MobileNet-SSD-RealSense 
OpenVINO-YoloV3 
I wrote an English article, here
◆ これまでの検証の経過
(2) CPU単体で無理やり RealTime Semantic Segmentaion 【その1】 [1 FPS / CPU only]
(4) CPU単体で無理やり YoloV3 OpenVINO [4-5 FPS / CPU only] 【その3】
(5) RaspberryPi3をNeural Compute Stick 2(NCS2 1本)で猛烈ブーストしMobileNet-SSDの爆速パフォーマンスを体感する (Core i7なら21 FPS)
(6) CPU単体で無理やり tiny-YoloV3 OpenVINO [60 FPS / CPU only] 今度こそ絶対速いと感じるに違いない、というか、速すぎです 【その4】
(7) CPU単体で無理やり tiny-YoloV3 OpenVINO [30 FPS / CPU only] Python実装版 【その5】
◆ はじめに
2019.01.04 パフォーマンスを4倍にチューニングしました。この記事より下記リンクの記事のほうが爆速です。
[24 FPS, 48 FPS] RaspberryPi3 + Neural Compute Stick 2 一本で真の力を引き出し、悟空が真のスーパーサイヤ「人」となった日
2019.01.04 あるいは、YoloV3なら下記の記事のほうが高速です。
[13 FPS] NCS2 x4 + Full size YoloV3 の性能を3倍に改善しました
連休に入ってコードをゆっくり書く時間がとれたため、NCS2のマルチスティック対応を実施しました。
年末・年始はずっとコーディングと情報収集をしていました。
暇な奴、とか冷たいこと言わないでください。
確かに暇なんで。
今回は MobileNet-SSD と YoloV3 をNCS2マルチスティックで並列推論を行ってブーストしてみます。
なお、 RaspberryPi3 と Core i7機 の2台で検証します。
既に、NCS2では初代NCSの2倍近いパフォーマンスが得られることが前回までの検証で分かっています。
ただ、RaspberryPi3はUSB2.0ポートしか装備していないため、期待どおりの推論性能が出るのか、また、ARM CPUでどれほどの性能を維持できるのか、が今回の検証のポイントになります。
ちなみに、マルチプロセスによるNCS2のまともな並列推論の実装は、Intelのサンプルには有りません。
日本人ですので気軽にコメントください。
◆ 検証環境
- Core i7 Laptop PC (Ubuntu 16.04 x86_64)
- RaspberryPi3 (Raspbian Stretch)
- OpenVINO toolkit 2018 R5 (2018.5.445)
- Python 3.5
- OpenCV 4.0.1-openvino
- MobileNet-SSD (Pascal VOC)
- YoloV3 (MS-COCO)
- Neural Compute Stick 2 (NCS2) x 4本
- Self-Powered USB HUB 2.0 (6ポート)
◆ 実装
- NCSDK から OpenVINOへ移行したことにより、APIの仕様が大幅に変更されています。
- OpenVINOには、Neural Compute Stick 1本1本を効率良く制御するメソッドは存在しません。
- OpenVINOには、Neural Compute Stick の接続状態を検出するメソッドは存在しません。
- OpenVINOには、Stick の内部温度を計測するメソッドは存在しません。
以上の大幅な仕様変更により、実装にはかなり苦戦しました。
Stick 1本にプロセス1個を割り当てることができません。
今回は heapq を使用して1プロセスでゴリゴリにトリッキーな実装をしてしまいました。
MultiThread では、Python の GIL問題(Global Interpreter Lock) の影響でパフォーマンスが上がらないことは今までの検証で明らかになっていますので、あくまで MultiProcess にこだわっています。
● MobileNet-SSD の MultiProcess実装
この記事を書いている最中に、私のリポジトリに対してフランス人のピエールさんからフィードバックをいただけました。
下記のロジックを仕込むと、より性能が良くなるみたいだよ、とのことです。
後日実験してみようと思います。
Many thanks for your code.
Got about 15 FPS, using USB Webcam on Rpi 3 B+ and 2 ncs2.
Have you bench using 4 ncs on rpi ?
I use https://github.com/umlaeute/v4l2loopback to feed trafic cam view.
I get better result starting cam in 640x480 and cropping like this:
color_image=cv2.resize(color_image,(532,400))
color_image=color_image[100:100+300,116:116+300]
ピエールさんのロジックはまだ反映していませんが、私が書いた MobileNet-SSD の OpenVINO実装 は下記です。
<MobileNet-SSD + MultiStick + MultiProcess>
※ RealSense対応や背景透過のロジックを残したままにしていますので、かなりゴチャゴチャしています。
import sys
if sys.version_info.major < 3 or sys.version_info.minor < 4:
print("Please using python3.4 or greater!")
sys.exit(1)
import pyrealsense2 as rs
import numpy as np
import cv2, io, time, argparse, re
from os import system
from os.path import isfile, join
from time import sleep
import multiprocessing as mp
from openvino.inference_engine import IENetwork, IEPlugin
import heapq
pipeline = None
lastresults = None
threads = []
processes = []
frameBuffer = None
results = None
fps = ""
detectfps = ""
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
graph_folder = ""
cam = None
camera_mode = 0
camera_width = 320
camera_height = 240
window_name = ""
background_transparent_mode = 0
ssd_detection_mode = 1
face_detection_mode = 0
elapsedtime = 0.0
background_img = None
depth_sensor = None
depth_scale = 1.0
align_to = None
align = None
LABELS = [['background',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor'],
['background', 'face']]
def camThread(LABELS, results, frameBuffer, camera_mode, camera_width, camera_height, background_transparent_mode, background_img):
global fps
global detectfps
global lastresults
global framecount
global detectframecount
global time1
global time2
global cam
global window_name
global depth_scale
global align_to
global align
# Configure depth and color streams
# Or
# Open USB Camera streams
if camera_mode == 0:
pipeline = rs.pipeline()
config = rs.config()
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
profile = pipeline.start(config)
depth_sensor = profile.get_device().first_depth_sensor()
depth_scale = depth_sensor.get_depth_scale()
align_to = rs.stream.color
align = rs.align(align_to)
window_name = "RealSense"
elif camera_mode == 1:
cam = cv2.VideoCapture(0)
if cam.isOpened() != True:
print("USB Camera Open Error!!!")
sys.exit(0)
cam.set(cv2.CAP_PROP_FPS, 30)
cam.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)
cam.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)
window_name = "USB Camera"
cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE)
while True:
t1 = time.perf_counter()
# 0:= RealSense Mode
# 1:= USB Camera Mode
if camera_mode == 0:
# Wait for a coherent pair of frames: depth and color
frames = pipeline.wait_for_frames()
depth_frame = frames.get_depth_frame()
color_frame = frames.get_color_frame()
if not depth_frame or not color_frame:
continue
if frameBuffer.full():
frameBuffer.get()
color_image = np.asanyarray(color_frame.get_data())
elif camera_mode == 1:
# USB Camera Stream Read
s, color_image = cam.read()
if not s:
continue
if frameBuffer.full():
frameBuffer.get()
frames = color_image
height = color_image.shape[0]
width = color_image.shape[1]
frameBuffer.put(color_image.copy())
res = None
if not results.empty():
res = results.get(False)
detectframecount += 1
imdraw = overlay_on_image(frames, res, LABELS, camera_mode, background_transparent_mode,
background_img, depth_scale=depth_scale, align=align)
lastresults = res
else:
imdraw = overlay_on_image(frames, lastresults, LABELS, camera_mode, background_transparent_mode,
background_img, depth_scale=depth_scale, align=align)
cv2.imshow(window_name, cv2.resize(imdraw, (width, height)))
if cv2.waitKey(1)&0xFF == ord('q'):
# Stop streaming
if pipeline != None:
pipeline.stop()
sys.exit(0)
## Print FPS
framecount += 1
if framecount >= 15:
fps = "(Playback) {:.1f} FPS".format(time1/15)
detectfps = "(Detection) {:.1f} FPS".format(detectframecount/time2)
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
t2 = time.perf_counter()
elapsedTime = t2-t1
time1 += 1/elapsedTime
time2 += elapsedTime
# l = Search list
# x = Search target value
def searchlist(l, x, notfoundvalue=-1):
if x in l:
return l.index(x)
else:
return notfoundvalue
def inferencer(graph_folder, results, frameBuffer, ssd_detection_mode, face_detection_mode, device_count):
plugin = None
net = None
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
model_xml = join(graph_folder, "MobileNetSSD_deploy.xml")
model_bin = join(graph_folder, "MobileNetSSD_deploy.bin")
plugin = IEPlugin(device="MYRIAD")
net = IENetwork(model=model_xml, weights=model_bin)
input_blob = next(iter(net.inputs))
exec_net = plugin.load(network=net, num_requests=device_count)
while True:
try:
if frameBuffer.empty():
continue
color_image = frameBuffer.get()
prepimg = preprocess_image(color_image)
reqnum = searchlist(inferred_request, 0)
if reqnum > -1:
exec_net.start_async(request_id=reqnum, inputs={input_blob: prepimg})
inferred_request[reqnum] = 1
inferred_cnt += 1
if inferred_cnt == sys.maxsize:
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
heapq.heappush(heap_request, (inferred_cnt, reqnum))
cnt, dev = heapq.heappop(heap_request)
if exec_net.requests[dev].wait(0) == 0:
exec_net.requests[dev].wait(-1)
out = exec_net.requests[dev].outputs["detection_out"].flatten()
results.put([out])
inferred_request[dev] = 0
else:
heapq.heappush(heap_request, (cnt, dev))
except:
import traceback
traceback.print_exc()
def preprocess_image(src):
try:
img = cv2.resize(src, (300, 300))
img = img - 127.5
img = img * 0.007843
img = img[np.newaxis, :, :, :] # Batch size axis add
img = img.transpose((0, 3, 1, 2)) # NHWC to NCHW
return img
except:
import traceback
traceback.print_exc()
def overlay_on_image(frames, object_infos, LABELS, camera_mode, background_transparent_mode, background_img, depth_scale=1.0, align=None):
try:
# 0:=RealSense Mode, 1:=USB Camera Mode
if camera_mode == 0:
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
depth_frame = frames.get_depth_frame()
color_frame = frames.get_color_frame()
elif background_transparent_mode == 1:
aligned_frames = align.process(frames)
depth_frame = aligned_frames.get_depth_frame()
color_frame = aligned_frames.get_color_frame()
depth_dist = depth_frame.as_depth_frame()
depth_image = np.asanyarray(depth_frame.get_data())
color_image = np.asanyarray(color_frame.get_data())
elif camera_mode == 1:
color_image = frames
if isinstance(object_infos, type(None)):
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
return color_image
elif background_transparent_mode == 1:
return background_img
# Show images
height = color_image.shape[0]
width = color_image.shape[1]
entire_pixel = height * width
occupancy_threshold = 0.9
if background_transparent_mode == 0:
img_cp = color_image.copy()
elif background_transparent_mode == 1:
img_cp = background_img.copy()
for (object_info, LABEL) in zip(object_infos, LABELS):
drawing_initial_flag = True
for box_index in range(100):
if object_info[box_index + 1] == 0.0:
break
base_index = box_index * 7
if (not np.isfinite(object_info[base_index]) or
not np.isfinite(object_info[base_index + 1]) or
not np.isfinite(object_info[base_index + 2]) or
not np.isfinite(object_info[base_index + 3]) or
not np.isfinite(object_info[base_index + 4]) or
not np.isfinite(object_info[base_index + 5]) or
not np.isfinite(object_info[base_index + 6])):
continue
x1 = max(0, int(object_info[base_index + 3] * height))
y1 = max(0, int(object_info[base_index + 4] * width))
x2 = min(height, int(object_info[base_index + 5] * height))
y2 = min(width, int(object_info[base_index + 6] * width))
object_info_overlay = object_info[base_index:base_index + 7]
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
min_score_percent = 60
elif background_transparent_mode == 1:
min_score_percent = 20
source_image_width = width
source_image_height = height
base_index = 0
class_id = object_info_overlay[base_index + 1]
percentage = int(object_info_overlay[base_index + 2] * 100)
if (percentage <= min_score_percent):
continue
box_left = int(object_info_overlay[base_index + 3] * source_image_width)
box_top = int(object_info_overlay[base_index + 4] * source_image_height)
box_right = int(object_info_overlay[base_index + 5] * source_image_width)
box_bottom = int(object_info_overlay[base_index + 6] * source_image_height)
# 0:=RealSense Mode, 1:=USB Camera Mode
if camera_mode == 0:
meters = depth_dist.get_distance(box_left+int((box_right-box_left)/2), box_top+int((box_bottom-box_top)/2))
label_text = LABEL[int(class_id)] + " (" + str(percentage) + "%)"+ " {:.2f}".format(meters) + " meters away"
elif camera_mode == 1:
label_text = LABEL[int(class_id)] + " (" + str(percentage) + "%)"
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
box_color = (255, 128, 0)
box_thickness = 1
cv2.rectangle(img_cp, (box_left, box_top), (box_right, box_bottom), box_color, box_thickness)
label_background_color = (125, 175, 75)
label_text_color = (255, 255, 255)
label_size = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)[0]
label_left = box_left
label_top = box_top - label_size[1]
if (label_top < 1):
label_top = 1
label_right = label_left + label_size[0]
label_bottom = label_top + label_size[1]
cv2.rectangle(img_cp, (label_left - 1, label_top - 1), (label_right + 1, label_bottom + 1), label_background_color, -1)
cv2.putText(img_cp, label_text, (label_left, label_bottom), cv2.FONT_HERSHEY_SIMPLEX, 0.5, label_text_color, 1)
elif background_transparent_mode == 1:
clipping_distance = (meters+0.05) / depth_scale
depth_image_3d = np.dstack((depth_image, depth_image, depth_image))
fore = np.where((depth_image_3d > clipping_distance) | (depth_image_3d <= 0), 0, color_image)
area = abs(box_bottom - box_top) * abs(box_right - box_left)
occupancy = area / entire_pixel
if occupancy <= occupancy_threshold:
if drawing_initial_flag == True:
img_cp = fore
drawing_initial_flag = False
else:
img_cp[box_top:box_bottom, box_left:box_right] = cv2.addWeighted(img_cp[box_top:box_bottom, box_left:box_right],
0.85,
fore[box_top:box_bottom, box_left:box_right],
0.85,
0)
cv2.putText(img_cp, fps, (width-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
cv2.putText(img_cp, detectfps, (width-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
return img_cp
except:
import traceback
traceback.print_exc()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-grp','--graph',dest='graph_folder',type=str,default='./lrmodel/MobileNetSSD/',help='OpenVINO lrmodels Path. (Default=./lrmodel/MobileNetSSD/)')
parser.add_argument('-mod','--mode',dest='camera_mode',type=int,default=0,help='Camera Mode. (0:=RealSense Mode, 1:=USB Camera Mode. Defalut=0)')
parser.add_argument('-wd','--width',dest='camera_width',type=int,default=320,help='Width of the frames in the video stream. (USB Camera Mode Only. Default=320)')
parser.add_argument('-ht','--height',dest='camera_height',type=int,default=240,help='Height of the frames in the video stream. (USB Camera Mode Only. Default=240)')
parser.add_argument('-tp','--transparent',dest='background_transparent_mode',type=int,default=0,help='TransparentMode. (RealSense Mode Only. 0:=No background transparent, 1:=Background transparent)')
parser.add_argument('-sd','--ssddetection',dest='ssd_detection_mode',type=int,default=1,help='[Future functions] SSDDetectionMode. (0:=Disabled, 1:=Enabled Default=1)')
parser.add_argument('-fd','--facedetection',dest='face_detection_mode',type=int,default=0,help='[Future functions] FaceDetectionMode. (0:=Disabled, 1:=Full, 2:=Short Default=0)')
parser.add_argument('-numncs','--numberofncs',dest='number_of_ncs',type=int,default=1,help='Number of NCS. (Default=1)')
args = parser.parse_args()
graph_folder = args.graph_folder
camera_mode = args.camera_mode
camera_width = args.camera_width
camera_height = args.camera_height
background_transparent_mode = args.background_transparent_mode
ssd_detection_mode = args.ssd_detection_mode
face_detection_mode = args.face_detection_mode
number_of_ncs = args.number_of_ncs
# 0:=RealSense Mode, 1:=USB Camera Mode
if camera_mode != 0 and camera_mode != 1:
print("Camera Mode Error!! " + str(camera_mode))
sys.exit(0)
if camera_mode != 0 and background_transparent_mode == 1:
background_transparent_mode = 0
if background_transparent_mode == 1:
background_img = np.zeros((camera_height, camera_width, 3), dtype=np.uint8)
if face_detection_mode != 0:
ssd_detection_mode = 0
if ssd_detection_mode == 0 and face_detection_mode != 0:
del(LABELS[0])
try:
mp.set_start_method('forkserver')
frameBuffer = mp.Queue(10)
results = mp.Queue()
# Start streaming
p = mp.Process(target=camThread,
args=(LABELS, results, frameBuffer, camera_mode, camera_width, camera_height, background_transparent_mode, background_img),
daemon=True)
p.start()
processes.append(p)
# Start detection MultiStick
# Activation of inferencer
p = mp.Process(target=inferencer,
args=(graph_folder, results, frameBuffer, ssd_detection_mode, face_detection_mode, number_of_ncs),
daemon=True)
p.start()
processes.append(p)
while True:
sleep(1)
except:
import traceback
traceback.print_exc()
finally:
for p in range(len(processes)):
processes[p].terminate()
print("\n\nFinished\n\n")
下記の部分が推論実行部の本体です。
もはや書いた本人にしか分からないほど意味不明なロジックになってしまいました。
非同期処理と同期処理を無理やり同居させたうえで、ヒープキュー(heapq) を使用して推論対象フレームの前後関係を崩さないように制御しています。
また、接続されているスティック本数分の要素を持つリストを生成し、内部で 「推論中:1、 推論中ではない:0」 というフラグを設け、同じスティックに対して2回以上推論要求を同時に出さないように制御しています。(同じスティックに数回続けて推論要求を出すと Busy!!! と怒られて異常停止します。)
NCSDKと違って低レベルの制御が全く出来ない分、OpenVINOのAPIはかなり扱いづらいです。

while True:
try:
if frameBuffer.empty():
continue
color_image = frameBuffer.get()
prepimg = preprocess_image(color_image)
reqnum = searchlist(inferred_request, 0)
if reqnum > -1:
exec_net.start_async(request_id=reqnum, inputs={input_blob: prepimg})
inferred_request[reqnum] = 1
inferred_cnt += 1
if inferred_cnt == sys.maxsize:
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
heapq.heappush(heap_request, (inferred_cnt, reqnum))
cnt, dev = heapq.heappop(heap_request)
if exec_net.requests[dev].wait(0) == 0:
exec_net.requests[dev].wait(-1)
out = exec_net.requests[dev].outputs["detection_out"].flatten()
results.put([out])
inferred_request[dev] = 0
else:
heapq.heappush(heap_request, (cnt, dev))
except:
import traceback
traceback.print_exc()
● YoloV3 の MultiProcess実装
YoloV3 の OpenVINO実装 は下記です。
import sys, os, cv2, time, heapq, argparse
import numpy as np, math
from openvino.inference_engine import IENetwork, IEPlugin
import multiprocessing as mp
from time import sleep
m_input_size = 416
yolo_scale_13 = 13
yolo_scale_26 = 26
yolo_scale_52 = 52
classes = 80
coords = 4
num = 3
anchors = [10,13,16,30,33,23,30,61,62,45,59,119,116,90,156,198,373,326]
LABELS = ("person", "bicycle", "car", "motorbike", "aeroplane",
"bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird",
"cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack",
"umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat",
"baseball glove", "skateboard", "surfboard","tennis racket", "bottle",
"wine glass", "cup", "fork", "knife", "spoon",
"bowl", "banana", "apple", "sandwich", "orange",
"broccoli", "carrot", "hot dog", "pizza", "donut",
"cake", "chair", "sofa", "pottedplant", "bed",
"diningtable", "toilet", "tvmonitor", "laptop", "mouse",
"remote", "keyboard", "cell phone", "microwave", "oven",
"toaster", "sink", "refrigerator", "book", "clock",
"vase", "scissors", "teddy bear", "hair drier", "toothbrush")
label_text_color = (255, 255, 255)
label_background_color = (125, 175, 75)
box_color = (255, 128, 0)
box_thickness = 1
processes = []
fps = ""
detectfps = ""
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
lastresults = None
def EntryIndex(side, lcoords, lclasses, location, entry):
n = int(location / (side * side))
loc = location % (side * side)
return int(n * side * side * (lcoords + lclasses + 1) + entry * side * side + loc)
class DetectionObject():
xmin = 0
ymin = 0
xmax = 0
ymax = 0
class_id = 0
confidence = 0.0
def __init__(self, x, y, h, w, class_id, confidence, h_scale, w_scale):
self.xmin = int((x - w / 2) * w_scale)
self.ymin = int((y - h / 2) * h_scale)
self.xmax = int(self.xmin + w * w_scale)
self.ymax = int(self.ymin + h * h_scale)
self.class_id = class_id
self.confidence = confidence
def IntersectionOverUnion(box_1, box_2):
width_of_overlap_area = min(box_1.xmax, box_2.xmax) - max(box_1.xmin, box_2.xmin)
height_of_overlap_area = min(box_1.ymax, box_2.ymax) - max(box_1.ymin, box_2.ymin)
area_of_overlap = 0.0
if (width_of_overlap_area < 0.0 or height_of_overlap_area < 0.0):
area_of_overlap = 0.0
else:
area_of_overlap = width_of_overlap_area * height_of_overlap_area
box_1_area = (box_1.ymax - box_1.ymin) * (box_1.xmax - box_1.xmin)
box_2_area = (box_2.ymax - box_2.ymin) * (box_2.xmax - box_2.xmin)
area_of_union = box_1_area + box_2_area - area_of_overlap
return (area_of_overlap / area_of_union)
def ParseYOLOV3Output(blob, resized_im_h, resized_im_w, original_im_h, original_im_w, threshold, objects):
out_blob_h = blob.shape[2]
out_blob_w = blob.shape[3]
side = out_blob_h
anchor_offset = 0
if side == yolo_scale_13:
anchor_offset = 2 * 6
elif side == yolo_scale_26:
anchor_offset = 2 * 3
elif side == yolo_scale_52:
anchor_offset = 2 * 0
side_square = side * side
output_blob = blob.flatten()
for i in range(side_square):
row = int(i / side)
col = int(i % side)
for n in range(num):
obj_index = EntryIndex(side, coords, classes, n * side * side + i, coords)
box_index = EntryIndex(side, coords, classes, n * side * side + i, 0)
scale = output_blob[obj_index]
if (scale < threshold):
continue
x = (col + output_blob[box_index + 0 * side_square]) / side * resized_im_w
y = (row + output_blob[box_index + 1 * side_square]) / side * resized_im_h
height = math.exp(output_blob[box_index + 3 * side_square]) * anchors[anchor_offset + 2 * n + 1]
width = math.exp(output_blob[box_index + 2 * side_square]) * anchors[anchor_offset + 2 * n]
for j in range(classes):
class_index = EntryIndex(side, coords, classes, n * side_square + i, coords + 1 + j)
prob = scale * output_blob[class_index]
if prob < threshold:
continue
obj = DetectionObject(x, y, height, width, j, prob, (original_im_h / resized_im_h), (original_im_w / resized_im_w))
objects.append(obj)
return objects
def camThread(LABELS, results, frameBuffer, camera_width, camera_height):
global fps
global detectfps
global lastresults
global framecount
global detectframecount
global time1
global time2
global cam
global window_name
#cam = cv2.VideoCapture(0)
#if cam.isOpened() != True:
# print("USB Camera Open Error!!!")
# sys.exit(0)
#cam.set(cv2.CAP_PROP_FPS, 30)
#cam.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)
#cam.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)
#window_name = "USB Camera"
#wait_key_time = 1
cam = cv2.VideoCapture("data/input/testvideo4.mp4")
camera_width = int(cam.get(cv2.CAP_PROP_FRAME_WIDTH))
camera_height = int(cam.get(cv2.CAP_PROP_FRAME_HEIGHT))
frame_count = int(cam.get(cv2.CAP_PROP_FRAME_COUNT))
window_name = "Movie File"
wait_key_time = 30
cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE)
while True:
t1 = time.perf_counter()
# USB Camera Stream Read
s, color_image = cam.read()
if not s:
continue
if frameBuffer.full():
frameBuffer.get()
height = color_image.shape[0]
width = color_image.shape[1]
frameBuffer.put(color_image.copy())
if not results.empty():
objects = results.get(False)
detectframecount += 1
for obj in objects:
if obj.confidence < 0.2:
continue
label = obj.class_id
confidence = obj.confidence
if confidence > 0.2:
label_text = LABELS[label] + " (" + "{:.1f}".format(confidence * 100) + "%)"
cv2.rectangle(color_image, (obj.xmin, obj.ymin), (obj.xmax, obj.ymax), box_color, box_thickness)
cv2.putText(color_image, label_text, (obj.xmin, obj.ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, label_text_color, 1)
lastresults = objects
else:
if not isinstance(lastresults, type(None)):
for obj in lastresults:
if obj.confidence < 0.2:
continue
label = obj.class_id
confidence = obj.confidence
if confidence > 0.2:
label_text = LABELS[label] + " (" + "{:.1f}".format(confidence * 100) + "%)"
cv2.rectangle(color_image, (obj.xmin, obj.ymin), (obj.xmax, obj.ymax), box_color, box_thickness)
cv2.putText(color_image, label_text, (obj.xmin, obj.ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, label_text_color, 1)
cv2.putText(color_image, fps, (width-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
cv2.putText(color_image, detectfps, (width-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
cv2.imshow(window_name, cv2.resize(color_image, (width, height)))
if cv2.waitKey(wait_key_time)&0xFF == ord('q'):
sys.exit(0)
## Print FPS
framecount += 1
if framecount >= 15:
fps = "(Playback) {:.1f} FPS".format(time1/15)
detectfps = "(Detection) {:.1f} FPS".format(detectframecount/time2)
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
t2 = time.perf_counter()
elapsedTime = t2-t1
time1 += 1/elapsedTime
time2 += elapsedTime
# l = Search list
# x = Search target value
def searchlist(l, x, notfoundvalue=-1):
if x in l:
return l.index(x)
else:
return notfoundvalue
def inferencer(results, frameBuffer, device_count, camera_width, camera_height):
plugin = None
net = None
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
forced_sleep_time = (1 / device_count)
model_xml = "./lrmodels/YoloV3/FP16/frozen_yolo_v3.xml"
model_bin = "./lrmodels/YoloV3/FP16/frozen_yolo_v3.bin"
plugin = IEPlugin(device="MYRIAD")
net = IENetwork(model=model_xml, weights=model_bin)
input_blob = next(iter(net.inputs))
exec_net = plugin.load(network=net, num_requests=device_count)
while True:
try:
if frameBuffer.empty():
continue
color_image = frameBuffer.get()
prepimg = cv2.resize(color_image, (m_input_size, m_input_size))
prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add
prepimg = prepimg.transpose((0, 3, 1, 2)) # NHWC to NCHW
reqnum = searchlist(inferred_request, 0)
if reqnum > -1:
sleep(forced_sleep_time)
exec_net.start_async(request_id=reqnum, inputs={input_blob: prepimg})
inferred_request[reqnum] = 1
inferred_cnt += 1
if inferred_cnt == sys.maxsize:
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
heapq.heappush(heap_request, (inferred_cnt, reqnum))
cnt, dev = heapq.heappop(heap_request)
if exec_net.requests[dev].wait(0) == 0:
exec_net.requests[dev].wait(-1)
objects = []
outputs = exec_net.requests[dev].outputs
for output in outputs.values():
objects = ParseYOLOV3Output(output, m_input_size, m_input_size, camera_height, camera_width, 0.7, objects)
objlen = len(objects)
for i in range(objlen):
if (objects[i].confidence == 0.0):
continue
for j in range(i + 1, objlen):
if (IntersectionOverUnion(objects[i], objects[j]) >= 0.4):
objects[j].confidence = 0
results.put(objects)
inferred_request[dev] = 0
else:
heapq.heappush(heap_request, (cnt, dev))
except:
import traceback
traceback.print_exc()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-numncs','--numberofncs',dest='number_of_ncs',type=int,default=1,help='Number of NCS. (Default=1)')
args = parser.parse_args()
number_of_ncs = args.number_of_ncs
camera_width = 320
camera_height = 240
try:
mp.set_start_method('forkserver')
frameBuffer = mp.Queue(10)
results = mp.Queue()
# Start streaming
p = mp.Process(target=camThread, args=(LABELS, results, frameBuffer, camera_width, camera_height), daemon=True)
p.start()
processes.append(p)
# Start detection MultiStick
# Activation of inferencer
p = mp.Process(target=inferencer, args=(results, frameBuffer, number_of_ncs, camera_width, camera_height), daemon=True)
p.start()
processes.append(p)
while True:
sleep(1)
except:
import traceback
traceback.print_exc()
finally:
for p in range(len(processes)):
processes[p].terminate()
print("\n\nFinished\n\n")
◆ NCS2を4本挿しした結果
今回は、Core i7 のノートパソコンと RaspberryPi3 の2機種で検証します。
重みの数値精度は共に、 FP16 です。
MobileNet-SSD の モデルサイズ
・・・ 11.6 MB
YoloV3 の モデルサイズ
・・・ 123.8 MB (MobileNetの10倍)
● Core i7 での検証結果
<Core i7 + MobileNet-SSD + NCS2 x4 + MultiProcess, 48 FPS>
速いです。 48 FPS 出ています。 精度の観点でモデル改善の余地はありそうです。
本来、単純計算はできませんが、NCS2 1本あたり、 12 FPS の性能が出ています。
Youtube: https://youtu.be/HJLMB3an_Rw

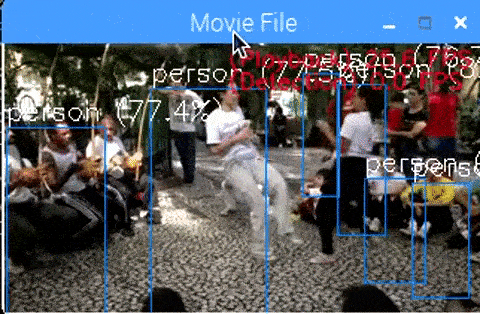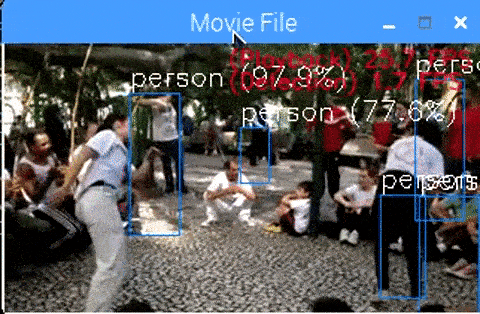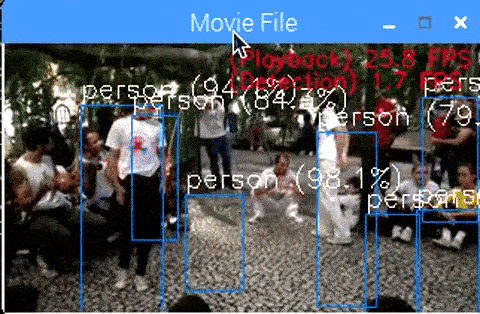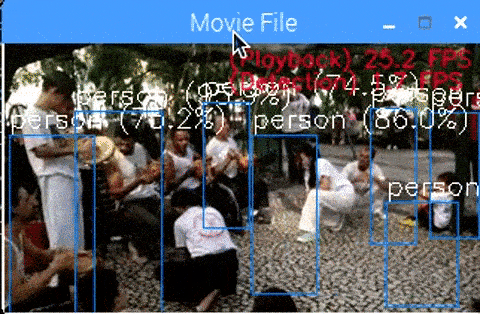
<Core i7 + YoloV3 + NCS2 x4 + MultiProcess, 4 FPS>
4本でブーストしても、わずか 4FPS です。 少々苦しいですね。
しっかりとモデルサイズと推論スピードが反比例しているようです。
ただ、間違いなく初代NCSではこんなに軽快には動作しないでしょう。
非同期ですので、動画は等倍速で再生されています。
カポイエラなのでリアルの動きがゆっくり目なだけです。
tiny-YoloV3は。。。 240 FPS ほど出る想定で無駄に速くなることが想定されますので試していません。
Youtube: https://youtu.be/3mKkPXpIc_U

● RaspberryPi3 での検証結果
<RaspberryPi3 + MobileNet-SSD + NCS2 x4 + MultiProcess, 24 FPS>
期待値よりもかなり遅いです。 が、十分な速さで推論されているとも言えます。
Core i7 との比較により、ARM CPU (Coretex-A57) の性能の低さがボトルネックとなっていることが露見しています。
本来であれば、Neural Compute Stick2 1本あたり、 9 FPS の性能向上が期待されていました。
推論スピードは速いのですが、CPU側で実施している前処理と後処理で大幅に時間を要しています。
これは、RaspberryPi3 に標準搭載されている VideoCoreⅣ を最大限活用するなどの一層トリッキーな実装が必要になると考えます。
Youtube: https://youtu.be/RBU1sDHNqxs

<RaspberryPi3 + YoloV3 + NCS2 x4 + MultiProcess, 1.7 FPS>
とてつもなく遅いです。
さすがにモデルサイズが100MBオーダーともなると、CPUの性能の低さも相まってかなりの低速FPSになってしまいます。
フルサイズのYoloV3をRaspberryPi3で使用するのは無理がありそうです。
Youtube: https://youtu.be/7QIKZ7tizEE
◆ おわりに
- OpenVINOのAPIはもう少し低レベルの制御ができるようにして欲しいです。(Stick1本づつのきめ細やかな制御がしたい。)
- OpenVINOは 1プロセスで複数スティックを制御せざるを得ない仕様です。
- NCSDK のほうが低レベル制御が出来て高パフォーマンスを発揮できていました。
- フルサイズのYoloV3をRaspberryPi3で使用するのは実用に耐えません。
- ARM CPU では、Neural Compute Stick2 の本来の性能を十分に発揮できないことが分かりました。
- 無理してRaspberryPi3にこだわらず、数千円だけプラスで投資して、UP2board や LattePanda Delta / Alpha などの Intel x86系CPU搭載 のエッジコンピュータを手に入れたほうが、NCS2の性能を十分に発揮できそうです。
- RaspberryPi3 で NCS2 を使用する場合は、1本 あるいは 2本の手配までにとどめておくのが良策だと思います。
- 近いうちに、外付けのデバイスに頼らなくても、オンボードにAI特化のチップがどんどん搭載されていくと考えますので、NCS2は取り急ぎ今をしのぎたい方向けのデバイスだと思います。
- OpenVINOによる CPU / GPU / NCS2 実装のノウハウは手に入れたので、今後もしばらくは遊べそうです。
- 環境導入手順が気になる方は、 ページトップのGithubへのリンク 又は ◆ これまでの検証の経過 のリンクを総ナメしてください。
- 年内のオブジェクトディテクションに関する人柱検証はこれで終わりです。(今、1月1日ですけど。。。)
- こちらのデバイスのほうが有望な気がする。 Orange Pi AI Stick 2801 Neural Network Computing Stick Artificial Intelligence
- 公式 LIGHTSPEEUR® 2801S NEURAL ACCELERATOR
[24 FPS] Boost RaspberryPi3 with four Neural Compute Stick 2 (NCS2) MobileNet-SSD / YoloV3 [48 FPS for Core i7]
◆ The course of verification so far
(2) Forcibly with CPU alone RealTime Semantic Segmentaion 【Part.1】 [1 FPS / CPU only]
(4) Forcibly with CPU alone YoloV3 OpenVINO [4-5 FPS / CPU only] 【Part.3】
◆ Introduction
I implemented NCS2's multistick support.
This time I will boost MobileNet-SSD and YoloV3 by parallel inference with NCS2 multistick.
In addition, I will verify with RaspberryPi3 and Core i7 aircraft.
NCS2 knows about nearly twice the performance of the original NCS by verification to the previous round.
Since RaspberryPi 3 has only USB 2.0 port, it will be inferring the inference performance as expected, and, How much performance can be maintained with ARM CPU, It is the point of this verification.
By the way, the implementation of decent parallel inference of NCS2 by multiprocessing is not in Intel's sample.
◆ Verification environment
- Core i7 Laptop PC (Ubuntu 16.04 x86_64)
- RaspberryPi3 (Raspbian Stretch)
- OpenVINO toolkit 2018 R5 (2018.5.445)
- Python 3.5
- OpenCV 4.0.1-openvino
- MobileNet-SSD (Pascal VOC)
- YoloV3 (MS-COCO)
- Neural Compute Stick 2 (NCS2) x 4 Sticks
- Self-Powered USB HUB 2.0 (6 ports)
◆ Implementation
- Due to the transition from NCSDK to OpenVINO, API specification has been changed drastically.
- In OpenVINO, there is no method to control one Neural Compute Stick.
- There is no method for detecting the connection status of Neural Compute Stick in OpenVINO.
- OpenVINO does not have a method to measure Stick's internal temperature.
Due to the above-mentioned drastic specification change, I fought hard for implementation.
One process can not be assigned to one stick.
In MultiThread, it is clarified by past verification that performance does not rise due to Python's GIL problem (Global Interpreter Lock), so I am sticking to MultiProcess to the last.
● MultiProcess implementation of MobileNet-SSD
While writing this article, I received feedback from French Pierre against my repository.
Performance will improve if adding the following logic.
I think I will experiment at a later date.
Many thanks for your code.
Got about 15 FPS, using USB Webcam on Rpi 3 B+ and 2 ncs2.
Have you bench using 4 ncs on rpi ?
I use https://github.com/umlaeute/v4l2loopback to feed trafic cam view.
I get better result starting cam in 640x480 and cropping like this:
color_image=cv2.resize(color_image,(532,400))
color_image=color_image[100:100+300,116:116+300]
Pierre's logic has not yet been reflected, but the OpenVINO implementation of MobileNet-SSD I wrote is below.
<MobileNet-SSD + MultiStick + MultiProcess>
import sys
if sys.version_info.major < 3 or sys.version_info.minor < 4:
print("Please using python3.4 or greater!")
sys.exit(1)
import pyrealsense2 as rs
import numpy as np
import cv2, io, time, argparse, re
from os import system
from os.path import isfile, join
from time import sleep
import multiprocessing as mp
from openvino.inference_engine import IENetwork, IEPlugin
import heapq
pipeline = None
lastresults = None
threads = []
processes = []
frameBuffer = None
results = None
fps = ""
detectfps = ""
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
graph_folder = ""
cam = None
camera_mode = 0
camera_width = 320
camera_height = 240
window_name = ""
background_transparent_mode = 0
ssd_detection_mode = 1
face_detection_mode = 0
elapsedtime = 0.0
background_img = None
depth_sensor = None
depth_scale = 1.0
align_to = None
align = None
LABELS = [['background',
'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor'],
['background', 'face']]
def camThread(LABELS, results, frameBuffer, camera_mode, camera_width, camera_height, background_transparent_mode, background_img):
global fps
global detectfps
global lastresults
global framecount
global detectframecount
global time1
global time2
global cam
global window_name
global depth_scale
global align_to
global align
# Configure depth and color streams
# Or
# Open USB Camera streams
if camera_mode == 0:
pipeline = rs.pipeline()
config = rs.config()
config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
profile = pipeline.start(config)
depth_sensor = profile.get_device().first_depth_sensor()
depth_scale = depth_sensor.get_depth_scale()
align_to = rs.stream.color
align = rs.align(align_to)
window_name = "RealSense"
elif camera_mode == 1:
cam = cv2.VideoCapture(0)
if cam.isOpened() != True:
print("USB Camera Open Error!!!")
sys.exit(0)
cam.set(cv2.CAP_PROP_FPS, 30)
cam.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)
cam.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)
window_name = "USB Camera"
cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE)
while True:
t1 = time.perf_counter()
# 0:= RealSense Mode
# 1:= USB Camera Mode
if camera_mode == 0:
# Wait for a coherent pair of frames: depth and color
frames = pipeline.wait_for_frames()
depth_frame = frames.get_depth_frame()
color_frame = frames.get_color_frame()
if not depth_frame or not color_frame:
continue
if frameBuffer.full():
frameBuffer.get()
color_image = np.asanyarray(color_frame.get_data())
elif camera_mode == 1:
# USB Camera Stream Read
s, color_image = cam.read()
if not s:
continue
if frameBuffer.full():
frameBuffer.get()
frames = color_image
height = color_image.shape[0]
width = color_image.shape[1]
frameBuffer.put(color_image.copy())
res = None
if not results.empty():
res = results.get(False)
detectframecount += 1
imdraw = overlay_on_image(frames, res, LABELS, camera_mode, background_transparent_mode,
background_img, depth_scale=depth_scale, align=align)
lastresults = res
else:
imdraw = overlay_on_image(frames, lastresults, LABELS, camera_mode, background_transparent_mode,
background_img, depth_scale=depth_scale, align=align)
cv2.imshow(window_name, cv2.resize(imdraw, (width, height)))
if cv2.waitKey(1)&0xFF == ord('q'):
# Stop streaming
if pipeline != None:
pipeline.stop()
sys.exit(0)
## Print FPS
framecount += 1
if framecount >= 15:
fps = "(Playback) {:.1f} FPS".format(time1/15)
detectfps = "(Detection) {:.1f} FPS".format(detectframecount/time2)
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
t2 = time.perf_counter()
elapsedTime = t2-t1
time1 += 1/elapsedTime
time2 += elapsedTime
# l = Search list
# x = Search target value
def searchlist(l, x, notfoundvalue=-1):
if x in l:
return l.index(x)
else:
return notfoundvalue
def inferencer(graph_folder, results, frameBuffer, ssd_detection_mode, face_detection_mode, device_count):
plugin = None
net = None
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
model_xml = join(graph_folder, "MobileNetSSD_deploy.xml")
model_bin = join(graph_folder, "MobileNetSSD_deploy.bin")
plugin = IEPlugin(device="MYRIAD")
net = IENetwork(model=model_xml, weights=model_bin)
input_blob = next(iter(net.inputs))
exec_net = plugin.load(network=net, num_requests=device_count)
while True:
try:
if frameBuffer.empty():
continue
color_image = frameBuffer.get()
prepimg = preprocess_image(color_image)
reqnum = searchlist(inferred_request, 0)
if reqnum > -1:
exec_net.start_async(request_id=reqnum, inputs={input_blob: prepimg})
inferred_request[reqnum] = 1
inferred_cnt += 1
if inferred_cnt == sys.maxsize:
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
heapq.heappush(heap_request, (inferred_cnt, reqnum))
cnt, dev = heapq.heappop(heap_request)
if exec_net.requests[dev].wait(0) == 0:
exec_net.requests[dev].wait(-1)
out = exec_net.requests[dev].outputs["detection_out"].flatten()
results.put([out])
inferred_request[dev] = 0
else:
heapq.heappush(heap_request, (cnt, dev))
except:
import traceback
traceback.print_exc()
def preprocess_image(src):
try:
img = cv2.resize(src, (300, 300))
img = img - 127.5
img = img * 0.007843
img = img[np.newaxis, :, :, :] # Batch size axis add
img = img.transpose((0, 3, 1, 2)) # NHWC to NCHW
return img
except:
import traceback
traceback.print_exc()
def overlay_on_image(frames, object_infos, LABELS, camera_mode, background_transparent_mode, background_img, depth_scale=1.0, align=None):
try:
# 0:=RealSense Mode, 1:=USB Camera Mode
if camera_mode == 0:
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
depth_frame = frames.get_depth_frame()
color_frame = frames.get_color_frame()
elif background_transparent_mode == 1:
aligned_frames = align.process(frames)
depth_frame = aligned_frames.get_depth_frame()
color_frame = aligned_frames.get_color_frame()
depth_dist = depth_frame.as_depth_frame()
depth_image = np.asanyarray(depth_frame.get_data())
color_image = np.asanyarray(color_frame.get_data())
elif camera_mode == 1:
color_image = frames
if isinstance(object_infos, type(None)):
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
return color_image
elif background_transparent_mode == 1:
return background_img
# Show images
height = color_image.shape[0]
width = color_image.shape[1]
entire_pixel = height * width
occupancy_threshold = 0.9
if background_transparent_mode == 0:
img_cp = color_image.copy()
elif background_transparent_mode == 1:
img_cp = background_img.copy()
for (object_info, LABEL) in zip(object_infos, LABELS):
drawing_initial_flag = True
for box_index in range(100):
if object_info[box_index + 1] == 0.0:
break
base_index = box_index * 7
if (not np.isfinite(object_info[base_index]) or
not np.isfinite(object_info[base_index + 1]) or
not np.isfinite(object_info[base_index + 2]) or
not np.isfinite(object_info[base_index + 3]) or
not np.isfinite(object_info[base_index + 4]) or
not np.isfinite(object_info[base_index + 5]) or
not np.isfinite(object_info[base_index + 6])):
continue
x1 = max(0, int(object_info[base_index + 3] * height))
y1 = max(0, int(object_info[base_index + 4] * width))
x2 = min(height, int(object_info[base_index + 5] * height))
y2 = min(width, int(object_info[base_index + 6] * width))
object_info_overlay = object_info[base_index:base_index + 7]
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
min_score_percent = 60
elif background_transparent_mode == 1:
min_score_percent = 20
source_image_width = width
source_image_height = height
base_index = 0
class_id = object_info_overlay[base_index + 1]
percentage = int(object_info_overlay[base_index + 2] * 100)
if (percentage <= min_score_percent):
continue
box_left = int(object_info_overlay[base_index + 3] * source_image_width)
box_top = int(object_info_overlay[base_index + 4] * source_image_height)
box_right = int(object_info_overlay[base_index + 5] * source_image_width)
box_bottom = int(object_info_overlay[base_index + 6] * source_image_height)
# 0:=RealSense Mode, 1:=USB Camera Mode
if camera_mode == 0:
meters = depth_dist.get_distance(box_left+int((box_right-box_left)/2), box_top+int((box_bottom-box_top)/2))
label_text = LABEL[int(class_id)] + " (" + str(percentage) + "%)"+ " {:.2f}".format(meters) + " meters away"
elif camera_mode == 1:
label_text = LABEL[int(class_id)] + " (" + str(percentage) + "%)"
# 0:= No background transparent, 1:= Background transparent
if background_transparent_mode == 0:
box_color = (255, 128, 0)
box_thickness = 1
cv2.rectangle(img_cp, (box_left, box_top), (box_right, box_bottom), box_color, box_thickness)
label_background_color = (125, 175, 75)
label_text_color = (255, 255, 255)
label_size = cv2.getTextSize(label_text, cv2.FONT_HERSHEY_SIMPLEX, 0.5, 1)[0]
label_left = box_left
label_top = box_top - label_size[1]
if (label_top < 1):
label_top = 1
label_right = label_left + label_size[0]
label_bottom = label_top + label_size[1]
cv2.rectangle(img_cp, (label_left - 1, label_top - 1), (label_right + 1, label_bottom + 1), label_background_color, -1)
cv2.putText(img_cp, label_text, (label_left, label_bottom), cv2.FONT_HERSHEY_SIMPLEX, 0.5, label_text_color, 1)
elif background_transparent_mode == 1:
clipping_distance = (meters+0.05) / depth_scale
depth_image_3d = np.dstack((depth_image, depth_image, depth_image))
fore = np.where((depth_image_3d > clipping_distance) | (depth_image_3d <= 0), 0, color_image)
area = abs(box_bottom - box_top) * abs(box_right - box_left)
occupancy = area / entire_pixel
if occupancy <= occupancy_threshold:
if drawing_initial_flag == True:
img_cp = fore
drawing_initial_flag = False
else:
img_cp[box_top:box_bottom, box_left:box_right] = cv2.addWeighted(img_cp[box_top:box_bottom, box_left:box_right],
0.85,
fore[box_top:box_bottom, box_left:box_right],
0.85,
0)
cv2.putText(img_cp, fps, (width-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
cv2.putText(img_cp, detectfps, (width-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
return img_cp
except:
import traceback
traceback.print_exc()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-grp','--graph',dest='graph_folder',type=str,default='./lrmodel/MobileNetSSD/',help='OpenVINO lrmodels Path. (Default=./lrmodel/MobileNetSSD/)')
parser.add_argument('-mod','--mode',dest='camera_mode',type=int,default=0,help='Camera Mode. (0:=RealSense Mode, 1:=USB Camera Mode. Defalut=0)')
parser.add_argument('-wd','--width',dest='camera_width',type=int,default=320,help='Width of the frames in the video stream. (USB Camera Mode Only. Default=320)')
parser.add_argument('-ht','--height',dest='camera_height',type=int,default=240,help='Height of the frames in the video stream. (USB Camera Mode Only. Default=240)')
parser.add_argument('-tp','--transparent',dest='background_transparent_mode',type=int,default=0,help='TransparentMode. (RealSense Mode Only. 0:=No background transparent, 1:=Background transparent)')
parser.add_argument('-sd','--ssddetection',dest='ssd_detection_mode',type=int,default=1,help='[Future functions] SSDDetectionMode. (0:=Disabled, 1:=Enabled Default=1)')
parser.add_argument('-fd','--facedetection',dest='face_detection_mode',type=int,default=0,help='[Future functions] FaceDetectionMode. (0:=Disabled, 1:=Full, 2:=Short Default=0)')
parser.add_argument('-numncs','--numberofncs',dest='number_of_ncs',type=int,default=1,help='Number of NCS. (Default=1)')
args = parser.parse_args()
graph_folder = args.graph_folder
camera_mode = args.camera_mode
camera_width = args.camera_width
camera_height = args.camera_height
background_transparent_mode = args.background_transparent_mode
ssd_detection_mode = args.ssd_detection_mode
face_detection_mode = args.face_detection_mode
number_of_ncs = args.number_of_ncs
# 0:=RealSense Mode, 1:=USB Camera Mode
if camera_mode != 0 and camera_mode != 1:
print("Camera Mode Error!! " + str(camera_mode))
sys.exit(0)
if camera_mode != 0 and background_transparent_mode == 1:
background_transparent_mode = 0
if background_transparent_mode == 1:
background_img = np.zeros((camera_height, camera_width, 3), dtype=np.uint8)
if face_detection_mode != 0:
ssd_detection_mode = 0
if ssd_detection_mode == 0 and face_detection_mode != 0:
del(LABELS[0])
try:
mp.set_start_method('forkserver')
frameBuffer = mp.Queue(10)
results = mp.Queue()
# Start streaming
p = mp.Process(target=camThread,
args=(LABELS, results, frameBuffer, camera_mode, camera_width, camera_height, background_transparent_mode, background_img),
daemon=True)
p.start()
processes.append(p)
# Start detection MultiStick
# Activation of inferencer
p = mp.Process(target=inferencer,
args=(graph_folder, results, frameBuffer, ssd_detection_mode, face_detection_mode, number_of_ncs),
daemon=True)
p.start()
processes.append(p)
while True:
sleep(1)
except:
import traceback
traceback.print_exc()
finally:
for p in range(len(processes)):
processes[p].terminate()
print("\n\nFinished\n\n")
The following part is the body of the inference execution part.
Logic has become complicated unnecessarily.
I forcibly live asynchronous processing and synchronous processing, and use heap queue (heapq) to control so that the context of the inference target frame is not destroyed.
Unlike NCSDK, low level control is not possible at all. OpenVINO API is very inconvenient.
while True:
try:
if frameBuffer.empty():
continue
color_image = frameBuffer.get()
prepimg = preprocess_image(color_image)
reqnum = searchlist(inferred_request, 0)
if reqnum > -1:
exec_net.start_async(request_id=reqnum, inputs={input_blob: prepimg})
inferred_request[reqnum] = 1
inferred_cnt += 1
if inferred_cnt == sys.maxsize:
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
heapq.heappush(heap_request, (inferred_cnt, reqnum))
cnt, dev = heapq.heappop(heap_request)
if exec_net.requests[dev].wait(0) == 0:
exec_net.requests[dev].wait(-1)
out = exec_net.requests[dev].outputs["detection_out"].flatten()
results.put([out])
inferred_request[dev] = 0
else:
heapq.heappush(heap_request, (cnt, dev))
except:
import traceback
traceback.print_exc()
● MultiProcess implementation of YoloV3
The OpenVINO implementation of YoloV3 is as follows.
import sys, os, cv2, time, heapq, argparse
import numpy as np, math
from openvino.inference_engine import IENetwork, IEPlugin
import multiprocessing as mp
from time import sleep
m_input_size = 416
yolo_scale_13 = 13
yolo_scale_26 = 26
yolo_scale_52 = 52
classes = 80
coords = 4
num = 3
anchors = [10,13,16,30,33,23,30,61,62,45,59,119,116,90,156,198,373,326]
LABELS = ("person", "bicycle", "car", "motorbike", "aeroplane",
"bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird",
"cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack",
"umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat",
"baseball glove", "skateboard", "surfboard","tennis racket", "bottle",
"wine glass", "cup", "fork", "knife", "spoon",
"bowl", "banana", "apple", "sandwich", "orange",
"broccoli", "carrot", "hot dog", "pizza", "donut",
"cake", "chair", "sofa", "pottedplant", "bed",
"diningtable", "toilet", "tvmonitor", "laptop", "mouse",
"remote", "keyboard", "cell phone", "microwave", "oven",
"toaster", "sink", "refrigerator", "book", "clock",
"vase", "scissors", "teddy bear", "hair drier", "toothbrush")
label_text_color = (255, 255, 255)
label_background_color = (125, 175, 75)
box_color = (255, 128, 0)
box_thickness = 1
processes = []
fps = ""
detectfps = ""
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
lastresults = None
def EntryIndex(side, lcoords, lclasses, location, entry):
n = int(location / (side * side))
loc = location % (side * side)
return int(n * side * side * (lcoords + lclasses + 1) + entry * side * side + loc)
class DetectionObject():
xmin = 0
ymin = 0
xmax = 0
ymax = 0
class_id = 0
confidence = 0.0
def __init__(self, x, y, h, w, class_id, confidence, h_scale, w_scale):
self.xmin = int((x - w / 2) * w_scale)
self.ymin = int((y - h / 2) * h_scale)
self.xmax = int(self.xmin + w * w_scale)
self.ymax = int(self.ymin + h * h_scale)
self.class_id = class_id
self.confidence = confidence
def IntersectionOverUnion(box_1, box_2):
width_of_overlap_area = min(box_1.xmax, box_2.xmax) - max(box_1.xmin, box_2.xmin)
height_of_overlap_area = min(box_1.ymax, box_2.ymax) - max(box_1.ymin, box_2.ymin)
area_of_overlap = 0.0
if (width_of_overlap_area < 0.0 or height_of_overlap_area < 0.0):
area_of_overlap = 0.0
else:
area_of_overlap = width_of_overlap_area * height_of_overlap_area
box_1_area = (box_1.ymax - box_1.ymin) * (box_1.xmax - box_1.xmin)
box_2_area = (box_2.ymax - box_2.ymin) * (box_2.xmax - box_2.xmin)
area_of_union = box_1_area + box_2_area - area_of_overlap
return (area_of_overlap / area_of_union)
def ParseYOLOV3Output(blob, resized_im_h, resized_im_w, original_im_h, original_im_w, threshold, objects):
out_blob_h = blob.shape[2]
out_blob_w = blob.shape[3]
side = out_blob_h
anchor_offset = 0
if side == yolo_scale_13:
anchor_offset = 2 * 6
elif side == yolo_scale_26:
anchor_offset = 2 * 3
elif side == yolo_scale_52:
anchor_offset = 2 * 0
side_square = side * side
output_blob = blob.flatten()
for i in range(side_square):
row = int(i / side)
col = int(i % side)
for n in range(num):
obj_index = EntryIndex(side, coords, classes, n * side * side + i, coords)
box_index = EntryIndex(side, coords, classes, n * side * side + i, 0)
scale = output_blob[obj_index]
if (scale < threshold):
continue
x = (col + output_blob[box_index + 0 * side_square]) / side * resized_im_w
y = (row + output_blob[box_index + 1 * side_square]) / side * resized_im_h
height = math.exp(output_blob[box_index + 3 * side_square]) * anchors[anchor_offset + 2 * n + 1]
width = math.exp(output_blob[box_index + 2 * side_square]) * anchors[anchor_offset + 2 * n]
for j in range(classes):
class_index = EntryIndex(side, coords, classes, n * side_square + i, coords + 1 + j)
prob = scale * output_blob[class_index]
if prob < threshold:
continue
obj = DetectionObject(x, y, height, width, j, prob, (original_im_h / resized_im_h), (original_im_w / resized_im_w))
objects.append(obj)
return objects
def camThread(LABELS, results, frameBuffer, camera_width, camera_height):
global fps
global detectfps
global lastresults
global framecount
global detectframecount
global time1
global time2
global cam
global window_name
#cam = cv2.VideoCapture(0)
#if cam.isOpened() != True:
# print("USB Camera Open Error!!!")
# sys.exit(0)
#cam.set(cv2.CAP_PROP_FPS, 30)
#cam.set(cv2.CAP_PROP_FRAME_WIDTH, camera_width)
#cam.set(cv2.CAP_PROP_FRAME_HEIGHT, camera_height)
#window_name = "USB Camera"
#wait_key_time = 1
cam = cv2.VideoCapture("data/input/testvideo4.mp4")
camera_width = int(cam.get(cv2.CAP_PROP_FRAME_WIDTH))
camera_height = int(cam.get(cv2.CAP_PROP_FRAME_HEIGHT))
frame_count = int(cam.get(cv2.CAP_PROP_FRAME_COUNT))
window_name = "Movie File"
wait_key_time = 30
cv2.namedWindow(window_name, cv2.WINDOW_AUTOSIZE)
while True:
t1 = time.perf_counter()
# USB Camera Stream Read
s, color_image = cam.read()
if not s:
continue
if frameBuffer.full():
frameBuffer.get()
height = color_image.shape[0]
width = color_image.shape[1]
frameBuffer.put(color_image.copy())
if not results.empty():
objects = results.get(False)
detectframecount += 1
for obj in objects:
if obj.confidence < 0.2:
continue
label = obj.class_id
confidence = obj.confidence
if confidence > 0.2:
label_text = LABELS[label] + " (" + "{:.1f}".format(confidence * 100) + "%)"
cv2.rectangle(color_image, (obj.xmin, obj.ymin), (obj.xmax, obj.ymax), box_color, box_thickness)
cv2.putText(color_image, label_text, (obj.xmin, obj.ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, label_text_color, 1)
lastresults = objects
else:
if not isinstance(lastresults, type(None)):
for obj in lastresults:
if obj.confidence < 0.2:
continue
label = obj.class_id
confidence = obj.confidence
if confidence > 0.2:
label_text = LABELS[label] + " (" + "{:.1f}".format(confidence * 100) + "%)"
cv2.rectangle(color_image, (obj.xmin, obj.ymin), (obj.xmax, obj.ymax), box_color, box_thickness)
cv2.putText(color_image, label_text, (obj.xmin, obj.ymin - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.6, label_text_color, 1)
cv2.putText(color_image, fps, (width-170,15), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
cv2.putText(color_image, detectfps, (width-170,30), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (38,0,255), 1, cv2.LINE_AA)
cv2.imshow(window_name, cv2.resize(color_image, (width, height)))
if cv2.waitKey(wait_key_time)&0xFF == ord('q'):
sys.exit(0)
## Print FPS
framecount += 1
if framecount >= 15:
fps = "(Playback) {:.1f} FPS".format(time1/15)
detectfps = "(Detection) {:.1f} FPS".format(detectframecount/time2)
framecount = 0
detectframecount = 0
time1 = 0
time2 = 0
t2 = time.perf_counter()
elapsedTime = t2-t1
time1 += 1/elapsedTime
time2 += elapsedTime
# l = Search list
# x = Search target value
def searchlist(l, x, notfoundvalue=-1):
if x in l:
return l.index(x)
else:
return notfoundvalue
def inferencer(results, frameBuffer, device_count, camera_width, camera_height):
plugin = None
net = None
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
forced_sleep_time = (1 / device_count)
model_xml = "./lrmodels/YoloV3/FP16/frozen_yolo_v3.xml"
model_bin = "./lrmodels/YoloV3/FP16/frozen_yolo_v3.bin"
plugin = IEPlugin(device="MYRIAD")
net = IENetwork(model=model_xml, weights=model_bin)
input_blob = next(iter(net.inputs))
exec_net = plugin.load(network=net, num_requests=device_count)
while True:
try:
if frameBuffer.empty():
continue
color_image = frameBuffer.get()
prepimg = cv2.resize(color_image, (m_input_size, m_input_size))
prepimg = prepimg[np.newaxis, :, :, :] # Batch size axis add
prepimg = prepimg.transpose((0, 3, 1, 2)) # NHWC to NCHW
reqnum = searchlist(inferred_request, 0)
if reqnum > -1:
sleep(forced_sleep_time)
exec_net.start_async(request_id=reqnum, inputs={input_blob: prepimg})
inferred_request[reqnum] = 1
inferred_cnt += 1
if inferred_cnt == sys.maxsize:
inferred_request = [0] * device_count
heap_request = []
inferred_cnt = 0
heapq.heappush(heap_request, (inferred_cnt, reqnum))
cnt, dev = heapq.heappop(heap_request)
if exec_net.requests[dev].wait(0) == 0:
exec_net.requests[dev].wait(-1)
objects = []
outputs = exec_net.requests[dev].outputs
for output in outputs.values():
objects = ParseYOLOV3Output(output, m_input_size, m_input_size, camera_height, camera_width, 0.7, objects)
objlen = len(objects)
for i in range(objlen):
if (objects[i].confidence == 0.0):
continue
for j in range(i + 1, objlen):
if (IntersectionOverUnion(objects[i], objects[j]) >= 0.4):
objects[j].confidence = 0
results.put(objects)
inferred_request[dev] = 0
else:
heapq.heappush(heap_request, (cnt, dev))
except:
import traceback
traceback.print_exc()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-numncs','--numberofncs',dest='number_of_ncs',type=int,default=1,help='Number of NCS. (Default=1)')
args = parser.parse_args()
number_of_ncs = args.number_of_ncs
camera_width = 320
camera_height = 240
try:
mp.set_start_method('forkserver')
frameBuffer = mp.Queue(10)
results = mp.Queue()
# Start streaming
p = mp.Process(target=camThread, args=(LABELS, results, frameBuffer, camera_width, camera_height), daemon=True)
p.start()
processes.append(p)
# Start detection MultiStick
# Activation of inferencer
p = mp.Process(target=inferencer, args=(results, frameBuffer, number_of_ncs, camera_width, camera_height), daemon=True)
p.start()
processes.append(p)
while True:
sleep(1)
except:
import traceback
traceback.print_exc()
finally:
for p in range(len(processes)):
processes[p].terminate()
print("\n\nFinished\n\n")
◆ The result of inserting four NCS2
This time, I will verify with 2 models of Core i7 laptop computer and RaspberryPi3.
The numerical precision of the weight is FP16.
Model size of MobileNet-SSD
・・・ 11.6 MB
Model size of YoloV3
・・・ 123.8 MB (10 times of MobileNet)
● Validation results at Core i7
<Core i7 + MobileNet-SSD + NCS2 x4 + MultiProcess, 48 FPS>
It is fast. 48 FPS has appeared. There seems to be room for improvement in terms of accuracy.
Simple calculation is impossible, but 12 FPS performance has come out per NCS2.
Youtube: https://youtu.be/HJLMB3an_Rw
<Core i7 + YoloV3 + NCS2 x4 + MultiProcess, 4 FPS>
Even if boosting with four, it is only 4FPS.
The model size seems to be inversely proportional to the reasoning speed.
However, it will definitely not work so lightly in the original NCS.
Since it is asynchronous, the movie is played at the same speed.
Youtube: https://youtu.be/3mKkPXpIc_U
● Validation result with RaspberryPi3
<RaspberryPi3 + MobileNet-SSD + NCS2 x4 + MultiProcess, 24 FPS>
It is considerably slower than the expected value. However, It can be said that reasoning is being made at sufficient speed.
By comparison with Core i7, it is revealed that the low performance of the ARM CPU (Coretex-A57) is a bottleneck.
Originally, performance improvement of 9 FPS was expected per Neural Compute Stick 2.
Although the reasoning speed is fast, it takes a lot of time in preprocessing and post-processing which are executed on the CPU side.
Youtube: https://youtu.be/RBU1sDHNqxs
<RaspberryPi3 + YoloV3 + NCS2 x4 + MultiProcess, 1.7 FPS>
It is tremendously slow.
As expected, when the model size becomes 100 MB order, together with the low performance of the CPU, it becomes considerably low speed FPS.
It seems impossible to use full size YoloV3 with RaspberryPi3.
Youtube: https://youtu.be/7QIKZ7tizEE