環境
本記事における実装環境です.
- Windows10 professional
- python 3.6.6
- TensorFlow 1.10.0
ソースコードはこちらから.
https://github.com/tks10/segmentation_unet
(2018/8/30: ええ加減だったので少し直しました)
概要
U-NetによるSemantic SegmentationをTensorFlowで実装しました.
SegNetやPSPNetが発表されてる中今更感がありますが、TensorFlowで実装した日本語記事が見当たらなかったのと,意外とVOC2012の扱い方に関する情報も無かったので,まとめておこうと思います.
まずはじめに,本記事を読むに当たり不可欠な要素
- Semantic Segmentation
- U-Net
- Pascal VOC 2012
について,説明しておきます.
(ここらへんを既に分かっている方は実装へ)
Semantic Segmentation
Semantic(意味)の Segmentation(分割)です.
機械学習をかじっている方ならどこかで見たことがあるであろう,アレです.


YOLOなどObject Detectionとの違いは,画素単位で分類を行う点です.
出力がピクセルごとの予測になることから,出力次元数が大きくなることはなんとなく想像できるのではないでしょうか.
U-Net
U-Netは2015年に発表されたセグメンテーションのためのencoder-decoderモデルで,医療用のセグメンテーション課題 (細胞のセグメンテーションなど) で成果を出しました.
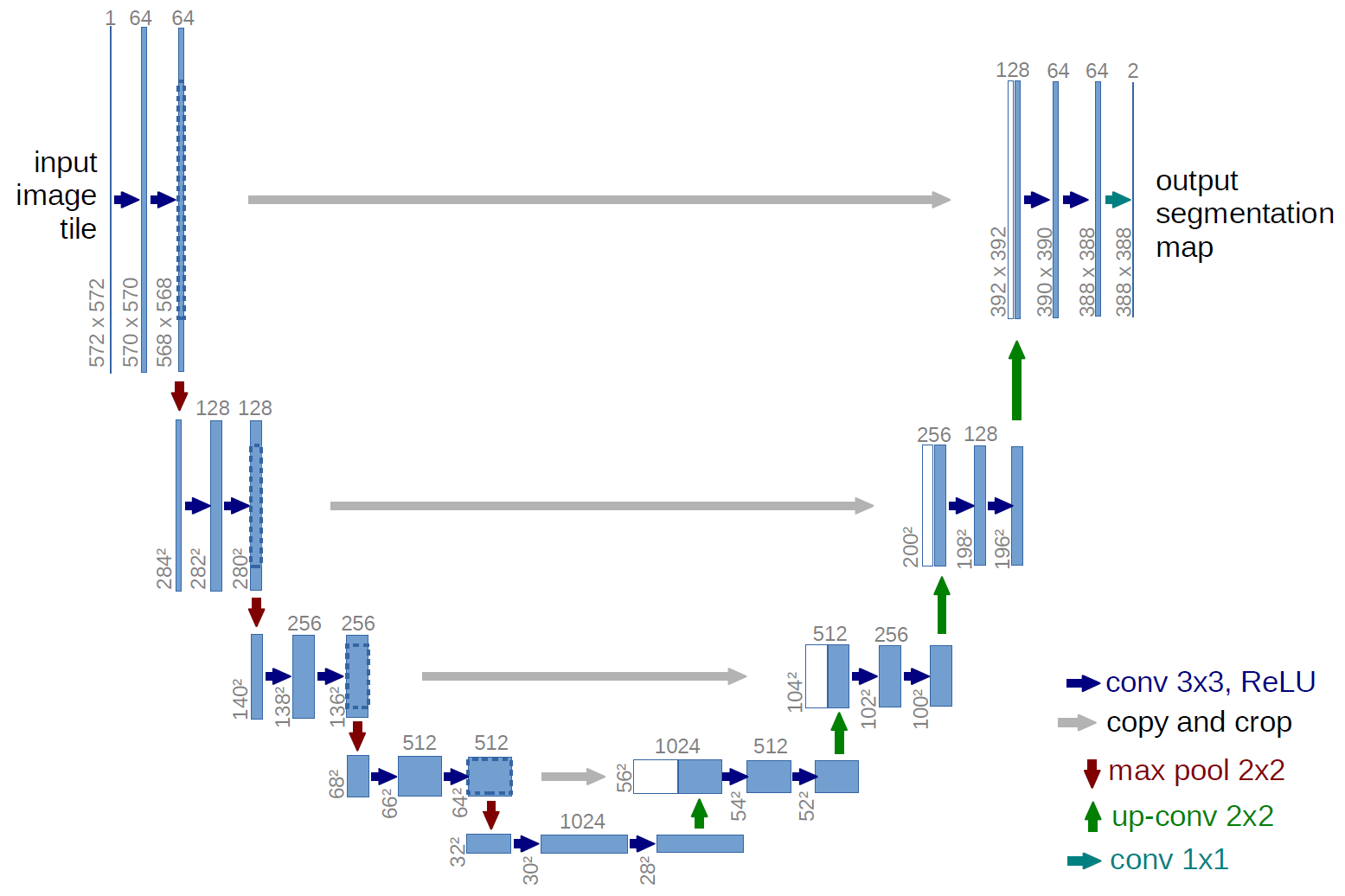
U-Net: Convolutional Networks for Biomedical Image Segmentation
URL : https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
上記の構造が "U" に見えることからU-Netと呼ばれています.
(あれ,どんな構造でも曲げればUになr・・・)
FCNとの違い
基本的にFCN (Fully Convolutional Networks)と比較されることが多いです.
FCNってなんやねん,って方はこちらに原著があります.
いやそういうんじゃなくt...,という方は以下のように日本語の記事があります.
U-NetもConvolution層のみなので厳密に言えばFCN(の改良版)ですが,
本記事においてFCNと記述したときは,オリジナルのFCNを指すこととします.
他の解説記事 (上記の記事ではないです!) において,スキップ結合があることや,全結合層が無いことがU-Netのオリジナリティのように書かれているのを見かけますが,FCNにもスキップ結合はありますし,同じく全結合層もありません.
ただ,確かにそれぞれの要素において改良点はあって,それらとその他の工夫によりSOTAを出したことで知名度が上がったと思われます.
以下,FCNに対するU-netの全体的な構造とスキップ結合の違いについて説明します.
FCNの構造
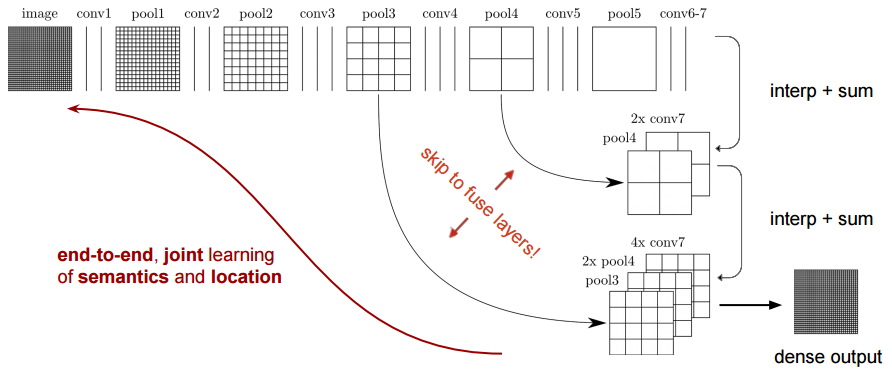
Semantic Segmentation using Fully Convolutional Networks over the years
少し見にくいですが,FCNの構造は上記のようになっています.
upsamplingにbilinear補間を用いているなどの違いもありますが,大きな構造的違いはencoder部分の一部からしかスキップ結合が無いことです.先に示したU-Netの構造では,最初のpooling層からの出力も,decoder部に結合されていました.より低次元の特徴量をスキップすることで,位置情報を保持したままのセグメンテーションができるようになっています.
スキップ結合
先程FCNにもスキップ結合があると言いましたが,細かく見ると少し差があります.FCNの原著では少しわかりにくいのですが,スキップ結合先ではチャネルに対する**和(sum)**をとっています.
対するU-Netでは,チャネルに対する**連結(concatenate)**をしています.スキップ元の情報をそのまま使うことで,位置情報を保っているということですね.
CNNでは特徴マップを畳み込むほど位置情報は曖昧になりますが,Semantic Segmentationにおいて位置情報は非常に重要です.故に,Up-Sampling後にencoder部の同次元数の特徴マップを連結することで,従来どおり特徴を抽出しつつ,位置情報を保持することができます.
Pascal VOC 2012
VOC2012は画像認識用の実写データセットであり,
- Classification
- Detection
- Segmentation
をサポートしています.本家サイトはこちら.
Development Kitの欄から2GBほどのデータがダウンロードできます.
データ
冒頭で述べたとおり,VOC2012を使用します.
公式documentのデータセットに関する説明は豊富なのですが,データのフォーマット等についてはすこし分かりづらい印象を受けました.Detectionタスクではxmlでバウンディングボックスの情報が載っていたりするのですが,Segmentationタスクではオリジナルの画像 (入力データ) とSegmentation後の画像 (教師データ) しかありません.
とすると,教師のラベルはどこに・・・?
まさか,画素値をもとに自前で作る・・・?
なんてことはなくて,ちゃんと画像を読めば分かるようになっています.
自分も最初はわからなかったのですが,色々いじっているうちにPNGカラーパレットのインデックス値をクラスとして扱っていることに気づいて,うまいことできてるな,と.
(Segmentationではスタンダードなのかもしれませんが,実装は初めてだったので知りませんでした)
詳しい読み込み方は以下で述べます.
概要
ディレクトリ構成
ダウンロードしたらまず解凍しましょう.
(windowsだとデフォルトでtarコマンドが入ってないかもしれません.導入法は調べれば出ます.)
tar -xvf pascal_voc_2012.tar
すると,以下のような構成になっていると思います.
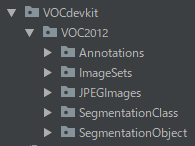
今回Segmentationにおいて使用するファイルは,
- JPEGImages (原画像)
- SegmentationClass (セグメンテーション後画像)
の中にすべて入っています.
(ImageSets/Segmentation内に,Segmentation用の学習と検証用のファイル名のリストがあるのですが,画像データが差し替わっても動作するようにするため,今回は使用していません.)
クラスとインデックス
学習データは背景と境界線を除くと,全20クラスからなります.
クラスインデックスとクラスの対応関係を以下に示します.
本家サイトでは少し見つけにくいのですが,こちらにあります.
| Index | Class | Index | Class |
|---|---|---|---|
| 0 | background | 11 | dining table |
| 1 | aeroplane | 12 | dog |
| 2 | bicycle | 13 | horse |
| 3 | bird | 14 | motor bike |
| 4 | boad | 15 | person |
| 5 | bottle | 16 | potted plant |
| 6 | bus | 17 | sheep |
| 7 | car | 18 | sofa |
| 8 | cat | 19 | train |
| 9 | chair | 20 | tv/monitor |
| 10 | cow | (255) | (void) |
なんとなく通し番号をつけているだけかな,と思いきや,次で述べるデータフォーマットにおいて非常に重要な情報になります.
データフォーマット
先程,入力データも教師データも画像でしか用意されていない,と言いました.
入力データはJPEGファイルであり,何の変哲もない画像データです.
一方,教師データをよく見るとこちらはPNGファイルになっています.
実はこれらの画像,インデクスカラーを使って作成されています.
インデクスカラーについては,以下の記事が分かりやすかったです.
すごく簡単に言うと,色情報はヘッダ部で定義され (パレット),データ本体はそれを参照するインデックスしか持っていないんですね.以下の画像であれば,ヘッダ内で
1:赤, 2:緑
にように定義されているということです.

ここから分かることは,教師データは難しいことをしなくても,
画素値を見ればもう既にクラスインデックスになっている
という事です.
読み込み
ということ,実際にデータを読み込んでいきたいと思います.
(全てコードを載せていると膨大な量になるので,キーになる部分だけかいつまんで解説します)
さて,データが大きい場合には学習時にgeneratorで逐次データを読みこみますが,今回はまだメモリに余裕を持って乗りそうなので,初めに全て読み込んでしまいます.画像の入出力にはPillowを使っています.(AugmentationはTensorflow)
先に注意しておくのが,必ずしも入力画像全てにそれぞれ対応する教師画像が存在しないことです.入力画像の集合を $Original$, 教師画像の集合を$Teacher$としたとき(画像の種類),
Teacher \subset Original
となるわけですね.ですから,教師画像にない画像は使えないということです.
ということで,先に読み込むべきデータのファイル名を生成する関数を作っておきます.
@staticmethod
def generate_paths(dir_original, dir_segmented):
'''
dir_original(str): 入力画像のディレクトリ
dir_segmented(str): 教師画像のディレクトリ
'''
# ファイル名を取得
paths_original = glob.glob(dir_original + "/*")
paths_segmented = glob.glob(dir_segmented + "/*")
if len(paths_original) == 0 or len(paths_segmented) == 0:
raise FileNotFoundError("Could not load images.")
# 教師画像の拡張子を.pngに書き換えたものが読み込むべき入力画像のファイル名になります
filenames = list(map(lambda path: path.split(os.sep)[-1].split(".")[0], paths_segmented))
paths_original = list(map(lambda filename: dir_original + "/" + filename + ".jpg", filenames))
return paths_original, paths_segmented
次に生成したパスを用いて画像をロードしますが,先述したとおり既に教師データにはクラスのインデックスが格納されているため,特に気にせず普通に読み込んでいきます.
from PIL import Image
image = Image.open(file_path) #パスから画像1枚をロード
print(image.mode) #教師データを読み込んだ際,自動で"P"モード(パレットモード)になります
PillowのImageオブジェクトにはモードが存在し,
| モード | データフォーマット |
|---|---|
| RGB | Red, Green, Blueの3チャネル |
| RGBA | Red, Green, Blue, Alphaの4チャネル |
| P | インデクスカラー |
あたりを使うことになります.
今回だと,入力画像がRGBモード,教師データがPモードになります.
ちなみに,convertメソッドでモードの変換が可能です
image_rgbmode = image_pmode.convert("RGB")
前処理
機械学習にあたっては,画像を(0.0~1.0に)正規化するなどの前処理が必要です.
また,VOC2012のデータはそれぞれ画像のサイズが異なります.ですから,今回は各画像を正方形にcrop(切り抜き)し,所定のサイズにリサイズすることで対処します.まとめると以下の4点ですね.(今回のデータセットでは大丈夫ですが,アルファチャネルを持つ画像の場合意図せずshapeが4chになってしまうため,念の為除去しておきます.)
- 画素値の正規化
- crop
- resize
- (アルファチャネルの除去)
ただ,インデクスカラーの画像に正規化をかけても仕方がないので,これらの操作をON/OFF可能なgeneratorとして定義しておきます.使いまわしもできそうですね.
@staticmethod
def image_generator(file_paths, init_size=None, normalization=True, antialias=False):
"""
`A generator which yields images deleted an alpha channel and resized.
アルファチャネル削除、リサイズ(任意)処理を行った画像を返します
Args:
file_paths (list[string]): File paths you want load.
init_size (tuple(int, int)): If having a value, images are resized by init_size.
normalization (bool): If true, normalize images.
antialias (bool): Antialias.
Yields:
image (ndarray[width][height][channel]): Processed image
"""
for file_path in file_paths:
if file_path.endswith(".png") or file_path.endswith(".jpg"):
# open a image
image = Image.open(file_path)
# to square
image = Loader.crop_to_square(image)
# resize by init_size
if init_size is not None and init_size != image.size:
if antialias:
image = image.resize(init_size, Image.ANTIALIAS)
else:
image = image.resize(init_size)
# delete alpha channel
if image.mode == "RGBA":
image = image.convert("RGB")
image = np.asarray(image)
if normalization:
image = image / 255.0
yield image
さりげなくPILオブジェクトをnumpyにキャストしていますが,このように簡単です.
image = np.asarray(image)
このgeneratorを使って,先程のファイル名のリストから画像全てを読み込みます.
images_original, images_segmented = [], []
# Load images from directory_path using generator
for image in Loader.image_generator(paths_original, init_size, antialias=True):
images_original.append(image)
for image in Loader.image_generator(paths_segmented, init_size, normalization=False):
images_segmented.append(image)
assert len(images_original) == len(images_segmented)
# Cast to ndarray
images_original = np.asarray(images_original, dtype=np.float32)
images_segmented = np.asarray(images_segmented, dtype=np.uint8)
ここで注意ですが,先程各インデックス値に対応するクラスを表で載せたと思います.そこでvoid(unlabeled)のインデックス値を255と書きましたが,実際のデータも境界線のインデックスは255となっています(あとからクラス数が増えてもいいように後ろにおいたのかな).
リストで扱うにあたってひとつだけ値が離れているのは扱いづらいので,255→21に変換しておきます.
# Change indices which correspond to "void" from 255
images_segmented = np.where(images_segmented == 255, len(DataSet.CATEGORY)-1, images_segmented)
numpy.whereは,条件によって要素の値をreplaceすることができます.「条件に当てはまる要素だけ変えたい」,という場合は,上記のように第3引数に自分自身のオブジェクトを入れることで実現します.
さて,このあと書いてからtf.losses.sparse_softmax_cross_entropyで良かったなと思ったんですが,インデックス値をone-hotベクトルに直します.せっかく書いたので書かせてください.
# One hot encoding using identity matrix.
if one_hot:
identity = np.identity(len(DataSet.CATEGORY), dtype=np.uint8)
images_segmented = identity[images_segmented]
クラス数分の単位行列を生成して,インデックスに対応するone-hotベクトルfancy indexingによって抽出することで実現しています.numpy.takeでも同じことができますね.(numpy.takeのほうがメモリのオーバーヘッドが少ないと聞きかじったんですが,実際どうなのでしょうか.少しテストしても,速度/メモリ共にそんなに変わらなかったのでした.)
以上で,学習データとして使えるnumpy配列の形に成形することができました.
入力画像と教師画像それぞれのshapeは,
- 入力画像 (RGBなので3チャネル)
input[data_size][width][height][3] - 教師画像 (背景/voidを含む22クラスのone-hotベクトル)
teacher[data_size][width][height][class_size(22)]
となっているはずです.
Data Augmentation
VOC2012でSegmentationに使える画像は,2913枚です.モデルのサイズに対してちょっと少ないですね.ですからData Augmentation(データ水増し)をしようと思います.Data Augmentationについてはこちらの記事などがわかりやすかったです.元のデータを水増しすることでOver fitting(過学習)を抑えることが目的です.
今回はtensorflow.imagesのメソッドたちを用いて,Augmentationを行います.
もちろんTensorFlowのメソッドですから,計算グラフとして構築されます.Augmentation用の計算グラフを構築して,そこに入力画像を流してあげることでAugmentされた画像を得るといった形ですね.ということで,image_augmenter.pyを作成しました.
Augmentationは主題ではないので,例としてhue(色相)を変換する実装だけ紹介します.
def hue(self):
max_delta = 0.5
image_in_processed = tf.image.random_hue(self._ph_original, max_delta)
return {"original": image_in_processed, "segmented": self._ph_segmented}
計算グラフの構築ですから,この時点では具体的なデータは得られません.実行時に前もって定義済みの入力用プレースホルダself._ph_originalとself._ph_segmentedにデータを流すことによって,初めて変換された画像を得ます.今回はhueを含めて4種類のAugmentationを用意しました.
- Flip_left_right (左右反転)
- Brightness (輝度)
- Hue (色相)
- Saturation (彩度)
上下反転は,人や自転車など,逆さに映ることの少ないオブジェクトを含んでいるため実装していません.しかしそれらデメリットより,それ以外の画像が増えることのメリットのほうが大きく実験すれば精度が上がる気もしますが,今回は含めていません.むしろ回転のほうが必要だった気がします.
実験せずに言うのも気が引けますが,このようにAugmentationする際にはタスクの性質を踏まえてオペレーションを決定する必要があります.
例えば顔認識において,データセットに同じサイズの顔しか含まれないのにもかかわらず,テスト時には遠近両用で検出する必要がある場合ならば,縮小/拡大が有効に働くでしょう.
学習
モデル設計
冒頭で述べたとおりU-Netを使います.
U-Netは同じパラメータのconvとpoolの組み合わせを繰り返し使うことになるので,既存の関数をラップしておきます.真面目にすべて書き下すとすごい量になります.
また,再利用しやすくするためできる範囲でstatic methodとして実装しています.
# Convolution layer
@staticmethod
def conv(inputs, filters, kernel_size=[3, 3], activation=tf.nn.relu, l2_reg_scale=None, batchnorm_istraining=None):
if l2_reg_scale is None:
regularizer = None
else:
regularizer = tf.contrib.layers.l2_regularizer(scale=l2_reg_scale)
conved = tf.layers.conv2d(
inputs=inputs,
filters=filters,
kernel_size=kernel_size,
padding="same",
activation=activation,
kernel_regularizer=regularizer
)
if batchnorm_istraining is not None:
conved = UNet.bn(conved, batchnorm_istraining)
return conved
# Batch normalization
@staticmethod
def bn(inputs, is_training):
normalized = tf.layers.batch_normalization(
inputs=inputs,
axis=-1,
momentum=0.9,
epsilon=0.001,
center=True,
scale=True,
training=is_training,
)
return normalized
# Pooling layer
@staticmethod
def pool(inputs):
pooled = tf.layers.max_pooling2d(inputs=inputs, pool_size=[2, 2], strides=2)
return pooled
# Transpose convolution layer (Deconvolution)
@staticmethod
def conv_transpose(inputs, filters, l2_reg_scale=None):
if l2_reg_scale is None:
regularizer = None
else:
regularizer = tf.contrib.layers.l2_regularizer(scale=l2_reg_scale)
conved = tf.layers.conv2d_transpose(
inputs=inputs,
filters=filters,
strides=[2, 2],
kernel_size=[2, 2],
padding='same',
activation=tf.nn.relu,
kernel_regularizer=regularizer
)
return conved
畳み込み,プーリング,BatchNorm, 逆畳み込み層を生成するメソッドです.
一昔前,逆畳み込みはDeconvolution (デコンボリューション) と呼ばれていましたが,誤解を生むとのことで現在はTranspose convolutionなどと呼ばれています.
逆畳み込みについては,こちらの記事がわかりやすいかと思います.
通常の畳込みではpaddingを大きくするほど出力サイズは小さくなりますが,"逆"ですので,
paddingを大きくするほど出力サイズも大きくなります.
気をつけましょう.
さて,メソッドをラップすることで簡素化できたので,これらを使ってU-Netを構築します.
@staticmethod
def create_model(size, l2_reg):
inputs = tf.placeholder(tf.float32, [None, size[0], size[1], 3])
teacher = tf.placeholder(tf.float32, [None, size[0], size[1], ld.DataSet.length_category()])
is_training = tf.placeholder(tf.bool)
# 1, 1, 3
conv1_1 = UNet.conv(inputs, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv1_2 = UNet.conv(conv1_1, filters=64, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool1 = UNet.pool(conv1_2)
# 1/2, 1/2, 64
conv2_1 = UNet.conv(pool1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv2_2 = UNet.conv(conv2_1, filters=128, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool2 = UNet.pool(conv2_2)
# 1/4, 1/4, 128
conv3_1 = UNet.conv(pool2, filters=256, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv3_2 = UNet.conv(conv3_1, filters=256, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool3 = UNet.pool(conv3_2)
# 1/8, 1/8, 256
conv4_1 = UNet.conv(pool3, filters=512, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
conv4_2 = UNet.conv(conv4_1, filters=512, l2_reg_scale=l2_reg, batchnorm_istraining=is_training)
pool4 = UNet.pool(conv4_2)
# 1/16, 1/16, 512
conv5_1 = UNet.conv(pool4, filters=1024, l2_reg_scale=l2_reg)
conv5_2 = UNet.conv(conv5_1, filters=1024, l2_reg_scale=l2_reg)
concated1 = tf.concat([UNet.conv_transpose(conv5_2, filters=512, l2_reg_scale=l2_reg), conv4_2], axis=3)
conv_up1_1 = UNet.conv(concated1, filters=512, l2_reg_scale=l2_reg)
conv_up1_2 = UNet.conv(conv_up1_1, filters=512, l2_reg_scale=l2_reg)
concated2 = tf.concat([UNet.conv_transpose(conv_up1_2, filters=256, l2_reg_scale=l2_reg), conv3_2], axis=3)
conv_up2_1 = UNet.conv(concated2, filters=256, l2_reg_scale=l2_reg)
conv_up2_2 = UNet.conv(conv_up2_1, filters=256, l2_reg_scale=l2_reg)
concated3 = tf.concat([UNet.conv_transpose(conv_up2_2, filters=128, l2_reg_scale=l2_reg), conv2_2], axis=3)
conv_up3_1 = UNet.conv(concated3, filters=128, l2_reg_scale=l2_reg)
conv_up3_2 = UNet.conv(conv_up3_1, filters=128, l2_reg_scale=l2_reg)
concated4 = tf.concat([UNet.conv_transpose(conv_up3_2, filters=64, l2_reg_scale=l2_reg), conv1_2], axis=3)
conv_up4_1 = UNet.conv(concated4, filters=64, l2_reg_scale=l2_reg)
conv_up4_2 = UNet.conv(conv_up4_1, filters=64, l2_reg_scale=l2_reg)
outputs = UNet.conv(conv_up4_2, filters=ld.DataSet.length_category(), kernel_size=[1, 1], activation=None)
return Model(inputs, outputs, teacher, is_training)
class Model:
def __init__(self, inputs, outputs, teacher, is_training):
self.inputs = inputs
self.outputs = outputs
self.teacher = teacher
self.is_training = is_training
これ以上まとめると逆に可読性を損ないそうなので,モデルの構造が見えるこの程度が好きです.
損失関数
ピクセルに対するクラス分類になるので,cross_entropyを使います.
# Set loss function and optimizer
# 誤差関数とオプティマイザの設定をします
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=model_unet.teacher,
logits=model_unet.outputs))
tf.nn.softmax_cross_entropy_with_logits さんはsoftmaxの演算もしてくださるので,ネットワークの出力を恒等関数にしておくのを忘れないようにしましょう.
評価
今回は単純な Pixel-wise accuracy (正解画素の比率) にしましたが,Segmentationタスクでは一般的に,Mean accuracy などクラスごとの比率を正規化した指標を用いることが多いです.意味的には recall と同じですね.画像占める割合が一番大きいbackgroundクラスと,比較的割合が小さいbottleクラスを同等に比較するのはアンフェアだからです.(また,厳密に言えばvoidクラスは評価から除外すべきでしょうが,今回実装はしていませんので気をつけてください)
代表例として以下にPixel Wise AccuracyとMean Accuracyの式を示します.
ただし$n_{ij}$は,正解がクラス$i$である画素に対し,クラス$j$であると予測した数です.
$i=j$なら正解ということですね.
Pixel\verb\-\ wise \, accuracy = \frac{1}{N}\sum_{i=0}^{k}n_{ii}\\
\\
\\
Mean \, accuracy = \frac{1}{k}\sum_{i=0}^{k}\frac{n_{ii}}{t_{i}}\\
\\
\quad\\
N:全画素数 \quad k:クラス数 \quad t_{i}:クラスiの正解画素数 \qquad
結果
結果から言うと,そこそこセグメンテーションできました.
そこそこってどれくらいよ,と言われるので,実際の画像を使って示していきます.
出力画像
| 位置 | 種類 |
|---|---|
| 左 | 入力画像 |
| 中央 | 予測画像 |
| 右 | 正解画像 |
という順番です.
訓練
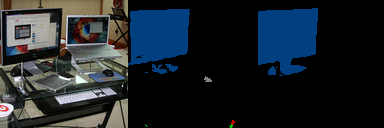


訓練画像なので驚くことではないですが,けっこう鮮明ですね.
大事なのはテストです.
テスト
- 良い例


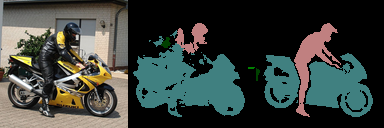
うまく意味単位でセグメントできていない部分もありますが、
正直テストでここまで鮮明に輪郭が出るとは思っていませんでした.
- **ちょっとつらい例**
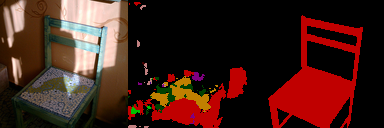
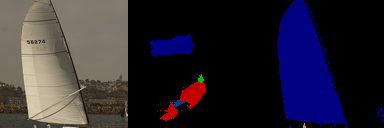
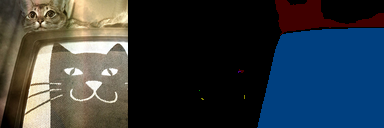
一番下の画像,悪意に満ち溢れていて好きです.
うまくいかない例では,乱雑な画像が出る or 何も出ない というパターンが多いですね.
学習データを見ても分かる通り,かなり様々なシチュエーションの画像が含まれているので,3000枚弱そこらではAugmentationをしても一定の過学習をしてしまいます.
全体的に,うまくいっている画像とうまくいっていない画像,比率は1:1くらいでした.
学習の推移
実験設定
| パラメータ | 値 |
|---|---|
| epoch | 250 |
| batch size | 32 |
| trainrate | 0.85 |
| l2 regularization | 0.001 |
| Optimizer | Adam |
さて,上記の設定で学習の推移を見ていきます.
学習は以下の3パターンを試しました.
- ① Data Augmentationなし, L2正則化なし
- ② Data Augmentationあり, L2正則化あり
- ③ Data Augmentation(Flipのみ)あり, L2正則化あり
Accuracy / Loss
① Data Augmentationなし, L2正則化なし
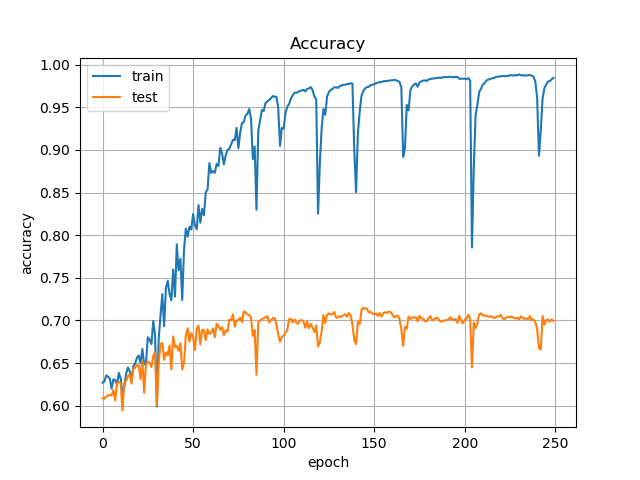
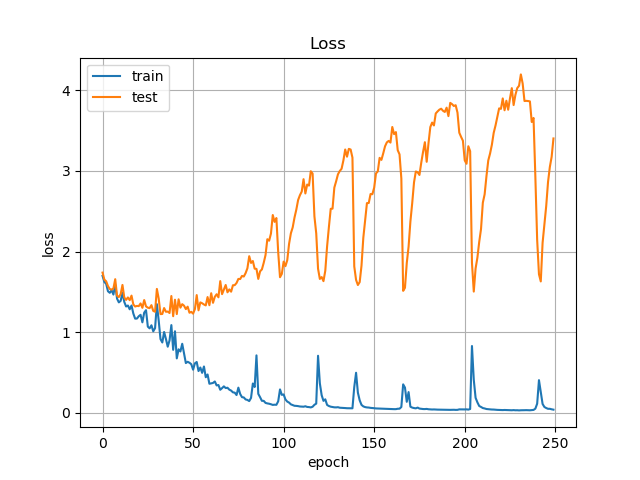
テストの精度は70%くらいですね.Pixel-wiseですから見た目とは直結しませんが,指標にはなります.
Lossを見ると,50epochくらいから大きく上昇してしまっています.過学習してますね.
ただ,Accuracyはあまり連動しておらず下がっていないので,気にしすぎることもないかもしれません.実際の出力画像も,大きくは変わっていませんでした.
さて,手軽に改善できることとして次の2点があるかなと考えました.
- test精度
- 学習の不安定さ
test精度は言うまでもないでしょう,上がるほどよいです.
2つ目に学習が不安定であることを挙げましたが,特にLossの推移に注目すると,後半に大きく振動しています.また,これに連動してAccuracyも低下していますね.
Learning rate を下げることも対処としてありえますが,今回は
- Data Augmentation
- L2正則化
この2点で対処してみたいと思います.
#### ② Data Augmentationあり, L2正則化あり
Augmentationには記事内で紹介したとおり,4つのオペレーションを用意しました.
mnist程度であれば予めAugmentationしてメモリ上に乗せてしまうのですが,VOC2012はカラー画像でサイズもそこそこあります.pickle等でローカルに保存してしまうのもアリですが,試行ごとに異なる変換をしたいのもあり,バッチを作成する際に,画像1枚1枚に対してランダムでAugmentationの処理を適用しました.epochを重ねるほど,一様分布に近づいていくはずです.
学習過程は以下のようになりました.
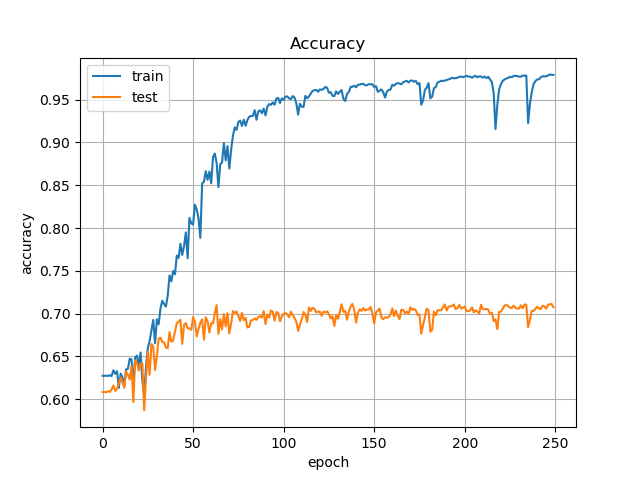
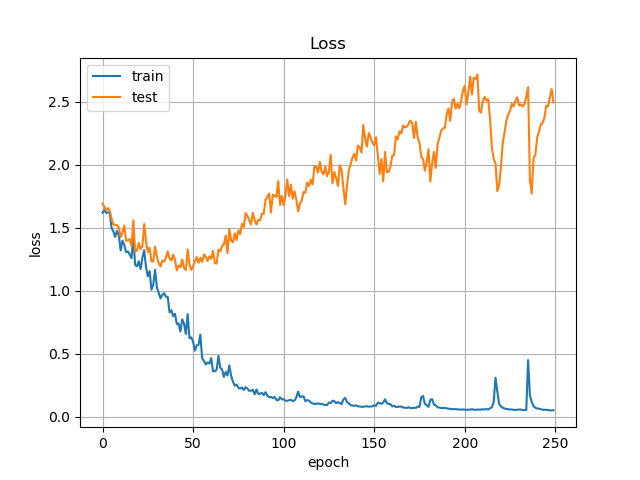
先程は2.5以上振動していたLossですが,1.0未満まで低下しています.Accuracyを見ても,比較的安定したと言えるでしょう.
しかし,思ったよりAccuracyが上がりません.そこで少し仮説を立ててみます.
- 仮説① : 学習が安定化したのはL2正則化の効果であり,そもそもAugmentationの効果がなかった
- 仮説② : Augmentationによって学習は安定化したものの,画像のバリエーションをあまり増やせなかった
仮説①もありえますが,流石に回転/平行移動等のメジャーなオペレーションを使用しなかったからといって,効果はほぼ無いということはあまり考えにくいです.
仮説②は,Augmentationによって正則化のような効果はあったものの,精度を押し上げるまでにバリエーションのある画像を増やすことができなかったのではないか,という考えです.
振り返ってみると,セグメンテーションでは位置情報が大きなカギを握っているタスクであると記事内で言及しました.それにしては,Data Augmentationに位置情報を変換するオペレーションが少なかったと自分で反省しています.
また,VOC2012の画像の撮影条件は見た目的にもどれも似ており,画質の差などはあまり見受けられません.よって,明るさや彩度を変換するオペレーションは,効果的には働かないと予想されます.(もちろんサンプルが増えるため,学習の安定化は大いに望めます)
これらのことから,Augmentationのオペレーションを,位置情報の変換であるFlipのみにする,ことが考えられます.
もし仮説が正しければ,安定化をもたらすオペレーションが減り,また結果的に精度を上げるFlipの比率が増えることで,
学習は若干不安定になるものの,精度は向上する
ことが考えられます.実際にやってみましょう.
#### ③ Data Augmentation(Flipのみ)あり, L2正則化あり
AugmentationにおいてFlipのみを行うようにして,再度学習します.
その他のパラメータは変更していません.
学習過程は以下のようになりました.
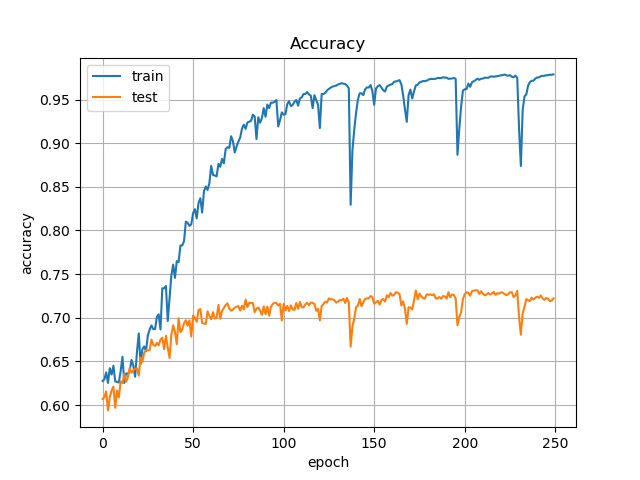
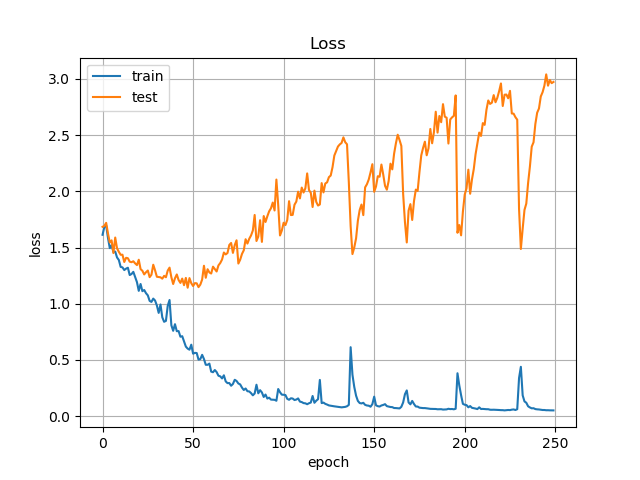
Accuracyに注目すると,先程は約70%だったところが,73%前後まで向上しています.
また,(嬉しくはないですが)学習は②に比べ若干不安定になっています.Lossの振れ幅は1.5くらいですね.
これらのことから,平行移動や回転など,位置情報を変換するようなオペレーションを採用することで,さらなる精度の向上を期待できるでしょう.また,それらのオペレーションを増やすことで輝度や彩度の変換をいれても,精度の低下を招かずに学習を安定化することもできるかもしれません.
さらに精度を上げるには
とりあえず比較簡単に実装できる対処として,先程述べたような実験を行いました.
更に精度を上げるには,損失関数の式を変更する(クラスごとの画素数を考慮する)だとか,モデル自体を改良することが考えられます.
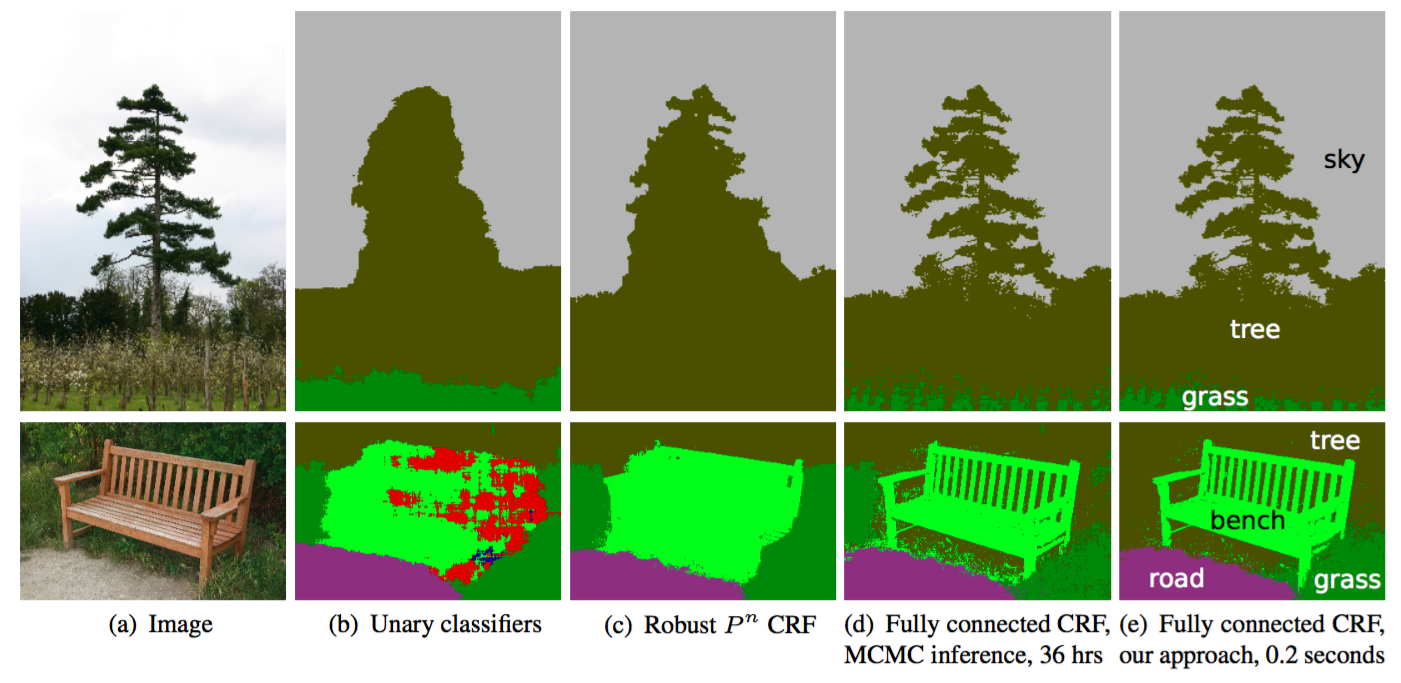
Segmentationの有名な改善策として,**CRF(Conditional Random Field)(条件付き確率場後処理)**といったものもあります.人間ならば自然にやっていることでしょうが,似た輝度の画素値は同じクラスになりやすいだろう,といったことをモデル化したものです.以下のようなイメージで,結構強力な補正ですね.
まとめ
長くなってしまいましたが,U-Netを使って Pascal VOC2012 のデータセットをSegmentationしました.FCNの改良であるU-Netを使うことで,従来に比べ高精細なSegmentationができるようになっています.
今は2018年で,U-Net自体ももう新しいモデルでもなく,その後にSegNetやPSPNetなどの新しいモデルも出ています.しかし,どのモデルも過去のモデルから発想を得ているものがほとんどですから,こうやって実装してみるのもいいかな,と思いました(どんなことにも言えますが).
U-NetとVOC2012,どちらも知識としては知っていたんですが,実際に扱ってみて記事にすることで,意外と自分の知らないところがポロポロと出てきます.FCNのスキップ結合にsumを使っている事とか,なかなか出てきませんでした (最終的にgithubでいろんな人の実装を探したりもした).
英語でググれる力,大事ですね.