Pythonの散布図作成について
Q&A
Closed
[初心者です]pythonのグラフ作成について
python始めたての初心者です。
独学でやっていて、Kaggleにたどり着いたので試しにやってみようと思ったところ、次の疑問ができました。
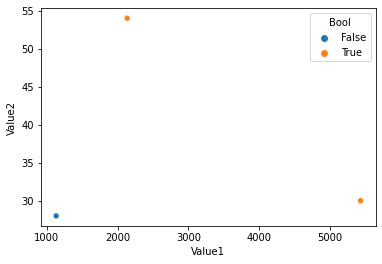
以下のような.csvファイルを配列として読み込み、散布図を書くことを考えています。
横軸にValue1、縦軸にValue2をとってプロットするのですが、BoolがTrueの場合のプロットだけ色を変えるなどで強調したいです。
どんな方法で記述すればよいでしょうか。
test.csv
ID, Value1, Value2, Sex, Bool
0, 2135, 54, male, True
1, 1133, 28, male, False
2, 5430, 30, female, True
...
現状自分で記述したコードは以下のようになっています。
import pandas as pd
import matplotlib.pyplot as plt
...
test = pd.read_csv("train.csv")
plt.scatter(test["Value1"],test["Value2"])
plt.show()
初めは、testの{Bool}ラベルの値によって、if文で一つずつプロットすることを考えていたのですが、
変数の型をtype()関数で調べると意味不明なものになっていて???でした。そこから先に進めていません。
0 likes