- 製造業出身のデータサイエンティストがお送りする記事
- 今回は状態空間モデルを実装してみました。
はじめに
先日、ご紹介した(時系列解析)をもう少し調べていたら、状態空間モデルという手法を知りましたので、実装してみました。
状態空間モデルとは
前回ご紹介した時系列モデルは、前処理を適切に行わないと使えないとかで現実の問題では結構使い勝手が悪いのではないかと思っております。そんな時に使える手法が状態空間モデルになります。
今回は詳しい理論を整理するわけではないので、状態空間モデルの美味みを下記に記載しておきます。
- 非線形な挙動をする時系列も扱える
- 観測値が正規分布以外の分布に従う場合も扱える
状態空間モデルの考え方
状態空間モデルの基本的な考え方を下記に整理します。
- ある時点での観測値はその時点における真の状態から誤差を伴って発生する
- ある時点での真の状態は1時点前の真の状態に似ている
- つまり、時点とともに真の状態が確率的に変化する

- 観測方程式:観測値の時系列
- 状態方程式:真の状態の時系列
pythonのコードは下記の通りです。
# 必要なライブラリーのインポート
import numpy as np
import pandas as pd
from numpy.random import *
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# グラフを横長にする
from matplotlib import rcParams
rcParams['figure.figsize'] = 10, 6
sns.set()
# pystanの読み込み
import pystan
# データの読み込み
# https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/AirPassengers.html
df = pd.read_csv('AirPassengers.csv')
# float型に変換
df['#Passengers'] = df['#Passengers'].astype('float64')
df = df.rename(columns={'#Passengers': 'Passengers'})
# datetime型にしてインデックスにする
df.Month = pd.to_datetime(df.Month)
df = df.set_index("Month")
# データの中身を確認
df.head()

# データの可視化
plt.plot(df.earnings)
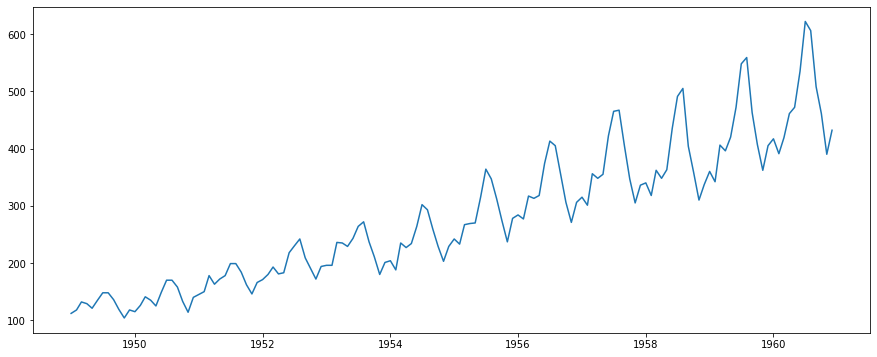
今回使用したデータは、月ごとの飛行機の乗客数データです。対象期間は1949年1月から1960年12月です。
初出は「Box, G. E. P., Jenkins, G. M. and Reinsel, G. C. (1976) Time Series Analysis, Forecasting and Control. Third Edition. Holden-Day. Series G.」となります。
URLから、データの詳細を確認できます。
次にローカルレベルモデルをStanでベイズ推定します。
\begin{align*}
y_t &= \mu_t + \epsilon_t, &\epsilon_t \sim N(0, \sigma_y^2) \\
\mu_t &= \mu_{t-1} + \eta_t, &\eta_t \sim N(0, \sigma_{\mu}^2)
\end{align*}
stanコードは下記のようになります。
local_level = '''
data {
int<lower=0> T; // number of learning points
int<lower=0> M; // number of predict points
real Y[T]; // observations
}
parameters {
real mu[T]; // trend
real<lower=0> s_y; // sd of observations
real<lower=0> s_mu; // sd of trend
}
transformed parameters {
real y_hat[T]; // prediction
for(t in 1:T) {
y_hat[t] = mu[t];
}
}
model {
for(t in 1:T) {
Y[t] ~ normal(mu[t], s_y);
}
for(t in 2:T) {
mu[t] ~ normal(mu[t-1], s_mu);
}
}
generated quantities {
real mu_pred[T+M];
real y_pred[T+M];
for(t in 1:T) {
mu_pred[t] = mu[t];
y_pred[t] = y_hat[t];
}
for(t in (T+1):(T+M)) {
mu_pred[t] = normal_rng(mu_pred[t-1], s_mu);
y_pred[t] = mu_pred[t];
}
}
'''
次にstanファイルのコンパイルを行います。
stan_model = pystan.StanModel(model_code=local_level)
次に諸設定を行います。
# 目的変数の指定
y = df["Passengers"]
# 学習期間と予測期間の時点を指定
T = 130 #学習期間
M = 14 #予測期間
# 目的変数を学習用と予測用に分割
y_train = y[:-M]
y_test = y[-M:]
次にstanにデータを引き渡します。この際、データはディクショナリでオブジェクトに代入することを注意してください。
predict_dat = {'T': T, 'M' : M, 'Y': y_train}
次にsampling関数を用いて事後分布からのサンプリングを行います。
fit_local_level = stan_model.sampling(data=predict_dat, iter=3000, chains=1, seed=10, n_jobs=1)
サンプリング結果の抽出を行います。Rhatが事後分布が収束しているかどうかの判断指標となります。1.1以下であれば収束していると判断しても良いです。
fit_local_level
次にサンプリング結果を抽出し、結果をプロットします。
# サンプリング結果の抽出
ms_local_level = fit_local_level.extract()
# 予測値
y_pred = ms_local_level['y_pred'].mean(axis=0)
quantile = [5, 95]
per_5_95 = np.percentile(ms_local_level['y_pred'], q=quantile, axis=0).T
colname = ['p5', 'p95']
df_pred = pd.DataFrame(per_5_95, columns=colname)
# 予測値を追加
df_pred['y_pred'] = y_pred
mu_hat = ms_local_level['mu'].mean(axis=0)
# 状態の推定値を追加
df_pred['mu_hat'] = np.nan
df_pred.loc[0:129,'mu_hat'] = mu_hat
df.plot(y="Passengers", legend=False) # 目的変数
plt.plot(df_pred[['p5','p95']][-14:], linestyle="dashed", color='purple') # 予測区間
plt.plot(df_pred[['y_pred']][-14:], color='red') # 予測値
plt.plot(mu_hat, color='green') # 状態
plt.show()

予測値はほぼ直線となり、信頼区間は徐々に広がる結果になってしまいました。
これはモデルが良くないのでこのような結果になってしまいました。
本当はここからモデルを改良して適切なモデルを構築していくことで、良い予測ができるようになりますが、それは次回以降の記事で整理したいと思います。
さいごに
最後まで読んで頂き、ありがとうございました。
今回は状態空間モデルをpystanを用いて実装してみました。
今後はモデルの改良等を行う必要がありますが、そこは実際のデータに合わせて実施して頂ければと思います。
訂正要望がありましたら、ご連絡頂けますと幸いです。