(この記事は「言語実装 Advent Calendar 2018」の2日目です)
ZACKYこと山崎進です。
「言語実装 Advent Calendar 2018」 1日目は @blackenedgold (κeen) さんの「JITあれこれ」でした。
「言語実装 Advent Calendar 2018」2日目の今日は,私が研究開発している Elixir 処理系,micro Elixir / ZEAM についてお話ししたいと思います。
この記事は,2018年12月1日に公開した2つのアドベントカレンダー記事,「技術的ポエム Advent Calendar 2018」1日目の「ZEAM開発ログ2018ふりかえり第1巻(黎明編): 2017年秋の出会いから2018年2月にElixirを始めるに至った経緯について」と,「fukuoka.ex Elixir/Phoenix Advent Calendar 2018」1日目の「ZEAM開発ログ2018年総集編その1: Elixir 研究構想についてふりかえる(前編)」の続きでもあります。
Elixir の利点〜並列処理の観点
私たち fukuoka.ex がなぜ Elixir に注目しているかというと,Elixir の持つ並列処理性能と耐障害性が高い上に,文法が平易で記述が容易であるからです。ここでは,並列処理性能に注目してみましょう。
Elixir では MapReduce に基づくプログラミングスタイルが広く普及しています。例えば次のようなコードです。
1..1_000_000
|> Enum.map(foo)
|> Enum.map(bar)
- 1行目の
1..1_000_000は,1から1,000,000までの要素からなるリストを生成します。なお,数字の間の_(アンダースコア)によって,数字を分割するコンマを表します。 - 2,3行目の先頭にある
|>はパイプライン演算子で,パイプライン演算子の前に書かれている記述の値を,パイプライン演算子の後に書かれた関数の第1引数として渡します。すなわち,このような記述と等価です。Enum.map(Enum.map(1..1_000_000, foo), bar) - 2,3行目に書かれている
Enum.mapは,第1引数に渡されるリスト(など)の要素1つ1つに,第2引数で渡される関数を適用します。ここでは関数fooを各要素に適用した後,関数barを各要素に適用します。もし,fooが2倍する関数で,barが1加える関数だった時には,これらの記述により,2倍してから1加える処理を1から1,000,000までの要素に適用したリスト,[3, 5, 7, ...]を生成します。
このような**MapReduceによる記述は並列処理にとても向いています。**この例だと,リストの1つ1つの要素に対して,関数 foo と bar を順番に適用するわけですが,それぞれの要素に対する計算は互いに干渉しません。そのため,各要素の計算を異なるコアに配置して独立させて計算しても結果は変わらないですし,互いにコミュニケーションを取り合いながら同期させて計算する必要もありません。
このことを利用して,Elixir では Flow という並列処理ライブラリが開発されてきました。 Enum.map のときとコードはとても似ています。
1..1_000_000
|> Flow.from_enumerable() # リストの要素を各コアに分配する
|> Flow.map(foo)
|> Flow.map(bar)
|> Enum.to_list() # リストに戻す
なんと,このように書くだけで,並列処理をしてくれます。とても簡単ですね。
しかし,Flow によって,I/Oバウンド(CPUよりもI/Oに負荷がかかる状態)なプログラムはほぼ確実に高速化するのですが,CPUバウンド(I/OよりもCPUに負荷がかかる状態)なプログラムはよほど負荷の大きなプログラムでないと高速化しないです。
処理の流れを解析すると,現状の Elixir / Erlang VM の処理系で Flow を扱う時には,リストを各コアに分配する前処理の部分や,各コアで計算した結果を集約する後処理の部分に実行時間が多くかかっていることがわかりました。前処理・後処理を含めた並列処理全体をネイティブコードで実行できるようになると,格段に高速化されることだろうと予測できます。
Hastega / micro Elixir / ZEAM の研究開発
そこで,私たちは Elixir の一部機能に限定した micro Elixir というプログラミング言語を策定し,従来の Erlang VM に代わる処理系 ZEAM を研究開発しています。この新しいプログラミング言語処理系を micro Elixir / ZEAM と称しています。
また,この並列処理に関わる機能のことをとくに Hastega (ヘイスガ)と呼んでいます。 Elixir という名称はファイナルファンタジー由来なのですが,Hastega もファイナルファンタジー由来で,最強のスピードアップ呪文です。並列処理を高速化する機能の名称として最もふさわしい名称ではないでしょうか。
Hastega の研究で最初に取り組んだのは,Elixir から GPU を駆動させる仕組みづくりでした。この取り組みについてはこちらにまとまっています。


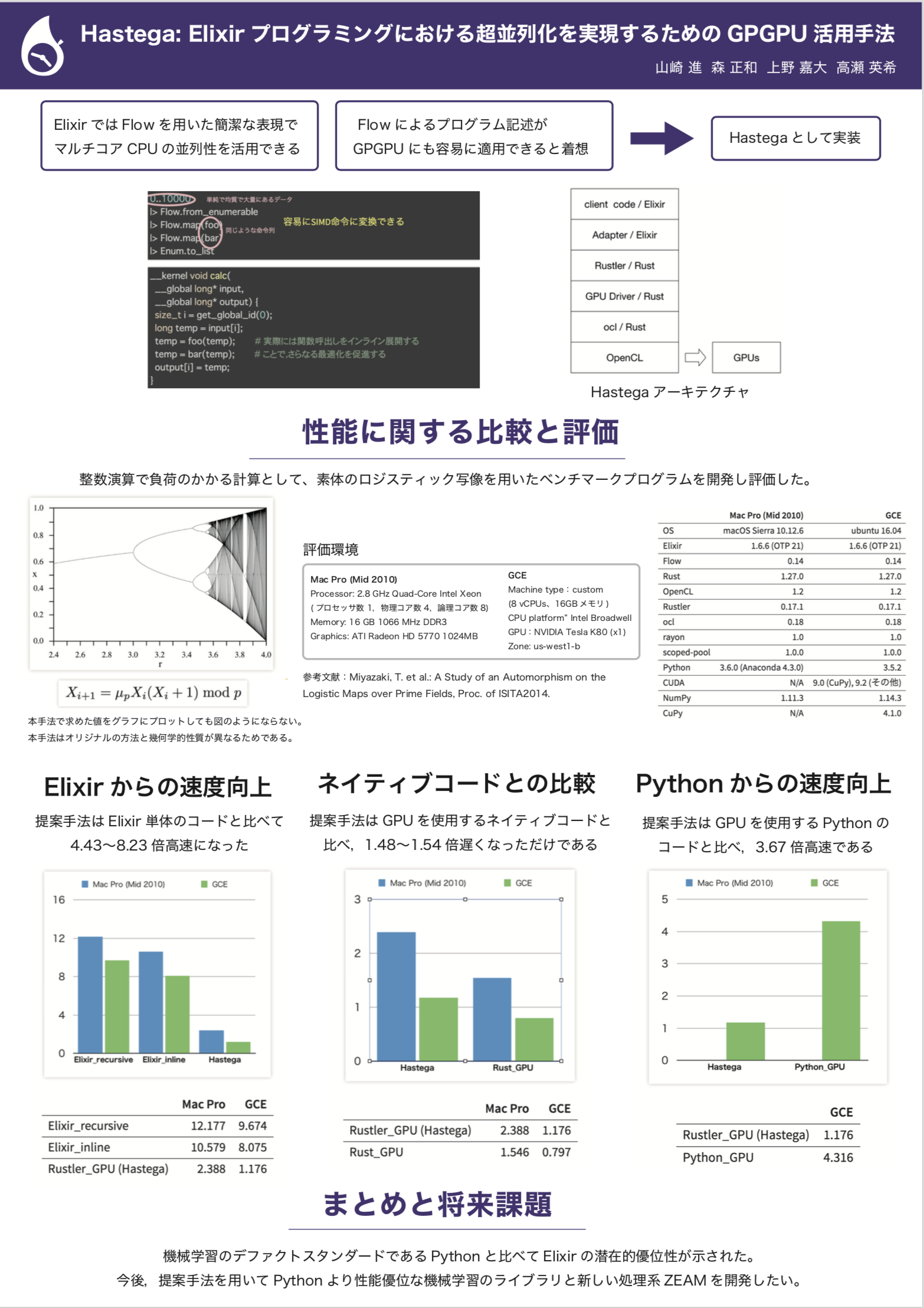
今度,Lonestar ElixirConf 2019 (2月28日〜3月2日 テキサス州 オースティン)でも発表してきます!
原理としては,前述のコード(下記)
1..1_000_000
|> Enum.map(foo)
|> Enum.map(bar)
は,単純で均質で大量にあるデータ 1..1_000_000 と 同じような命令列 foo |> bar で構成されます。したがって,これはGPUの基本アーキテクチャであるSIMDに適合します。次のようにOpenCLのネイティブコードで書いてみると,先ほどのコードから容易に変換できそうです。
__kernel void calc(
__global long* input,
__global long* output) {
size_t i = get_global_id(0);
long temp = input[i];
temp = foo(temp);
temp = bar(temp);
output[i] = temp;
}
このアイデアに基づいてプロトタイプを実装してみたところ,Python の NumPy ライクな GPU 実行系である CuPy での実行と比べて,3倍以上速度向上するという結果が得られました。
Hastega には SIMD 命令を用いた並列実行機能も備えようとしています。現時点では Rust によるループに対する SIMD 命令生成をそのまま利用しています。
micro Elixir / ZEAM の基本構成
micro Elixir / ZEAM を開発するには,Elixir コードを解析して中間コードにする部分(解析部)と,中間コードを元に最適化・コード生成する部分(合成部)を開発する必要があります。
私たちが採用している基本構成は次のようにします。
- 解析部: Elixir の言語処理系をそのまま利用し Elixir マクロを用いて拡張する
- 合成部: 近年のコンパイラで広く普及している LLVM を用いて,Elixir からコードを生成・実行できるようにする
それぞれを採用した理由は次の通りです。
- Elixirマクロは,簡潔な記述ながらとても強力な機能を有しています。また,既存の Elixir の文法であれば,とくに容易に記述できます。今回は,Elixir の文法を元に処理系を開発することから,Elixir マクロの採用により,開発効率が向上します。
- LLVMは,対応しているプロセッサが多く,最適化も充実しています。したがって LLVM のコードを生成することで,幅広いアーキテクチャに最適なコードを生成できる可能性が高まります。
今のところ,LLVM については,Elixir から Rustler 経由で Rust の LLVM バイディングである llvm-sys につなげて出力しています。
現在用いている llvm-sys は,GPUを含むクロスコンパイルについてはテストしていないということなので,もしかすると,Elixir-LLVM バインディングを新たに開発する必要性が出てくるかもしれません。
現在の進捗と今後の展望
Elixir マクロを使った解析部については,下記の記事のような感じで実装をしています。
Elixir マクロ 解析部
|> ZEAM開発ログ v.0.4.10 マクロを使って micro Elixir のフロントエンドを作ってみる (試行錯誤編)
|> ZEAM開発ログ v.0.4.11 マクロを使って micro Elixir のフロントエンドを作ってみる (黎明編)
|> ZEAM開発ログ v.0.4.12 マクロからコンパイルエラーやウォーニングを生成する
|> ZEAM開発ログ v.0.4.13 マクロを使って micro Elixir のフロントエンドを作ってみる (野望編)
LLVM による合成部については,下記の記事のような感じで実装しています。
LLVM 合成部
|> ZEAM開発ログ v.0.4.15 Rustler から LLVM 7.0 を動かしてみた
|> ZEAM開発ログ v.0.4.15.1 Rustler から LLVM を呼出してコード生成したあと,Elixirに戻ってから実行する
|> ZEAM開発ログ v.0.4.15.2 LLVMコード実行をネイティブコード実行可否判断して初期設定するようにする
|> ZEAM開発ログ v.0.4.15.3 LLVM生成/実行でエラーメッセージをElixirで受け取れるようにする
現在,この両者をつなげ,算術演算を行う micro Elixir のコードをネイティブコードに変換して Elixir から呼び出せるようにする処理系を一所懸命実装しているところです。
それが出来上がったら,リスト構造と Enum.map のパイプラインを SIMD 命令を用いたループに変換するようにします。ベンチマークプログラムの作り方にもよると思うのですが,元の Enum.map を用いたプログラムより10〜20倍くらい高速になりえるんじゃないかと期待しています。
マルチコア活用についても研究していきたいところですが,Rustler のスレッドは Rust のスレッドを用いる構成になっていて,Erlang VM の軽量プロセスを用いる構成にはなっていないので,独自のベンチマーク結果から考察する限り,意外と重たいようです。この点については Erlang VM の軽量プロセスを用いる方法を探求するか,Erlang VM を離れて独自の処理系を作っていくか,というところになってきます。この他にも,マルチコア並列の場合は処理の分配と集計で同期を取る必要性があり,ここを高速化しないと全体の高速化が頭打ちになるという問題があります。このあたりの全体の設計を考えていく必要があるかなと思います。
一方,GPU駆動については,llvm-sys で GPU 向けクロスコンパイルができるかどうかにかかっています。もしこれが難しいとなると,llvm-sys を改造するか,新たにElixir-LLVMバインディングを実装するということになります。どちらもかなり工数がかかりそうです。
他には, Enum と Stream で登場する関数を一通り,リストだけでなく他のデータ構造も含めて,SIMD ループ並列化できるように頑張るという道筋もあります。もしこれが実現できると,Elixir / Phoenix 界隈にとっては大きな貢献になりそうです。ソースコードはマクロを多用した難解なものでしたので,テストコードで推察される要求仕様に沿って実装することになるかなと思います。工数はマルチコア化やGPU駆動より少ないんじゃないかと見積もりましたが,どうですかね。
なお,「ZEAM開発ログ 目次」には,試行錯誤を含めて研究開発の全過程を記録しています。(最近の研究成果は更新が間に合っていないですが)
おわりに
現在研究開発している Hastega / micro Elixir / ZEAM について,軽くご紹介しましたがいかがだったでしょうか? 2018年のアドベントカレンダー各所でも展開していきます! 次に私がアドベントカレンダーの記事を書くのは2018年12月3日の「Elixir Advent Calendar 2018」4日めの「ZEAM開発ログ番外編: Elixir で再帰とStreamのどちらが速いのか,素因数分解で比較してみた」です。お楽しみに!
「言語実装 Advent Calendar 2018」,明日の記事は @yhara さんの「Shiika進捗」です。こちらもお楽しみに!