はじめに
この記事は以前作成した競艇予想のモデルをAWS Lambda上で使用し、
競艇予想APIを作成したときのお話です。
やっていることは単純ですが、これを実現するために私の夏休みをすべて費やしました(泣)
ですので、私のようにAWS Lambdaで自身が作成した機械学習モデルを使用したいと
考えている方の助けとなれるように記事を書きました。
アジェンダ
1.使用したライブラリ、実行環境について
2.処理内容について
3.アーキテクチャ図について
4.競艇予想APIを作る上で困った点について
5.Serverlessについて
6.ServerlessによるAWS Lambdaのデプロイ方法について
7.競艇予想APIのつくり方について
8.最後に
1.使用したライブラリ、実行環境について
・Python 3.6
・TensorFlow 1.14.0
・Numpy 1.15.4, 1.17.2
・h5py 2.10.0
・Skipy 1.1.0
2.処理内容について
今回はローカル環境で作成した機械学習モデルで競艇予想を行います。
手順は以下の通りです。
①予想したい競艇レースについて予想結果が既にDBに存在する場合は、DBのデータを返却する。
(DBに予想結果が存在しない場合は②以下を実行)
②予想したい競艇レースの情報を取得する。
③取得したレース情報を加工し、機械学習モデルの入力データを作成する。
④機械学習モデルに入力データを投入し、予想結果を取得する。
⑤予想結果をDBに登録し、返却する。
モデルがすでに存在するため処理も少なく
かつ シンプルな内容となります。
3.アーキテクチャ図について
今回のアーキテクチャ図は以下の通りです。
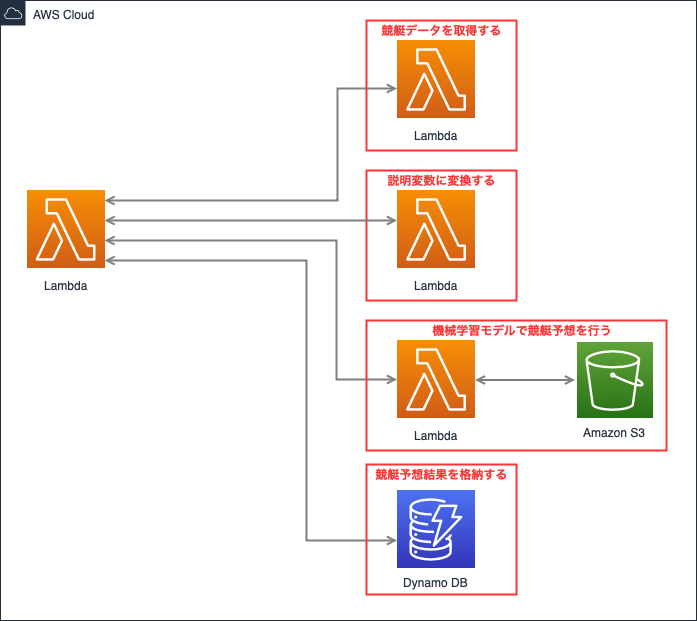
前章で説明した通り、まずはDynamo DBに競艇予想結果が存在するのかを
確認します。
予想結果が存在する場合は、そちらを返却します。
なければ各Lambdaを順番に実行し、競艇予想を行います。
4.競艇予想APIを作る上で困った点について
今回の処理は非常にシンプルですが、Lambdaの仕様・Pythonのライブラリについて
理解が不足していたため、想像以上に苦戦しました。
苦戦した点について
①Lambdaの環境には外部ライブラリは用意されていない
pipコマンドでインストールするNumpyやTensorFlowなどの
所謂外部ライブラリはLambda上にはインストールされていません。
ですので、外部ライブラリをインストールする場合は以下のいづれかの方法で行います。
・外部ライブラリと実装したLambda関数をzip化し、直接アップロードする
(zipファイルが10MB以下の場合)
・zipファイルをS3にアップロードし、Lambdaにデプロイする
** (zipファイルが10MBを超過する場合)**
②zip化したデプロイパッケージサイズは50MB以下
zipファイルが10MBを超過する場合はS3経由でアップロードする必要があります。
ただし、そのzipファイルも50MB以下にしなければなりません。
外部ライブラリの中にはとても大きなサイズのものもあります。
今回の場合はTensorFlowはなんと450MB以上ですので、大幅にサイズ超過しています。
③非Pure PythonライブラリはAmazon Linuxでインストールする
以下のサイトでご説明されているように、Numpyなどの一部のPython外部ライブラリは
内部でC言語を使用しています。
これらは自身のローカル環境にてpipコマンドでインストールし、
zip化してアップロードしてもAWS Lambda上では動きません。
・[AWS LambdaでNumpy、Scipyを使ってみる!Serverless Frameworkとプラグインを使えばパッケージ管理が簡単!]
(https://dev.classmethod.jp/cloud/serverless-framework-lambda-numpy-scipy/)
これらの非Pure PythonライブラリはAmazon Linux上で
インストールしたものを使用しなければなりません。
これらの制約を守りつつ、Lambda上にTensorFlowなどをインストールする方法は
以下の2通りです。
①Amazon EC2を起動し、Pythonライブラリをインストールし、zip化してS3にアップロードする。
②Serverlessを使用し、S3にPythonライブラリとLambda関数をアップロードする。
アップロード完了後CloudFormationを使用し、Lambdaにデプロイする。
今回は②の手段を利用しました!
ですので次章以降でその手順を説明します!
5.Serverlessについて
Serverless(正しくはServerless Framework)はサーバレスアプリケーションの
実装、テスト、デプロイまでを包括的に支援するオープンソースフレームワークです。
Serverlessを使用することで、Lambda関数を定義し、必要なライブラリと共にAWS Lambdaに
簡単にデプロイを行えます!!
また、Numpyなどの非Pure Pythonライブラリもserverless-python-requirements
とDockerを使って、Lambdaにインストールできます!
インストール方法
ServerlessはNode.jsのCLI(Command Line Interface)ツールです。
そのため、Serverlessをインストールする前にNode.jsが自身の環境に
インストールされているのかをご確認ください。
インストールされていない方はこちらの方の記事などをご参考にインストールしてください。
・MacにNode.jsをインストール
Node.jsのインストール後、以下のコマンドを実行してください。
$ npm install -g serverless
コマンドが成功するとServerlessのインストールが完了します!
6.ServerlessによるAWS Lambdaのデプロイ方法について
Serverlessのインストールが完了したので、ここからはServerlessで
Lambdaへのデプロイ手順をご説明します。
【手順一覧】
① 管理者権限を持つIAMユーザを作成し、ServerlessがAWSにアクセスできるように設定する
② Serverlessで管理するサービスを作成する
③ Lambda関数とServerlessの設定ファイルを編集する
(非Pure Pythonライブラリをインストールする場合)
③’-1 serverless-python-requirementsをインストールする
③’-2 Dockerを起動する
④ Serverlessをデプロイする
① 管理者権限を持つIAMユーザを作成し、ServerlessがAWSにアクセスできるように設定する
IAMユーザは以下の記事などをご参考に作成してください。
・【初心者向け】IAM完全攻略アルティマニア
作成する際は以下の点に注意してください。
・アクセスキーIDとシークレットアクセスキーを有効にすること
・AdministratorAccessポリシーをアタッチすること
・ユーザ作成時に表示されるアクセスキーIDとシークレットアクセスキーを控えておくこと
IAMユーザの作成が完了したら以下のコマンドでServerlessからAWSにアクセスできるようになります!
$ serverless config credentials
—provider aws
—key “IAMユーザのアクセスキーID”
—secret “IAMユーザのシークレットアクセスキー”
② Serverlessで管理するサービスを作成する
Serverlessはサービスという単位でプロジェクトを管理します。
ですのでまずは以下のコマンドでサービスを作成します。
$ serverless create —template aws-python —path “自身の作業ディレクトリ”
今回はPythonでLambda関数を実装するため、templateオプションにaws-pythonを指定しました。
Pythonではなく、Node.jsやjavaなどで実装する場合はtemplateオプションを変更してください。
③ Lambda関数とServerlessの設定ファイルを編集する
②でサービスを作成すると、指定した作業ディレクトリ配下に以下のファイルが生成されます。
・serverless.yml
・handler.py
Serverless.ymlではデプロイするサービスについての設定を行います。
Serverless.ymlからAWS CloudFormationテンプレートに変換されて、
AWS上でデプロイを実施する流れとなります。
Serverless.ymlでは以下のような設定ができます。
service: “作成したサービス名”
provider:
name: aws
region: ”デプロイしたいリージョン(東京の場合は ap-northeast-1)”
runtime: “使用する言語とバージョン(python3.6 など)”
stage: “デプロイするステージ(特に指定がなければ dev)”
functions:
“Lambda関数名”:
handler: handler.”Lambda関数名”
timeout: ”Lambdaのタイムアウト(秒)”
memory: “Lambdaのメモリ数(MB)”
他にも、Lambda関数のIAMロールやLambda関数のトリガとなるイベントの設定などができます。
handler.pyにはLambda関数を実装します。
import son
def lambda_handler(event, context):
return ~
③’-1 serverless-python-requirementsをインストールする
serverless-python-requirementsはServerlessのプラグインです。
以下のサイトで詳しくご説明されていますが、Serverlessをデプロイする際にPython
のライブラリをインポートしてくれるものです。
・Serverless Frameworkのプラグインを利用した外部モジュールの管理
serverless-python-requirementsは以下のコマンドでインストールできます。
$ serverless plugin install -n serverless-python-requirements
serverless-python-requirementsを使用する場合は以下の作業が必要です。
・serverless.ymlの編集
・requirements.txtの作成
serverless.ymlは以下の内容を追記してください。
plugins:
- serverless-python-requirements
requirements.txtにはインストールするPythonのライブラリを記載します。
例えばTensorFlowをインストールしたい場合は以下の通りです。
tensorflow==1.14.0
あるいは自身の環境にインストールされているライブラリと同じものを
Lambdaで使用する場合は、以下のコマンドで自動的にrequirements.txtに追加できます。
$ pip freeze > requirements.txt
③’-2 Dockerを起動する
非Pure PythonのライブラリはServerlessをデプロイする際に内部でDockerを使用し、
インストールします。
ですのでDockerを起動する必要があります。
Dockerのインストールや起動方法については以下の記事をご参照ください。
・Dockerインストールメモ
また、Dockerを使用する場合もserverless.ymlの編集が必要となります。
serverless.ymlは以下の内容を追記してください。
custom:
pythonRequirements:
dockerizePip: true
④ Serverlessをデプロイする
ここまでくれば、あとはServerlessのデプロイのみとなります。
デプロイは以下のコマンドで実行できます。
$ serverless deploy
コマンドを実行し、以下の表示があれば完了です!
Serverless: Stack update finished...
Service Information
service: “サービス名”
stage: dev
region: ap-northeast-1
stack: “サービス名”-dev
resources: 5
api keys:
None
endpoints:
None
functions:
collectRaceData: サービス名”-dev-”Lambda関数名”
layers:
None
Serverless: Removing old service artifacts from S3...
Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.
以上がServerlessでLambdaにデプロイする際の手順です。
次章では実際にTensorFlowなどのライブラリと競艇予想のLambda関数を
デプロイしていきます!
7.競艇予想APIのつくり方について
それでは実際に私が作った競艇予想APIについてご説明します。
手順は前章で説明した通りです。
ですのでこの章ではLambda関数の説明とServerlessの設定について
詳しくお話しします。
アーキテクチャ図では複数のLambda関数を使用していました。
元々は全て一つのLambda関数で完結する予定でしたが、
インストールするライブラリの容量を考慮し、以下の4つのLambda関数を作りました!
① 予想したい競艇レースの情報を取得するLambda関数
② ①で取得したレース情報を機械学習の説明変数に変換するLambda関数
③ ②の説明変数とS3に格納した機械学習モデルを使用し、順位予想を行うLambda関数
④ ①〜③の呼び出しとDynamo DBとの入出力を行うLambda関数
①はレース日・競艇場No・レースNoを引数としてあらかじめ取得したレース情報を
返却します。
②は①の情報を元に標準化を行います。
import json
import numpy as np
import scipy.stats
def lambda_handler(event, context):
one_race_data = event["one_race_data"]
explanatory_variable = arrange_raceData(one_race_data)
return explanatory_variable
def arrange_raceData(one_race_data):
explanatory_variable = scipy.stats.zscore(one_race_data)
explanatory_variable = explanatory_variable.tolist()
return explanatory_variable
②は当初③の競艇予想のプログラムにて実施する内容でしたが、Pythonライブラリの
容量の都合上、SkipyをTensorFlowなどと一緒にインストールできなかったため、
Lambda関数として切り出しました。
幸い、SkipyとNumpyについてはAWSが公式でLambda-Layerを用意しているので、
そちらを利用しました。
Lambda-Layerの追加方法は以下の通りです。
まずは、Lambdaのマネジメントコンソール画面で関数名が表示されている箇所の
下の「Layers」を選択します。
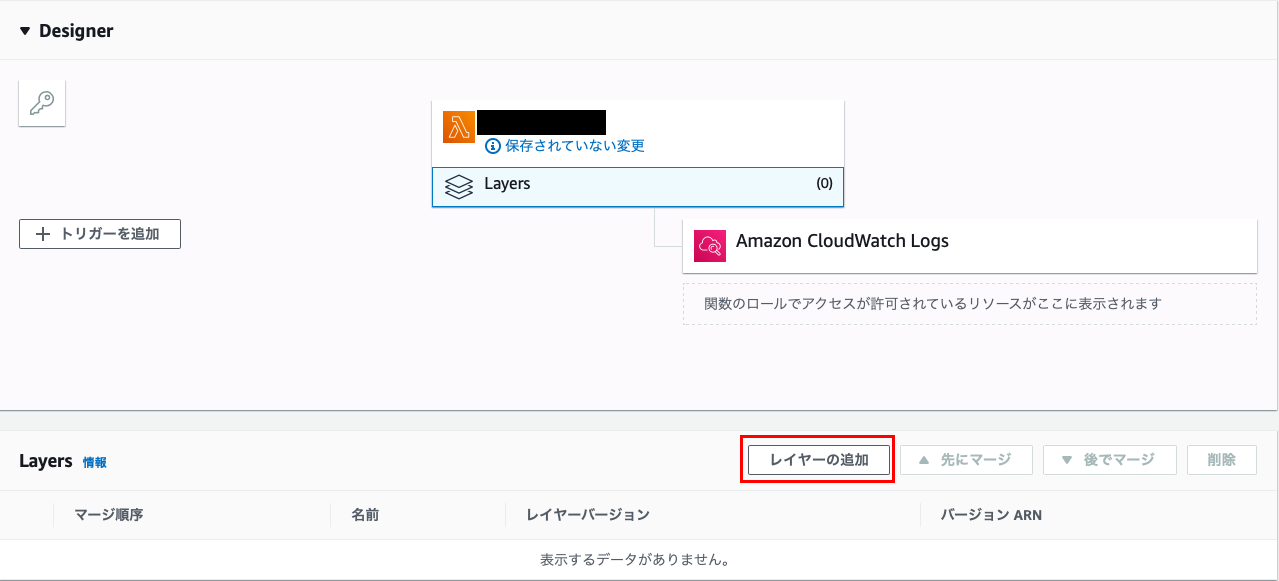
「Layers」画面が表示されましたら、「レイヤーの追加」をクリック
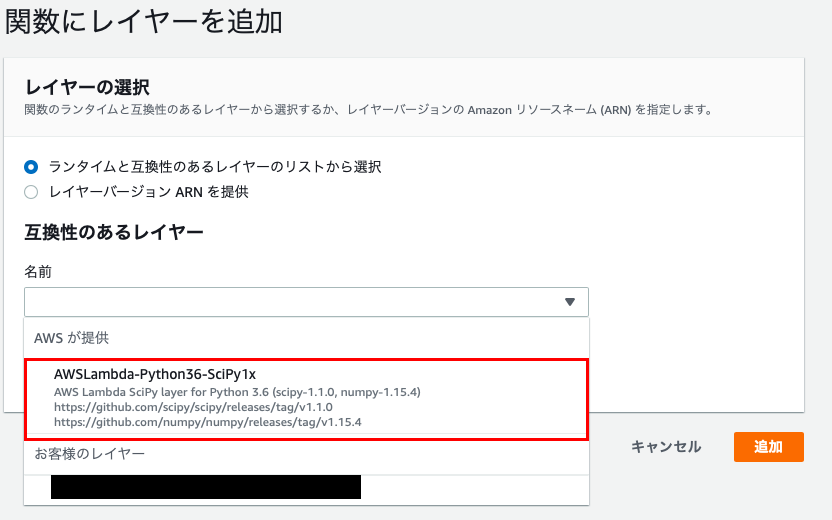
「関数にレイヤーを追加」画面が表示されましたら、「互換性のあるレイヤー」のプルダウンから
「AWSが提供」となっているLambda-Layerを選択します。
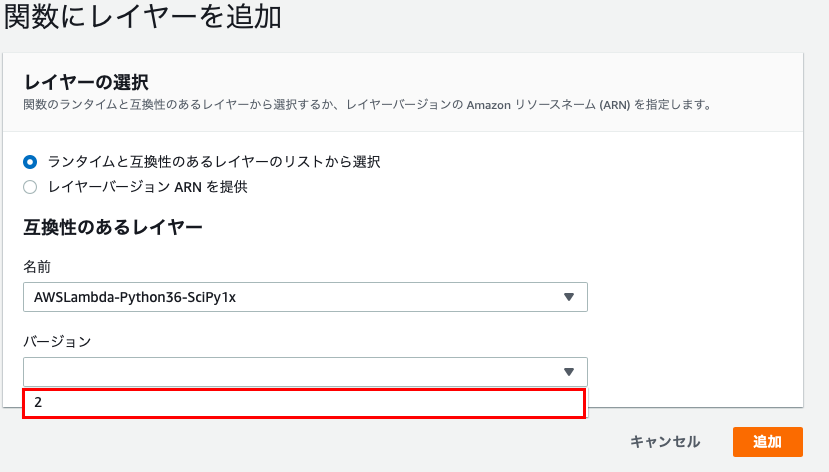
「バージョン」もプルダウンから最新のものを選択します。
最後に「追加」をクリック

「Layers」画面に先ほど選択したLayerが追加されていれば、OKです!
③は以下のサイトを参考にLambda関数の実装、Serverlessの設定を行いました!
・AWS LambdaでTensorFlow 2.0を使った画像分類
Lambdaの構成もほぼ同じ内容となります。
・TensorFlowは不要なファイルを削除し、tmpディレクトリ配下に展開
・TensorFlow以外のライブラリはLambda-Layerとしてデプロイ
Lambdaの構成については上記のサイトで懇切丁寧に解説されていますので、
そちらをご参照ください。
Lambda関数の実装は以下の通りです。
try:
import unzip_requirements
except ImportError:
pass
import io
import os
import json
import time
import boto3
import h5py
from boto3.session import Session
from tensorflow.keras.models import load_model
import itertools
import numpy as np
session = Session()
s3_client = session.client("s3")
def lambda_handler(event, context):
# 変数一覧
explanatory_variable = event["explanatory_variable"] # 説明変数
MODEL_NAME = event["model_name"] # モデル名
MODEL_BUCKET = "モデルを格納しているS3バケット名"
winner_label = ["1", "2", "3", "4", "5", "6"] # 目的変数のラベル(単勝予想)
result_list = [] # 予想結果
# S3からモデルを取得する
MODEL_PATH = os.path.join('/tmp', MODEL_NAME)
s3_client.download_file(MODEL_BUCKET, MODEL_NAME, MODEL_PATH)
model = load_model(MODEL_PATH, compile=False)
# 説明変数をNumpy配列に変換する
explanatory_variable = np.array(explanatory_variable)
explanatory_variable = explanatory_variable.reshape(1,-1)
# 単勝予想を実施し、予想上位2つを取得する
result = model.predict(explanatory_variable, batch_size=50,verbose=0)
predict1 = winner_label[np.argmax(result)]
result_list.append(predict1)
result = result[0]
index = np.where(result==np.sort(result)[-2])[0]
predict2 = winner_label[index[0]]
result_list.append(predict2)
return result_list
TensorFlowをインストールするためのServerlessの設定は以下の通りです。
service: xxx
plugins:
- serverless-python-requirements
provider:
name: aws
region: ap-northeast-1
runtime: python3.6
stage: dev
custom:
pythonRequirements:
dockerizePip: true
zip: true
slim: true
slimPatterns:
- "**/debug"
- "**/grpc"
- "**/h5py"
- "**/markdown"
- "**/numpy"
- "**/pkg_resources"
- "**/setuptools"
- "**/tensorboard/plugins"
- "**/tensorboard/webfiles.zip"
- "**/tensorflow_core/contrib"
- "**/tensorflow_core/examples"
- "**/tensorflow_core/include"
- "**/tensorflow_estimator"
- "**/werkzeug"
- "**/wheel"
requirementsService: xxx-layer
requirementsExport: xxxLayer
requirementsLayer: ${cf:${self:custom.requirementsService}-${self:provider.stage}.${self:custom.requirementsExport}}
iamRoleStatements:
- Effect: Allow
Action:
- s3:*
Resource:
Fn::Join:
- ""
- - "arn:aws:s3:::"
- ${self:provider.environment.BUCKET}
- "/*"
environment:
BUCKET: yyybucket
functions:
handler:
handler: handler.lambda_handler
timeout: 600
memory: 1024
layers:
- ${self:custom.requirementsLayer}
absl-py==0.8.0
astor==0.8.0
gast==0.3.2
google-pasta==0.1.7
grpcio==1.23.0
Keras-Applications==1.0.8
Keras-Preprocessing==1.1.0
Markdown==3.1.1
protobuf==3.9.2
tensorboard==1.14.0
tensorflow==1.14.0
tensorflow-estimator==1.14.0
termcolor==1.1.0
Werkzeug==0.16.0
wrapt==1.11.2
最後にTensorFlow以外のライブラリをインストールする
Serverlessの設定は以下の通りです。
service: xxxlayer
plugins:
- serverless-python-requirements
custom:
pythonRequirements:
dockerizePip: true
layer:
compatibleRuntimes:
- python3.6
slim: true
strip: false
provider:
name: aws
runtime: python3.6
stage: dev
region: ap-northeast-1
resources:
Outputs:
xxxLayer:
Value:
Ref: PythonRequirementsLambdaLayer
h5py==2.10.0
six==1.12.0
numpy==1.17.2
これらを作成し、$ serverless deployを実行してください。
④は以下のようなLambda関数でDynamo DBの呼び出しを行なっています。
Dynamo DBからデータを取得できた場合はその結果を返却します。
取得できなかった場合は①〜③を順に呼び出しています。
import boto3
import json
def lambda_handler(event, context):
print(event)
#パラメータ取得
hd = event["date"]
jcd = event["jcd"]
rno = event["raceNo"]
#date = "20160101"
#jcd = "23"
#raceNo = "1"
#boto3からDynamoDBアクセスのためのオブジェクト取得
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table('Race')
#getItemメソッドの呼び出し(主キー検索)
response = table.get_item(
Key={
#主キー情報を設定
'date_jcd': hd +"_"+jcd,
'raceNo': rno
}
)
#responseの正体は、Itemなどのキーが定義された辞書型オブジェクト
print(response)
# 予想結果が取得できた場合は、そのまま返却する。
if 'Item' in response :
print("予想済み")
item = response['Item']
return {
'statusCode': 200,
'body': json.dumps(item["predict_result"])
}
else:
clientLambda = boto3.client("lambda")
jcd = event["jcd"] # レース会場
hd = event["hd"] # 日付
rno = event["rno"] # レースNo
predict_type_winner = "winner"
result_list = []
# レースデータを取得する
one_race_data = collect_one_race_data(jcd, hd, rno, clientLambda)
# レースを実施していない or 選手情報が足りない場合は順位予想を行わない
if one_race_data[0] == "0":
result_list = one_race_data
return result_list
# 単勝予想用の説明変数を取得する
explanatory_variable_winner =
arrenge_explanatory_variable(one_race_data, clientLambda)
# 単勝予想を行う
winner_list = predict(
explanatory_variable_winner,
rno, predict_type_winner, clientLambda)
result_list.extend(winner_list)
# 予想結果を登録する
db_result = table.put_item(
Item={
'date_jcd': hd +"_"+jcd,
'raceNo': rno,
'predict_result': predict_result
}
)
return {
'statusCode': 200,
'body': json.dumps(predict_result)
}
# レース情報を収集する
def collect_one_race_data(jcd, hd, rno, clientLambda):
collect_params = {
"jcd": jcd,
"hd": hd,
"rno": rno
}
collect_res = clientLambda.invoke(
FunctionName = "collect_race_data",
InvocationType = "RequestResponse",
Payload=json.dumps(collect_params)
)
one_race_data = json.loads(collect_res["Payload"].read())
return one_race_data
# 競艇データを説明変数に変換する
def arrenge_explanatory_variable(one_race_data, clientLambda):
arrange_params = {
"one_race_data": one_race_data
}
arrange_res = clientLambda.invoke(
FunctionName = "arrange_data",
InvocationType = "RequestResponse",
Payload=json.dumps(arrange_params)
)
explanatory_variable = json.loads(arrange_res["Payload"].read())
return explanatory_variable
# 競艇予想を実施する
def predict(explanatory_variable, rno, predict_type, clientLambda):
# 予想に使用するモデル一覧
model_list = {"winner": "model_winner.h5"}
# 予想に使用するモデル
model_name = model_list[predict_type]
predict_params = {
"explanatory_variable": explanatory_variable,
"model_name": model_name,
"result3_sign": result3_sign
}
predict_res = clientLambda.invoke(
FunctionName = "predict",
InvocationType = "RequestResponse",
Payload=json.dumps(predict_params)
)
result_predict = json.loads(predict_res["Payload"].read())
return result_predict
これでLambda関数の実装は全て完了です。
あとはS3に機械学習モデルをアップロードし、
S3のgetObjectを許可し、
LambdaからLambdaを呼び出せるようにIAMロールを設定すればようやく完成です!!
④を実行すると、1位予想結果を確率が高い順に2つ返却します。
['1','4']
ヤッタネ!
8.最後に
今回の実装はやっていることはそこまで難しいものではありません。
しかし、自分の知識不足や確認不足により私の夏休みはこのプログラミングに
全て捧げることになりました。
もし、同じような悩みを抱えている方がおりましたら微力ながらお力添えできれば幸いです。
まだまだServerlessの知識などは不足しているため、もし参考となる書籍などご存知の方が
おりましたら、ご紹介ください。
最後になりますが、今回のプログラミングではたくさんの方の記事を参考とさせていただきました。
この場を借りてお礼申し上げます。