アバンは前回と同じことを書いてます。本編は学習モデルのアップグレードからはじまります。
はじめに
Python3とKerasを使った画像認識の勉強をしていますが、ワンストップで完結するTipsがなかなかないので、自分用&後続の人のために一連の流れでMNISTチュートリアルから画像判別まで進めるような内容で書き連ねて行こうと思います。
これを読んで、画像認識の勉強をはじめた人が何か面白いものを作れるようになってくれれば嬉しいです。そしてあわよくば「こんなの作ったよ!」と教えてください。もっと言うと、うちやうち周辺の勉強会で発表してください。お待ちしています。
ぼく自身プログラマでもなんでもないので、ノンプログラマでも理解したうえでコーディングできるように書いていくつもりです。分かりにくいところがあれば教えてくださると助かります。
なお、そもそもディープラーニング・畳み込みニューラルネットワーク(CNN)が何なのかや、仕組み等は詳しく語れる程の知見がないのでこのシリーズでは解説しません。
ディープラーニング・CNNによる画像認識の仕組みを知りたい方は、以下のTipsがとても分かりやすく詳しいので、オススメです。
目標
KerasとMNISTデータセットを使った手書き数字認識を行います。最終的に以下のようなイメージを目指します。
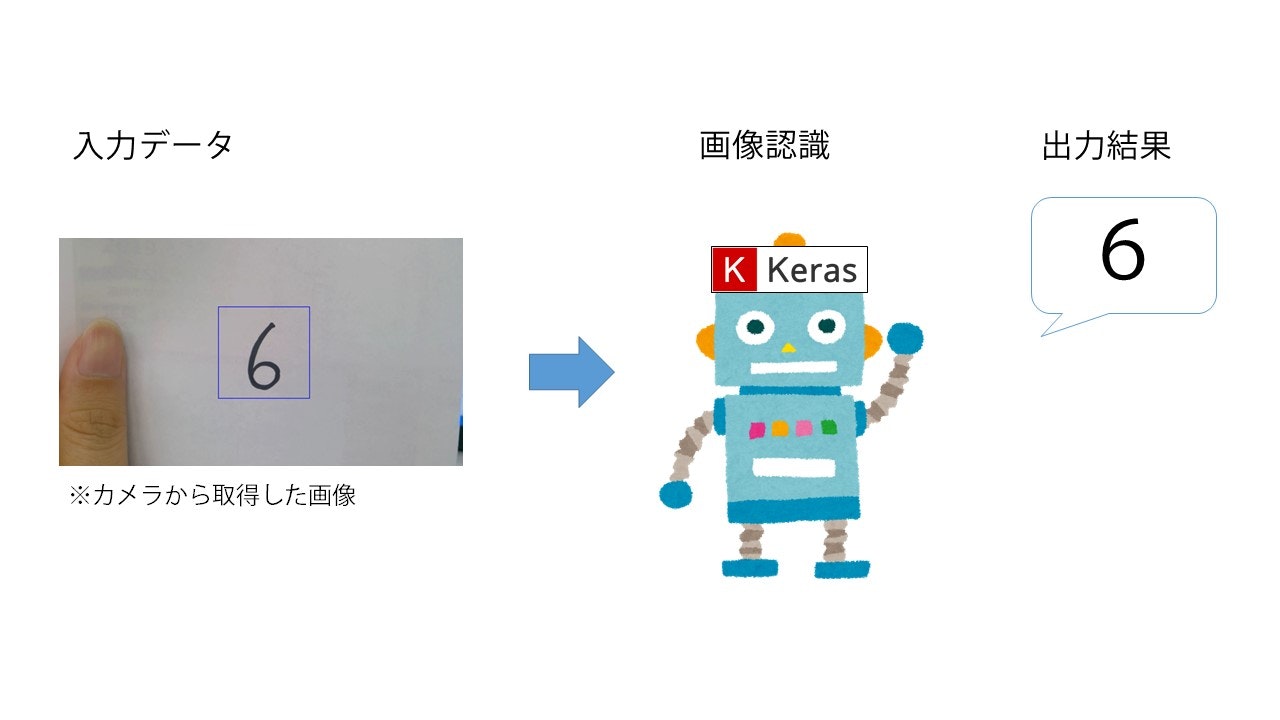
なお、今回は簡単のために一度静止画に保存してから判定させますが、ちょっとした応用でリアルタイム認識も可能と思います。
シリーズ全貌
- 環境構築
- MNISTチュートリアル
- OpenCVチュートリアル
- 学習モデルのアップグレード <-- 今回はここ
- 手書き数字認識(終)
学習モデルのアップグレード
この辺から、やっと独自色が出てきます。前置き長いねん。でもこの記事までが前置きやねん。前置き長いわ。
前々回、MNISTのチュートリアルで学習モデルを作りました。以下のコードです。
from keras.models import Sequential
from keras.layers.core import Dense, Activation
model = Sequential()
model.add(Dense(512, input_dim=(784)))
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
前々回説明しましたが、このモデルは全結合層のみです。そもそも全結合層ってなんやねんっていう話を少しだけすると、入力されたデータを結合して指定された活性化関数に応じて特徴づけする部分です。
この部分だけのモデルだと、テストの前日夜に問題と答えを見て丸暗記しているイメージです。
詳しくはこちらの記事がとてもとても分かりやすいのでご覧ください。
結論から言うと、上のモデルはそもそも畳み込んでないので、ディープラーニングのうまあじを活かせてないわけですね。
MNISTぐらい簡単かつ大量な画像ならそれでもまあまあ上手くいきます。ですが、今後を考えると畳み込み層を追加したモデルは作りたいですよね。ところが、MNISTの全結合層のみモデル構築から畳み込み層込みのモデル構築へとステップアップするTipsはなかなかみつからない。
それが、このシリーズを書こうと思ったそもそもの理由です。伏線回収。
ということで、今回は上のモデルに畳み込み層を加えてモデルをCNNへとアップグレードします。
畳み込み層の追加
今回はモデルの構築から話をしていきたいので、少しコーディングが前後する部分や重複する部分が出ます。わかりにくいところがあるかもしれませんので、最後に今回書いたコードの全文を載せます。行詰ったらそれと見比べてコーディングしてみてください。
KerasのSequentialモデルには、畳み込み層のレイヤーが用意されています。二次元の畳み込み層はConv2D()です。試しに畳み込み層を1層追加してみましょう。
from keras.models import Sequential
from keras.layers.core import Dense, Activation
from keras.layers import Conv2D # 追加した部分
model = Sequential()
model.add(Conv2D(32,(3,3))) # 追加した部分
model.add(Activation("relu")) # 追加した部分
model.add(Dense(784)) # 書き換えた部分
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
Conv2D()を使うには、keras.layersからインポートをします。32は出力ノード数、(3,3)は畳み込み処理の際の特徴フィルターの大きさです。特徴フィルターってなに?っていうのは毎回記事の冒頭に載せているBrandon Rohrerさんの翻訳記事にわかりやすく書いています。
畳み込み層が上にきたことで、全結合層のインプットを指定しなくなりました。784は出力ノードの数ですが、正直この辺の決め方はぼくもよく分かっていません。誰か教えてください。
さて、上のコードですが、実はこのままではエラーを吐きます。MNISTチュートリアルの回で、全結合層は一次元配列しか受け付けないと説明したのを覚えているでしょうか。
Conv2D()は二次元配列を扱うための層なので、画像を一次元配列化しなくても扱うことができます。というか一次元配列に整形したものを入れようとするとエラーになります。そして、Conv2D()の出力もまた、二次元配列です。
よって、全結合層に渡す前に、一次元配列に整形してやらないといけません。Kerasにはちゃんとそういうレイヤーも用意されています。Flatten()を使います。
Flatten()を使うためには、keras.layers.coreからインポートする必要があります。コードを以下のように書き換えてください。
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten # Flattenを追加
from keras.layers import Conv2D
model = Sequential()
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(Flatten()) # 追加した部分
model.add(Dense(784))
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
これでひとまずモデルの構築はできました。他の画像を扱うなら、これで良いのですが「MNIST」はグレースケールの画像で、チャンネル情報を持っていません。ところが、Conv2D()はチャンネル情報を持っていないと受け付けてくれません。
なので、Conv2D()で扱えるように入力データを整形する層を追加して、チャンネル情報を追加します。Reshape()レイヤーです。Reshape()レイヤーはkeras.layersからインポートします。
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, Reshape # Reshapeを追加
model = Sequential()
model.add(Reshape((28,28,1), input_shape=(28,28))) # 追加した部分
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(Flatten())
model.add(Dense(784))
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
MNISTの画像は28×28サイズですので、input_shape()には(28,28)としています。変換後には、チャンネル情報(白黒だけなのでチャンネルは1)を追加してやりたいので、(28,28,1)としています。
これで、ディープラーニングモデルがMNISTのデータを受け取れるようになりました。ですが、折角なのでここでプーリング層も追加して、処理を効率化できるようにしておきましょう。
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, Reshape, MaxPooling2D # Maxpooling2Dを追加
model = Sequential()
model.add(Reshape((28,28,1), input_shape=(28,28)))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2))) # 追加した部分
model.add(Flatten())
model.add(Dense(784))
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
MaxPooling2D()はkeras.layersからインポートします。プーリング層がどういうことをしている層かというのは、Brandonさんの記事を(以下略)ですが、ざっくり言うと指定した窓の大きさ(今回は2×2)の領域を1×1サイズに圧縮する動作です。単純計算で1/4にしていることになります。
窓のサイズは2×2か2×3がうまくいくとBrandonさんが言っているので、今回は2×2にしています。
さあ、これで畳み込み層1、プーリング層1、全結合層1のディープラーニングモデルが完成しました。
ですが、前々回作ったMNIST学習のコードの該当部分をこれに差し替えただけではまだエラーが出ます。
なぜなら、前回は直接全結合層に投入するため、モデルの外でMNISTのデータを整形していたからです。この作業は、モデルの内部に入れ込んだので不要です。書き換えましょう。あるいは、MNIST読み込みの部分をまるっと以下のコードに差し替えてください。
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = np.array(X_train)/255
X_test = np.array(X_test)/255
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
ここにきてnumpy先生が初参戦です。numpyは数値計算や配列を扱うためのライブラリで、Pythonによるデータ分析では必ずと言っていいほど出てきます。使わないとしてもとりあえず呼び出しとけ、ぐらいの勢いで使用頻度が高いです。
今まではたまたま出てきていませんでした。
ここまで来たら、あとはコンパイル&学習です。一気に行きましょう。
model.compile(loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])
hist = model.fit(X_train, y_train, batch_size=200, verbose=1,
epochs=10, validation_split=0.1)
学習が終わったら、評価してみます。
score = model.evaluate(X_test, y_test, verbose=1)
print("正解率(acc):", score[1])
9割5分くらいの正解率が出たでしょうか。前々回の学習よりも、かなり時間がかかるようになったと思います。計算処理が一気に重くなったので仕方ない部分ではありますが、人によってはそう何度もやり直したくないぐらいの計算時間になっているかもしれません。
ということで、前々回紹介した保存方法が活きてきます。
model.save("MNIST.h5")
ちなみに、保存したモデルは以下のコードでロードできます。
from keras.models import load_model
model = load_model("MNIST.h5")
ここまでで、一応モデルのアップグレードは終わりました。ひとまずこれで今回やりたいことに対しては問題ないので、以下は読み飛ばしていただいても結構です。
もう少し汎用性を上げたモデルにする
MNISTくらい単純かつ大量の画像を扱うモデルなら、ここまでで作ったモデルで問題ないです。ですがこれから先、他のデータセットを使ったり、自前でデータを用意して学習させたときに陥りやすい現象として「過学習」があります。
過学習とは、ある問題に特化しすぎて転用が利かなくなった状態のことで、訓練データでは精度が十分なのに検証データにした途端精度がガクッと落ちる、なんてことがままあります。
これを防ぐ方法はいくつかありますが、簡単な方法としてドロップアウト層を追加する、というものがあります。モデルを以下のように書き換えてみてください。
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, Reshape, MaxPooling2D, Dropout # Dropoutを追加
model = Sequential()
model.add(Reshape((28,28,1), input_shape=(28,28)))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.5)) # 追加部分
model.add(Flatten())
model.add(Dense(784))
model.add(Activation("relu"))
model.add(Dropout(0.5)) # 追加部分
model.add(Dense(10))
model.add(Activation("softmax"))
Dropoutレイヤーはkeras.layersからインポートします。ドロップアウトとはその名の通り、その層を通過するときに指定した割合のデータを捨てる層です。このモデルの場合、プーリング層と全結合層を通過した後に半分ずつデータを捨てています。
折角用意したデータを捨てるのか、と思うかもしれませんが、出題される問題が毎回同じだと丸暗記で過学習を起こしやすくなってしまいます。ドロップアウトするデータはepoch毎にランダムですので、こうしておけば毎回ランダムな問題が出題されることになり、過学習を抑制しやすくなります。
また、途中でデータを捨てるので当然処理が軽くなるというメリットもあります。
とはいえ、データを捨てるわけですので、捨てすぎると学習精度が上がらなくなってしまいます。ドロップアウトさせるデータの量はケースバイケースで変えてみるといいと思います。
過学習を抑制する方法としては、他に正規化(バッチノーマライゼーション)なんかもありますが、これはドロップアウトと同時に使っても効果がないので、今回は触れません。
これで、役者はほぼ出揃いました。最後に、我が心の師匠Brandonさんの記事に載っているモデルを再現して、学習モデルの完成としたいと思います。
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, Reshape, MaxPooling2D, Dropout
model = Sequential()
model.add(Reshape((28,28,1), input_shape=(28,28)))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.5))
model.add(Conv2D(16,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(784))
model.add(Activation("relu"))
model.add(Dropout(0.5)) # 追加部分
model.add(Dense(10))
model.add(Activation("softmax"))
これで、かなり汎用性が高い基本的なモデルになっていると思います。
コード全文
今回作ったコードの全文を改めて載せます。
from keras.models import Sequential
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, Reshape, MaxPooling2D, Dropout
# モデル構築
model = Sequential()
model.add(Reshape((28,28,1), input_shape=(28,28)))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(Conv2D(32,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.5))
model.add(Conv2D(16,(3,3)))
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2)))
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(784))
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(10))
model.add(Activation("softmax"))
# MNISTをロード
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = np.array(X_train)/255
X_test = np.array(X_test)/255
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
# コンパイル
model.compile(loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])
# 学習実行
hist = model.fit(X_train, y_train, batch_size=200, verbose=1,
epochs=10, validation_split=0.1)
# 評価
score = model.evaluate(X_test, y_test, verbose=1)
print("正解率(acc):", score[1])
# モデルを保存
model.save("MNIST.h5")
ついでにモデルをロードして学習を再開するコードも載せます(新しくソースを作ってください)。
from keras.datasets import mnist
from keras.models import load_model
from keras.utils import np_utils
import numpy as np
# MNISTデータをロード
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_train = np.array(X_train)/255
X_test = np.array(X_test)/255
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
# 学習済モデルをロード
model = load_model("MNIST.h5")
# 学習実行
hist = model.fit(X_train, y_train, batch_size=200, verbose=1,
epochs=10, validation_split=0.1)
# 評価
score = model.evaluate(X_test, y_test, verbose=1)
print("正解率(acc):", score[1])
# モデルを保存
model.save("MNIST.h5")
以上です。お疲れ様でした。
次回予告
次回は、いよいよ手書き数字を認識させてみます。
シリーズ一覧
- 環境構築
- MNISTチュートリアル
- OpenCVチュートリアル
- 学習モデルのアップグレード
- 手書き数字認識(終)