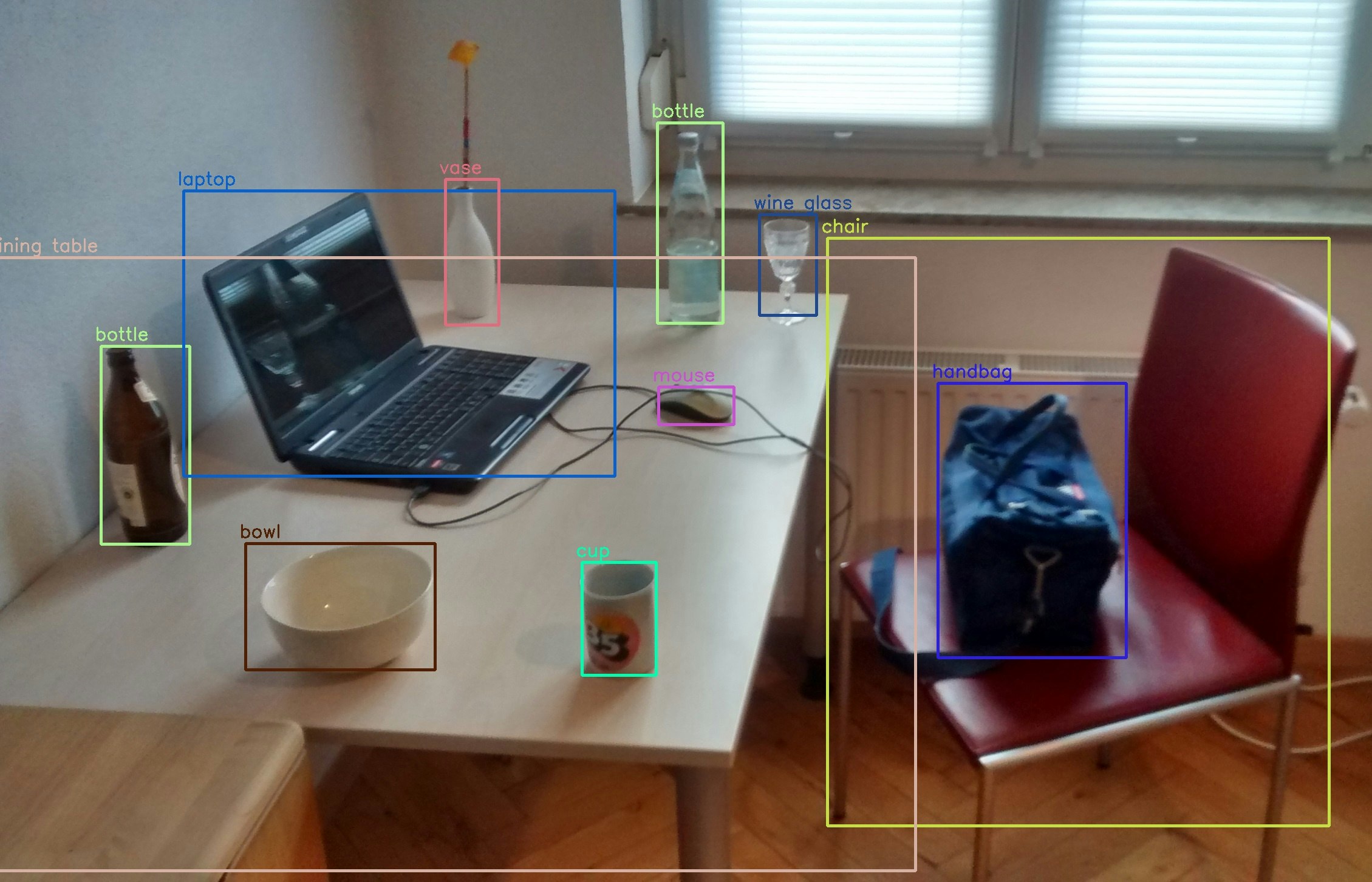
Object Detection(物体認識)モデルに関する指標である mAP (mean Average Precision) について考える。
概要
- Object Detection モデルの評価指標として使われる mAP について、定義とか実装を考えたり調べたりしたよ
- 実際に実装してみたよ
- mAP に似た指標についても考えてみたよ
- 一般的な Average Precision と Object Detection における Average Precision は全く別物なので、混同してはいけないよ
Object Detection とは
Object Detection は、1枚の画像の中から目的となる対象物の位置を Bounding Box(四角の枠)として予測するものである。一般的な Classification, Regression などの Machine Learning とは以下の点で趣が異なる。
- 場所を指し示す Bounding Box も(出来る限り正確に)予測しなければならない。
- 画像の中に対象となる物体が何個あるか分からない。無いかもしれない。
- 認識する対象物は1種類の場合もあるが、多くの場合は複数種類を一度に予測する。
難しいことだなぁと思う。(小並感)
 画像認識の例[^1]
画像認識の例[^1]
mAP とは
Object Detection は一般的な Machine Learning とは趣が異なるので、この Object Detection の「精度」を評価するためには、一般的な metric とは異なるものが必要である。この Object Detection の metric の中で最もメジャーなものが mAP (mean Average Precision) だと思う。
mAP とはどんなものなのか、その定義を探したのだが、これ!という定義は見つからない(探し方が悪いのかもしれない)。ただし解説している記事は沢山見つかる。その中でも最も親切で分かりやすかったのが、github.com/rafaelpadilla/Object-Detection-Metrics である。私がグダグダ述べるより、ここを見て頂いた方が何万倍も早い。これ以上の解説は見つかっていない。
 mAP を計算する上で考えるケースの例[^2]
mAP を計算する上で考えるケースの例[^2]
IoU (Intersection of Union) とは
話を進める前に、IoU について述べなくてはならない。これも github.com/rafaelpadilla/Object-Detection-Metrics にて丁寧に解説されている。
Ground Truth(正解)と Prediction1(予測)の2つの Bounding Box があった時に、ピッタリ一致することが理想だが、大抵ちょっとはズレる。あまりにもズレてたら「予測が正しい」とは言えない。なので「どれだけズレてますか」というのを数値にしたもの。
要するに、IoU = (2つの Bouding Box が重なってる部分の面積)/(2つの Bouding Box を合体させた形の面積)である。この値がある閾値以上なら予測は正しいとする、というように使う。$1.0$ の場合がピッタリ一致、$0.0$ の場合は重なってない、ということになる。
 IoU の計算式の説明[^2]
IoU の計算式の説明[^2]
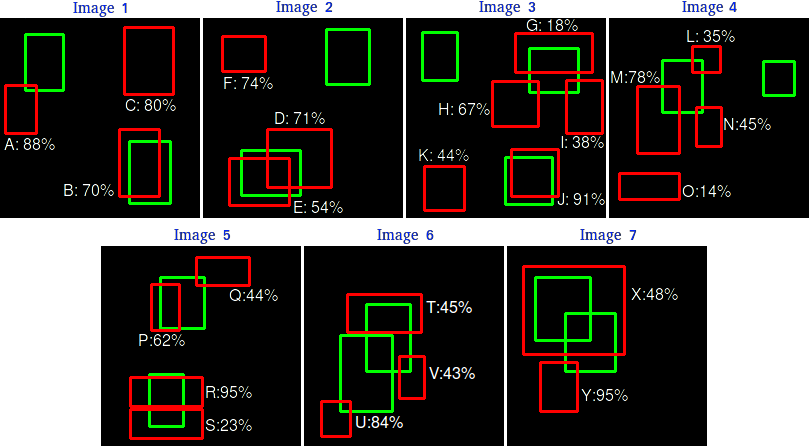
mAP についての疑問
で、たぶん github.com/rafaelpadilla/Object-Detection-Metrics の解説は正しい。どの解説記事を見ても同じようなことが述べられている。でも、この解説(定義)では不確かな点が残る。不十分だと思う(天邪鬼)。具体的には以下のケースでどう判断するかが不明瞭である。

- 左は、ひとつの Ground Truth に対して、複数の Prediction が共に高い IoU で存在する場合。Prediction 同士の IoU はそれほど高くない。
- 右は、複数の Ground Truth があまりにも重なっているため、ひとつの Prediction がどちらの Ground Truth も表しているように見える場合。
大抵の Object Detection モデルは、Machine Learning モデルで予測(出力)した Bounding Box を、NMS (Non Maximum Suppression)2 という手法を使い、あまりにも高い IoU を持つものが無いように削除している。
しかしそれであっても、左のケースは Prediction 同士の IoU がそれほど高くない場合が考えられるので、実際にあり得る形である(ひとつの Prediction が Ground Truth のちょうど上半分、もうひとつの Prediction が Ground Truth のちょうど下半分を覆うような、図に表したような場合)。
右のケースは、例えば写真から人物を判定する場合に、いっぱい人がいて、ほぼ重なって写っている場合が相当する。なので、こちらも十分にあり得る形である。
要するに私が気にしているのは、Ground Truth と Prediction は、1:1 なのか 1:N なのか N:1 それとも実は N:N なのか、ということである。
実装による解決
普通に考えると、当たり前のように Ground Truth と Prediction は 1:1 なのだと思う。当たり前過ぎてサラっと書かれているだけで、私が見逃しているだけかもしれない。だって 1:1 じゃないとしたら、ひとつの Ground Truth に対して何十個も Prediction 作って「ウェーイ、いっぱい正解したぜー」って言って、そのモデルは実際には全然使い物にならん、ってことがありそうじゃん。
ってことで、私が見逃しているという可能性が大きいとしても、実際の実装が以下のようになっていたら 1:1 なのが確認できるだろうなぁと考えた。
- すべての画像に対して以下の処理を行う
- Ground Truth と Prediction それぞれのリストを持つ
- Prediction を Confidence Score の高い順にソートする
- Ground Truth と Prediction それぞれのリストを認識対象の物体の種類(カテゴリ)に分割する
- すべてのカテゴリに対して以下の処理を行う
- すべての Ground Truth vs Prediction の組み合わせに対する IoU を計算する
- Prediction の Confidence Score が高い順に以下の処理を行う
- 最も IoU が高い Ground Truth との IoU が閾値を超えている場合
- その Prediction は TP (True-Positive) とカウント
- その Ground Truth をリストから除外する
- Ground Truth が残っていない、もしくはどの Ground Truth との IoU も閾値を超えない場合
- その Prediction は FP (False-Positive) とカウント
- 最も IoU が高い Ground Truth との IoU が閾値を超えている場合
- どの Prediction とも IoU が高くなくて、もしくは Prediction の数が少なくて残ってしまった Ground Truth は FN (False-Negative) とカウント
- すべての画像・カテゴリの結果を集めて、mAP を計算する
ここで Confidence Score が初めて出てきたが、これは Object Detection における decision function のようなもので、その予測結果が確からしい度合いを表すスコアである。
TP, FP, FN に関しては、後述。
実装の調査
github を見ても、mAP の実装はたくさんある。そこから良さげなものを選んでソースコードを読んでみた。
読むに当たって、次の気になるポイントについても調べた。
- Prediction があるのに Ground Truth が無いカテゴリをちゃんと考えているか
- Ground Truth があるのに Prediction が無いカテゴリをちゃんと考えているか
- カテゴリは一般的に整数で表現されるが、その整数の値が飛び飛びの場合もちゃんと扱えているか
調べたものは以下。
-
github.com/cocodataset/cocoapi
- Object Detection と言ったら COCO、で有名な COCO (Common Objects in COntext) プロジェクトの公式 repository
- データセットには毎度お世話になっているが、評価ツールも提供している
- Object Detection だけではなく、Object Segmentation, Image Recognition in context も取り扱っている
- Object Segmentation: 画像に写っている物体の(任意の)形に従って画像を分割する
- Image Recognition in context: 画像を説明する文章(キャプション)を生成する
- Object Detection と言ったら COCO、で有名な COCO (Common Objects in COntext) プロジェクトの公式 repository
-
github.com/rafaelpadilla/Object-Detection-Metrics
- 解説を絶賛してきたが、実装もある
-
github.com/LeMuecke/mapcalc
- PyPIに登録されている(pipでインストールできる)mapcalc の repository
-
github.com/bes-dev/mean_average_precision
- multiprocessing で並列化・高速化を狙っている
と書いてはみたものの、COCO の実装は Mac で動かなかったし、コードが汚くて正直読む気がしないので、実際に読んだのは後半の3つ。そんなに真面目に読んでないので、間違えていたらごめんなさい。
-
github.com/LeMuecke/mapcalc
- Ground Truth : Prediction = 1 : 1
- COCO 形式の mAP じゃなくて、PASCAL VOC 形式の mAP にしか対応してない
- Prediction 毎に最も IoU が高い Ground Truth しか見てない、即ち
- ある Ground Truth に対して、IoU は比較的低いが、高い Confidence Score を持つ Prediction があっても、それは無視
- ある Prediction に対して、1番 IoU が高い Ground Truth が他の Prediction に取られてしまった場合に、2番目以降に閾値より高い IoU を持つ Ground Truth があっても、それは無視
- Ground Truth のカテゴリしか見ていないので、Prediction にしか存在しないカテゴリを無視している
-
bes-dev/mean_average_precision
- Ground Truth : Prediction = 1 : 1
- Ground Truth に対する
crowdフラグとdifficultフラグの実装がある-
crowdは、ひとつの Ground Truth に対して Prediction が重なっていたら、無視する(群衆写真に対する対策) -
difficultは、それはそもそも難しいので、端から無視
-
- PASCAL VOC 形式の mAP「にも」対応
- Prediction に対して IoU が最も高い Ground Truth しか見ない
- multiprocessing の実装がとてもしっかりしている
- mAP 以外の metric にも対応できるよう準備されているが、mAP 以外は未実装
- ツールに対してカテゴリをカテゴリ数とでしか与えられないため、カテゴリの値が 0 から連続した値の場合しか対応できず、飛び飛びの場合に対応できない
-
rafaelpadilla/Object-Detection-Metrics
- Ground Truth : Prediction = 1 : 1
- 特に問題は見当たらない
- for loop を多用しているので、速度は遅そう?
- 実装の癖が強い!(千鳥風に)
ということで、結論として Ground Truth : Prediction = 1 : 1 で Final Answer だろう。
実装してみた
実装を調べて、疑問点に対しては納得はしたものの、満足できる実装は無かったので、自分で作ってみた。車輪の再発明は百も承知。
特徴(自慢)
- 読み込むべき Ground Truth のファイル、Prediction のファイルを JSON Lines フォーマットとした
- どの実装も JSON ファイルを一気に読み込んでるが、絶対に JSON Lines の方が良いと思う
- エラーが発生した場合の対処、書き出す・読み込む際の必要メモリ
- human friendly.
- みんなもっと JSON Lines 使おうぜ
- それだけだとアレなので、COCO形式の JSON から、対応する JSON Lines に変換する Python ツールを作成
- JSON Lines の中身は、COCO 形式に準拠
- どの実装も JSON ファイルを一気に読み込んでるが、絶対に JSON Lines の方が良いと思う
- ファイルの読み込みに際し、pydantic でフォーマットのチェックを行う
- pydantic、最高だよ?
- 後日 pydantic の記事を書こうと思う
- Ground Truth vs Prediction の IoU 計算を、numpy の3次元配列を使って一気に
- 上記で作った IoU の numpy 配列から、True-Positive を直接計算
- ここはあんまり上手くないかな
- AveragePrecision の計算に独自アルゴリズムを採用
- たぶん高速だし、たぶん合っていると思う
- mean Average Precision の "mean" として、micro, macro, weighted を実装
- 後述
- Type Hinting を頑張っている
- コメントとか docstring とか頑張って書いたので、sphinx に優しい
- Python ツールとしても Python library としても動くよ
- 上記3つらへんに関しても後日、記事に書きたい
使ってくれとはあまり思ってませんが、どなたかの何らかの参考になれば。
で、mAP って何なのさ
今まで肝心の説明を全部 github.com/rafaelpadilla/Object-Detection-Metrics にブン投げちゃってたけど、ちょっとだけ引用しながら説明します。(それでも引用するけど)
上に挙げたアルゴリズムで、IoU や Confidence Score を使って各 Prediction, Ground Truth に対して TP (True-Positive), FP (False-Positive), FN (False-Negative) が判断できる。TN (True-Negative) は Object Detection の場合、存在しない。
- TP, FP, FN, TN の説明3(一部表記を揃える)
- True Positive (TP): A correct detection. Prediction with IOU ≥ threshold
- False Positive (FP): A wrong detection. Prediction with IOU < threshold
- False Negative (FN): A ground truth not detected
- True Negative (TN): Does not apply. It would represent a corrected mis-detection. In the object detection task there are many possible bounding boxes that should not be detected within an image. Thus, TN would be all possible bounding boxes that were correctly not detected (so many possible boxes within an image). That's why it is not used by the metrics.
FN は mAP では使わないので、ここからは Prediction(TP と FP)(と Ground Truth の個数)だけを考える。
次に、各カテゴリ毎に全部の画像の情報(TP, FP, Ground Truth の個数)を集め、画像の枠を超えて Prediction を Confidence Score 順に並べる。すると、「最も Confidence Score が高い Prediction から1個だけ評価した場合」「最も Confidence Score が高い Prediction から2個だけ評価した場合」・・・と、順々に Precision, Recall が計算できる。
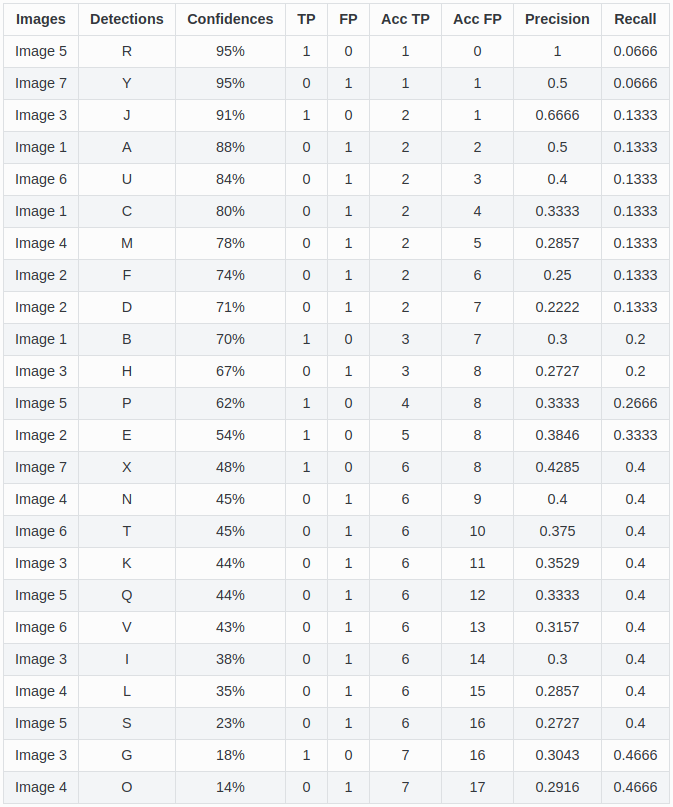 あるカテゴリの Prediction を表で表した例[^2]
あるカテゴリの Prediction を表で表した例[^2]
この場合の Precision, Recall の計算式は、一般的な Precision, Recall と全く同じ。
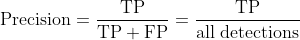
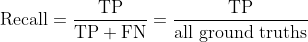 Precision と Recall の計算式[^2]
Precision と Recall の計算式[^2]
この場合の TP は、評価する Prediction の中での TP の数を指す(上の表における "AccTP"(累積TP数)に相当)。なので TP の値は増えていくことはあっても絶対に減らない。(重要)
すると Precision は、評価する Prediction の数が増える毎に、分母の "all detections" は確実に増えていくが、TP (AccTP) は時々増えるだけなので、不正解だとガクンと減り、正解だとチョロっと増える。
一方 Recall は、"all ground truths" は常に同じ値であるが、TP は同じか増えるだけなので、絶対に減らない。(重要)
こうして作った Precision と Recall を用いて、x軸を Recall、y軸に Precision を取った Precision-Recall Curve を描く。
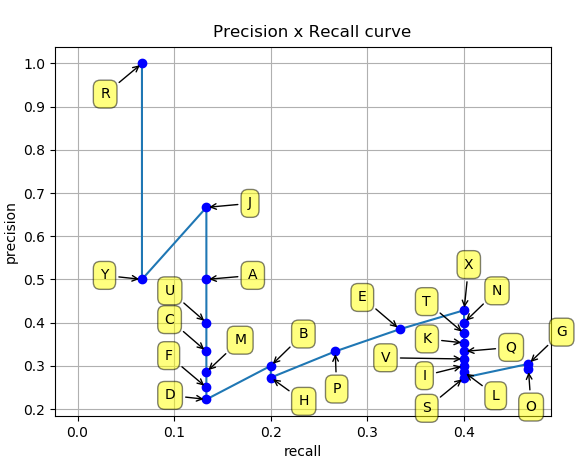 Precision-Recall Curve の例[^2]
Precision-Recall Curve の例[^2]
こうして作った Precision-Recall Curve の下の領域の面積(AUC: Area Under the Curve)が、"Average Precision" である。この面積を馬鹿正直に計算するのは(一般的に)とても大変なので、右上に飛び出した点から左に向かって四角形を描き、その面積を "Average Precision" とする。(言葉で説明するのは難しいが、図を見れば一発で分かる)
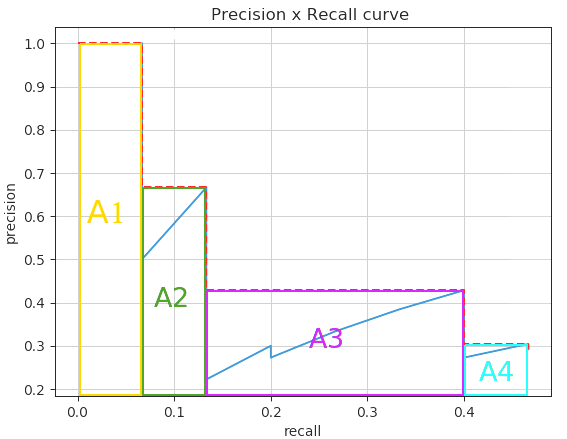 Average Precisionで計算する面積を表したもの[^2]
(上図において、A1の面積+A2の面積+A3の面積+A4の面積が Average Precision)
Average Precisionで計算する面積を表したもの[^2]
(上図において、A1の面積+A2の面積+A3の面積+A4の面積が Average Precision)
各カテゴリに対して Average Precision (AP) を計算し、全部集めて平均したものが、Object Detection モデルの評価指標となる mean Average Precision (mAP)。
この AP は、TP を判断したときの IoU の閾値によって値が変化する。IoU の閾値が低い場合には多くの Prediction が TP になり得るので、AP, mAP の値は大きくなる。IoU の閾値が高い場合には、Prediction が TP になりにくいので、AP, mAP の値は小さくなる。
例えば IoU の閾値を $0.95$ とする場合は、Prediction と Ground Truth がほぼ完全に一致した場合でないと TP と判断されないので、AP, mAP の値が非常に小さい。
IoU の閾値を $0.5$ とした場合の mAPを $mAP^{0.50}$、IoU の閾値を $0.75$ とした場合の mAP を $mAP^{0.75}$ と表記する。
また、単純に $mAP$ と表記する場合は、IoU の閾値を $0.5$ から $0.95$ まで $0.05$ 刻みで増やしていき、それらをすべて平均した値を指す($mAP^{0.50:0.95:0.05}$ 的に表記する場合もある)。この素晴らしく面倒くさい $mAP$ が、COCO における最重要指標となっている。
mAR って何なのさ
mean Average Precision (mAP) があるなら、mean Average Recall (mAR) もあるはずだ、って、実際にある。COCO では指標の一つとして採用されている。
 COCO が採用する metric の一覧[^5]
COCO が採用する metric の一覧[^5]
じゃあこれはどうやって計算するかというと、どこにも定義や解説がない。上記のページにも「採用してるよ」ってだけあって、どうやって計算するか全く情報がない。
安直に想像すると、Precision-Recall Curve の AUC (Area Under the Curve) が Average Precision だったら、Recall-Precision Curve の AUC が Average Recall なんじゃね、って。そう思うじゃん?
ちょっと考えれば小学生でも分かるけど、その AR って AP と全く同じ値なんだよね。だって x軸と y軸を入れ替えただけだから、y = x の直線を軸に線対称にひっくり返しただけだから、面積が変わるはずない。
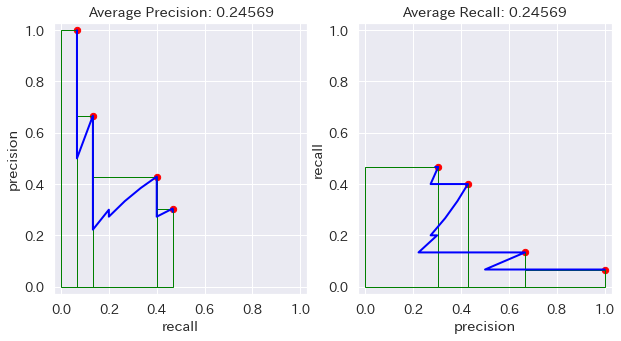
github.com/rafaelpadilla/Object-Detection-Metrics の例で計算した場合
特殊な場合も色々試してみたけど、どうやったって同じものは同じ。
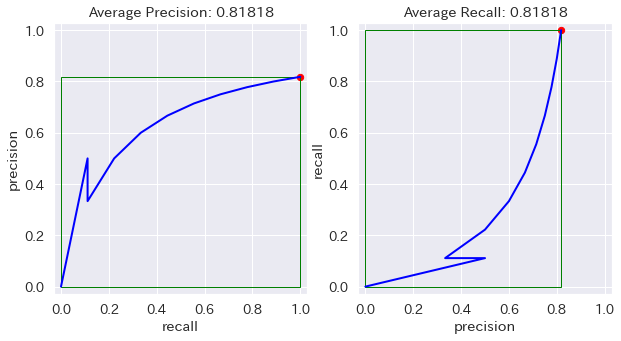
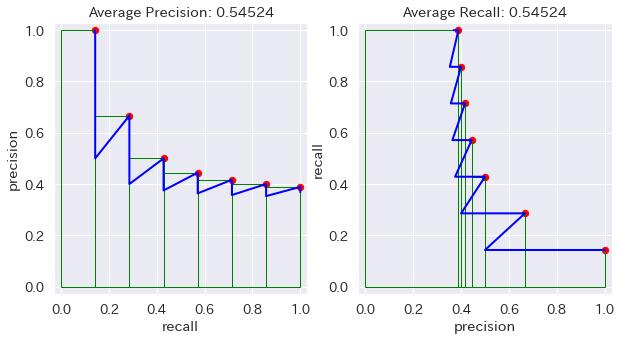
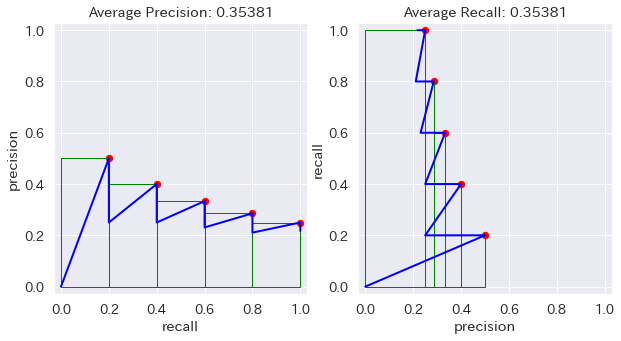
COCOの定義を見ると、maxdet(評価する Prediction の最大数)が変数としてあるみたいなので、それを入れてやってみたけど、maxdet は尻尾を切り落とすだけなんで、やっぱり変わらない。
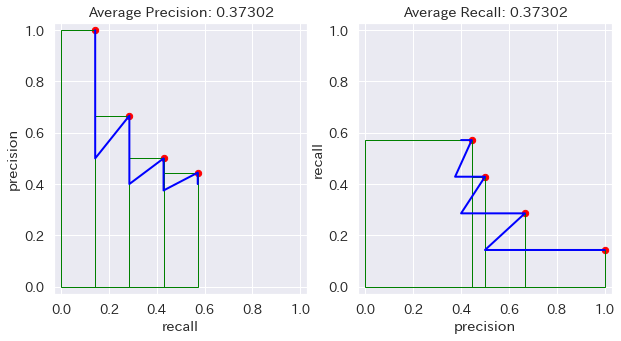
ここらへんが COCO しか mAR って言ってない理由なのかもしれない。
(蛇足) mAF どうでしょう
mean Average Precision と mean Average Recall があるとしたら、Precision と Recall の調和平均である F1-score のように、mean Average F1-score (mAF) だってあっても良いはずじゃん?
まぁ、やればできるけど、無意味だ。
そもそも mAP と mAR が同じって問題も解決してないのに。
(mAP == mAR なら、mAP == mAR == mAF)
理屈から考えても、Average Precision は面積を計算するのに Precision と Recall を掛けちゃっているので、Precision と名前ではあるが意味合い的には F1-score に近い。
なので、mAP だけで十分じゃね?ってなってるのかもしれない。(想像)
一般的な AP との違い
Object Detection じゃなくても、Precision-Recall Curve4 とか Average Precision とか使う場合があるし、実際に scikit-learn には関数が用意されている。
- sklearn.metrics.precision_recall_curve
- sklearn.metrics.average_precision_score
- sklearn.metrics.PrecisionRecallDisplay
最初、これを使って Average Precision を計算して、すっかり出来た気になってたが、結果を見ると全然変な値が出てくるし、そもそもエラーが頻発する。
よくよく考えると、名前は全く同じで、表面上に見える計算式も全く同じだけど、前提条件が全く違う。 一般的な Average Precision と Object Detection における Average Precision は完全に別物です。混同してはいけません。 要するに Object Detection では上記の scikit-learn の関数は使えない(涙)。
Object Detection における Precision-Recall curve の各点は、IoU の閾値は一定だが計算する対象(Prediction)の数を変化させた時の Precision と Recall の値である。
しかし一般的な Precision-Recall curve の各点は、decision function に対する閾値(Object Detection においては Confidence Score に設ける閾値5に相当)を変化させた時の Precision と Recall の値である。この時にデータの数は変化などさせていない。
名前も意味も計算式も全く同じだが、各点の前提条件が全然違うのである。だからこの両者が同じであろう筈がない。
そもそも API として、scikit-learn の average_precision_score() は decision function の値と各 Prediction に対する Ground Truth の値(0 or 1)しか必要としない。だって閾値を(勝手に)決めれば、各 Prediction が TP,FP,FN,TN のどれかは内部で判断できる。そして与えられる Prediction の他のデータなど AP の計算には関係ない。
それに対して Object Detection の Average Precision は、各 Prediction に対応している Ground Truth の他に、考慮しなければならない Ground Truth (FN) が存在する可能性がある。なので "all ground truths" は Prediction とは別に与えられなければならない。さらに decision function (Confidence Score) の値は Object Detection における AP に関係しない!
正直、混乱してました。何も考えずに実装するって怖いですね。(白目)
"mean" について
scikit-learn の average_precision_score() は(average_precision_score() に限らず)当然のように multi-label の際の平均の取り方を "micro", "macro", "weighted" から選べる。("samples" は敢えて無視)
- "micro": 各 label の TP, FP, FN を合計して計算する
- "macro": AP なら、各 label の AP を単純に平均する
- "weighted": "macro" の平均を、Ground Truth の数を重みとした重み付き平均にする
上で説明した Object Detection の mean Average Precision の "mean" は、各カテゴリの Average Precision を「平均する」という箇所に相当する。
上の解説では「単純に平均する」って言っちゃったんで、これは "macro" ですね。
どの解説・実装を見ても "macro" なんで、まいっかなとは思いつつ、結果を見るとせめて "weighted" は欲しいなぁと。
だから実装したよ!全部!(ドヤ)
平均としては、上記の各カテゴリの AP の平均の他に、$mAP$ の計算で IoU 閾値を $0.50$ から $0.05$ 刻みで $0.95$ まで計算させたものの平均、ってのをやってるけど、これは流石に普通の「平均」一択だろう。
最後に
とまぁ長々と述べてきましたが、実際に実装して計算した結果は、COCO おひさるライブラリで計算した結果(github にアップされてるサンプル結果)と全然違うんだよなぁ。だから、実装 or 上の考察が全然違う可能性もあるよなぁ・・・
COCOの実装、読まないとアカンかなぁ・・・
-
この記事の中では "Prediction" という表記で統一していますが、"Detection" や "Detected Object" とも言います("Detection" だと Object Detection と紛らわしい。でも "Prediction" も Precision と紛らわしい・・・)。適宜、脳内変換をお願いします。 ↩
-
余談だが、Precision-Recall curve と ROC (Receiver Operating Characteristic) curve の違いは、PR curve が x軸に Recall ($\frac{TP}{TP+FN}$) 、y軸に Precision ($\frac{TP}{TP+FP}$) を取るものなのに対し、ROC curve は x軸に FPR (False Positive Rate: $\frac{FP}{FP+TN}$)、y軸に TPR (True Positive Rate = Recall) を取るものであるということである。一般的に PR curve は左下にヘコみ、ROC curve は左上にふくらむ。AUC-PR は decision function に対する閾値を変化させた時の総合的なモデルの正確さを測りたい場合に用い、AUC-ROC は decision function に対する閾値を変化させた時の総合的なモデルのリバレッジ(リスク(FPR)に対する利潤(TPR))を測りたい場合に用いる。語弊を恐れずに言えば、AUC-PR は Precision(予測が正確かどうか)が重要なケースにおいて総合的な Precision (Average Precision) を評価したい場合に用い、AUC-ROC は Recall(予測がどれだけ正解をカバーしているか)が重要なケースにおいて総合的な Recall (Average Recall) を評価したい場合に用いる。残念ながら Object Detection に TN (True-Negative) は存在しないので、Object Detection に ROC は適用できない。AUC-PR と AUC-ROC の関係については、The Relationship Between Precision-Recall and ROC Curves に詳しい。 ↩
-
Object Detection において、Confidence Score に対する閾値は mAP の計算の外側、そもそもモデルがその Prediction を出力するか否かという判断に使われている。だから mAP の計算は既に Confidence Score の閾値が適用された後の予測結果(Prediction)だけに行われるものであり、mAP の計算において Conidence Score の閾値は利用しない。 ↩