目的
最近巷でで流行っている専門モデルの考え方や論文を紹介します。
元論文は専門モデルやモデルカスコードなどの技術を使い、YOLOを1000倍(!)高速化するという結果を挙げています。
1000xはちょっと吹き過ぎな気がしますが元論文のタイトルだったので。。
紹介論文
Title: NoScope: 1000x Faster Deep Learning Queries over Video
所属; Stanford Univ.
Authors: Daniel Kang, John Emmons, Firas Abuzaid, Peter Bailis, and Matei Zaharia
Project page: https://dawn.cs.stanford.edu/2017/06/22/noscope/
学会:VLDB2017 (データベース処理のトップ学会)
Github: https://github.com/stanford-futuredata/noscope
arXiv: https://arxiv.org/abs/1703.02529
背景
CNNやその応用(物体検出やセグメンテーションなど)ではネットワークの大きさと精度が比例してししまいます。そのため出来るだけ高い精度を出したい!と思うと**resnet101や152を使うハメになり速度やメモリがとんでもないことになってしまいます。**AWSなどでサービスを走らせるのならば出来るだけモデル演算量は小さい方が安く済むため、小さいことに越したことはないですね。
モデルの演算量を削減するアプローチとしては枝切りや量子化などが出てきていますが、それらはImagenet等の汎用タスクの精度を下げずに演算量を下げる工夫でした。30~80%ほど早くなるのですが、最近はサチってきてるな、というのが実感です。
専門モデルの考え方は更に思い切り、ある特定タスクにフォーカスする代わりにモデルサイズを思いっきり小さくしてしまおう、というアプローチです。
データドメインによっては1000xの爆速化も同精度で達成できるのがメリットです。
汎用モデルと専門モデル
大体ユーザーが使うresnet101などはImageNetのような大規模データセットで訓練され、様々な画像の特徴を抽出出来る非常に優れた汎用モデルです。
ただ実際にこのような汎用モデルが求められるのはデータセンターなどに限定され、例えばCNNが近年用途を広げている監視カメラや交通カメラなどの定点カメラは背景が固定で映る物体の種類も限られます。
ただユーザーがこなす特定タスク(車の数を数える、船の場所を特定する)といったタスクには上記はオーバースペックであり、もっと小さなモデル(res18くらい)でも十分なモデルでも高い精度が達成できる可能性があります。
直感的に言ってしまうと車を数えるモデルは車の特徴量が抽出できれば十分であり、Imagenetモデルで要求されるような数十種類の犬種を見分けるほどの特徴抽出は必要ないため小型化できるという考えです。このようなあるタスクに特化したモデルを専用モデルとこの記事では呼びます。
交通カメラの画像例


上記のGIFはNoScopeページから拝借しました。
交通カメラの画像ですが、ほぼ物体の種類は車とスクーター、バスと種類は片手で足りるくらいです。MS-COCOなどはクラス分類が80種もありますが、それに比べると特徴量抽出は大幅に簡略化できそうじゃないですか?
NoScope
専門モデルの考え方を初めて導入したのがスタンフォード大のNoScopeです。
NoScopeの目的は長期間ビデオ処理を出来るだけ低コストにすることです。
NoScopeのアプリはビデオクエリ処理であり、例えば30時間の監視カメラ映像をモデルが処理する時に”車が通過したフレームをピックアップしたい”などの用途です。ただ30時間もの映像全てにCNNを適応すると(それがたとえYOLOと言った軽量性を謳っているネットワークであったとしても)、非常にGPUコストが掛かってしまいます。
そこでバカ正直に精度の高いCNNを使うのではなく、ズルをしてしまおう、というのが提案です。
NoScopeの新規性
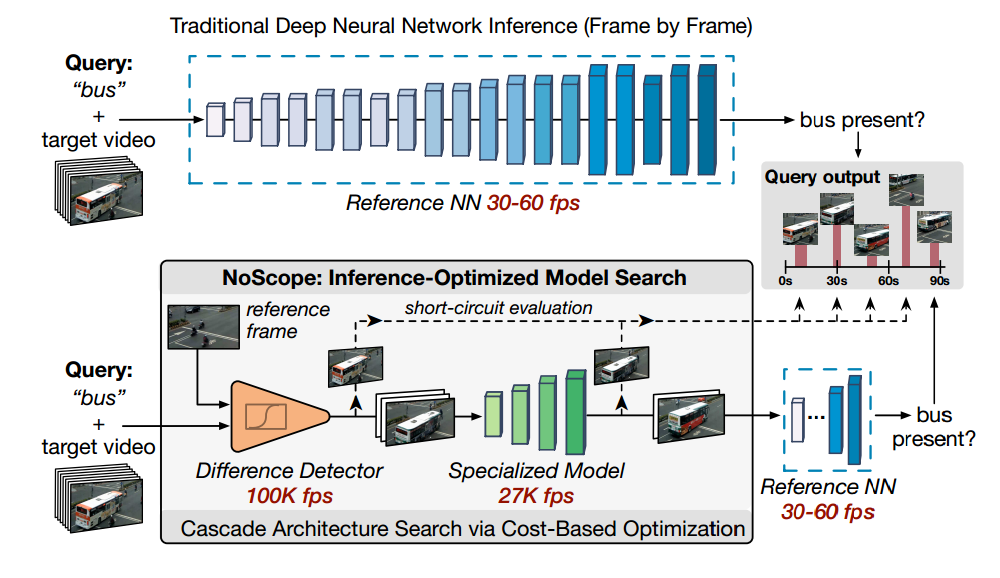
NoScopeのフレームワークです。
モデルを複数縦続的に接続したものなのでモデルカスコードと論文中で呼称しています。
コストの安いモデルを出来るだけ使い、精度が求められるデータに対しては適応的に高コストモデルを起動することでクレバーに総コストを削減します。

-
まず交通カメラには車や物体が全く写っていない時間がありますが、このようなフレームを真面目に処理するのは時間の無駄です。
そこでまずパイプラインの頭でそのような物体のないフレームを弾くモデルを入れます。これは背景差分を計算するだけなので、YOLOに対して2000倍高速です。
ある意味コレは背景ー物体を検知する専門モデルと言えます。
-
そして次に物体の写っているフレームに対しては専門CNNモデルを用いて処理をします。これは層の浅い(4層ほど)のCNNを特定の交通カメラの映像を用いて学習したものを使います。監視カメラ映像に対し特化したモデルなので、層が浅くても十分な精度を達成できます。
この専門モデルはYOLOに対し500倍高速です。 -
そしてこの専門モデルが上手く推論できなかった結果(logitが背景か物体か自信がない)に対してのみ、高精度なYOLOモデルを使い精度の高い推論結果を得ます。このように難しいデータにのみYOLOを使うことで総合的な精度を低下せずに総演算コストは低くするようなパイプラインになっているのが興味深いです。

**このような簡単なデータはテキトーに処理し、難しいデータのみちゃんと推論をする。。**というアプローチで演算コストの1000x改善に成功してます。
蒸留を用いた専門モデルの学習
CNNの学習をするとなると一般的には教師データが必要です。
ですが監視カメラごとのデータに対して人手でラベル付するのはコストが掛かりすぎます。
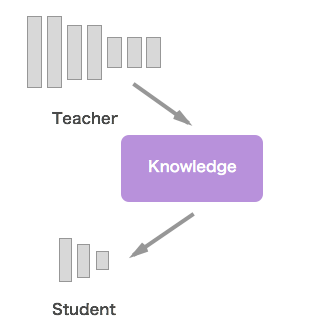
そこでNoScopeでは**Knowledge Distillation(蒸留)**を用いて学習を行っています。
蒸留はStudentとする専門モデルと教師とするモデル(ここではYOLO)とドメインデータがあればよく、ground truth labelsは必要ありません。
この図でいうKnowledgeはドメインデータに対する回答ですね。
教師モデルの推論結果を真ラベルとして生徒を訓練することで、十分に学習を行うことができます(もちろん教師モデルの推論精度が高いことが前提)。
NoScopeのLimitations
1) NoScopeのタスクはバイナリ分類のみ
NoScopeが行っているタスクはフレーム内に特定物体があるかないかのみのタスクなのでYOLOに対しそもそも非常に簡単であるというツッコミはあります。(だから1000xも改善できる)
ただより複雑なタスク(物体検出、セグメンテーション)は他の論文で実証されてきてます。当然演算コストの改善幅は狭まりますが。。(res101のモデルに対し10-20xくらい)
セグメンテーション
Online Model Distillation for Efficient Video Inference (ICCV 2019)
https://github.com/ravi-teja-mullapudi/JITNet-online-distillation
物体検出
Dataset Culling: Towards efficient training of distillation based domain specific models. (ICIP 2019)
https://github.com/kentaroy47/DatasetCulling
2) 専門モデルの学習やドリフトについて
専門モデルはある特定期間のデータに対し学習するため、常にアップデートしなければなりません。
例えば雨や雪が振ったりするとモデルはアップデートしなければいけないですね。
これらはこれから研究する必要がありそうです。
ドメインアダプテーションなどの技術でどうにかなるかも?