はじめに
「メルアイコン」と呼ばれる、Melvilleさんの描くアイコンはその独特な作風から大勢から人気を集めています。

上はMelvilleさんのアイコンです。
特にこの方へアイコンの作成を依頼し、それをtwitterアイコンとしている人がとても多いことで知られています。
代表的なメルアイコンの例



自分もこんな感じのメルアイコンが欲しい!!ということで機械学習でメルアイコン生成器を実装しました!!...というのが前作の大まかなあらすじです。
今回は大きくアルゴリズムを見直すことで多くの点を改善、メルアイコン生成器を大幅に進化させました。
本記事ではそれに用いた手法を紹介していきます。
GANとは
画像の生成にあたってはGAN(Generative adversarial networks、敵対的生成ネットワーク)という手法を用いています。
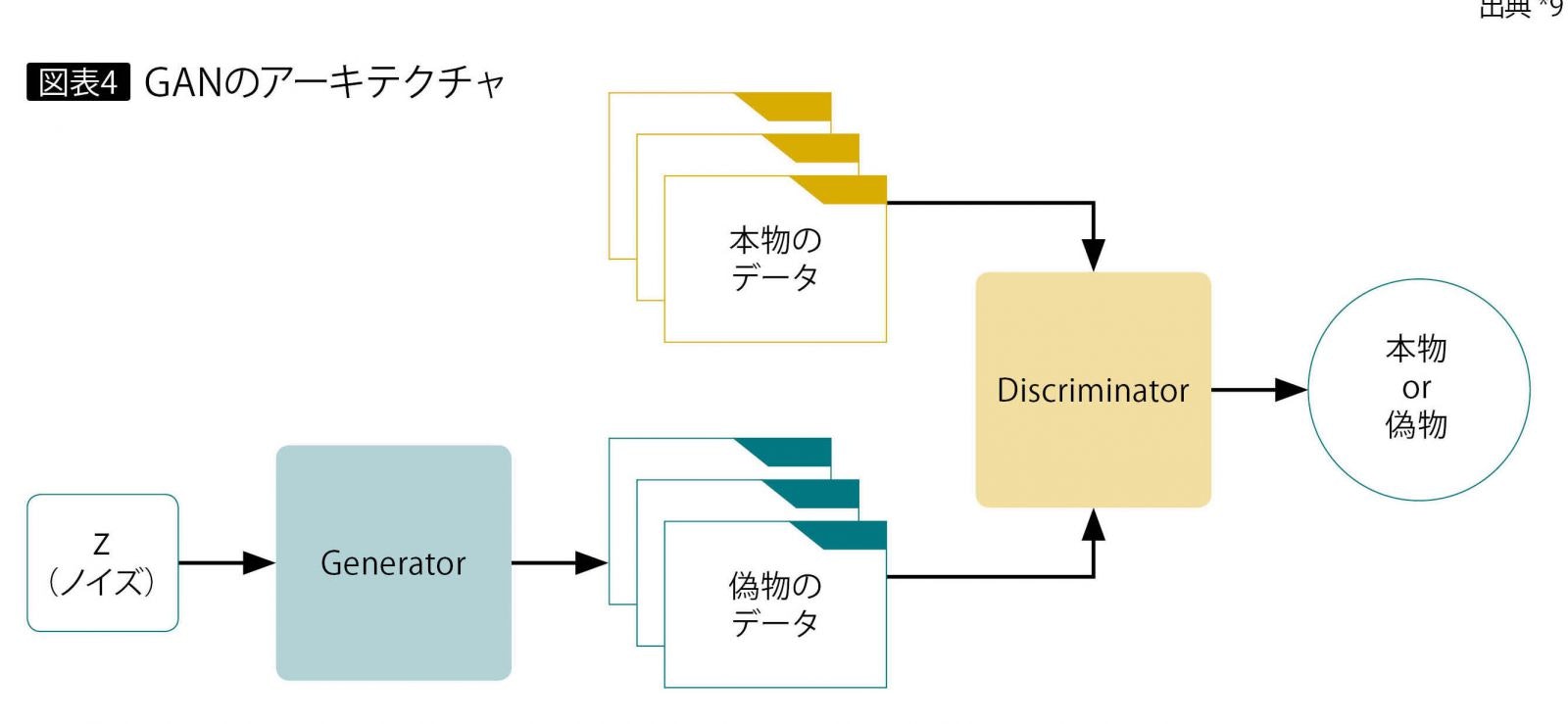
この手法では画像を生成するニューラルネットワーク(Generator)と、入力されたデータがメルアイコンなのかそうでないのかを識別するニューラルネットワーク(Discriminator)の2つを組み合わせます。
GeneratorはDiscriminatorを欺くためにできるだけメルアイコンに似せた画像を生成しようとします。Discriminatorは騙されないよう、より正確に画像を識別しようと学習します。二つのニューラルネットワークがお互いに鍛え合うことでGeneratorはメルアイコンに近い画像を生成できるようになっていく、というわけです。
要するにGenerator VS Discriminatorです。
Progressive GAN
一口にGANといっても、様々な種類の手法があります。今回はそのうちの1つ、Progressive GANというものを用いています。
これは、例えば最初は4×4の低解像度に対応した畳み込み層である回数学習を行い、それに8×8に対応した畳み込み層を追加し学習を行い、次は16×16を追加し.....といった風に、段階的に解像度を上げながら学習を進めていく方法となります。

学習の初めでは、図のようにGeneratorは4×4の解像度の画像を出力できる状態です。Discriminatorも4×4の解像度の画像を入力にとり、それがどれだけメルアイコンっぽいかを表す値を出力します。
Generatorは画像を生成し、Discriminatorには生成画像と本物の画像(学習データのメルアイコン)の2種類が入力されます。
4×4の解像度での学習がある程度進んだら、8×8に対応した畳み込み層を追加し、さらに学習を続けていきます。

8×8が終わったら16×16を追加し....といったことを繰り返し、最終的にはこのような構造となります。
今回の目標は256×256の画像の出力としました。

GANは解像度の比較的高い画像の学習を行おうとすると、学習が不安定になりやすいという弱点をもちます。しかしProgressive GANでは最初は画像の大体の特徴からみていき、徐々に細かい複雑な箇所に注目するという手法をとるため、これを克服することができます。
データセットの準備
Generatorがメルアイコンっぽい画像を生成できるようになったり、Discriminatorが入力された画像をメルアイコンなのかどうかを識別できるようになったりするためには、実在するメルアイコンをできるだけ大量に持ってきて教師データとなるデータセットを作り、これを学習に用いる必要があります。
今回はなんとMelvilleさんから今までに作成したメルアイコンを全て提供していただきました。その数なんと751枚です。(圧倒的.....感謝....!!!!!)
ここから学習に使えそうなメルアイコンを探していきます。今回はあまりに変則的すぎるメルアイコンは学習から除外しました。
具体的には


このようなものです。
他、アイコンとしてはほぼ同じでも髪の長さだけ微妙に違うといった物もありました。これらは学習全体に与える影響を考え、似たメルアイコンは4枚までならデータセットに加え、5枚以上あるようならそれらは除外しました。
こうして使えそうなデータセットは約640枚となりました。前回が高々100枚であったことを考えると、6倍以上も使える量が増えています。
これらを学習データとして用います。
Generatorの作成
Generatorの役割は、入力に乱数で構成された数列(これをノイズと表現することにします)をとり、それをもとにメルアイコンっぽい画像を生成することです。生成したメルアイコンをDiscriminatorに入力した時、本物のメルアイコンだと騙せるように学習していきます。
基本的な動作として、Generatorは入力されたノイズに対し畳み込みを繰り返すことによって画像を生成します。
まず最初の状態では、Generatorを構成するニューラルネットワークは以下の図のようになっています。

一番上の層からデータを入力、処理を施し順次下の層へ渡し、一番下の層からデータを得る、というイメージの図です。
一番上の畳み込み層が、Generatorに入力されたノイズ(ノイズの大きさはチャネル数512,解像度4×4)を受け取り、畳み込みの処理をしてチャネル数256,解像度4×4のデータを出力します。そのデータを次の畳み込み層に渡し...ということを繰り返し、最後の層はチャネル数3,解像度4×4の画像を出力します。
最後の層の出力のチャネル数の3は(R,G,B)のそれぞれに対応し、4×4はGeneratorの出力する画像の解像度です。
これらの層の学習をしながら、次の解像度「8×8」に対応する層をこれから「少しづつ導入」していきます。(「少しづつ導入」については後述。)
「少しづつ導入」することによって以下の状態を目指します。

ここで、4×4の層と8×8の層の間にUpsampleという層を挟んでいます。この層は解像度4×4のデータが入力されると、それを解像度8×8に変換し出力します。各ピクセルの中間の値をうまく補完することでこれは実現されています。
これにより4×4の層と8×8の層の間のデータの橋渡しを行うことができます。
「少しづつ導入」
新しい層の導入をいきなり始めてしまうと、学習によくない影響を与えてしまうことが知られています。そこで、Progressive GANでは層を「少しづつ導入」していきます。

例えば、4×4の層の次に8×8の層を追加するときは、4×4の層からの出力に(1-α)を乗算したものと、8×8の層からの出力にαを乗算したものを得ます。次にこの2つを加算し出力画像とします。
αの値を初めは0にしておき、学習回数を重ねるごとに1へ近づけていきます。
αが0の時Generatorのニューラルネットは下と同じです。
αが1の時Generatorのニューラルネットは下と同じです。
αが0の状態から1の状態へと徐々に近づけることで、いきなり高解像度の学習を始めるのではなく、少しづつ高解像度の層を混ぜ合わせていくような学習が可能になります。
これを8×8から16×16への移行、16×16から32×32への移行、......でも使っていきます。最終的には以下のような、解像度256×256かつ(R,G,B)の3チャネルのメルアイコンを生成できるようなネットワークを目指して学習します。

Discriminatorの作成
Discriminatorの役割は、入力に画像データをとり、それが本物のメルアイコンなのかどうかを識別することです。Generatorに騙されないよう、精度をどんどん上げていくよう学習します。
最初の状態では、Discriminatorを構成するニューラルネットワークは以下の図のようになっています。
(図中の赤い箇所、MiniBatchStdについては後述します。)

一番上の畳み込み層が、Discriminatorに入力された画像(チャネル数3((R,G,B)に対応)、解像度4×4)を受け取り、畳み込みの処理をしてチャネル数256、解像度4×4のデータを出力、次の層に渡します。そのデータを次の層が処理しさらに次の層に渡し...ということを繰り返し、最後の層はチャネル数1,解像度1×1のデータを出力します。
この出力される1×1×1のデータ、要は1個の値ですが、これは入力された画像がどれだけメルアイコンっぽいかを示す値です。
Generatorと同様、これらの層の学習をしながら、次の解像度「8×8」に対応する層を「少しづつ導入」し、以下の状態を目指します。

Generatorでは各解像度に対応した層間でのデータを橋渡しするため、Upsampleという処理を施し、解像度を上げた上で次の層にデータを渡せる仕組みを実現していました。
Discriminatorではこれと真逆の動作をする、Downsampleという処理を挟みます。これにより例えば8×8の解像度のデータを4×4に変換、8×8の層から4×4の層へデータを橋渡しできるようになります。(pytorchにおいてはAdaptiveAvgPool2dという関数がこれをする上で便利です。)

Generatorと同様、このようにしてαの値を0から1まで徐々に大きくしていき、緩やかに新しい層を混ぜていきます。
最終的には以下のような、解像度256×256かつ(R,G,B)の3チャネルのメルアイコンを入力にとり、それを本物か偽物か判定できるようなネットワークを目指して学習します。

VS モード崩壊
4×4の層にのみ含まれている「MiniBatchStd」により、「モード崩壊」と呼ばれる現象を防止します。
モード崩壊とは
Generatorにはできるだけ様々な種類のメルアイコンを生成して欲しいです。しかし、GANではいろんな乱数を入力しているにもかかわらず、ほとんど違いのわからないような画像しか生成しなくなってしまう状態に陥ってしまうことがあります。このような現象はモード崩壊と呼ばれています。

これは前作の結果ですが、例として最適なためこれを使って説明します。
上段が学習に使ったデータの例5種類、下段がGANによって出力された5種類の画像です。
5回違う乱数を入力しているにもかかわらず、出力結果がほとんど同じになってしまっているのがわかります。
この現象は、Generatorが「味をしめてしまう」ことに起因します。ある生成画像がうまくDiscriminatorを騙すことに成功したとします。その画像とほとんど変わらない画像をまた生成すればもう一度Discriminatorを騙せる可能性は高いでしょう。これを繰り返していくうちにほとんど同じ画像しか生成できなくなってしまいます。
ミニバッチ標準偏差
Progressive GANには、Generatorがこんなズルをできないようにする機能が備わっています。それが先ほどの「MiniBatchStd」という層です。
これによってミニバッチ標準偏差という統計量を求め、モード崩壊の防止をします。
Discriminatorは、画像の識別の際に一度に何枚かをまとめて受け取り、画像の各pixelごとに標準偏差をとります。
例えば8枚の画像を受け取ったのならば、その8枚がGeneratorから出力されたものなのか、本物のメルアイコンなのかを識別することになりますが、この8枚に対し画像の各pixelごとに標準偏差をとります。

さらに、標準偏差を各pixelに対して取れたら、全てのチャネル、pixelに対し平均を取ります。

これにより最終的にチャネル数1で、かつ解像度は元入れた画像のものと同じデータがMiniBatchStd層から出てきます。これを次の4×4の層に、元の画像とセットにして渡します。
この値は複数入力された入力画像がどれだけ多様であるかを表す量です。(分散みたいなイメージです。)あまりにもこれが小さいようであれば、DiscriminatorはGeneratorがズルを始めたと判断でき、入力画像が生成画像だと見破ることができます。
Generatorは同じような画像ばかり生成すると、Discriminatorに生成画像だと看破されてしまうことになります。そのためいろいろな種類の画像を生成することを余儀なくされるわけです。
このようなことができるMiniBatchStd層を、Discriminatorの最後の方の4×4の層とセットにすることでモード崩壊の可能性を潰します。
学習方法・誤差関数
GeneratorとDiscriminatorでは、損失関数にWGAN-GPというものを用います。定義は以下です。
- Generatorの損失関数
-E[d_{fake}]
- Discriminatorの損失関数
E[d_{fake}] - E[d_{real}] + \lambda E_{\substack{\hat{x}\in P_{\hat{x}}}}[(||\nabla_{\hat{x}}D(\hat{x})||_{2}-1)^{2}]
これらについて順番に解説していきます。
ノイズ$z$をGeneratorへ入力、ミニバッチの数だけ画像を得ます。(以降ミニバッチの数を$M$とします。今回は$M = 8$としました。)それをDiscriminatorに入力し、どれだけメルアイコンらしいかを示す値をそれぞれの画像に対し$M$個出力させます。これを$d_{fake}$とします。
また、実在のメルアイコンを$M$枚Discriminatorに入力し、その時の$M$個の出力を$d_{real}$とします。
WGAN-GPではこの$d_{real}$と$d_{fake}$を損失の算出に用います。
Generatorの学習
Generatorは乱数でできた数列が入力されるとDiscriminatorを騙すべく、できるだけメルアイコンっぽい画像を生成しようとします。
損失関数
WGAN-GPではGeneratorの損失関数は次のように定義されます。
-E[d_{fake}]
要はGeneratorからの生成画像$M$枚をDiscriminatorで判定、その出力の平均をとりマイナスをつけたものです。WGAN-GPではこう定義すると経験的にうまくいくことが知られているようです。
誤差伝搬の最適化手法にはAdamを使い、学習率0.0005、Adamの一次モーメントと二次モーメントはそれぞれ0.0と0.99に設定しました。
また、256×256の層を学習している時に限って、ある一定回数まで学習を回したならば学習率を0.0001に下げる処理を入れています。
(心なしか、なんかこうするとメルアイコンの生成が比較的うまくいく....気がする。(気のせいかも。)もしかしたら他にもっといい方法があるかもしれません)
Discriminatorの学習
Generatorの誤差伝搬をしたら、次はDiscriminatorの誤差伝搬です。
損失関数
WGAN-GPではDiscriminatorの損失関数は次のように定義されます。
E[d_{fake}] - E[d_{real}] + \lambda E_{\substack{\hat{x}\in P_{\hat{x}}}}[(||\nabla_{\hat{x}}D(\hat{x})||_{2}-1)^{2}]
- 1項目
- 生成画像$M$枚をDiscriminatorで判定、結果の平均をとったもの
- 2項目
- 本物画像$M$枚をDiscriminatorで判定、結果の平均をとったもの
- 3項目
- 勾配制約項で、gradient penaltyと呼ばれている項です。これについて解説します。
gradient penalty
gradient penaltyの定義は以下です。
\lambda E_{\substack{\hat{x}\in P_{\hat{x}}}}[(||\nabla_{\hat{x}}D(\hat{x})||_{2}-1)^{2}]
ただし、生成画像の分布、本物画像の分布をそれぞれ$P_{fake}$、$P_{real}$として、
\epsilon\in U[0,1],x_{fake}\in P_{fake},x_{real}\in P_{real}
\hat{x}=(1-\epsilon)x_{fake}+\epsilon x_{real}
と決めています。
これについてイメージを説明します。(あくまでイメージです。それもかなりアバウトです。)
生成画像と本物画像を、それぞれランダムな割合で混ぜ合わせた画像$\hat{x}$がいっぱいあります。これをDiscriminatorに入れた時の、出力がなす空間を考えます。
最適化されたDiscriminatorにおいては、この空間内のほぼ全ての点で、勾配が1になっていることが知られています。
おそらく誤差伝播の時に勾配が消失したり発散したりしないためには1付近が都合がいい、ということなのでしょう。
ということでメルアイコン生成器のDiscriminatorでも、この値が1になるように学習を進めます。そのための項がgradient penalty、すなわち
\lambda E_{\substack{\hat{x}\in P_{\hat{x}}}}[(||\nabla_{\hat{x}}D(\hat{x})||_{2}-1)^{2}]
です。
また、今回は定数$\lambda$は10.0としました。(参考にした資料が10.0と決めていたのでそれに倣いました。)
以上がWGAN-GPにおけるDiscriminatorの損失関数ですが、ここにさらに$d_{real}$の二乗をとって、それを平均したもの$E[{d_{real}}^2]$を追加します。
この項により、傾きが極端になることによる学習へのよくない影響を抑えます。
E[d_{fake}] - E[d_{real}] + \lambda E_{\substack{\hat{x}\in P_{\hat{x}}}}[(||\nabla_{\hat{x}}D(\hat{x})||_{2}-1)^{2}] + \beta E[{d_{real}}^2]
定数$\beta$は0.001としました。(これも参考にした資料が0.001と決めていたためです。)
以上が今回用いるDiscriminatorの損失関数となります。
誤差伝搬の最適化手法にはAdamを使い、学習率0.0005、Adamの一次モーメントと二次モーメント(モーメント推定に使う指数減衰率)はそれぞれ0.0と0.99に設定しました。
さらに、256×256の層を学習している時に限って、ある一定回数まで学習を回したならば学習率を0.0001に下げる処理を入れています。
(損失関数以外はGeneratorと全く同じです。)
全体像
上でも紹介した画像の再掲ですが、先ほど作成したGeneratorとDiscriminatorを組み合わせ、Progressive GANを構成します。下のような状態を最終目標にして層ごとに低解像度から順番に学習していきます。
いざ生成
今回はミニバッチ数8、学習回数7500回ごとに次の解像度へ移行するよう設定しました。
頂いた実在のメルアイコンを用いて学習を行い、Generatorにメルアイコンを生成させます。

うまくいっているのではないでしょうか?
毎回違う画像を生成するのに成功しています。解像度の向上もできています。

GANの解説記事とかでありがちなやつメルアイコン生成器でもやってみた pic.twitter.com/6hvfoiD8Ze
— zassou (@zassouEX) August 17, 2020
また、学習途中における出力は下のようになりました。
- 解像度4×4

- 解像度8×8

- 解像度16×16

- 解像度32×32

- 解像度64×64

- 解像度128×128

- 解像度256×256
解像度ごとに学習が進められているのが分かります。
余談:データオーギュメンテーション
機械学習において、データセットの画像の種類を増やす方法の1つとして、「データオーギュメンテーション」という手法がよく用いられています。
学習ごとに、画像のコントラストや色相の変換、左右反転、角度の変更や画像全体を歪ませるなどをランダムに行うことでデータセットの水増しを行うことができます。
しかしメルアイコン生成器においてこれを行う際には問題点があります。まず、メルアイコンの特筆すべき点として、頭が左下から生えてくるようにして描かれているという特徴があります。

このため画像の歪曲、回転、左右反転などは意図にそぐわない学習をしてしまう可能性が高く、やめておいた方が良いでしょう。また、色相の変換も不気味な色のアイコンが出てきてしまうため使いません。
しかし、コントラストの変換に関しては良くない影響がぱっと見少なかったのでデータオーギュメンテーションを用いた状態での学習も行いました。


左が元の画像、右がコントラストを約2倍にした変換済み画像です。
こうして前回よりも圧倒的にデータセットを増やすことができるのではと考え、さらに欲張って学習回数を2倍にした上で学習を実行、出力をしてみました。その結果が以下です。

使わなかった場合と比べて飛躍的によくなったかというとそうでもない気がしますが、こちらの方法でも良さそうな結果は出ています。
まとめ
メルアイコン生成器はProgressive GANによってモード崩壊に打ち勝つだけでなく、解像度を上げることにまで成功しました。
Progressive GANはどうやらやり方やデータセット次第ではフルHDの高解像度の画像を生成することすら可能な手法のようです。(twitterアイコンとして使うのであれば256×256でも十分だとは思いますが。)
実社会においても、特に医療の分野での応用例が活発なようで今後もさらに注目が高まっていく手法ではないかと思われます。
みなさんもProgressive GANでガンガン画像生成しましょう。
ソースコード
書いたコードはこのリポジトリにあります。
https://github.com/zassou65535/image_generator_2
おまけ
今回データセットに用いた約640枚の画像に対し、各pixelごとに平均(torch.mean)をとったところ次のような画像が出てきました。

同様にして様々な統計量で試しました。
以下は左から順に、標準偏差(torch.std)、中央値(torch.median)、最頻値(torch.mode)です。



最小値(torch.min)、最大値(torch.max)も試しましたが、それぞれほとんど真っ黒い画像と真っ白い画像が出てくるだけでした。
ちなみにランダムに抽出した5枚に対して標準偏差(torch.std)を計算したらこんなの出てきた。ちょっとオシャレかも。

他、最小値(torch.min)は640枚近い全てのデータセットに対して計算してしまうとただの真っ黒に近い画像しか出力されませんが、7枚程度に数を抑えるとこんな感じのメルアイコンがガンガン出てきます。
以下はランダムに抽出した7枚に対し最小値を取ったものです。



続編
前作
参考
実践GAN ~敵対的生成ネットワークによる深層学習
つくりながら学ぶ-PyTorchによる発展ディープラーニング
PytorchでPGGANを実装する
PGGAN「優しさあふれるカリキュラム学習」
[DL輪読会]Improved Training of Wasserstein GANs
今さら聞けないGAN(4) WGAN