イラスト集: Transformer | Autoformer | PatchTST | iTransformer (この記事)
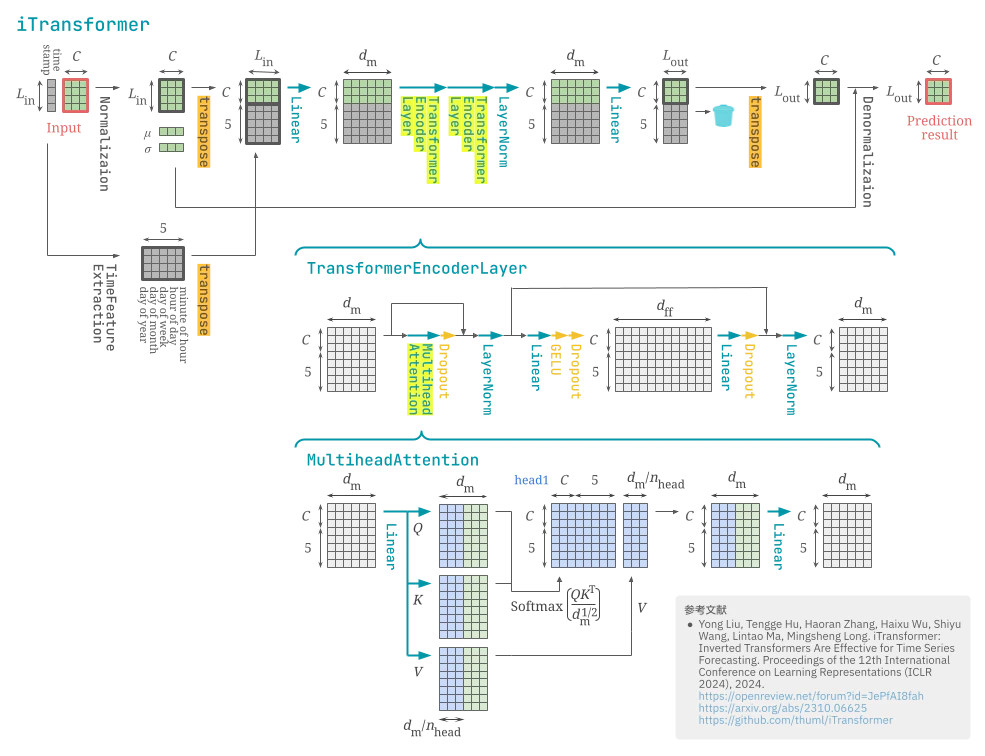
Transformer を時系列予測向けに改修した恰好をしているが、「各時刻の観測ベクトルの列」ではなく「各チャネルの時系列の列」として扱い (=転置する)、エンコーダのみからなる iTransformer (Yong Liu et al., ICLR 2024) のイラストを描きました。処理に漏れや誤りがあったらご指摘ください。
- イラスト内の TransformerEncoderLayer と MultiheadAttention はオリジナル Transformer のそれと変わりません (しいていうなら既定の活性化関数が GELU です)。
- なお、ハイパーパラメータの値まで同一ではなく、リポジトリのスクリプトによると、モデル次元数 d_m、中間層次元数 d_ff、エンコーダ層数 e_layers の設定値はデータセットに応じて変更しているようです (ただし n_head は一貫して 8 のようです)。
参考文献
- Yong Liu, Tengge Hu, Haoran Zhang, Haixu Wu, Shiyu Wang, Lintao Ma, Mingsheng Long. iTransformer: Inverted Transformers Are Effective for Time Series Forecasting. Proceedings of the 12th International Conference on Learning Representations (ICLR 2024), 2024.
https://openreview.net/forum?id=JePfAI8fah
https://arxiv.org/abs/2310.06625
https://github.com/thuml/iTransformer
トイモデル実装
以下にトイモデルの実装例を記します。論文のリポジトリ (リビジョン c2426e6) を取得してインポートしただけです。※ 構造確認用に小さいサイズでインスタンス化しているのでトイモデルといっていますが、ハイパーパラメータによって大きいサイズにもできます。
script.py
import sys
import types
# import エラー回避用 (iTransformer 自体はこれらを利用しない)
sys.modules['reformer_pytorch'] = types.SimpleNamespace(LSHSelfAttention=object)
sys.modules['einops'] = types.SimpleNamespace(rearrange=lambda **kwargs: None)
from model.iTransformer import Model
import torch
def main():
configs = {
'seq_len': 8, 'pred_len': 3, 'embed': 'timeF', 'freq': 'h',
'd_model': 6, 'n_heads': 2, 'd_ff': 12, 'e_layers': 2,
'activation': 'gelu', 'dropout': 0.05,
'use_norm': True, 'output_attention': False,
# 以下は iTransformer では未使用だが指定が必要なハイパーパラメータ
'factor': 1, 'class_strategy': 'projection',
}
model = Model(types.SimpleNamespace(**configs))
print(model)
x_enc = torch.randn(1, 8, 5)
x_dec = torch.zeros(1, 7, 5)
x_mark_enc = torch.rand(1, 8, 4) - 0.5
x_mark_dec = torch.rand(1, 7, 4) - 0.5
with torch.no_grad():
output = model(
x_enc,
x_mark_enc,
x_dec,
x_mark_dec,
)
assert output.shape == (1, 3, 5)
if __name__ == '__main__':
main()
出力
Model(
(enc_embedding): DataEmbedding_inverted(
(value_embedding): Linear(in_features=8, out_features=6, bias=True)
(dropout): Dropout(p=0.05, inplace=False)
)
(encoder): Encoder(
(attn_layers): ModuleList(
(0-1): 2 x EncoderLayer(
(attention): AttentionLayer(
(inner_attention): FullAttention(
(dropout): Dropout(p=0.05, inplace=False)
)
(query_projection): Linear(in_features=6, out_features=6, bias=True)
(key_projection): Linear(in_features=6, out_features=6, bias=True)
(value_projection): Linear(in_features=6, out_features=6, bias=True)
(out_projection): Linear(in_features=6, out_features=6, bias=True)
)
(conv1): Conv1d(6, 12, kernel_size=(1,), stride=(1,))
(conv2): Conv1d(12, 6, kernel_size=(1,), stride=(1,))
(norm1): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.05, inplace=False)
)
)
(norm): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
)
(projector): Linear(in_features=6, out_features=3, bias=True)
)