アバンは前回と同じことを書いてます。本編はMNISTの正体からはじまります。
はじめに
Python3とKerasを使った画像認識の勉強をしていますが、ワンストップで完結するTipsがなかなかないので、自分用&後続の人のために一連の流れでMNISTチュートリアルから画像判別まで進めるような内容で書き連ねて行こうと思います。
これを読んで、画像認識の勉強をはじめた人が何か面白いものを作れるようになってくれれば嬉しいです。そしてあわよくば「こんなの作ったよ!」と教えてください。もっと言うと、うちやうち周辺の勉強会で発表してください。お待ちしています。
ぼく自身プログラマでもなんでもないので、ノンプログラマでも理解したうえでコーディングできるように書いていくつもりです。分かりにくいところがあれば教えてくださると助かります。
なお、そもそもディープラーニング・畳み込みニューラルネットワーク(CNN)が何なのかや、仕組み等は詳しく語れる程の知見がないのでこのシリーズでは解説しません。
ディープラーニング・CNNによる画像認識の仕組みを知りたい方は、以下のTipsがとても分かりやすく詳しいので、オススメです。
目標
KerasとMNISTデータセットを使った手書き数字認識を行います。最終的に以下のようなイメージを目指します。
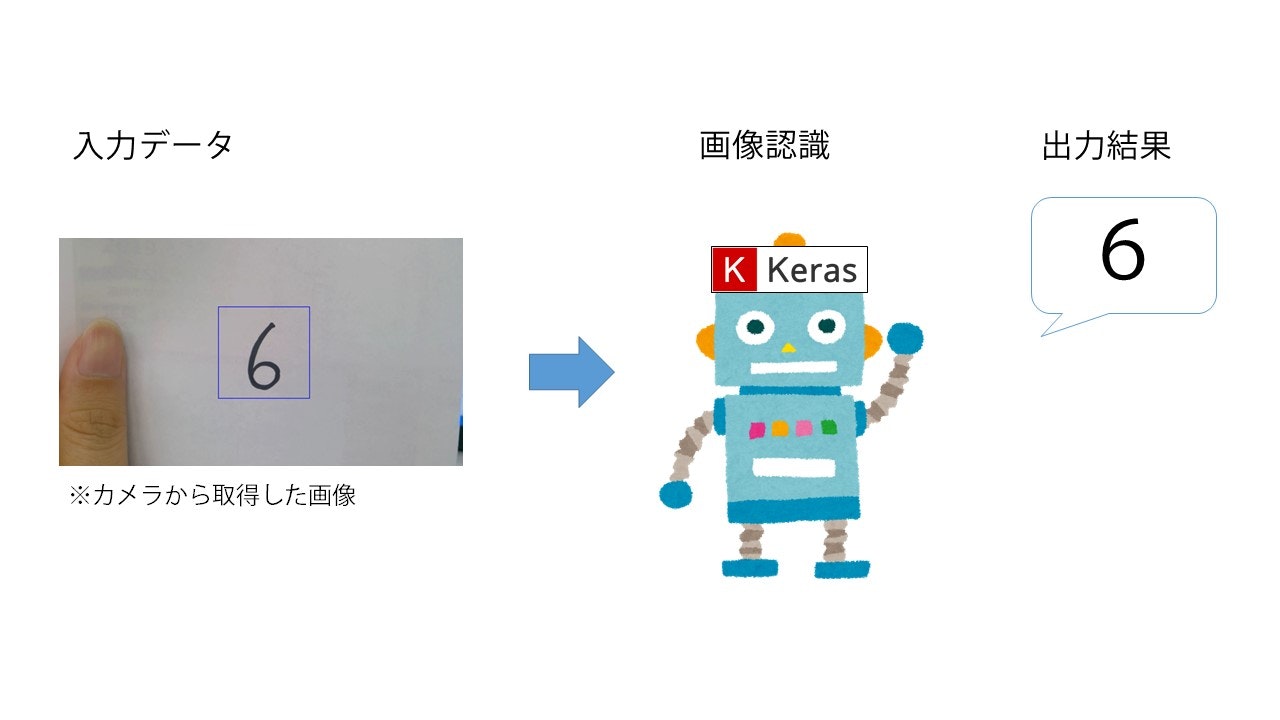
なお、今回は簡単のために一度静止画に保存してから判定させますが、ちょっとした応用でリアルタイム認識も可能と思います。
シリーズ全貌
- 環境構築
- MNISTチュートリアル
- OpenCVチュートリアル
- 学習モデルのアップグレード
- 手書き数字認識(終) <-- 今回はここ
MNISTの正体
Tensorflowにヘソを曲げられて原因を調べる作業をしていたら遅くなりました(言い訳になっていない言い訳)。TensorflowがGPU専有しようとする仕様だなんて私聞いてない
詳細は別の記事にまとめたので見てくれてら嬉しいです。
余談はさておき本題です。今回が最終回ですが、実はディープラーニングについては前回で終わっています。今回は、誰もが気になる(で、あろう)、じゃあ学習させたデータの活用ってどうするの?という部分。いよいよ手書き数字認識をさせます。
その前に改めて覚えておきたい注意点として、認識させたい手書き数字の画像は学習させたモデルのデータセットと同じような形である必要があります。
国語の勉強をしてテストに臨んだら当日出てきたのが英語のテストだった、ではテストの結果は良くなるわけないですよね。
人間なら要領の良い人は国語の勉強の応用で英語の問題もある程度解けるかもしれませんが、コンピュータは人間と比べて全然応用が利かないので、テストデータ(今回はカメラで撮ってきた画像)は学習データセットと同じルールのデータじゃないといけません。
つまり、「MNISTの1枚の画像と同じサイズ、同じ色ルールの画像」じゃないと正確な判別ができないのです。
今まで「MNISTは28×28の白黒画像」と繰り返しお伝えしてきました。ですが、どうせなら正体を自分の目で確かめたいですよね。
というわけで、せっかく勉強したOpenCVを使って、そもそもMNISTに入ってる画像がどんなものなのかを見てみましょう。最終回にして真の姿を見せるなんて、ラスボスみたいですね。
import cv2
from keras.datasets import mnist
(X_train,_),(_,_)=mnist.load_dataset()
cv2.imshow("MNIST", X_train[100])
cv2.waitKey(0)
cv2.destroyAllWindows()
OpenCVでの画像の表示は、前回と同様です。少し横道に逸れますがなにかしらの値を取得してくるとき、Pythonでは必要ない変数を_とすることで、取得しないようにすることが可能です。今回は、MNISTの画像データがどういう姿をしているのかを確認したいだけなので、MNISTのロードの際にX_train以外を省略しました。
X_train[100]は「X_train」という配列の100番目の値という意味です。
さて、何が見えたでしょう?黒いバックに白い数字のような小さいなにかが映し出されましたでしょうか?100の部分を変えると、他の数字(のようななにか)も見えると思います。
これが、MNISTに入っている画像の正体です。
せっかくなので、サイズも測ってみます。
height, width = X_train[100].shape[:2]
print("height:", height, "px, width:", width, "px")
表示された数字が、MNIST画像1つのサイズです。縦:28px, 横:28pxと出たと思います。
これでMNISTの画像が「黒背景に白で書かれた28×28サイズの画像」ということが確認できました。
必要な機能の再確認
上の確認で、MNISTの画像ルールが分かりました。つまり、手書き文字を認識させるためには見せる画像が
- 28×28サイズ
- 白黒(しかも黒背景)
のルールに従っていないといけないわけです。
こう書くと、最初から28×28サイズの画像を撮影して、見せる画像は黒い紙に修正ペンで書いた数字にしないといけないのか、と思うかもしれませんが、そんな大変なことしたくないしそもそも黒地に白で書いたところでカメラがフルカラーなら撮ってきた画像はフルカラーです。
なので、カメラで写す画像の方は極力いじらず、撮った写真を加工する方向で考えた方が現実的です。
PCのカメラはよほど変な設定じゃない限り、横長(タブレットなら縦長)のサイズだと思います。つまり、カメラで撮った画像の数字が映っている部分を切り取って、しかるべき加工を施してやれば目的の画像は得られるのですが、どこに数字が映ってるのかを探す(トラッキング)機能を入れようとするとすごく大変ですし、今回やりたいことにそこまでの機能は必要ない気がします。なら、少しだけPCに手伝ってもらいつつ、その部分くらいは人間の方で作業しましょう。歩み寄りは大事です。
どういうことかというと、カメラ映像の真ん中に正方形の領域を描写して、そこに手書きの文字を映すようにするわけです。完成形は以下のようになります。

こうすれば、あとはその画像の正方形領域部分をトリミングして、Kerasが判別できるように加工してやれば良いということになります。
必要なプロセスが見えてきました。まとめます。
- カメラの映像を映し出す
- 映し出した映像に正方形の領域を描画する
- 描画した領域内に手書きの数字を映す
- 撮影する
- 撮影した画像の正方形部分(数字が映ってる部分)だけを切り取る
- 切り取った画像を白黒にする
- 白黒にした画像の白と黒を反転させる(黒背景に白文字にする)
- 28×28サイズに圧縮する
こう書くとちょっと大変そうに見えますが、前々回OpenCVのチュートリアルで使った機能でほぼほぼまかなえます。注意するべきは画像の白黒反転部分です。ここで素直にネガ反転だけしても精度の高い結果は得られません。なぜなら、MNISTの画像データの黒の部分はもれなく「0」だからです。
カラー画像を白黒化してネガ反転しても、黒く見える部分は実は微妙に黒じゃなかったりします。白い部分も同様です。
じゃあどうするか、という話ですが今回は画像を一度2値化する、という手法を取ります。
以下のイメージです。
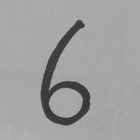 ⇒
⇒ 
こうすれば、黒く見える部分は本当に黒(0)だし、白の部分は本当に白(255)です。これをネガ反転して文字周辺のぼかしを入れれば、MNISTのデータセットと同じルールの画像ができるというわけです。
必要なプロセスを画像にまとめると、以下のようになります。
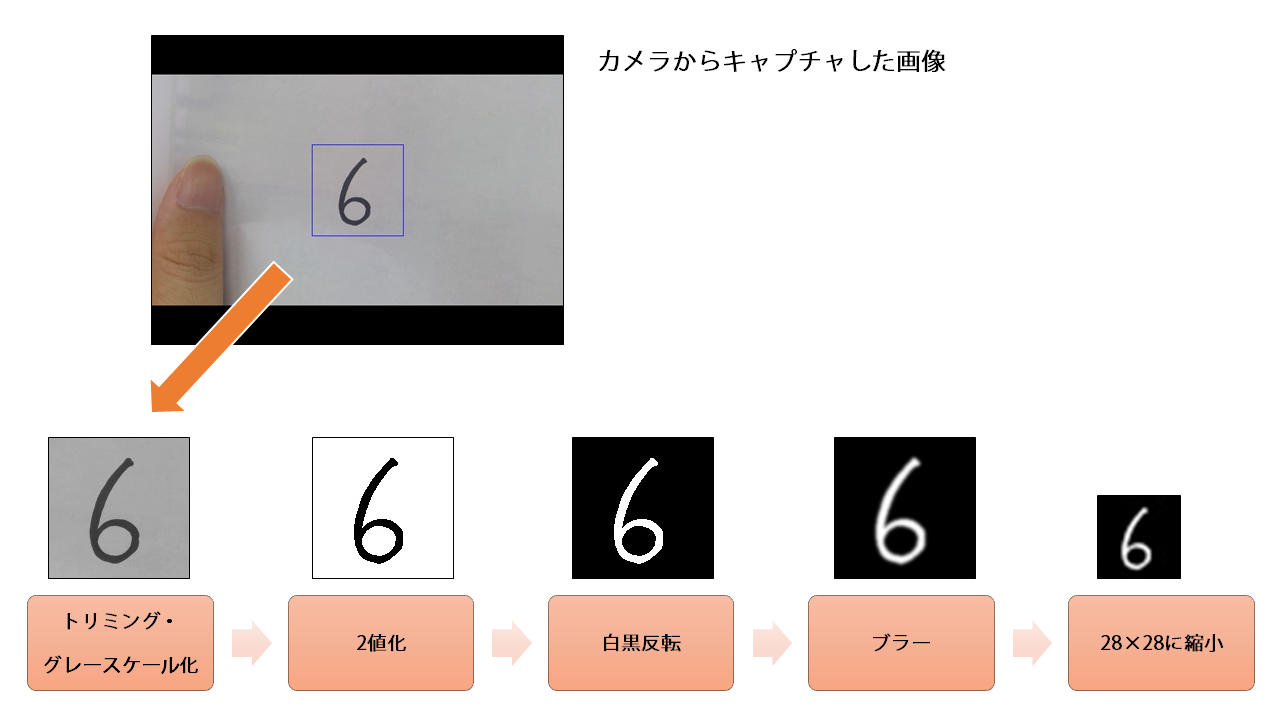
これで、道筋ができました。
手書き数字画像の取得
実際のコーディング作業に入ります。まっさらなソースファイルをご準備ください。まずはカメラの映像を取ってきましょう。前々回書いたコードを使います。
import cv2
cap = cv2.VideoCapture(1)
while(True):
ret, frame = cap.read()
cv2.imshow("frame",frame)
k = cv2.waitKey(1) & 0xFF # 64ビットマシンの場合,& 0xFFが必要
if k == ord("q")
break
cap.release()
cv2.destroyAllWindows()
これでとりあえず、カメラから映像を取得できるようにはなりました。今回欲しいのは手書き数字が映った静止画なので、特定のキー(ここでは、"s"とします)が押されたら画像が保存されるように処理を加えてみましょう。
画像を保存する命令、前々回登場しましたが覚えてますか?
imwrite()ですね。ということで、"s"が押されたらimwrite()を呼び出して画像を保存する命令を加えます。
import cv2
cap = cv2.VideoCapture(1)
while(True):
ret, frame = cap.read()
cv2.imshow("frame",frame)
k = cv2.waitKey(1) & 0xFF # 64ビットマシンの場合,& 0xFFが必要
if k == ord("q"):
break
elif k == ord("s"): # 追加部分
cv2.imwrite("frame.jpg", frame) # 追加部分
break # 追加部分
cap.release()
cv2.destroyAllWindows()
実行してみましょう。sキーが押されたらframe.jpgという名前のファイルで画像が保存され、カメラの映像も閉じるようになったでしょうか。
思ってたカメラと違うものが起動したり、そもそもカメラが立ち上がらない人はcv2.VideoCapture(1)の()内の番号を変えてみてください。
画像が保存できるようになったら次は、本筋とは関係ないのですが一つ、安全対策を入れたいと思います。
立ち上がったウィンドウですが、右上の×ボタンを押しても一瞬消えてまた立ち上がると思います。
これ、コードを見れば当たり前なのですが、このプログラムが終わる条件は"q"か"s"が押されてループを抜けた時だけです。
ループをかけていない時も同様で、見た目上はウィンドウを閉じたように見えていても、実は裏でデータが残ってて蓄積したらハングする…なんてことにもなりかねません。
なので、×ボタンを押した時も終了するようにしましょう。
×ボタンで閉じたことを判別するには、ウィンドウの情報を取得する命令getWindowProperty()を使います。
ここで引用できるWND_PROP_ASPECT_RATIOというパラメータを使うと、ウィンドウのアスペクト比を取得できます。ウィンドウが閉じられると"-1"が戻り値として返されるので、これを使って×ボタンが押されたかを判断します。
import cv2
cap = cv2.VideoCapture(1)
while(True):
ret, frame = cap.read()
cv2.imshow("frame",frame)
k = cv2.waitKey(1) & 0xFF # 64ビットマシンの場合,& 0xFFが必要
prop_val = cv2.getWindowProperty("frame", cv2.WND_PROP_ASPECT_RATIO) # 追加部分
if k == ord("q") or (prop_val < 0): # or(prop_val < 0)を追加
break
elif k == ord("s"):
cv2.imwrite("frame.jpg", frame)
break
cap.release()
cv2.destroyAllWindows()
続いて、手書き数字の映っている部分を切り取る処理を加えていきます。今回は、映像の真ん中に四角の領域を描写して、そこに手書き数字を映すことにしました。
なので、画像の中心の座標を取得します。中心が分かればそこからどれだけ離れているかで座標を指定すれば、画像の真ん中に四角が描けます。
OpenCVの座標は左上からどれだけ離れているかで表現されるので、画像の高さ、幅を取得してそれぞれ1/2すれば中心が求まります。記述としては以下です(最後に一連の処理を全部載せるので、まだ実行しないでください)。
h, w, _ = frame.shape[:3]
w_center = w//2
h_center = h//2
cv2.rectangle(frame, (w_center-71, h_center-71), (w_center+71, h_center+71),(255, 0, 0))
チャンネル情報はいらないので省略します。演算子//は小数点以下切捨てで割ります。上の命令を挿入すれば、映像の中心に142×142サイズの青い四角が描画されます。最終的に140×140サイズに切り取ろうと思うので、枠はそれよりわずかに大きくしています。切り取った際に枠が入り込まないようにするためです。
次に、140×140サイズにトリミング、グレースケール化、2値化、反転、ブラー処理を一気に入れます。この辺は難しいことは一切ないです。それぞれに対応した処理を、"s"が押されたときに画像を保存する前に加えるだけです。
# 中心から140×140サイズにトリミング。xとyの順番に注意
im = frame[h_center-70:h_center+70, w_center-70:w_center+70]
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) # グレースケールに変換
# 大津の方法で2値化。retはいらないので取得しない
_, th = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU)
th = cv2.bitwise_not(th) # 白黒反転
th = cv2.GaussianBlur(th,(9,9), 0) # ガウスブラーをかけて補間
threshold()はtrueorfalseを返しますが、今回はいらないので取得しません。
ここまでの処理を組み込みましょう。
import cv2
cap = cv2.VideoCapture(1)
while(True):
ret, frame = cap.read()
h, w, _ = frame.shape[:3] # 追加部分
w_center = w//2 # 追加部分
h_center = h//2 # 追加部分
cv2.rectangle(frame, (w_center-71, h_center-71), # 追加部分
(w_center+71, h_center+71),(255, 0, 0)) # 追加部分
cv2.imshow("frame",frame) # 追加部分
k = cv2.waitKey(1) & 0xFF
prop_val = cv2.getWindowProperty("frame", cv2.WND_PROP_ASPECT_RATIO)
if k == ord("q") or (prop_val < 0):
break
elif k == ord("s"):
im = frame[h_center-70:h_center+70, w_center-70:w_center+70] # 追加部分
im = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY) # 追加部分
_, th = cv2.threshold(im, 0, 255, cv2.THRESH_OTSU) # 追加部分
th = cv2.bitwise_not(th) # 追加部分
th = cv2.GaussianBlur(th,(9,9), 0) # 追加部分
cv2.imwrite("capture.jpg", th)
break
cap.release()
cv2.destroyAllWindows()
これでカメラの映像取得~白黒反転した140×140サイズの画像取得まで準備できました。試しに実行してみてください。
手書き数字を映してみて、黒バックに白い数字、という画像に加工されていれば成功です。
次は、最後の工程です。いよいよ用意した画像を認識させてみましょう。
手書き数字認識
カメラから画像を取れればもう終わったようなものですが、カメラがダメで別口で画像を用意した場合でも運用できるように、あえて処理を分離させました。
注意するべき点としては、これまでもお伝えしているように、学習データと同じルールのデータじゃないと判別できないという部分です。
なので最後の仕上げとして、用意した画像を28×28サイズに加工しつつ、numpy配列に変換しましょう。
import numpy as np
Xt = []
img = cv2.imread("capture.jpg", 0)
img = cv2.resize(img,(28, 28), cv2.INTER_CUBIC)
Xt.append(img)
Xt = np.array(Xt)/255
resize()は画像を指定したピクセルか、比率で拡大・縮小する命令です。INTER_~のような書き方で補間法を何種類かから選択可能です。今回はバイキュービック法を使いました。
あとは、前回学習させたモデルをロードして、判別させる処理を入れれば完成です。
from keras.models import load_model
model = load_model("MNIST.h5")
result = model.predict_classes(Xt)
print(result[0])
今回結果の出力にはpredict_classes()を使いました。これは、予測結果をクラス名で返してくれるもので、MNISTの場合クラス名=回答なのでそのまま使っています。
load_model()で呼び出してくるモデルデータは、自分で用意したデータの名前に書き換えてください。
予測結果が出力されれば成功です。ちなみに、"6"は判定精度が甘いらしく、ACCが0.98程度あっても誤認識されることがそこそこありました("3"か"5"に誤認識されることが多い印象です)。この辺は、MNISTではそもそも"6"の学習データが少ないらしく、これ以上精度が上がらないんじゃないかなと思うので、より高精度を目指すなら追加でデータセットを用意して学習させるとか、そういう手法になってくると思います。
ただ、Pythonによる画像認識の導入としては十分なのではないでしょうか。
終わりに
5回に分けてOpenCV+Kerasでの手書き数字認識を解説してきました。Pythonでの画像認識のプロセスがなんとなくでも伝わっていれば嬉しいです。
それと、できるだけ分かりやすく解説したつもりでしたが、分かり難かった部分がありましたら教えてください。
今回の一連のコードが書ければ、あとはもう、ちょっとした応用でコードを改変してデータセットを自前で用意すれば自分が好きなテーマで画像認識プログラムが作れますし、リアルタイム処理を加えてやればカメラの中央部にあるものが映ったらそれを判定する、とかも可能になります。
学習データをHDF5形式で出力するやり方も触れたので、それをC++やC#でインポートすればARアプリなんかにも使えると思います。
今回の手法は簡単な割に応用の幅がなかなか広いんじゃないかなと思います。ぜひいろいろ試してみてください。
シリーズ一覧
- 環境構築
- MNISTチュートリアル
- OpenCVチュートリアル
- 学習モデルのアップグレード
- 手書き数字認識(終)