(この記事は「FPGA Advent Calendar 2018」17日目です)
すみません,技術ポエムです。
「FPGA Advent Calendar 2018」16日目は @youkis さんの「GUINNESS + Intel OpenCLでディーブラーニング(1)」でした。
私は基本的にソフトウェア屋さんですが,以前より FPGA の潜在的可能性には大いに期待していました。そこで,FPGA に関連する共同研究をスタートさせています。
今回は,その共同研究者による研究構想がまだ間に合っていないので,今後ご期待を...!!! ということなのですが,せっかく「FPGA Advent Calendar 2018」がオープンになっていたので,RISC-V のソフトコアを FPGA に載せてプロセッサアーキテクチャとプログラミング言語処理系の研究してみたいというポエムを書くことで,名乗りを上げてみました。
今日の記事は「FPGA Advent Calendar 2018」としては,だいぶ異色な記事だと思います。ポエムで恐縮ですが,よろしければお付き合いくださいませ。
背景
CPU の進化はここ数年,クロック数は伸び悩み,コア数ばかりが増加してます。
たとえば,2006年の Intel Core 2 Extreme X6800 は次のようなスペックでした。
- クロック数: 2.93GHz
- コア数: 2
これに対し,11年経った 2017年の Intel Core i9 7980XE は次のようなスペックです。
- クロック数: 2.6GHz
- コア数: 18
ちなみに 2018年の AMD Ryzen Threadripper 2990WX はこんな感じです。
- クロック数: 3GHz
- コア数: 32
単純比較はもちろんできないのですが,クロック数は伸び悩み,コア数ばかりが増加,という状況は見て取れるのではないかと思います。
同じ時間で1つのコアで処理できる命令の数は クロックの大きさに比例するので,クロック数が伸びないということは,シングルスレッドのプログラムのままでは性能が向上しないということを意味します。そのため,現代においては性能向上させるには,プログラムをマルチスレッドにする,すなわち並列プログラミングが必須です。
ところが従来のプログラミング言語の多くは並列プログラミングをする上で難点があります。
たとえば下図のように複数のコア間でデータを共有しているとします。
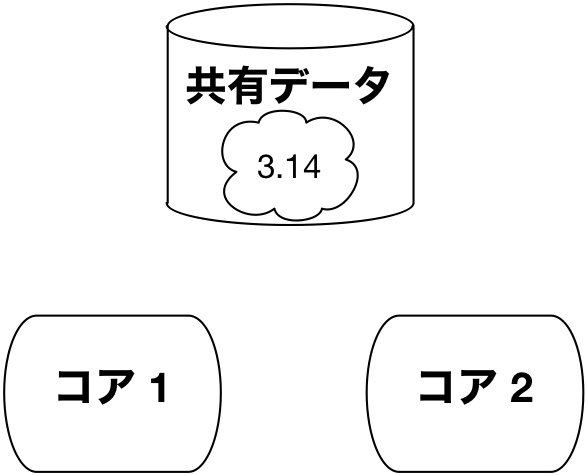
全てのコアで共有データを読込むだけであれば,下図のようにコアそれぞれで勝手に処理をすることができます。
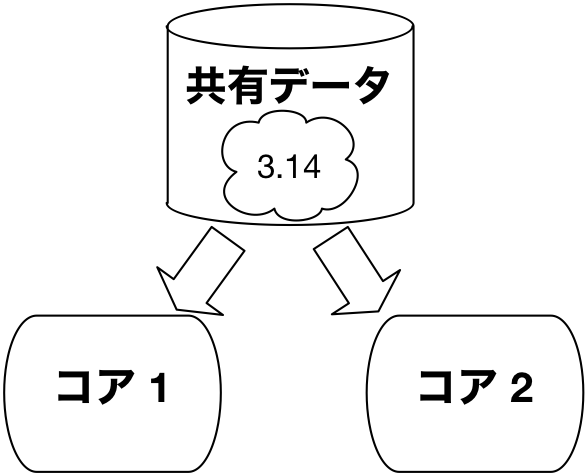
しかし共有データに対する書込みがありうる場合には,下図のように,あるコアが書込みをする前に,同期・排他制御を行う,すなわち,他のコアすべてに通知して共有変数に対する計算を一時停止する必要があります。
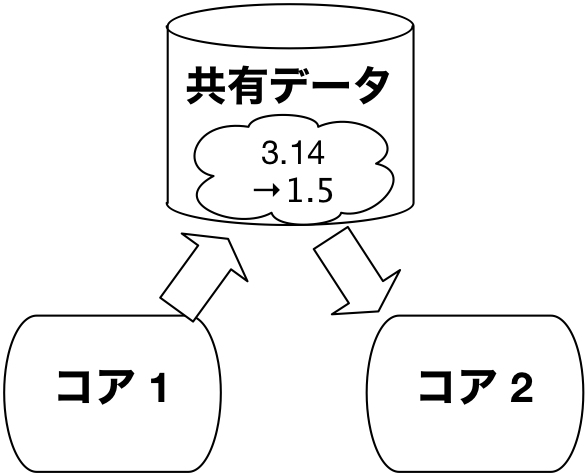
コア数が増えれば増えるほど,同期・排他制御にかかるコストが増大し,性能を発揮できなくなります。
そこで,私たちfukuoka.exはこの問題を Elixir (エリクサー) で解決しています。Elixir ではパラダイム・シフトすなわち発想を根本から転換することを提唱しています。なんと変数の書換えを一切無くしましょうという提案です。これをイミュータブル性と言います。
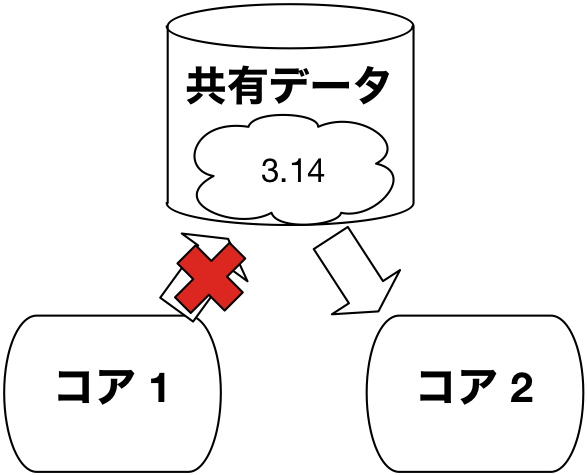
これにより,コア間の同期・排他制御の多くが不要となり,コア数が増えても性能が落ちにくくなります。
でも,変数の書換えなしで,どのようにプログラミングするのでしょうか? Elixir のプログラミング例を見てみましょう。
1..1_000_000
|> Enum.map(foo)
|> Enum.map(bar)
|> IO.inspect
- 1行目の
1..1_000_000は,1から1,000,000までの要素からなるリストを生成します。なお,数字の間の_(アンダースコア)によって,数字を分割するコンマを表します。 - 2,3行目の先頭にある
|>はパイプライン演算子で,パイプライン演算子の前に書かれている記述の値を,パイプライン演算子の後に書かれた関数の第1引数として渡します。すなわち,このような記述と等価です。Enum.map(Enum.map(1..1_000_000, foo), bar) - 2,3行目に書かれている
Enum.mapは,第1引数に渡されるリスト(など)の要素1つ1つに,第2引数で渡される関数を適用します。ここでは関数fooを各要素に適用した後,関数barを各要素に適用します。 - もし,
fooが2倍する関数で,barが1加える関数だった時には,これらの記述により,2倍してから1加える処理を1から1,000,000までの要素に適用したリスト,[3, 5, 7, ...]を生成します。
このように Elixir は,データを変換しながら計算が進行していくようなプログラミング・パラダイムを採用しています。それぞれのデータは,一度値が決まると変わることはない,すなわちイミュータブルです。そのことで,コア数が増えても性能が落ちにくく,並列処理がしやすくなります。クロック数が増えずにコア数が増える現代には,Elixir こそが性能向上の切り札になるだろうと私たち fukuoka.ex は考えています。
その観点から,私は ZEAM というプログラミング言語処理系を研究・開発しています。Elixir のプログラミング言語処理系として従来から用いられている Erlang VM より高い性能を発揮することを目指しています。Qiita にも多数の記事を書いていますので,読んでいただけたら幸いです。(リファレンスは記事の最後に紹介します)
RISC-V に対する期待
RISC-V (リスク・ファイブ)は,パタヘネ本で有名なデイビッド・パターソン(David Patterson)先生が推しているオープンソースの CPU です。RISC-V の研究開発を主導しているのは,Krste Asanović 先生とのことです(@takasehideki 先生,thanks!)。詳しくはRISC-V 原典をご覧いただければと思います。
私はRISC-V 原典を読んで軽く感動を覚えました。RISC-V 原典で解説されている設計の背景にある原理・原則の解説や設計の狙い,裏付けとなるエビデンスなど,素晴らしい!と思いました。以下,私が特に期待を込めている点について,書き下したいと思います。
- 何よりオープンソースであること。しかも BSD ライセンス というゆるいオープンソースライセンスであることは,実に意義深いことです! すなわち RISC-V のソースコードは,その気になれば全て自由に入手できるということですし,RISC-V を参考に独自の拡張をするのも自由であるということです。私はもし独自拡張してもオープンソースのままで行くつもりですが,誰かがその気になれば RISC-V を基にした独自拡張をクローズドにして独占することもできるわけです。
- ISA がシンプルであること。RISC-V の ISA マニュアルと比べて,ARM-32は11倍以上,x86-32に至っては28倍以上もの語数があるそうです。全ての拡張機能を含む RISC-V ISA の要約は,なんとたったの2ページに収まります!
- ISA がシンプルゆえに プロセッサのサイズが小さくで済むこと。ARM-32 Cortex A5 のサイズは,RISC-V Rocket のサイズに比べて,面積比で約2倍,コスト比で約4倍になるそうです。x86 アーキテクチャと比べた場合は,もっと差が開くでしょうね。したがって潜在的には,コア数を面積比の分だけ増やせる,例えば同じプロセス技術を使えば,ARM-32 Cortex A5 に比べて RISC-V Rocket は2倍の数のコア数を備えることができます! これは 並列プログラミングが得意,すなわちマルチコアCPUの活用が得意な Elixir にとっては,とても強い追い風になります。
- ISA がシンプルであるがゆえに,プロセッサの性能を向上させやすいこと。ISA がシンプルだと,クロックサイクルを速めたり,命令あたりのクロックサイクル数(CPI)を小さくしたりするのが容易になります。したがって,ARM-32 Cortex-A9 と比べて全体性能で約30%勝るということです。コア数を増やせるだけでなく,コアあたりの性能も高めやすいということであれば,性能向上に期待が持てます。
- ISA がシンプルであるがゆえに,命令を追加しやすいこと。x86アーキテクチャも ARM アーキテクチャも元々持っている命令の種類が多すぎるので,命令を追加するときには,命令長を大きく増やすしか手立てがありません。RISC-V では拡張の余地を大きく残しているので,命令長を増やすことなく命令を追加することができます。特定ドメイン向けの命令を追加することでパフォーマンスを上げる余地が大いに確保されています。
- キャッシュがヒットしさえすれば,ほぼ全ての命令が1クロックサイクルで完了すること。すなわちプロセッサの性能を向上させやすいだけでなく,機械語コードの実行時間の予測が立てやすいことも意味します。私はハードリアルタイム性の確保やスケジューリングの最適化の目的で,プログラムの実行時間の予測を重要な研究目標としているので,とてもありがたいです。
- 以上のようなさまざまな特性から,プログラミング言語処理系を設計しやすいこと。プログラミング言語処理系を研究・開発する立場としては,とてもありがたいです。
- RISC-V 財団が SIMD 命令より優れていると主張するベクトル機能拡張 RV32V が提案されていること。私は Hastega (ヘイスガ) という Elixir から SIMD 命令や GPU を駆動する超並列高速化処理系を研究開発しています。超並列化マニアとしては,是非とも使いこなしてみたい!
購入を希望する FPGA ボード
本格的に FPGA の研究を始めるために,2019年度に確保する研究予算で,大規模な FPGA ボードを購入することを決意しました。 @takasehideki 先生の助言で,Xilinx Kintex UltraScale FPGA を採用した PCIe ボードである KCU1500 あたりを購入しようかなと思っています。
Xilinx Kintex UltraScale FPGA KCU1500 の LUT 搭載量(システム ロジックセル)は,1,451K です。これだけ大規模なら,いろんな研究ができるな〜と妄想を繰り広げています。
さらにハイエンドならば,Xilinx Alveo U250 も高価ですが魅力的です。LUT搭載量は 1,341K と KCU1500 より少ないですが,帯域幅が77GB/sのオフチップメモリに64GB,帯域幅が38Tb/sのSRAMを54MBも積んでいたり,PCI Express が Gen3 x16 と高速だったりします。この高速性は魅力的ですね!
RISC-V の所要 LUT 数
@takasehideki 先生が苦労して調べてくださいました!
-
SpinalHDL/VexRiscv: 5段パイプライン
- RV32I(乗算・除算を含まない整数演算のみの ISA) かつキャッシュメモリ/MMUなし: 500LUT程度
- RV32IM(乗算・除算命令を含む整数演算のみの ISA) かつキャッシュメモリ/MMUなし: 1,400LUT程度
- RV32IM(乗算・除算命令を含む整数演算のみの ISA) かつ4KB命令・データそれぞれのキャッシュメモリあり,MMUなし: 1,800LUT程度
- RV32IM(乗算・除算命令を含む整数演算のみの ISA) かつ4KB命令・データそれぞれのキャッシュメモリあり,MMUあり: 2,000LUT程度
-
Verilog HDLで記述する RISC-V 命令セットの 教育用アウトオブオーダ実行プロセッサ: 6段パイプライン,アウトオブオーダー実行
- RV32IM(乗算・除算命令を含む整数演算のみの ISA) キャッシュメモリ/MMUなし: 48,000LUT程度
KCU1500に搭載できるコア数は?
先ほどの先行研究結果は,マルチコア実装に必要な不可分命令(RV32A)を搭載しているかどうかが不分明です。またキャッシュメモリが無いか,そう大きくありません。マルチコアだった場合にはキャッシュメモリの調停も必要でしょうから,先ほどのデータから単純にコア数を試算することはできません。
とは言うものの,概算はできるんじゃないかな,と思って計算してみました。
- アウトオブオーダー実行つき6段パイプライン MMU / キャッシュなし構成: 30コア程度
- 5段パイプライン キャッシュ / MMU つき構成: 725コア程度...!
- 5段パイプライン キャッシュ / MMU なし,乗算・除算なし構成: 2,900 コア程度...!!!
すごい! MIMD アーキテクチャで 1,000 コア以上いける可能性があるというのは驚異としか言いようがないですね。
ちなみに AMD Ryzen Threadripper は 32 コア,SIMD アーキテクチャである NVIDIA GeForce GTX 1080 Ti は 3,584 CUDA コア,NVIDIA GeForce RTX 2080 Ti で 4,352 CUDA コアです。
繰り返しますが,もちろん実際にはそんなに簡単ではなく,通常のマルチコアCPUで採用されている密結合プロセッサアーキテクチャだと,コア間の同期・排他制御やメモリバスとキャッシュメモリの設計は非常に難しくなります。この問題をクリアする解決アプローチのアイデアについては後述します。
1,000 コア以上クラスの超マルチコア MIMD プロセッサを見据えた研究
でも,MIMD アーキテクチャで 1,000 コア以上という「超マルチコアCPU」って,厨二病的にワクワクしませんか?
かつて1980年代に「第5世代コンピュータ」という国家プロジェクトがありました。第2次AIブームの真っ盛りの頃,エキスパートシステムの可能性を探求していた時代の国家プロジェクトです。
「第5世代コンピュータ」の主要成果物の1つは,KL1 という超並列論理型言語です。これは,ムーアの法則が終焉するだろうという予測のもとで,性能を向上させるには並列にすることが不可欠であるという前提を立て,考えられる限りの並列性を引き出すことを最重要目標として設定した野心的なプログラミング言語でした。とにかく,命令1つ1つのレベルから並列性を引き出すので,簡単なプログラムでも並列度が1,000以上に到達するという凄まじさです。
あまりにも非現実的な並列性を引き出すので,最適化の観点としては,多すぎる並列性を束ねて数十程度の現実的な粒度の並列性に抑え込んでいました。
現実はムーアの法則がそう簡単には終焉を迎えず,その後も30年以上に渡ってプロセッサの性能は向上し続けました。最近になってようやく「ムーアの法則が終焉したのでは?」とささやかれるようになりました。
そして,前述したように 1,000 コア以上の超マルチコア MIMD プロセッサを実装できる可能性が,2018年の今になってようやく現実のものになったのです!
「第5世代コンピュータ」プロジェクトは,一般には失敗に終わったと評価されることが多いです。しかし,私はそうではなく,時代を先取りしすぎたのだと,学生時代の頃から思っていました。
もちろん,KL1 が志向した並列化のアプローチは,プロセッサ内部の命令レベルの並列化をするのには良いのかもしれませんが,マルチスレッドのコードとして生成してしまうと,パイプラインと分岐予測が発達した現代のプロセッサでは粒度が細かすぎて高速化できないと思います。この点は,Elixir が採用している並列プログラミングモデルの方が優れています。
しかしながら,1,000コア以上クラスの超マルチコア MIMD プロセッサを見据えた時には,KL1 が志向した,逐次的に書かれたプログラムの並列性を読み取れるだけ読み取る,というアプローチは,温故知新的に探求してもいいのではないのかな?と思っています。
Hastega ではその片鱗を実装しようとしています。例えば冒頭で紹介した Elixir のコードですが,
1..1_000_000
|> Enum.map(foo)
|> Enum.map(bar)
|> IO.inspect
このコードは,1,000,000並列のプログラムであると読み取ることができます。しかも,単純で均質で大量にあるデータ(1..1_000_000)を同じような命令列(foo, bar)で処理するという点で,SIMD アーキテクチャに適合します。
1,000コア以上クラスの超マルチコア MIMD プロセッサを見据えたならば,このような要領で並列性をもっと貪欲に探求してもいいと思うのです。
MIMDアーキテクチャのコア間同期・排他制御とメモリアクセスの壁を超えるには
事前に @takasehideki 先生にこの記事を見せた時にいただいた指摘は「通常のマルチコアCPUで1,000コア以上の超並列を実現するには,コア間の同期・排他制御とメモリアクセスに大きな障害がある」というようなコメントでした。
私はこの問題についても,Elixir ならではの解決アプローチがあるんじゃないかと考えています。
Elixir で表現される並列性は,今のところ私が認識しているのは3通りあります。
1つ目は前述の
1..1_000_000
|> Enum.map(foo)
|> Enum.map(bar)
|> IO.inspect
で示されるような並列性です。これは Hastega による超並列高速化が適合するので Hastega 型並列性 とでも呼びましょう。プロセッサアーキテクチャとしては,SIMD アーキテクチャやベクトル機能拡張 RV32V によって効率よく高速化できます。
2つ目は Elixir が標準で用意しているプロセスで表されるような並列性です。これは Sabotender のようなマルチコアCPUのタスクスケジューリングの最適化が適合するので,Sabotender 型並列性 とでも呼びましょう。プロセッサアーキテクチャとしては,MIMD アーキテクチャの出番です。
3つ目は,命令レベル並列性です。プロセッサアーキテクチャとしては,一般にはアウト・オブ・オーダー実行が有効です。
2つ目と3つ目について議論を深めます。
2つ目の Sabotender 型並列性については,Elixir の並行プロセスモデルがアクターモデルである点に注目してみたいと思います。アクターモデルについては次の記事の図が直感的で理解しやすいです(アクターモデルという言葉は出てきませんが「Erlang や Elixir における並行処理」というタイトルでアクターモデル相当の図が登場します)。
挑戦! Elixirによる並行・分散アプリケーションの作り方【第二言語としてのElixir】
アクターモデルでは,ある資源を扱うプロセスは1つに固定されており,資源を利用したい場合には,そのプロセスにメッセージを送って依頼することで表現します。メッセージはキューに到着順で蓄積され,1つずつ取り出して処理します。そのため,資源に関する同期・排他制御は不要になります。
Sabotender ではアクターモデルに準じながら,キューにメッセージがたまって遅滞する問題を解決するために,必要に応じてキューからの取り出しと資源へのアクセスを並列に行うことを検討しています。この場合,資源を扱うプロセス群の間では資源に関する同期・排他制御が必要になりますが,他のプロセスには影響を及ぼしません。
このとき,もし扱う資源が1つしかないのであれば,複数のコアに割り当てるよりも,単一のコアで Node プログラミングモデルのように非同期アクセスとコールバックを用いて処理をするのが合理的です。これに対し,扱う資源が複数存在する場合には,複数のコアを割り当てて並列処理した方が効率的な場合があります。
いずれにせよ,アクターモデルを前提にすると,プロセスと資源に明確な対応関係をつけて同期・排他制御をなくしたり最小限にしたりすることができます。このことを利用して,Sabotender 型並列性の場合,各コアが利用する資源を限定することで,コア間の同期・排他制御を削減できます。
また,Elixir ではプロセスごとに独立したメモリ管理を行います。プロセス間通信によりデータを共有した場合でも,イミュータブル性により各プロセスのメモリにコピーしても問題ありません。したがって,Sabotender 型並列性の場合,基本的に分散メモリアーキテクチャを採用することができます。コア間の通信は,Elixir のアクターモデルに基づくプロセス間通信に沿って設計すれば良いです。これにより,共有メモリを介したコア間の同期・排他制御をなくすことができます。
オフチップメモリおよびSRAMの帯域幅が大きく大容量な Xilinx Alveo U250 を前提にすることにより,Sabotender 型並列性に対応する分散メモリ MIMD アーキテクチャの超並列マルチコア CPU を組める可能性があります。
また3つ目に挙げたアウト・オブ・オーダー実行については,私は少し疑念を持っています。KL1のような細粒度の並列性の抽出を前提とした命令スケジューリングを追求することで,**アウト・オブ・オーダー実行によってコアサイズが極端に大きくなるよりも,アウト・オブ・オーダー実行を無しにしてコアサイズを抑えてコア数を増やしたほうが,性能が向上するのではないか?**と思っています。
さらに Elixir の命令レベルの最適化の研究を進めることで,VLIW アーキテクチャ的なアプローチの復権もありえるかもしれないと思っています。KL1 的なアプローチによる命令レベルの並列性を用いて,VLIW のように複合命令を発行して静的に複数命令発行をするというアプローチを探求してみても面白いんじゃないでしょうか。
所信表明
そういうわけで,私たちは Elixir に最適化されたプロセッサアーキテクチャとプログラミング言語処理系を探求する研究を始めたいと思います。
超マルチコア MIMD プロセッサの方向性も,SIMD の方向性も,RV32V で提唱されているベクトル・アーキテクチャの方向性も,CPU-FPGA 密結合アーキテクチャの方向性も,さらに未知のアーキテクチャの方向性も,いろいろ探求してみたいのです。
かつて RISC が生み出された時には,コンパイラ側の要望や制約を基にプロセッサアーキテクチャを検討していました。近未来の文脈に適合したプロセッサアーキテクチャとプログラミング言語処理系の総合研究をしてみたいのです。
こういう「ぼくがかんがえたさいきょうのぷろせっさとこんぱいら」みたいな厨二病的な研究って,熱くなりませんか?
そう思った研究者の方は,ぜひ join していただければ幸いです。
FPGA で性能検証を繰り返したのち,ASIC にできたらいいなと思っています。
おまけの考察
その1: 割込みをなくす
SpinalHDL/VexRiscvを調べてみた感触として,RISC-V は実に細かくカスタマイズできそうです。
なんと割込みを無しにすることもできます! 実は私が研究開発している省メモリ並行プログラミング機構 Sabotender (サボテンダー) ではタスクの静的スケジューリングの可能性を探求しているのですが,**プロセッサに割込みの機能を無くし,代わりに Sabotender のカーネルで一定時間ごとにポーリングしてソフトウェア的に割込みを実現した方が好都合なのではないか?**と考えていたところだったのです。
「ZEAM開発ログ2018年総集編その2: Elixir 研究構想についてふりかえる(後編)」に書いたように,停止性問題の実用的アプローチによる克服と,それによって可能になる実行時間予測とスケジューリングの最適化を研究しているのですが,それらが可能になると,割込みを用いずに,コードを実行しながらポーリングしても,ハードリアルタイム性を保証できると見込んでいます。
ポーリング方式に変更することで,タスクの静的スケジューリングの可能性と効果がさらに広がります。例えば,割込みがあるとキャッシュメモリの大域的な最適化をしても割込みによって乱れる可能性がありますが,割込みをなくすとキャッシュメモリの大域的最適化が計画通りに効果を発揮します。
これを読んだ @kikuyuta 先生からのリクエストで「制御用 PLC の置換えに利用したいので,ZEAM は ITRON 風の優先度付きキュー(優先順位が高いタスクを実行している間は,より優先順位の低いタスクを実行せずに優先順位が高いタスクの実行に専念する,ただし優先順位逆転問題には配慮する)であってほしい」とのコメントが来ました。
Erlang VM が提供しているタスクの優先順位づけについては,process_flag(Flag :: priority, Level) -> OldLevel が提供しています。
キューには優先度に応じて max, high, normal, low の4つがあり,normal と low は,UNIX風に CPU を割り当てる頻度が normal の方が高いだけで,low にも CPU を割り当てる。max, high, {normal, low} の3段階に対しては ITRON 風で,上のレベルキューに CPU があると,それに必ず CPU を割り当てる。max は Erlang VM が使うのでユーザーは使用禁止。このような優先度の考え方は変わる可能性があるので,依存しないようにする。
(Thanks, @kikuyuta 先生)
難しいのは,単一コアの並行プログラミングでは,ITRON 風の優先度の設計方針は妥当かもしれませんが,マルチコアの並列プログラミングの時代には,厳しいと思います。もし ITRON 風を徹底するとなれば,全てのコアで実行中の優先度を揃える必要があり,そのためにはコア間の同期・排他制御を頻繁に行う必要があるので,オーバーヘッドが大きくなります。
そもそも ITRON 風の優先度の設計方針が生まれたのは,リアルタイム性をできるだけ追求したい,すなわちデッドラインまでに実行が完了することを保証したい,保証できない時には優先順位に従って妥協するということがしたかったわけです。これを実現したいがために,優先度の高いタスクと低いタスクが同じ資源を確保しようとした場合に優先度の高い方が確保し優先度の低い方が待つという方針を採ったり,優先度逆転,すなわち優先度の低いタスクが資源を確保して実行している時に優先度の高いタスクが割り込んでその資源を利用しようとした時には,優先度の低いタスクの優先度を一時的に優先度の高いタスクと同じ優先度にして実行を進めたりしているわけです。
その原点に立ち返って,現代・近未来の状況に合わせて再設計する必要があると私は考えています。
私の考える解決法は,次のようなアプローチです。
- 実行時間推定を使って,デッドラインまでに実行が完了するかを厳密に把握する。
- 資源の利用を,データベースのようにアトミック(不可分)な操作として扱う。このことにより,資源の利用を途中で中断(アボート)する時には,ロールバックする。
- デッドラインが遅くていいタスクが資源を利用中に,デッドラインが早いタスクが割り込んできて,かつデッドラインが遅くていいタスクの完了を待っていては,デッドラインが早いタスクのデッドラインには間に合わない場合には,デッドラインが遅くていいタスクをアボートしてロールバックする。
- もちろんアボートができるだけ起こらないで済むようにスケジューリングを最適化する。
- I/O の性質によっては,ロールバックできないようなものも多々あるので,うまく仮想化して扱えないかを検討する。
- 優先度の低いバックグラウンドタスクやデッドラインがゆるい周期タスクは,デッドラインが密に混み合っている時間区間では起動しない。デッドラインが疎に空いている時間区間では積極的に実行する。
- とくに GC はデッドラインが疎に空いている時間区間で積極的に実行しておくようにスケジューリングする。
その2: 記憶するより再計算
定数に起源がある計算は常に一定の値であるという定理とイミュータブル性,メモリよりALUの方が圧倒的に速いということを考慮すると,あらかじめ計算して記憶しておくよりも再計算した方が速いというケースも多いと思います。そこで,再計算を組込んだメモリ管理というのも研究してみたいです。Sabotender と統合することで,再計算のスケジューリングも最適化するというのも面白そうです。
再計算しても問題ない,すなわち,ある操作を1回行っても複数回行っても結果が同じであることを 冪等性(べきとうせい: idempotence) と言います。
その3: 機械学習ドメイン特化
もちろん機械学習で特に有効な,ベクター積和演算命令や行列演算命令を拡張命令として組込んでみたいという野望もあります。
Elixir とプログラミング言語処理系 ZEAM に興味があるなら
Elixir 入門記事
|> Excelから関数型言語マスター1回目:行の「並べ替え」と「絞り込み」
|> Excelから関数型言語マスター2回目:「列の抽出」と「Web表示」
|> Excelから関数型言語マスター3回目:WebにDBデータ表示【PostgreSQL or MySQL編】
|> Excelから関数型言語マスター4回目:Webに外部APIデータ表示
|> Excelから関数型言語マスター5回目:Webにグラフ表示
|> Excelから関数型言語マスター6回目: Vue.js+内部API(表示編)
|> Excelから関数型言語マスター7回目: Vue.js+内部API(更新編)
Hastega
|> ZEAM開発ログ2018年総集編その1: Elixir 研究構想についてふりかえる(前編)
|> ZEAM開発ログ: Elixir マクロ + LLVM で超並列プログラミング処理系を研究開発中
Sabotender
|> ZEAM開発ログ2018年総集編その2: Elixir 研究構想についてふりかえる(後編)
今までの ZEAM 開発ログ
|> ZEAM開発ログ 目次
おわりに
今回は「RISC-V on FPGA と Elixir で究極のマルチコアシステムを構築しよう!」というタイトルで技術ポエムを書いてみましたが,いかがだったでしょうか?
これを機に Elixir に注目していただき,さらに情熱が湧き上がったならば,私たちの研究に join していただければ幸いです。特に RISC-V に明るいプロセッサアーキテクチャの研究者の方をお待ちしております!
次に私がアドベントカレンダー記事を書くのは12/22の「WebGL Advent Calendar 2018」22日目の「WebGL / WebGPU + Hastega / Elixir / Phoenix で分散/エッジ・コンピューティング」です。お楽しみに!
明日の「FPGA Advent Calendar 2018」17日目は @stranger_yellow さんの「普通のプログラミング初心者がAutoencoderをFPGAに実装してみた」です。こちらもお楽しみに!