アバンは前回と同じことを書いてます。本編はMNISTとはからはじまります。
はじめに
Python3とKerasを使った画像認識の勉強をしていますが、ワンストップで完結するTipsがなかなかないので、自分用&後続の人のために一連の流れでMNISTチュートリアルから画像判別まで進めるような内容で書き連ねて行こうと思います。
これを読んで、画像認識の勉強をはじめた人が何か面白いものを作れるようになってくれれば嬉しいです。そしてあわよくば「こんなの作ったよ!」と教えてください。もっと言うと、うちやうち周辺の勉強会で発表してください。お待ちしています。
ぼく自身プログラマでもなんでもないので、ノンプログラマでも理解したうえでコーディングできるように書いていくつもりです。分かりにくいところがあれば教えてくださると助かります。
なお、そもそもディープラーニング・畳み込みニューラルネットワーク(CNN)が何なのかや、仕組み等は詳しく語れる程の知見がないのでこのシリーズでは解説しません。
ディープラーニング・CNNによる画像認識の仕組みを知りたい方は、以下のTipsがとても分かりやすく詳しいので、オススメです。
目標
KerasとMNISTデータセットを使った手書き数字認識を行います。最終的に以下のようなイメージを目指します。
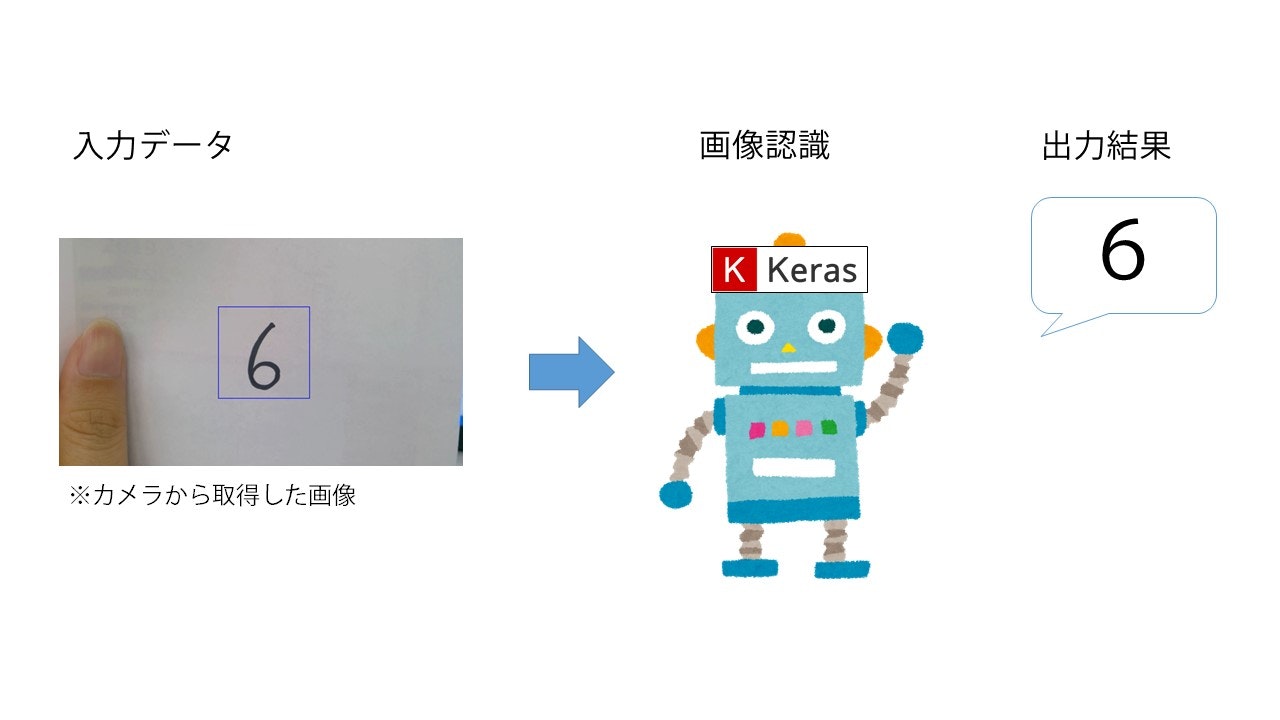
なお、今回は簡単のために一度静止画に保存してから判定させますが、ちょっとした応用でリアルタイム認識も可能と思います。
シリーズ全貌
- 環境構築
- MNISTチュートリアル <-- 今回はここ
- OpenCVチュートリアル
- 学習モデルのアップグレード
- 手書き数字認識(終)
MNISTとは
AI・ディープラーニングというと未だに万能感ある魔法の杖的なイメージで語られることが多いのですが、その実、AIを作るためにやってることは大量のデータセットを集めてマシンスペックで殴るという力技です。
有名どころではGoogleが公開している学習済みモデルデータ「Inception-v3」なんてのがあります。これをロードするだけで1,000種類(!)の画像を判別ができるようになるのですが、その裏ではGoogleが誇るさいつよスペックのマシンで120万枚の画像セットを使って学習させてたりします。やばい。
というわけで、TensorFlowやKerasで身近になったとはいえ、効果的にディープラーニングを行うには、大量の画像とGeekしか買わないようなつよつよスペックマシンを用意してやる必要があります。
具体的には最低でも1万枚くらいの画像と、GTX1050くらいは搭載したマシンが欲しいよねと言われてます。
とはいえ、いきなりそんなもの用意しろと言われても困るので、TensorFlow(と、そのラッパークラスであるKeras)にはそこそこのスペックのマシンでも動かせる、大量のデータセットが予めいくつか用意されています。そのうちの一つが今回扱う「MNIST」です。
「MNIST」には「0」~「9」までの手書き数字画像が70,000枚(訓練用60,000枚、検証用10,000枚)と、それに対応するラベルデータ(この画像は「3」だよ、というような答えのこと)が含まれています。これを使ってディープラーニングの機能を体験してみるのが、ディープラーニングの最初の一歩です。
そんなわけでディープラーニング界の「Hello, World !」と呼ばれることもある「MNIST」チュートリアルですが、プログラミング言語界の「Hello, World !」こと
# include<stdio.h>
int main(void){
printf("Hello, World !\n");
return 0;
}
と違って、「MNIST」だけでも実は結構遊べます。
とにもかくにも今回は「MNIST」でディープラーニング界に「Hello, World !」しましょう。
コーディング
順を追ってコードを書いていきます。以下、黒背景の塊ごとにJupyterのセルに貼り付けてShift+Enterまたは「Run」で実行させていってください。
あと、何か所かでWARNINGが出るかもしれませんが、「その関数、なくなるから他の使ってね」みたいな内容なのでエラーじゃない限りは無視して大丈夫です。
まずはMNISTを落としてこないことにはどうしようもないので、「MNIST」を読み込みます。
from keras.datasets import mnist
(X_train, y_train), (X_test, y_test) = mnist.load_data()
「MNIST」は、先ほども書きましたが、60,000の訓練用画像+ラベルと10,000の検証用画像+ラベルで構成されています。訓練用画像と訓練用ラベルをそれぞれ「X_train」と「y_train」、検証用画像と検証用ラベルを「X_test」と「y_test」に格納するのが、上のコードです。
これでディープラーニングをするためのデータは用意できました。早い。
次はディープラーニングモデルを構築します。
from keras.models import Sequential
model = Sequential()
Kerasのモデル構築は、予め一通りの構造が用意されている「Sequential」モデルと、自分で全部組み立てていく「Functional API」モデルの2種類が用意されています。
Sequentialでのモデル構築が物足りなくなった上級者用のモデルがFunctional APIですので、ぼくたちは大人しくSequentialモデルを使って構築していきましょう。
今回はチュートリアルなのでシンプル&シンプルに、全結合層(と、出力層)のみのモデルを構築してみます。
from keras.layers.core import Dense, Activation
model.add(Dense(512, input_dim=(784)))
model.add(Activation("relu"))
model.add(Dense(10))
model.add(Activation("softmax"))
model = Sequential()で定義したディープラーニングモデルに層を後から追加するためにはadd()を使います。
mogumogu = Sequential()と定義したモデルに全結合層(Dense)を追加したい場合はmogumogu.add(Dense())
と書きます。最初の「512」という数字は出力のノード数です。input_dim=()は入力データの持ってる要素の数(次元数)です。
784個の要素を持っている入力データが入ってきます、ということですね。なぜ「784」なのかは後で説明します。
活性化関数の種類を指定してやるためにはActivation()を使います。活性化関数は何種類か指定してやれるものがありますが、畳み込みニューラルネットワークによる画像処理では「Relu」を使うことが多いそうなので、今回は「Relu」を指定しています。
2つ目のDense(10)は出力層です。今回の答えは「0」~「9」の10通りの数字なので、出力のノード数は10を指定します。活性化関数に「softmax」を指定しているのは、お約束のようなものなので、深く考えず書きます。
この辺の活性化関数の選び方は論文になるレベルのようなので、ぼくたちは脳死で選んでいいんじゃないかと思います。
これでモデルの定義ができました。
ただ、今のままだとモデルを定義しただけで、実際に学習をさせることはできません。学習をさせるためには学習のさせ方をcompileで指定してやる必要があります。
model.compile(loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"])
lossで損失関数を指定します。通常は「交差エントロピー」で良いでしょう。最適化関数はoptimizerで指定します。こちらも、「確率的勾配降下法(SGD)」がデフォルトです。最後のmetricsは評価の方法です。今回は「正解率(acc)」で評価します。
この辺は、行き詰った時以外は変えなくて良いと思います。
これで、データのロード、モデルの構築・宣言まで終わりました。じゃあ次はいよいよ学習、と行きたいところですが、実は今回用意した「MNIST」は「INT型配列」のデータセットです。これ、Kerasでは扱えないデータ種です。まじか。
「MNIST」の画像セットは28×28のグレースケール画像の集合です。1つのドット(点)を、0~255までの整数(INT型)で構成された「二次元配列」で表現しています。ちなみに0は黒、255は白です。
ですがKerasでは0.0~1.0までの、float型の配列じゃないと扱うことができません。もっと言うと、今回はDense層のみの構造ですが、Dense層が入力として受け取れるのは一次元配列のみです。
なので、Dense層が受け取れるように、入力データを整形する必要があります。
X_train = X_train.reshape(60000, 784)/255
X_test = X_test.reshape(10000, 784)/255
前述しましたが、X_trainには60,000個の訓練用画像、X_testには10,000個の検証用画像が読み込まれています。また、1つのデータは28×28の二次元配列です。
これを、28 × 28 = 784 の一次元配列に整形(reshape)するのが、上のコードです。input_dim()で指定した入力値が784だったのは、これが理由です。
また、0~255のデータをKerasで扱えるように0.0~1.0の間の数値に変換してやりたいので、255で割っています。
ところで、先ほど「MNISTはINT型配列」と言ったのを覚えているでしょうか。実はこれ、画像データだけじゃなく、ラベルデータの方もINT型配列です。
そして、Kerasではラベルデータは「バイナリ型」じゃないといけないというルールがあります。バイナリとは0か1ということです。つまり二進数です。
よって、ラベルデータの方もKerasが扱えるように変換してやりましょう。以下のコードです。
from keras.utils import np_utils
y_train = np_utils.to_categorical(y_train)
y_test = np_utils.to_categorical(y_test)
これによって、「0」は「0」、「1」は「1」、「2」は「10」という風に変換されます。この時、変換された二進数の変数を「ダミー変数」といいます。
今回、形上は10進数から2進数への変換なのでなんでダミーなんて呼ぶのか理解しにくいのですが、例えば
「リンゴ」というラベルを「0」、「ミカン」というラベルを「1」、「バナナ」というラベルを「10」とします
という言い方をするとわかりやすいでしょうか。要は本来なんの関連性もない2つを勝手に関連付けてルール化してるので「ダミー」なわけです。
ともあれ、これでようやく準備が整いました。いよいよ学習させます。
hist = model.fit(X_train, y_train, batch_size=200, verbose=1,
epochs=10, validation_split=0.1)
ここで重要になるのはbatch_sizeとepochsです。batch_sizeは一度に放り込むデータの数です。今回は200個の画像をまとめて放り込んで処理しています。
epochsは学習を繰り返す回数です。基本的に繰り返すほど賢くなりますが限界はあります。今回は10回繰り返しますが、概ね100回ほど繰り返して正解率がイマイチなら、入力データを見直すか、モデルの構築を再設定してやった方が良いです。
validation_splitは、入力データの何割を検証用に回すかの設定です。MNISTは既に10,000個が検証用データとして用意されてるので、60,000個の中から更に検証用に回すの?と思われるかもしれませんが、ここで設定した割合での分割は、epoch毎にランダムで割り振られるので、過学習を防ぐのと、正解率を上げるのに貢献してくれます。
人間でも、出題される問題が順番どおりだと順番で答えを覚えちゃうけど、出題がランダムだとそうもいかなくなりますよね?あれと同じようなもんです。
なお、verboseは学習過程の表示の仕方で、「1」を指定するとプログレスバー方式で表示してくれます。
ここまでのコードを実行すると、出力部分がわちゃわちゃしだすと思います。これが止まると学習完了なのでしばらく待ちましょう。
最終的に、下のような表示になると思います。

せっかく学習させたので、検証用データでどのくらいの正解率かを見てみましょう。
score = model.evaluate(X_test, y_test, verbose=1)
print("正解率(acc):", score[1])

大体、9割くらいの正解率になっていれば、今回のところは成功です。お疲れ様でした。
ところで、せっかく学習させたので、学習済モデルを保存したいと思いませんか?思いますよね。
ということで、以下のコードで保存しましょう。
model.save("MNIST.h5")
h5pyがちゃんとインストールできていれば、今回のコードがあるフォルダに上の名前で保存されるはずです。
保存したモデルは、もちろんロードすることができます。
from keras.models import load_model
model = load_model("MNIST.h5")
そのままfitしてやれば、保存した続きから学習を再開することも可能です。
hist = model.fit(X_train, y_train, batch_size=200, verbose=1,
epochs=10, validation_split=0.1)
次回予告
次回は、OpenCVのチュートリアルをします。
シリーズ一覧
- 環境構築
- MNISTチュートリアル
- OpenCVチュートリアル
- 学習モデルのアップグレード
- 手書き数字認識(終)