イラスト集: Transformer | Autoformer (この記事) | PatchTST | iTransformer
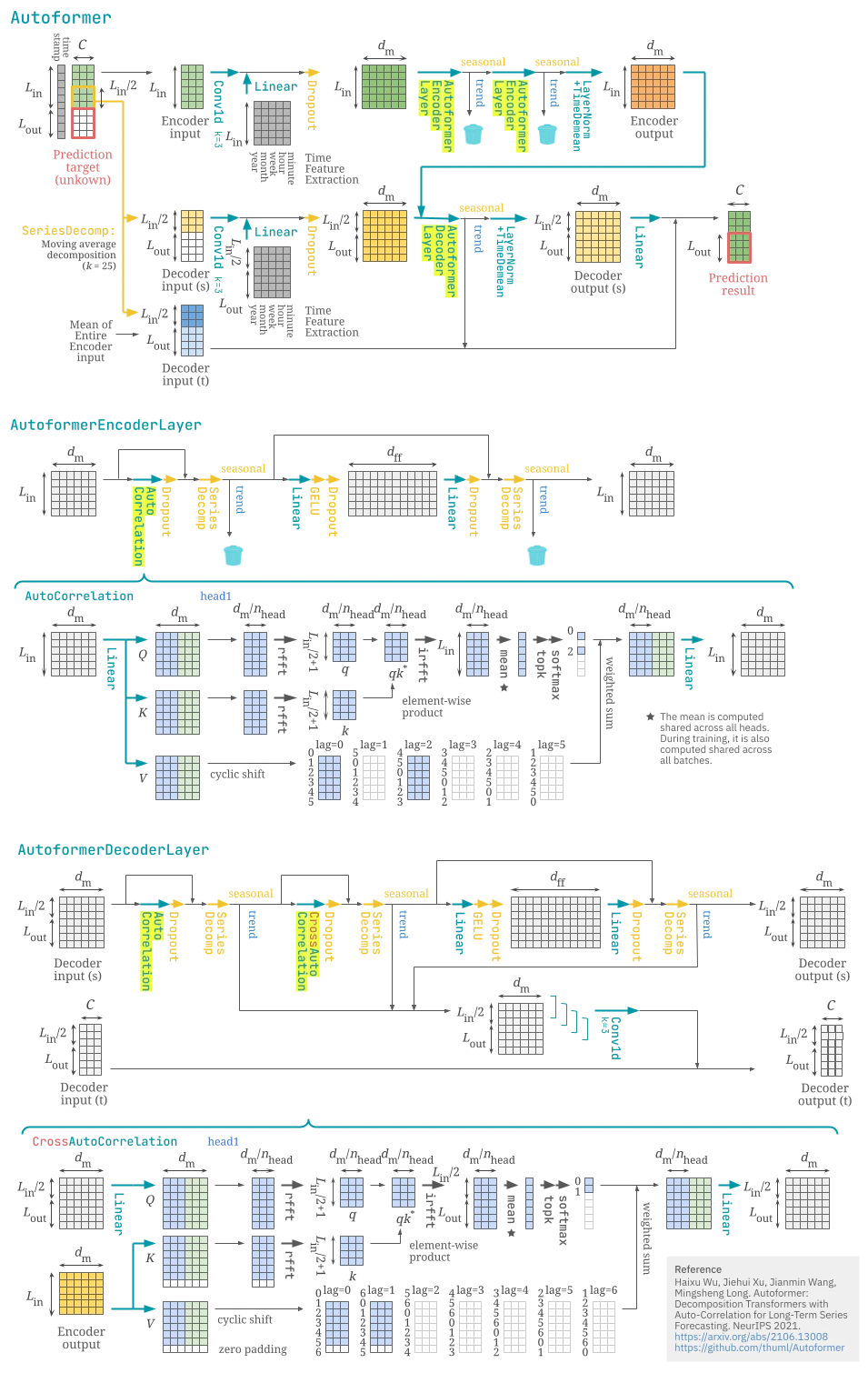
Transformer を時系列予測向けに改修した恰好をしている Autoformer (Haixu Wu et al., NeurIPS 2021) のイラストを描きました。処理に漏れや誤りがあったらご指摘ください。
2026-04-23 イラストに諸々の誤りがあったので修正しました。
2026-04-10 イラストにテキスト追加・レイアウト修正をしました。
SVG 版はこちらです。この SVG の掲載記事はこちらです (イラストの元のメモがあります)。
参考文献
イラスト内のグレーのボックスと同じ内容です。
- Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long. Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. Advances in Neural Information Processing Systems (NeurIPS 2021), vol. 34, 2021.
https://arxiv.org/abs/2106.13008
https://github.com/thuml/Autoformer
補足
- Time Feature Extraction はタイムスタンプから「1年のうち何日目」「1ヶ月のうち何日目」…を抽出する操作であるが、実際には [-0.5, 0.5] に正規化する。「何分」の特徴量は時系列の時間間隔が 1 時間未満の場合のみ。
- イラストは d_model=6, d_ff=12, n_head=2 として描かれているが、実際にはオリジナル Transformer と同じ d_model=512, d_ff=2048, n_head=8 が採用されている。但し、活性化関数は GELU が採用されている。また、エンコーダ層が2層のみ、デコーダ層が1層のみであることもオリジナル Transformer と異なる。
- AutoCorrelation 層では rfft → irfft で全ラグの Q-K 相互相関を計算してから、各ステップについてモデル次元方向の mean をとり、値が大きい k ステップに絞る。 この k は floor(c log L) で、係数 c の規定値は 1 なので、イラストのケースでは実際にはエンコーダ側では floor(log 6)=1 ステップ、デコーダ側でも floor(log 7)=1 ステップに絞られるはずだが、常に 1 ステップに絞るものという誤解を招きそうなため、敢えて 2 ステップ残している。
トイモデル実装
以下にトイモデルの実装例を記します。論文リポジトリの 2026/04/09 現在の最新リビジョン (51c7d41) を取得してインポートしただけです。※ 構造確認用に小さいサイズでインスタンス化しているのでトイモデルといっていますが、ハイパーパラメータによって大きいサイズにもできます。
script.py
from models.Autoformer import Model
import types
import torch
def main():
configs = {
'seq_len': 8, 'label_len': 4, 'pred_len': 3,
'embed': 'timeF', 'freq': 'h',
'moving_avg': 25, 'd_model': 6, 'n_heads': 2,
'factor': 1, 'd_ff': 12,
'e_layers': 2, 'enc_in': 5,
'd_layers': 1, 'dec_in': 5, 'c_out': 5,
'activation': 'gelu', 'dropout': 0.05,
'output_attention': False,
}
model = Model(types.SimpleNamespace(configs))
print(model)
x_enc = torch.randn(1, 8, 5)
x_dec = torch.zeros(1, 7, 5)
x_mark_enc = torch.rand(1, 8, 4) - 0.5
x_mark_dec = torch.rand(1, 7, 4) - 0.5
with torch.no_grad():
output = model(
x_enc,
x_mark_enc,
x_dec,
x_mark_dec,
)
assert output.shape == (1, 3, 5)
if __name__ == '__main__':
main()
出力
Model(
(decomp): series_decomp(
(moving_avg): moving_avg(
(avg): AvgPool1d(kernel_size=(25,), stride=(1,), padding=(0,))
)
)
(enc_embedding): DataEmbedding_wo_pos(
(value_embedding): TokenEmbedding(
(tokenConv): Conv1d(5, 6, kernel_size=(3,), stride=(1,), padding=(1,), bias=False, padding_mode=circular)
)
(position_embedding): PositionalEmbedding()
(temporal_embedding): TimeFeatureEmbedding(
(embed): Linear(in_features=4, out_features=6, bias=False)
)
(dropout): Dropout(p=0.05, inplace=False)
)
(dec_embedding): DataEmbedding_wo_pos(
(value_embedding): TokenEmbedding(
(tokenConv): Conv1d(5, 6, kernel_size=(3,), stride=(1,), padding=(1,), bias=False, padding_mode=circular)
)
(position_embedding): PositionalEmbedding()
(temporal_embedding): TimeFeatureEmbedding(
(embed): Linear(in_features=4, out_features=6, bias=False)
)
(dropout): Dropout(p=0.05, inplace=False)
)
(encoder): Encoder(
(attn_layers): ModuleList(
(0-1): 2 x EncoderLayer(
(attention): AutoCorrelationLayer(
(inner_correlation): AutoCorrelation(
(dropout): Dropout(p=0.05, inplace=False)
)
(query_projection): Linear(in_features=6, out_features=6, bias=True)
(key_projection): Linear(in_features=6, out_features=6, bias=True)
(value_projection): Linear(in_features=6, out_features=6, bias=True)
(out_projection): Linear(in_features=6, out_features=6, bias=True)
)
(conv1): Conv1d(6, 12, kernel_size=(1,), stride=(1,), bias=False)
(conv2): Conv1d(12, 6, kernel_size=(1,), stride=(1,), bias=False)
(decomp1): series_decomp(
(moving_avg): moving_avg(
(avg): AvgPool1d(kernel_size=(25,), stride=(1,), padding=(0,))
)
)
(decomp2): series_decomp(
(moving_avg): moving_avg(
(avg): AvgPool1d(kernel_size=(25,), stride=(1,), padding=(0,))
)
)
(dropout): Dropout(p=0.05, inplace=False)
)
)
(norm): my_Layernorm(
(layernorm): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
)
)
(decoder): Decoder(
(layers): ModuleList(
(0): DecoderLayer(
(self_attention): AutoCorrelationLayer(
(inner_correlation): AutoCorrelation(
(dropout): Dropout(p=0.05, inplace=False)
)
(query_projection): Linear(in_features=6, out_features=6, bias=True)
(key_projection): Linear(in_features=6, out_features=6, bias=True)
(value_projection): Linear(in_features=6, out_features=6, bias=True)
(out_projection): Linear(in_features=6, out_features=6, bias=True)
)
(cross_attention): AutoCorrelationLayer(
(inner_correlation): AutoCorrelation(
(dropout): Dropout(p=0.05, inplace=False)
)
(query_projection): Linear(in_features=6, out_features=6, bias=True)
(key_projection): Linear(in_features=6, out_features=6, bias=True)
(value_projection): Linear(in_features=6, out_features=6, bias=True)
(out_projection): Linear(in_features=6, out_features=6, bias=True)
)
(conv1): Conv1d(6, 12, kernel_size=(1,), stride=(1,), bias=False)
(conv2): Conv1d(12, 6, kernel_size=(1,), stride=(1,), bias=False)
(decomp1): series_decomp(
(moving_avg): moving_avg(
(avg): AvgPool1d(kernel_size=(25,), stride=(1,), padding=(0,))
)
)
(decomp2): series_decomp(
(moving_avg): moving_avg(
(avg): AvgPool1d(kernel_size=(25,), stride=(1,), padding=(0,))
)
)
(decomp3): series_decomp(
(moving_avg): moving_avg(
(avg): AvgPool1d(kernel_size=(25,), stride=(1,), padding=(0,))
)
)
(dropout): Dropout(p=0.05, inplace=False)
(projection): Conv1d(6, 5, kernel_size=(3,), stride=(1,), padding=(1,), bias=False, padding_mode=circular)
)
)
(norm): my_Layernorm(
(layernorm): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
)
(projection): Linear(in_features=6, out_features=5, bias=True)
)
)