はじめに
Python3とKerasを使った画像認識の勉強をしていますが、ワンストップで完結するTipsがなかなかないので、自分用&後続の人のために一連の流れでMNISTチュートリアルから画像判別まで進めるような内容で書き連ねて行こうと思います。
これを読んで、画像認識の勉強をはじめた人が何か面白いものを作れるようになってくれれば嬉しいです。そしてあわよくば「こんなの作ったよ!」と教えてください。もっと言うと、うちやうち周辺の勉強会で発表してください。お待ちしています。
ぼく自身プログラマでもなんでもないので、ノンプログラマでも理解したうえでコーディングできるように書いていくつもりです。分かりにくいところがあれば教えてくださると助かります。
なお、そもそもディープラーニング・畳み込みニューラルネットワーク(CNN)が何なのかや、仕組み等は詳しく語れる程の知見がないのでこのシリーズでは解説しません。
ディープラーニング・CNNによる画像認識の仕組みを知りたい方は、以下のTipsがとても分かりやすく詳しいので、オススメです。
目標
KerasとMNISTデータセットを使った手書き数字認識を行います。最終的に以下のようなイメージを目指します。
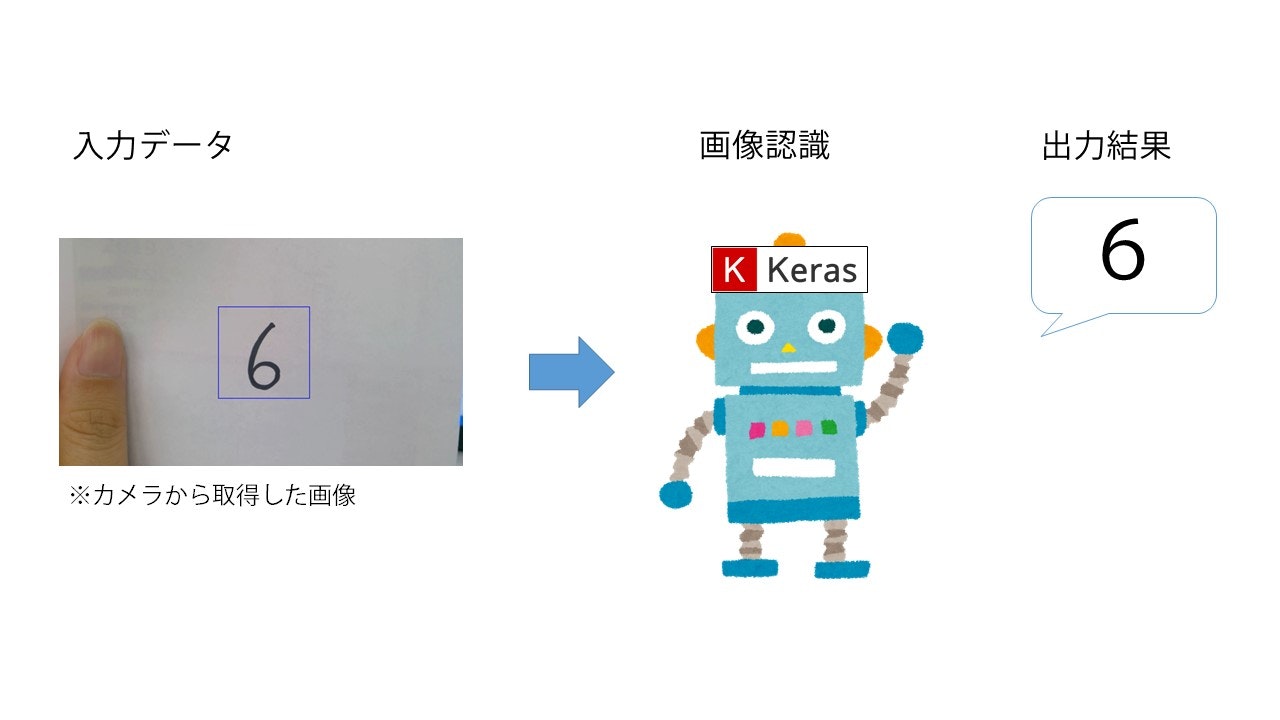
なお、今回は簡単のために一度静止画に保存してから判定させますが、ちょっとした応用でリアルタイム認識も可能と思います。機会があればそっちも記事にしたい。
シリーズ全貌
- 環境構築 <-- 今回はここ
- MNISTチュートリアル
- OpenCVチュートリアル
- 学習モデルのアップグレード
- 手書き数字認識(終)
構成
必要なものを整理します。
「0~9までの手書き数字を見せることで、その数字が何なのかを判別させるプログラム」を作りたいわけですがそのためには、
- ディープラーニング(手書き数字の学習)
- 判別させたい画像(テストデータ)の読み込み
- 読み込んだ画像が何かを判別させる
- 判別した結果を表示する
というムーブが必要になってきます。
画像の読み込みは、今回PCのカメラ(or USBカメラ)を使おうと思うので、OpenCVを使用します。また、画像を判別させるのにディープラーニングを行うため、Kerasを使用します。
Kerasによる画像認識を行うには、本来は画像セットの収集を行わないといけませんが、今回はその手間を省略するため、機械学習のチュートリアル用に用意されているデータセット「MNIST」を使用します。
独自の画像セットを用いたやり方は機会があれば記事にしたいと思います。
なお、このシリーズでは上の内容を段階的に解説していきますが、解説が必要ない方向けにこの記事の最後にコードの全文を載せておきます。
Kerasとは
Pythonのディープラーニング用ライブラリです。ディープラーニングの理論とPythonでのコーディングがほぼ1:1で対応しているので、非常に理解しやすいという特徴があります。
バックエンドでTensorFlowやTheanoといった機械学習ライブラリが動いています。導入は以下の公式リファレンスを参照してください。
ただ、↑のページからKerasを導入しようとすると、まずTensorFlowを入れてね、ということでリンクが張られているのですが、そちらからTensorFlowの公式に行くと2.0ベータ版をインストールさせようとしてくる罠があります。こっちをインストールするとKerasが動かないので、TensorFlowは大人しくpipでインストールしましょう。
その他、graphvizはパスが通ってないとエラーを吐くとか、そもそもKeras公式チュートリアルの**「30秒でKerasに入門しましょう.」のコードがエラー吐く**とかいろいろ罠が潜んでいますが頑張りましょう。
最低限、TensorFlow、HDF5、Keras本体が導入できていれば、少なくともこのシリーズでは大丈夫だと思います。
おまじないで良い人向け導入方法
とはいえ環境が整わないことにはどうしようもないので、調べるのめんどい、いいからここで入れ方教えろという人向けに黒魔術(ターミナルの画面色的な意味で)を書きます。一応、Anaconda Navigatorを前提にしていますが、他の環境でもやり方はそんなに変わらないんじゃないかと思います。
仮想環境をつくる
TensorFlowはPython3.6環境下じゃないと動かないようなので、python3.6の環境(Environment)を用意してやります。Anacondaの場合、Environments>Createで新しく環境を作れます。名前は、自分が分かりやすい半角英数の名前(例えばKerasとか)、Pythonのバージョンは3.6を選択してください。Rは使わないのでチェックしなくていいです。
そこまで終わったら、Createを選んで環境が構築し終わるまで待ちましょう。
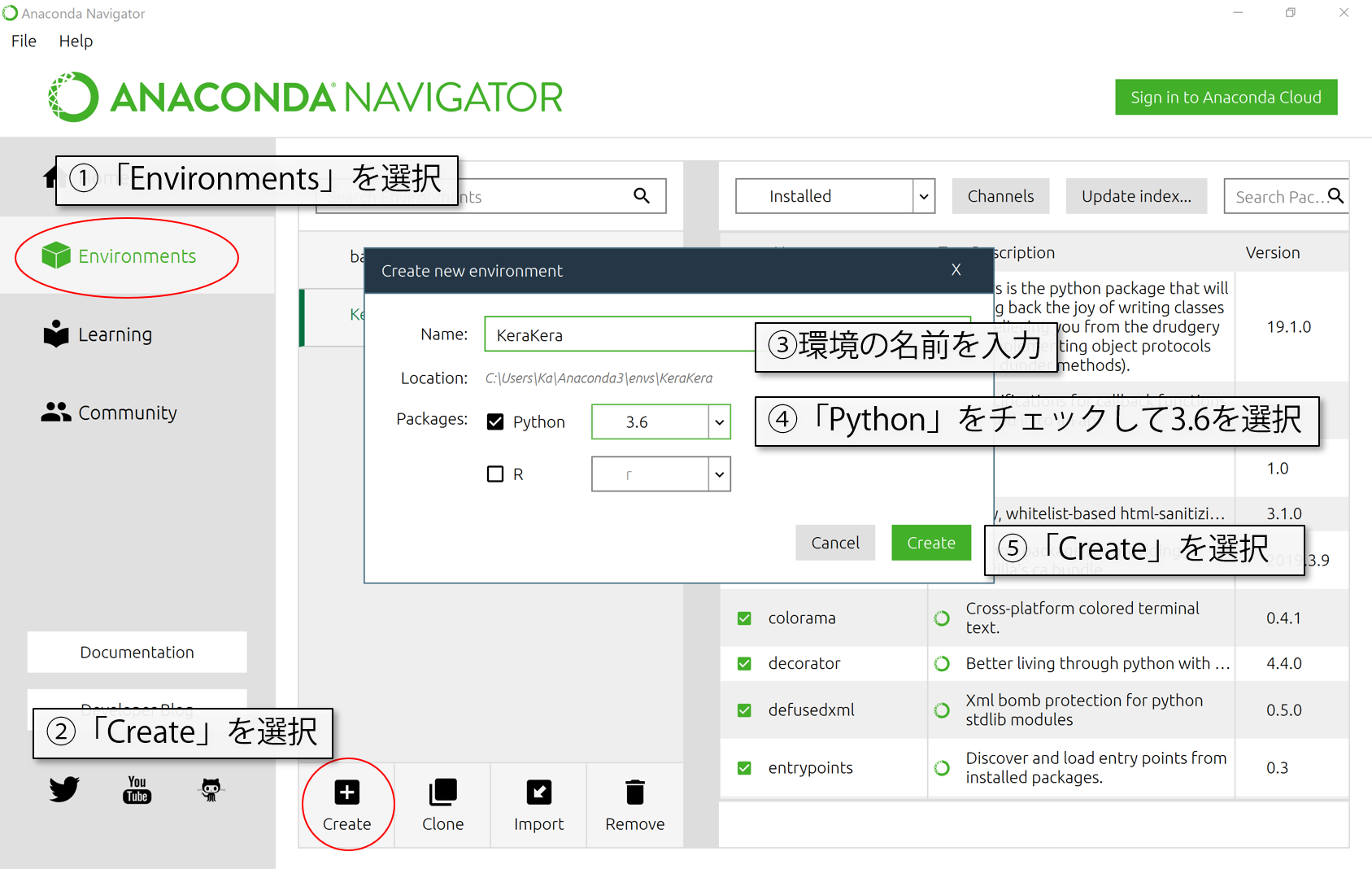
作り終わったらターミナルから必要なものをインストールしていきます。
ライブラリのインストール
環境がちゃんと切り替わっていたら、作った環境の名前の横に再生ボタンみたいなマークがあると思います。そこから、「Open Terminal」を選んでターミナル(黒い画面に白い文字で表示されるちょっと見た目が怖そうなやつ)を起動させましょう。
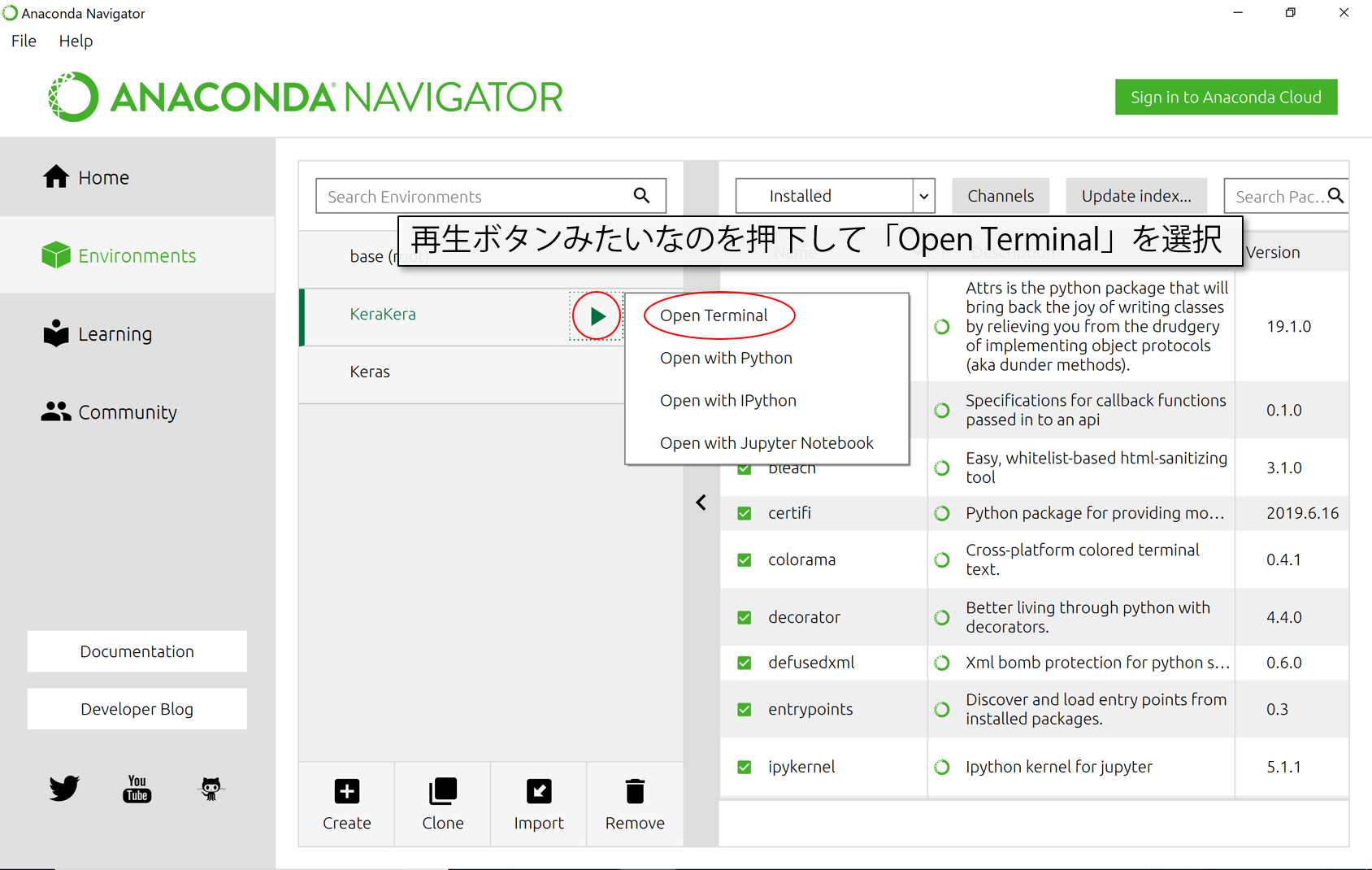
立ち上げたら、以下の呪文をコピペして順番にEnterしていってください。
Keras召喚の儀式
TensorFlowをインストール。Enterを押すとなんか英語で召喚魔法の詠唱がはじまって、ちょっと時間がかかります。
pip install tensorflow
続いてHDF5(学習済モデルを保存するのに必要)を入れます。これはすぐ詠唱が終わります。メラみたいなもんです。
pip install h5py
最後にKerasをインストールします。これもちょっと長いです。
pip install keras
ついでに、あとで使うのでOpenCVもここで入れときましょう。
pip install opencv-python
動作確認
Homeに戻ってJupyterNotebookを準備します。Anacondaは環境毎にアプリケーションをインストールしてやらないといけないので、元々の環境で入っていたとしても環境を新しく作ったら都度この作業が必要になります。
「Install」を押します。
終わったら、「Install」が「Launch」に変わっているはずなので、押してJupyterを立ち上げます。
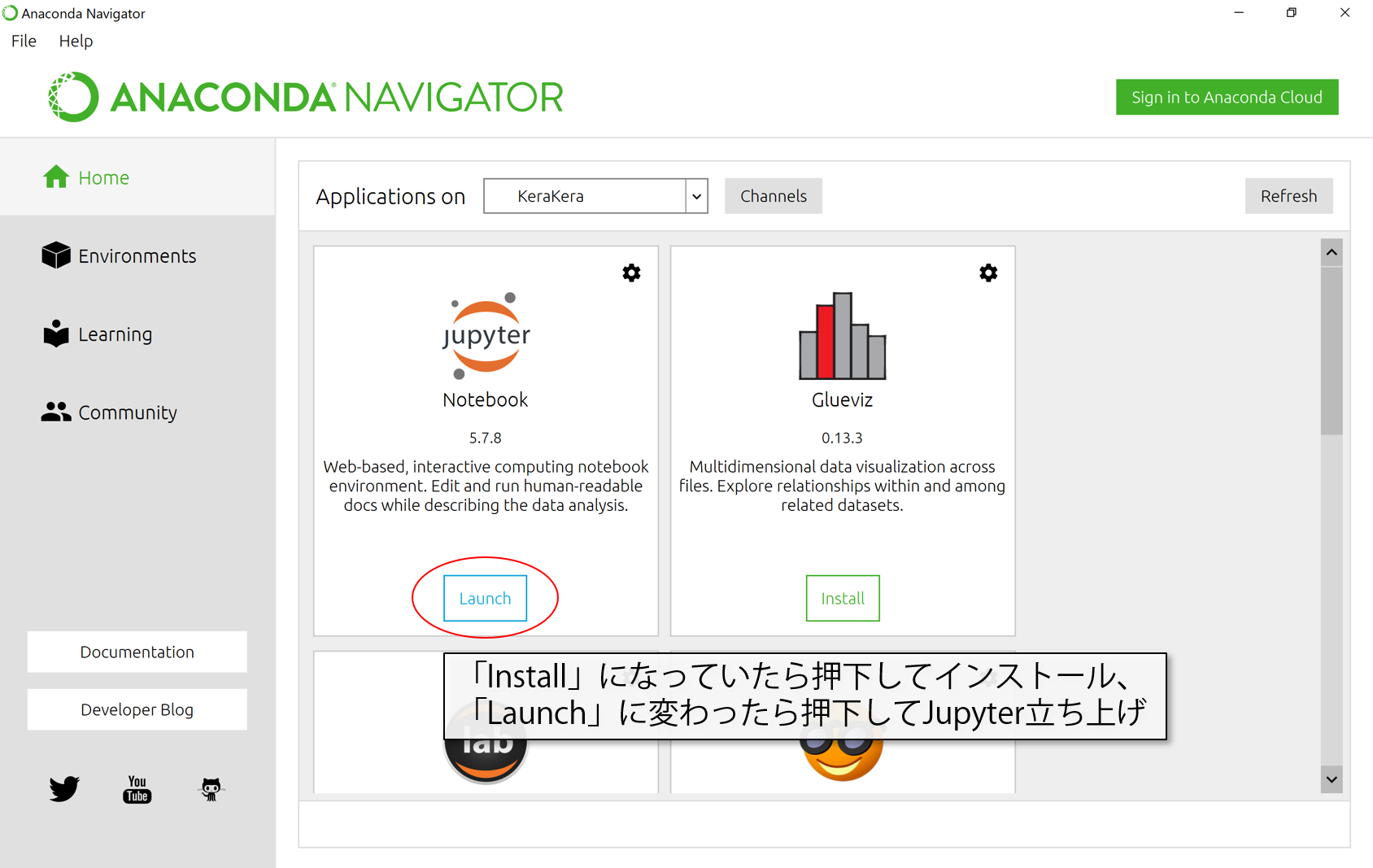
New>Python3を押して、ファイルを作ります。
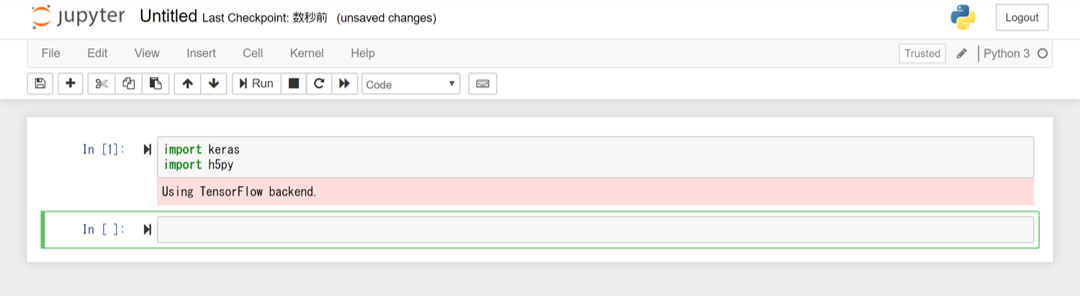
以下のコードを書いてShift+Enterまたは「Run」で実行。
import keras
import h5py
以下のSSのようになれば完了です。お疲れ様でした。
思ってたより長くなってしまったので、実際のコーディング解説は次回からにします。
もしうまくいかなかったら(2020/2/10追記)
import kerasを実行した際にエラーが出る場合、TensorFlowのバージョンとKerasのバージョンがかみ合っていないことが考えられます。
具体的には、以下のようなエラー。
Using TensorFlow backend.
Traceback (most recent call last):
File "<ipython-input-51-ab79294f2004>", line 1, in <module>
import keras
File "C:\Users\...\AppData\Local\Continuum\anaconda3\lib\site-packages\keras\__init__.py", line 3, in <module>
from . import utils
File "C:\Users\...\AppData\Local\Continuum\anaconda3\lib\site-packages\keras\utils\__init__.py", line 6, in <module>
from . import conv_utils
File "C:\Users\...\AppData\Local\Continuum\anaconda3\lib\site-packages\keras\utils\conv_utils.py", line 9, in <module>
from .. import backend as K
File "C:\Users\...\AppData\Local\Continuum\anaconda3\lib\site-packages\keras\backend\__init__.py", line 87, in <module>
from .tensorflow_backend import *
File "C:\Users\...\AppData\Local\Continuum\anaconda3\lib\site-packages\keras\backend\tensorflow_backend.py", line 357, in <module>
name_scope = tf.name_scope
AttributeError: module 'tensorflow' has no attribute 'name_scope'
KerasがTensorFlowの最新バージョンに対応していないと出てくるエラーですので、TensorFlowをインストールし直すと解消します。
Pythonターミナル上でpipアンインストールを実行
pip uninstall tensorflow
その後、バージョンを指定してTensorFlowをインストール
pip install tensorflow==1.14
その後、再度Jupyter等でimport kerasを実行してみて、エラーを吐かなければ成功です。
※warningが出る可能性がありますが、関数のサポートがもうじき終わるよ!というような内容なので、今回は無視して構いません。
次回予告
次回は、MNISTのチュートリアルをします。
コード全文
いいから先に答え見せろという人向けに今回のシリーズで作るコードの全文を載せます。
以下のコードをJupyter等にコピペすれば、MNIST学習~OpenCVでの画像取り込み~画像判別がひととおり動くと思います。
一度学習済みモデルを保存すれば、「# カメラから画像を取得する処理」以降のコードだけでも動きます(当然、各種ライブラリのimportは必要ですが)。
冗長な構文や無駄な変数がありますが、パーツ毎に作っていくため+チュートリアル用なので目をつむってください。
from keras.datasets import mnist
from keras.models import Sequential, load_model
from keras.layers.core import Dense, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, Dropout, Reshape
from keras.utils import np_utils
import numpy as np
import cv2
# MNISTデータのダウンロード
# MNISTは60,000件の訓練用データと10,000件のテストデータを持つ
# (a, b), (c, d) 2セットのタプル
# a,c:shape(num_samples,28,28)の白黒画像uint8配列
# b,d:shape(num_samples,)のカテゴリラベル(1~9)のuint8配列を戻り値として返す
(X_train, y_train),(X_test, y_test) = mnist.load_data()
# 0~1の値じゃないと扱えないので、255で割って0~1の範囲の値に変換
X_train = np.array(X_train)/255
X_test = np.array(X_test)/255
# カテゴリラベルをバイナリのダミー変数に変換する
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
# モデルの構築
model = Sequential()
# MNISTはチャンネル情報を持っていないので畳み込み層に入れるため追加する
model.add(Reshape((28,28,1),input_shape=(28,28)))
model.add(Conv2D(32,(3,3))) # 畳み込み層1
model.add(Activation("relu"))
model.add(Conv2D(32,(3,3))) # 畳み込み層2
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2))) # プーリング層
model.add(Dropout(0.5))
model.add(Conv2D(16,(3,3))) # 畳み込み層3
model.add(Activation("relu"))
model.add(MaxPooling2D((2,2))) # プーリング層2
model.add(Dropout(0.5))
model.add(Flatten())
model.add(Dense(784)) # 全結合層
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(10)) # 出力層
model.add(Activation("softmax"))
# モデルのコンパイル
# 損失関数:交差エントロピー、最適化関数:sgd、評価関数:正解率(acc)
model.compile(loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])
# 学習。バッチサイズ:200、ログ出力:プログレスバー、反復数:50、検証データの割合:0.1
hist = model.fit(X_train, y_train, batch_size=200,
verbose=1, epochs=50, validation_split=0.1)
# 学習結果の評価。今回は正答率(acc)
score = model.evaluate(X_test, y_test, verbose=1)
print("test accuracy:", score[1])
# モデルを保存,削除
model.save("kerastest.h5")
del model
# カメラから画像を取得する処理
# 動画表示
# 使用するカメラの指定, 0:内カメラ, 1:外カメラ
# ※PCの機種やUSBカメラの場合等で番号が違う可能性あり
cap = cv2.VideoCapture(1)
# 無限ループ
while(True):
ret, frame = cap.read()
# 画像のサイズを取得。グレースケールの場合,shape[:2]
h, w, _ = frame.shape[:3]
# 画像の中心点を計算
w_center = w//2
h_center = h//2
# 画像の真ん中に142×142サイズの四角を描く
cv2.rectangle(frame, (w_center-71, h_center-71),
(w_center+71, h_center+71),(255, 0, 0))
cv2.imshow("frame",frame) # カメラ画像を表示
# キーが押下されるのを待つ。1秒置き。64ビットマシンの場合,& 0xFFが必要
k = cv2.waitKey(1) & 0xFF
# ウィンドウのアスペクト比を取得。閉じられると-1.0になる
prop_val = cv2.getWindowProperty("frame", cv2.WND_PROP_ASPECT_RATIO)
if k == ord("q") or (prop_val < 0): # qが押下されるorウィンドウが閉じられたら終了
break
elif k == ord("s"): # sが押下されたらキャプチャして終了
# 画像を中心から140×140サイズでトリミング
# xとyが逆なので注意
im = frame[h_center-70:h_center+70, w_center-70:w_center+70]
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) # グレースケールに変換
# 大津の方法で2値化。retはいらないので取得しない
_, th = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU)
th = cv2.bitwise_not(th) # 白黒反転
th = cv2.GaussianBlur(th,(9,9), 0) # ガウスブラーをかけて補間
cv2.imwrite("capture.jpg", th) # 処理が終わった画像を保存
break
cap.release() # カメラを解放。つかんだままだとハングの原因になる
cv2.destroyAllWindows() # ウィンドウを消す
# 学習完了したモデルで画像判別を試してみる
Xt = []
img = cv2.imread("capture.jpg", 0)
img = cv2.resize(img,(28, 28), cv2.INTER_CUBIC) # 訓練データと同じサイズに整形
Xt.append(img)
Xt = np.array(Xt)/255
model = load_model("kerastest.h5") # 学習済みモデルをロード
# 判定
# predict_classは予測結果のクラスを返す。MNISTは正解ラベル=クラスなのでそのまま利用
result = model.predict_classes(Xt)
print(result[0])
キャプチャした数字が出力されれば成功です。