データサイエンス タクシーの値段予測?について
解決したいこと
Ridge回帰モデルを作成して予測を実行したいのですが、
予想結果が ほぼ同じような数字、(平均ぽい?)数字になってしまいます。
モデルは、kaggleのNYタクシーの値段の予測のデータセットの
テストデータを10000件のみにしてそれらを train_test_split しています。
使用しているcsvはKaggleの test_data のうちの上から10000行
https://www.kaggle.com/competitions/new-york-city-taxi-fare-prediction/data
jupyter lab を使用しています
コードです
#ライブラリ読込
import numpy as np
import pandas as pd
from scipy import stats
import statsmodels.formula.api as smf
import statsmodels.api as sm
from sklearn.linear_model import RidgeCV
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from geopy.distance import geodesic
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set()
#csv読み込み
data = pd.read_csv('NewYork.csv', nrows=10000)
緯度経度でerrorがあったので90以上の行を削除
data = data.query('pickup_latitude <= 90')
#降りた地点の緯度経度からそれぞれ距離を求める,新しい列 adistance を作成~
data['adistance'] = data.apply(lambda x:geodesic((x["pickup_latitude"], x["pickup_longitude"]), (x["dropoff_latitude"], x["dropoff_longitude"])), axis=1)
#adistance のindex が特殊なデータなので float型へ 変換
data['adistance'] = data['adistance'].astype(str).str[:-3].astype(float)
#散布図にするとこのようになりました
data.plot.scatter(x='adistance',y='fare_amount')
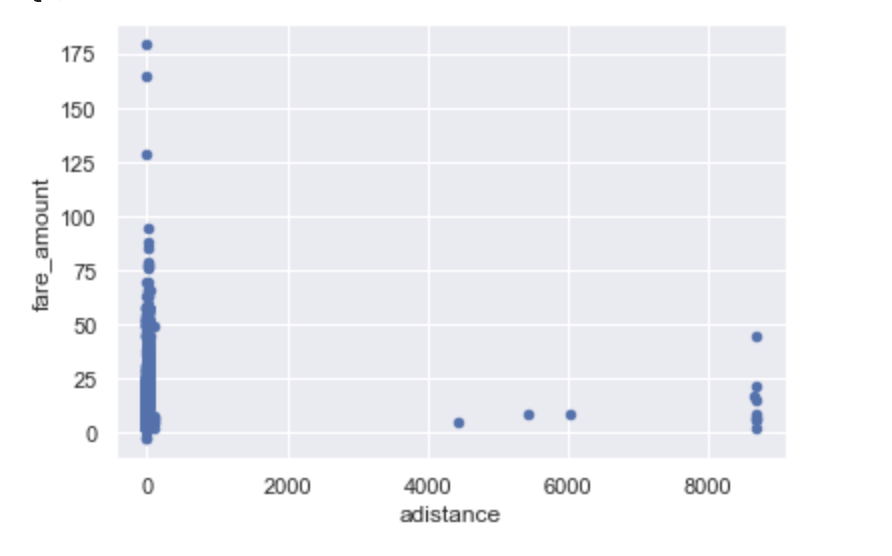
#adistance 大きく外れている値が多いので 2000より小さいものに絞って表示
data.query('adistance < 2000').plot.scatter(x='adistance',y='fare_amount')
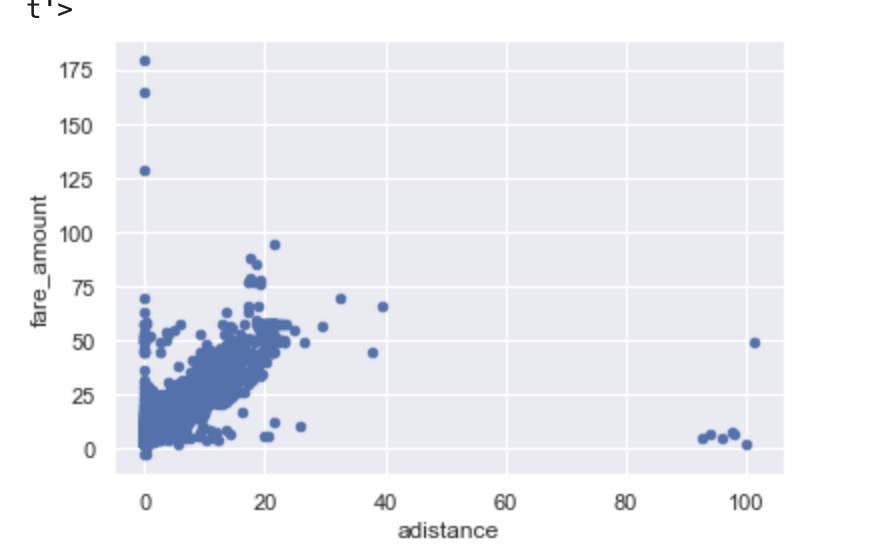
発生している問題です
#fare_amount = x ,adistance = y に代入
X = data['adistance'].values
y = data['fare_amount'].values
#下でエラーが出たので2次元に変換
X = X.reshape(-1,1)
y = y.reshape(-1,1)
#train_test_split する
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,random_state = 2)
X_train, X_valid, y_train, y_valid = train_test_split(X_train, y_train, test_size=0.3,random_state = 2)
# Ridge回帰モデルを作成して予測を実行する
# ambdaを50個つくる
n_lambda = 50
ridge_lambdas = np.logspace(-10, 1, n_lambda)
# RidgeCVを使って最適なlambdaでモデルを構築する
model = RidgeCV(cv = 10, alphas = ridge_lambdas, fit_intercept = True)
model.fit(X_train, y_train)
# テストデータから予測を行います。
y_pred = model.predict(X_valid)
#省略せずに表示する
np.set_printoptions(threshold=np.inf)
print(y_pred)
[[11.31607674]
[11.31211052]
[11.31268757]
[11.31513604]
[11.31296162]
[11.3127759 ]
[11.31233691]
[11.32064725]
[11.31375034]
[11.3171895 ]
[11.31421966]
[11.3144373 ]
[11.31351692]
[11.31230689]
[11.3150098 ]
[11.31379239]
[11.31641956]
[11.31818041]
[11.31181638]
[11.31372906]
[11.31411797]
[11.40207334]
[11.32004773]
[11.33141205]
[11.3188236 ]
[11.31397801]
[11.31233667]
[11.32087634]
[11.31453726]
[11.32510593]
[11.31613114]
[11.3130242 ]
[11.31426498]
[11.31474028]
[11.3157681 ]
[11.3134119 ]
[11.31304438]
[11.31293331]....
というようにずっと 11.いくつが 延々と続きます。
ambdaを50個つくる 以降からは 丸々引用してきたのですが、
切片を求める? fit_intercept の引数を False にし
その後y_pred 予測を行うと
[[1.31234801e-02]
[9.06065791e-04]
[2.68360775e-03]
[1.02257774e-02]
[3.52775870e-03]
[2.95568818e-03]
[1.60344036e-03]
[2.72023395e-02]
[5.95730867e-03]
[1.65511852e-02]
[7.40298417e-03]
[8.07341403e-03]
[5.23830659e-03]
[1.51097296e-03]
[9.83692222e-03]
[6.08684107e-03]
[1.41795102e-02]
[1.96035560e-02]
[0.00000000e+00]
[5.89178040e-03]
[7.08976219e-03]
[2.78024514e-01]
[2.53555827e-02]
[6.03618518e-02]
[2.15848168e-02]
[6.65861851e-03]
[1.60270512e-03]
[2.79080064e-02]
[8.38132722e-03]
[4.09367027e-02]
[1.32910664e-02]
[3.72055651e-03]
[7.54261161e-03]
[9.00669260e-03]
[1.21727460e-02]
[4.91479327e-03]...
このようになりもはやなんの数字かわかりません。
もう少しのような気もするのですが 理解度がきっと足りてない所がたくさんあるような気もします、
根本的に何か間違っているのか、、、?
しかしどのようなことをすれば良いのかわかりません、、どなたかご教授よろしくお願いします。


