが挙げられます。これらはロジスティック回帰に比べて表現力が高く、高性能に予測できる可能性を秘めています。特に上位陣での採用率が高いのは「LightGBM」25という勾配ブースティングのパッケージです。sklearnと同様のインターフェイスも用意されていますが、ここではPython-package Introduction26に記載の方式で実装します。
sklearn
まずはsklearn内で機械学習アルゴリズムを変更していきましょう。これまではロジスティック回帰を使ってきました。
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression(penalty='l2', solver='sag', random_state=0)
sklearnでは、clfで宣言するモデルを切り替えるだけで機械学習アルゴリズムを差し替えられます。例えば、ランダムフォレスト27と呼ばれる機械学習アルゴリズムを使ってみましょう。
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(n_estimators=100, max_depth=2, random_state=0)
あとはロジスティック回帰の場合と同様に学習・予測が実行可能です。
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
ランダムフォレストでの予測結果を提出してみると、私の環境では0.77990というロジスティック回帰の時よりも格段に良いスコアが出ました。

sklearnには非常に多くの種類の機械学習アルゴリズムが実装されている28ので、ぜひいろいろな機械学習アルゴリズムを試してみてください。
LightGBM
続いて、LightGBMを使います。sklearnとの差異もあり、いくつか下準備が必要です。
- 学習用・検証用にデータセットを分割する
- カテゴリ変数をリスト形式で宣言する
LightGBMは大量の決定木を作成しながら学習を進めます。そのため、学習に利用したデータセットなどにのみ過剰に適合してしまい、本来の目的である未知の値に対する性能が劣化してしまう「過学習」という現象に陥りがちです。そこで学習に利用しない検証用のデータに対する性能を見ながら学習を打ち切る「early stopping」を利用するのが一般的となっています。
ここでは、X_trainをX_train(学習用)とX_valid(検証用)に分割します。
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.3, random_state=0, stratify=y_train)
LightGBMでは、カテゴリ変数に対して特別な処理29を自動的に実行してくれます。次のように、何をカテゴリ変数として扱ってほしいか明示的にLightGBMに教えてあげましょう。
categorical_features = ['Embarked', 'Pclass', 'Sex']
下準備も終わったところで、LightGBMで学習・予測を実施します。
import lightgbm as lgb
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid, reference=lgb_train, categorical_feature=categorical_features)
params = {
'objective': 'binary'
}
model = lgb.train(
params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
callbacks=[lgb.early_stopping(10)]
)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
次のような実行ログと共に、学習が進行します。
Training until validation scores don't improve for 10 rounds.
[10] training's binary_logloss: 0.425241 valid_1's binary_logloss: 0.478975
[20] training's binary_logloss: 0.344972 valid_1's binary_logloss: 0.444039
[30] training's binary_logloss: 0.301357 valid_1's binary_logloss: 0.436304
[40] training's binary_logloss: 0.265535 valid_1's binary_logloss: 0.438139
Early stopping, best iteration is:
[38] training's binary_logloss: 0.271328 valid_1's binary_logloss: 0.435633
y_pred[:10]
array([0.0320592 , 0.34308916, 0.09903007, 0.05723199, 0.39919906,
0.22299318, 0.55036246, 0.0908458 , 0.78109016, 0.01881392])
今回のLightGBMの設定では、出力結果は1になる予測値になります。今回はしきい値を決め打って、0.5を上回っていれば1と予測したと見なして、提出してみます。
y_pred = (y_pred > 0.5).astype(int)
y_pred[:10]
array([0, 0, 0, 0, 0, 0, 1, 0, 1, 0])
LightGBMでの予測結果を提出してみると、私の環境では0.75598というスコアが出ました。ランダムフォレスト同様、ロジスティック回帰の時のスコアよりも向上しているのが分かります。
このように利用する機械学習アルゴリズム次第で、Kaggleのスコアを向上させることが可能です。
その他
勾配ブースティング系では今回紹介したLightGBM以外に、数年前から人気の根強い「XGBoost」30や、徐々に頭角を現している「CatBoost」31などがあります。
「PyTorch」32「TensorFlow」33などのパッケージを用いてニューラルネットワークを実装する場合もあります(TensorFlowを用いた例:①MLP②1DCNN)。「TabNet」のような、テーブル形式のデータ向けのニューラルネットワークを実装したモデルも登場しています。
5. 機械学習アルゴリズムのお気持ち?! ハイパーパラメータを調整してみよう
先にも説明したように、機械学習アルゴリズムの振る舞いはハイパーパラメータという値で制御されます。もちろん、ハイパーパラメータの値次第で予測結果は変わり得ます。
ハイパーパラメータの調整は、主に2種類の方法があります。
- 手動で調整
- チューニングツールを使う
後者としては、Grid search34, Hyperopt35, Optuna36など、いくつかのツールがあります。
このNotebookでは、最初に手動でハイパーパラメータを調整し、機械学習アルゴリズムの振る舞いが異なることを確認します。その後、Optunaを用いたチューニングを実施します。
最近のKaggleのコンペティションでは、データサイズが大きいため上記のツールでのハイパーパラメータ調整が現実的な時間で終わらない問題もあります。また一般に、ハイパーパラメータでのスコアの上がり幅は特徴量エンジニアリングで良い特徴量を見つけた場合に劣るので、あまり時間をかけずに手動で微調整をする場合も多いです。
手動で調整
ここでは、LightGBMの精度の向上を試みます。これまではobjectiveのみを指定していました。明示的に指定しない場合は、defaultの値37が自動的に定義されます。
params = {
'objective': 'binary'
}
公式documentationの「Parameters Tuning」38に従って、手動で調整を行っていきましょう。いくつかのユースケース別に、ハイパーパラメータ調整のTipsが記載されています。
今回は、精度を高めるのが目的なので「For Better Accuracy」39を参照します。
- Use large max_bin (may be slower)
- Use small learning_rate with large num_iterations
- Use large num_leaves (may cause over-fitting)
- Use bigger training data
- Try dart
- 1つ目は「大きめの
max_binを使え」です。defaultの値は255なので、ここでは300にしてみます。 - 2つ目は「小さめの
learning_rateを使え」です。defaultの値は0.1なので、ここでは0.05にしてみます。 - 3つ目は「大きめの
num_leavesを使え」です。defaultの値は31なので、ここでは40にしてみます。
手動で調整するにせよ、チューニングツールを使うにせよ、機械学習アルゴリズムをブラックボックス的に利用するのではなく、ハイパーパラメータを正しく理解することが非常に大切です。
ハイパーパラメータの説明については、英語ですが公式のdocumentation40で確認するのが確実です。
日本語の記事だと、例えば「勾配ブースティングで大事なパラメータの気持ち」41に、LightGBMなどの勾配ブースティングの主要なハイパーパラメータ解説が記載されています。LightGBMのコミッタの大元さんの発表資料42も、開発者の視点でハイパーパラメータの方法が紹介されており参考になります。
params = {
'objective': 'binary',
'max_bin': 300,
'learning_rate': 0.05,
'num_leaves': 40
}
lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid,
reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train, valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
Training until validation scores don't improve for 10 rounds.
[10] training's binary_logloss: 0.505699 valid_1's binary_logloss: 0.532106
[20] training's binary_logloss: 0.427825 valid_1's binary_logloss: 0.482279
[30] training's binary_logloss: 0.377242 valid_1's binary_logloss: 0.456641
[40] training's binary_logloss: 0.345424 valid_1's binary_logloss: 0.447083
[50] training's binary_logloss: 0.323113 valid_1's binary_logloss: 0.440407
[60] training's binary_logloss: 0.302727 valid_1's binary_logloss: 0.434527
[70] training's binary_logloss: 0.285597 valid_1's binary_logloss: 0.434932
Early stopping, best iteration is:
[66] training's binary_logloss: 0.293072 valid_1's binary_logloss: 0.433251
y_predはハイパーパラメータ変更前と異なる値を取ります。出力ログにも変化があり、最終的なvalid_1's binary_loglossが 0.433251 と、変更前よりも小さい値になっています。binary_loglossは損失なので、小さい方が望ましいです。
LightGBMでの予測結果を提出してみると、私の環境では0.77033というスコアが出ました。ハイパーパラメータ変更前の0.75598に比べて、スコアが向上しています。

Optunaを使う
ここまで手動でハイパーパラメータを調整してきましたが、次のような感情が芽生えている方もいるのではないでしょうか。
- 「大きめ」「小さめ」といっても、具体的にどの値にすればよいのか分からない
- 各パラメータの組み合わせ方もいくつかあり、逐一設定・実行して性能を検証するのは煩わしい
そのような課題を解決してくれるのが、ハイパーパラメータのチューニングツールです。今回はOptunaを使っていきます。
Optunaを使うに当たっては、あらかじめ次の関数のtrial.suggest_int()のように、探索範囲を定義します。
ここでは、意図的にlearning_rateの調整を実施していません。テーブルデータをLightGBMで扱う場合、一般にlearning_rateが低いほど高い性能が得られるためです。そのため探索範囲には含めず、必要であれば後に手動で低い値に変更することにします。
import optuna
from sklearn.metrics import log_loss
def objective(trial):
params = {
'objective': 'binary',
'max_bin': trial.suggest_int('max_bin', 255, 500),
'learning_rate': 0.05,
'num_leaves': trial.suggest_int('num_leaves', 32, 128),
}
lgb_train = lgb.Dataset(X_train, y_train,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_valid, y_valid,
reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
y_pred_valid = model.predict(X_valid, num_iteration=model.best_iteration)
score = log_loss(y_valid, y_pred_valid)
return score
n_trialsは試行回数です。ここでは計算を短くするため、40回程度にしておきます。乱数も固定しておきます。
study = optuna.create_study(sampler=optuna.samplers.RandomSampler(seed=0))
study.optimize(objective, n_trials=40)
study.best_params
{'max_bin': 427, 'num_leaves': 79}
指定した範囲内で試行回数だけ探索した結果得られた最良のハイパーパラメータが表示されています。こちらで改めて予測し直して、提出してみると、私の環境では0.77033というスコアが出ました。偶然手動での調整と同じスコアになっています。探索範囲や試行回数を変えれば、より良いスコアが出るかもしれません。

6. submitのその前に! 「Cross Validation」の大切さを知ろう
3〜5つ目のNotebookでは、特徴量エンジニアリング・機械学習アルゴリズム・ハイパーパラメータの面で、スコアを上げていく方法を学びました。
このNotebookでは、機械学習モデルの性能を見積もる「validation」について解説します。
提出時のスコアで検証してはいけないのか?
これまではモデルの性能について、主に実際にKaggleに提出した際のスコアで確認していました。しかし、この方法には次のような問題点があります43。
- 提出回数に制限がある
- public LBで良いスコアが出ても、一部のデータのみに過学習した結果の可能性がある
Kaggleのコンペティションには1日の提出回数に制限があり、スコアが上がる保証もないのに気軽に提出するのは得策ではありません。1日の提出回数分しか試行錯誤ができない状況にも陥ってしまいます。
またメダルが獲得できるコンペティションでは、y_testの一部データのみがpublic LBに利用されておりスコアを随時確認できますが、最終順位は残りのprivate LBのデータに対する性能で決定します。

public LBで良いスコアが出ても、public LBのデータのみに過学習した結果の可能性があり、必ずしもprivate LBでの性能に寄与するかは分かりません。
public LBにどのようなデータが使われているか分からないという問題もあります。極端な例ですが、Titanicのような二値分類の問題で0のラベルが付いたデータのみがpublic LBに使われている可能性を考えましょう。この場合、仮にpublic LBで高いスコアを出すモデルが作成できても、そのモデルは1のラベルを当てる性能がどれだけあるか確認できていません。
以上の問題を踏まえて、Kaggleではvalidationスコアを通じて自分のモデルの性能を測るのが一般的です。ここでのvalidationは「モデルの汎化性能の検証」を意味します。汎化性能とは「未知のデータに対する性能」のことです。「過学習をしていないかの確認」というような意味合いでもあります。
ホールドアウト検証
実は既に、LightGBMを利用する段階で「ホールドアウト検証」と呼ばれる一種のvalidationを実施していました。次の図のように、学習用データセットを分割した上でLightGBMを学習させていたことを思い出してください。

この検証用データセットは、自分で学習用データセットから切り出しているため、目的変数を含めて全容を把握できています。全体像の見えていないpublic LBのスコアに比べて、信頼性の高いスコアを得られる可能性を秘めています。
検証用データセットに対する性能、すなわちvalidationスコアは、提出することなく手元で確認可能です。自分の気の済むだけ試行錯誤を回し、良いスコアを得た場合に実際にKaggleに提出するような運用が可能です。
交差検証(Cross Validation)
さて、ここで「Cross Validation」を実行すると、ホールドアウト検証の例よりも、更に汎用的に性能を確認できます。交差検証(Cross Validation)とは、次の図のように複数回に(図では3回)わたって異なる方法でデータセットを分割し、それぞれでホールドアウト検証を実行する方法です。そのスコアの平均を確認することで、1回のホールドアウト検証で生じうる偏りに対する懸念を弱めることができます。
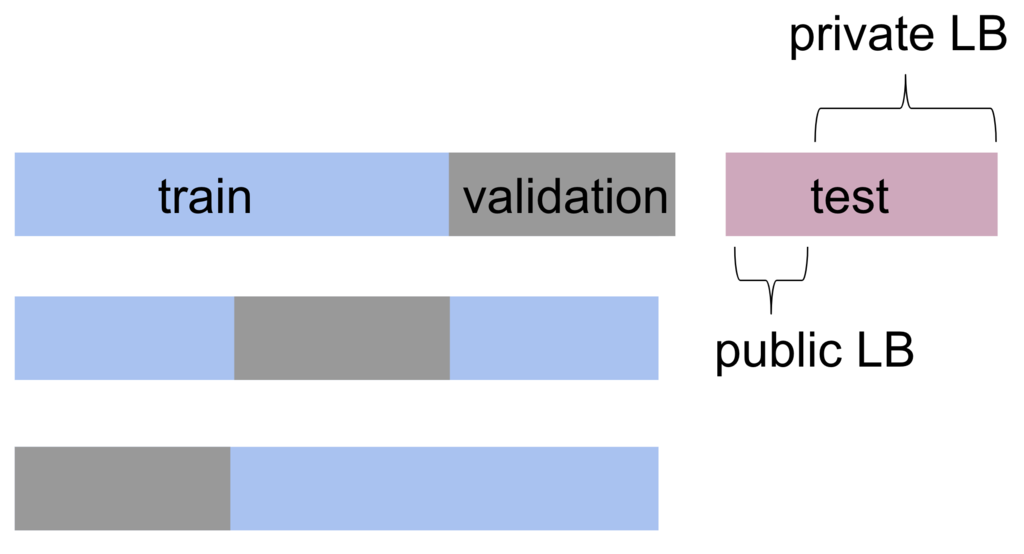
train_test_split を複数回書いて実装することもできそうですが、より便利なパッケージが用意されています。n_splitsは分割数で、ここではデータセットを5つに分けます。
from sklearn.model_selection import KFold
kf = KFold(n_splits=5, shuffle=True, random_state=0)
コードの全容は以下に示します。
from sklearn.model_selection import KFold
y_preds = []
models = []
oof_train = np.zeros((len(X_train),))
cv = KFold(n_splits=5, shuffle=True, random_state=0)
categorical_features = ['Embarked', 'Pclass', 'Sex']
params = {
'objective': 'binary',
'max_bin': 300,
'learning_rate': 0.05,
'num_leaves': 40
}
for fold_id, (train_index, valid_index) in enumerate(cv.split(X_train)):
X_tr = X_train.loc[train_index, :]
X_val = X_train.loc[valid_index, :]
y_tr = y_train[train_index]
y_val = y_train[valid_index]
lgb_train = lgb.Dataset(X_tr, y_tr,
categorical_feature=categorical_features)
lgb_eval = lgb.Dataset(X_val, y_val,
reference=lgb_train,
categorical_feature=categorical_features)
model = lgb.train(params, lgb_train,
valid_sets=[lgb_train, lgb_eval],
verbose_eval=10,
num_boost_round=1000,
early_stopping_rounds=10)
oof_train[valid_index] = model.predict(X_val, num_iteration=model.best_iteration)
y_pred = model.predict(X_test, num_iteration=model.best_iteration)
y_preds.append(y_pred)
models.append(model)
Cross Validationを実施した際は、全体の平均をvalidationスコアと見なすことが多いです。このスコアのことを「CVスコア」、省略して単に「CV」とも呼びます。
scores = [
m.best_score['valid_1']['binary_logloss'] for m in models
]
score = sum(scores) / len(scores)
print('===CV scores===')
print(scores)
print(score)
===CV scores===
[0.3691161193267495, 0.4491122965802196, 0.3833384988458873, 0.43712149656630833, 0.43469994547894103]
0.41467767135962114
Cross Validationには、学習用データセットを無駄にしないという利点もあります。1回のみのホールドアウト検証では検証用データセットに該当する部分を学習に利用できていないですが、Cross Validationでは複数の分割を実施するので、全体としては与えられたデータセットをもれなく学習に利用できています。
この予測値を提出すると、私の環境で0.76555というスコアが出ました。ホールドアウト検証の時よりも悪いスコアになってしまいました。その原因の一つは、データセットの分割方法だと推察されます。最後に、この部分を掘り下げて解説していきます。

データセットの分割方法
データセットの分割に当たっては、データセットや課題設定の特徴を意識するのが大切です。
ここまで使っていたKFoldは、特にデータセットや課題設定の特徴を考慮することなくデータセットを分割します。例えば、学習用・検証用データセット内のy==1の割合を見てみると次のようになりました。fold: 2, 4などで顕著に割合が異なっていると分かります。
from sklearn.model_selection import KFold
cv = KFold(n_splits=5, shuffle=True, random_state=0)
for fold_id, (train_index, valid_index) in enumerate(cv.split(X_train)):
X_tr = X_train.loc[train_index, :]
X_val = X_train.loc[valid_index, :]
y_tr = y_train[train_index]
y_val = y_train[valid_index]
print(f'fold: {fold_id}')
print(f'y_tr y==1 rate: {sum(y_tr)/len(y_tr)}')
print(f'y_val y==1 rate: {sum(y_val)/len(y_val)}')
fold: 0
y_tr y==1 rate: 0.38342696629213485
y_val y==1 rate: 0.3854748603351955
fold: 1
y_tr y==1 rate: 0.3856942496493689
y_val y==1 rate: 0.37640449438202245
fold: 2
y_tr y==1 rate: 0.39831697054698456
y_val y==1 rate: 0.3258426966292135
fold: 3
y_tr y==1 rate: 0.3856942496493689
y_val y==1 rate: 0.37640449438202245
fold: 4
y_tr y==1 rate: 0.36605890603085556
y_val y==1 rate: 0.4550561797752809
繰り返しになりますが、Kaggleの目的は未知のデータセットであるLBに対する性能を高めることです。未知のデータセットにおけるy==1の割合は誰にも正確には分からないですが、既存のデータセットである学習用データセットと同様の割合だと近似するのが一般的です。つまり、データセットはy==1の割合を保つように分割するのが理想的です。
y==1の割合が均等でない場合、y==1を重要視したり逆に軽視したりと、機械学習アルゴリズムの学習がうまくいかない傾向にあります。このような状況では適切に特徴を学習できず、未知のデータセットに対する性能が劣化してしまう可能性があります。KFoldを用いた場合にスコアが悪化した原因もここにあると考えられます。
ちなみに以前にtrain_test_splitを利用した際には、stratifyという引数でy_trainを指定することで、割合を保ったままデータセットを2つに分割していました。
from sklearn.model_selection import train_test_split
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.3, random_state=0, stratify=y_train)
割合を保ったままCross Validationを実施するためにはStratifiedKFoldを使います。学習用・検証用データセット内のy==1の割合が可能な範囲で均一に保たれています。
from sklearn.model_selection import StratifiedKFold
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
for fold_id, (train_index, valid_index) in enumerate(cv.split(X_train, y_train)):
X_tr = X_train.loc[train_index, :]
X_val = X_train.loc[valid_index, :]
y_tr = y_train[train_index]
y_val = y_train[valid_index]
print(f'fold: {fold_id}')
print(f'y_tr y==1 rate: {sum(y_tr)/len(y_tr)}')
print(f'y_val y==1 rate: {sum(y_val)/len(y_val)}')
fold: 0
y_tr y==1 rate: 0.38342696629213485
y_val y==1 rate: 0.3854748603351955
fold: 1
y_tr y==1 rate: 0.38342696629213485
y_val y==1 rate: 0.3854748603351955
fold: 2
y_tr y==1 rate: 0.38429172510518933
y_val y==1 rate: 0.38202247191011235
fold: 3
y_tr y==1 rate: 0.38429172510518933
y_val y==1 rate: 0.38202247191011235
fold: 4
y_tr y==1 rate: 0.38375350140056025
y_val y==1 rate: 0.384180790960452
この分割を用いて学習・予測を実行したところ、私の環境で0.77511というスコアが出ました。KFoldの時よりも、ホールドアウト検証の時よりも良いスコアが出ています。

分割の際に気を付けたいことは、目的変数の割合以外にも、以下のような点があります。
- データセット内に時系列性がないか
- データセット内にグループが存在しないか
詳細は「validationの切り方いろいろ(sklearnの関数まとめ)」44に譲りますが、前者については時系列性を意識したデータセットの分割が必要です。ここでの未知のデータセットとは時系列的に未来のデータが該当します。つまりは、学習に使うデータセットが検証用・評価用のデータセットよりも過去になるような分割が望ましいです。
後者の場合は、同一のグループ内の場合は予測が比較的容易である点に注意しましょう。仮に未知のデータセットには既存のデータセットと同一のグループが存在しないと予想される場合、データセットの分割の際にも同一のグループが分割されないように気を付ける必要があります。
7. 三人寄れば文殊の知恵! アンサンブルを体験しよう
ここでは、機械学習における「アンサンブル」について解説します。アンサンブルとは、複数の機械学習モデルを組み合わせることで精度の高い予測値を獲得する手法です。
アンサンブルはKaggleなどのコンペにおける最後の一押しとして、大きな成果を発揮する場合があります。近年は多くのチームで、取り組みの深さは違えど至極当然に用いられる手法になっている印象です。
時には「実際の業務には役に立たない」と批判される対象にもなるものですが、個人的には「良くも悪くも機械学習コンペの特徴」と言えるものの一つだと思っています。
最初に、簡単な例を通じてアンサンブルの考え方を学びましょう。次いで、このNotebookの中で、実際にアンサンブルの効果を確認します。
三人寄れば文殊の知恵
アンサンブルについては「Kaggle Ensembling Guide」45と呼ばれる有名な記事が存在します。ここでは「Kaggle Ensembling Guide」の冒頭からの具体例を引用して、アンサンブルの考え方を学びましょう。
10個のyに対して、0か1の二値分類を考えます。
つまりは
(y_0, y_1, ... , y_9)=(0, 1, ... , 0)
のような予想をする問題です。簡単のため、以後は右辺の括弧内だけを取り出して次のように表現したいと思います。次の例は $y_4$ と$y_9$ のみを1と予想した」という意味です。
0000100001
さて、ここで正解が全て1であるような問題を考えます。
1111111111
この問題に対して、モデルA・B・Cがそれぞれ次のような予測をしたとしましょう。
モデルA = 80% accuracy
1111111100
モデルB = 70% accuracy
0111011101
モデルC = 60% accuracy
1000101111
単純に一番良いモデルを選んだ場合、モデルAを採用すれば80%の正解率を得られる状況です。しかし、ここでアンサンブルを使うと80%以上の正解率を出すモデルを得ることができます。
今回使うアンサンブルは、非常に単純な「多数決」の技法です。 $y_0, y_1, ... , y_9$ のそれぞれで各モデルの予測を確認し、多数決で最終的な予測結果を導出します。
例えば $y_0$ について、モデルAとモデルCは1を、モデルBは0を予測しています。そのため、最終的な予測結果は1とします。
同様に考えていくと、下記が最終的な予測結果です。
最終的な予測結果 = 90% accuracy
1111111101
なんと、基にした全てのモデルよりも高い正解率を得ることができました。
数式的な説明は「Kaggle Ensembling Guide」に記載があるので割愛しますが、それぞれのモデルの良い部分・悪い部分を補完し合い、全体として良い予測結果が得られています。
Titanicでの実験
このNotebookでは、これまで作ってきたNotebookの延長線上で実際にアンサンブルの効果を確認します。
ここでは「提出ファイルによるアンサンブル」を試してみましょう。これまで作成したランダムフォレストとLightGBMによる提出ファイルを利用します。
それぞれ提出スコアは、0.77511、0.77033、0.77990です。
import pandas as pd
sub_lgbm_sk = pd.read_csv('../input/submit-files/submission_lightgbm_skfold.csv')
sub_lgbm_ho = pd.read_csv('../input/submit-files/submission_lightgbm_holdout.csv')
sub_rf = pd.read_csv('../input/submit-files/submission_randomforest.csv')
「Kaggle Ensembling Guide」と同様に、多数決で予測値を決定します。3ファイルの予測値部分を合計し、合計が2以上の場合は全体としての予測値を1とします。
sub = pd.DataFrame(pd.read_csv('../input/titanic/test.csv')['PassengerId'])
sub['Survived'] = sub_lgbm_sk['Survived'] + sub_lgbm_ho['Survived'] + sub_rf['Survived']
sub['Survived'] = (sub['Survived'] >= 2).astype(int)
sub.to_csv('submission_lightgbm_ensemble.csv', index=False)
この予測値を提出すると、私の環境で0.78468という過去最高のスコアが得られました。

「Kaggle Ensembling Guide」には今回体験したような「提出ファイルによるアンサンブル」だけではなく、より高度な「Stacked Generalization (Stacking)」「Blending」といった様々な技法が紹介されています。より深くアンサンブルを勉強したい場合は、ご一読をオススメします。
8. Titanicの先へ行く①! 複数テーブルを結合してみよう
Titanicでは訓練用データが「train.csv」という1つのcsvファイルにまとまっていますが、複数ファイルが用意されている場合も多いです。
例えば「Home Credit Default Risk」46というコンペティションでは、次の図のような関係を持つ複数のファイルが提供されました。
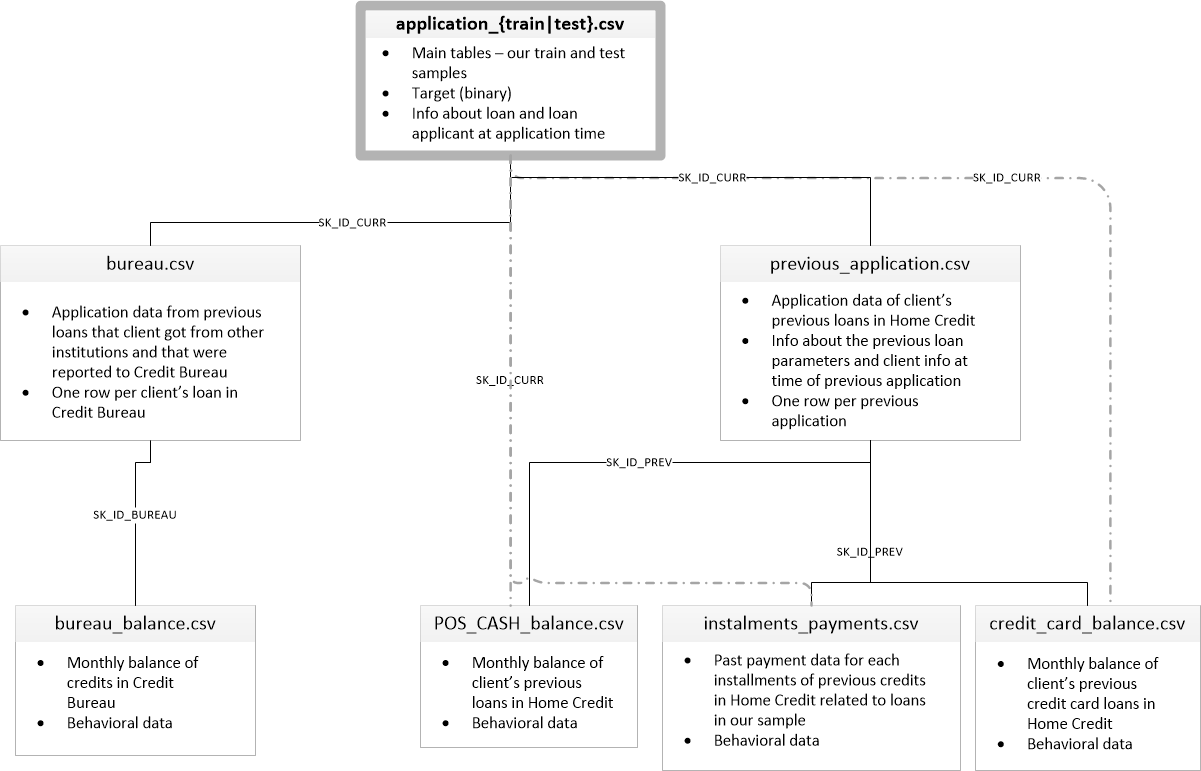
(画像はHome Credit Default Riskの「Data」タブから引用)
個人的には、こういったコンペティションに直面した際のデータの扱い方が分からず、Titanicの次へ行く障壁の1つになっているのではないかと考えています。
このNotebookでは、複数のファイルを結合して機械学習アルゴリズムに入力するためのデータを用意する方法を扱います。
題材にするのは先に紹介した「Home Credit Default Risk」コンペです。このコンペでは、融資の申込に対して、それぞれが債務不履行になるか否かを予測します。application_{train/test}.csvに含まれる申込1件に対して、過去の申込履歴などの関連情報を含むcsvファイルが複数存在するデータ構造で、どのように有益な情報を取り出すかが問われるコンペとなりました47。
Home Credit Default Risk
ここでは、公開Notebook「Introduction to Manual Feature Engineering」48の冒頭の例を引用します。
まずは主ファイルであるapplication_train.csvを読み込みます。各行が1つの融資の申込を表し、TARGETが予測の対象です。
application_train = pd.read_csv('../input/home-credit-default-risk/application_train.csv')
application_train.head()

次いで、サブファイルに当たるbureau.csvを読み込みます。bureau.csvには、他の金融機関から提供された過去の申込履歴が記録されています。
図に示された通り、SK_ID_CURRで紐づく関係性です。過去の履歴なので、application_trainの1行に対して、bureauの複数行が対応する可能性があります。
bureau = pd.read_csv('../input/home-credit-default-risk/bureau.csv')
bureau.head()

仮に1:1の関係ならば、純粋にデータを結合してしまえば良いです。ここでは1:Nの関係なので、N側のデータセットを何かしらの方法で集約して情報量を落とす必要があります。
「何かしらの方法で集約」の部分は、「3. ここで差がつく! 仮説に基づいて新しい特徴量を作ってみよう」で説明したような特徴量エンジニアリングの力が試されます。思考停止でさまざまな集約パターンを試す場合もありますが、今回のデータセットのようにある程度カラム数も多い場合には、意味のある仮説を立てるのが望ましいと思います。
ここでは「過去の申込回数」が有効な特徴量になるという仮説を得たとします。この特徴量は、次のようにbureauから作成可能です。SK_ID_CURRごとに、回数が集計されています。
previous_loan_counts = bureau.groupby('SK_ID_CURR', as_index=False)['SK_ID_BUREAU'].count().rename(columns={'SK_ID_BUREAU': 'previous_loan_counts'})
previous_loan_counts.head()

あとは、application_trainにSK_ID_CURRをキーにして結合するだけです。
application_train = pd.merge(application_train, previous_loan_counts, on='SK_ID_CURR', how='left')
この際how='left'という引数が与えられている点に注目です。SQLを使ったことのある方はイメージしやすいかと思いますが、引数として与えられているデータセットのうち、左側のファイルを軸にデータセットを結合していくという意味合いです。右側のデータセットに該当する値が含まれていない場合は、欠損値になります。
仮にこの引数を指定しないと、両者に含まれるSK_ID_CURRのデータセットのみが返ります49。ここでprevious_loan_countsには申込が0回のSK_ID_CURRは含まれていないので、データセットの欠落が発生する可能性があります。
application_trainの行数が減るのは学習用データセットの量を保つ観点から望ましくありません。application_test.csvを扱う場合は、予測すべきデータセットが欠落する事態を招いてしまいます。
この欠損値は、意味合いを考えると0で補完するのが適切です。
application_train['previous_loan_counts'].fillna(0, inplace=True)
application_train.head()

今回は単純な仮説を基に特徴量を作成しましたが、例えば「直近の申込履歴を重視して集計したい」など、さまざまな観点でデータセットを集約できます。このような考え方で、複数のファイルを結合して機械学習アルゴリズムに入力するためのデータを用意することが可能となります。
9. Titanicの先へ行く②! 画像データに触れてみよう
Kaggleのコンペティションで扱うデータは、大きく分けて次の3種類があります。
- テーブルデータ
- 画像データ
- テキストデータ
Titanicのデータはテーブルデータに該当しますが、他のコンペティションでは画像データやテキストデータを扱う場合も多いです。
「PetFinder.my Adoption Prediction」のように、3種類全てのデータを扱うコンペティションも存在します。テーブルデータとしてはペットの犬種や年齢、画像データとしてはペットの写真、テキストデータとしてはペットの説明文といった情報が提供されました。

9〜10つ目のNotebookでは、それぞれ画像とテキストデータを扱う方法を解説します。とはいえ、近年に急速に発展を遂げる画像認識・自然言語処理分野を網羅的に紹介するのは現実的ではありません。
本記事では画像とテキストデータを扱うコンペティションの概要を述べ、これまで学んできたテーブルデータを扱うコンペティションと比較して、共通する・異なる部分を簡潔に説明します。今後ご自身で取り組んでいく上での最初の取っ掛かりになればと考えています。
画像を扱うコンペティションの概要
ここでは、画像を扱うコンペティションの概要を説明します。略して「画像コンペ」などと表現されることも多いです。
画像コンペでは、画像認識分野で一般的な課題が出題されることが多いです50。具体的には、分類・検出・セグメンテーションなどが挙げられます。その他には「Adversarial Example」51「Generative Adversarial Network(GAN)」52など具体的な技術に特化したコンペティションも開催されています。
分類
分類の問題では、与えられた画像に対して、適切なラベルを推定します。出力は最も可能性の高いラベルの場合もあれば、ラベルと確率の場合もあります。
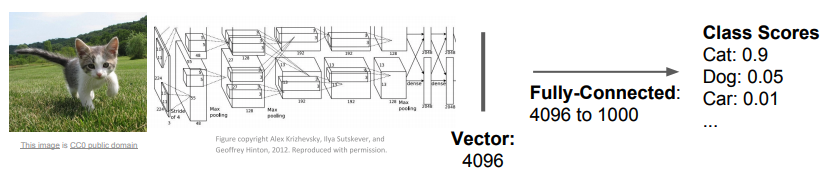
(画像は「CS231n: Convolutional Neural Networks for Visual Recognition」53の講義資料54から引用)
検出
検出の問題では、与えられた画像の中にある物体の場所・ラベルを推定します。どの粒度で何を検出すべきかは問題設定次第です。例えば下図では「DOG」「CAT」を出力していますが、犬の目や鼻の部分を抽出すべき場合もあるかと思います。

(画像は「CS231n: Convolutional Neural Networks for Visual Recognition」の講義資料から引用)
セグメンテーション
セグメンテーションの問題では、与えられた画像をいくつかの領域に塗り分けます。出力画像の見た目から「塗り絵」などと呼ばれることもあります。

(画像は「CS231n: Convolutional Neural Networks for Visual Recognition」の講義資料から引用)
Adversarial Example
2017年には「Neural Information Processing Systems (NeurIPS)」55という著名な国際会議に併設される形で、Adversarial Exampleを題材にしたコンペティションが開催されました56。画像コンペは、国際学会に併設されて開催されることも多い印象です。
Adversarial Exampleは、入力に対し人間が検知できない微量な変更を加えることで機械学習アルゴリズムの出力を大きく狂わせてしまう現象のことです。このコンペティションでは、出力を狂わせる「攻撃側」と、出力を狂わされにくい機械学習アルゴリズムを作る「防御側」の2部門が設けられました。より具体的な詳細については、4位に入賞したPreferred Networksのブログ57をご参照ください。

(画像は「Explaining and Harnessing Adversarial Examples」58から引用)
GAN
2019年には、新たにGANを題材にしたコンペティションも開催されました59。GANは画像の生成器と識別器という2種類のニューラルネットワークを組み合わせて精度の高い画像を生成する技術です。GANを用いて、いかに精度の高い画像を生成できるかを競う問題設定になっていました。
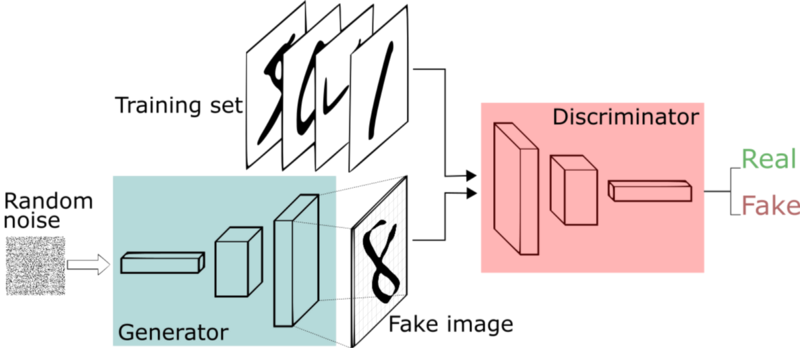
(画像は「An intuitive introduction to Generative Adversarial Networks (GANs)」60から引用)
GANを用いずに評価指標を不当に最適化しようとする試みがはびこるなど、GANを題材にする難しさも露呈したコンペティションとなりました61。
テーブルデータと共通する・異なる部分
ここでは、これまで学んできたテーブルデータを扱うコンペティションと比較して、共通する・異なる部分を簡潔に説明します。
まず前提として機械学習の教師あり学習の枠組みである限り、学習用データセットの特徴量・目的変数の対応関係を機械学習アルゴリズムで学習して未知のデータセットに対する汎化性能を得るという部分は共通です。教師あり学習の枠組みについては「2. 全体像を把握! 提出までの処理の流れを見てみよう」で解説しました。
テーブルデータ同様、画像も数値データの集合に過ぎない点に考えると類似点が分かりやすいかもしれません。
以降、Notebookでは、PyTorchの提供するチュートリアル「TRAINING A CLASSIFIER」62に沿って画像データを扱っていきます。
import torch
import torchvision
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
まずはデータセットをダウンロードします。Notebookを利用する場合は、右サイドバーの「Internet」をOnにしておく必要があります。今回利用するのは「CIFAR10」63と呼ばれる、10種類のラベルが付与された画像分類の著名なデータセットです。
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
画像を可視化した結果を以下に示します。
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(trainloader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

batch_size=4にしているためimagesには、4枚の画像データが配列形式で含まれています。それぞれの画像は縦横32ピクセル×32ピクセルのRGB値(3種類)のデータになっています。
images.shape
torch.Size([4, 3, 32, 32])
この画像1枚の数値データが、Titanicでのテーブル1行に対応しています。
images[0]
tensor([[[ 0.0824, 0.0510, 0.0510, ..., 0.0745, 0.0745, 0.0902],
[ 0.1137, 0.0745, 0.0588, ..., 0.0980, 0.0980, 0.0980],
[ 0.1294, 0.0902, 0.0745, ..., 0.1137, 0.1059, 0.0980],
...,
[-0.5686, -0.6000, -0.6157, ..., -0.6549, -0.6549, -0.6314],
[-0.5765, -0.6078, -0.6314, ..., -0.6863, -0.7020, -0.6941],
[-0.6000, -0.6235, -0.6549, ..., -0.6941, -0.7020, -0.7098]],
[[ 0.1137, 0.1059, 0.1216, ..., 0.1294, 0.1294, 0.1216],
[ 0.1373, 0.1137, 0.1216, ..., 0.1373, 0.1373, 0.1294],
[ 0.1373, 0.1137, 0.1216, ..., 0.1373, 0.1294, 0.1216],
...,
[-0.4745, -0.4824, -0.4902, ..., -0.5294, -0.5373, -0.5137],
[-0.4902, -0.4902, -0.4902, ..., -0.5451, -0.5608, -0.5529],
[-0.5059, -0.5059, -0.5137, ..., -0.5529, -0.5608, -0.5686]],
[[ 0.2078, 0.1922, 0.2000, ..., 0.2157, 0.2157, 0.2157],
[ 0.2157, 0.1843, 0.1922, ..., 0.2078, 0.2157, 0.2078],
[ 0.2078, 0.1843, 0.1843, ..., 0.2078, 0.2000, 0.1922],
...,
[-0.4510, -0.4745, -0.4824, ..., -0.5294, -0.5294, -0.4980],
[-0.4745, -0.4824, -0.4902, ..., -0.5451, -0.5608, -0.5529],
[-0.4902, -0.5059, -0.5137, ..., -0.5529, -0.5608, -0.5686]]])
テーブルデータと画像データを扱うに当たって、特に大きく異なるのは特徴量エンジニアリングの部分だと思います。
伝統的な画像認識では「画像のどこに注目し、何を特徴として取り出すか」という手続きが存在していました64。局所特徴量「SIFT」65などが有名です。SIFTなどを用いて画像を数値化した上で、ロジスティック回帰などの機械学習アルゴリズムに投入するやり方が採用されていました。このやり方はテーブルデータから特徴量を作っていく過程とも類似していると思います。
ただし近年はニューラルネットワークの台頭に伴い、画像から特徴量を抽出する部分をニューラルネットワークに任せる手法が一般的です。詳細は割愛しますが、画像のデータセットをそのまま入力として利用し、ニューラルネットワークの高い表現力で有用な特徴量を獲得しています。この辺りは歴史も含めて『画像認識』(機械学習プロフェッショナルシリーズ)66の第1章に記載されています。
こういった背景もあり、画像コンペでは特徴量エンジニアリングよりも、ニューラルネットワークの構造設計に注力する面が大きい印象です。「第9回:Kaggleの「画像コンペ」とは--取り組み方と面白さを読み解く」67では、論文を読みながら研究動向を追うなど、DeNAの矢野さんの画像コンペへの取り組み方がまとめられています。画像コンペの取り組み方については、phalanxさんの資料68も参考になります。
他にも、データセットのサイズの違いは大きいです。例えばTitanicの「train.csv」は61KBですが、画像コンペのデータセットは10GBを超えることも珍しくありません。また機械学習アルゴリズムにも層の深いニューラルネットワーク(ディープラーニング)を利用する場合が多く、計算量が多いです。計算資源としてGPUが必須になる場合が多いでしょう。
このNotebookでは、PyTorchのチュートリアルの冒頭部分からコードを流用しました。チュートリアルの続きでは、GPUを用いてディープラーニングの一種「Convolutional Neural Network (CNN)」69を学習し、予測を実行しています。興味があれば、最初の取っ掛かりとして取り組むのも良いかと思います。
10. Titanicの先へ行く③! テキストデータに触れてみよう
ここでは、テキストデータを扱う方法を解説します。
テキストを扱うコンペティションの概要
まず、テキストを扱うコンペティションの概要を説明します。自然言語処理(Natural Language Processing)が題材なので「NLPコンペ」などと表現されることも多いです。
自然言語処理の課題としては、一般に分類・文生成・質問応答などが挙げられます。Kaggleではデータセットや採点の都合か、分類や回帰に帰着した出題が多い印象です。最近の例で言うと「Quora Insincere Questions Classification」70「Jigsaw Unintended Bias in Toxicity Classification」71は、文章の有害度合いを予測するコンペティションでした。
テーブルデータと共通する・異なる部分
ここでは、これまで学んできたテーブルデータを扱うコンペティションと比較して、共通する・異なる部分を簡潔に説明します。
前章でも述べた通り、NLPコンペでも機械学習の教師あり学習の枠組みである限り、大まかな考え方は変わりません。学習用データセットの特徴量・目的変数の対応関係を機械学習アルゴリズムで学習して、未知のデータセットに対する汎化性能を得るのが目的となります。
一つ大きく異なるのは、文章はそのままでは機械学習アルゴリズムで扱えないという点です。コンピュータで表示している以上は英語・日本語のテキストデータも大元を辿れば数値データですが、テーブルデータ・画像データのように特徴量という意味のあるベクトルとして見なす必要があります。
以降、Notebookでは、テキストデータを扱っていきます。サンプルデータとしては、次の3文を利用します。
import pandas as pd
df = pd.DataFrame({'text': ['I like kaggle very much',
'I do not like kaggle',
'I do really love machine learning']})
これらの文は、このままでは機械学習アルゴリズムの入力として扱えません。文の特徴を保持したまま何かしらの方法でベクトルに変換する必要があります。
Bag of Words
単純なアイディアとして、文で登場した単語の回数を数える方法があります。この方法は「Bag of Words」と呼ばれます。
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(token_pattern=u'(?u)\\b\\w+\\b')
bag = vectorizer.fit_transform(df['text'])
bag.toarray()
array([[0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1],
[1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0],
[1, 1, 0, 1, 0, 1, 1, 0, 0, 1, 0]], dtype=int64)
arrayの中には3つの要素が存在し、それぞれが文に対応しています。1つ目の要素は[0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1]です。これは、indexの1, 2, 4, 7, 10に値する単語が文に含まれているという意味です。
各indexに対応している単語は、次のように確認できます。例えばindexが1になっている「i」は、全ての文章で1のフラグが立っています(indexが0始まりであることに注意してください)。
vectorizer.vocabulary_
{'i': 1, 'like': 4, 'kaggle': 2, 'very': 10, 'much': 7, 'do': 0, 'not': 8, 'really': 9, 'love': 5, 'machine': 6, 'learning': 3}
Bag of Wordsは単純で分かりやすい手法ですが、次のような弱点があります。
- 単語の珍しさを表現できていない
- 単語同士の近さを考慮できていない
- 文中の単語の順番に関する情報を捨ててしまっている
1点目について、文の特徴を捉えたいという目的ならば、「I」などの一般に文に多く登場する単語よりも「Kaggle」「machine learning」などの特徴的な単語を重要視したいです。2点目について、ここでは「like」と「love」を完全に別の単語として扱っており、この2つの単語が似ているという情報は使えていません。3点目について、文を単語に分割して考えることで文の意味を正確に捉えるのは難しくなっています。
TF-IDF
先に述べた1点目の問題に対処したのが、登場する単語の珍しさを考慮した「TF-IDF」と呼ばれる手法です。「Term Frequency」(単語の登場頻度)を数えるだけではなく、「Inverse Document Frequency」(ドキュメント内での登場頻度の逆数)を掛け合わせています。
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
vectorizer = CountVectorizer(token_pattern=u'(?u)\\b\\w+\\b')
transformer = TfidfTransformer()
tf = vectorizer.fit_transform(df['text'])
tfidf = transformer.fit_transform(tf)
# tfidfが計算された結果の表示
print(tfidf.toarray())
[[0. 0.31544415 0.40619178 0. 0.40619178 0.
0. 0.53409337 0. 0. 0.53409337]
[0.43306685 0.33631504 0.43306685 0. 0.43306685 0.
0. 0. 0.56943086 0. 0. ]
[0.34261996 0.26607496 0. 0.45050407 0. 0.45050407
0.45050407 0. 0. 0.45050407 0. ]]
Bag of Wordsと同様に、arrayの中には3つの要素が存在し、それぞれが文に対応しています。
1文目をBag of WordsとTF-IDFで比較してみましょう。今回、各indexに対応している単語は両者で変わらないので、0より大きい値を含むindexは同じです。
- Bag of Words: [0, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1]
- TF-IDF: [0., 0.31544415, 0.40619178, 0., 0.40619178, 0., 0., 0.53409337, 0., 0., 0.53409337]
違うのは、Bag of Wordsでは0か1のみの値を取るのに対して、TF-IDFでは0-1の値を取っている点です。
TF-IDFでは「I」は0.31544415、「kaggle」と「like」は0.40619178、「very」と「much」は0.53409337の値が割り当てられています。「I」は3文全てに登場している一方で、「very」と「much」は1文目にのみ存在しており、単語の珍しさに応じて大きな値になっていると読み取れます。
Word2vec
先に、Bag of Wordsの2つ目の問題点として「単語同士の近さを考慮できていない」と述べました。このような単語同士の意味の近さを捉えたベクトル化の手法として「Word2vec」などが挙げられます。
具体的な仕組みについては「絵で理解するWord2vecの仕組み」72や「word2vec(Skip-Gram Model)の仕組みを恐らく日本一簡潔にまとめてみたつもり」73が詳しいです。
from gensim.models import word2vec
sentences = [d.split() for d in df['text']]
model = word2vec.Word2Vec(sentences, size=10, min_count=1, window=2, seed=7)
以上で学習が完了しました。学習に用いた単語は、次のようにしてベクトル形式に変換できます。
model.wv['like']
array([-0.01043484, -0.03806506, 0.01846329, 0.04698185, 0.02265111,
-0.0275427 , 0.00458471, 0.04774009, 0.01365959, 0.01941545],
dtype=float32)
次のようにして、学習に用いた単語の中から似ている単語を抽出できます。今回はデータセットが3文しかないので十分に単語の意味の近さを学習できていないようです。
model.wv.most_similar('like')
[('really', 0.3932609558105469),
('do', 0.34805530309677124),
('very', 0.29682281613349915),
('machine', 0.20769622921943665),
('learning', 0.08932216465473175),
('love', -0.035492151975631714),
('not', -0.13548487424850464),
('I', -0.2518322765827179),
('much', -0.40533819794654846),
('kaggle', -0.44660162925720215)]
このようなアイディアで単語をベクトル化することで、文を機械学習アルゴリズムに入力として利用可能です。具体的には、次のような方法が挙げられます。
- 文に登場する単語のベクトルの平均を取る
- 文に登場する単語ベクトルの各要素の最大値を取る
- 各単語の時系列データとして扱う
1つ目は非常に単純なやり方です。今回の場合は5つの単語の平均を計算します。
df['text'][0].split()
['I', 'like', 'kaggle', 'very', 'much']
import numpy as np
wordvec = np.array([model.wv[word] for word in df['text'][0].split()])
wordvec
array([[ 0.03103545, -0.01161594, -0.04156914, 0.0151331 , -0.02015941,
0.02498668, 0.01226169, -0.01423238, 0.0299348 , -0.0235391 ],
[-0.01043484, -0.03806506, 0.01846329, 0.04698185, 0.02265111,
-0.0275427 , 0.00458471, 0.04774009, 0.01365959, 0.01941545],
[ 0.00562139, 0.04261161, 0.01942341, 0.02058475, -0.04178216,
0.0483778 , 0.02867676, -0.03482581, 0.00596862, 0.01260627],
[-0.00546305, 0.04037713, -0.02587517, 0.02301916, 0.03183642,
-0.0372007 , 0.03839479, 0.01596523, 0.02796198, 0.01038733],
[-0.01727871, 0.03896596, -0.01460331, -0.01620135, 0.01536224,
0.02102943, 0.00892776, 0.00372602, 0.02321487, -0.01123929]],
dtype=float32)
np.mean(wordvec, axis=0)
array([ 0.00069605, 0.01445474, -0.00883218, 0.0179035 , 0.00158164,
0.0059301 , 0.01856914, 0.00367463, 0.02014797, 0.00152613],
dtype=float32)
2つ目の方法では、平均ではなく各要素の最大値を計算します。この手法は「SWEM-max」74などと呼ばれています。
np.max(wordvec, axis=0)
array([0.03103545, 0.04261161, 0.01942341, 0.04698185, 0.03183642,
0.0483778 , 0.03839479, 0.04774009, 0.0299348 , 0.01941545],
dtype=float32)
3つ目の方法はwordvecのベクトルをそのまま時系列の入力として扱います。Bag of Wordsの3つ目の問題点として挙げた「文中の単語の順番に関する情報を捨ててしまっている」の部分に対応する手法となっています。
ここまで、機械学習の教師あり学習の枠組みの中で、文を機械学習アルゴリズムの入力として扱うためのいくつかの手法を紹介しました。
最近のKaggleのNLPコンペでは機械学習アルゴリズムとして、時系列性を扱える「Recurrent Neural Network(RNN)」などのニューラルネットワークが頻繁に使われています。文をベクトル化して機械学習アルゴリズムで予測する一連の流れは「Approaching (Almost) Any NLP Problem on Kaggle」75と題された優れたNotebookで解説されています。
直近のNLPコンペである「Jigsaw Unintended Bias in Toxicity Classification」では汎用言語表現モデルの「BERT」76を用いた解法が目立ちました。このコンペでは終了1週間前に公開された「XLNet」77という機械学習アルゴリズムも利用されました。テーブルデータを扱うコンペと比較して、NLPコンペでは画像コンペ同様、研究の最新動向が積極的に使われている印象があります。
メダルが獲得できる開催中のコンペティションに参加しよう
入門 10 Kernelで学んだこと
- 1つ目のNotebookでは、Notebookを用いてKaggleのコンペティションに提出して順位表に載る方法、2つ目のNotebookでは全体の処理の流れを解説しました。
- 3〜7つ目のNotebookでは、既存のNotebookに手を加えていきながら、スコアを上げていく方法を学びました。
- 8〜10つ目のNotebookでは、Titanicでは扱わない複数テーブルを結合する方法、画像・テキストデータを扱う方法を紹介しました。
タイトルにもある通り「これだけやれば十分戦える!」と言える内容になっているかと思います。ぜひ次は、メダルが獲得できる開催中のコンペティションに参加してみてください。
開催中のコンペティションを確認する
開催中のコンペティションの一覧は、KaggleのCompetitions78というページの「Active Competitions」で確認できます。それぞれのページでは具体的なコンペティションの内容が記載されています。
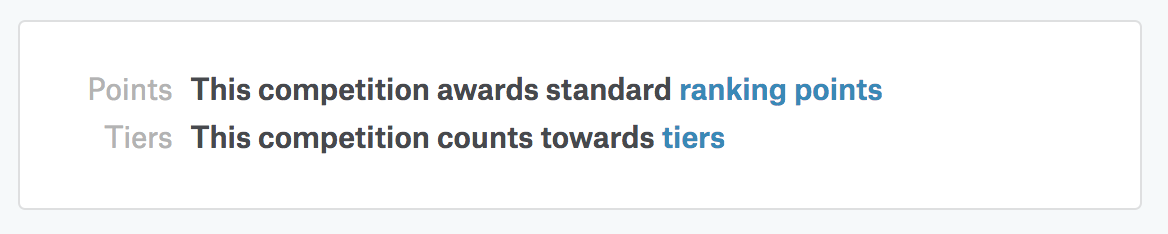
ただし、Titanicと同様のチュートリアル的なコンペティションなど、開催中でもメダルが獲得できないコンペティションもあるので注意が必要です。Kaggleでメダルが獲得できるコンペティションか否かは、トップページの「Tiers」部分の表記で確認できます79。
例えば、メダルが獲得できるコンペティションでは、次のような表記です。
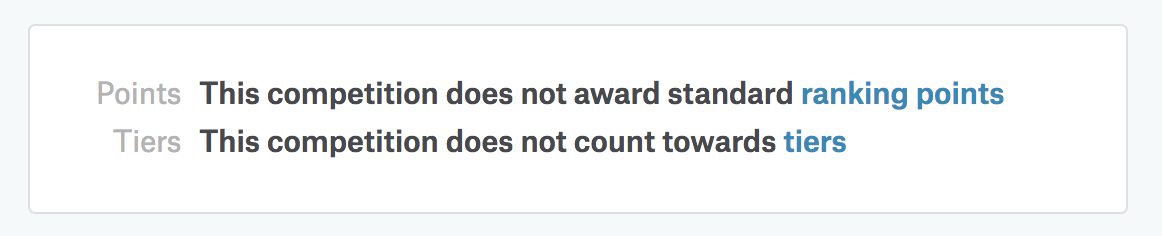
一方で、Titanicなどのメダルが付与されないコンペティションでは、次のような表記になっています。
私がコンペの選び方について発表したスライド80・動画もあります。
Kaggle以外のプラットフォーム
時期によっては、手頃なコンペがKaggleで開催されていないこともあります。その際には、次のようなKaggle以外のプラットフォームも検討すると良いでしょう。日本発のサイトの場合、言語が日本語でも記載されているため取っつきやすいかもしれません。
その他、「KDD CUP」85などの学会併設のコンペや、企業が独自に開催するコンペもあります。
初心者にオススメの戦い方
ここでは参加するコンペティションが決まった後、初心者にオススメの戦い方を書いておきます。tkm2261さん流のKaggle入門方法86にも、似たような内容が記載されています。
- ベースラインとなるNotebookを探す
- 本記事の内容を参考に、ベースラインを改善する
ベースラインとなるNotebookを探す
今回は「Santander Customer Transaction Prediction」87を例に解説します。
まず「Notebooks」タブに行き、右のプルダウンで「Most Votes」を選びましょう。
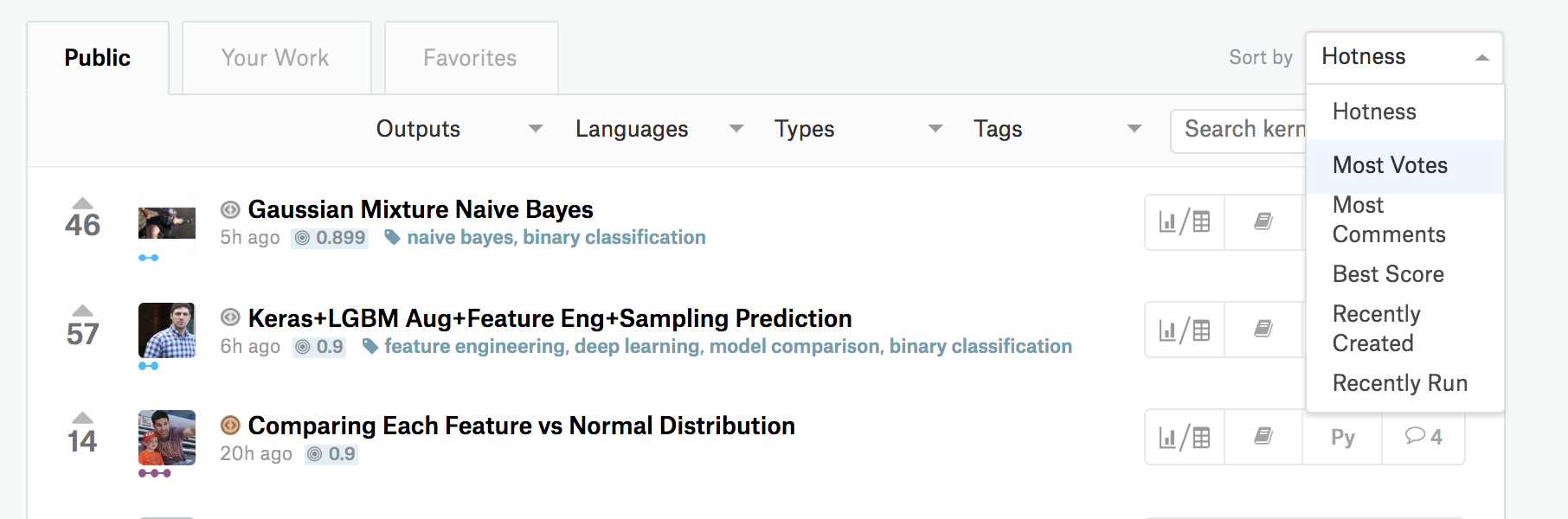
すると、参加者に多く「いいね」された順にNotebookが表示されます。
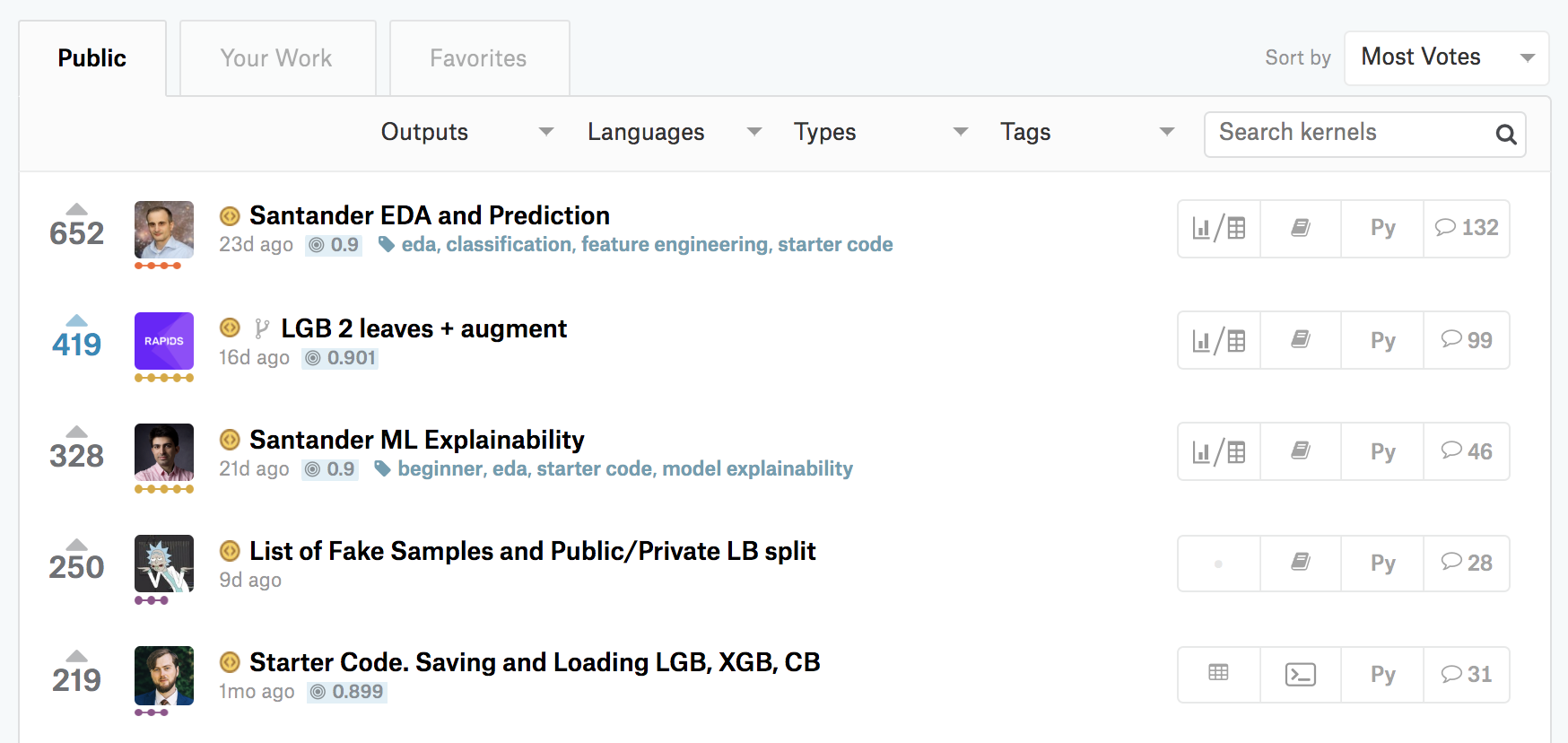
0.9, 0.901 など数字の数字は、そのNotebook経由で提出されスコアが付いていることを意味します。稀に、csvファイルでのアンサンブルのみを実施しているNotebookが上位に来ているのは注意が必要です。きちんと、Kaggleから提供された大元のデータから提出までの一連の流れを実行しているNotebookをベースラインとすると良いでしょう。
最上位のNotebookはタイトルに「EDA」と入っています。これは「Explanatory Data Analysis」、日本語だと「探索的データ分析」を意味します。これらのNotebookは、提供されたデータの特徴などを解説してくれており、ベースラインとして適していると思います。
本記事の内容を参考に、ベースラインを改善する
ベースラインのNotebookが決まったら、本記事の入門 10 Kernelと同様に、NotebookをCopy and Editして自分で手を動かしてみてください。
例えば特徴量エンジニアリングで新しい特徴量を追加したり、機械学習アルゴリズムを差し替えたり、ハイパーパラメータを調整したり、アンサンブルをしてみたり、いろいろな手数があるかと思います。自分のアイディアでスコアが増減する経験を楽しんでみてください。
コンペ中に取り組む手順について、自分なりの方法は以前にブログに記載しています88。
できれば、自分が取り組んだコンペティションには終了日まで継続して取り組んでみてほしいです。Twitterのタイムラインなどで一喜一憂したり、終了後に共有される上位者の解法から多くのことを学んだり、Kaggleの醍醐味が味わえるかと思っています。
その意味では、締切2週間前くらいのコンペティションに参加するのも1つの手だと思います(コンペティションの参加は締切1週間前に締め切られる点には注意してください)。最終的な成績を決める際に使われる自分の提出は忘れずに選ぶようにしましょう89。
さらなる学びのために
最後に、さらなる学びに向けたリンクをいくつか掲載します。
Kaggleで勝つデータ分析の技術
データ分析コンペのテーブルデータコンペに注力して書かれた「教科書」です90。体系的かつ網羅的に知見がまとまっています。技法のみならず筆者および関係者の実体験に基づいた集合知が言語化されている点も魅力です。GitHubでソースコードも公開されています。
Approaching (Almost) Any Machine Learning Problem
Kaggleの全4カテゴリでGrandmasterの称号を持つAbhishekさんによる書籍です。英語の書籍で、GitHubでPDFが無料公開されています91。実践的にKaggleに参加する上で必要となる機械学習に関する知識を学べる内容になっています。
phalanxさんの画像コンペTips
Kaggle Masterのphalanxさんによる画像コンペのTipsまとめです92。事前に必要な知識・取り組み方・参考リンク集などが掲載されています。
PyTorchチュートリアル(日本語翻訳版)
9つ目のNotebookで紹介したPyTorchの公式チュートリアルの日本語翻訳版です93。ブラウザ上の実行環境「Google Colaboratory」へのリンクがあり、実行しながら基礎的な内容を学べます。
言語処理100本ノック
実践的な課題に取り組みながら自然言語処理の基礎を学べる問題集です94。2020年版では、機械学習に関連する項目が増えています。Pythonを用いた個人的な解答はブログ95に掲載しています。
kagger-ja slack
主に日本人のKagglerが集まっているSlackのワークスペースです96。質問が飛び交うチャンネルやコンペティションの解法を共有するチャンネルなどが活発で、参加して閲覧しているだけでも多くの知見が得られると思います。メールアドレスをフォームに入力するだけで、誰でも参加可能です。過去ログはこちら97で公開されています。
kaggler-ja wiki
kagger-ja slackで話題になった内容などを体系的にまとめたページです98。次のようなコンテンツがまとめられています。
- kaggle初心者ガイド
- なんでもkaggle関連リンク
- よくある質問
- 過去コンペ情報
Kaggle Tokyo Meetupの動画・資料
Kaggle Tokyo Meetupは、Kagglerが一堂に会すイベントです。上位に入賞した方が解法を発表したり、多種多様なLTがあったり、学びの多いイベントです。
過去6回99100101102103104開催されており、特に第4回は動画105も公開されているのでオススメです。
tkm2261さんのKaggle入門動画
次のコンテンツが動画で用意されています106。
- Kaggleについて
- Porto Seguroコンペについて
- GCP立ち上げ(アカウント作ると付いてくる$300クーポン使用)
- Bitbucketでgitリポジトリ作成
- GCPの使い方
- Ubuntuセットアップ
- Anacondaセットアップ
- Pythonコーディング (Pandas, scikit-learn, xgboost)
- Gitの使い方
- loggerの使い方
- ロジスティック回帰
- Cross Validation解説
- Grid Search解説
- xgboost解説
- one hot encoding解説
- Kaggleの提出方法
- おまけ: 私の過去コンペのコードの解説
Twitter Kaggle リスト
私が日々見ているKagglerを集めたTwitterのリストです107。Kaggleに取り組む方々の日常から、さまざまな刺激を受けています。
Weekly Kaggle News
私が発行している、日本語でKaggleをはじめとするデータ分析コンペティションに関する話題を取り扱っているニューズレターです108。コンペ更新情報や、直近で公開されたKaggle関連の記事を紹介しています。週次で、毎週金曜ごろに更新しています。
おわりに
本記事では「Kaggleに登録したら次にやること」と題して、Kaggleに入門したい方に向けた情報を掲載しました。少しでも多くの方のお役に立てていれば幸いです。
-
https://www.kaggle.com/c/santander-value-prediction-challenge ↩
-
https://www.kaggle.com/bminixhofer/deterministic-neural-networks-using-pytorch ↩
-
https://naotaka1128.hatenadiary.jp/entry/kaggle-compe-tips ↩
-
https://lightgbm.readthedocs.io/en/latest/Python-Intro.html ↩
-
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html ↩
-
https://tebasakisan.hatenadiary.com/entry/2019/01/27/222102 ↩
-
https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html ↩
-
https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html ↩
-
https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html#for-better-accuracy ↩
-
https://nykergoto.hatenablog.jp/entry/2019/03/29/%E5%8B%BE%E9%85%8D%E3%83%96%E3%83%BC%E3%82%B9%E3%83%86%E3%82%A3%E3%83%B3%E3%82%B0%E3%81%A7%E5%A4%A7%E4%BA%8B%E3%81%AA%E3%83%91%E3%83%A9%E3%83%A1%E3%83%BC%E3%82%BF%E3%81%AE%E6%B0%97%E6%8C%81%E3%81%A1 ↩
-
https://mlwave.com/kaggle-ensembling-guide/ 2022年現在閲覧できない状況になっている(アーカイブ) ↩
-
https://www.kaggle.com/willkoehrsen/introduction-to-manual-feature-engineering ↩
-
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.merge.html ↩
-
http://cs231n.stanford.edu/slides/2018/cs231n_2018_lecture11.pdf ↩
-
https://www.kaggle.com/c/nips-2017-non-targeted-adversarial-attack/ ↩
-
https://research.preferred.jp/2018/04/nips17-adversarial-learning-competition/ ↩
-
https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html ↩
-
https://www.robots.ox.ac.uk/~vgg/research/affine/det_eval_files/lowe_ijcv2004.pdf ↩
-
https://speakerdeck.com/phalanx/imet-7th-place-solution-and-my-approach-to-image-data-competition?slide=30 ↩
-
https://www.kaggle.com/c/quora-insincere-questions-classification/ ↩
-
https://www.kaggle.com/c/jigsaw-unintended-bias-in-toxicity-classification ↩
-
https://www.kaggle.com/abhishek/approaching-almost-any-nlp-problem-on-kaggle ↩
-
https://speakerdeck.com/upura/how-to-choose-kaggle-competitions ↩
-
http://kaggler-ja-wiki.herokuapp.com/kaggle%E5%88%9D%E5%BF%83%E8%80%85%E3%82%AC%E3%82%A4%E3%83%89#%E3%82%AA%E3%83%AC%E3%82%AA%E3%83%ACKaggle%E5%85%A5%E9%96%80%E6%96%B9%E6%B3%95 ↩
-
https://www.kaggle.com/c/santander-customer-transaction-prediction ↩
-
https://github.com/phalanx-hk/kaggle_cv_pipeline/blob/master/kaggle_tips.md ↩
-
https://yutori-datascience.hatenablog.com/entry/2017/08/23/143146 ↩
-
http://yutori-datascience.hatenablog.com/entry/2017/10/29/205433 ↩
-
https://www.youtube.com/watch?v=VMjnhGW2MgU&list=PLkBjLQIGEjJlciM9lEz1AsuZZ8lDgyxDu ↩
-
http://yutori-datascience.hatenablog.com/entry/2017/10/24/215647 ↩