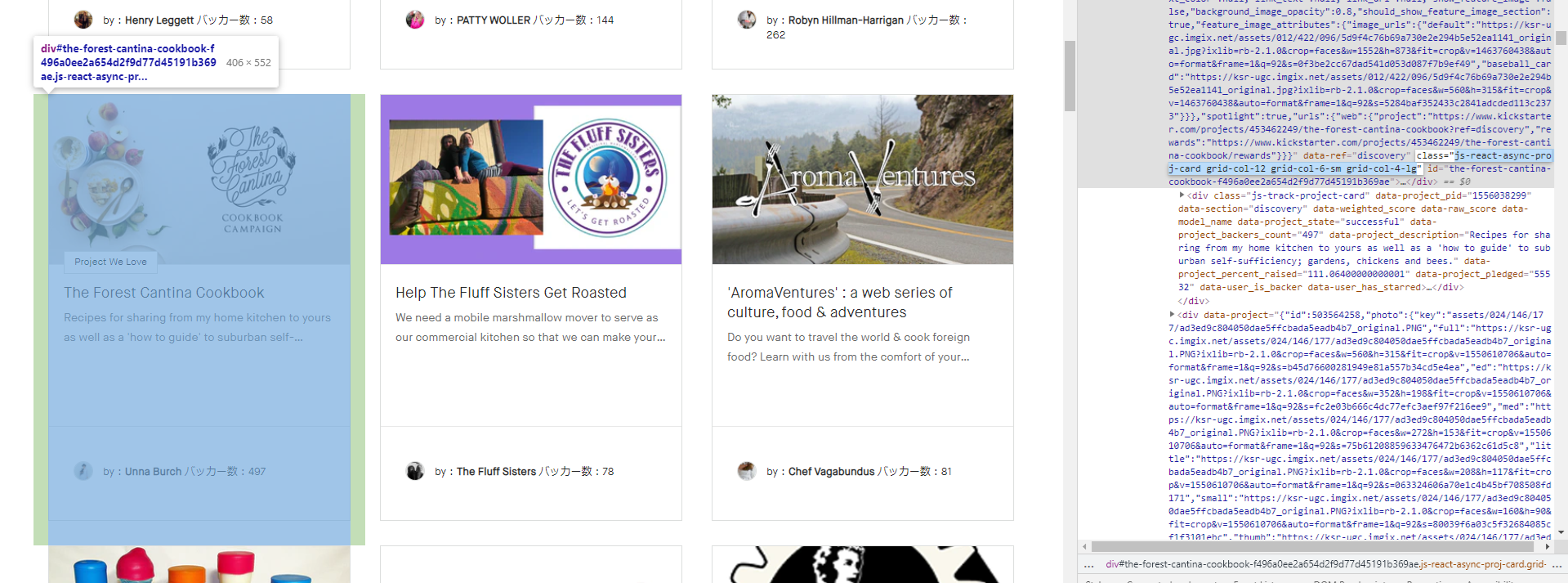
Xpathを用いて、スクレイピングしていますが、うまくテキストを抽出できません。
解決したいこと
下記サイトの、各プロジェクト名を抽出したいと思っています。
https://www.kickstarter.com/discover/advanced?term=Kitchen+as&woe_id=0&sort=magic&seed=2700321&page=4
・Selenium で無限スクロール⇒全情報取得⇒classなどを指定してプロジェクト名を抽出
という流れを想定しております。
プロジェクト名がh3タグなので、
find_element_by_tag_name("h3").text
こちらで最初は抽出してみたのですが、最初に5個ほど、プロジェクトタイトルと関係のない情報も抽出してしまうため、ピンポイントでタイトルを指定したいと思っています。
その流れでXpathを使用しているのですが、返却が空の状態になってしまっております。
該当するソースコード
pids = []
h3 = []
elems = driver.find_elements_by_class_name("js-track-project-card")
for elem in elems:
pid = elem.get_attribute("data-project_pid")
pids.append(pid)
wraps = driver.find_elements_by_xpath("//div[contains(@class, 'flex-wrap')]")
for wrap in wraps:
childs = wrap.find_elements_by_xpath("//div[contains(@class, 'js-track-project-card')]")
title = childs.find_element_by_tag_name("h3").text
h3.append(title)
自分で試したこと
この状態で取得すると、一つ目のpid=プロジェクトidは抽出できています。
h3が[]と空の状態です。
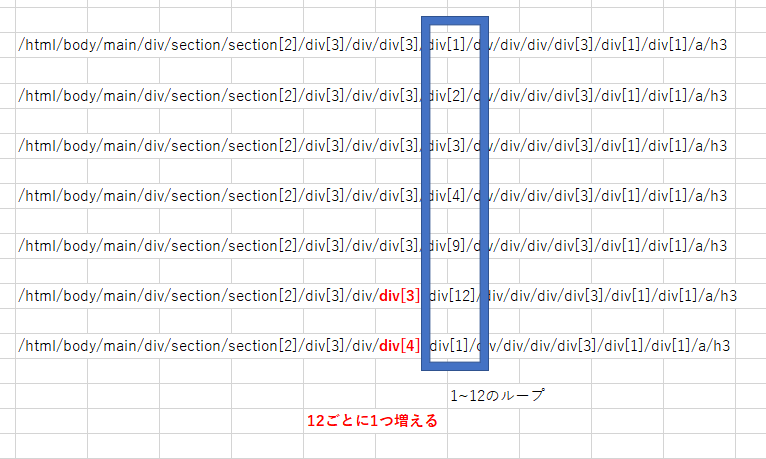
【サイトの構成】
抽出したいプロジェクトタイトルは、下図Excelのスクショのような構造になっており、
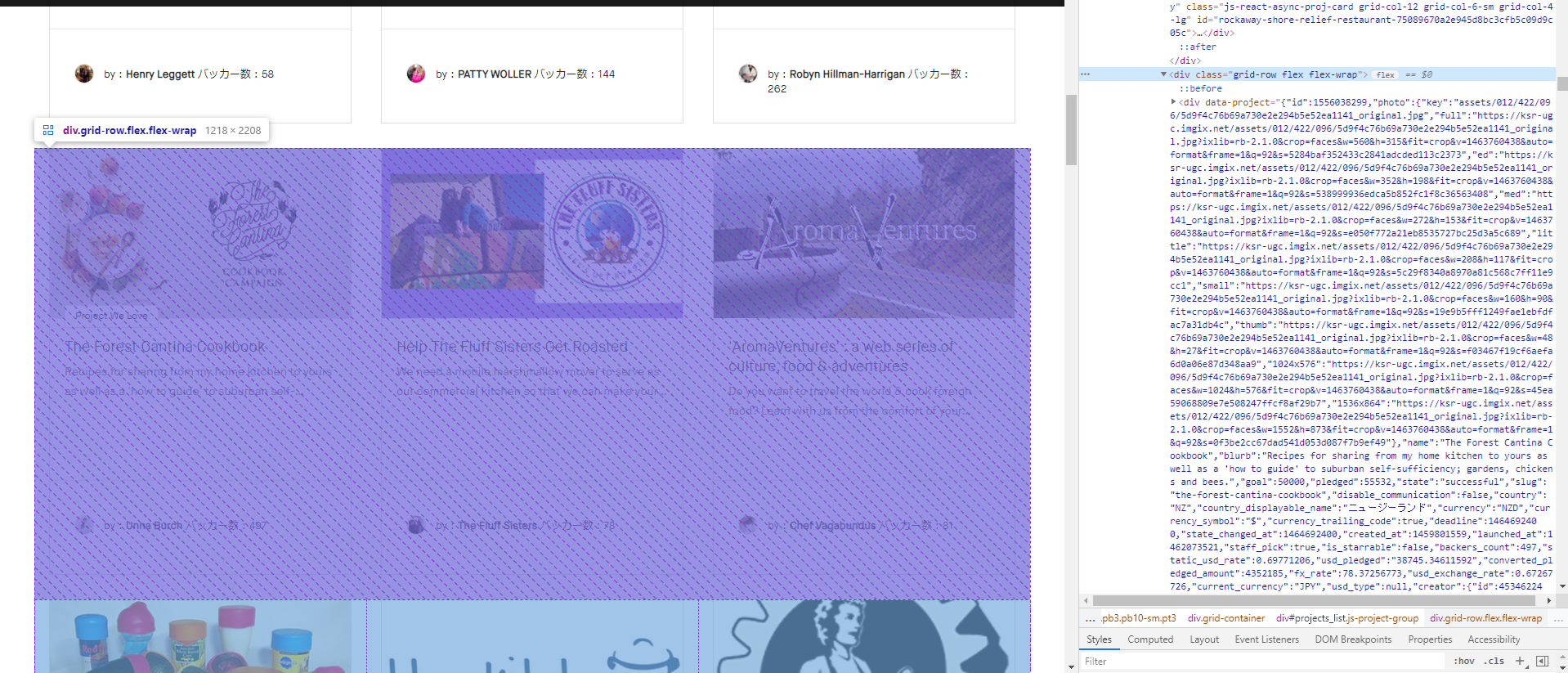
wrapperで12個のプロジェクトを包んでおり、
スクロールごとに現れ、divの階層が一つ深くなる(div[3]⇒div[4]になる)という仕組みです。
自分のイメージでは、wrapperをfor文でループ
⇒その中でプロジェクトをループしつつ、h3タグの要素を抽出し、テキスト(プロジェクトタイトル)を抽出
⇒h3[]リストに格納し
⇒print(h3)
というイメージですが、うまくいきません。
取得の仕方が間違っておりますでしょうか?💦
恐縮ですが、お時間ございます方がいらっしゃれば、ご回答頂けると幸いでございます🙇
宜しくお願い致します。
【xpath構造】
【wrapperの構成】
【プロジェクトの構成】