物体検出についての歴史まとめ
https://qiita.com/mshinoda88/items/9770ee671ea27f2c81a9
の続きです。ここでは、FPN、RetinaNet、M2Det、CSPNet、YOLOv4,YOLOv5 のアプローチとそれぞれの特徴を見ていきます。
- Feature Pyramid Networks
- RetinaNet
- M2Det
- Cross Stage Partial Network
- 活性関数 Mish
- Soft-NMS
- IoUベースのレグレッションロス
- データオーグメンテーション
- DropBlock regularization
- Cross-Iteration Batch Normalization
- YOLOv4
- YOLOv5
参考文献
(2020/08/29現在、YOLOv5について加筆中)
1. Feature Pyramid Networks
Feature Pyramid Networks for Object Detection,CVPR'17[1]では、Faster R-CNN のAuthorである、Ross Girshick氏が関わっている研究です。
物体の検出にあたってはマルチスケールのFeatureを用いることが昔からあった一方で、
DeepLearningではなかなかそれを組み込めないでいたところに対して、Feature Pyramid Network を提案しています。
1-1. アーキテクチャの分類
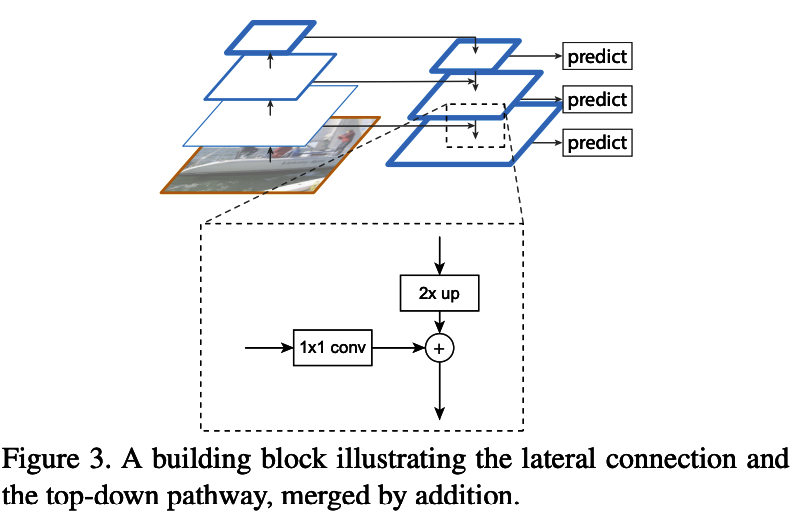
Feature Pyramid Network(以下、FPN)とその他のDeepLearningの手法との比較については、図1-1を参照。
図1-1

(a)は遅い。(b)はFast R-CNNやFaster R-CNN、YOLOで採用。(c)はSSDで採用されています。
(d)がこの論文で提案されている手法。
図において青枠で囲ったところがfeature mapであり、太い線は意味的に強い特徴量であることを示しています。
(b)はfeature mapの解像度が低い。
(c)は低いレイヤの特徴抽出が弱い。
(d)は低いレイヤもコンテキストを抽出した特徴を利用でき、解像度も高い。
1-2. FPNの詳説
図1-2
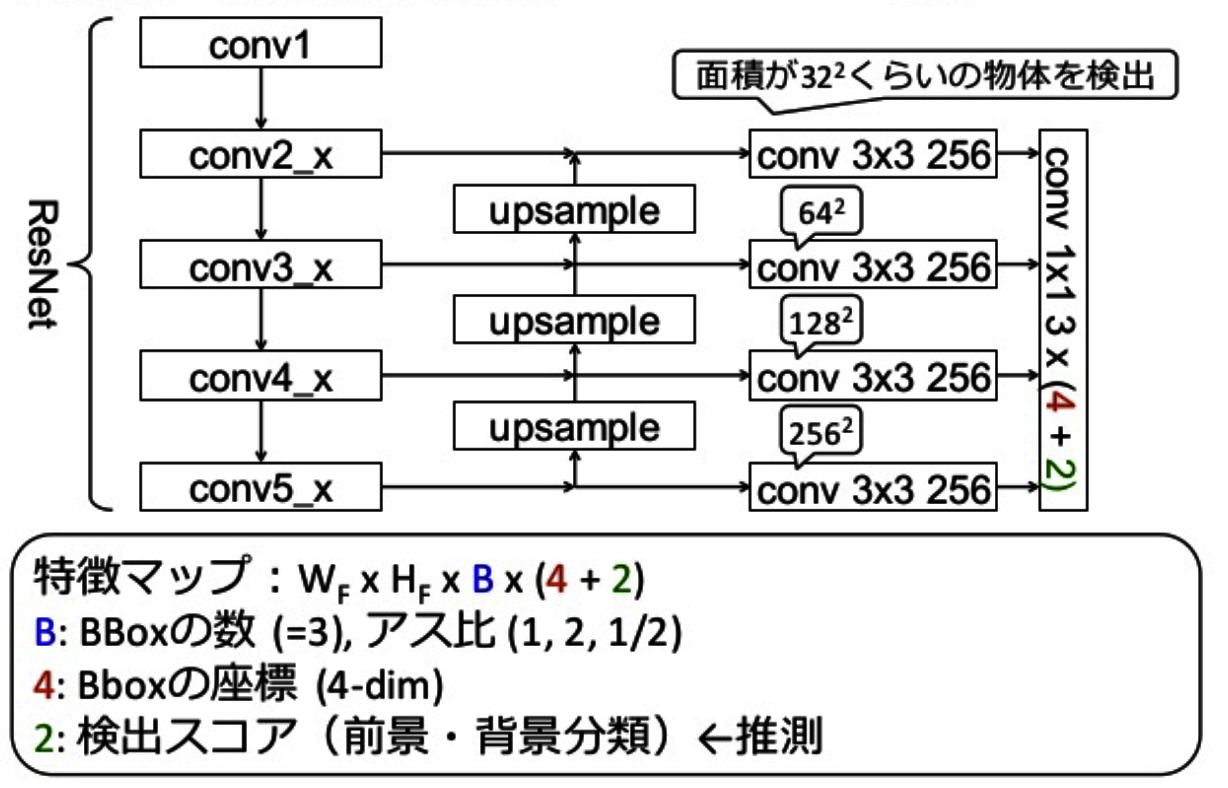
図1-3
・ボトムアップ
図1-3の左側のfeature map生成ステップを指していますが、「backbone ConvNet」とあるようにVGGやResNetなどのベースのCNNのアーキテクチャの feedforward です。特にResNetを利用することを記述しています。
様々なスケールのfeature mapを構成する特徴階層を算出します。それぞれのネットワーク階層の最後の層をfeature mapとして用い、ピラミッドを作成していきます。
・トップダウン
図1-3の右側のステップですが、アップサンプリングして、
空間的には疎だけれど、正確な場所が把握できる強い特徴を作成しています。
図1-3のように「nearest neighbor upsampling」を用いて2ずつ解像度をアップサンプリングしていきます。粗い画質のmapを作成するため、ボトムアップの最後のlayerに1×1のconvolutional layerを付け足します。
最後に、アップサンプリングによって画像境界がギザギザになってしまうエイリアシング効果を減らすために、結合された各mapに3×3の畳み込みを加えます。
2. RetinaNet
2-1. two-stage detector と one-stage detector の特性
two-stage detector:Faster R-CNN系。propopsal stage(背景候補となる大部分を排除)と classfiy stage(背景/背景でないを分類)で動作している。
one-stage detector:YOLO,SSD。
one-stage の物体検出モデル(YOLOやSSD)は計算スピードは早いですが、精度ではtwo-stage物体検出モデルに劣る。この理由は背景と背景じゃない領域の比率が均衡でないことが原因でした。
Two stageのモデルではproposal stageで背景のサンプルをフィルターし、候補数をまず減らしています。その後の分類ステージでは背景と背景でない領域の数の比率を3:1に固定にしたり、OHEMを利用したりすることでバランスを保っています。
one stageのモデルでは、簡単に背景に分類された領域が多すぎて、これらの手法は非効率です。そこで、この論文では新しい損失関数 Focal Loss の導入を提案し、この問題に取り組んでいます。
2-2. Focal Loss
2-2-1. Focal 導入の背景と狙い
abstractから。
・フォアグラウンドクラスとバックグラウンドクラスの間に極端な不均衡が存在する
・この問題に着目し、解決のため「標準のクロスエントロピー誤差をカスタマイズ」する
・この新しいFocal Lossは、「膨大な数のeasy negativesが誤差関数を圧迫すること」を防ぐ
・このFocal Lossを導入したシンプルな検出器を我々はRetinaNetと名付けた。
・Focal Loss導入でtwo-stageの検出器の精度向上しつつ、one-stage検出器のスピードを実現した。
図2-2-1
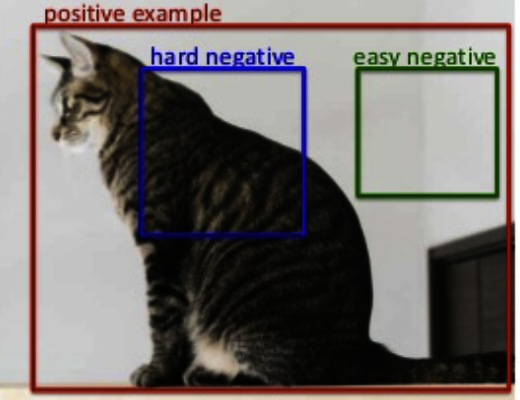
2-2-2. 2値分類のクロスエントロピー
まずは通常の2値分類のクロスエントロピー(CE)を復習です。
CE(p, y)=
\begin{cases}
-log(p) & if y=1\\
-log(1-p) & otherwise
\end{cases}
ここで $p$ はラベルが $y=1$ となる確率の予測を表します。また、$p_t$ を以下のように定義すると $CE(p,y)=CE(p_t)=-log(p_t)$ と表せます。
p_t=
\begin{cases}
p & if y=1\\
1-p & otherwise
\end{cases}
図2-2-2
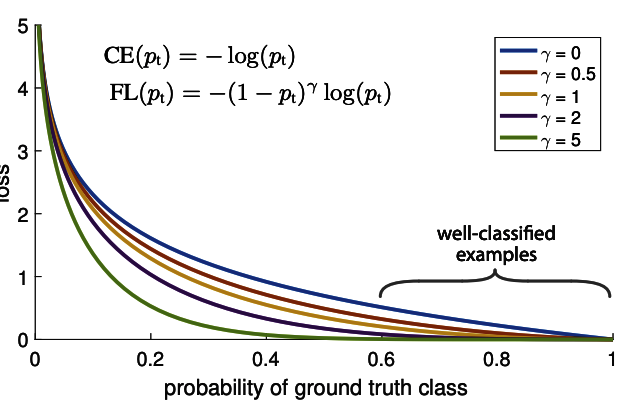
2値分類のクロスエントロピーでは、図2-1の青色カーブを参照すると分かるように
$p_t>>0.5$ のケースでもそれなりの損失を発生させていることが確認できます。
2-2-3. Balanced Cross Entrophy
クラスの不均衡によく使われる方法は、重みを導入する方法です。
クラス1には $α∈[0,1]$ の重みを、クラス-1には $1−α$ の重みをつけます。
$α_t$ を $p_t$ と同様に定義すると、以下のようになります。
CE(p_t)=-α_t log(p_t)
2-2-4. Focal Loss
one-stage 物体検出モデルでは、negative(背景)に分類された領域がクラスの不均衡から損失の大部分を占めてしまいます。$α$ は positive と negative の重要性の均衡は取れますが、分類が簡単/難しい(easy/hard)例を区別しません。
そこで、$FL(p_t)$ をFocal Loss として提案しています。
FL(p_t)=-(1-p_t)^{\gamma} log(p_t)
ここで $ {\gamma}∈[0,5]$
パラメータは2つ導入しています。
(1) $p_t$:分類の容易さを表す。$p_t$ が小さい場合は分類確率が低いので、分類を間違う hard example を表します。
(2) ${\gamma}$:分類の容易な場合の重みをどれくらい小さくするか調整する。
$(1-p_t)^{\gamma} $に着目します。
$p_t$ が小さく分類を間違えた場合、重みは1に近くなり、損失は影響を受けまん。
一方 $p_t→1$ の時、分類は容易(easy example)なので、重みはゼロに近くなり損失は小さくなります。
$γ=0$ のとき、全ての$p_t$に関して $(1−p_t)^0=1$ となるので Focal Loss は Cross Entropy に一致します。
また、$γ=1$ のとき、$(1−p_t)^1=−p_t+1$ となるので、$y=−x+1$ のような直線で表すことができます。
Focal Loss まとめ
- Focal Loss は 分類が容易な例(easy example)は重みを小さくし、分類が困難な例(hard negative) の訓練に焦点を当てています。
2-2-5. Class Imbalance and Model Initialization
実際には次のの損失を用います。
FL(p_t)=-{\alpha_t}(1-p_t)^{\gamma} log(p_t)
2値分類の場合、どちらのクラスも同じ確率で出力されるように初期化されますが、不均衡データの場合、よく現れるクラスの損失が支配的になってしまいます。
そこで、推定される $p$ のために $prior$ ${\pi}$ という概念を導入します。
推定される確率$p$ の値が低くなるように ${\pi}$ を設定します。
2-3. RetinaNet のネットワーク
図2-3
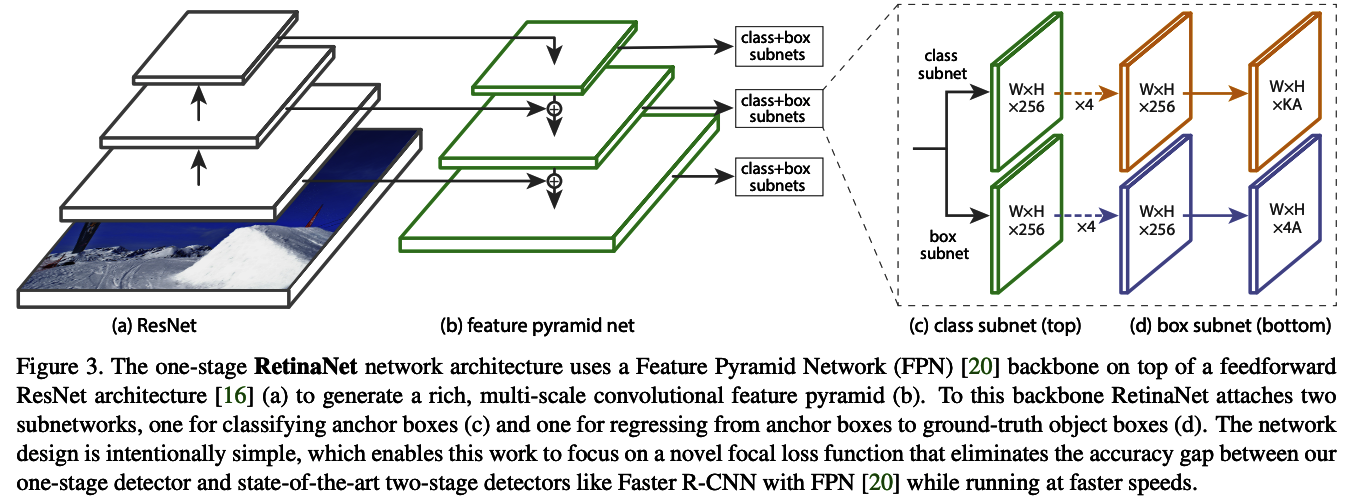
Focal Lossを組み込んだ RetinaNet については 4. RetinaNet Detector のセクションで記載されており、Feature Pyramid Networks が採用されていることが分かります。
2-3-1. 2つのサブネット
RetinaNetは2つのサブネットワークを形成しており、1つはアンカーボックスを分類するため、もう1つはアンカーボックスから物体位置を近似するためです。
ネットワーク設計は意図的にシンプルに設計されており、one-stage 物体検出モデルとFPNを備えたFaster R-CNNなどの最新の two-stage 物体検出モデル間の精度のギャップを排除することを狙っています。
2-4. Focal Loss の効果
Focal Loss の最適なパラメータの探索結果が論文では記述されています。
図2-4
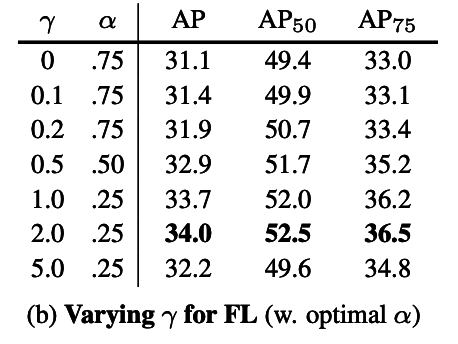
${\alpha}=0.25$, ${\gamma}=2.0$
2-5. Online Hard Example Mining (OHEM) との比較
図2-5
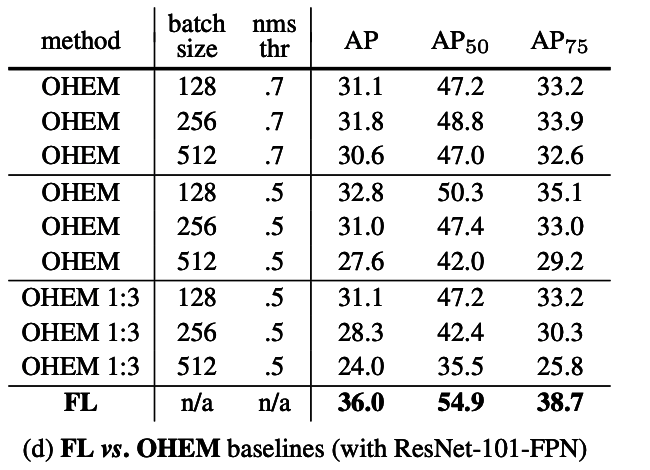
- OHEMは学習時に hard example をサンプリングする手法
- OHEMよりも良い結果になった
- OHEMが easy negative を排除して全く学習に利用しないのが精度を下げているのでは、と考察されている。
2-6. easy negative の損失の低減
図2-6
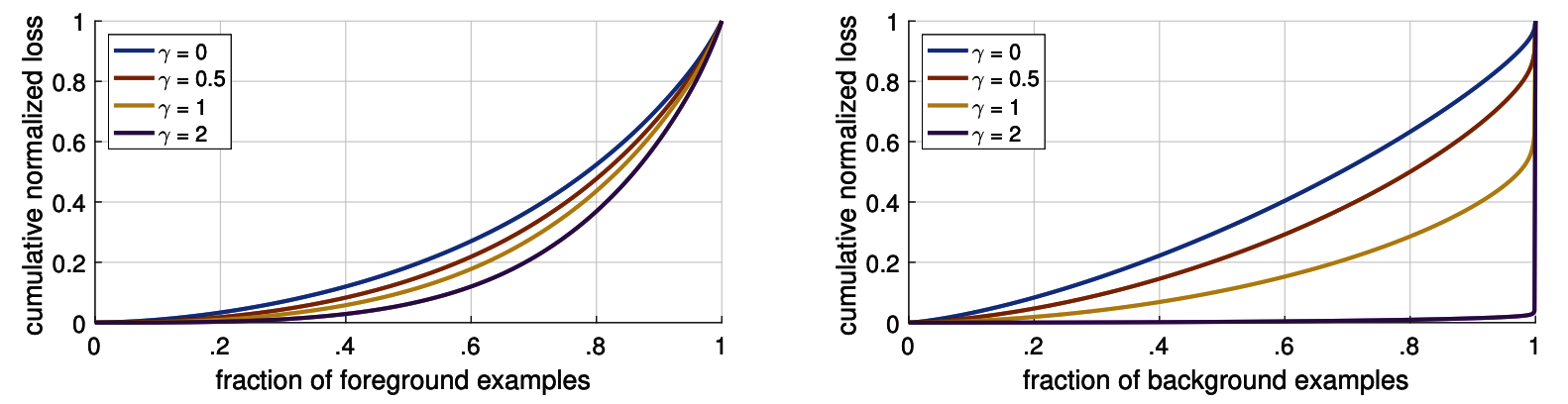
- 累積分布関数により、各抽出領域の損失への寄与を可視化している。
- ${\gamma}=2.0$ において negative sample の損失のほとんどが hard exampleからなる ことがわかる。
- Focal Loss の「分類が困難な例(hard negative) の訓練に焦点を当てている」ことの妥当性を示している。
3. M2Det
2018年11月のAlibaba Groupなどが行なった研究である"M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network[3]"について見ていきます。
3-1. 性能比較
図3-1

スピード面と精度面の両方で高いパフォーマンスが実現されている模様。
3-2. Feature pyramids の限界と Multi-Level Feature Pyramid Network(MLFPN)
RetinaNetの際のone-stageとtwo-stageの議論や Feature Pyramid Network(FPN) の構造を受け継いだ上で、FPNの構造をMulti-Levelにしています。
abstractから。
- Feature pyramids は物体間を通したスケールの違いのために生じる問題に取り組むために、SOTAのレベルでone-stage(DSSD,RetinaNet,RefineNet)、two-stage(Mask R-CNN,DetNet)の双方の検出器で広く用いられている。
- この Feature Pyramids の構造は頼もしい成果を出しているが、マルチスケールの計算の箇所が一つしかないことで限界が生じていると思われる。
- そこでこの研究では、Multi-LevelのFeature Pyramid Network(MLFPN)を提案する。
- MLFPNではThinned U-shape Modules(TUM)や、Feature Fusion Module(FFM)などのモジュールを用いている。
- このMLFPNの効率性を評価するために我々はSSDにMLFPNを組み込む
- それにより、end-to-endのパワフルな one-stage 検出器であるM2Detを提案し、SOTAのone-stage検出器の精度を上回った。
3-3. Feature pyramid の比較
図3-3
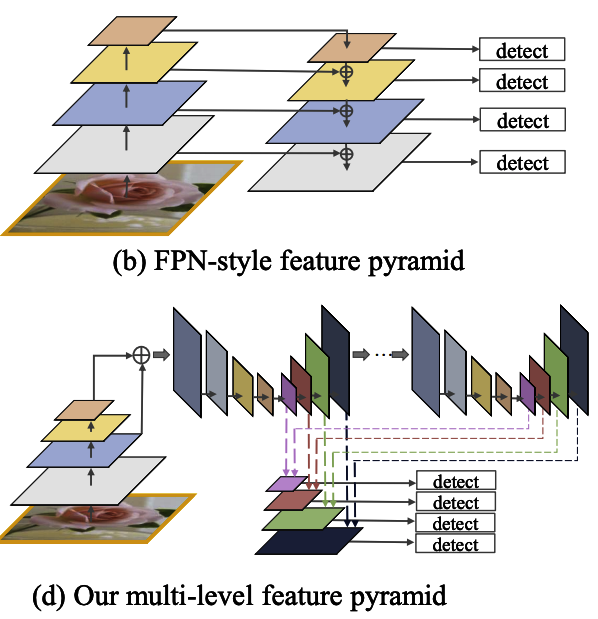
- 従来の Feature pyramids(b)と提案している マルチレベルのFPN(d) の比較
3-4. Multi-Level Feature Pyramid Network(MLFPN) の構造概要
MLFPNの全体処理フローを解説します。
図3-4-1
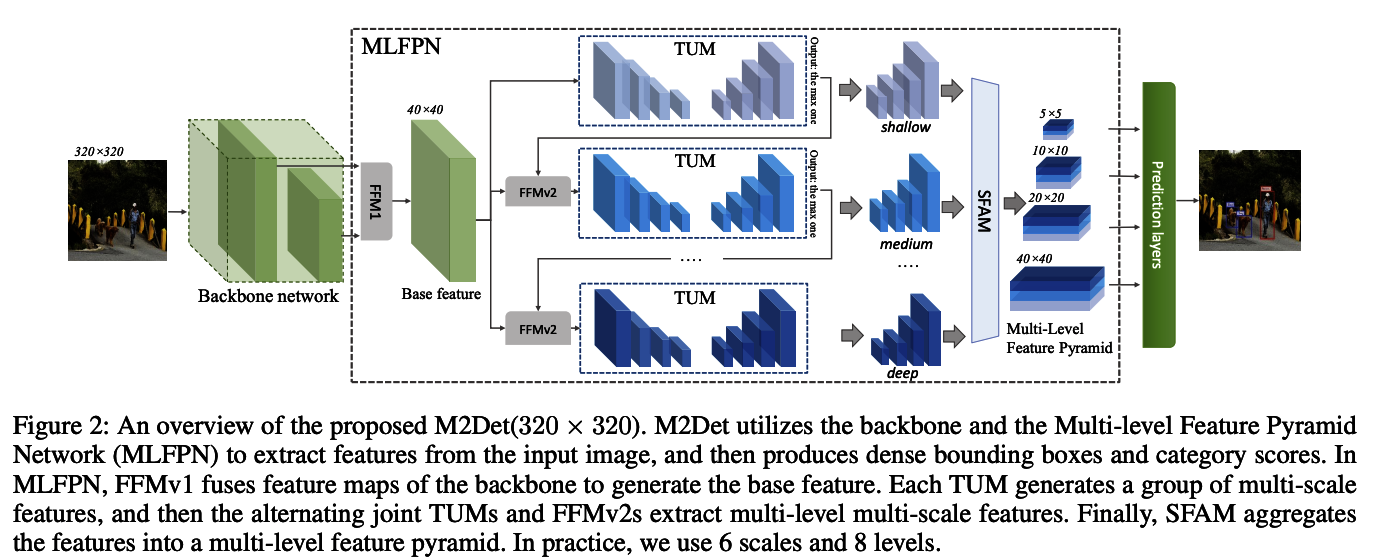
step1 まず、入力画像をVGGやResNetのようなbackboneのネットワークで処理しています。
図3-4-2
step2 FFMv1を用いて混ぜ合わせ、ベースの特徴量(base feature)を作成しています。
図3-4-3
step3 次にこのBase featureを入力としてTUM(Thinned U-shape Modules)を用いてmulti-scaleの特徴量のグループを生成しています。
図3-4-4
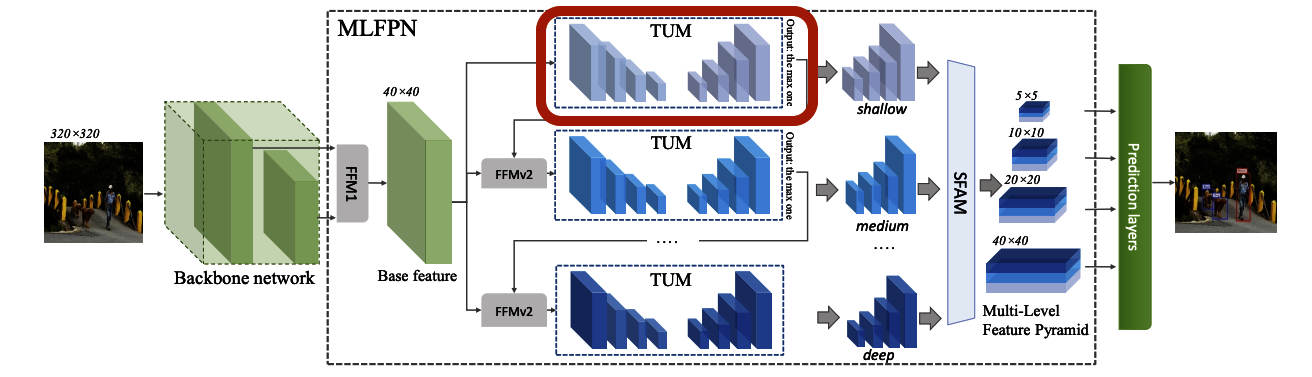
step4 またこのアウトプットをFFMv2で混ぜ合わせmulti-scaleだけでなくmulti-levelも実現したとされています。levelはここでは層の深さを表しており、それぞれ図ではshallow、medium、deepとされています。
図3-4-5
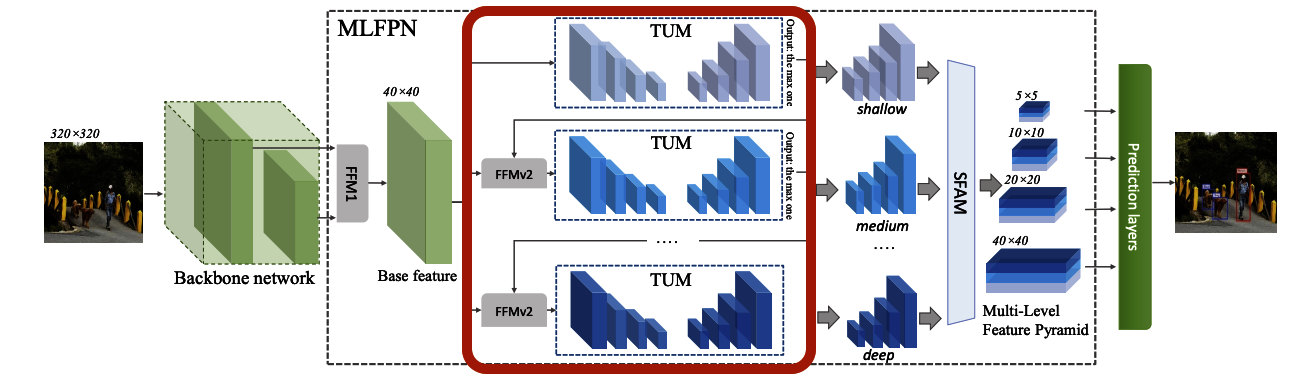
step5 最後にSFAM(Scale-wise Feature Aggregation)を用いて、Multi-Level Feature Mapとして出力されます。
ここでは、スケールごとの特徴マップを結合し、Feature Pyramidを生成して、複数の解像度の特徴マップから構成される Feature Map を生成しています。
図3-4-6
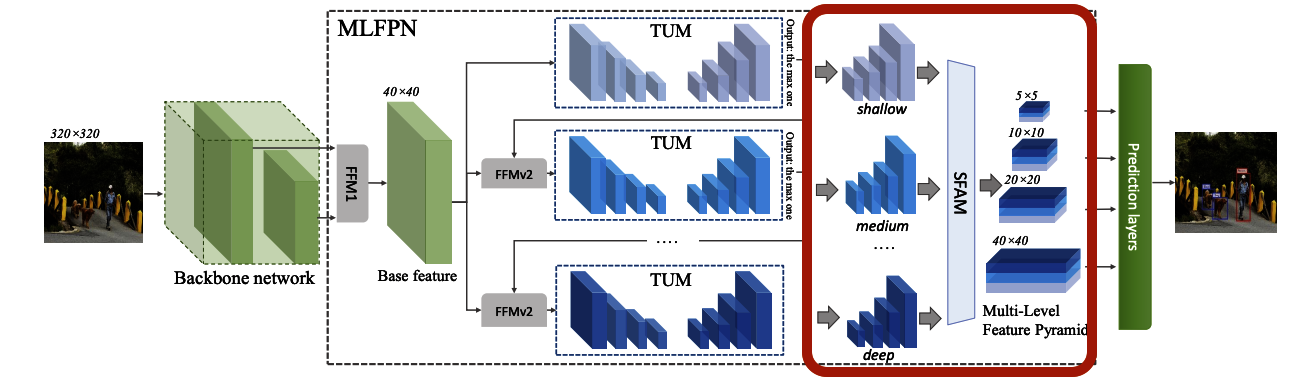
全体として次のようなパーツで構成されていることが分かります。
- Backbone Network
- Feature Pyramid
- Feature Fusion Module(FFM)
- Thinned U-Shape Modules(TUMs)
- Scale-wise Feature Aggregation Module (SFAM)
- Prediction Layer
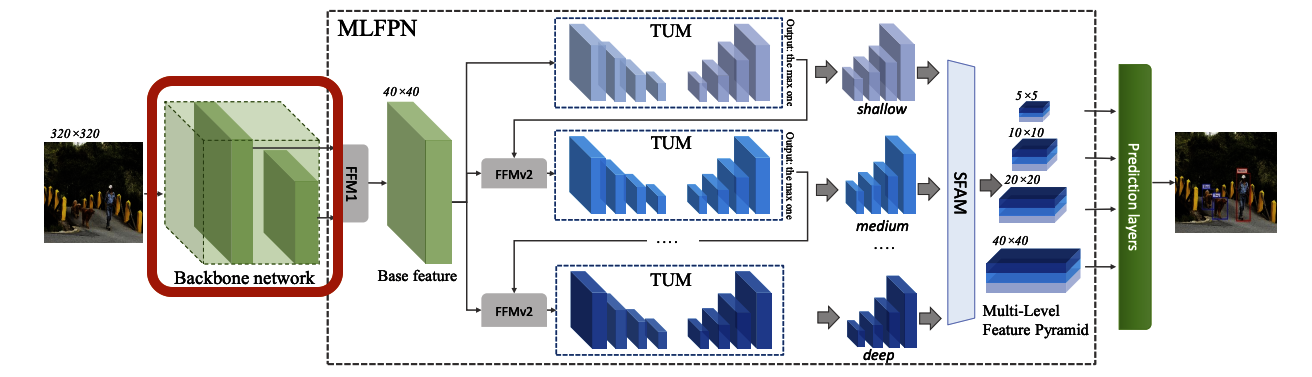
3-5. バックボーンネットワーク
論文では、VGGとResNet の2種類のBackboneを実験しています。
入力画像サイズをそれぞれ320×320px、512×512px、800×800pxに設定した際の各モデルの精度は下表1の通り。
図3-5-1
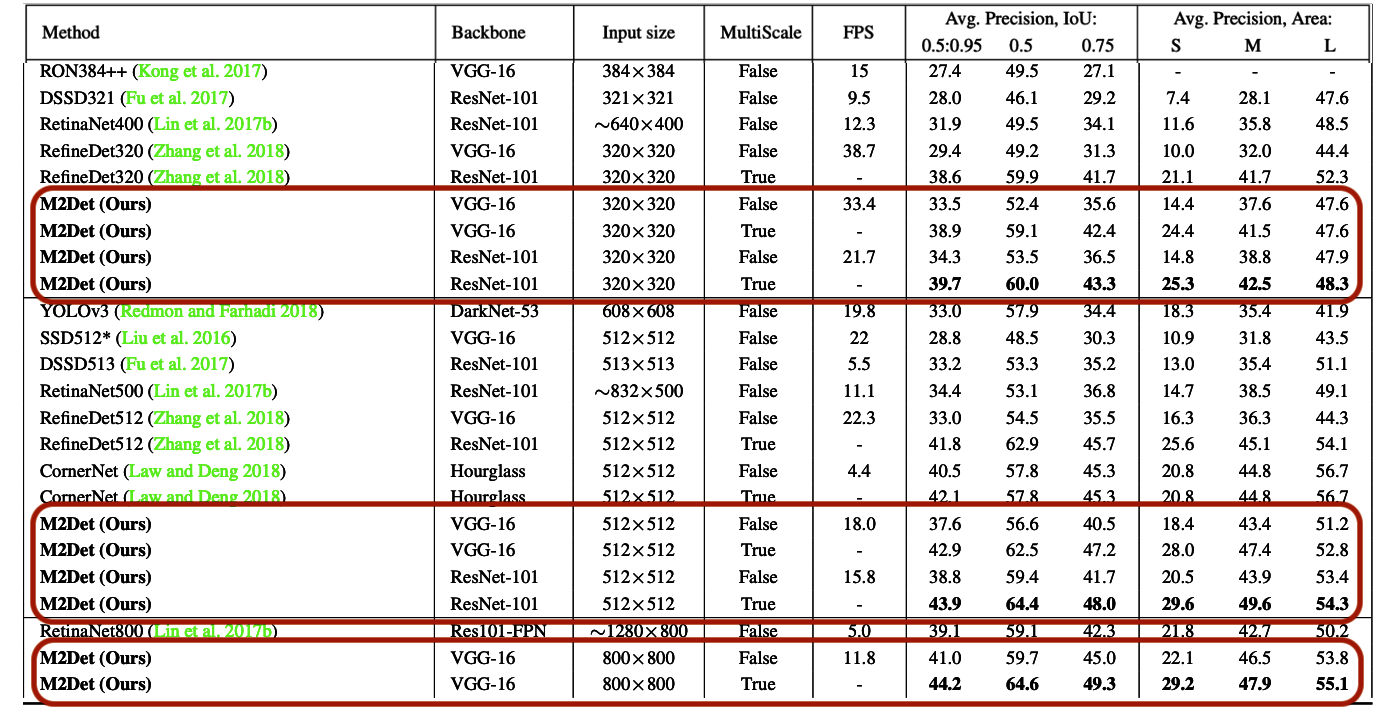
- FPS(Frames per second;1秒間あたり何枚の画像を処理できるかの性能)の値についてはVGG-16のBackboneを選択したモデルの性能が良い
- 一方、精度(Avg Precision,IoU)については、ResNet-101をBackboneに利用したモデルが最も良い
なお著者実装におけるBackboneの呼び出し(layers/nn_utils.py 122-130行目)
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/layers/nn_utils.py#L122-L130
は、設定ファイル中の値「backbone_name」 から設定可能です。Backboneの種類として
- VGG16
- ResNet50
- ResNet101
のいずれかを選択できます。
3-5-1. VGG Backbone
M2Det のVGG Backborn の著者実装(layers/nn_utils.py 100-120行目)
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/layers/nn_utils.py#L100-L120
は、SSDの非公式PyTorch実装のひとつである ssd.pytorch のコード(ssd.py 124-146行目)
https://github.com/amdegroot/ssd.pytorch/blob/master/ssd.py#L124-L146
を流用する形で実装されています。
ssd.pytorchにおけるVGG16の実装は、PyTorchの公式ライブラリであるtorchvisionのコード(torchvision/models/vgg.py)
https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
を拡張実装したものです。
VGG16 (batch_norm なし) の最後のAvgPool層とFC層に代わり、
- MaxPool層(ソースコード中の変数pool5)
- ReLU付きDilated畳み込み層(conv6)
- ReLU付き1×1畳み込み層(conv7)
を加えた構成になっています。
これによりVGG Backbone全体では35層(ReLU層も1層とみなす)で構成されます。
3-5-2. ResNet Backbone
M2DetのResNet Backborn
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/layers/resnet.py#L101-L111
もVGG同様に、torchvisionのコード
https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
をベースにしており、必要な部分のみを抜き出した形で実装しています。
しかし論文中に言及がありませんが、Layer3層がオリジナル版ResNetとは異なり、
strideが2->1に変更されています。
オリジナルのResNet Layer3 stride=2
https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py#L153-L154
self.layer3 = self._make_layer(block, 256, layers[2], stride=2,
dilate=replace_stride_with_dilation[1])
M2Det用の ResNet Backborn Layer3 stride=1
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/layers/resnet.py#L108
self.layer3 = self._make_layer(block, 256, layers[2], stride=1)
変更の結果、layer3とlayer4の出力サイズが2倍になりますが、これは後述するM2DetのFeature Pyramidで ResNetのlayer2(or layer3)とlayer4の出力を利用できるようにするためです。
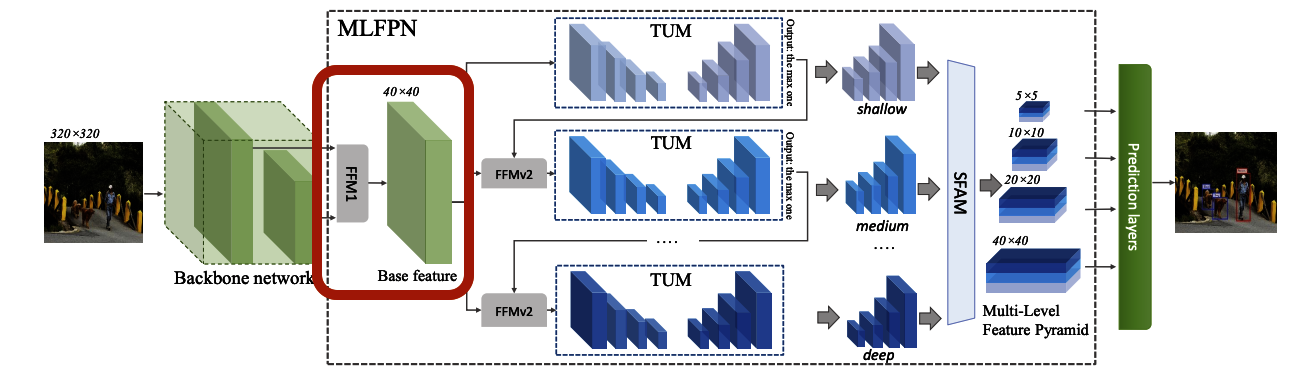
3-6. FFMv1 → Base Feature
図3-6-1
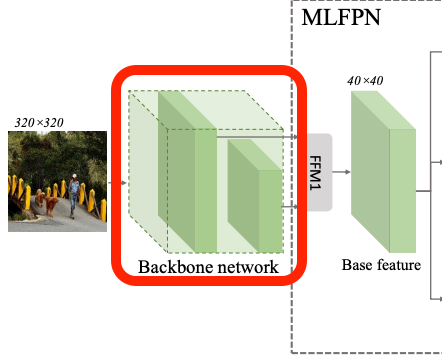
FFMv1では、Backbone中の特定の2つの層を取り出して結合することでBase Featureを生成します。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/m2det.py#L72-73
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/m2det.py#L103-L113
VGG Backbone を利用する場合は、Backbone側の(最初を0番目と数えて)22番目と34番目の層の出力を結合。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/configs/m2det320_vgg.py#L9
ResNet Backboneを使用する場合は、Layer2(or Layer3)とLayer4の出力層を結合。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/configs/m2det320_resnet101.py#L9
具体的には、Backboneの2つのfeature layerをそれぞれに畳み込み層に通した後に、
小さいサイズの特徴マップを大きいサイズの特徴マップにアップサンプリングし連結しています。
Backboneによって畳み込み層への入力チャネルサイズは異なるため、ハードコーディングされた2つのパラメーター「shallow_in, deep_in」で制御しています。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/m2det.py#L63-L73
VGG backboneの場合は、浅い層のチャネルサイズが512、深い層のチャネルサイズが1024であるため「shallow_in=512、deep_in=1024」に設定。
ResNet backboneの場合、layer2とlayer4を利用する前提で「shallow_in=512、deep_in=2048」と設定されています。もしも layer3とlayer4の出力を利用したい場合にはここを「shallow_in=1024、deep_in=2048」のように変更することが必要。
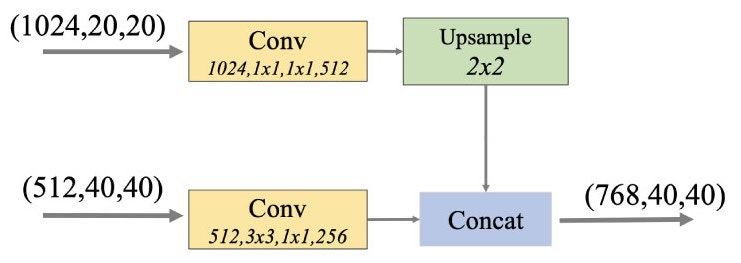
畳み込み層からの出力チャネル数も、同じ実装箇所において2つのパラメーター「shallow_out, deep_out」で設定されていますが、こちらはいずれのBackboneも共通した値「shallow_out=256、deep_out=512」で設定されています。この場合のBase Featureのサイズは、2つのチャネル数をあわせた(768, 40, 40)となります。
(C, W, H):チャネル数Cの解像度 (W x H) の特徴マップであることを表します。
図3-6-2
3-7. FFMv2 → TUMs
図3-7-1
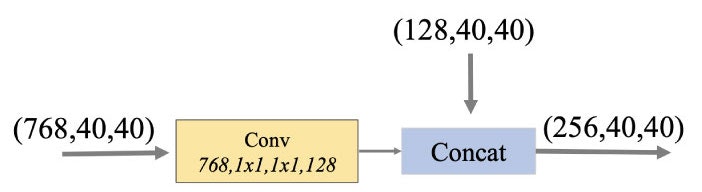
ここではFFMv1で作成された BaseFeature を Thinned U-shape Modules(TUMs)に繋ぎます。
まず、Base Feature (768, 40, 40) を畳み込み、チャネルを圧縮して(128, 40, 40)のサイズに変換。
これを直前のTUMが出力する複数サイズの特徴マップのうち、サイズが最も大きな(128, 40, 40)と結合し、特徴マップ(256, 40, 40)を生成して、次のTUMへ渡します。
最初のTUMには直前のTUMが存在しないため、FFMv2は使わず、チャネルを圧縮した Base Feature (128, 40, 40)だけが渡されます。
なお著者実装ではFFMという単語は出ておらず、また前半のConvolution部分
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/m2det.py#L79-L82
と後半のConcat計算部分
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/layers/nn_utils.py#L76-L79
が別々になっています。
3-8. TUM の構造
TUMはダウンサンプリングとアップサンプリングを行う複数の層から構成されます。
TUMの数は、著者実装では「num_levels=8」と設定されています。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/configs/m2det320_vgg.py#L11
個々のTUMの深さ(convolution層-deconvolution層ペアの数)は同じく「num_scales=6」と設定されています。これらについては論文通りの設定値です。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/configs/m2det320_vgg.py#L12
論文中ではTUMの数と各TUMのチャネルサイズの各パラメーターがモデルのmAPへ与える影響度合いについて比較検証が行われています。
※TUMの数(=num_levels)、各TUMのチャネルサイズ(=input_planes)
図3-8-1
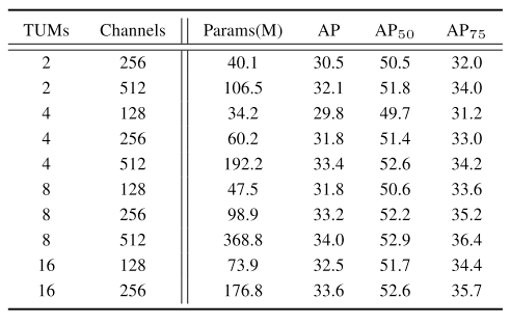
論文中の結果からはTUMおよびチャネルサイズの数を増やすごとに多少少精度が上がっていることが確認できます。
3-9. SFAM の構造
図3-9-1
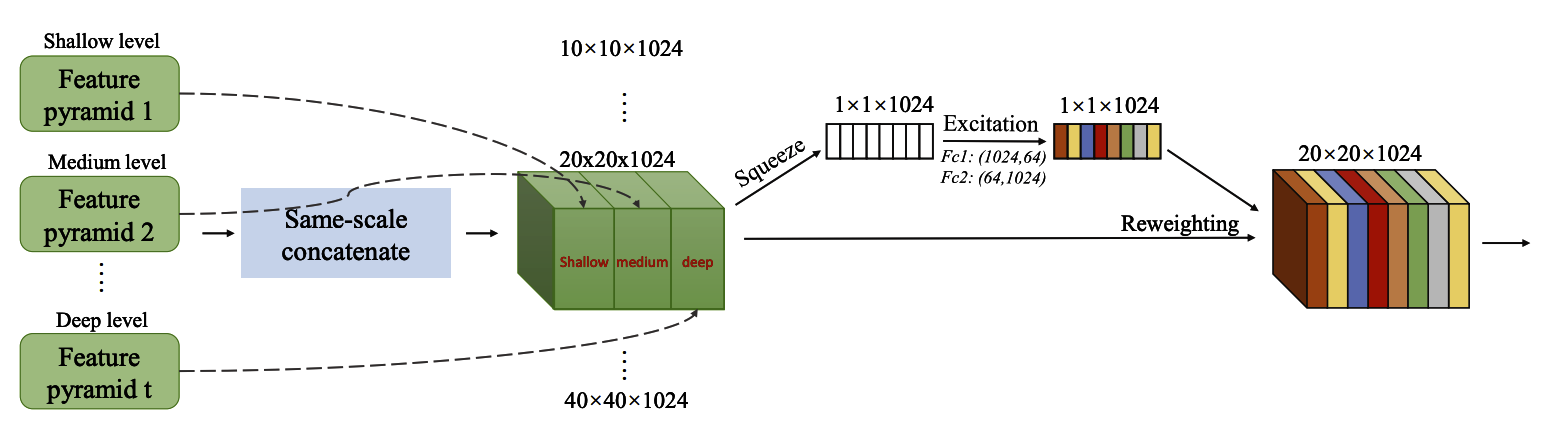
Scale-wise Feature Aggregation Module(SFAM) は各TUMの出力を統合してprediction Layerで推論処理をできるように整形します。
SFAMは主に2つのステージに分かれています。
-
Stage1では、TUM間の出力を同じ大きさごとに結合して新たな特徴マップを作成します。
前のセクションで説明した例の場合には、各TUMが6種類のサイズの特徴マップを出力するため、Stage1の出力で6つの特徴マップが得られます。 -
Stage2では、SE (Squeeze-and-Excitation) によるAttention 機構を用いて、Stage1で結合された特徴マップを重み付けします。
図3-9-2
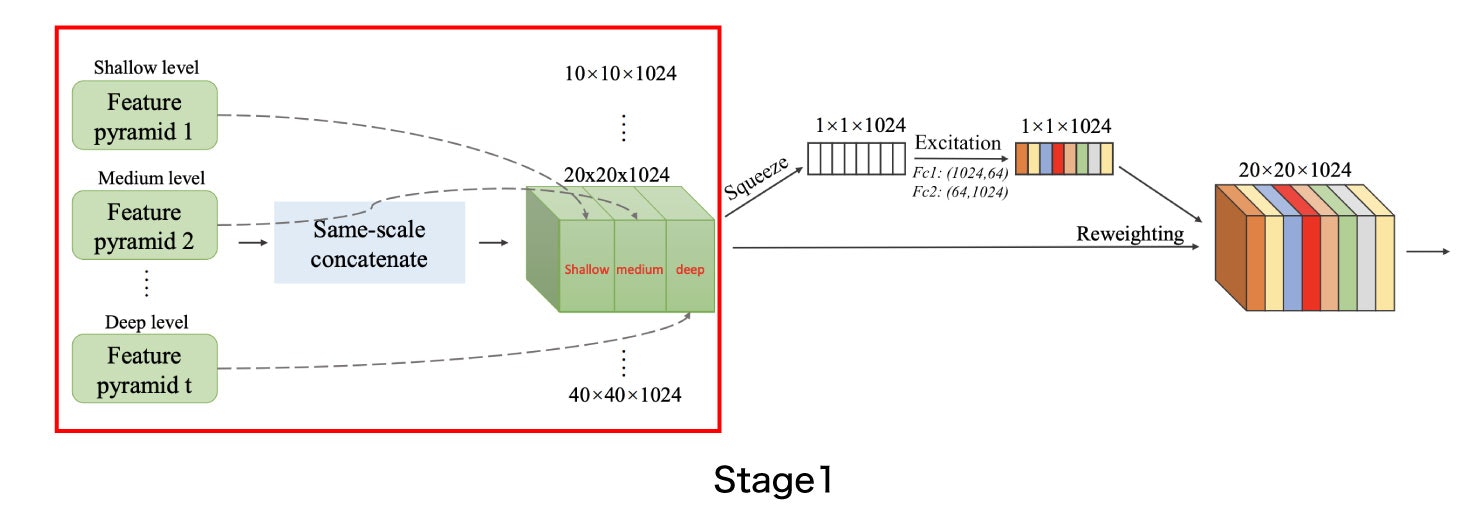
SFAMのアーキテクチャのうち、Stage1は、m2det.py 124行目で実装されています。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/m2det.py#L124
図3-9-3
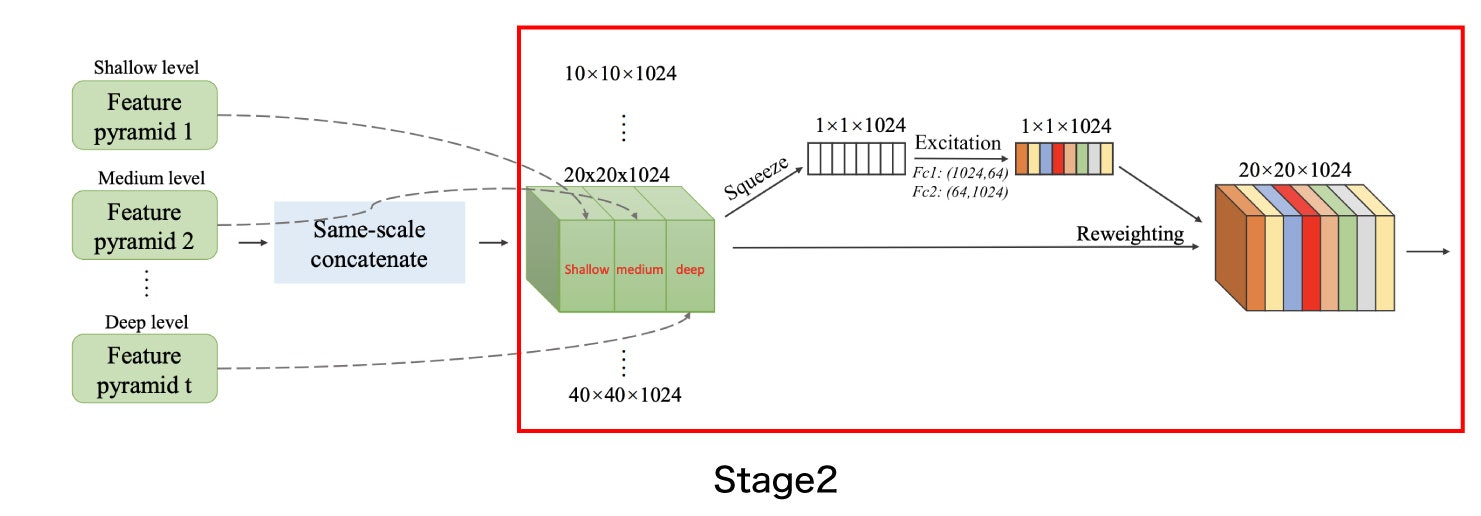
論文上ではStage1とStage2をあわせてSFAMと説明されていますが、ソースコードではStage2の部分のみがSFAMクラスとして実装されています。
https://github.com/qijiezhao/M2Det/blob/de4a6241bf22f7e7f46cb5cb1eb95615fd0a5e12/layers/nn_utils.py#L133-L160
結合した特徴マップのチャネル数が論文とソースコードで異なっており、
論文では1024であるもののソースコード上のチャネル数は2倍の2048となっています。
そのためSqueeze-and-Excitation で用いるFc1,Fc2のサイズも同じくそれぞれ論文の2倍のサイズである(2048,128), (128,2048)となります。
4. Cross Stage Partial Network(CSPNet)
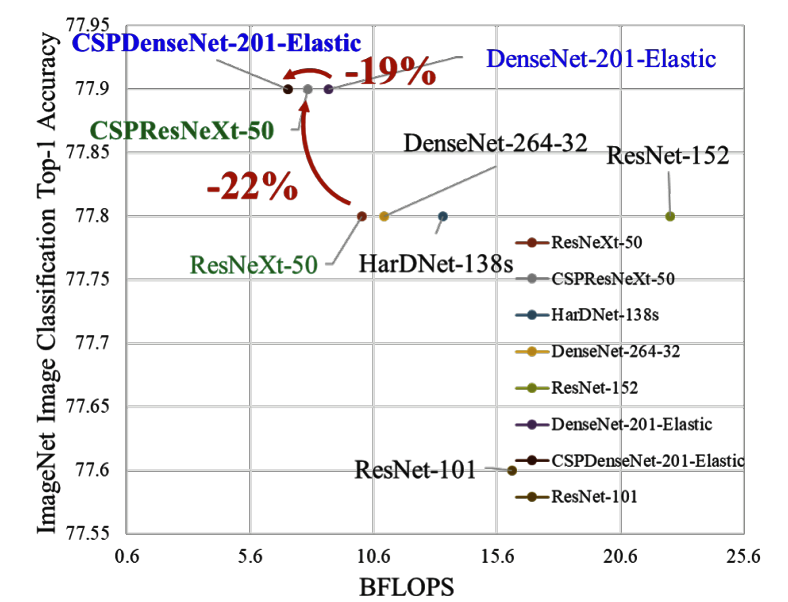
4-1. CSPNet とResNet/ResNeXt/DenseNet との性能比較
コンピューティングコスト、メモリの削減のみならず、速度・精度でも優位です。
4-2. ネットワーク概要
CSPNet ベースレイヤーの特徴マップを2つの部分に分割します。
1つのパーツは「dense block」 を通過して「transition層」へと流れていき、
他方のパーツは、「transition層」で結合されます。


4-3. CSPNetの特長
- CNNの各レイヤーでの計算量を均等に分散させて、各計算ユニットの使用率を効果的にアップグレードし、不要なエネルギー消費を削減
- MS COCOデータセットベース利用の実験では、YOLOv3ベースのモデル比較で計算上のボトルネックを80%効果的に削減
- CSPNetは、特徴量ピラミッド生成時に PeleeNet のメモリ使用量を75%削減。
CSPNetは精度をあまり落とさずに、計算コストを省略するための手法。
「Dense Blockで処理する特徴マップを一部分だけにして、処理しないものを後で結合する」
というResBlockっぽい機構を導入していることが分ります。
5. 活性化関数 Mish の採用
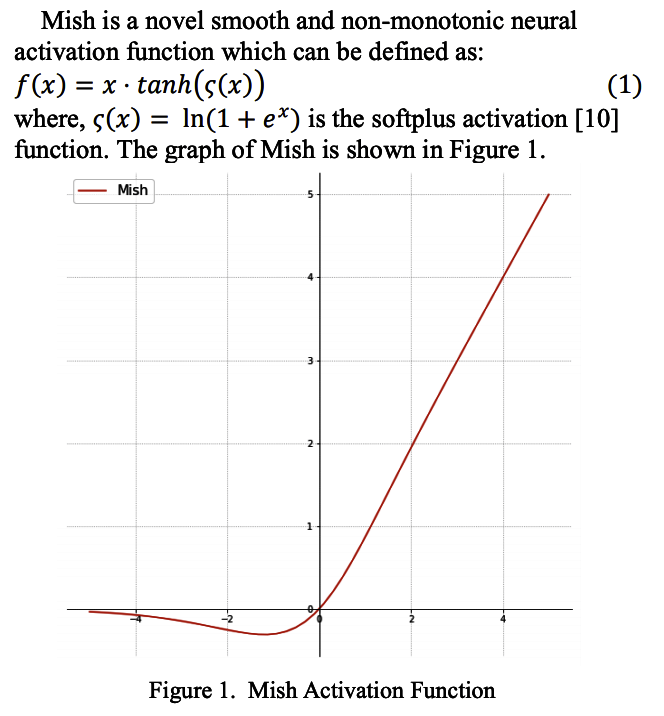
Mish(Mish: A Self Regularized Non-Monotonic Neural Activation Function)
は比較的新しいReLU系列の活性化関数。負の値を持つところでReLUとは異なります。
- 2017年にSwishが発明され、ようやくReLUは精度の面ではようやく第一線を退いた。
- 2019年8月に登場した新しい活性化関数 Mishは Swish のアイデアを元に考案されている。
- 滑らか、非単調、最小値はあるけど最大値は無限
- MishはCIFAR 100などの複数のベンチマークでSwishやReLUを使用したネットワークより、高いスコアを安定して獲得している。実装は簡単で効果的なため、最近注目されている活性化関数。
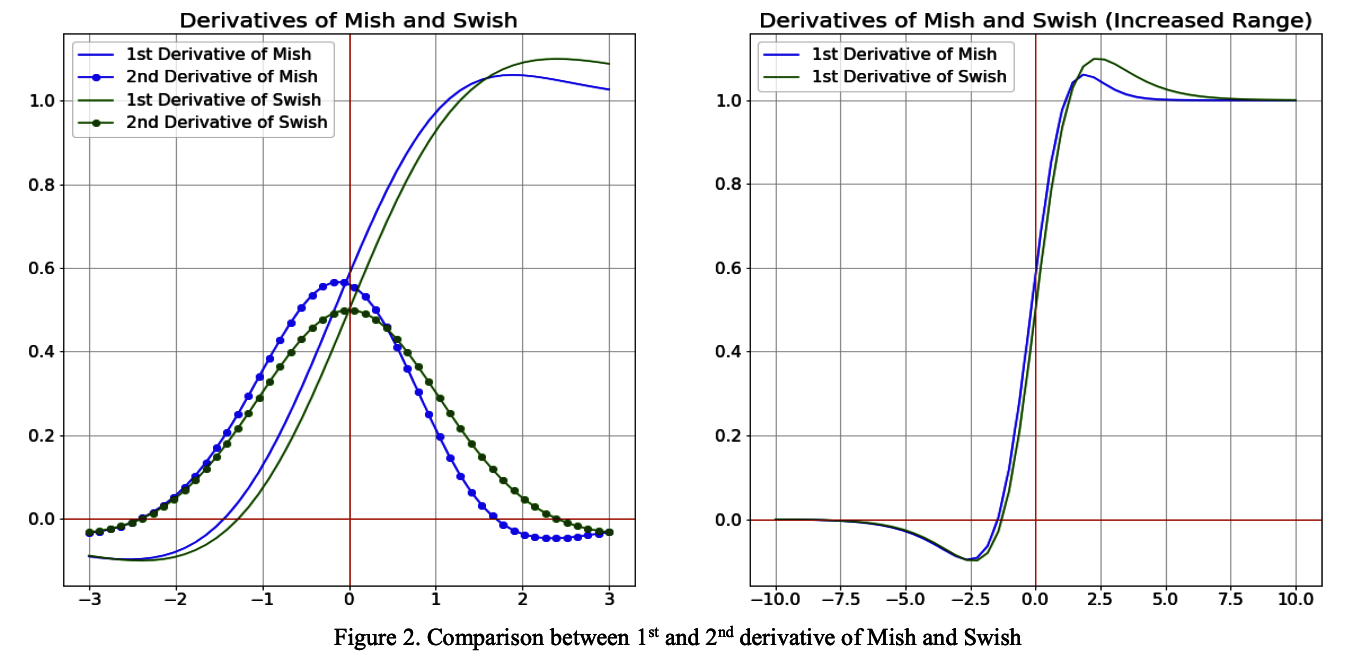
2回微分のグラフを比較した時に、Mishの方がSwishよりも勾配が急なグラフ。
つまり出力層が0付近において、Mishの方がより広い範囲を持つといえます。
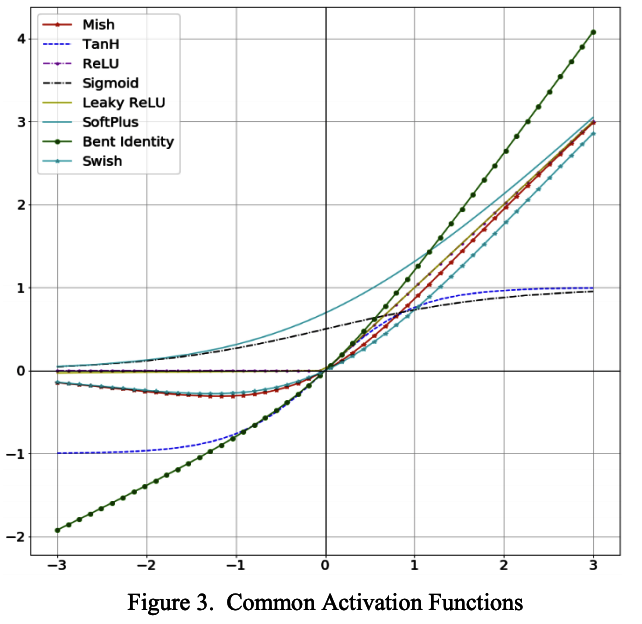
これまでの主要活性化関数まとめ
6. Soft-NMS
ここでは Soft-NMS(Soft Non-maximum supression)の提案について解説します。
6-1. NMS(Non-maximu supression) の問題

この画像では赤と緑で表示された検出ボックスがあり、それぞれ0.95と0.8のスコアが示されています。
緑の検出ボックスは赤のボックスとかなり重なり合っています。
このように、従来のNMS手法ではあるしきい値以上で重なり合ったボックスで検出された物体の他方を検出抑制してしまい、検出されないといった問題が発生してしまいます。
6-2. Soft-NMS の改善点
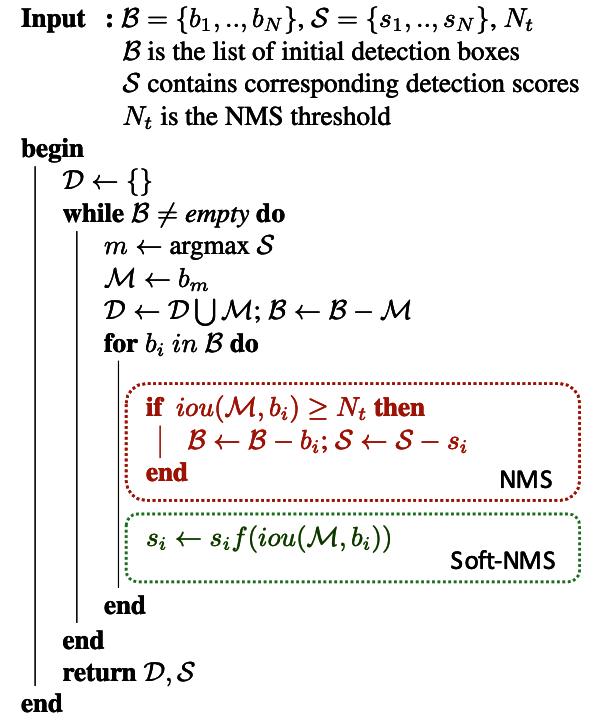
しきい値で検出を抑制してしまうのではなく、検出スコアを重なり具合によって補正するというアプローチを採用しています。
重なり具合が大きい場合は検出スコアを小さく補正し、
重なり具合が小さい場合は検出スコアを維持するといった補正を施しています。
(赤で囲んだ従来のNMSロジックの代わりに、緑で囲んだSoft-NMSロジックに置き換える)
7. IoUベースのレグレッションロス
7-1. IoUベースのロスの歴史
MSE誤差が一般的
物体認識のモデルの損失関数は、Bounding Box(以下、bbox) の位置を正解ラベルとのMSE誤差を取るのが一般的。しかし、bboxの各点を独立に最適化してしまう問題があった。
IoU loss の提案
そこで、2016年にIoUをloss として使う IoUベースのロス(IoU loss)が提案されました。
UnitBox: An Advanced Object Detection Network
Generalized IoU の登場
2019年2月に Generalized IoU が登場。
Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
Distance-IoU の登場
その後、2020年に Distance-IoU が登場。
Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
7-2. Generalized IoU
IoU = \frac{|A \cap B|}{|A \cup B|}
IoUは、二つの領域が全くoverlapしていない場合は全て値が0となる。
なので、二つの領域が近くにあるのか遠くにあるのか という点を反映させていない点が問題。
二つの領域A,Bの積と和に加えて、「二つの領域を囲む最小かつ同じ形状の領域C」を用いて、Generalized IoUを以下で定義する。
GIoU = \frac{|A \cap B|}{|A \cup B|} - \frac{|C \setminus (A \cup B)|}{|C|}
また、GIoU loss は以下で定義する。
L_{GIoU}=1−GIoU
7-3. Distance-IoU
L_{DIoU}=1- IoU + \frac{\rho(b,b^{gt})}{c^2}
$B,B^{gt}$はそれぞれ予想されたbboxと正解データのbbox
$b,b^{gt}$は$B,B^{gt}$の中心点
$\rho$はユークリッド距離
$c$は、2つのボックスを覆う最小のボックスの対角線の長さ
8. データオーグメンテーション
8-1. CutMix

CutMix によるデータ拡張は Mix-up, Cutout の手法と比較してImageNetのクラス分類・位置判定、Pascal VOCの精度においても改善されていることが確認できます。
「1つの画像から部品を切り取り、それらを拡張画像に貼り付けることで画像を結合」します。これにより、モデルは強い特徴量に基づいて予測を行うことを学習します。
Cutoutがない場合、モデルは犬の頭に特に依存して予測を行うため、頭が隠れている犬(茂みの後ろなど)を正確に認識したい場合は、問題があります。
CutMixでは、この処理を2番目の画像の正解ラベルとともに、別の画像の一部に置き換えられます。各画像の構成比率は0.4:0.6 のように画像生成プロセスで設定されます。
下の図では、この手法が単純なMixUpとCutoutよりもうまく機能することを示しています。


8-2. Mosaic data augmentation
モザイクデータ拡張は、4つのトレーニング画像を特定の比率で1つに結合します。この手法は、YOLOv4で導入された最初の新しいデータ拡張手法です。
これにより、モデルは通常よりも小さい縮尺でオブジェクトを識別する方法を学習できます。
また、フレームのさまざまな部分にさまざまなタイプのイメージをローカライズするようにモデルに働きかけます。

8-3. Class label smoothing
クラスラベルのスムージングは、画像操作の手法ではなく、クラスラベルの変更です。
一般に、境界ボックスの正しい分類は、クラス[1、0、0、1、0、0、…]といった one-hot ベクトルとして表され、損失関数はこの表現に基づいて計算されます。
ただし、モデルが1.0に近い予測で過信すると、他のクラス予測を誤って見過ごしたりします。
そのため、ある程度の不確実性を評価するために[0,0,0,0.9、0…]といったクラスラベル表現をエンコードします。
8-4. Self-Adversarial Training(SAT)
まず、画像を通常のトレーニングステップを経て、次に、重みを介してバックプロップするのではなく、画像を修正して損失信号を使用します。
モデルは敵対的手法に対抗して特徴を学ぶことになります。
9. DropBlock regularization
Google Brainチームが書いた論文で、NIPS2018に採択された正則化手法。
DropBlock: A regularization method for convolutional networks
9-1. Dropout の問題点
Deep learningが深い層でも学習に成功した一つの理由としてDropoutが有名です。
Dropoutは、ランダムにユニットの値を使えなくすることで過学習を防ぎ、汎化性能を向上させる効果があります。
しかしこれは全結合層で特に有効で、Convolution層ではあまり有効ではない という報告があります。下図の(b)参照。
この論文ではその理由を、Convolution層では空間的に隣り合ったユニットは共通の情報を多く共有しており、情報の相関があるため と指摘しています。
Although dropout is widely used as a regularization technique for fully connected layers, it is often less effective for convolutional layers.
This lack of success of dropout for convolutional layers is perhaps due to the fact that activation units in convolutional layers are spatially correlated so information can still flow through convolutional networks despite dropout.
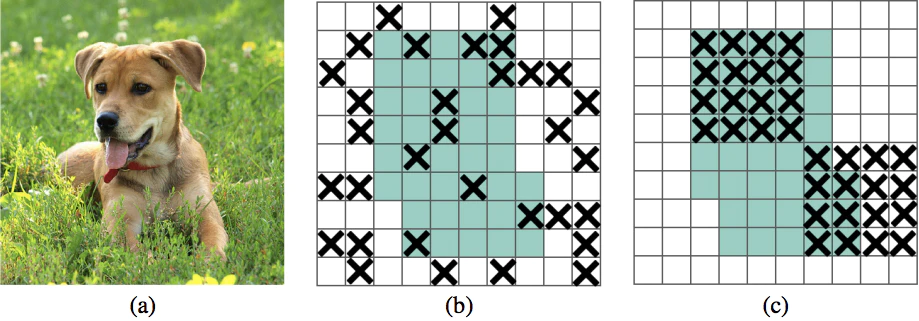
筆者らは(c)のように**「矩形領域をドロップする」**のを提案しています。
9-2. 先行研究
-
ピクセルをドロップ
- Variational Dropout
Dropoutを変分アプローチの元で再解釈、データに基づいてドロップ確率の決定が可能。 - Information Dropout
Information bottleneck の観点からDropoutを一般化。 - alpha Dropout
SELU とともに提案されたDropout。self-normalization の性質を担保するために入力のもとの平均と分散を保持しつつドロップする。 - guided Dropout
推論に強く寄与しているノードをドロップすることで、学習が不十分なノードの学習を集中的に行う。
- Variational Dropout
-
ピクセル以外をドロップ
- Spatial Dropout
チャネル全体を確率的にドロップ - Stocastic Depth
ResNetにおいてBlockを確率的にドロップ - DropPath
複数ブランチが生えているモデルに対してブランチのパスを確率的にドロップ
- Spatial Dropout
-
その他
- ZoneOut
RNNに特化した正則化手法。RNNのセル/出力の更新を行うことでRNNに対して正則化を行う。 - Shake-Shake
2つのブランチの forward/backward 双方で外乱を与えることで、擬似的にデータ拡張のような効果を与える。 - Shake Drop
Stocastic DepthのようなパスのスキップとShake-Shake のような外乱の双方をforward/backward 双方に入れている。
- ZoneOut
Cutoutは隣接画素に相関がある画像データに対して効果的な Data augumentation と知られている。DropBlock は Cutout と同様に中間層の特徴量に対して矩形領域 をドロップすることで、Dropoutより正則化効果が高まると考えた。 中間層の特徴量に対して Cutout的な事を行う。
9-3. DropBlock の特徴
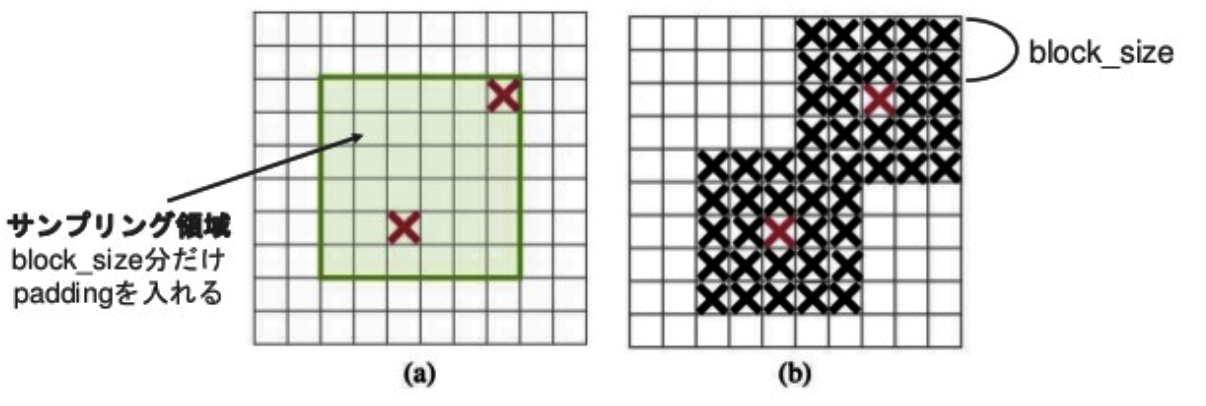
(a)ドロップする矩形領域の中心ユニットを 𝛾個サンプルし、
(b)サンプルした中心 ユニットの 分だけ広げマスクを作り、特徴量に掛け合わせる

- ドロップする矩形領域の中心ユニットはベルヌーイ分布からサンプリング。
- 最後にドロップした数に応じて値のスケールを合わせる。
- 推論時は特に何も行わない。
9-4. パラメータの詳細
- block_size:ドロップする矩形領域の幅
- block_size=1のとき、Dropoutと等しい
- block_sizeが特徴量の幅と等しいとき、SpatialDropoutと等しい
- keep_prob: ユニットの生存確率
- 最初は1にして目標の値まで徐々に下げていくと良い
- 筆者らは線形にスケジューリングしている
- 𝜸: ドロップするユニットの数
- 特徴量全体がマスクされないように調整したい。
- 筆者らは(keep_probが0.75〜0.95と見積もって)下記の式で𝛾を決定している。
\gamma = \frac{1 - keep_prob }{block_size^2} \frac{feat_size^2}{(feat_size - block_size + 1)^2}
$(feat_size - block_size + 1)^2$ は(a)の緑の領域の面積
9-5. Pros&Cons
-
Pros
-
- 画像のような隣接ユニットに強い相関をもつデータに対して効果的な正則化効果をもたらせる
-
- より広い領域の特徴量を見て推論できるようになる
-
- 手法が圧倒的にシンプルでわかりやすい
-
-
Cons
-
- パラメータ数が増えた
-
- チューニングが大変そう → 実験結果でパラメータによって精度が大きく左右しています
-
9-6. 実験
本論文では、実験を通して以下の事柄を確認している
- 既存手法と比較したDropBlockの有効性
- 最適なkeep_prob
- DropBlockの最適な適用箇所とblock_size
- DropBlockが効果的に画像情報を落とせているか
- より広域に特徴量をみているか
- 他のモデルでも学習可能か
- 一般物体認識以外のタスクでの効果
a. Object Detection
b. Semantic Segmentation
既存手法と比較したDropBlockの有効性
- ResNet-50をベースとしてImageNet Classificationを学習

- 既存の正則化手法よりも性能は上がっている。
- また、Cutoutなどのデータ拡張手 法よりも性能があがっている。
最適なkeep_prob
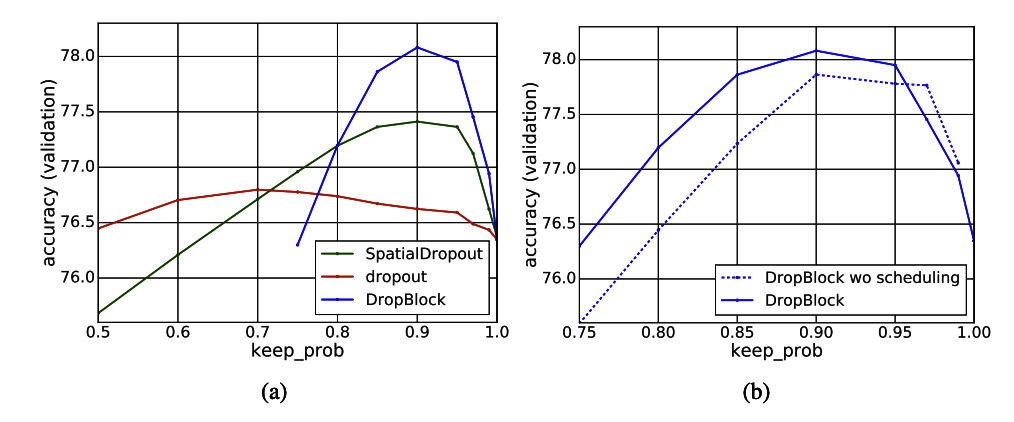
- keep_prob の変化でどのように精度が変化するかをImageNet Classifcationで評価。
- keep_probをうまく調整すれば精度は高くなるが、keep_probが小さすぎると精度がかなり落ちる。
- keep_probのスケジューリングを入れることも有益
DropBlockの最適な適用箇所とblock_size

- ImageNet Classification で block_size を変化させる。
- さらに ResNetの Group4 (最終ブロック)と Group 3&4 (最後から1・2番目ブロック) に適用した場合で比較。
- block_size は多少大きくても良さそう。
- Group 3&4 適用 + block_size=7 が最良。
DropBlockが効果的に画像情報を落とせているか
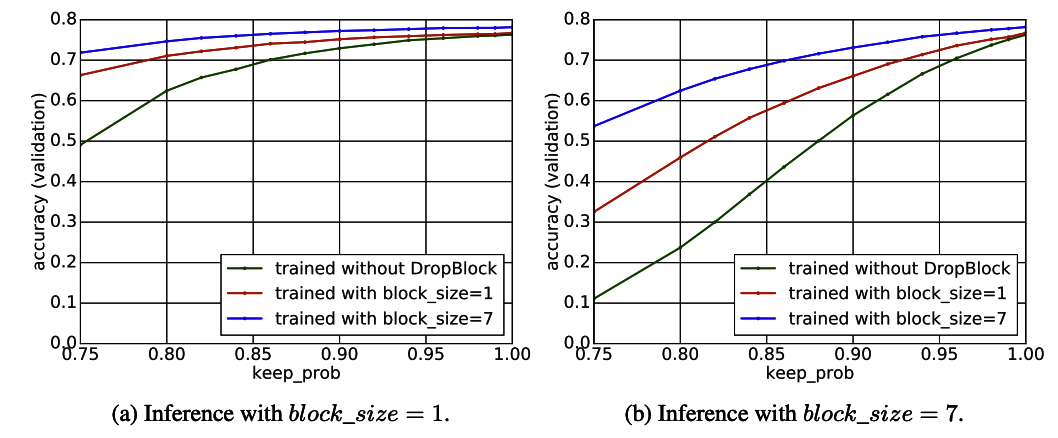
- 推論時にblock_size=1(左)とblock_size=7(右)をそれぞれ適用する。
- より効果的に情報を落とせていれば大きく性能は下る。
- block_size=7,keep_prob=0.9 で学習したモデルが最良。
より広域に特徴量をみているか

- 局所的な特徴量だけでなく、より幅広い特徴を元に推論できているか検証。
- ResNet-50の Conv5_3 に対してclass activation maps (CAM)を適用。
- DropBlockは より広い特徴量をみるようになっている
他のモデルでも学習可能か

- AmoebaNet にも同様にDropBlockを適用しImageNet Classificationで評価。
- 僅かではあるが性能向上している。
一般物体認識以外のタスクでの効果

- RetinaNetにDropBlockを適用しMS COCOで評価。
- block_size=5 のときが最良。

- ResNet-101 FPNモデルにDropBlockを適用し、PASCAL VOC2012で評価。
- fine-tuningには劣るがDropBlockを入れることで大きく性能向上。
- block_size=16 のときに最良。
- このように比較的 block_size が大きいときが最適な場合もある。
9-7. まとめ
- DropBlock は既存手法や、Cutout などよりも性能向上させている
- keep_prob や block_size は、タスクやモデルに依存し性能を大幅に上下させる
- block_size は小さすぎると正則化効果薄く keep_prob が小さいと学習しない。
- block_size は少し大きめにして、最適な keep_prob を探すと良さそう。
- DropBlock の自動パラメータチューニングが必要そう。
10. Cross-Iteration Batch Normalization
10-1. バッチ正規化の問題
- バッチ正規化のよく知られた問題:小さなミニバッチサイズの場合に有効性が著しく低下すること
- ミニバッチに含まれている例が少ない場合、正規化が定義されている統計は、トレーニングの反復中にそこから確実に推定できない。
10-2. Cross-Iteration Batch Normalization(CBN)の概要
- バッチ正規化の問題に対処するために
CBNでは、複数の最近の反復サンプルを利用して、推定品質を向上させる。 - 複数の反復にわたって統計を計算する際の課題
ネットワークの重みの変化により、異なる反復からのネットワークアクティベーションが互いに比較できないこと - 解決方法
よって、テーラー多項式に基づいて提案された手法を介してネットワークの重みの変化を補正し、統計を正確に推定し、バッチ正規化を効果的に適用できるようにする。 - 小さなミニバッチサイズでのオブジェクト検出と画像分類では
CBNは、提案された補正手法を使用せずに、元のバッチ正規化と以前の反復の統計の直接計算よりも優れていることが判明した。
11. YOLOv4
11-1. 概要
YOLOv4 では、元々のYOLOの作者である Joseph Redmon氏は著者ではありません。(Jeseph Redmon氏は研究の軍事利用やプライバシーへの懸念から研究を辞めてしまっています。)
元々YOLOv3の著者実装のある darknet をフォークして開発を進めていた Alexey Bochkovskiy氏がfirst authorになっています。
github:YOLOv4
https://github.com/AlexeyAB/darknet
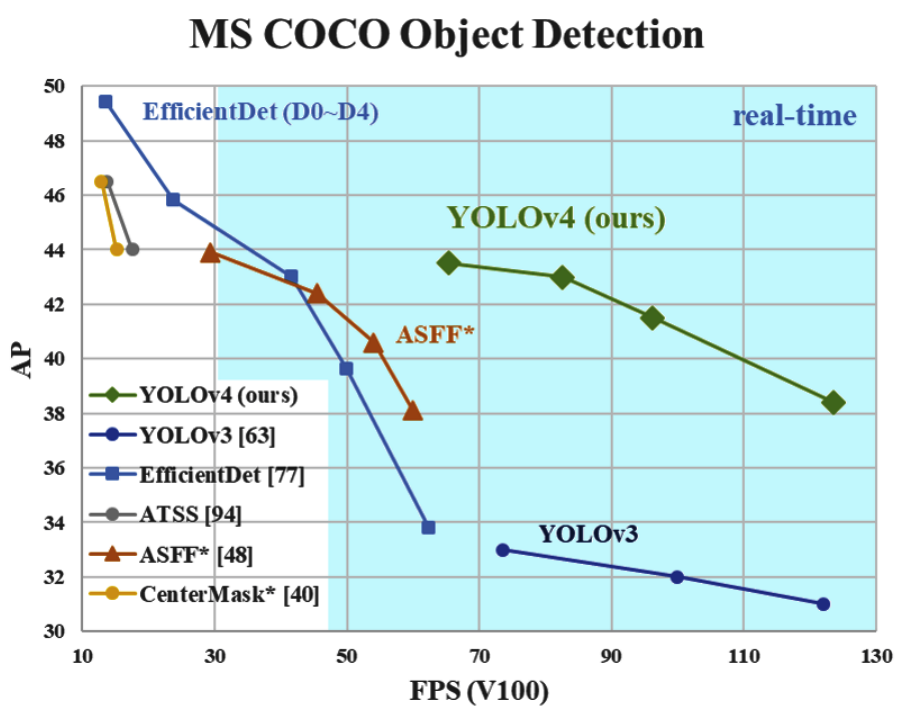
- 既存の物体認識モデルの考え方から離れ、シンプルな手法を提案
- YOLOv3 や M2Det より速くて精度のいいモデルもできる one-stage 物体認識モデルを達成。
ざっと
- モデルアーキテクチャ
- 学習上の工夫を表す Bag of freebies
- 精度改善上の工夫を表す Bag of specials
の3つに分かれます
Bag of specials は「少ないコスト(推論時時間や計算リソース)で大きな精度向上ができるもの」と説明されています。
11-2. 最近のネットワークアーキテクチャの分類
物体認識のアーキテクチャは大きく2つに分かれます。
- 画像の特徴抽出の役割を持つ backbone
- クラス分類やbbox(物体を囲む四角形)の位置を予測する head
backboneは例えばResNetのような画像のクラス分類でよく使われるようなモデルが一般的に採用されます。
headの部分はいわいる大きく one-stage か two-stage かに分かれます。
基本的に one-stageは速度重視、two-stageは精度重視の側面があり、最近では、one-stage系列の発展がよく見られます。
さらに、最近ではこの head と backbone の中に、neck と呼ばれるレイヤーが入ることがあります。
これは backbone から受けた特徴マップを操作して、よりよい特徴量を生み出します。
M2Det もこの neck のアーキテクチャを提案した手法だし、
精度的に SoTA といえる EfficientDet もこの neck をアップデートした手法です。
図4-2-1
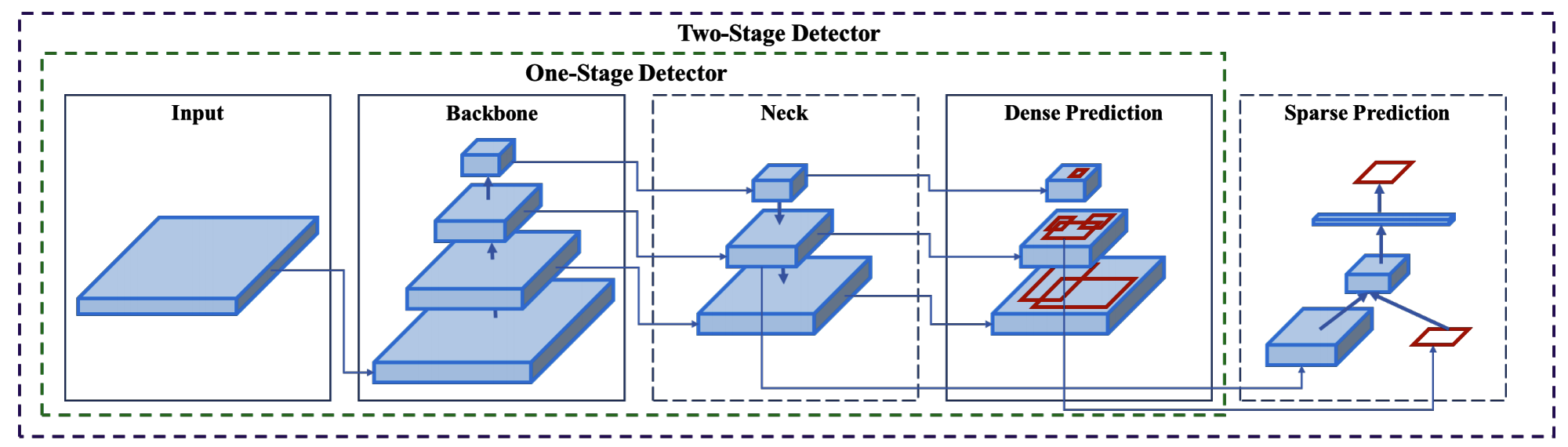
物体認識は小さい物体や大きい物体、単純な物体や複雑な物体など様々な物体を認識する必要があり、複数サイズの受容野を扱うことが有効に機能すると考えられます。
11-3. YOLOv4 のネットワークアーキテクチャ概要
- Backbone: CSPDarknet53
- Neck: SPP、PAN
- Head: YOLOv3
YOLOv4では backbone にCSPDarkenet53を採用しています。
neck には
- SPP (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition) というブロックを追加
- PAN(Path Aggregation Network for Instance Segmentation) という機構を導入
Head としては YOLOv3 と同等のものを採用しています。
11-4. neck の詳細
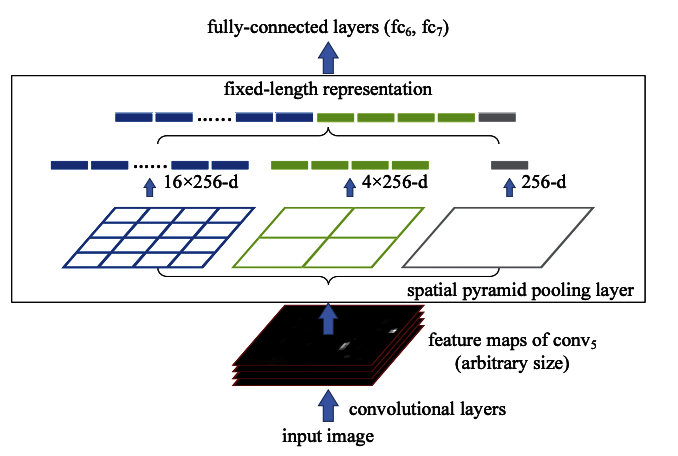
11-4-1. SPP (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
複数サイズのwindowでプーリングして特徴量を作ります。
これにより、受容野を広げることが可能になります。
11-4-2. PAN(Path Aggregation Network for Instance Segmentation)

11-5. 学習・速度改善の工夫
- 活性関数 Mish の採用
- CIoU-loss の採用
- DIoU-NMS の採用
- データオーグメンテーション
CutMix、Mosaic data augmentation、Class label smoothing、Self-Adversarial Training を採用 - 正則化:DropBlock regularization を採用
- 正規化:CmBN を採用
12. YOLOv5
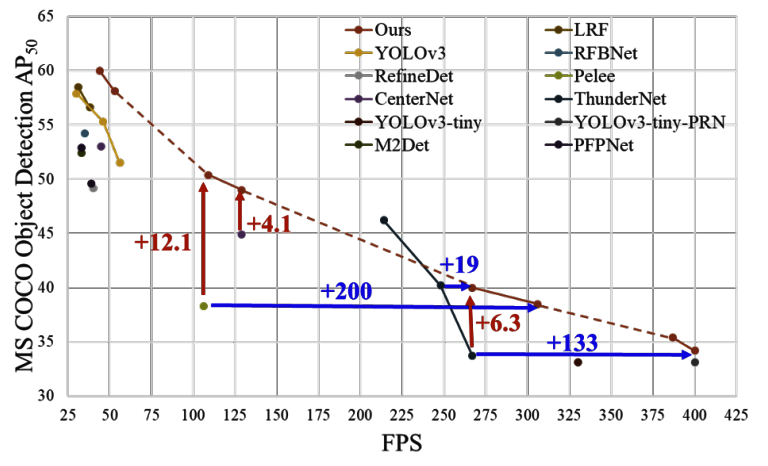
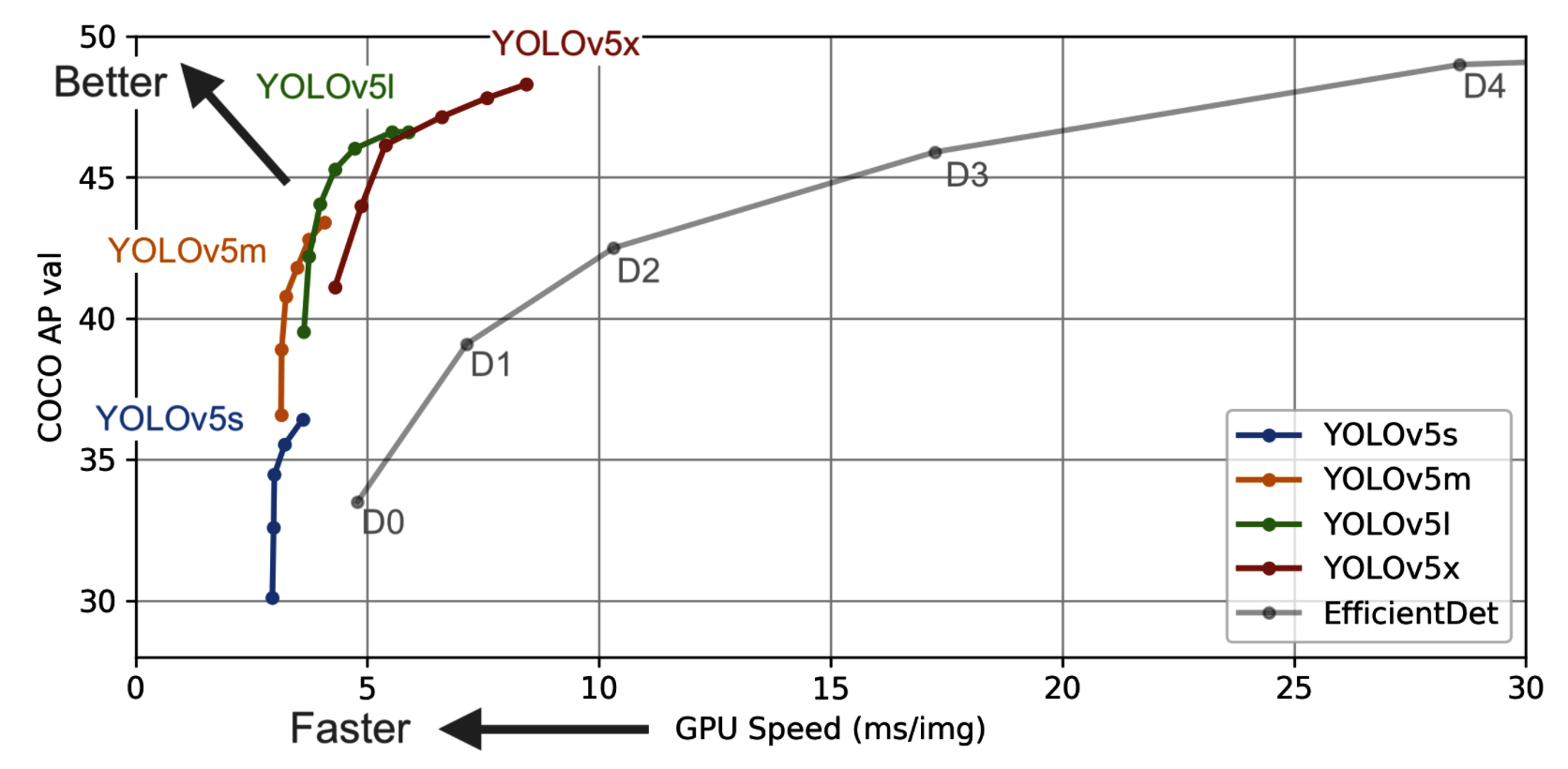
YOLOv5は、以前のすべてのバージョンよりも優れており、より高いFPSでEfficientDet APに接近している。以下のグラフ参照。
...
TODO:加筆準備中
参考文献
[1] Feature Pyramid Networks for Object Detection,2016
https://arxiv.org/abs/1612.03144
[2] Focal Loss for Dense Object Detection,2017
https://arxiv.org/abs/1708.02002
[3] M2Det: A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network,2018
https://arxiv.org/abs/1811.04533
[4] Understanding Feature Pyramid Networks for object detection (FPN)
https://medium.com/@jonathan_hui/understanding-feature-pyramid-networks-for-object-detection-fpn-45b227b9106c
[5] CSPNet: A new backbone that can enhance learning capability of CNN
https://arxiv.org/pdf/1911.11929
[6] Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
https://arxiv.org/pdf/1406.4729
[7] Path Aggregation Network for Instance Segmentation
https://arxiv.org/pdf/1803.01534
[8] Mish: A Self Regularized Non-Monotonic Neural Activation Function
https://arxiv.org/pdf/1908.08681
[9] UnitBox: An Advanced Object Detection Network
https://arxiv.org/abs/1608.01471
[10] Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
https://arxiv.org/abs/1911.08287
[11] Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
https://arxiv.org/abs/1902.09630
[12] Improving Object Detection With One Line of Code
https://arxiv.org/pdf/1704.04503
[13] CutMix: Regularization Strategy to Train Strong Classifiers
with Localizable Features
https://arxiv.org/pdf/1905.04899
[14] Data Augmentation Strategies Deployed in YOLOv4
https://towardsdatascience.com/data-augmentation-in-yolov4-c16bd22b2617
[15] DropBlock: A regularization method for convolutional networks
https://arxiv.org/abs/1810.12890
[16] Cross-Iteration Batch Normalization
https://arxiv.org/abs/2002.05712
[17] YOLOv4: Optimal Speed and Accuracy of Object Detection
https://arxiv.org/abs/2004.10934
[18] You Only Look Once: Unified, Real-Time Object Detection
https://arxiv.org/abs/1506.02640
[19] YOLOv5 is Here!
https://towardsdatascience.com/yolo-v5-is-here-b668ce2a4908
[20] github実装 ultralytics/yolov5
https://github.com/ultralytics/yolov5