(参考):2022年における物体検出ライブラリについてまとめました。
更新履歴
Mask R-CNNについて加筆(12/13)。
F-RCNNのAnchorについて記述(12/23)。
Chainerのrepoについて追記(1/3/19)。
Detectronについて追記(3/28/19)。
高速化について追記(9/10/19)。
Torchvision FasterRCNNについて追記(7/6/20)
SSD,YOLOについて準備中。
本記事は2018に記述したものです。RCNNの基本などは本記事の記述からさほど大きな変化はないものの、EfficientDet、Yolov4などsingle stage detectorの精度がここ数年で大きく伸びたことはご留意下さい。
目的
自身の復習を兼ねて最新の物体検出を行うRegion CNN(領域ベースCNN)について技術解説を行う。
この記事ではR-CNN、Fast R-CNN, Faster R-CNN、Mask R-CNNが主になる。
ちなみにFast,Faster R-CNN,Mask R-CNNはResnetを提案したKaming Heのグループからすべて提案されたもの。
SingleShotDetector系(SSD,YOLO)は書くとしたら別記事になるが、理解するにはいずれにせよR-CNN系の内容がベースとして必要と思う。
なお以下のMedium記事がベースとなっており、多くの画像を引用する。その度に明記するのを心がけたい。
[What do we learn from region based object detectors (Faster R-CNN, R-FCN, FPN)?]
(https://medium.com/@jonathan_hui/what-do-we-learn-from-region-based-object-detectors-faster-r-cnn-r-fcn-fpn-7e354377a7c9)
物体検出とは?

有名なMNISTデータセットで行っているのは"画像認識(Image Classification)"というタスク。
これは一枚の画像が与えられ、機械学習モデルが0~9のどの数字か当てる。
(例えば左上は5の画像が与えられ、"5"とモデルが返せたら正解)
これは画像全体に対して推論を行い、結果は一つという点に注目したい。

一方で"物体検出(Object Detection)"は更にタスクが複雑になる。
これは画像をPASCAL VOC 2007という物体検知タスクのMNIST的なデータセットから拝借している。
ここでは画像に複数の物体(車*2+バス)が写り込んでおり、モデルはその物体が画像中のどこの座標に存在しているか当てる必要がある。
例えばモデルは
bus xmin=300, ymin=150, xmax=450, ymax=200
と物体が何であるか(bus)とその座標(xmin=300, ymin=150, xmax=450, ymax=200)を回答し、その結果として生成される物体を囲む箱をBoundingBox(BBox)などと表現する。
平たく言うと物体検出タスクは画像中の物体全てを箱で囲み、それが何であるかを当てれればよい。
物体検出モデルは大きく2つのタスクを実施している。
- ある画像領域が背景か物体か?(物体検出タスク)
- もし物体ならばなんの物体か?(画像認識タスク)
そのため単純に画像認識だけを行うモデルに対し、タスク難易度は数段高い。

例えば上手く学習できていないモデルは背景を物体として誤検知してしまう。(正解Ground Truthは赤枠)
それでは物体検知の基礎がわかったところで、DNNを利用したモデルの遍歴を見ていく。
Windowベース検出器

2012年にAlexnetが現れ、研究者達はとても精度の良い画像認識モデル(CNN)を手に入れました。
じゃあ画像を細かく(数1000~)分割して片っ端からCNNに突っ込めばいいじゃん!という力技のアプローチが元祖Window-CNN。
CNNは高品質な特徴量抽出ができるため、CNN出力から画像の一部分が背景または物体かを当てるのは難しくない。
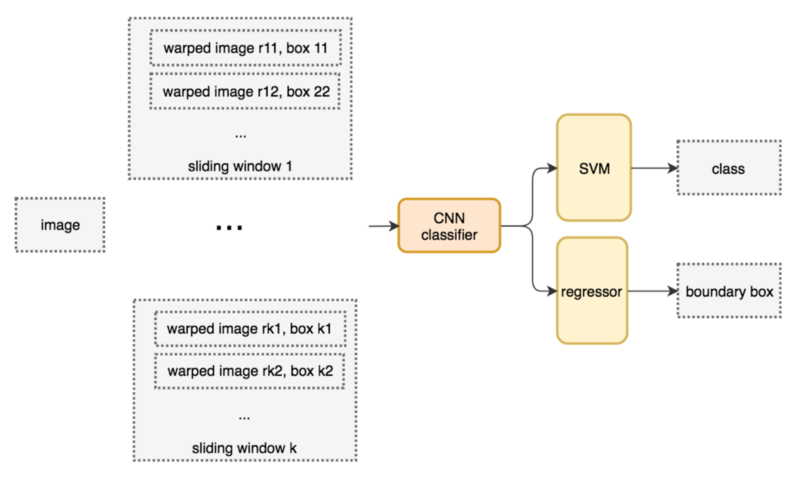
ここで実際のWindow-CNN動作を見てみよう。
ネットワーク図では分割した画像をwarped imageとし、CNNに入力する。
CNNは画像の特徴量を抽出し、4096値の特徴量ベクトルを出力する。
この抽出した特徴量を回帰器(SVMなど)に突っ込み、推論結果を得る(画像の一部分は背景、自転車、人、車いずれかであったかわかる)。
Window base CNNのメリット・デメリット
物体認識タスク(VoC2007)の精度変貌を見てみましょう。
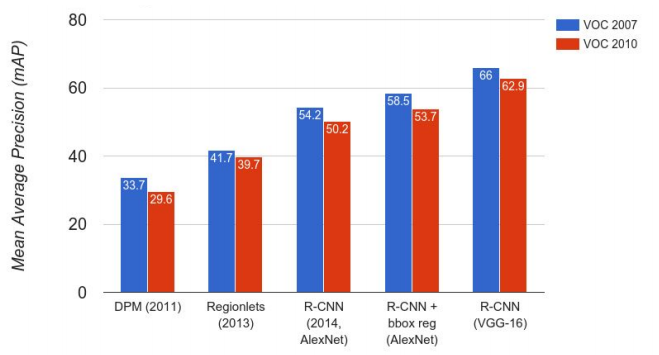
CS231nより引用
DPMとRegionLetsは非DNNアプローチ(特徴量設計)で精度は低いです(~40 mAP)。
ディープニューラルネットワークを使用することで、従来に比べ認識精度が大きく向上するのが最大のメリットです(~60 mAP)。数年の間位に20%近く精度が向上していますね。
AlexNetの登場でImageNet精度が大幅に向上したのと似ています。
for window in windows
patch = get_patch(image, window)
results = CNNdetector(patch)
一方でWindow-CNNのデメリットは*処理時間(または演算量)*であった。
画像一枚につきCNNを数千回、数万回回さなくてはならないため、検出が非常に遅い(リアルタイム性が低い)というのが欠点。
画像一枚の認識結果を得るために数十秒待つというのもザラだった。(0.1 FPS)
想像してみよう。。AlexNetを画像一枚に対して1000回動かしていたら?30fpsの動画では1秒に3万回AlexNetを回さなければならない。。ヒー!
将来的に自動運転やロボットなどにこの技術を展開する場合、1秒間に10枚ほどの処理スピードは最低求められます(10 FPS)。
要求に対して100倍の速度ギャップがまだある!
それではR-CNN,Faster-R-CNNが技術の進化でこの速度ギャップを埋める様を見ていく。
端的に言うと、如何にCNN detectorを回す回数を減らすかというのが研究の主眼となっている。
R-CNN(Regional CNN)
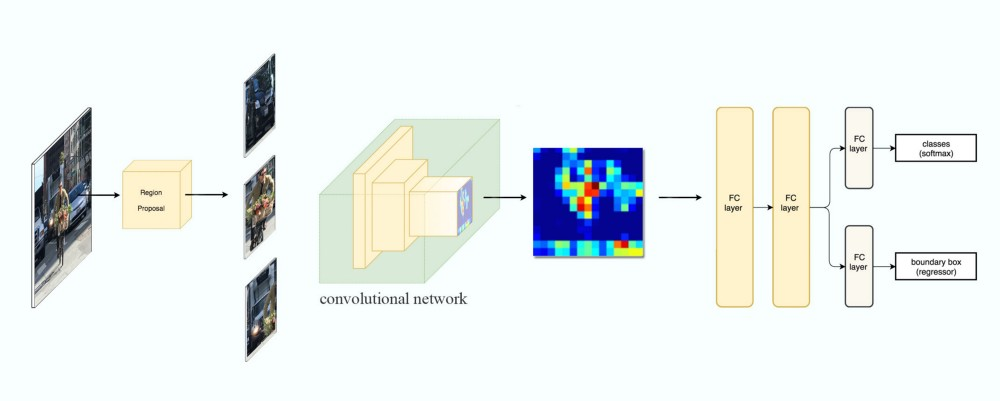
これも従来の物体検出モデルをCNNに置き換えたものであるが、考え方は重要。
画像内に隈なくdetectorを走らせると計算コストが大きすぎるので、最初に物体があるっぽい領域を提案させよう!というアプローチ。
detectorは物体があるっぽい領域のみ計算すればいいのでWindowベースモデルよりは高速化が期待できる。
また物体があるっぽい領域をregion-of-interest(ROI)などと呼ぶ。またROIを提案するモデルをregion proposalと呼ぶ。
R-CNN系のDNNモデルの基本となる構造がここで提案されている。
1. 物体があるっぽい領域を提案するモデル
2. 画像認識をするモデル
とモデルは2-stage構成になっているのに注目したい。
R-CNNのメリット・デメリット
以下のコードを見てみよう。
ROIs = region_proposal(image)
for ROI in ROIs
patch = get_patch(image, ROI)
results = CNNdetector(patch)
R-CNNはregion proposalされた画像部分に対してCNNdetectorを回す。
そのためCNNを回す回数はwindow-baseに対しては大幅に削減可能だ。
region proposalで使われるのは非DNN技術の従来技術のため精度がまだ低いという欠点があるものの、考え方そのものは汎用的で現代のtwo-staged detectorの基本となっている。
しかしregion proposal自体の精度は非常に重要で、物体のない領域を提案してしまうといくら後段のCNNの認識精度がどれほど高くても検出を間違えてしまう。
またこのプロポーザル自体の演算量も大きいという欠点もあった。
Fast R-CNN
[R Girshick, "Fast r-cnn"] (https://www.cv-foundation.org/openaccess/content_iccv_2015/html/Girshick_Fast_R-CNN_ICCV_2015_paper.html)
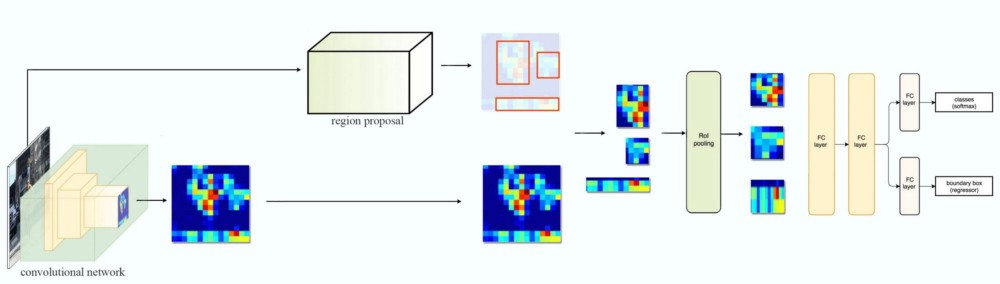
ネットワーク:
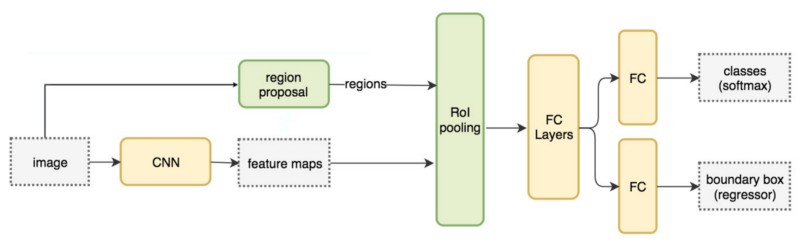
待望のFast-RCNNまでたどり着いた!
直球な名前が示すとおり、R-CNNの高速化を達成した研究だ。
ネットワーク図の方がわかりやすいのでそちらに注目する。
構造としてはR-CNNに似ている:RegionProposal(RP)があり、CNNがある。
ではどこがFastなのか?
RegionProposalはCNNの出力する特徴量領域を指しているのに注目したい。
(RPとCNN出力をつなぐRegion-of-interest pooling layerを提案している)
Fast-RCNNのブレイクスルー
F-RCNNでは画像認識を行う時には毎回CNNを走らせる必要はなく、RegionProposalの抽出した特徴領域を切り出し、全結合層に与えるだけでよい。
従来のR-CNNが画像認識毎にCNN層も走らせていたのに比べると大幅な高速化を達成できる。
RegionProposalが1000回あったとすると演算量は:
従来R-CNN:CNN1000+FC1000
F-R-CNN:CNN1+FC1000
とCNNの演算回数を1/1000にできる!
(また全結合相は遅いため画像認識層を全てConvolution層に置き換えるFully convolutional Fast R-CNNも提案された。)
またF-RCNNはMulti-task lossという学習技術を提案。BBとクラス分類のネットワークを同時に学習をすることに成功している。
RegionProposalモデルも込でモデル全体をend-to-endで学習させることに成功している。これは学習効率向上につながる。
これはRPのロスと画像認識モデルのロスを同時にバックプロパゲーションをかけてもちゃんとモデル精度が収束することを示した、というイメージ。
ご指摘どおりこれはFaster-RCNNで提案された変更点でした。
まだFast~ではend-to-endではない。
結果としてFast R-CNNはR-CNNに対し150xの推論速度向上と10xの学習速度向上を実現している。
名前通りFast!!
擬似コードで書くとFast R-CNNは以下のようになる。
ROIs = region_proposal_by_selective_search(image)
Fmaps = CNN(image)
for ROI in ROIs
patch = ROI_pooling(Fmaps, ROI)
results = FCdetector(patch)
特徴量マップ(Fmaps)を一度取得し、それをfor loopの中で使い回す。
CNNを回す回数は一度に削減できた。
Faster R-CNN
結果としてFast R-CNNはR-CNNに対し150xの推論速度向上と10xの学習速度向上を実現している。
と書いたが実はこれには嘘が含まれている・・・
実はこれはRegion Proposalの時間を除いた場合の比較でFast R-CNNはRegion Proposalの実行時間が支配的になってしまっている。
一枚の画像に2.3秒かかるが、そのうち2秒(86%!)がRegionProposalに費やされていた。
というのもFast R-CNNではRegion Proposalに従来技術であるSelective Searchを使用しており、そこが速度ボトルネックとなっていた。(コメント有難うございます)
Faster R-CNNはRegionProposalもCNN化することで物体検出モデルを全てDNN化し、高速化するのがモチベーションとなっている。
またFaster-RCNNはMulti-task lossという学習技術を使っており、RegionProposalモデルも込でモデル全体をend-to-endで学習させることに成功している。
参考:
https://qiita.com/Almond/items/7850cf81903fbe2a2c6c
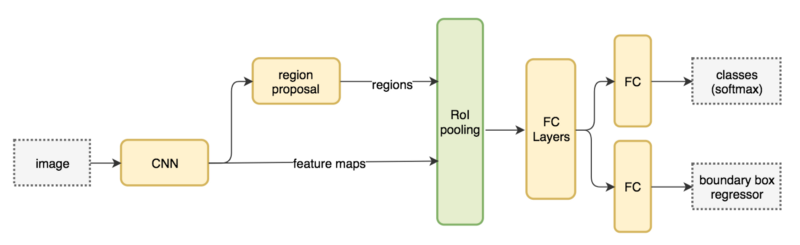
Faster-RCNNはCNN出力(特徴マップ)を元にregion proposal(物体があるっぽい領域を抽出)するモデルを構築している。実際のregion proposalは3~4層ほどのCNNで構成可能で小さい。
できるだけCNNが生成した特徴マップを使い倒す!という流れがR-CNN系の発展に見て取れる。
実際にこのアプローチは精度向上・計算効率向上に寄与しており、興味深い。
Faster R-CNNを擬似コードで書くと以下のようになる。
Fmaps = CNN(image)
ROIs = regionproposalCNN(Fmaps)
for ROI in ROIs
patch = ROIpooling(Fmaps, ROI)
results = FCdetector(patch)
・Fast R-CNNからの変更点
Regionproposalの軽量化
・結果
一枚の画像の推論時間
Fast R-CNN:2.3秒
Faster R-CNN:0.2秒
RegionProposalにかかる時間をほぼゼロに近づけたことにより、大幅な高速化を達成。
ほぼ全てのモデルがDNNに!
またこれはTitanXpでFaster R-CNNのバックボーンにResnet101を用いたときの実動作速度である。
検出タスクによってはバックボーンにResnet18などを用いることで検出速度は20~40msまで短縮することができる。
Region proposalとAnchorについて
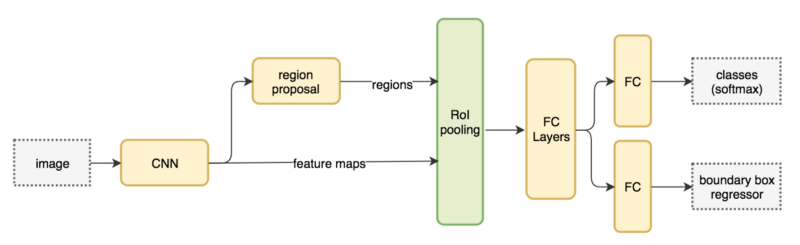
Region Propsal Network(RPN)はCNNの特徴マップ(つまりResnet等のCNN層出力)を入力。
ある領域が物体か背景か(objectness)およびアンカーの位置の補正データ(corrdinates)を出力する。objectnessは0-1の値で1に近いほど物体である確証が高い。corrdinatesはBoundingBoxの四角の座標について補正する量を出力する。
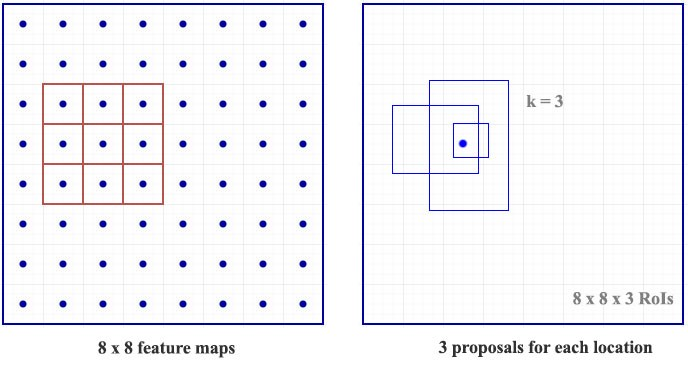
RPNは一箇所につきk個のBoundingBoxを提案する。これは一つの物体について重複することが多く、最も確度の高い高いBoundingBoxのみ残したい(refining)。大体k=128などが使われることがある通り、refineなしでは大量のpredicitionが生成されてしまい実用的でない。
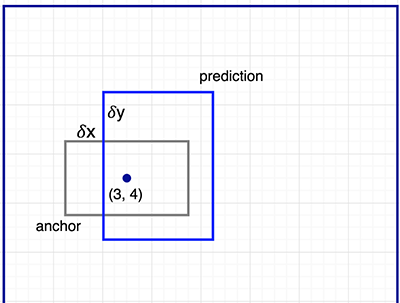
Refineに使われる概念がAnchorである。
物体検出において物体は3x3のような正方形であることは少ない。
例えば人間はだいたい縦長であったり、車は横長で有ることが多い。
このような図形情報を扱うために提案された概念がAnchorである。
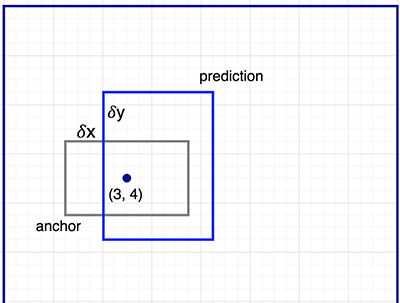
座標に付き提案するBoundingBoxに対しAnchor情報とどれくらい異なるかを導出し、一番Anchorに近いBoundingBoxをMain Predictionとして出力する。これによって物体一つにつきBoundingBoxを一つに絞り込み、かつ一番高精度なものを残すことができる。
例えばF-RCNNでは正方形、縦長、横長の3種類とそれをそれぞれスケールした計9種類が使われている。これはCOCOなど一般物体検知は様々な形の物体を検出するためで、もし使うデータセットが車のみならば横長のアンカーだけを使うなどカスタマイズすれば、高精度化が可能になるだろう。
Mask R-CNN
参考:
https://medium.com/@jonathan_hui/image-segmentation-with-mask-r-cnn-ebe6d793272

Mask R-CNNはFasterとほぼ同じネットワークを持ちながらイメージセグメンテーションのタスクを行うモデル。
セグメンテーションは上の画像の通り、物体の周りにBoundingBoxを囲うだけではなく、ピクセルレベルで判定をする。
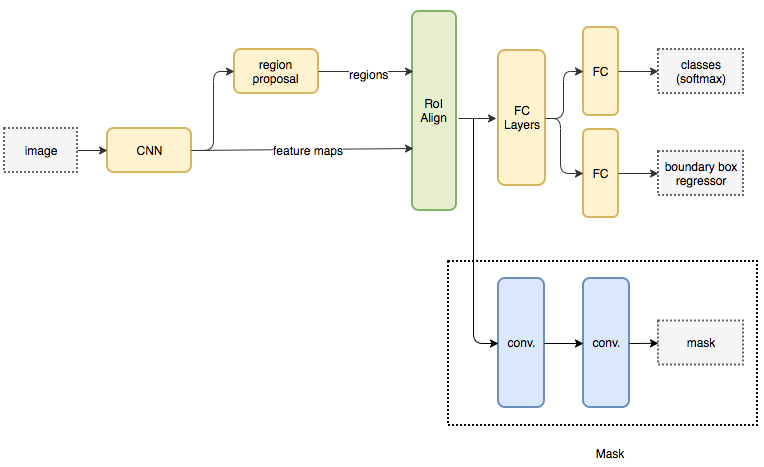
聞いた感じ難しそうですが、ネットワーク構造はFasterを理解していれば結構単純だ。
RPNレイヤ前後まではインプリはFasterと同じ。
違いとしてはRPN結果をROIアラインレイヤでサイズを正規化したあとに、deconvolutionレイヤを用いて物体用のマスクを作成している。
行っているのはDC-GANのgeneratorに近いのでないか。
クラスやBoundingBox生成はFasterと同じ事をやっている。
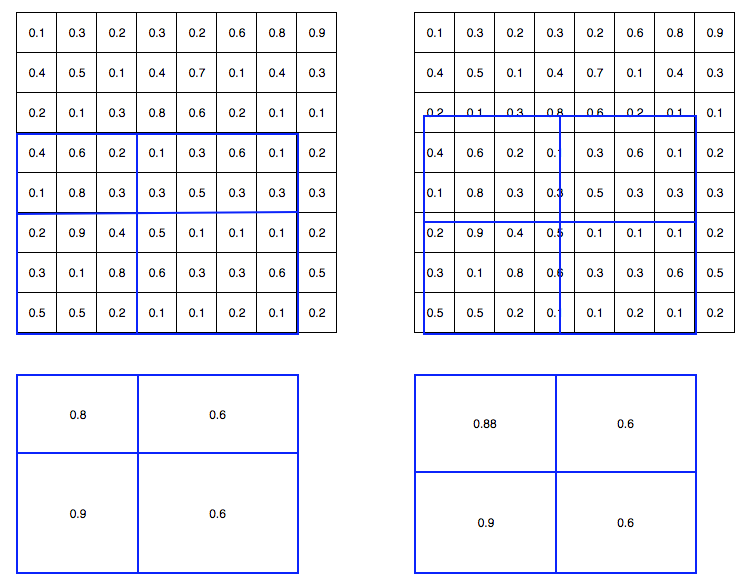
ROIAlignレイヤは単純なプーリングではなく、画像サイズを正規化しているようなイメージ。
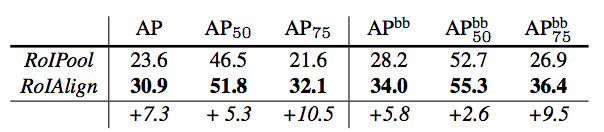
ただ精度向上の効果は大きく、Fasterのインプリの多くもROIalignが使われている(使う分には詳細実装は理解しなくて良い)。
R-CNN系を試したい人へ
Torchvision FasterRCNN
PytorchのtorchvisionにFasterRCNNが追加されました。かなり使いやすく面倒なインストールもないので初手はこちらがオススメです。
from torchvision.models.detection.faster_rcnn import FastRCNNPredictor
# load a model pre-trained pre-trained on COCO
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
このようにFasterRCNNが呼び出せます。今までの苦労は一体
自分のデータセットにおける学習などを含むドキュメントは以下がわかりやすいです。
TorchVision Object Detection Finetuning Tutorial
またMaskRCNNも付属しており、人の検出などの用途であればtorchvisionモデルで十分かと思います。
Pytorch(更に精度を求めたり論文実装したいなら。。)
mmDetection おすすめ
Detectron2 二番目におすすめ
A Faster Pytorch Implementation of Faster R-CNN もう古いです
https://github.com/jwyang/faster-rcnn.pytorch
上記のResnet50版
https://github.com/kentaroy47/faster-rcnn.pytorch_resnet50
Facebook公式実装
[2020/01/20追記] Detectron2
Detectron2が追加されました。
https://github.com/facebookresearch/detectron2
Detectronからの変更点
- すべてPytorchで実装
- 学習が大幅に高速化
- APIなどもかなり使いやすくなった
- panoptic segmentation, densepose, Cascade R-CNN, rotated bounding boxesなどのタスクに対応
精度もよく高速なのでKaggleのコンペでも改造元として使われることが増え始めている、という印象です。
最先端の精度を得たい場合はDetectron2を使用するのがオススメです。
Detectron2 is Facebook AI Research's next generation software system that implements state-of-the-art object detection algorithms. It is a ground-up rewrite of the previous version, Detectron, and it originates from maskrcnn-benchmark.
Detectron
https://github.com/facebookresearch/Detectron
Detectron is Facebook AI Research's software system that implements state-of-the-art object detection algorithms, including Mask R-CNN. It is written in Python and powered by the Caffe2 deep learning framework.
Mask-RCNN, F-RCNNまで何でもあり。学習済みモデルの数も恐ろしく多く、オススメ。
ただ中身はCaffe2で書かれているため、改造などするのは難しい。
Faster R-CNN and Mask R-CNN in PyTorch 1.0
https://github.com/facebookresearch/maskrcnn-benchmark/blob/master/MODEL_ZOO.md
より高速な公式実装。こちらはPytorchで書かれているため改造もできる。
PyTorch 1.0: RPN, Faster R-CNN and Mask R-CNN implementations that matches or exceeds Detectron accuracies
Very fast: up to 2x faster than Detectron and 30% faster than mmdetection during training. See MODEL_ZOO.md for more details.
Memory efficient: uses roughly 500MB less GPU memory than mmdetection during training
Multi-GPU training and inference
Chainer
ChainerCV 情報がまとまっておりわかりやすい。
https://github.com/chainer/chainercv
Faster R-CNN
https://github.com/chainer/chainercv/tree/master/examples/faster_rcnn
SSD
https://github.com/chainer/chainercv/blob/master/examples/ssd
YOLO
https://github.com/chainer/chainercv/blob/master/examples/yolo
SegNet
https://github.com/chainer/chainercv/blob/master/examples/segnet
TensorFlow
FasterRCNN in TensorPack
https://github.com/tensorpack/tensorpack/tree/master/examples/FasterRCNN
Pytorchのほうが資料など豊富です。
Keras
Faster R-CNN from scratch written with Keras
https://github.com/kentaroy47/frcnn-from-scratch-with-keras
Keras Faster-RCNN(メンテストップ)
https://github.com/jinfagang/keras_frcnn
試したい人へ 物体検知のよく使われるデータセット
PASCAL-VOC2007

http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
Download mirror:
https://pjreddie.com/projects/pascal-voc-dataset-mirror/
まずはPascal-VOCから始めるのがおすすめだ。
データ数も5000と少なく一晩でなんとか学習ができる。
画像中に車、猫、人、テレビ。。など20個の物体の位置を当てるタスク。
よく物体検知タスクのベンチマークとして出てくる。
上の例ではMNIST的な存在と書いたけどタスク難易度はこちらの方が全然上。
データセットとしては1万枚(train 5000, val 5000)で学習も数時間で終わる@GPU。
まずはこのデータセットで学習を試すと良い。
難易度は画像認識でいうとCIFAR10~100なイメージでベンチマークが行われる。
SoAのmAPは75%くらい。 mAPに関しては後述したい。
MS-COCO

Download:
http://cocodataset.org/#home
API:
readmeを読むといい。
https://github.com/cocodataset/cocoapi
更に複雑なデータセットとして有名なのがMS-COCO。
論文などを書きたい場合はCOCOベンチマークが必要だがGPU一つでは学習に一週間以上かかってしまう。
画像内の物体が多く、SoAのmAPは35%ほどでかなり難しい。(追記:現在は45-50%まで向上。)
研究用のベンチマークとしてはVOCよりもCOCOが最近は使われる。
データセットサイズは8万枚ほど。(学習は長い)
感覚としてはImageNet相当の難しさ。
この精度向上は重要なトピックだが中々難しい。評価 尺度もmAP@IoU 0.5:0.95やmAP@IoU0.5など何種類かある。
KITTI Object detection

自動運転系のデータセットではKITTI object detectionがある。
データセットサイズは5000枚と小規模。
上の2つほどは使われないがアプリによっては(自動運転などをターゲットとするなら)重要。
VOD-Converter(ツール)
Visual Object Dataset converter
https://github.com/umautobots/vod-converter
物体検知系データセットの形式を変換できるツール。超便利。
PASCALデータセットをMS-COCO形式に変換など行いたいときが多々あります。
そんなコード卒中書いてたら何も進まないので。。
物体検出の高速化には?
FRCNNは計算量が大きいため、GPUでもリアルタイム(30FPS)は出ません。
そこで高速化するアプローチをいくつか書いてみました。
-
YOLO,SSDなどのsingle-stage detectorを使う
ssd.pytorchなどわかりやすいです。
https://github.com/amdegroot/ssd.pytorch -
量子化などでネットワーク軽量化
Jetson Nanoでリアルタイムに物体検出をする方法(TensorFlow Object Detection API/NVIDIA TensorRT)
https://qiita.com/karaage0703/items/67050f2418aa6bb3851a -
専門モデルの使用
専門モデルでYOLOを1000倍高速化(手前味噌)
https://qiita.com/arutema47/items/a4197677c09a0d6eb3bf
専門モデルの高速学習+α
https://github.com/kentaroy47/DatasetCulling
## 演算量を下げる基本テクニック
またテクニックとしては自動運転でもない限り、動画のFPSを落とし間の検出結果は補完することで大きく計算量は下げられます。例えば人が歩くスピードは遅いので30fpsは必要ないですね。5fpsまで下げることで演算量は1/6になります。
またリアルタイム(30fps)で検出するとBoundingBoxのチラツキなどが起きて返って解析しづらくなります。
もう一つ強力なのは入力画像の解像度を下げることです。HDは1080x720ですが、ここまで大きい画像が必要なのは稀です。例えばWebカメラ用途であれば対象物は大きいため、300x300まで小さくすることで演算量は1/10程度まで小さくすることができます。
上記のFPS下げと併用することで容易に演算量は1/60まで下げられるので愚直にGPUなどを使わなくても(場合によってはですが)CPUでInferenceは行うこともできます。
このようなテクニックを応用している面白い論文が以下にあります。
Chameleon: scalable adaptation of video analytics
https://dl.acm.org/citation.cfm?id=3230574
PS
またCV分野で一年ほどKaggleにチャレンジし、こちらにKaggle masterになるまでの軌跡を書きました。更にデータ分析としてどうCVを勉強したらよいか、kaggleの所感などを記述しているので参考になれば幸いです。