(この記事はFPGA Advent Calendar 2018 18日目です)
※FPGAに本格的に触れ始めてまだ3-4ヶ月のB4です。初心者です。
※AutoencoerをFPGAに実装する方法を記した記事ではありません。その過程で知ったけれども,研究会とかではあまり話さない…みたいなことをつらつらと書こうと思います。ソースコードはのせていません。
※工業大学生です。文章力に期待をしてはいけません。
Autoencoderとは
漢字では「自己符号化器」と記すらしいです。漢字で記す方がしっくりきますね。
最近流行っている(?)ニューラルネットワークのモデルの一つで,以下の図のように,大きく2つの部分に分けて考えることができます。
Encoder部分は高次元な入力から低次元へと符号化する部分,Decoder部分は低次元から入力と同じ次元へと復号する部分です。
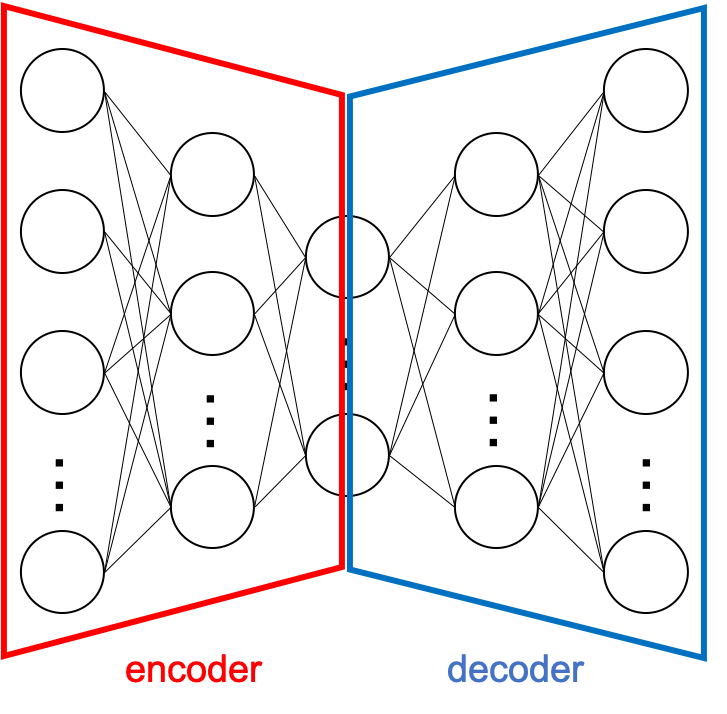
入力データを出力に対する教師データとして与えることで,入力から符号化,復号化するEncoder,Decoderを学習します。
今回は,全結合層で構成されたAutoencoderを作成しました。
以下のような式で表されます.
Xは入力,EはEncoder,DはDecoder,g()は活性化関数,Wは重みパラメータ(行列),bはバイアスです.
\begin{align}
E(X)&=g(X\cdot W+b_E)\\
D(X)&=g(E(X)\cdot W^T + b_D)
\end{align}
ニューラルネットワークとしては,とても軽いモデルだと思います。このような簡単な構造のモデルでも,外れ値検出やノイズ除去等,適合する用途があれば,優れた性能を出すことができます。用途に応じてニューラルネットワークのモデルを選ぶというのは,とても重要だと思います。
FPGAに実装するときの問題点
GPUで学習したAutoencoderをFPGAに実装し,推論させてみます。
ニューラルネットワークをFPGAに実装する際にボトルネックとして挙げられるのが,パラメータ数の多さです。FPGAは限られたリソースで実装する必要があります。そのため,GPUで学習したそのままのモデルでは,メモリが足りなくて実装することができません。
私が行った実装では,スパース化を行うことによって,パラメータ数を削減しました。

スパース化は,簡単に言ってしまえば,0に近いパラメータを「0」として扱い,残った非零パラメータだけを記憶することによって,パラメータ数を削減する方法です。パラメータ数が減るのでメモリ量が削減できますし,そもそもの乗算の回数も減らせますので,推論の計算も(たぶん)早く終わります。FPGAに実装することができれば,消費電力の削減に加え,計算時間が短くなることにより,トータルの消費電力量の削減も期待できます。
FPGA実装
ここから本編です。
ニューラルネットワークの本質的な計算は,積和演算です。今回の全結合層を用いたAutoencoderの場合,Matrix-Vectorの計算としてみれば,それほど難しい実装では無いと思います。パラメータがメモリに乗ってさえしまえば,大丈夫です(そこが一番難しい)。
今回の実装では,ビットストリーム生成にXilinx SDSoCを,評価ボードはZedBoardを使用しました。Autoencoderの推論を行うC/C++のコードを用意して,Buildしてみます。
32bit浮動小数点
まずはスパース化したモデルそのまま,32bit浮動小数点で。

パイプライン化等はしましたが,それ以外は特に高速化の処理はしていないので,このくらいの速度かな…とは思います.
(※注)スパース化をしているため,計算回数はノードにより異なります。maxは,そのうち最大のループ回数を回した場合の値なので,実際の計算時間とは異なります。あくまでこの後のデータとの参考程度に…
16bit浮動小数点
ニューラルネットにおいては,その計算に用いるパラメータのbit幅を削減しても,結果には大きく影響が無いことが知られています.
とりあえず,先程の半分の精度である16bit浮動小数点でも実装してみます.bit幅が半分になりますので,重みパラメータの占める容量も半分になります。"hls_half"をincludeし,floatで宣言している部分を,halfに置き換えるだけで実装できます.
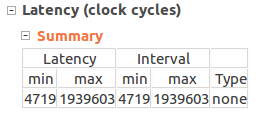
16bit浮動小数点の方が,計算が遅いという結果になりました.感覚的には早くなりそうなものですが…
原因を探ってみる
Vivado HLSを用いて,どこで時間がかかっているかを見てみます.
すると,各ノードに乗算の結果を加算する部分で,計算時間に違いがあることがわかりました.
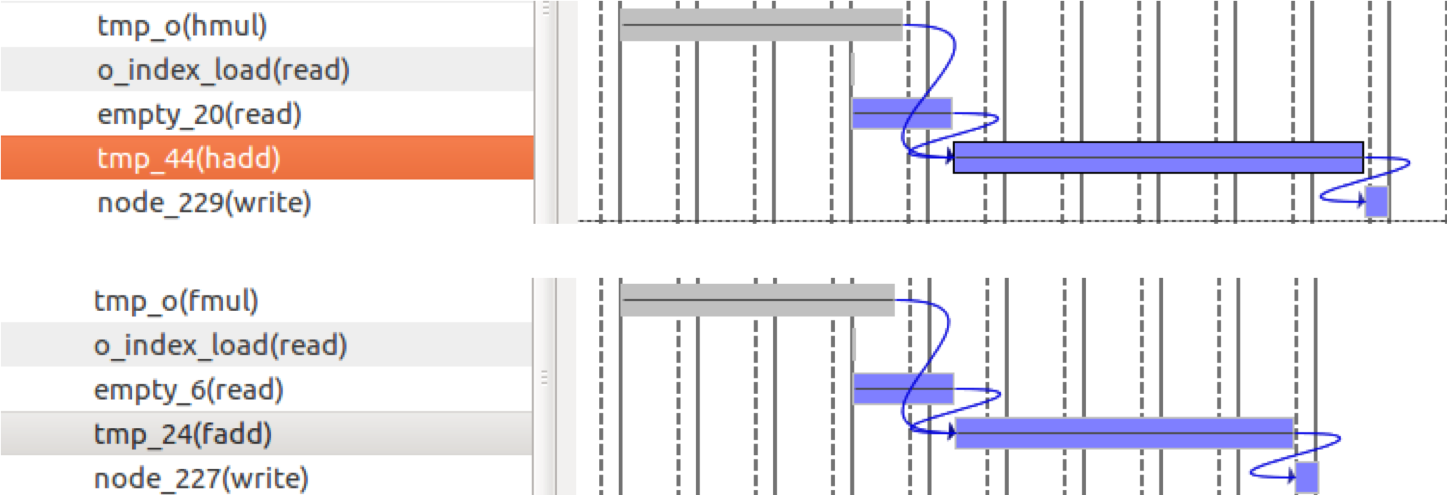
上段:float16 下段:float32
ある出力ノードの計算をするためには,複数の入力ノードからの乗算の結果を加算する必要があります.
output_j = \sum_i w_{i,j} \times input_i
今回の実装では計算資源をできるだけ節約するため,ニューラルネットワークの計算のための乗算器,加算器はひとつずつしか用意しませんでした.そのため,一度outputから値を読み出し,そこに乗算結果を加算,そしてoutputに再び書き戻すという動作をさせていました.その過程に時間のかかる計算が存在すると,その分だけ待つ必要がありました.
今回の場合は,32bit浮動小数点の加算よりも,16bit浮動小数点の加算の方が時間がかかるために,16bit浮動小数点の実装の方が計算が遅いという結果になったようです.
今回のまとめ
Autoencoderを私が想定していたようには実装できませんでしたというお話でした。
重みパラメータの容量は,bit幅の調整等でかなり削減が期待できますが,bit幅を小さくしたからといって,必ずしも計算が早くなるわけではありません。むしろ,実装によっては遅くなる場合もあります。用途によって,計算の高速化等が求められるならば,まずはそれを達成するためのアーキテクチャから考えた方が良さそうです(そこが難しい…)。