編集中のため、記事内容に一部抜け/不完全な点があります。
物体検出ライブラリMMDetectionを使ってObject DetectionおよびInsatance Segmentationモデルを開発することができるようになるための一連の流れを紹介します。
かなり長くなるため、技術的に不適当な表現/内容の場合は編集リクエストを頂けると幸いです。
対象
何が書いてあるか
- MMDetectionの既存モデルの利用する
- MMDetectionの既存モデルに対し、既存モジュールを用いた変更を加える
何が書いてないか
- MMDetectionでの新規モジュール作成 (日本語情報を作る意味を見出せませんでした)
MMDetectionとは
香港中文大学マルチメディアラボとその関連会社であるSenseTimeが中心となって主催している、OpenMMLabによるMMCVシリーズ第一弾です。メインの開発者は(おそらく)MMDetectionの論文とCVPR 2019のHybrid task cascade for instance segmentationの1st authorであるKai Chen氏です。Issueでよく見ます。
2018年に開発が開始され、現在ではPaper with CodeのObject Detection on COCO test-devランキングのうち以下モデルの公式実装がMMDetectionベースで実装されており、それ以外にもConvNeXt等、相当数の最新モデルが実装されています。(2022/2/1時点)
Paper with CodeのInstance Segmenation on COCO test-devランキングもかなりの割合でMMDetectionの実装になっています。
- #1 Swin Transformer V2とHTC
- #4 Soft Teacher
- #6 CBNetV2
- #8 Focal-L
- #18 QueryInst
- #20 DetectoRS
MMDetectionの公式でない実装も、MMDetectionベースの論文実装が公開されています。
また、Real-time Object Detection on COCOの#1であるYOLORなんかもMMDetectionベースでの実装を検討しているそうです。
MMDetectionに代表されるMMCVシリーズは(筆者の知る限りでは)基本的に使い方が同じなので、MMDetectionを理解することで、MMCVシリーズがなんとなく使えることになります。
性能についても申し分なく、初出論文内の表によると、他のライブラリと比較してtrainingもinferenceも十分速く、性能もほぼ論文実装を再現できています。

PyTorchで実装が行われており、基本的な感触としてはPyTorchと変わりがないため、PyTorchに親しんでいない方はそこの勉強をするのをお勧めします。
日本語書籍としてはPyTorch実践入門か最短コースでわかる PyTorch &深層学習プログラミングが良いです。
ちなみに筆者はこの中でHTCとSwin TransformerとCBNetくらいしかろくに理解していません。最近の物体検出難しすぎる。
いつかフォロワー氏がバズっていたのですが、「論文1報を読むのに必要な情報は論文30報分」だそうです。ねずみ算的に増えていく"読む論文リスト"と戦う人類。筆者の読む論文リストは残り850報です。(2022/2/1時点)
何ができるのか
画像処理におけるタスクの分類
MMDetectionでは物体検出タスクのうち、Object DetectionとInstance Segmentationを行うことができます。
主な物体検出タスクの違いについては下図がかなりよく説明しており、
- Classificationでは、それぞれの画像において「画像に猫がいる」ことまでしか特定しない。(付与するラベルは基本的に1つ)
- Classification + localizationでは、画像中の猫がどこにいるかを特定する。
- Object Detectionは、Classification + localizationをmultiple objectsに対して行う。
-
Instance Segmentationでは各動物の位置を特定しつつ、動物同士を区別もする。(Object Detection + Segmentation)
ということになります。

具体的な手法として、有名なものがGithubにまとまっていますが、多分今だとPaper with Codeを見た方が良いです。

物体検出モデルとは
YOLOv4論文内の図によると、物体検出モデルの構造は以下のように一般化できます。

MMDetectionでは、図内の各パーツ(Backbone、Neck、Dence Prediction、Sparce Prediction)をモジュール化して扱えるようになっています。最近のモデルのDETRシリーズなどはちょっと構成が違います。
物体検出における主要な概念について
TP/FP/FN
True Positive (TP) - 正しい検出結果
False Positive (FP) - 検出されるべきでない検出結果
False Negative (FN) - 検出器によって検出されなかったものの、実際には検出されるべき結果
Precision&Recall

Annotation Format
物体検出タスクの場合、学習用データに対してBBoxとPolygonをannotationしますが、このannotationにはいくつかのformatがあります。
有名なものはCOCO formatやPascal VOC format、Tensorflow TFRecord、CreateML、YOLO Darknetあたりがありますが、最近はCOCO formatに落ち着いてきた感じがあります。
Bounding Box
検出対象を囲む矩形をBounding Box(BBox)と呼びます。
一般にボックスに対しての(中心bx, 中心by, 幅bw, 高さbh)で定義されます。(COCO formatの場合)

Anchor Box
物体検出の検出候補を決めるために初期設定されるBBoxのことをAnchor Boxと呼びます。
このBBoxは検出したい学習datasetのobject sizeとaspect ratioに応じて設定されます。
物体検出での学習時には、あらかじめ定義されたAnchor Boxが画像全体に並べられ、それぞれのAnchor boxごとに確率、IoU等を予測し、その結果によってAnchor boxを改良していくことで最終的なBBoxを出力します。
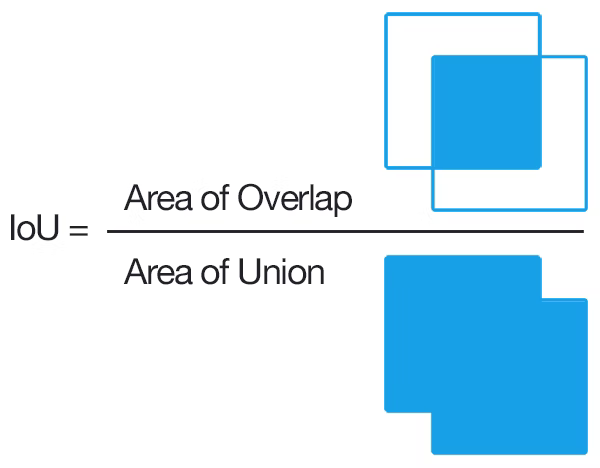
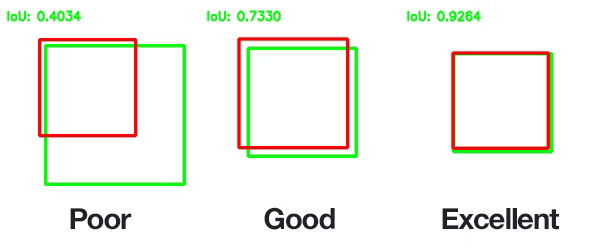
Intersection over Union (IOU)
学習時に予測されたBBox(Predicted Bouding Box)の精度を、実際のAnnotation Data (Ground-truth Bounding Box)と比較して確認するための評価指標としてIntersection over Union (IOU)が用いられます。

物体検出においては「クラス分類精度」と「物体領域の検出精度」も評価する必要があるため、それらを統合した指標としてIoUが設計されました。
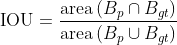
閾値(一般に0.5)以上のIOUは良い予測とみなされ、さらなる評価に使用されます。
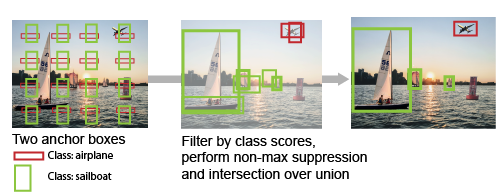
Non-max suppression(NMS)
あるGround-truth(GT) Bounding Boxに複数の箱が存在する場合、最大のIoUを持つ箱以外のすべての箱を破棄する手法です。他にも類似手法がたくさんあります。

Mean Average Precision(mAP)
直感的な説明がかなり難しいので、@tetutaro様によるmAP (mean Average Precision) について考えるを参照ください。
具体的な手法など
具体的な手法は、有名なものがGithubにまとまっていますが、多分今だとPaper with Codeを見た方が良いです。
Deep以降、Mask R-CNNまでの各手法の技術的詳細は過去にえらい方がまとめてくださっています。
物体検出についての歴史まとめ(1)
https://qiita.com/mshinoda88/items/9770ee671ea27f2c81a9
物体検出についての歴史まとめ(2)
https://qiita.com/mshinoda88/items/c7e0967923e3ed47fee5
最新のRegion CNN(R-CNN)を用いた物体検出入門 物体検出とは? R-CNN, Fast R-CNN, Faster R-CNN, Mask R-CNN
https://qiita.com/arutema47/items/8ff629a1516f7fd485f9
ただ、正直最近(2018のYOLOv3以降)の物体検出手法についてまとめると、それだけで本が書けるレベルになってしまうので、たぶんまとまった記事は存在しないかと思います。(@mshinoda88さんのまとめ(2)は2020年のYOLOv4あたりに対応していましたが、まだCascade、CBNet、DetectoRS、HTCやTransformer系があります...)
なぜか、SSDには良い日本語の解説書籍があり、PyTorchによる物体検出と物体検出とGAN、オートエンコーダー、画像処理入門 PyTorch/TensorFlow2による発展的・実装ディープラーニングを読めばよく分かります。
SSDってネーミングどうなんですかね。ストレージじゃんって突っ込む人居なかったのかな。
何がうれしいのか
TensorflowやPytorch等の深層学習ライブラリに比べ、Detector、Head、Neck、Backbone、Lossなどのモデルの構成要素やDataloader、Evaluationなどが共通の記法で書かれているため、各モジュールを接続することで多様なモデルを評価&比較できる点が優れています。
さらに、このモジュール機能に少し変更を加えることで、独自実装がかなり複雑になりがちなObjectDetectionタスクでも、とてもお手軽&他人がすぐ使える形で独自モデルが構築できます。
筆者も昔Fast-RCNN(だったかな)を自分で実装しようとして、かなり再現に苦しんで結局mAPが数%足りなかった、という経験をしたことがあるのですが、類似した経験をお持ちの方は多いと思います。
MMDetectionのほかにはMetaResearchによるDetectron(Pytorch、#5 DyHeadの公式実装)や、BaiduによるPaddleDetection(Paddle)、やたらkaggleでよく見るYOLOv5なんかもこれですかね...などが開発されています。
FAIR(MetaAIRとでもいうのかな)はDetectronを持っているのに結構よくMMDetectionに論文実装を上げていたりします。(Swin-DetとかConvNeXt-Detとか。)PyTorchならなんでもいいのかな。
さらに、これらのライブラリのさらに高レベルなライブラリとしてIceVisionなどがあり、EfficientDetやYOLOv5などを取り込めると話題になっていました。
タクシーに物体検出にお世話になりっぱなしなMoTLabさんの紹介記事がわかりやすいです。確かいつかのアップデートでこのままだと動かないので、筆者の紹介記事も参照ください。
環境構築
使用環境
- Intel Core i5 10400F
- RAM 64GB
- Nvidia RTX 3090
- ubuntu 20.04 LTS
- pyenv
- pipenv
- Python3.8.0
- 10GbE Intranet上にdataが置いてあるので、読み込みが若干遅いです。
- Windowsでの動作はかなり難しいので、Google Colab/GCP等を使うかWSLを入れてください。
GPUがなくても一応動くには動きますが、かなり辛い思いをすることになると思います。
注意点
- AmpereなのでCUDA11.3を使用
- mmcvが新しいとDeformable DETRが動かないので、mmcv 1.4.2 & mmdet 2.22.0 & mmcls 0.21.0を使用 (更新につれ動かないモデルが発生しがちですが、mmcvとmmdetをモデルの実装当時までバージョンを落としたら結構解決します。)
手順
最近はpipenvが好きなので、pipenvで書きます。
[[source]]
url = "https://pypi.org/simple"
verify_ssl = true
name = "pypi"
[packages]
numpy = "*"
imagecorruptions = "*"
scipy = "*"
sklearn = "*"
timm = "*"
matplotlib = "*"
pycocotools = "*"
six = "*"
terminaltables = "*"
asynctest = "*"
codecov = "*"
flake8 = "*"
interrogate = "*"
isort = "==4.3.21"
kwarray = "*"
mmtrack = {editable = true, git = "https://github.com/open-mmlab/mmtracking"}
onnx = "==1.7.0"
onnxruntime = ">=1.8.0"
pytest = "*"
ubelt = "*"
xdoctest = ">=0.10.0"
yapf = "*"
Cython = "*"
cityscapesScripts = "*"
torch = {file = "https://download.pytorch.org/whl/cu113/torch-1.10.2%2Bcu113-cp38-cp38-linux_x86_64.whl"}
torchvision = {file = "https://download.pytorch.org/whl/cu113/torchvision-0.11.3%2Bcu113-cp38-cp38-linux_x86_64.whl"}
mmcv-full = {file = "https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/mmcv_full-1.4.2-cp38-cp38-manylinux1_x86_64.whl"}
mmdet = {ref = "v2.22.0", git = "https://github.com/open-mmlab/mmdetection.git"}
mmcls = {ref = "v0.21.0", git = "https://github.com/open-mmlab/mmclassification.git"}
[dev-packages]
[requires]
python_version = "3.8"
データセット
必要に応じてデータセットのダウンロードをします。
COCO-Stuff datasetとPASCAL VOC2007 datasetがあれば十分な気がします。
# COCO-Stuff dataset
wget http://images.cocodataset.org/zips/train2017.zip
wget http://images.cocodataset.org/zips/val2017.zip
wget http://images.cocodataset.org/zips/test2017.zip
wget http://images.cocodataset.org/annotations/annotations_trainval2017.zip
wget http://calvin.inf.ed.ac.uk/wp-content/uploads/data/cocostuffdataset/stuffthingmaps_trainval2017.zip
# VOC 2007 dataset
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
MMDetectionが用意してくれた高レベルなAPIもあります。
python tools/misc/download_dataset.py --dataset-name coco2017
python tools/misc/download_dataset.py --dataset-name voc2007
python tools/misc/download_dataset.py --dataset-name lvis
その他fine-tuning用に使えそうな楽しげデータセットはRoboflowやkaggleとかにあります。
ディレクトリ構造
ディレクトリ構造として以下のような構造を想定します。
mmdetection
├── mmdet
├── tools
├── checkpoints #downloadした重みを入れるところ
├── configs #プリセットのconfigがあるところ
├── experiments #作成したconfigを入れるところ
├── data
│ ├── coco #COCO-format datasetはこの形
│ │ ├── annotations
│ │ ├── train2017
│ │ ├── val2017
│ │ ├── test2017
│ │ ├── stuffthingmaps
│ ├── VOCdevkit #VOC-format datasetはこの形
│ │ ├── VOC2007
│ │ │ ├── annotations
│ │ │ ├── ImageSets
│ │ │ ├── JPEGImages
│ │ │ ├── SegmentationClass
│ │ │ ├── SegmentationObject
│ │ ├── VOC2012
│ ├── cityscapes
│ │ ├── annotations
│ │ ├── train
│ │ ├── val
ユースケース
英語でもイケる場合はMMDetectionのDocsを読むと良いです。
config classによるモデル定義
MMDetection (OpenMMProject全般) ではconfig classを用いてモデル定義を行います。このconfig classはmoduleと継承から成り立っており、簡単に実験管理ができます。
config classの構造
config fileは一般にdictのような構造を取っています。
動かすだけであればここは特に理解する必要はないです。
a = 1
b = dict(b1=[0, 1, 2], b2=None)
c = (1, 2)
d = 'string'
config fileをmmcv.Config.fromfileで読み込むとkey = valueの形をしたdictとして読み込まれていることが分かります。
>>> from mmcv import Config
>>> cfg = Config.fromfile('test_config.py')
>>> cfg
# Config (path: test_config.py): {'a': 1, 'b': {'b1': [0, 1, 2], 'b2': None}, 'c': (1, 2), 'd': 'string'}
_base_ = 'config fileのpath'とすることで、config fileの継承を行うことができます。
_base_ = ['config file Aのpath', 'config file Bのpath']のように、pathをリストに入れることで複数のファイルから継承できます。
_base_ = 'test_config.py'
b = dict(b2=1, b3=None) #辞書の要素を追加・変更できる
e = "added"
>>> from mmcv import Config
>>> cfg = Config.fromfile('test_config2.py')
>>> cfg
Config (path: test_config2.py): {'a': 1, 'b': {'b1': [0, 1, 2], 'b2': 1, 'b3': None}, 'c': (1, 2), 'd': 'string', 'e': 'added'}
継承したもののうち、dictの要素を全部消したい場合(MMDetectionでは割とよくあります。)は_delete_=Trueを用いることでdict内の要素を全て消すことができます。
_base_ = 'test_config2.py'
b = dict(_delete_=True, b2=100, b3="deleted")
>>> from mmcv import Config
>>> cfg = Config.fromfile('test_config3.py')
>>> cfg
Config (path: test_config3.py): {'a': 1, 'b': {'b2': 100, 'b3': 'deleted'}, 'c': (1, 2), 'd': 'string', 'e': 'added'}
一般的にconfigの変数を指定する場合は以下のような記法で行うことができます。
(具体的な例: Resnetのdepthを更新したい場合 = model.backbone.depth = 101 など)
item1 = 'a'
item2 = dict(item3 = 'b')
_base_ = ['./base.py']
item = dict(a = {{ _base_.item1 }}, b = {{ _base_.item2.item3 }})
MMDetectionにおけるconfig class
MMDetectionにおけるconfig classでは、基本的にconfig/_base_にある以下の4つのファイルを継承して学習用ファイルを作成します。
- dataset: データセットのpathや読み込み方法など
- model: モデルの構造など
- schedule: 学習スケジュールなど
- runtime: ログやチェックポイントの保存方法など
これらの_base_で構成されるconfig fileはprimitive configと呼ばれ、1つのfolder内に1つのみ存在させ、他のファイルはこのprimitive configから継承させることが推奨されています。
_base_ = [
'../_base_/models/faster_rcnn_r50_fpn.py',
'../_base_/datasets/coco_detection.py',
'../_base_/schedules/schedule_1x.py', '../_base_/default_runtime.py'
]
configの全体構造の確認
継承されたconfig classはかなり構造が入り組んでいて確認が煩雑になりがちなので、python tools/misc/print_config.py /PATH/TO/CONFIGを用いることで継承が展開されたconfig fileを出力することができます。学習を走らせることでも同じものは生成されます。
config fileのin placeな変更
後述のtools/train.py や tools/test.py を使ってジョブを投げる際に、--cfg-optionsを用いることでin placeでconfigを変更することができます。
(具体例: --cfg-options model.backbone.norm_eval=False)
個人的には実験管理がわからなくなって嫌&リストとタプルを考えなければならないのが面倒なので、基本的にはconfig fileをいちいち作っています。(後述するwork_dirの指定と、推論時くらいにしか使ったことがありません)
config fileの命名方法
config fileの命名方法は以下のstyleが推奨されています。
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
{xxx} は必須、 [yyy] は推奨の項目です。
-
{model}:faster_rcnnやmask_rcnnなどのモデルの名前です。 -
[model setting]: 例えばhtcにおけるwithout_semanticなどのモデルに特有なsettigです。あんまり使わない。 -
{backbone}:r50(ResNet-50)やx101(ResNeXt-101) などのbackboneの名前です。 -
{neck}:fpnやpafpn、nasfpnなどのneckの名前です。 -
[norm_setting]: normのsettingですが、bn (Batch Normalization) を使う場合は特に指定されません。他のgn (Group Normalization), syncbn (Synchronized Batch Normalization)あたりの特殊なものを使う場合には指定されます。 -
[misc]: dconv, gcb, attention, albu, mstrain等の設定がここに入ります。 -
[gpu x batch_per_gpu]: GPUの数とバッチサイズです。デフォルトは8x2です。 -
{schedule}: 学習scheduleについてですが、結構ややこしいので気になった場合にはdocsを読むことを推奨します。 -
{dataset}: 使われたデータセットです。
configについてもっと知りたい場合はMask R-CNNのconfigの解説を読むとわかります。
学習済みモデルによる物体検出
やっとMMDetectionに実装されている学習済みモデルを使って簡単にモデルを動かしてみます。
大体こういう時はFaster-RCNNを使うものだと思うんですが、今は2022年なのでSenseTimeによる軽量なTransformer baseな物体検出モデルであるDeformable DETRを使っていきたいと思います。
Deformable DETR
ICLR 2021 Oral
DETRには小さい物体の検出が苦手な問題と収束が遅く計算コストが高い問題が存在します。(GPU1枚だと太刀打ちできない)
1つ目の問題である、小さい物体の検出には一般にFeature Pyramid Networks(FPN)が有効ですが、これはかなりの計算量を要するため、計算量が$O(H^2W^2C)$になってしまうDETRには適用できません。そこで、Deformable DETRでは、deformable convolutionsに着想を得た変形可能(Deformable)なDeformable attention moduleを導入し、これをFPNの代わりとすることで、DETRに比べ、10倍の学習時間短縮と小さい物体の検出に成功しています。Faster R-CNN並の速度で学習/推論ができるDETRです。
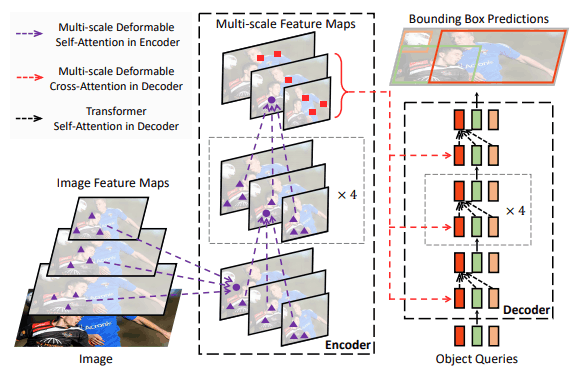
この論文はDETRが出てからわずか5ヶ月でpublishされています。頭がおかしいのでは?
Checkpoint fileのダウンロード
mmdetectionで公開されているcheckpoint fileをダウンロードしていきます。
wget -P ./checkpoints https://download.openmmlab.com/mmdetection/v2.0/deformable_detr/deformable_detr_r50_16x2_50e_coco/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth
単一画像のInference
demo用に用意されているこの画像(demo/demo.jpg)をinferenceしてみます。

import mmcv
from mmcv.runner import load_checkpoint
from mmdet.apis import inference_detector, show_result_pyplot
from mmdet.models import build_detector
# modelを定義するためのconfigファイルのpathを指定します。
config = 'configs/deformable_detr/deformable_detr_r50_16x2_50e_coco.py'
# modelに読み込ませるcheckpointファイル(重み)を指定します。
checkpoint = 'checkpoints/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth'
# 推論に使うdeviceを指定します。
device='cuda:0'
# modelを定義するためのconfigを読み込みます。
config = mmcv.Config.fromfile(config)
# 今回はbackboneが学習済みmodelである必要はないため、以下の設定をします。
config.model.pretrained = None
# configからmodelを構築します
model = build_detector(config.model)
# modelにcheckpointを読み込ませます。
checkpoint = load_checkpoint(model, checkpoint, map_location=device)
# modelにclassを読み込ませます。
model.CLASSES = checkpoint['meta']['CLASSES']
# modelにconfigを読み込ませます(最新のバージョンだと多分必要ないです)
model.cfg = config
# modelをGPU上に載せます
model.to(device)
# modelをevaluation modeに変更します。
model.eval()
# モデルを使ってinferenceします。
img = 'demo/demo.jpg'
result = inference_detector(model, img)
# 結果を出力します。
model.show_result(img, result, out_file='result.jpg')
実際は、configの読み込みからeval modeにするところまでをAPIとして簡単に書けます。
model = init_detector(config_file, checkpoint_file, device='cuda:0')
img = 'test.jpg'
result = inference_detector(model, img)
inference_defectorの引数imgはpathのみでなく、mmcv.imreadで読み込んだ画像も引数として取り扱えます。
img = 'test.jpg'
img_mm = mmcv.imread(img)
result = inference_detector(model, img_mm)
model.show_result(img_mm, result, out_file='result_mm.jpg')
また、MMDetectionのfile ioを担っているMMCVはOpenCVを使っているため、cv2.imreadで読み込んだファイル(要はNumPy)も引数として取り扱えます。
img = 'demo/demo.jpg'
img_cv = cv2.imread(img)
result = inference_detector(model, img_cv)
model.show_result(img_cv, result, out_file='result_cv.jpg')

Modelのtest / batch inference
Modelのtest
ある程度大量の枚数の画像を用いたmodel評価は、tools/test.pyを用いることで行えます。
python tools/test.py \
configs/deformable_detr/deformable_detr_r50_16x2_50e_coco.py \
checkpoints/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth \
Argumentsとしては
-
--out: pathを指定することでpickleフォーマットで結果が出力されます。 -
--eval: 結果の評価に使う項目が指定できます。例えば、proposal_fast, proposal, bbox, segmはCOCOで、mAPはPASCAL VOCで、recallはPASCAL VOCで利用できます。 -
--show-dir: bboxとsegmを入力画像に反映した画像が指定したディレクトリに保存されます。 -
--format-only:--optionsでファイルパスを指定することで、推論結果をjson file or txt fileを出力することができます。 -
--show-score-thr: 閾値を変更します。デフォルトは0.3になっています。
具体例
以下のコマンドによりdeformable_detr_r50_test-dev_results.bbox.jsonの結果ファイルが出力されます。
python tools/test.py \
configs/deformable_detr/deformable_detr_r50_16x2_50e_coco.py \
checkpoints/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth \
--format-only \
--options "jsonfile_prefix=./deformable_detr_r50_test-dev_results" \
この評価で用いる画像とannotationファイルはconfig file内のdata.test.ann_fileとdata.test.image_prefix内で指定します。(大元はconfigs/_base_/datasets/coco_detection.pyを継承しています)
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
data = dict(
test=dict(
type=dataset_type,
ann_file=data_root + 'annotations/instances_val2017.json',
img_prefix=data_root + 'images/val2017/'))
batch inference
続けて、GT annotationがない画像に対してのtest (=batch inference)を行います。
ただ、annotation fileがない状態ではconfig fileにおいてannotationを指定できないため、空のcoco formatのannotation fileを作成し、代替します。
python tools/dataset_converters/images2coco.py \
${IMG_PATH} \
${CLASSES} \
${OUT} \
[--exclude-extensions]
Argumentsは
-
IMG_PATH: 画像ディレクトリのpathを指定します。 -
CLASSES: カテゴリのリストが含まれたtxt fileを指定します。 -
OUT: 出力されるannotation json fileの名前。デフォルトでは画像のディレクトリと同じディレクトリに出力されます。 -
exclude-extensions: pngやbmpなどの想定される拡張子です。
具体例
ここで作成した空のannotation dataを--cfg-optionsを使って代入していきます
python tools/dataset_converters/images2coco.py \
data/my_dataset/test \
data/my_dataset/class.txt \
test_annotation
python tools/test.py \
configs/deformable_detr/deformable_detr_r50_16x2_50e_coco.py \
checkpoints/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth \
--cfg-options data.test.ann_file = data/my_dataset/test_annotation
--cfg-options data.test.img_prefix = data/my_dataset/test
--format-only \
--options "jsonfile_prefix=./deformable_detr_r50_test-dev_results" \
とすることで、batchでの推論が実行できます。
既存モデルを用いたfine-tuning
続けて、既存モデルを用いたfine-tuningを行っていきます。大規模データセットを用いた事前学習も基本的にやることは同じです。
fine-tuningに使うデータセットとして、roboflowからRaccoon DatasetをCOCO Formatの形式で持ってきました。かわいい。

このdatasetを読み込む様、config fileを書き換えていく必要があります。
Raccoon Datasetの読み込み
まず、deformable_detr_r50_16x2_50e_coco.pyは_base_/datasets/coco_detection.pyからdataset configを継承しています。
そのままではDatasetを読み込むことができないため、Raccoon Datasetの読み込みをconfigに反映させます。
- Raccoon datasetはsupercategory
RaccoonsとそのsubcategoryRaccoonを持つため、classとmodel.bbox_head.num_classesを設定する - Raccoon dataseへのpathを設定する
- fine-tuningを行うために
load_fromに学習済みデータセットの重みへのpathを設定する
_base_ = '../../configs/deformable_detr_r50_16x2_50e_coco.py'
data_root = "data/raccoon/"
classes = ["raccoons", "raccoon"]
train_dataloader = dict(
dataset=dict(
metainfo=dict(classes=classes),
data_root=data_root,
ann_file='train/_annotations.json',
data_prefix=dict(img='train/')
)
)
val_dataloader = dict(
dataset=dict(
test_mode=True,
metainfo=dict(classes=classes),
data_root=data_root,
ann_file='valid/_annotations.json',
data_prefix=dict(img='valid/')
)
)
test_dataloader = dict(
dataset=dict(
test_mode=True,
metainfo=dict(classes=classes),
data_root=data_root,
ann_file='test/_annotations.json',
data_prefix=dict(img='test/')
)
)
val_evaluator = dict(
ann_file= data_root + '/valid/_annotations.json',
)
test_evaluator = dict(
ann_file = data_root + "/test/_annotations.json"
)
model = dict(
bbox_head=dict(
num_classes=2))
load_from = "checkpoints/deformable_detr_r50_16x2_50e_coco_20210419_220030-a12b9512.pth"
同じprimitive configから継承したconfig fileは同じディレクトリ内に継承していくことをMMDetectionでは推奨していますが、個人的には実験管理が面倒(プリセットが多すぎる)なのでconfigsはprimitive configを作った場合のみ操作することにし、configs/*/*.pyを継承する場合はexperiments/*/*.py に移動させています。
学習の実行
学習は推論と同様にtools/train.pyを用いて以下のように行います。
学習結果はconfig file内のwork_dirによって指定され、特に何も指定がない場合はwork_dirs/[モデル名]のディレクトリが生成され、学習結果の重み、log、学習に用いたconfig fileが出力されます。
python tools/train.py\
configs/deformable_detr/deformable_detr_r50_16x2_50e_Raccoon.py \
--cfg-options work_dir="work_dirs/raccoon_experiment"
RTX 3090上では10分程度で50 epochの学習が終わりました。
学習結果の確認
前述のtools/test.pyを用いて推論を行いました。評価指標も出したいので--evalをbboxに指定します。
python tools/test.py\
work_dirs/deformable_detr_r50_16x2_50e_Raccoon/deformable_detr_r50_16x2_50e_Raccoon.py\
work_dirs/deformable_detr_r50_16x2_50e_Raccoon/epoch_50.pth\
--eval bbox\
--show-dir "results/DETR_raccoon"
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.637
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=1000 ] = 0.846
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=1000 ] = 0.728
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.153
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.692
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.770
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=300 ] = 0.770
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=1000 ] = 0.770
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=1000 ] = -1.000
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=1000 ] = 0.500
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=1000 ] = 0.800
OrderedDict([('bbox_mAP', 0.637), ('bbox_mAP_50', 0.846), ('bbox_mAP_75', 0.728), ('bbox_mAP_s', -1.0), ('bbox_mAP_m', 0.153), ('bbox_mAP_l', 0.692), ('bbox_mAP_copypaste', '0.637 0.846 0.728 -1.000 0.153 0.692')])
こちらに向かってくるかわいいRaccoonと見切れたRaccoonが検出されました。

Formatが異なる場合
用いたいDatasetのFormatが異なる場合、学習時のオンライン変換用のConfig file(configs/_base_/datasetsに相当するもの)Dataset classを設定してからDataset classを定義することで導入できますが、正直COCO Formatに自力で書き換えてしまうorRoboflowのフォーマット変換なんかを使ってCOCO Formatに書き換えてしまう方が筋が良いんじゃないかと思います。
tensorboard等の学習監視系書きたい
既存moduleを用いたモデル構築方法
続けて、MMDetectionに実装されているmoduleを用いて独自モデルを構築していきたいと思います。
独自モデルを構築するにはDeformable-DETRは少し難易度が高いので、RetinaNetにBiFPNとEfficientNet Backboneを導入して疑似EfficientDetを作っていきます。
primitive configの生成
鋭意学習中です
timm backboneを用いたオレオレSoTAモデル構築
もともとかなり豊富にbackboneがあり、既存backboneを編集するのも簡単なことで有名なMMDetでしたが、v2.22.0でついにbackboneとしてPyTorch Image Models(timm)への対応が発表されました。ConvNeXtへの対応でMMClassificationがtimmに対応したことによる変更のようです。
今回はこのtimmを使って、Object Detection on PASCAL VOC 2007のSoTAモデルを作っていこうと思います。かなり見切り発車です。
2022/3/1時点でのSoTAであるCascade Eff-B7 NAS-FPNは転移学習を使っているようなので、#2のDETRegがマークしている0.8416を目指していきます。
Faster-RCNN & ResNet18 & FPN on VOC 2007 dataset
まず、簡単な例として、Faster-RCNNにResNet18を接続してみたいと思います。ResNet18はImageNet-top1が69.744で、11.69 Paramsだそうです。
config fileに対して以下の手順で変更を加えます。
-
custom_imports=dict(imports=['mmcls.models'], allow_failed_imports=False)とする - model.backbone.typeを
mmcls.TIMMBackboneで設定し、model_nameにtimmのmodelの名前を入れる - timmでそのモデルが
features_only=Trueにしたときの出力の形(以下参照)をmodel.neck.in_channelsに設定する
import torch
import timm
m = timm.create_model('resnet18', features_only=True, pretrained=True)
print(f'Feature channels: {m.feature_info.channels()}')
o = m(torch.randn(2, 3, 224, 224))
#Feature channels: [64, 64, 128, 256, 512]
for x in o:
print(x.shape)
#torch.Size([2, 64, 112, 112])
#torch.Size([2, 64, 56, 56])
#torch.Size([2, 128, 28, 28])
#torch.Size([2, 256, 14, 14])
#torch.Size([2, 512, 7, 7])
一応、mmcls.models.backbones.TIMMBackboneをもってきているみたいですが、backboneのin_channlesのargumentも使えるみたいなので、モノクロやRGB-D等のデータにも対応できそうです。(やってないので実際に使えるかはわかりませんが...)
具体的には、以下のconfig fileを用いることで学習を行いました。
ちなみに、比較的高速に学習できるであろうFaster-RCNN & Resnet18を選択したものの、COCO Dataset 2017を用いると12epochの学習にRTX3090で1dayかってしまいます。(VOCでも1.5時間かかります。)
_base_ = [
'../../configs/_base_/models/faster_rcnn_r50_fpn.py',
'../../configs/_base_/datasets/voc07.py',
'../../configs/_base_/schedules/schedule_1x.py',
'../../configs/_base_/default_runtime.py'
]
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
model = dict(
backbone=dict(
_delete_=True,
type='mmcls.TIMMBackbone',
model_name='resnet18',
features_only=True,
pretrained=True,
out_indices=(1, 2, 3, 4)),
neck=dict(in_channels=[64, 128, 256, 512]),
roi_head=dict(
bbox_head=dict(
num_classes=20))
)
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
data = dict(
samples_per_gpu=8,
workers_per_gpu=8)
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 4952/4952, 50.1 task/s, elapsed: 99s, ETA: 0s
---------------iou_thr: 0.5---------------
+-------------+------+------+--------+-------+
| mAP | | | | 0.693 |
+-------------+------+------+--------+-------+
というわけで、(精度が悪すぎて)MMDetectionに存在しないFaster-RCNN & ResNet18のObject Detectionモデルができました。大体論文で紹介されているmAPと同じになったのでよしとします。
ちなみに、MMDetはPycocotoolsでmAPを計算しているため、このmAPはMS COCO DatasetのmAPになる関係で厳密には同じ指標ではないのと、論文ではFeature Pyramid Networksを実装してないのでオーダーがあってるかどうかくらいしかあてにならないです。
Faster-RCNN & efficientnetv2_s & FPN on VOC 2007 dataset
続けて、ResNet18以外のモデルを使って学習してみます。
timmには嫌になるくらい大量のモデルリストがあるため、この中から使いたいモデルを選択します。
今回は計算量があまり増えられても困るのでtf_efficientnetv2_s(21.46 Params)を選択しました。ImageNetではtop1が83.886の100位で、resnet152や最近話題のconvnext_baseよりも優秀らしいです。
EfficientNetV2ってめっちゃ前な感じがするんですが、1年経ってないんですね。(2022/3/10時点)
RTX3090でvoc2007を学習した場合、3時間程度かかりました。
_base_ = [
'../../configs/_base_/models/faster_rcnn_r50_fpn.py',
'../../configs/_base_/datasets/voc07.py',
'../../configs/_base_/schedules/schedule_1x.py', '../../configs/_base_/default_runtime.py'
]
custom_imports = dict(imports=['mmcls.models'], allow_failed_imports=False)
model = dict(
backbone=dict(
_delete_=True,
type='mmcls.TIMMBackbone',
model_name='tf_efficientnetv2_s',
features_only=True,
pretrained=True,
out_indices=(1, 2, 3, 4)),
neck=dict(in_channels=[48, 64, 160, 256]),
roi_head=dict(
bbox_head=dict(
num_classes=20))
)
optimizer = dict(type='SGD', lr=0.02, momentum=0.9, weight_decay=0.0001)
data = dict(
samples_per_gpu=8,
workers_per_gpu=8)
[>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>] 4952/4952, 27.8 task/s, elapsed: 178s, ETA: 0s
---------------iou_thr: 0.5---------------
+-------------+------+------+--------+-------+
| mAP | | | | 0.769 |
+-------------+------+------+--------+-------+
mAPが0.769とそこそこいい感じのスコアが出てくれました。意外と推論速度遅いですね。
鋭意学習中です