この記事は創作+機械学習 Advent Calendar 2021の14日目の記事です。
はじめに
DiscordやVRChatなど、オンラインでの会話を楽しむプラットフォームが近年賑わいを見せています。
そんな中で「もしも自分の声をさまざまな声質のものへ変換できたら面白いだろう」と思い立ち、声質をさまざまに変換することのできるモデルを実装してみました。
本記事では声質の変換例として、データセット「JVS corpus」を用いた男声→女声の変換を取り扱います。例えば以下の紹介動画のような変換が実行できます。
【qiita記事】機械学習の一手法「Scyclone」で声質の変換を行ってみました。https://t.co/91GkC4zIb0
— zassou (@zassouEX) December 13, 2021
以下は生成例の紹介です。 pic.twitter.com/L6AxVLr2jw
以下ではこれに用いた手法について解説していきます。
GANとは
今回、音声間の変換にはScycloneというモデルを使いました。これは**GAN(Generative adversarial networks、敵対的生成ネットワーク)**という手法をベースにしたもので、GANは以下のように構成されています。
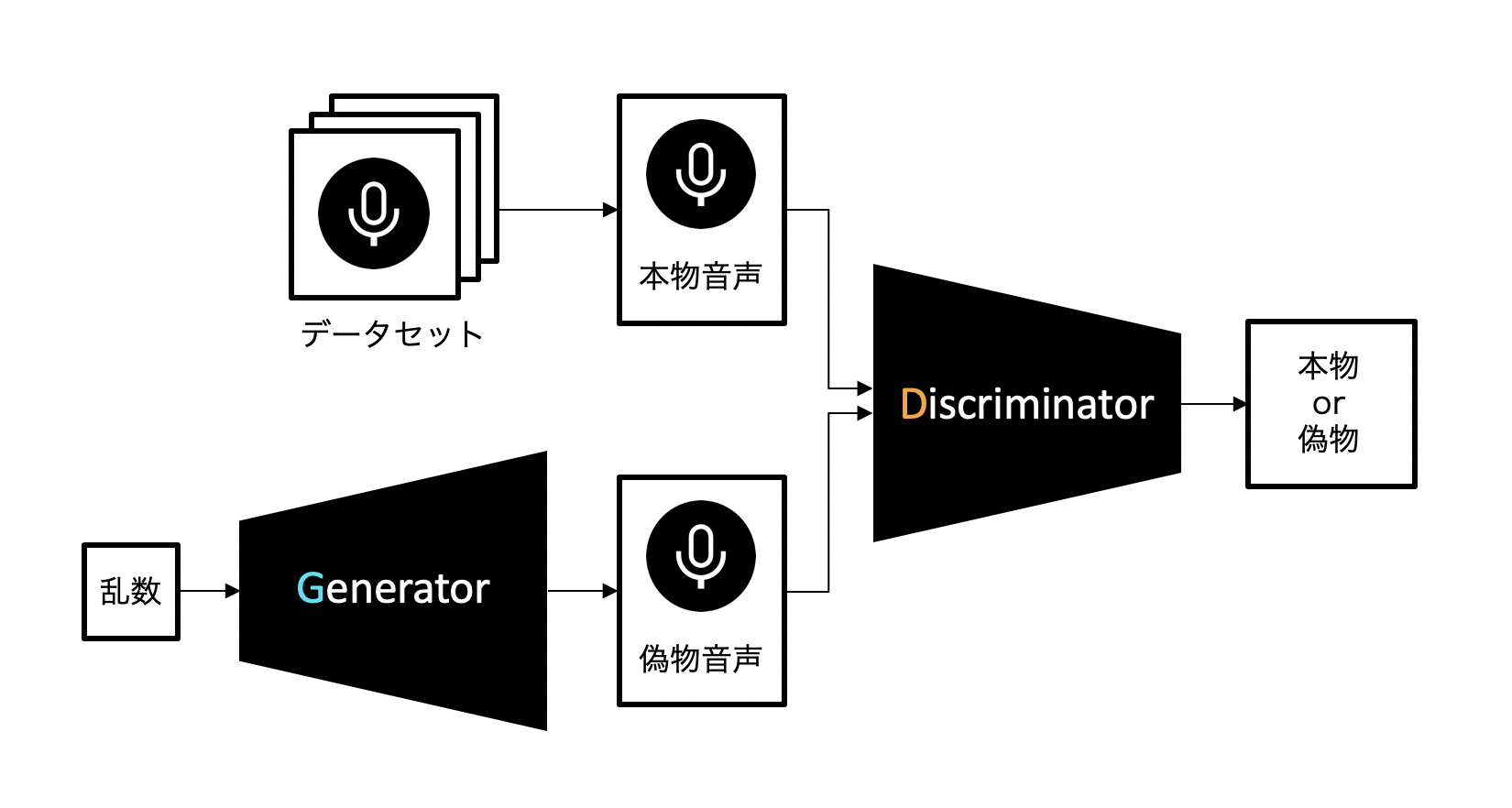
この手法では、音声を生成するニューラルネットワーク(Generator)と、音声を識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。
Generatorは音声データを生成し(これを偽物音声、あるいは単に偽物と呼ぶことにします)、それによってDiscriminatorをデータセット中の本物の音声データ(本物音声、あるいは単に本物と呼ぶことにします)だと誤認させることを目指して学習を進めます。一方でDiscriminatorはGeneratorに騙されないよう、より正確に音声データの真贋を見極めるよう学習します。
二つのニューラルネットワークがお互いに鍛え合うことで、Generatorは徐々に学習データに近い音声を生成できるようになっていきます。
要するにGenerator VS Discriminatorです。
スペクトログラムとは
今回使用する音声変換モデル「Scyclone」では、音声をスペクトログラムという形式で扱います。
音声波形は時間軸に対する音の振幅を示すのに対し、スペクトログラムは時間軸に対する周波数構成の変化を示します。
例えば本記事冒頭の紹介動画の、「変換前」の音声波形、スペクトログラムは以下のようになります。

スペクトログラムの縦軸は周波数、横軸は時間、色の強さはその成分の大きさを表します。
この例では、音声全体を通しておよそ100[Hz]〜2000[Hz]に成分が比較的集中(図の黄色が強い部分)していることが分かります。
短時間フーリエ変換(STFT)
音声波形からスペクトログラムの変換には**短時間フーリエ変換(STFT)**と呼ばれる手法を用います。
STFTは音声波形を一定間隔で区切り、それぞれに対しフーリエ変換を行うことで周波数成分を求めるという方法です。
具体的な計算方法を概略図を用いて説明します。下図の上側の音声波形からスペクトログラムを求めることを考えます。

まず下図のように音声波形から一定間隔切り取り(下図の例では5サンプル分切り出しています)、窓関数を乗算します。
次に、切り出した波形に対しフーリエ変換を実行、周波数領域へと変換します。
フーリエ変換では波形に周期性を仮定するため、対象となる波形の両端が不連続である場合、周波数分析した際に余計な周波数成分が出てきてしまいます。しかし窓関数によって、切り出した波形の両端を滑らかにすることによってこれを軽減することができます。

さらに、波形に対しホップ数(下図ではホップ数は3)だけ対象位置をずらし同様の操作をします。

このような操作を繰り返すことでスペクトログラムを時間領域にわたって算出することができます。

Scyclone
今回、男声⇄女声の変換にはScycloneというモデルを用いました。
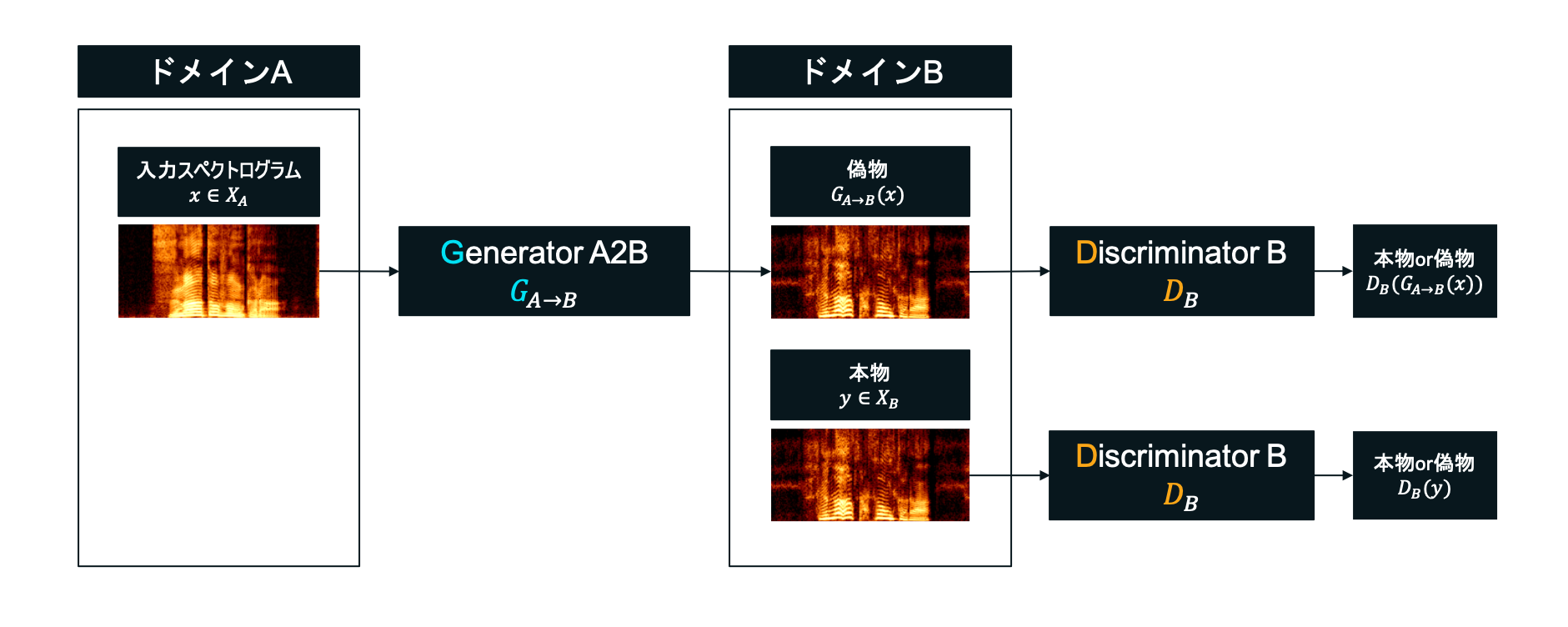
これはGenerator VS Discriminatorによって学習を進めていくGANを基とした方式で、大まかな全体図は以下の図のようになっています。

今回の場合はドメインAが男声、ドメインBが女声に相当します。
ScycloneではGeneratorを2種類、Discriminatorを2種類用います。
-
「ドメインA→ドメインB」の学習
DiscriminatorBは、本物の女声もしくはGeneratorA2Bによって生成された偽物の女声を入力に取り、それらが本物か偽物かを正しく識別できるように学習します。一方、GeneratorA2Bは男声を入力に取り、それを元に女声を生成し、DiscriminatorBを本物だと騙せるよう学習します。GeneratorA2BとDiscriminatorBが相互に鍛え合うことで、GeneratorA2Bはより女声に近いスペクトログラムを生成できるようになっていきます。 -
「ドメインA→ドメインB→ドメインA」の学習
先ほどGeneratorA2Bによって出力された女声をGeneratorB2Aに入力します。つまり「ドメインA→ドメインB→ドメインA」という変換を施します。DiscriminatorBを騙すだけでなく、変換前の男声と、2回変換されて出てきた男声のスペクトログラムが一致するようにも目指し学習を進めます。こうすることで生成結果に多様性を持たせ、モード崩壊の問題を軽減します。
また、「ドメインA→ドメインB」と「ドメインA→ドメインB→ドメインA」に関して説明しましたが、AとB逆バージョン「ドメインB→ドメインA」と「ドメインB→ドメインA→ドメインB」についても同様の学習を進めます。
データセット
今回はデータセットとして「JVS corpus」を用いました。これには100人の俳優/声優によるテキストの読み上げ(.wav形式)が含まれており、性別や継続長、発話内容などのラベルも付与されています。
ここから性別のラベルを元に、音声ファイルをドメインA(男声)、ドメインB(女声)へ振り分け学習に用います。振り分けた結果、AとBで音声ファイルはそれぞれ約6000個ずつとなりました。
Generatorの作成
Generatorの役割は、入力された男声のスペクトログラムをできるだけ女声に近くなるよう変換し、それを用いてDiscriminatorに本物の女声だと誤認させることです。うまく騙せるよう精度を上げることを目指して学習を進めます。
Generatorのネットワーク図は以下のようになっています。

入力スペクトログラムの大きさは縦128pixel(周波数)、横160pixel(時間)です。これに対し畳み込みを繰り返すことによって所望のスペクトログラムを計算します。
また、上では「男声→女声」の変換を実行するGeneratorについて紹介しましたが、逆の「女声→男声」を行うGeneratorに関しても全く同様の構成です。入力する声の種類と出力する声の種類がそれぞれ逆なだけです。
Discriminatorの作成
Discriminatorの役割は、入力されたスペクトログラムが本物の女声なのか、Generatorによって作成された偽物の女声なのかを判定することです。Generatorに騙されないように精度を上げていくことを目標に学習します。
Discriminatorのネットワーク図は以下のようになっています。

Discriminatorは、入力されたスペクトログラムに対し、畳み込みを繰り返すことにより真贋を判定します。
Generatorの出力するスペクトログラムは縦128pixel(周波数)、横160pixel(時間)ですが、一方Discriminatorへの入力は縦128pixel(周波数)、横128pixel(時間)です。実装ではGeneratorの出力の横160pixelのうち、中央128pixelを切り取りDiscriminatorへの入力としています。

Generatorは畳み込みによってスペクトログラムを生成していますが、畳み込み時にpaddingを行なっており、これが出力スペクトログラムの左右16pixel分に影響します。そのため左右から16pixelを除いた、128pixel分のみを本物or偽物の判定対象とします。
また、偽物スペクトログラム同様、本物スペクトログラムに対しても、Discriminatorへの入力時は横幅を128pixelに揃えます。
以上では女声を識別するDiscriminatorについて紹介しましたが、男声を識別するDiscriminatorも入力するスペクトログラムの種類が違うだけで同様の構成をしています。
損失関数
Scycloneでは次に解説する3種類の損失関数を用います。
- Adversarial loss
$$L_{D}^{adversarial} = E_{y\in X_B}[\mathrm{max}(0,m-D_{B}(y))] + E_{x\in X_A}[\mathrm{max}(0,m+D_{B}(G_{A→B}(x)))]$$$$L_{G}^{adversarial} = E_{x\in X_A}[\mathrm{max}(0,-D_{B}(G_{A→B}(x)))]$$
- Cycle loss
$$L_{G}^{cycle} = E_{x\in X_A}[|x-G_{B→A}(G_{A→B}(x))|_{1}]$$
- Identity loss
$$L_{G}^{identity} = E_{y\in X_B}[|y-G_{A→B}(y)|_{1}]$$
ただし変換元であるドメインAに属するスペクトログラムの集合を$X_{A}$,変換先であるドメインBのスペクトログラムの集合を$X_{B}$とします。$E$はミニバッチごとに平均をとる操作です。また$m=0.5$とします。
これらについて順番に解説していきます。以下では変換元ドメイン$X_{A}$を男声、変換先ドメイン$X_{B}$を女声として説明しますが、変換元と変換先逆バージョンについても同様のことをします。
Adversarial loss
$$L_{D}^{adversarial} = E_{y\in X_B}[\mathrm{max}(0,m-D_{B}(y))] + E_{x\in X_A}[\mathrm{max}(0,m+D_{B}(G_{A→B}(x)))]$$$$L_{G}^{adversarial} = E_{x\in X_A}[\mathrm{max}(0,-D_{B}(G_{A→B}(x)))]$$
 Discriminatorは$$L_{D}^{adversarial} = E_{y\in X_B}[\mathrm{max}(0,m-D_{B}(y))] + E_{x\in X_A}[\mathrm{max}(0,m+D_{B}(G_{A→B}(x)))]$$を最小化するよう目指すことで、本物の女声ほど大きい値を出力し、Generatorによって生成された偽物の女声ほど小さな値を出力できるよう学習します。Generatorに騙されないよう精度をあげることを目標とし学習を進めます。
Discriminatorは$$L_{D}^{adversarial} = E_{y\in X_B}[\mathrm{max}(0,m-D_{B}(y))] + E_{x\in X_A}[\mathrm{max}(0,m+D_{B}(G_{A→B}(x)))]$$を最小化するよう目指すことで、本物の女声ほど大きい値を出力し、Generatorによって生成された偽物の女声ほど小さな値を出力できるよう学習します。Generatorに騙されないよう精度をあげることを目標とし学習を進めます。
一方でGeneratorは$$L_{G}^{adversarial} = E_{x\in X_A}[\mathrm{max}(0,-D_{B}(G_{A→B}(x)))]$$を最小化するよう目指すことで、生成したスペクトログラムでDiscriminatorを本物だと騙せるよう学習します。
Cycle loss
$$L_{G}^{cycle} = E_{x\in X_A}[|x-G_{B→A}(G_{A→B}(x))|_{1}]$$

Cycle lossは「男声→女声→男声」と2回変換をかけたときに、ちゃんと元のスペクトログラムに戻ってこれるようにするための項です。元の音声のスペクトログラムと、2回変換をかけたあとのスペクトログラムのL1ノルムを最小化するよう目指すことでモード崩壊の問題を軽減します。
Identity loss
$$L_{G}^{identity} = E_{y\in X_B}[|y-G_{A→B}(y)|_{1}]$$

音声変換を行うGeneratorには、入力されたスペクトログラムのうち必要箇所のみを変換するように学習して欲しいです。逆に言えば、変更の必要のない箇所に関しては何もしないことが理想的です。これを実現するため、変換先ドメインに属するスペクトログラムをGeneratorに入力し、出力スペクトログラムとの距離を最小化するよう学習します(図のように、変換先ドメインに属するスペクトログラムをGeneratorに入力した時、入力と出力が一致するのを目指す)。
損失関数の全体像
以上で解説した$L_{D}^{adversarial},L_{G}^{adversarial},L_{G}^{cycle},L_{G}^{identity}$を用いて、DiscriminatorとGeneratorの損失関数全体をそれぞれ以下のように定義します。
$$L_{D}=L_{D}^{adversarial}$$$$L_{G}=L_{G}^{adversarial}+\lambda_{cycle}L_{G}^{cycle}+\lambda_{identity}L_{G}^{identity}$$
ただし係数はそれぞれ$\lambda_{cycle}=10,\lambda_{identity}=1$です。これらの最小化を目標とし学習を進めます。
また以上では「ドメインA→ドメインB」に関する損失関数について説明しましたが、逆バージョンの「ドメインB→ドメインA」に関してもAとBを逆にして同様の処理を実行します。
学習方法
バッチサイズは16とし、iteration数は380000としました。誤差伝搬の最適化手法にはAdamを使い、学習率0.0002、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.5と0.999に設定しました。
Scycloneの全体像
上でも紹介した画像の再掲ですが、作成したGeneratorとDiscriminatorを組み合わせ、Scycloneを構成し学習を実行します。
Neural Vocoder
スペクトログラムを生成後、音声として再生するためには音声波形に変換する必要があります。
今回、スペクトログラムから音声波形への変換にはニューラルネットを用いたモデルを使いました。音声生成の分野において、このような種類のモデルはNeural Vocoder(以下では単にVocoderと表記)などと呼ばれており、他の手法と比べ高品質な音声の生成を実現することができます。

Scycloneとは独立にVocoderの学習も行い、よりクオリティの高い音声の生成を目指します。
また、Vocoderと一括りにしてもさまざまな種類がありますが、今回はリポジトリ https://github.com/anandaswarup/waveRNN のコードを参考に実装しました。
Vocoderの作成
Vocoderの役割は、入力スペクトログラムを音声波形へと変換することです。
今回は女声のスペクトログラムを波形へと変換したいため、ドメインBへ分類した約6000個の音声ファイルをデータセットとします。

学習時の流れとしては、まずSTFTで入力音声をスペクトログラムへと変換します。これをVocoderへの入力とし、生成された音声波形が元の入力音声とできるだけ近くなるのを目標とします。
量子化
Vocoderでは音声波形の値は量子化した形で扱います。
量子化とはあらかじめ決められた離散的な数値へと値を近似する操作で、例えば下の図では音声波形の各サンプルの値を{-1.0, -0.5, 0.0, 0.5, 1.0}の5段階の値へと量子化しています。

今回はVocoderの学習時、データセットの音声波形の値をあらかじめ決められた$2^{10}$(=$1024$)段階の値へと量子化した形式で扱います。
他方でVocoderは音声波形の生成時には順番に1サンプルずつ、$2^{10}$段階の値からどれが一番相応しいかを推定することをします。
とてもアバウトなイメージですが、$2^{10}$種類のカテゴリーに対するクラス分類を順番に1サンプルずつ実行しているような感じです。

(※図では簡単のため5段階としていますが、実際の実装では$2^{10}$段階です。)
推論時の動作
Vocoderは学習時と推論時でそれぞれ少し違った動作をします。まず推論時の動作について解説します。
Vocoderのネットワークは以下のようになっています。

これについて順番に説明します。
まず、Vocoderへ入力されたスペクトログラム(縦128pixel(周波数)、横24pixel(時間))をGRUとUpsamplingを用いて、(128×24)channelかつ256次元の特徴マップに変換します。GRUはRNNやLSTMなどと似た、再帰構造を持つ層です。これによってスペクトログラム内の時間方向にまたがる特徴を捉えやすくします。
次に、得られた特徴量を用いて順番に波形のサンプルを生成します。$t-1$回目の操作で得られたサンプル$x_{t-1}$も合わせて用いて、大きさ$1024$(=$2^{10}$)の特徴量を生成します。1024個中の各値はそれぞれ量子化後の音声波形の値に対応し、それぞれの値がどれだけ生成結果として相応しいかを表します。
これを変数が1024個あるCategorical分布であると解釈し、そこから値をSamplingし生成結果$x_{t}$とします。
要するに面を1024個もつ、歪んだサイコロを振って出た面を生成結果としているということです。
この操作を繰り返すことで、スペクトログラム(縦128pixel(周波数)、横24pixel(時間))は最終的に音声波形(サンプル数128×24)へと変換されます。
学習時の動作
次に学習時の動作について解説します。推論時とは2つ違いがあります。

1つ目は$x_{t-1}$として直前の推定結果ではなく、入力スペクトログラムの元となった音声波形の$t-1$サンプル目を使う点です。これによってVocoderは、音声波形の$t-1$サンプル目を元に$t$サンプル目を推定します。
2つ目はCategorical分布を用いず、大きさ1024の特徴量をそのままVocoderの出力としている点です。学習時において$t$サンプル目の推定は、1024個それぞれの値がどれだけ生成結果として相応しいかを出力するという形で行います。これを後述の損失関数の計算に用います。
損失関数
Vocoderでは以下の損失関数を最小化するよう目指すことで波形の生成を学習します。この形の関数はCross Entropyと呼ばれています。
$$L_{V} = -\sum_{class} p(class) \mathrm{log}(q(class))$$
ただし$class$はクラス(全1024種類)、$p$は真の確率分布、$q$は推定された確率分布です。
簡単化した具体例を用いて説明します。例えば波形が{-1.0, -0.5, 0.0, 0.5, 1.0}の5クラスに量子化されているとします。このとき音声波形の内$t$サンプル目を推定しようとしていて、そこの真の値が0.5であったとします。この時$p$={0.0, 0.0, 0.0, 1.0, 0.0}です。
また、Vocoderは$t$サンプル目について、$q$={0.1, 0.2, 0.15, 0.4, 0.15}などと推定します。例えばこの推定ではクラス"0.5"に対応する値は0.4です。
この時Cross Entropyは
\begin{align}
L_{V} = -\sum_{class} p(class) \mathrm{log}(q(class)) = -\{
0.0 \cdot \mathrm{log}(0.1)
+ 0.0 \cdot \mathrm{log}(0.2) \\
+ 0.0 \cdot \mathrm{log}(0.15)
+ 1.0 \cdot \mathrm{log}(0.4)
+ 0.0 \cdot \mathrm{log}(0.15)
\}
\end{align}
と計算できます。
これを実際の学習では1024クラスで行います。
学習方法
バッチサイズは16とし、iteration数は250000としました。誤差伝搬の最適化手法にはAdamを使い、学習率0.0004、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.9と0.999に設定しました。
Vocoderの全体像
上でも紹介した画像の再掲ですが、ドメインBの音声ファイルをデータセットとし、作成したVocoderに対し元の音声波形を正しく推定できるよう学習を進めます。
Scyclone + Vocoder
以上で解説したScycloneとVocoderを用いて音声変換器全体を構成します。
Scycloneの推論時は以下のようにネットワークを組み合わせます。

ドメインAの音声波形をスペクトログラムに変換し、学習済みGeneratorを用いてドメインBのスペクトログラムへと変換します。さらにそれを学習済みVocoderを用いて音声波形へと変換、音声として再生できる状態にします。
いざ生成
用意したデータセットを用いて学習を行い、Generator + Vocoderで「男声→女声」の変換を実行します。
以下は生成例の比較動画です。Vocoderによる生成結果の他に、ニューラルネットを用いない波形生成手法の例として「GriffinLim」による生成結果もセットで紹介、比較しています。
サンプル音声4つに対する詳細な比較です。
— zassou (@zassouEX) December 13, 2021
Vocoderで生成した波形の方がGriffinLimよりも雑音を軽減できているかと思います。(詳細はqiita記事を参照) pic.twitter.com/Fu1UCeFBpV
個人的にはうまく変換できた方だと思っています。
まとめ
ScycloneとVocoderによって音声間の相互変換を実現できました。
機械学習によるスペクトログラム間の変換はScyclone以外ではAutoVCなどが有名で、GANだけでなくAuto Encoderを用いた手法も多く見られます。Vocoderはこの他にはWaveGlowなどが有名で、波形生成の学習にGANを使ったMelGANなどといったモデルも提案されています。
音声変換、Vocoderはどちらも現在研究が盛んな分野のようで、新しい手法が次々に開拓されています。皆さんもGANでガンガン音声合成しましょう。
個人的には今後データセットが揃えばアニメ声への変換などもやってみたいですね。
2022/2/26追記 : やってみました
【機械学習】VITSでアニメ声へ変換できるボイスチェンジャー&読み上げ器を作った話
ソースコード
書いたコードはこのリポジトリにあります。
https://github.com/zassou65535/voice_converter
余談
GANは本来音声の生成よりも、画像の生成で有名な手法です。
GANによる画像生成に関しても解説記事を書いているので是非こちらもどうぞ。
機械学習で画像を変換する手法「UGATIT」でメルアイコン変換器を作りました。https://t.co/stNnKuSf0Z pic.twitter.com/vk99ZXOX9g
— zassou (@zassouEX) December 1, 2020
参考
Scyclone: High-Quality and Parallel-Data-Free Voice Conversion Using Spectrogram and Cycle-Consistent Adversarial Networks
Reimplmentation of voice conversion system "Scyclone" with PyTorch
numpyでスペクトログラムによる音楽信号の可視化
JVS (Japanese versatile speech) corpus
【Cycle GAN】GANによるスタイル変換の仕組み解説と実験
話声の合成における応用技術
Recurrent Neural Network based Neural Vocoders
ややこしい離散分布に関するまとめ
交差エントロピー誤差をわかりやすく説明してみる
PytorchのCrossEntropyLossの解説
ReLUはGriffin–Limアルゴリズムの一助となるか