TensorflowLite-UNet 
Tensorflow-bin 
TensorflowLite-bin 
I wrote in English article, here (TensorflowLite-UNet)
【!注意!】 この記事を先頭から末尾までクソ真面目にトレースすると、「ただひたすら待つ」 という苦行に耐えるために カップラーメン600個 を手配する必要がある。 精神 と 財力 に余裕がある方、あるいは 悟り を開かれた方のみ挑戦されたし。
<2018.11.15 23:00更新>
Tensorflowメンバーの aselleさん が Tensorflow v1.12.0 のmasterブランチに Tensorflow Lite の スタンドアロンインストーラ の作成方法を開示してくれた。
RaspberryPi上に Tensorflow Lite の実行環境のみを導入する場合は、 コチラのチュートリアル を使用すると大幅な導入時間の短縮が期待される。
下記に Python2.7用 のWheelファイルが生成された。 概ね30分で完了。 イカすぜ。
Python2.7用 サイズ:1.1MB
/tmp/tflite_pip/dist/tflite_runtime-1.12.0rc0-cp27-cp27mu-linux_armv7l.whl
Python3.5用 サイズ:1.1MB
/tmp/tflite_pip/dist/tflite_runtime-1.12.0rc0-cp35-cp35m-linux_armv7l.whl
導入してみる。 アンインストールはともかくとして、インストールは10秒ほどで終わる。
$ sudo pip2 uninstall tensorflow
$ sudo pip3 uninstall tensorflow
$ sudo pip2 install tflite_runtime-1.12.0rc0-cp27-cp27mu-linux_armv7l.whl
$ sudo pip3 install tflite_runtime-1.12.0rc0-cp35-cp35m-linux_armv7l.whl
動作確認したところ。。。
import tflite_runtime as tflr
interpreter = tflr.lite.Interpreter(model_path="foo.tflite")
importしただけであちこちでエラーが発生して動作しない。。。
__init__.py を自力で書き換えたり、interpreter.py の import文 を修正する必要がある。
しばらくは v1.11.0 で様子見が良さそうだ。
◆ 前回記事
Caffeで超軽量な "Semantic Segmentation" のモデルを生成する Sparse-Quantized CNN 512x1024_10MB_軽量モデル_その1
◆ はじめに
精度が低い軽量モデルは国内ではあまり人気が無いようだ。
少なくとも私のように、 RaspberryPi + Tensorflow Lite 上で Google非公認の Semantic Segmentaion を実装するアホはどこを探しても見当たらない。
実際にまともに使える環境を一から十まで整えられる記事はどこにも無かった。
皆さん同じ思いを持たれているのではないかと思うが、やりたいことの本質は 環境を整えること ではなく 何かを推論すること なので、実現したいアイデアはあるのに環境構築でつまづくととてもテンションが下がる。
ちなみに、この記事で作成した Tensorflow の Wheelファイル で、Tensorflow公式リポジトリの issue をひとつ解決できたようだ。
海外のエンジニアに貢献できてうれしい。
さておき、前回は カスタムCaffe で軽量モデルを生成したが、今回は Tensorflow-GPU/CPU 1.11.0 + Ubuntu16.04、Tensorflow Lite 1.11.0 + RaspberryPi3 (Raspbian Stretch) + Python で、セマンティック・セグメンテーションの軽量モデル UNet と ENet の学習環境と実行環境を構築する。
最終成果物はコチラ。
PINTO0309 - TensorflowLite-UNet - Github
PINTO0309 - TensorFlow-ENet - Github
PINTO0309 - TensorflowLite v1.12.0 - スタンドアロンインストーラWheel - Github
PINTO0309 - Tensorflow - ネイティブビルド済みWheel - Github
PINTO0309 - Bazel - ネイティブビルド済みインストーラ - Github
UNet の Pure Tensorflow での最終生成モデル、 .pbファイル のサイズは 31.1MB or 1.9MB 、 UNet の Tenfowflow Lite 変換 + Quantize 後の最終生成モデル、 .tfliteファイル のファイルサイズは 9.9MB or 625KB となる。
フィルタの枚数を調整することでモデルサイズを2パターン試した。
なお、学習効率を最大化するため、VOC2012の 「Person」 クラスのみに絞り学習する方針をとっている。
ENet の Pure Tensorflow での最終生成モデル、 .pbファイル のサイズは 1.87MB となる。
※ ENet の Tensorflow Lite 実装はカスタムオペレーションをC++で自力実装する必要があり、しんどかったので対応を保留した。
Tensorflow Lite の公式ドキュメントは コチラ
Tensorflow Lite。。。 情報が薄すぎ。。。
GPU非搭載の非力なエッジコンピュータでPythonを使用してセマンティック・セグメンテーションを動作させるのが目的。
Bazel や Tensorflow Lite の導入につまづく方は多いと思うので、進んで人柱となり、導入の手順をしっかりと記載しようと思う。
国内外含め C++ と Java、Android や iOS による実装は散見されるが、RaspberryPi + Pythonでの実装例・体系的に整理されている記事がほぼ見当たらないため、誰かのためになれば嬉しい。
なお、公式の Tensorflow pip パッケージは壊れている。
Bus error や undefined symbol: _ZN6tflite12tensor_utils39NeonMatrixBatchVectorMultiplyAccumulateEPKaiiS2_PKfiPfi が発生し、自力でビルドしない限り、とにかくまともに動かない。
Tensorflow (Self-Build) をラズパイ上で自力ビルドすることになるとは夢にも思わなかった。
公式で提供されているツールチェーンにバグがあるのか何なのか分からないが、 クロスコンパイル をすると正常に動作しない。
必ず、 ネイティブコンパイル をする必要がある。
しんどかった。 が、ROS の NAVIGATIONパッケージビルド の沼よりは100倍浅かった。
<GPU版 Tensorflow v1.11.0 + UNet + Ubuntu16.04 PC によるテスト生成画像>
※ 学習モデルのサイズ 31.1MB
※ Geforce GTX 1070 で推論時間 1.83秒


<CPU版 Tensorflow Lite v1.11.0 (自力ビルド) + UNet + Ubuntu16.04 PC によるテスト生成画像>
※ 学習モデルのサイズ 9.9MB
※ 第8世代 Corei7 で推論時間 1.13秒


<GPU版 Tensorflow Lite v1.11.0 (自力ビルド) + UNet + Ubuntu16.04 PC によるテスト生成画像 その1>
※ 学習モデルのサイズ 9.9MB
※ Geforce GTX 1070 で推論時間 0.87秒
※ CUDA9.0 と cuDNN7.0 が有効。


<GPU版 Tensorflow Lite v1.11.0 (自力ビルド) + UNet + Ubuntu16.04 PC によるテスト生成画像 その2>
※ 学習モデルのサイズ 625KB
※ Geforce GTX 1070 で推論時間 0.07秒 (70ms)
※ さすがに爆速。 CUDA9.0 と cuDNN7.0 が有効。


<CPU版 Tensorflow v1.11.0 (自力ビルド) + ENet + RaspberryPi3 によるテスト生成画像>
※ 学習モデルのサイズ 1.87MB
※ ARM Cortex-A53 で推論時間 10.2秒 [2018.11.03] Tensorflow本体を高速化チューニングした後 9.5秒
※ 手抜きをしてpipコマンドで導入した Tensorflow v1.11.0 を使用すると「バスエラー」となって異常終了する。


<CPU版 Tensorflow Lite v1.11.0 (自力ビルド) + UNet + RaspberryPi3 によるテスト生成画像 その1>
※ 学習モデルのサイズ 9.9MB
※ ARM Cortex-A53 で推論時間 11.76秒
※ ENet の5倍以上のモデルサイズにもかかわらず、2.2秒しか差が無い。。。 Tensorflow Liteの破壊力、驚異的。
※ FlattBuffer化と量子化だけではパフォーマンスの上がり幅が凄すぎて説明出来ない。きっとRaspberryPiに搭載されているVFPV4か何かで Tensorflow Lite が最適化されているに違いない。
※遅いけど精度が高い。


<CPU版 Tensorflow Lite v1.11.0 (自力ビルド) + UNet + RaspberryPi3 によるテスト生成画像 その2>
※ 学習モデルのサイズ 625KB
※ ARM Cortex-A53 で推論時間 0.47秒
※ GPU未使用で鬼神のごとき速さだが、精度が低い。
◆ 参考にさせていただいた記事、謝辞
tktktks10 さん - Qiita
前回記事に続き、全面的に参考にさせていただいた。
UNet について非常にわかりやすく丁寧にまとめていただいている。
実は、こちらの記事にインスパイアされて軽量モデルの実装に取り組み始めた。
また、公開していただいていたGithubリポジトリの派生(改造)リポジトリ作成についても快く承諾していただけた。
誠に感謝しか無い。
U-NetでPascal VOC 2012の画像をSemantic Segmentationする (TensorFlow)
https://github.com/tks10/segmentation_unet.git
KimuraAkimasa さん - GClue
Android向け かつ 情報量はあまり多くないが、TOCO変換スクリプトを作成するときに一部を参考にさせていただいた。
TensorFlow Liteを使ってモバイル向けに最適化された機械学習モデルを動かしてみる
StackOverflow
Pythonの実装サンプルとして見つけたのはこれだけ。
https://stackoverflow.com/questions/50902067/how-to-import-the-tensorflow-lite-interpreter-in-python
HEARTBEAT - Compiling a TensorFlow Lite Build with Custom Operations
カスタムオペレーションの実装方法を解説してくれている。
が、学習コストが掛かるため、今回は採用しなかった。
https://heartbeat.fritz.ai/compiling-a-tensorflow-lite-build-with-custom-operations-cf6330ee30e2
(株)クラスキャット セールスインフォメーション
公式ドキュメントの和訳をしていただいている。
当然ながら、Android と iOS 前提。
TensorFlow : Mobile : TensorFlow Lite へのイントロダクション
TensorFlow : Extend : 新しい Op を追加する
Tensorflow 変数を定数に置き換えるサンプル
https://tyfkda.github.io/blog/2016/09/14/tensorflow-protobuf.html
TOCO変換サンプル
https://stackoverflow.com/questions/52400043/how-to-get-toco-to-work-with-shape-none-24-24-3
ENet のTOCO変換で 「カスタムオペレーションに未対応」 エラーが発生する
https://groups.google.com/a/tensorflow.org/forum/#!msg/tflite/YlTLq9fGnvE/SVfhSbklBAAJ
Tensorflow 公式
https://www.tensorflow.org/lite/rpi
https://www.tensorflow.org/api_docs/python/tf/contrib/lite/TocoConverter
https://www.tensorflow.org/lite/convert/python_api
https://www.tensorflow.org/lite/devguide
https://www.tensorflow.org/lite/convert/cmdline_examples
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/custom_operators.md
https://github.com/tensorflow/tensorflow/issues/21574
https://www.tensorflow.org/lite/tfmobile/prepare_models
Bazel 公式
Bazel Command-Line Reference
◆ 環境
● 開発環境
- Ubuntu 16.04
- Tensorflow-GPU v1.11.0 <- CPU版と相互に切り替えながらテストを実施、pipコマンド/自力ビルド
- Tensorflow-CPU v1.11.0 <- GPU版と相互に切り替えながらテストを実施、pipコマンド/自力ビルド
- Tesla K80 or Geforce GTX 1070 or Quadro P2000
- CUDA 9.0
- cuDNN 7.0
- Python 2.7 or 3.5
● 実行環境
- RaspberryPi3 + Raspbian Stretch
- Bazel 0.17.2 <- 自力ビルド
- Tensorflow v1.11.0 <- 自力ビルド
- Tensorflow Lite v1.11.0 <- 自力ビルド
- Python 2.7 or 3.5
- OpenCV 3.4.2 <- 自力ビルド
- MicroSD Card 32GB
◆ 学習環境構築
GPUを搭載したPC上に "ENet" と "UNet" のDeepLearning学習環境を構築する。
● GPU搭載PC Ubuntu16.04 への学習環境導入
既存環境を破壊したくない方は、やることがほぼ同じなので Docker を使用するのが吉。
今回は母艦に直接導入する手順のみ記載する。
$ cd ~
$ sudo apt-get remove cuda-*
$ sudo apt-get purge cuda-*
# 1.Download cuda-repo-ubuntu1604_9.0.176-1_amd64.deb from NVIDIA
# 2.Download libcudnn7_7.0.5.15-1+cuda9.0_amd64.deb from NVIDIA
# 3.Download libcudnn7-dev_7.0.5.15-1+cuda9.0_amd64.deb from NVIDIA
$ sudo dpkg -i libcudnn7*
$ sudo dpkg -i cuda-*
$ sudo apt-key add /var/cuda-repo-9-0-local/7fa2af80.pub
$ sudo apt update
$ sudo apt install cuda-9.0
$ echo 'export PATH=/usr/local/cuda-9.0/bin:${PATH}' >> ~/.bashrc
$ echo 'export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:${LD_LIBRARY_PATH}' >> ~/.bashrc
$ source ~/.bashrc
$ sudo ldconfig
$ nvcc -V
$ cd ~;nano cudnn_version.cpp
############################### 以下を貼り付け ###################################
# include <cudnn.h>
# include <iostream>
int main(int argc, char** argv) {
std::cout << "CUDNN_VERSION: " << CUDNN_VERSION << std::endl;
return 0;
}
############################### 以上を貼り付け ###################################
$ nvcc cudnn_version.cpp -o cudnn_version
$ ./cudnn_version
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 396.44 Driver Version: 396.44 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 107... Off | 00000000:01:00.0 Off | N/A |
| N/A 54C P0 32W / N/A | 254MiB / 8119MiB | 1% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1461 G /usr/lib/xorg/Xorg 184MiB |
| 0 3364 G ...quest-channel-token=4480583668747587845 67MiB |
+-----------------------------------------------------------------------------+
Tensorflowをpipコマンドで導入し、学習用GithubリポジトリをCloneする。
本家の Tensorflow-ENet リポジトリをForkして、軽微なバグフィックスとCPU実行対応、.pbスリム化の独自カスタマイズを加えてある。
PINTO0309 - TensorFlow-ENet - Github
$ cd ~
$ sudo pip2 install tensorflow-gpu==1.11.0
$ sudo pip3 install tensorflow-gpu==1.11.0
$ git clone -b pinto0309work https://github.com/PINTO0309/TensorFlow-ENet.git
$ cd TensorFlow-ENet
$ git checkout pinto0309work
◆ ENetの学習と.pbのスリム化
あえてイチから学習しなくても、Clone元リポジトリには 学習済みモデル を配備済み。
手っ取り早く動作の確認のみを行いたい場合は、 ● ENetの学習 をスキップする。
● ENetの学習
独自のデータセットで学習したいときのみ下記コマンドを実行する。
独自データセットで学習する必要の無い方はこのフェーズをスキップしても構わない。
このモデルの特徴や学習ロジックはこの場では触れないが、気になる方はCloneした リポジトリ をご参照願う。
独自データセットで学習する場合は、 ./train.sh の実行前に所定のパスへ好みの画像データセットを配備するのみ。
train_enet.py にデータセットの配置先パスなどの多くの入力パラメータが定義されているため、 train.sh を好みに合うように加工すれば良い。
**シェルパラメータの例・デフォルト値と説明**
# Directory arguments
flags.DEFINE_string('dataset_dir', './dataset', 'The dataset directory to find the train, validation and test images.')
flags.DEFINE_string('logdir', './log/original', 'The log directory to save your checkpoint and event files.')
flags.DEFINE_boolean('save_images', True, 'Whether or not to save your images.')
flags.DEFINE_boolean('combine_dataset', False, 'If True, combines the validation with the train dataset.')
# Training arguments
flags.DEFINE_integer('num_classes', 12, 'The number of classes to predict.')
flags.DEFINE_integer('batch_size', 10, 'The batch_size for training.')
flags.DEFINE_integer('eval_batch_size', 25, 'The batch size used for validation.')
flags.DEFINE_integer('image_height', 360, "The input height of the images.")
flags.DEFINE_integer('image_width', 480, "The input width of the images.")
flags.DEFINE_integer('num_epochs', 300, "The number of epochs to train your model.")
flags.DEFINE_integer('num_epochs_before_decay', 100, 'The number of epochs before decaying your learning rate.')
flags.DEFINE_float('weight_decay', 2e-4, "The weight decay for ENet convolution layers.")
flags.DEFINE_float('learning_rate_decay_factor', 1e-1, 'The learning rate decay factor.')
flags.DEFINE_float('initial_learning_rate', 5e-4, 'The initial learning rate for your training.')
flags.DEFINE_string('weighting', "MFB", 'Choice of Median Frequency Balancing or the custom ENet class weights.')
# Architectural changes
flags.DEFINE_integer('num_initial_blocks', 1, 'The number of initial blocks to use in ENet.')
flags.DEFINE_integer('stage_two_repeat', 2, 'The number of times to repeat stage two.')
flags.DEFINE_boolean('skip_connections', False, 'If True, perform skip connections from encoder to decoder.')
$ cd ~/TensorFlow-ENet
$ chmod 777 train.sh
$ ./train.sh
● checkpointファイルのスリム化
学習が終わったあとに実施する。
推論段階で不要となる無駄な変数やオプティマイズ処理をすべて排除してファイルサイズを圧縮する。
処理後、元のファイルサイズの3分の1ほどに圧縮される。
.ckpt- の直後に続く数字部分は学習のイテレーション数なので、学習の進捗状況ごとに異なる可能性がある。
こちらもClone元リポジトリに 処理済みのもの を配備済み。
checkpointフォルダ配下の下記3ファイルを元に、
model.ckpt-13800.data-00000-of-00001
model.ckpt-13800.index
model.ckpt-13800.meta
下記圧縮済みの4ファイルを生成する。
modelfinal.ckpt-13800.data-00000-of-00001
modelfinal.ckpt-13800.index
modelfinal.ckpt-13800.meta
semanticsegmentation_enet.pbtxt
下記コマンドを実行する。
$ python slim_infer.py
特別なことはしていないが、学習時のほぼすべてのロジックを削除し、リストア→セーブをするだけ。
参考までに下記にロジックを貼り付けておく。
独自データセットで学習した場合はckptファイル名が異なるため、
saver.restore(..)
saver.save(..)
に記載されているckptファイルのプレフィックスを実行前に変更する必要がある。
その場合、数字より後ろの部分、.data-00000-of-00001 .index .meta は指定不要。
**slim_infer.py のロジック**
import tensorflow as tf
from enet import ENet, ENet_arg_scope
slim = tf.contrib.slim
def main():
graph = tf.Graph()
with graph.as_default():
with slim.arg_scope(ENet_arg_scope()):
inputs = tf.placeholder(tf.float32, [None, 360, 480, 3], name="input")
logits, probabilities = ENet(inputs,
12,
batch_size=1,
is_training=False,
reuse=None,
num_initial_blocks=1,
stage_two_repeat=2,
skip_connections=False)
saver = tf.train.Saver(tf.global_variables())
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
saver.restore(sess, './checkpoint/model.ckpt-13800')
saver.save(sess, './checkpoint/modelfinal.ckpt-13800')
graphdef = graph.as_graph_def()
tf.train.write_graph(graphdef, './checkpoint', 'semanticsegmentation_enet.pbtxt', as_text=True)
if __name__ == '__main__':
main()
● 圧縮済み.pbファイルの生成
下記コマンドを実行し、.pbtxt から 圧縮済み.pb ファイルを生成する。
Output Node をカンマ区切りで2種類記載しているため、推論結果は2種類のNodeからの出力を受け取ることができる。
コマンドを実行すると、checkpointフォルダ配下に 1.78MB の semanticsegmentation_enet.pb ファイルが生成される。
$ python freeze_graph.py \
--input_graph=checkpoint/semanticsegmentation_enet.pbtxt \
--input_checkpoint=checkpoint/modelfinal.ckpt-13800 \
--output_graph=checkpoint/semanticsegmentation_enet.pb \
--output_node_names=ENet/fullconv/BiasAdd,ENet/logits_to_softmax \
--input_binary=False
◆ UNetの学習と.pbのスリム化
● UNetの学習
下記コマンドを実行し、学習用リポジトリをCloneする。
"人" が写っている画像ファイルのみ全件抽出して dataset フォルダに配備済み。
PINTO0309 - TensorflowLite-UNet - Person Dataset - Github
"Person" 画像だけを抽出する方法は、 VOC2012データセット をダウンロードして解凍後に生成されたフォルダ配下の、
VOCdevkit/VOC2012/ImageSets/Main/person_train.txt や VOCdevkit/VOC2012/ImageSets/Main/person_trainval.txt に 「1」 というフラグが立っている画像を全て抽出すれば良い。
"Person" 以外の画像を抽出する場合も、ファイル名からクラスを判別して同じ手番で抽出可能。
注意点は、 JPEGImages フォルダと SegmentationClass フォルダの両方から、同じ名前のファイルを同期をとりながら各フォルダから1枚ずつ抽出する必要があること。
$ cd ~
$ git clone https://github.com/PINTO0309/TensorflowLite-UNet.git
VOC2012のトレーニング画像だけではサンプル数が794枚と少なすぎて、大きく過学習してしまう。
下記プログラムを実行し、画像ファイルを20倍に水増しする。
水増し操作は下記をランダムに実施する。
(1)平滑化
(2)ガウシアンノイズ追加
(3)Salt & Pepperノイズ追加
(4)回転
(5)反転










data_set/VOCdevkit/person/JPEGImagesOUT と data_set/VOCdevkit/person/SegmentationClassOUT に水増し後の画像が保存される。
increase_num = 20 の部分の数字を好きな数に変更することで水増しの倍数を調整できる。
ただし、一度に処理できる画像枚数はGPUのVRAM容量に依存するため、 OutOfMemory が発生するようであれば数値を小さく調整する必要がある。
過学習が極力発生しなくて、かつ OutOfMemoryも発生しない、ギリギリのラインを見極める必要がある。
**IncreaseImage.py のロジック**
######################################################
# Segmentation image padding program
######################################################
import cv2
import os
import glob
import numpy as np
from PIL import Image, ImageOps
######################################################
increase_num = 20
######################################################
# Histogram homogenization function
def equalizeHistRGB(src):
RGB = cv2.split(src)
Blue = RGB[0]
Green = RGB[1]
Red = RGB[2]
for i in range(3):
cv2.equalizeHist(RGB[i])
img_hist = cv2.merge([RGB[0],RGB[1], RGB[2]])
return img_hist
# Gaussian noise function
def addGaussianNoise(src):
row,col,ch= src.shape
mean = 0
var = 0.1
sigma = 15
gauss = np.random.normal(mean,sigma,(row,col,ch))
gauss = gauss.reshape(row,col,ch)
noisy = src + gauss
return noisy
# Salt & Pepper noise function
def addSaltPepperNoise(src):
row,col,ch = src.shape
s_vs_p = 0.5
amount = 0.004
out = src.copy()
# Salt mode
try:
num_salt = np.ceil(amount * src.size * s_vs_p)
coords = [np.random.randint(0, i-1 , int(num_salt)) for i in src.shape]
out[coords[:-1]] = (255,255,255)
except:
pass
# Pepper mode
try:
num_pepper = np.ceil(amount* src.size * (1. - s_vs_p))
coords = [np.random.randint(0, i-1 , int(num_pepper)) for i in src.shape]
out[coords[:-1]] = (0,0,0)
except:
pass
return out
# Rotation
def rotate_image(src1, src2, angle):
orig_h, orig_w = src1.shape[:2]
#matrix = cv2.getRotationMatrix2D((orig_h/2, orig_w/2), angle, 1)
matrix = cv2.getRotationMatrix2D((orig_w/2, orig_h/2), angle, 1)
return cv2.warpAffine(src1, matrix, (orig_w, orig_h), src1, flags=cv2.INTER_LINEAR), src2.rotate(angle)
img_filesJ = sorted(glob.glob("data_set/VOCdevkit/person/JPEGImages/*"))
img_filesS = sorted(glob.glob("data_set/VOCdevkit/person/SegmentationClass/*"))
JPEG_out_base_path = "data_set/VOCdevkit/person/JPEGImagesOUT"
SEGM_out_base_path = "data_set/VOCdevkit/person/SegmentationClassOUT"
imgs = []
for (img_fileJ, img_fileS) in zip(img_filesJ, img_filesS):
imgs.append([cv2.imread(img_fileJ, cv2.IMREAD_UNCHANGED), Image.open(img_fileS)])
# Generate lookup table
min_table = 50
max_table = 205
diff_table = max_table - min_table
gamma1 = 0.75
gamma2 = 1.5
LUT_HC = np.arange(256, dtype = 'uint8')
LUT_LC = np.arange(256, dtype = 'uint8')
LUT_G1 = np.arange(256, dtype = 'uint8')
LUT_G2 = np.arange(256, dtype = 'uint8')
LUTs = []
# Smoothing sequence
average_square = (10,10)
# Create high contrast LUT
for i in range(0, min_table):
LUT_HC[i] = 0
for i in range(min_table, max_table):
LUT_HC[i] = 255 * (i - min_table) / diff_table
for i in range(max_table, 255):
LUT_HC[i] = 255
# Other LUT creation
for i in range(256):
LUT_LC[i] = min_table + i * (diff_table) / 255
LUT_G1[i] = 255 * pow(float(i) / 255, 1.0 / gamma1)
LUT_G2[i] = 255 * pow(float(i) / 255, 1.0 / gamma2)
LUTs.append(LUT_HC)
LUTs.append(LUT_LC)
LUTs.append(LUT_G1)
LUTs.append(LUT_G2)
imgcnt = 0
for img in imgs:
for i in range(increase_num):
jpgimg = img[0]
segimg = img[1]
# # Contrast conversion execution
# if np.random.randint(2) == 1:
# level = np.random.randint(4)
# jpgimg = cv2.LUT(jpgimg, LUTs[level])
# Smoothing execution
if np.random.randint(2) == 1:
jpgimg = cv2.blur(jpgimg, average_square)
# # Histogram equalization execution
# if np.random.randint(2) == 1:
# jpgimg = equalizeHistRGB(jpgimg)
# Gaussian noise addition execution
if np.random.randint(2) == 1:
jpgimg = addGaussianNoise(jpgimg)
# Salt & Pepper noise addition execution
if np.random.randint(2) == 1:
jpgimg = addSaltPepperNoise(jpgimg)
# Rotation
if np.random.randint(2) == 1:
jpgimg, segimg = rotate_image(jpgimg, segimg, np.random.randint(360))
# Reverse execution
if np.random.randint(2) == 1:
jpgimg = cv2.flip(jpgimg, 1)
segimg = ImageOps.mirror(segimg)
# Image storage after padding
JPEG_image_path = "%s/%04d_%04d.jpg" % (JPEG_out_base_path, imgcnt, i)
SEGM_image_path = "%s/%04d_%04d.png" % (SEGM_out_base_path, imgcnt, i)
cv2.imwrite(JPEG_image_path, jpgimg)
segimg.save(SEGM_image_path)
print("imgcnt =", imgcnt, "num =", i)
imgcnt += 1
print("Finish!!")
$ cd TensorflowLite-UNet
$ python3 IncreaseImage.py
ようやく下準備が終わったので学習プログラムを実行する。
この部分が、 tktktks10 さんのロジックを拝借して、One Class Segmentation に対応するための改造を加えている部分となる。
loader.py に "Person" 以外のクラスを "Back Ground (背景)" へ強制的に置き換える改造を加えた。
トレーニング画像 15,000枚 で学習完了まで5〜6時間掛かるため、寝る前に実行し、朝終わっている感覚。
トレーニング画像の多さとGPUの性能に依存するため、あまり闇雲に水増しし過ぎていると、かなりの長時間を要することになる。
また、epoch数 を闇雲に大きくすると、 60epoch から 70epoch あたりで猛烈に過学習が始まるため注意。
デフォルトでは < モデルサイズ 【大】 > のパターンで学習済みモデルを生成する。
$ python3 main.py --gpu --augmentation --batchsize 32 --epoch 50
なお、 < モデルサイズ 【小】 > とする場合は model.py および model_infer.py の、Convolution層のフィルタ数を下記のように4分の1に削減すると生成できる。
**< モデルサイズ 【小】 > にする場合の model.py の変更点**
conv1_1 = UNet.conv(inputs, filters=8, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv1_2 = UNet.conv(conv1_1, filters=8, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool1 = UNet.pool(conv1_2)
conv2_1 = UNet.conv(pool1, filters=16, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv2_2 = UNet.conv(conv2_1, filters=16, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool2 = UNet.pool(conv2_2)
conv3_1 = UNet.conv(pool2, filters=32, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv3_2 = UNet.conv(conv3_1, filters=32, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool3 = UNet.pool(conv3_2)
conv4_1 = UNet.conv(pool3, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv4_2 = UNet.conv(conv4_1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool4 = UNet.pool(conv4_2)
conv5_1 = UNet.conv(pool4, filters=256, l2_reg_scale=l2_reg)
conv5_2 = UNet.conv(conv5_1, filters=256, l2_reg_scale=l2_reg)
concated1 = tf.concat([UNet.conv_transpose(conv5_2, filters=128, l2_reg_scale=l2_reg), conv4_2], axis=3)
conv_up1_1 = UNet.conv(concated1, filters=128, l2_reg_scale=l2_reg)
conv_up1_2 = UNet.conv(conv_up1_1, filters=128, l2_reg_scale=l2_reg)
concated2 = tf.concat([UNet.conv_transpose(conv_up1_2, filters=64, l2_reg_scale=l2_reg), conv3_2], axis=3)
conv_up2_1 = UNet.conv(concated2, filters=64, l2_reg_scale=l2_reg)
conv_up2_2 = UNet.conv(conv_up2_1, filters=64, l2_reg_scale=l2_reg)
concated3 = tf.concat([UNet.conv_transpose(conv_up2_2, filters=32, l2_reg_scale=l2_reg), conv2_2], axis=3)
conv_up3_1 = UNet.conv(concated3, filters=32, l2_reg_scale=l2_reg)
conv_up3_2 = UNet.conv(conv_up3_1, filters=32, l2_reg_scale=l2_reg)
concated4 = tf.concat([UNet.conv_transpose(conv_up3_2, filters=16, l2_reg_scale=l2_reg), conv1_2], axis=3)
conv_up4_1 = UNet.conv(concated4, filters=16, l2_reg_scale=l2_reg)
conv_up4_2 = UNet.conv(conv_up4_1, filters=16, l2_reg_scale=l2_reg)
outputs = UNet.conv(conv_up4_2, filters=ld.DataSet.length_category(), kernel_size=[1, 1], activation=None, name="output")
**< モデルサイズ 【小】 > にする場合の model_infer.py の変更点**
conv1_1 = UNet.conv(inputs, filters=8, l2_reg_scale=l2_reg, batchnorm_istraining=False)
conv1_2 = UNet.conv(conv1_1, filters=8, l2_reg_scale=l2_reg, batchnorm_istraining=False)
pool1 = UNet.pool(conv1_2)
# 1/2, 1/2, 64
conv2_1 = UNet.conv(pool1, filters=16, l2_reg_scale=l2_reg, batchnorm_istraining=False)
conv2_2 = UNet.conv(conv2_1, filters=16, l2_reg_scale=l2_reg, batchnorm_istraining=False)
pool2 = UNet.pool(conv2_2)
# 1/4, 1/4, 128
conv3_1 = UNet.conv(pool2, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=False)
conv3_2 = UNet.conv(conv3_1, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=False)
pool3 = UNet.pool(conv3_2)
# 1/8, 1/8, 256
conv4_1 = UNet.conv(pool3, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=False)
conv4_2 = UNet.conv(conv4_1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=False)
pool4 = UNet.pool(conv4_2)
# 1/16, 1/16, 512
conv5_1 = UNet.conv(pool4, filters=256, l2_reg_scale=l2_reg)
conv5_2 = UNet.conv(conv5_1, filters=256, l2_reg_scale=l2_reg)
concated1 = tf.concat([UNet.conv_transpose(conv5_2, filters=128, l2_reg_scale=l2_reg), conv4_2], axis=3)
conv_up1_1 = UNet.conv(concated1, filters=128, l2_reg_scale=l2_reg)
conv_up1_2 = UNet.conv(conv_up1_1, filters=128, l2_reg_scale=l2_reg)
concated2 = tf.concat([UNet.conv_transpose(conv_up1_2, filters=64, l2_reg_scale=l2_reg), conv3_2], axis=3)
conv_up2_1 = UNet.conv(concated2, filters=64, l2_reg_scale=l2_reg)
conv_up2_2 = UNet.conv(conv_up2_1, filters=64, l2_reg_scale=l2_reg)
concated3 = tf.concat([UNet.conv_transpose(conv_up2_2, filters=32, l2_reg_scale=l2_reg), conv2_2], axis=3)
conv_up3_1 = UNet.conv(concated3, filters=32, l2_reg_scale=l2_reg)
conv_up3_2 = UNet.conv(conv_up3_1, filters=32, l2_reg_scale=l2_reg)
concated4 = tf.concat([UNet.conv_transpose(conv_up3_2, filters=16, l2_reg_scale=l2_reg), conv1_2], axis=3)
conv_up4_1 = UNet.conv(concated4, filters=16, l2_reg_scale=l2_reg)
conv_up4_2 = UNet.conv(conv_up4_1, filters=16, l2_reg_scale=l2_reg)
outputs = UNet.conv(conv_up4_2, filters=ld.DataSet.length_category(), kernel_size=[1, 1], activation=None, name="output")
● UNetの学習結果
< モデルサイズ 【大】 >
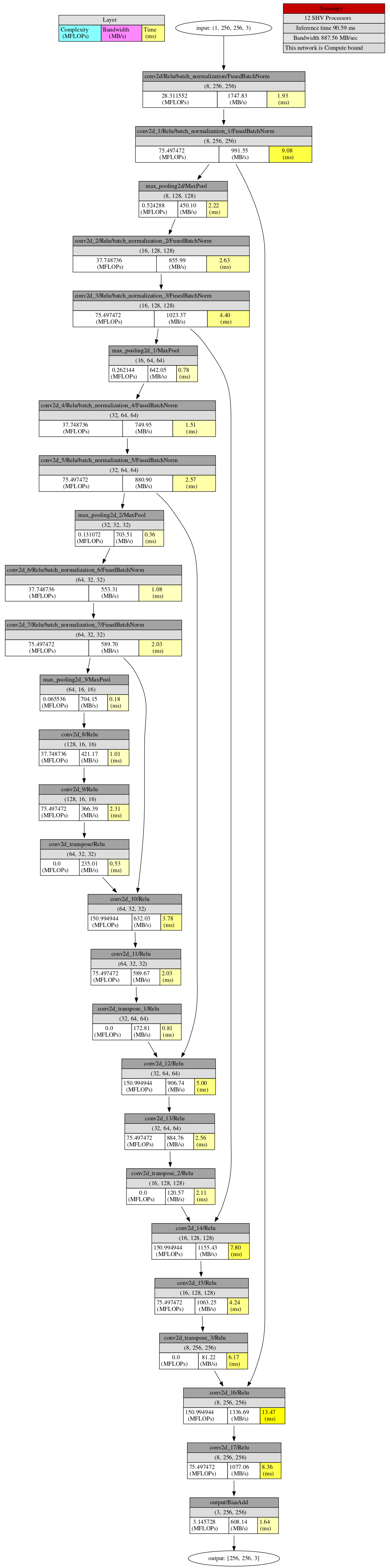
ネットワーク図

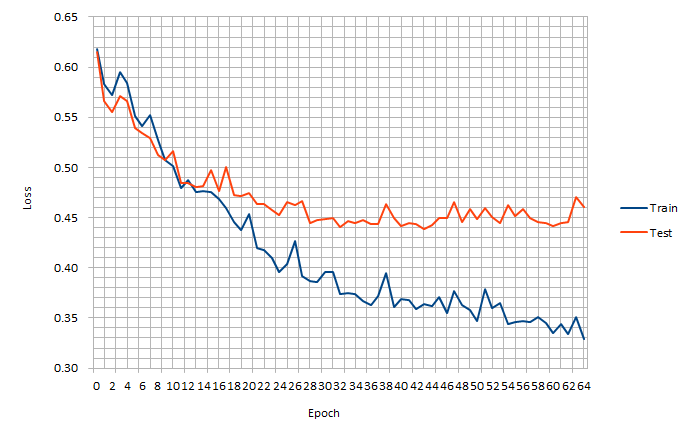
テスト画像に対する Accuracy値 は、約0.91 になった。
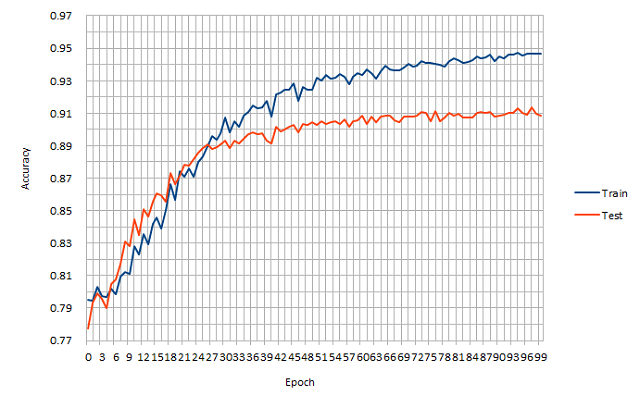
57エポック目あたりから5%ほど過学習になってしまったが、ボチボチ良い結果に。
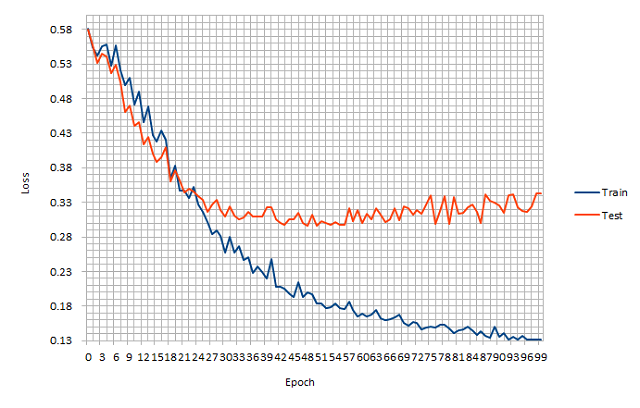
テスト画像に対する LOSS値 は、約0.35 になった。
ロースペックエッジ端末向けに深さや広さを極限まで削ったネットワークのため、これ以上の贅沢は言えそうに無い。
< モデルサイズ 【小】 >
ネットワーク図
テスト画像に対する Accuracy値 は、約0.84 になった。
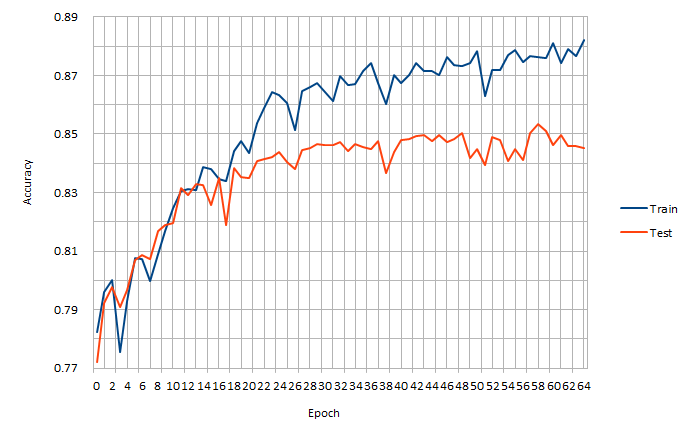
テスト画像に対する LOSS値 は、約0.46 になった。
● checkpointファイルのスリム化
下記コマンドを実行し、ENet のときと同じように、推論段階で不要となる無駄な変数やオプティマイズ処理をすべて排除してファイルサイズを圧縮する。
checkpointファイルは、 model フォルダ配下に生成される。
$ python3 main_infer.py
**main_infer.py のロジック**
import tensorflow as tf
from util import model_infer as model
#######################################################################################
### $ python3 main_infer.py
#######################################################################################
def main():
graph = tf.Graph()
with graph.as_default():
model_unet = model.UNet(l2_reg=0.0001).model
saver = tf.train.Saver(tf.global_variables())
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
print("in=", model_unet.inputs.name)
print("on=", model_unet.outputs.name)
saver.restore(sess, './model/deploy.ckpt')
saver.save(sess, './model/deployfinal.ckpt')
graphdef = graph.as_graph_def()
tf.train.write_graph(graphdef, './model', 'semanticsegmentation_person.pbtxt', as_text=True)
if __name__ == '__main__':
main()
● 圧縮済み.pbファイルの生成
下記コマンドを実行し、圧縮済み.pbファイルを生成する。
学習プログラムに何も調整を加えていなければ、 < モデルサイズ 【大】 > の 31.1MB の.pbファイルが生成される。
python freeze_graph.py \
--input_graph=model/semanticsegmentation_person.pbtxt \
--input_checkpoint=model/deployfinal.ckpt \
--output_graph=model/semanticsegmentation_frozen_person.pb \
--output_node_names=output/BiasAdd \
--input_binary=False
ここまででようやく、 ENet と UNet の学習作業は完了。
◆ 実行環境構築
RaspberryPi上に Tensorflow Lite の実行環境を構築する。
● RaspberryPi3のSWAP領域拡張
大容量パッケージをビルドするときはほぼ定型的に必要な作業。
RaspberryPiでパッケージをビルドするときに異常に時間が掛かってしまったり、何時間もハングする原因はSWAP領域不足。
下記コマンドを実行する。
$ sudo nano /etc/dphys-swapfile
CONF_SWAPSIZE=2048
$ sudo /etc/init.d/dphys-swapfile restart swapon -s
● RaspberryPi3へのBazel導入(Google製ビルドツール)
たったの1時間30分のビルド時間を待つだけの心に余裕が無い方は コチラ を使用することでビルドのステップをスキップできる。
深く考えずにBazelのリポジトリをCloneしただけでビルドすると、下記のとおりビルド途中でJavaのヒープエラー(Out of Memory)が発生する。
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at com.sun.tools.javac.resources.compiler_ja.getContents(compiler_ja.java:5)
at java.util.ListResourceBundle.loadLookup(ListResourceBundle.java:195)
at java.util.ListResourceBundle.handleGetObject(ListResourceBundle.java:130)
at java.util.ResourceBundle.getObject(ResourceBundle.java:441)
at java.util.ResourceBundle.getString(ResourceBundle.java:407)
at com.sun.tools.javac.util.JavacMessages.getLocalizedString(JavacMessages.java:190)
at com.sun.tools.javac.util.JavacMessages.getLocalizedString(JavacMessages.java:141)
at com.sun.tools.javac.util.JavacMessages.getLocalizedString(JavacMessages.java:135)
at com.sun.tools.javac.util.Log.localize(Log.java:684)
at com.sun.tools.javac.util.Log.printLines(Log.java:497)
at com.sun.tools.javac.main.Main.resourceMessage(Main.java:610)
at com.sun.tools.javac.main.Main.compile(Main.java:543)
at com.sun.tools.javac.main.Main.compile(Main.java:381)
at com.sun.tools.javac.main.Main.compile(Main.java:370)
at com.sun.tools.javac.main.Main.compile(Main.java:361)
at com.sun.tools.javac.Main.compile(Main.java:56)
at com.sun.tools.javac.Main.main(Main.java:42)
依存パッケージを2段階でインストールする。
openjdk-8-jdk でエラーが発生するが、いったん無視して先へ進む。
JDK の PATH が通っていない、というエラーになる模様。
$ sudo apt update;sudo apt upgrade -y
$ sudo apt-get install -y build-essential openjdk-8-jdk pkg-config zip g++ zlib1g-dev unzip
一度ターミナルを再起動し 、下記コマンドを再び実行する。
ターミナルの再起動は必須。
おそらく今度はエラーが発生しない。
2度実行が必要とか、意味不明。
$ sudo apt-get install -y openjdk-8-jdk
下記のとおり、スクリプト compile.sh を改変したうえでビルドすることで正常に導入できる。
bazel/scripts/bootstrap/compile.sh の124行目に -J-Xmx500M を追記して保存する。
2018年10月13日時点では、bazel-0.17.2 のバージョンであれば特に問題無く成功するようだ。
ビルド完了まで 1時間30分掛かる。
$ cd ~
$ mkdir bazel;cd bazel
$ wget https://github.com/bazelbuild/bazel/releases/download/0.17.2/bazel-0.17.2-dist.zip
$ unzip bazel-0.17.2-dist.zip
$ nano bazel/scripts/bootstrap/compile.sh
#################################################################################
run "${JAVAC}" -classpath "${classpath}" -sourcepath "${sourcepath}" \
-d "${output}/classes" -source "$JAVA_VERSION" -target "$JAVA_VERSION" \
-encoding UTF-8 ${BAZEL_JAVAC_OPTS} "@${paramfile}"
#################################################################################
↓
#################################################################################
run "${JAVAC}" -classpath "${classpath}" -sourcepath "${sourcepath}" \
-d "${output}/classes" -source "$JAVA_VERSION" -target "$JAVA_VERSION" \
-encoding UTF-8 ${BAZEL_JAVAC_OPTS} "@${paramfile}" -J-Xmx500M
#################################################################################
$ sudo bash ./compile.sh #<--- bazelフォルダ直下で実行する
$ sudo cp output/bazel /usr/local/bin #<--- ビルド終了後に必ず実行する
● RaspberryPi3 への Tensorflow Lite 導入
Tensorflow v1.11.0 より新しいリビジョンのものや、古いバージョンのモノをCloneしてビルドすると、あちこちでビルドエラーが発生する。
2018年10月13日時点では、必ず v1.11.0 を指定する必要がある。
すでに 別バージョンのTensorflow が導入されていることを見越して一度アンインストールしている。
なお、手抜きをして $ sudo pip2 install tensorflow==1.11.0 で導入すると、Tensorflow Lite特有のPythonロジック実行部で 未定義シンボルエラー という、訳のわからないバグっぽいエラーが発生して正常に動作しないため特筆しておく。
今回はあえて RaspberryPi 上で Tensorflow全体 をネイティブコンパイルする。
undefined symbol: _ZN6tflite12tensor_utils39NeonMatrixBatchVectorMultiplyAccumulateEPKaiiS2_PKfiPfi
下記コマンドを実行する。
下準備工程で1時間15分掛かる。
公式手順 を実施しただけだと、何故かPythonのWrapperが有効にならなかった (TensorflowがPython内でImportできなかった) ため、Tensorflow全体をBazelでビルドする。
$ cd ~
$ sudo pip2 uninstall tensorflow
$ git clone -b v1.11.0 https://github.com/tensorflow/tensorflow.git
$ cd tensorflow
$ git checkout v1.11.0
$ ./tensorflow/contrib/lite/tools/make/download_dependencies.sh
$ ./tensorflow/contrib/lite/tools/make/build_rpi_lib.sh
$ sudo bazel build tensorflow/contrib/lite/toco:toco
たったの27時間を待てないせっかちなあなたは コチラ を使用することで下記のTensorflowビルドステップをスキップできる。 その場合は、「追加依存パッケージをインストールする」から作業を再開する。
まずはビルドの初期設定をするため、configureスクリプトを実行する。
なんだか良くわからないモノや無駄なモノは軒並み「n」で拒絶し、その他はほぼデフォルトとした。
おそらくバインディング対象のPythonは、 Python2.7 となる。
対話的に質問されるので下記のとおり回答。
「n」が表示されていないところは Enterキー でスキップしている。
$ ./configure
WARNING: Running Bazel server needs to be killed, because the startup options are different.
WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown".
You have bazel 0.17.2- (@non-git) installed.
Please specify the location of python. [Default is /usr/bin/python]:
Found possible Python library paths:
/usr/local/lib/python2.7/dist-packages
/usr/local/lib
/home/pi/tensorflow/tensorflow/contrib/lite/tools/make/gen/rpi_armv7l/lib
/usr/lib/python2.7/dist-packages
/opt/movidius/caffe/python
Please input the desired Python library path to use. Default is [/usr/local/lib/python2.7/dist-packages]
Do you wish to build TensorFlow with jemalloc as malloc support? [Y/n]: y
No jemalloc as malloc support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: n
No Google Cloud Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: n
No Hadoop File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Amazon AWS Platform support? [Y/n]: n
No Amazon AWS Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Apache Kafka Platform support? [Y/n]: n
No Apache Kafka Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with XLA JIT support? [y/N]: n
No XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with GDR support? [y/N]: n
No GDR support will be enabled for TensorFlow.
Do you wish to build TensorFlow with VERBS support? [y/N]: n
No VERBS support will be enabled for TensorFlow.
Do you wish to build TensorFlow with nGraph support? [y/N]: n
No nGraph support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n
No OpenCL SYCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: n
No CUDA support will be enabled for TensorFlow.
Do you wish to download a fresh release of clang? (Experimental) [y/N]: n
Clang will not be downloaded.
Do you wish to build TensorFlow with MPI support? [y/N]: n
No MPI support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]:
Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n
Not configuring the WORKSPACE for Android builds.
Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See tools/bazel.rc for more details.
--config=mkl # Build with MKL support.
--config=monolithic # Config for mostly static monolithic build.
Configuration finished
$ sudo pip3 install keras_applications==1.0.4 --no-deps
$ sudo pip3 install keras_preprocessing==1.0.2 --no-deps
$ sudo pip3 install h5py==2.8.0
$ ./configure
WARNING: Running Bazel server needs to be killed, because the startup options are different.
WARNING: --batch mode is deprecated. Please instead explicitly shut down your Bazel server using the command "bazel shutdown".
You have bazel 0.17.2- (@non-git) installed.
Please specify the location of python. [Default is /usr/bin/python]: /usr/bin/python3
Found possible Python library paths:
/usr/local/lib
/usr/lib/python3/dist-packages
/usr/local/lib/python3.5/dist-packages
/opt/movidius/caffe/python
Please input the desired Python library path to use. Default is [/usr/local/lib] /usr/local/lib/python3.5/dist-packages
Do you wish to build TensorFlow with jemalloc as malloc support? [Y/n]: y
No jemalloc as malloc support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Google Cloud Platform support? [Y/n]: n
No Google Cloud Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Hadoop File System support? [Y/n]: n
No Hadoop File System support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Amazon AWS Platform support? [Y/n]: n
No Amazon AWS Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with Apache Kafka Platform support? [Y/n]: n
No Apache Kafka Platform support will be enabled for TensorFlow.
Do you wish to build TensorFlow with XLA JIT support? [y/N]: n
No XLA JIT support will be enabled for TensorFlow.
Do you wish to build TensorFlow with GDR support? [y/N]: n
No GDR support will be enabled for TensorFlow.
Do you wish to build TensorFlow with VERBS support? [y/N]: n
No VERBS support will be enabled for TensorFlow.
Do you wish to build TensorFlow with nGraph support? [y/N]: n
No nGraph support will be enabled for TensorFlow.
Do you wish to build TensorFlow with OpenCL SYCL support? [y/N]: n
No OpenCL SYCL support will be enabled for TensorFlow.
Do you wish to build TensorFlow with CUDA support? [y/N]: n
No CUDA support will be enabled for TensorFlow.
Do you wish to download a fresh release of clang? (Experimental) [y/N]: n
Clang will not be downloaded.
Do you wish to build TensorFlow with MPI support? [y/N]: n
No MPI support will be enabled for TensorFlow.
Please specify optimization flags to use during compilation when bazel option "--config=opt" is specified [Default is -march=native]:
Would you like to interactively configure ./WORKSPACE for Android builds? [y/N]: n
Not configuring the WORKSPACE for Android builds.
Preconfigured Bazel build configs. You can use any of the below by adding "--config=<>" to your build command. See tools/bazel.rc for more details.
--config=mkl # Build with MKL support.
--config=monolithic # Config for mostly static monolithic build.
Configuration finished
ビルドの実行。 カップラーメンに湯を足して27時間待つ。
高負荷になるたびSSHのパイプが壊れて停止する。
SSH経由ではなく、RaspberryPiへ直接HDMIディスプレイを接続してローカル実行する方法を推奨する。
大容量パッケージをビルドするときにSSHを使用しないのはセオリー。
本家GoogleのBazelのbuildコマンドチュートリアルは コチラ
$ sudo bazel build --config opt --local_resources 1024.0,0.5,0.5 \
--copt=-mfpu=neon-vfpv4 \
--copt=-ftree-vectorize \
--copt=-funsafe-math-optimizations \
--copt=-ftree-loop-vectorize \
--copt=-fomit-frame-pointer \
--copt=-DRASPBERRY_PI \
--host_copt=-DRASPBERRY_PI \
//tensorflow/tools/pip_package:build_pip_package
9時間経過後のビルド中の様子。
14時間経過後のビルド中の様子。
27時間後、ビルド完了後の様子。
下記コマンドを実行し、pipインストール用のwheelファイルを生成する。
$ sudo ./bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg
/tmp/tensorflow_pkg フォルダ配下に wheel ファイルが生成されたようだ。
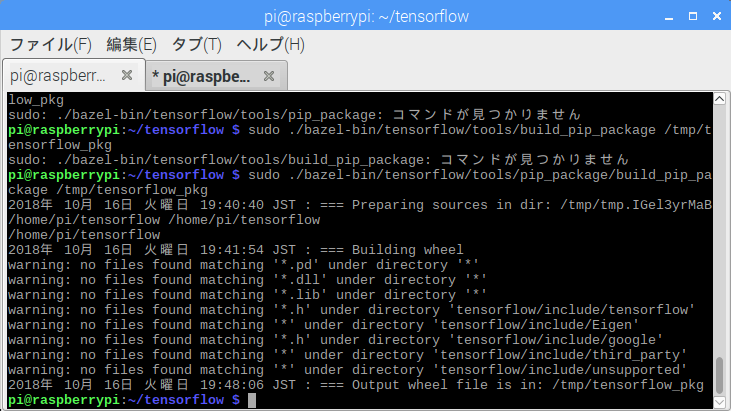
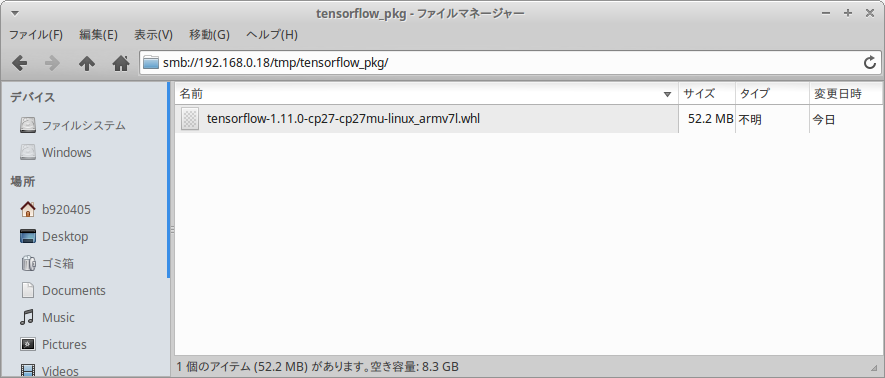
自力で生成した wheel ファイルを使用し、Tensorflow v1.11.0 をインストールする。
$ sudo pip2 install /tmp/tensorflow_pkg/tensorflow-1.11.0-cp27-cp27mu-linux_armv7l.whl
$ sudo pip3 install /tmp/tensorflow_pkg/tensorflow-1.11.0-cp35-cp35m-linux_armv7l.whl
Python3.x系のみココでターミナルを再起動する。ターミナルを再起動しないとTensorflowのimport時に下記のエラーが発生する。
ImportError: cannot import name 'build_info'
無事インストールが完了したようだ。
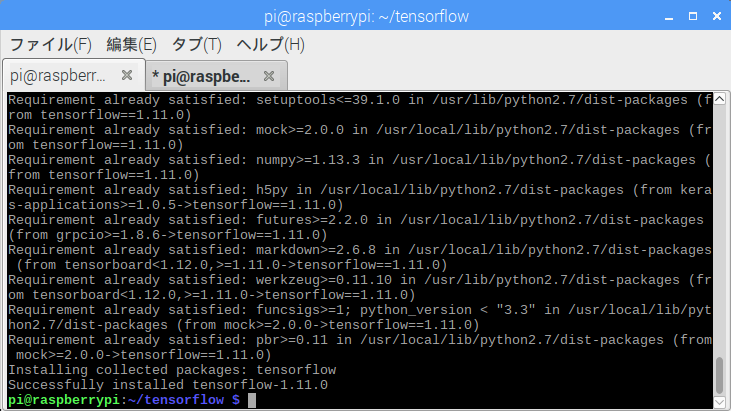
下記コマンドを実行し、追加依存パッケージをインストールする。
$ sudo apt install -y python-scipy python3-scipy
もはや不要となったゴミパッケージのパージ。下記コマンドを実行する。
$ sudo apt remove openjdk-8-*
$ sudo apt purge openjdk-8-*
● RaspberryPi3 で UNet の .pbファイル を .tfliteファイル に変換
学習済みデータを、Protocol Buffer形式から Tensorflow Lite用の Flat Buffer形式へ変換する。
https://www.tensorflow.org/lite/convert/cmdline_examples と
https://www.tensorflow.org/lite/convert/cmdline_reference を参考にした。
$ cd ~/tensorflow
$ mkdir output
$ cp ~/TensorflowLite-UNet/model/semanticsegmentation_frozen_person_32.pb .
.pb->.tflite_変換、量子化 (Quantize) 有効
sudo bazel-bin/tensorflow/contrib/lite/toco/toco \
--input_file=semanticsegmentation_frozen_person_32.pb \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TFLITE \
--output_file=output/semanticsegmentation_frozen_person_quantized_32.tflite \
--input_shapes=1,128,128,3 \
--inference_type=FLOAT \
--input_type=FLOAT \
--input_arrays=input \
--output_arrays=output/BiasAdd \
--post_training_quantize
◆ 動作検証
● Tensorflow v1.11.0 によるENetモデルでのRaspberryPi3動作検証
$ cd ~/TensorFlow-ENet
$ python predict_segmentation_CPU.py
10.2 秒でセグメンテーションされる。
[2018.11.03 Tensorflowを高速化チューニングした] 9.5 秒でセグメンテーションされる。
● Tensorflow Lite v1.11.0 による量子化有効UNetモデルでのRaspberryPi3動作検証
$ cp ~/tensorflow/output/semanticsegmentation_frozen_person_quantized_32.tflite ~/TensorflowLite-UNet/model
$ cd ~/TensorflowLite-UNet
$ python tflite_test.py
< モデルサイズ 【大】 > 9.9MB のモデルだと、11.7 秒でセグメンテーションされる。
モデルサイズがENetの5倍もあるのに処理時間に大差がないことに驚かされる。
< モデルサイズ 【小】 > 625KB のモデルだと、0.4 秒でセグメンテーションされる。
が、苦しい。。。かな?
下記は < モデルサイズ 【小】 > のサンプル。
◆ 【おまけ】tfliteモデルの視覚化
$ cd ~/tensorflow
$ bazel run tensorflow/contrib/lite/tools:visualize -- model.tflite model_viz.html
◆ 【おまけ】ENet の tfliteへの変換
カスタムオペレーションの組み込みができていない、と怒られる。
Tensorflow Lite のチュートリアルに従い、C++ でカスタムオペレーションを自力で実装する必要がある。
pi@raspberrypi:~/TensorflowLite-ENet $ python main.py
Traceback (most recent call last):
File "main.py", line 5, in <module>
interpreter = tf.contrib.lite.Interpreter(model_path="semanticsegmentation_enet_non_quantized.tflite")
File "/usr/local/lib/python2.7/dist-packages/tensorflow/contrib/lite/python/interpreter.py", line 53, in __init__
model_path))
ValueError: Didn't find custom op for name 'FloorMod' with version 1
Didn't find custom op for name 'Range' with version 1
Didn't find custom op for name 'Rank' with version 1
Didn't find custom op for name 'Abs' with version 1
Didn't find custom op for name 'MaxPoolWithArgmax' with version 1
Didn't find custom op for name 'ScatterNd' with version 1
Registration failed.
◆ 本日のまとめ
- なんとか Tensorflow Lite を RaspberryPi 上で正常に動作させることに成功した。
- リアルタイム動画のセグメンテーションをRaspberryPiのCPUのみでまかなおうとすると、10秒のラグを許容する必要がありそうだ。
- 精度が多少悪くても問題無いなら数秒で連続セグメンテーションできそう。ただ、精度は極悪。
- 学習のベースとする素材画像が794枚では少なすぎる。 もう少し色々なデータセットを組み合わせて素材の数を増やせば性能を引き上げられるかもしれない。
- 本当は ENet を Tensorflow Lite に対応させたいんだけど。 C++ が。。。 誰かカスタムオペレーションを実装してくれるか、詳細な実装の方法を紹介してくれないかなぁ。。。
- かなり苦戦しながら記事を書いたため、転記ミスが多いかもしれない。 間違いに気づかれた際はコメント欄にて教えていただきたい。
- ENet の全てのオペレーションが Tensorflow Lite に実装されたら速攻試そうと思う。
- 3ヶ月の子供を抱っこしたまま何時間も記事を書くのはつらい。。。
- [2018.10.28] Tensorflow の公式リポジトリに "ENet" 用カスタムオペレーション対応希望の issue #23320 をあげてみた。