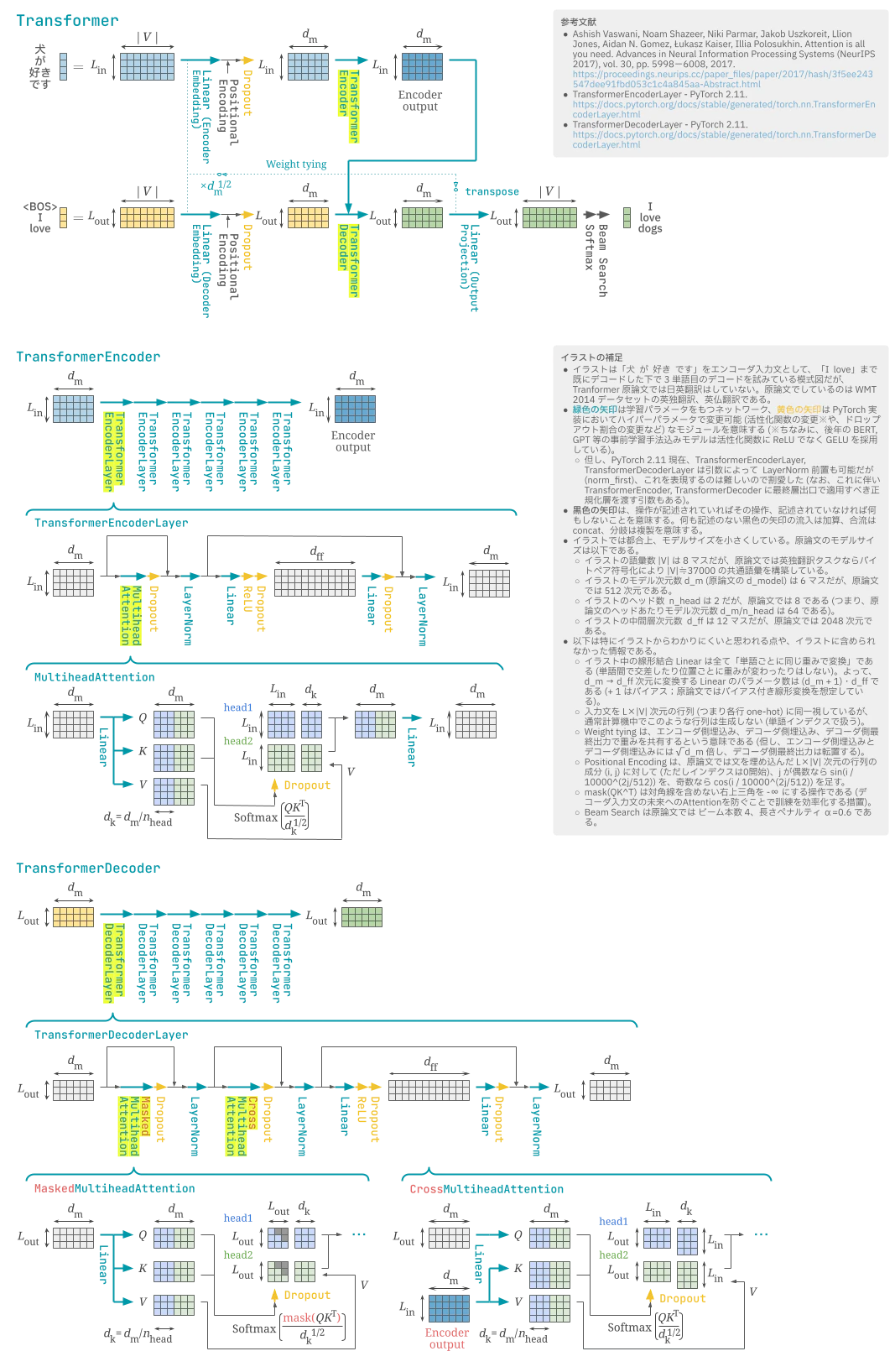
Transformer (原論文ベース) のイラストを、なるべくテンソル操作を漏らさないように描きました。テンソルを見守りたいとき向けです。操作に漏れ・誤りがあったらご指摘ください。
2026-04-12 self_attn 内スケールファクター誤植とドロップアウト漏れを修正 (但しこのドロップアウトは原論文内には記述がない) (実装上は存在していたようだ)。
2026-04-10 Weight tying スケールファクター漏れとドロップアウト漏れを修正。
以下の PNG は拡大すると (特に PC ブラウザでは) 透過背景がグレーになり見づらい & ぼやけがあるので、SVG 版はこちらです。この SVG を掲載しているページは Attention Is All You Need - Cookipedia α-version です (イラストの元にしたメモがあります)。
参考文献
イラスト内のグレーのボックスと同じ内容です。
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin. Attention is all you need. Advances in Neural Information Processing Systems (NeurIPS 2017), vol. 30, pp. 5998−6008, 2017.
https://proceedings.neurips.cc/paper_files/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html - TransformerEncoderLayer - PyTorch 2.11. https://docs.pytorch.org/docs/stable/generated/torch.nn.TransformerEncoderLayer.html
- TransformerDecoderLayer - PyTorch 2.11. https://docs.pytorch.org/docs/stable/generated/torch.nn.TransformerDecoderLayer.html
イラストの補足
イラスト内のグレーのボックスと同じ内容です。
- イラストは「犬 が 好き です」をエンコーダ入力文として、「I love」まで既にデコードした下で 3 単語目のデコードを試みている模式図だが、Tranformer 原論文では日英翻訳はしていない。原論文でしているのは WMT 2014 データセットの英独翻訳、英仏翻訳である。
-
緑色の矢印は学習パラメータをもつネットワーク、黄色の矢印は PyTorch 実装においてハイパーパラメータで変更可能 (活性化関数の変更※や、ドロップアウト割合の変更など) なモジュールを意味する (※ちなみに、後年の BERT, GPT 等の事前学習手法込みモデルは活性化関数に ReLU でなく GELU を採用している)。
- 但し、PyTorch 2.11 現在、TransformerEncoderLayer, TransformerDecoderLayer は引数によって LayerNorm 前置も可能だが (norm_first)、これを表現するのは難しいので割愛した (なお、これに伴い TransformerEncoder, TransformerDecoder に最終層出口で適用すべき正規化を渡す引数もある)。
- 黒色の矢印は、操作が記述されていればその操作、記述されていなければ何もしないことを意味する。何も記述のない黒色の矢印の流入は加算、合流は concat、分岐は複製を意味する。
- イラストでは都合上、モデルサイズを小さくしている。原論文のモデルサイズは以下である。
- イラストの語彙数 |V| は 8 マスだが、原論文では英独翻訳タスクならバイトペア符号化により |V|≒37000 の共通語彙を構築している。
- イラストのモデル次元数 d_m (原論文の d_model) は 6 マスだが、原論文では 512 次元である。
- イラストのヘッド数 n_head は 2 だが、原論文では 8 である (つまり、原論文のヘッドあたりモデル次元数 d_m/n_head は 64 である)。
- イラストの中間層次元数 d_ff は 12 マスだが、原論文では 2048 次元である。
- 以下は特にイラストからわかりにくいと思われる点や、イラストに含められなかった情報である。
- イラスト中の線形結合 Linear は全て「単語ごとに同じ重みで変換」である (単語間で交差したり位置ごとに重みが変わったりはしない)。よって、d_m → d_ff 次元に変換する Linear のパラメータ数は (d_m + 1)・d_ff である (+ 1 はバイアス;原論文ではバイアス付き線形変換を想定している)。
- 入力文を L×|V| 次元の行列 (つまり各行 one-hot) に同一視しているが、通常計算機中でこのような行列は生成しない (単語インデクスで扱う)。
- Weight tying は、エンコーダ側埋込み、デコーダ側埋込み、デコーダ側最終出力で重みを共有するという意味である (但し、エンコーダ側埋込みとデコーダ側埋込みには √d_m 倍し、デコーダ側最終出力は転置する)。
- Positional Encoding は、原論文では文を埋め込んだ L×|V| 次元の行列の成分 (i, j) に対して (ただしインデクスは0開始)、j が偶数なら sin(i / 10000^(2j/512)) を、奇数なら cos(i / 10000^(2j/512)) を足す。
- mask(QK^T) は対角線を含めない右上三角を -∞ にする操作である (デコーダ入力文の未来へのAttentionを防ぐことで訓練を効率化する措置)。
- Beam Search は原論文では ビーム本数 4、長さペナルティ α=0.6 である。
さらに補足
-
ドロップアウトについて:
- Transformer のドロップアウトに関する原論文内の記述は以下です。
- Residual Dropout We apply dropout [27] to the output of each sub-layer, before it is added to the sub-layer input and normalized. In addition, we apply dropout to the sums of the embeddings and the positional encodings in both the encoder and decoder stacks. For the base model, we use a rate of Pdrop = 0.1.
- つまり、上記の記述は以下の 💧 の箇所でドロップアウトすることを示しています (実際 PyTorch 実装でも以下の箇所で torch.nn.Dropout がコールされています)。
- エンコーダに入る直前 (位置エンコーディング加算直後) 💧
- エンコーダ層ごとに: MultiHeadAttention 直後💧、d_ff 次元に変換する直前💧、d_m 次元に再変換した直後💧
- デコーダに入る直前 (位置エンコーディング加算直後) 💧
- デコーダ層ごとに: MultiHeadAttention 直後 後💧、CrossMultiHeadAttention 直後💧、d_ff 次元に変換する直前💧、d_m 次元に再変換した直後💧
- それらに加えて、Google のリファレンス実装 Tensor2Tensor や PyTorch では、MultiHeadAttention 層内でアテンション重み softmax(QK^T/√d_k) にもドロップアウトがあります。そのため、イラストにもこのドロップアウトを含めました。
- Transformer のドロップアウトに関する原論文内の記述は以下です。
トイモデル実装
以下にトイモデルの実装例を記します (PyTorch のモジュールを利用しただけです)。
- 構造確認用に小さいサイズでインスタンス化しているのでトイモデルといっていますが、ハイパーパラメータによって大きいサイズにもできます。
- ただし、今日現在オリジナル Transformer を利用すべきかは目的によると思います。大規模化する場合は計算効率上の工夫も必要かもしれません。
- 以下のトイ Transformer は Positional Encoding を加算するところから Output Projection の手前までです。Weight tying は含みません。
- 以下では d_mm, n_head, d_ff はイラストと同じにしていますが、エンコーダ・デコーダ層数をどちらも 2 層にしている点がイラストより小さいです。このときモデルサイズは 1776 です (単に「2 × エンコーダ層サイズ + 2 × デコーダ層サイズ」に等しい)。
import torch
from torch.nn import TransformerEncoder as Encoder
from torch.nn import TransformerEncoderLayer as EncoderLayer
from torch.nn import TransformerDecoder as Decoder
from torch.nn import TransformerDecoderLayer as DecoderLayer
import math
class PositionalEncoding(torch.nn.Module):
def __init__(self, d_m, len_max=100):
super().__init__()
pe = torch.zeros(len_max, d_m)
pos = torch.arange(0, len_max).unsqueeze(1) # (max_len, 1)
div = torch.exp(torch.arange(0, d_m, 2) * (-math.log(10000.0) / d_m))
pe[:, 0::2] = torch.sin(pos * div)
pe[:, 1::2] = torch.cos(pos * div[:pe[:, 1::2].shape[1]])
self.register_buffer('pe', pe.unsqueeze(0)) # (1, len_max, d_m)
def forward(self, x):
return x + self.pe[:, :x.size(1)] # (batch, seq_len, d_m)
class ToyTransformer(torch.nn.Module):
def __init__(self, d_m, n_head, d_ff, p_drop=0.1):
super().__init__()
self.pos_enc = PositionalEncoding(d_m)
self.dropout = torch.nn.Dropout(p_drop)
common_params = {
'd_model': d_m,
'nhead': n_head,
'dim_feedforward': d_ff,
'batch_first': True,
}
self.encoder = Encoder(EncoderLayer(**common_params), num_layers=2)
self.decoder = Decoder(DecoderLayer(**common_params), num_layers=2)
def forward(self, src, tgt):
# src: (b, len_in, d_m)
# tgt: (b, len_out, d_m)
len_out = tgt.size(1)
mask = torch.nn.Transformer.generate_square_subsequent_mask(len_out)
encoded = self.encoder(self.dropout(self.pos_enc(src)))
decoded = self.decoder(self.dropout(self.pos_enc(tgt)), encoded, tgt_mask=mask)
return decoded
if __name__ == '__main__':
d_m = 6
n_head = 2
d_ff = 12
model = ToyTransformer(d_m, n_head, d_ff)
print(model)
# パラメータ数の確認
n_param = sum(p.numel() for p in model.parameters())
n_param_enc = sum(p.numel() for p in model.encoder.layers[0].parameters())
n_param_dec = sum(p.numel() for p in model.decoder.layers[0].parameters())
print(f'パラメータ総数: {n_param}')
print(f'encoder層のパラメータ数: {n_param_enc}')
print(f'decoder層のパラメータ数: {n_param_dec}')
assert n_param == 2 * n_param_enc + 2 * n_param_dec
# 入出力テンソルサイズの確認
src = torch.randn(1, 4, 6)
tgt = torch.randn(1, 3, 6)
with torch.no_grad():
out = model(src, tgt)
assert out.shape == (1, 3, 6)
ToyTransformer(
(pos_enc): PositionalEncoding()
(dropout): Dropout(p=0.1, inplace=False)
(encoder): TransformerEncoder(
(layers): ModuleList(
(0-1): 2 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=6, out_features=6, bias=True)
)
(linear1): Linear(in_features=6, out_features=12, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=12, out_features=6, bias=True)
(norm1): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
)
)
)
(decoder): TransformerDecoder(
(layers): ModuleList(
(0-1): 2 x TransformerDecoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=6, out_features=6, bias=True)
)
(multihead_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=6, out_features=6, bias=True)
)
(linear1): Linear(in_features=6, out_features=12, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=12, out_features=6, bias=True)
(norm1): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((6,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(dropout3): Dropout(p=0.1, inplace=False)
)
)
)
)
パラメータ総数: 1776
encoder層のパラメータ数: 354
decoder層のパラメータ数: 534