- 製造業出身のデータサイエンティストがお送りする記事
- 今回は時系列データの変化点を検知する異常検知手法のChangeFinderを実装(サンプルコード)しました。
はじめに
過去に異常検知手法や時系列データの解析手法を整理しておりますので、興味ある方はそちらも参照して頂けますと幸いです。
ChangeFinderとは
自己回帰モデル(ARモデル)の学習に「オンライン学習」と「忘却機能」を追加したSDARアルゴリズムを活用した手法が「ChangeFinder」です。山西先生がNEC在籍時代に発明した手法だそうです。詳細はデータマイニングによる異常検知に詳しく書かれておりますのでご参照ください。
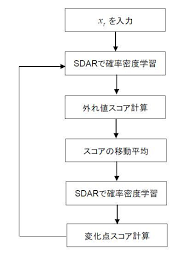
下記に簡単にアルゴリズムを整理しておきます。
- SDARで確率密度を学習(第一段階)
- 各時点での変化点スコアを算出
- 変化点スコアを平準化
- SDARで確率密度を学習(第二段階)
- 各時点での変化点スコアを算出
ChangeFinderの実装
今回はchangefinderのライブラリーにサンプルコードがありましたので、そちらを活用しました。
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
import numpy as np
import changefinder
import matplotlib.pyplot as plt
%matplotlib inline
最初に必要なライブラリーをimportします。
次に今回使用する3種類の正規分布に従う乱数を発生しさせます。
data=np.concatenate([np.random.normal(0.7, 0.05, 300),
np.random.normal(1.5, 0.05, 300),
np.random.normal(0.6, 0.05, 300),
np.random.normal(1.3, 0.05, 300)])
次にChangeFinderで変化点スコアを算出します。
cf = changefinder.ChangeFinder(r=0.01, order=1, smooth=7)
ret = []
for i in data:
score = cf.update(i)
ret.append(score)
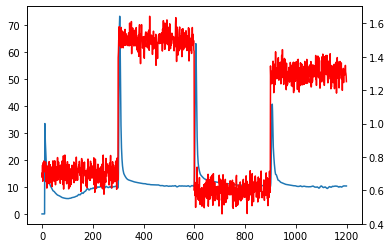
最後に結果を可視化します。
赤線が元のデータ、青線が変化点スコアです。
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(ret)
ax2 = ax.twinx()
ax2.plot(data,'r')
plt.show()
今回、ChangeFinderで設定したパラメータは下記3つです。
- r:忘却パラメータ(小さくすると過去の影響が大きくなり、変化点のバラツキが大きくなります)
- order:ARモデルの次数
- smooth:平滑化の範囲(長くすれば長くするほど外れ値ではなく「変化」が捉えられますが、大きくしすぎるとそもそも変化そのものが捉えづらくなります)
今回のデータセットでは、変化点が顕著に分かるため上手く検知できているように見えますが、実際私が現場のデータで使った時はパラメータチューニングに苦労しました。
さいごに
最後まで読んで頂き、ありがとうございました。
今回は、時系列データの変化点を検知する異常検知手法のChangeFinderについてサンプルコードを確認しました。
訂正要望がありましたら、ご連絡頂けますと幸いです。