アバンは前回と同じことを書いてます。本編はOpenCVとはからはじまります。
はじめに
Python3とKerasを使った画像認識の勉強をしていますが、ワンストップで完結するTipsがなかなかないので、自分用&後続の人のために一連の流れでMNISTチュートリアルから画像判別まで進めるような内容で書き連ねて行こうと思います。
これを読んで、画像認識の勉強をはじめた人が何か面白いものを作れるようになってくれれば嬉しいです。そしてあわよくば「こんなの作ったよ!」と教えてください。もっと言うと、うちやうち周辺の勉強会で発表してください。お待ちしています。
ぼく自身プログラマでもなんでもないので、ノンプログラマでも理解したうえでコーディングできるように書いていくつもりです。分かりにくいところがあれば教えてくださると助かります。
なお、そもそもディープラーニング・畳み込みニューラルネットワーク(CNN)が何なのかや、仕組み等は詳しく語れる程の知見がないのでこのシリーズでは解説しません。
ディープラーニング・CNNによる画像認識の仕組みを知りたい方は、以下のTipsがとても分かりやすく詳しいので、オススメです。
目標
KerasとMNISTデータセットを使った手書き数字認識を行います。最終的に以下のようなイメージを目指します。
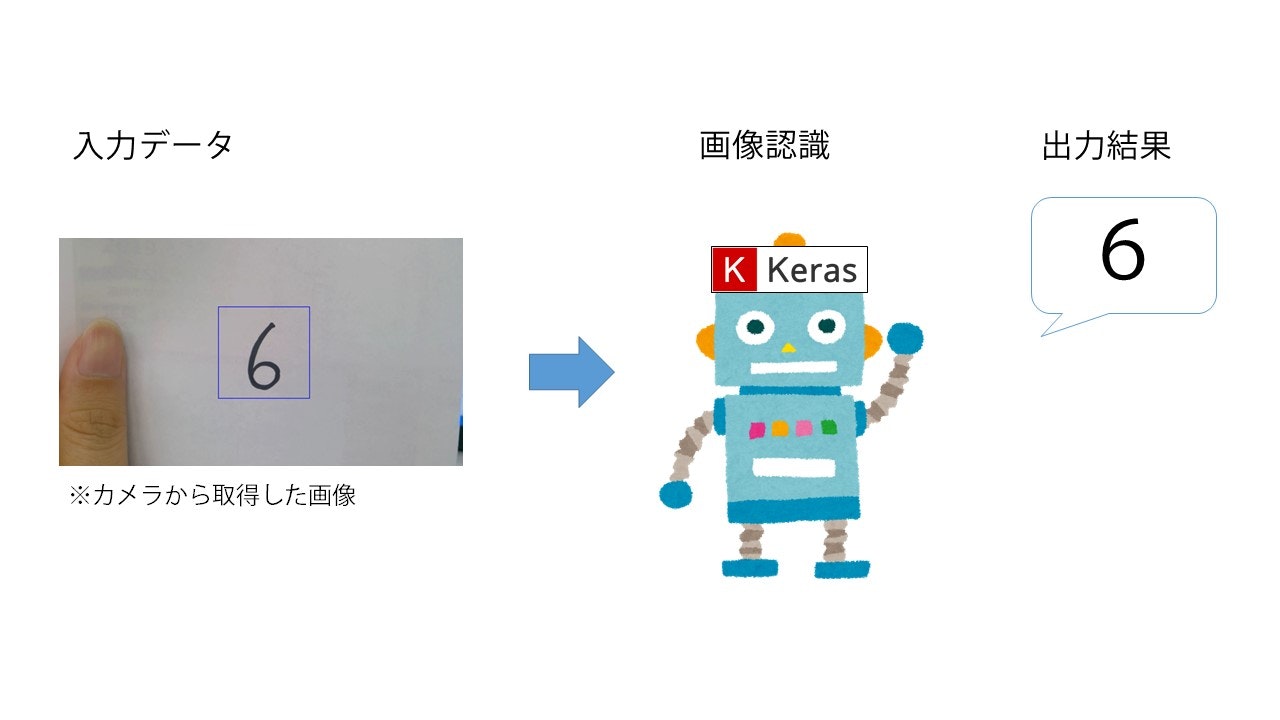
なお、今回は簡単のために一度静止画に保存してから判定させますが、ちょっとした応用でリアルタイム認識も可能と思います。
シリーズ全貌
- 環境構築
- MNISTチュートリアル
- OpenCVチュートリアル <-- 今回はここ
- 学習モデルのアップグレード
- 手書き数字認識(終)
OpenCVとは
Pythonにはいくつかの画像処理用ライブラリが用意されていますが、OpenCVはそのうちの1つです。OpenCVはもともとC++というプログラミング言語で書かれたライブラリで、Pythonでも使えるように翻訳されたという経緯があります。他にはJavaやMATLAB等の言語でも使えるようです。
つまりPythonでOpenCVを習得すれば、他の言語でも同じような処理ができるようになるということです。お得。
Python用の画像処理ライブラリでは、他にはPillow(PIL)というものが有名ですが、どちらかというとあちらは静止画向き、OpenCVは動画向き、という印象を受けます。
今回はOpenCVのチュートリアルを行いますが、動画向きという言葉から受けるイメージのとおり、非常に多機能なライブラリです。実は機械学習もできるらしいです。そんなものを全部勉強しようとすると、大変だと思います。
というわけで、今回はかなり基本的な部分だけ試していきます。
導入
このシリーズの1回目で既に導入済みですが、まだの人のために改めてインストール方法を書きます。Pythonのターミナルを立ち上げてpipインストールを実行してください。
pip install opencv-python
ちなみに既にインストールされてる場合は「もうインストールされてるよ」と言われます。
ちゃんとインストールされているかは、インポートしてみれば確認できます。ターミナルでPythonを立ち上げるか、Jupyter等のエディタで以下のコードを書いて実行してください。
import cv2
エラーを吐かなければ成功です。
コード
OpenCVの基本的な機能について見ていきましょう。まずは画像の読み込みです。
レナさんの画像を用意したので、まずはソースコードが置いてあるフォルダと同じところに保存してください

画像の読み込み・表示
レナさんを保存したら、以下のコードを書いて実行してみてください。
img = cv2.imread("Lenna.png", 1)
cv2.imshow("Window", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
先ほど動作確認したコードとは別に新しいソースコードを作った場合は、import cv2を忘れずに。
OpenCVで画像を読み込んでくるときはimread()を使います。その後の1はカラー画像として読み込みなさい、という意味です。グレースケールで読み込む場合は0とします。試しに書き換えてみてください。
画像を読み込んできただけでは表示されません。むしろ勝手に表示されては困ります。
ウィンドウに画像(動画)を表示させたいときはimshow()を使います。前半の"Window"はウィンドウの名前、後半のimgはウィンドウに移したい画像(映像)です。
「imgという変数(配列)の中に入っている画像をWindowという名前のウィンドウに表示してください」というのが、上の命令です。
その後、waitKey(0)で、何かしらのキーが押されるまで処理を待機して、待機が解除されたらdestroyAllWindows()でウィンドウをすべて閉じます。
画像のサイズを取得
読み込んだ画像の情報を取得してみます。
height, width, channel = img.shape[:3]
print("height :", height, "px")
print("width :", width, "px")
print("channel:", channel)
「height」は縦、「width」は横、「channel」は色要素の数です。カラー画像の場合はshape[:3]とすることで色要素数を取得できます。グレースケール画像の場合は、色要素数は取得できないので同じコードを書くとエラーが返ってきます。
グレースケールの場合はshape[:2]としましょう。
画像のグレースケール化
グレースケールの話が出たので、カラー画像をあとからグレースケール(白黒)に変換する方法も見てみます。
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
色の変換にはcvtColorを使います。COLOR_BGR2GRAYは「BGRの色情報を持っている画像をグレーに変えますよ」ということです。
OpenCVにはCOLOR_RGB2GRAYも用意されていますが、OpenCVで画像を読み込んだ場合、色情報は「RGB」ではなく「BGR」で格納されるため、その画像に対してCOLOR_RGB2GRAYを使うとBとRが入れ替わった変換がされるので注意しましょう。
せっかくなので、ちゃんとグレースケールになっているか見てみます。比較用に元の画像も一緒に表示します。
cv2.imshow("Gray", gray)
cv2.imshow("Color", img)
cv2.waitKey(0)
cv2.destroyAllWindows()

こういう感じで白黒変換されたものが表示されれば成功です。
図形を描画
OpenCVのウィンドウには、画像や映像を出力するだけでなく、図形等を描くこともできます。青い四角を描いてみましょう。
cv2.rectangle(img, (50, 50), (100, 100), (255, 0, 0))
OpenCVでは一番左上の点が原点(0, 0)です。そこからどれくらい離れているかで座標を表します。rectangle()では2点(図形の左上と右下の点)の座標と色を指定すると、四角を描いてくれます。
ちゃんと描画できてるか、見てみます。
cv2.imshow("Rectangle", img)
cv2.waitKey(0)
cv2.destroyAllWindows()

こういう感じに描画されていれば成功です。
画像のトリミング
読み込んだ画像の一部分を切り取ることもできます。
img = img[50:150, 50:150]
こう書いた場合、原点からの距離で「高さ50~150,幅50~150」の100×100の正方形領域を切り取ります。
通常、座標軸を表す場合(x,y)、つまり(幅、高さ)で表すのですが、この命令ではそれが逆です。注意しましょう。
トリミングした画像を表示してみます。
cv2.imshow("Trimming", img)
cv2.waitKey(0)
cv2.destroyAllWindows()

こんな風になってたら成功です(青い四角は出てても出てなくても良いです)。
画像の保存
画像を保存することももちろん可能です。
cv2.imwrite("Lenna_tm.png", img)
" "内は保存するファイルの名前、imgは保存したい画像です。今回のコードと同じフォルダに上のちっちゃい正方形の画像が保存されていれば成功です。
カメラの映像を表示
いよいよカメラから映像を取得して表示してみます。といっても、やることは簡単です。
cap = cv2.VideoCapture(1)
while(True):
ret, frame = cap.read()
cv2.imshow("frame",frame)
k = cv2.waitKey(1) & 0xFF # 64ビットマシンの場合,& 0xFFが必要
if k == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
ここにきていきなりWhileループとかifが出てきますが、ひるまないでくださいね。
やってることは静止画の時と本質的には一緒です。read()で読み込み、imshow()で表示、です。
いままでのimread()がread()に変わってるのと、読み込む前にカメラを指定する命令VideoCapture()が必要になるくらいの違いです。
VideoCapture()の括弧内の数字は、カメラの番号です。PCにカメラが内蔵されている場合、-1か0のどちらかが指定されていることが多いです。USBカメラ等を接続する場合は、1以降が割り振られていると思います。ぼくの機種の場合、外カメラの番号は1でしたので、1を指定しています。ここは、実際に実行してみて確認するのが手っ取り早いと思います。
さて、見慣れない部分を解説していきます。映像を取得するread()ですが、返り値はちゃんと指定したカメラとかが生きてるかのtrueorfalseです。trueorfalseが変数retに、画像が変数frameに格納されます。
これで正常に取得できていれば、あとのimshow()で映像(正確には、フレーム画像)を表示できます。これを、返り値がtrueである限り繰り返すことでカメラの映像を表示し、キーボードで"q"が押されたらループを抜けるようにしています。
waitKey()のあとに& 0xFFと書いているのは、キーボードのコードが64ビットマシンと32ビットマシンで異なるため、これがないと想定したキーとずれてしまうためです。32ビットマシンの場合は、& 0xFFは必要ないです。
最後に、ループを抜けたらrelease()でカメラを開放し、いつものようにdestroyAllWindows()でウィンドウを破棄します。
カメラをつかみ続けているとハングの原因になるので、終わったら開放する癖をつけましょう。キャッチ&リリース。
コードを実行してみて、カメラの映像が表示されていれば今回は終了です。お疲れ様でした。
次回予告
次回は、前回作ったMNIST学習モデルをアップグレードしてみます。
シリーズ一覧
- 環境構築
- MNISTチュートリアル
- OpenCVチュートリアル
- 学習モデルのアップグレード
- 手書き数字認識(終)