イラスト集: Transformer | Autoformer | PatchTST (この記事) | iTransformer
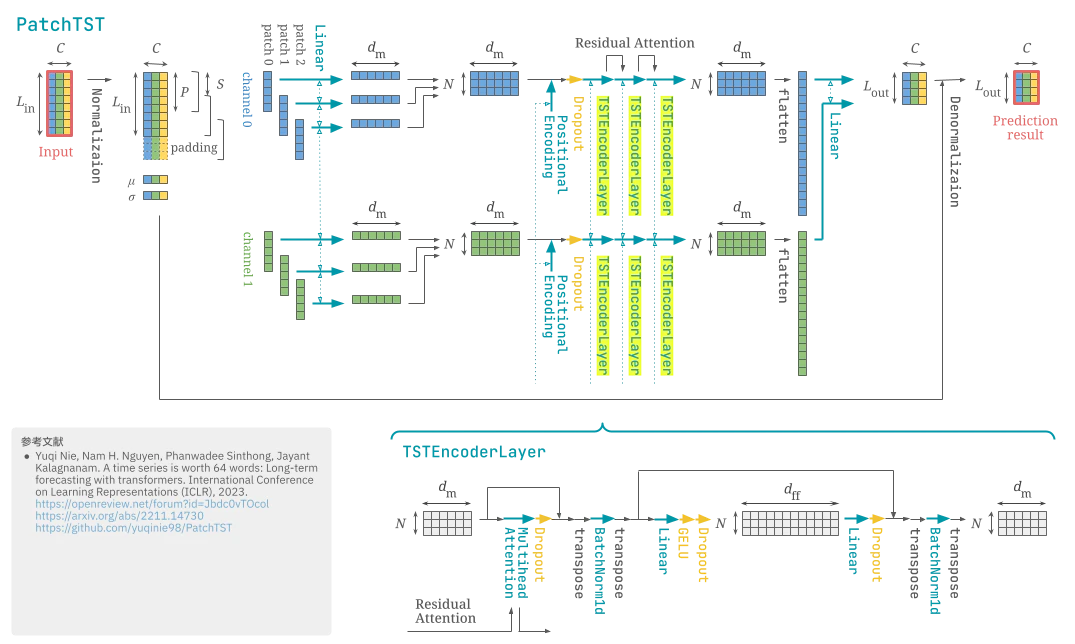
Transformer を時系列予測向けに改修した恰好をしているが、時系列の各チャネルを固定長の重複パッチに分割してトークンとし、チャネル別に共通の重みで処理する (リポジトリ実装では重みを独立にすることも可) エンコーダのみからなる PatchTST (Yuqi Nie et al., ICLR 2023) のイラストを描きました。処理に漏れや誤りがあったらご指摘ください。
参考文献
- Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam. A time series is worth 64 words: Long-term forecasting with transformers. International Conference on Learning Representations (ICLR), 2023.
https://openreview.net/forum?id=Jbdc0vTOcol
https://arxiv.org/abs/2211.14730
https://github.com/yuqinie98/PatchTST
イラストの補足
- 実装上、decomposition フラグ (True ならトレンド成分と残差成分を分けて別々の PatchTST を適用) があるが、規定値・実験設定で使用されている形跡はない。
- 実装上、エンコーダ出力を予測長次元に線形変換した後にドロップアウトがあるが、ドロップアウト割合の規定値が 0 のため省略した。
- BatchNorm1d の前後の転置は、BatchNorm1d がバッチ次元と最後の次元に沿った平均・分散を計算するので、パッチ軸を最後の次元にするための措置である。
トイモデル実装
以下にトイモデルの実装例を記します。論文のリポジトリ (リビジョン 204c21e) を取得してインポートしただけです。※ 構造確認用に小さいサイズでインスタンス化しているのでトイモデルといっていますが、ハイパーパラメータによって大きいサイズにもできます。
script.py
from pathlib import Path
import sys
sys.path.insert(0, str(Path(__file__).resolve().parent / 'PatchTST_supervised'))
from models.PatchTST import Model
import types
import torch
def main():
configs = {
'seq_len': 8, 'pred_len': 4, 'enc_in': 3,
'e_layers': 2, 'n_heads': 2, 'd_model': 8, 'd_ff': 16,
'dropout': 0.05, 'fc_dropout': 0.05, 'head_dropout': 0.0,
'individual': 0, # チャネルごとに重みを独立にするか
'patch_len': 5, 'stride': 2, 'padding_patch': 'end',
'revin': 1,
'affine': 0, # RevIN のアフィン変換を有効にするか
'subtract_last': 0, # RevIN で平均の代わりに系列の最後の値を引くか
'decomposition': 0, # 入力を移動平均と残差に分解して別々の backbone を適用するか
'kernel_size': 25, # decomposition=1 の場合のカーネルサイズ
}
model = Model(types.SimpleNamespace(**configs))
print(model)
x_enc = torch.randn(1, 8, 3)
with torch.no_grad():
output = model(x_enc)
assert output.shape == (1, 4, 3)
if __name__ == '__main__':
main()
出力
Model(
(model): PatchTST_backbone(
(revin_layer): RevIN()
(padding_patch_layer): ReplicationPad1d((0, 2))
(backbone): TSTiEncoder(
(W_P): Linear(in_features=5, out_features=8, bias=True)
(dropout): Dropout(p=0.05, inplace=False)
(encoder): TSTEncoder(
(layers): ModuleList(
(0-1): 2 x TSTEncoderLayer(
(self_attn): _MultiheadAttention(
(W_Q): Linear(in_features=8, out_features=8, bias=True)
(W_K): Linear(in_features=8, out_features=8, bias=True)
(W_V): Linear(in_features=8, out_features=8, bias=True)
(sdp_attn): _ScaledDotProductAttention(
(attn_dropout): Dropout(p=0.0, inplace=False)
)
(to_out): Sequential(
(0): Linear(in_features=8, out_features=8, bias=True)
(1): Dropout(p=0.05, inplace=False)
)
)
(dropout_attn): Dropout(p=0.05, inplace=False)
(norm_attn): Sequential(
(0): Transpose()
(1): BatchNorm1d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Transpose()
)
(ff): Sequential(
(0): Linear(in_features=8, out_features=16, bias=True)
(1): GELU(approximate='none')
(2): Dropout(p=0.05, inplace=False)
(3): Linear(in_features=16, out_features=8, bias=True)
)
(dropout_ffn): Dropout(p=0.05, inplace=False)
(norm_ffn): Sequential(
(0): Transpose()
(1): BatchNorm1d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): Transpose()
)
)
)
)
)
(head): Flatten_Head(
(flatten): Flatten(start_dim=-2, end_dim=-1)
(linear): Linear(in_features=24, out_features=4, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
)
)