TensorFlowのテストの処理がGPUのOOMで落ちるので、途中でメモリーを開放したい
環境
Windows 10
NVIDIA GeForce GTX 1660 Ti
Python 3.10.11
Pillow 9.5.0
tensorflow 2.9.0
numpy 1.24.3
状況
GLADNet(https://github.com/weichen582/GLADNet )のフォーク版でTensorFlow2.0用に作成されたものである、GLADNet2.0(https://github.com/abhishek-choudharys/GLADNet.git )をかなり大きいデータセット(おおよそ1.3TB)に使用(テストのみ)したいと考えています。
テストデータのディレクトリ構造(読み飛ばしてもらっても構いません)
split/
├ 0-100/ /* 1番目から100番目の画像のグループ*/
├ 100-200/ /* 101番目から200番目の画像のグループ*/
├ 200-300/ /* 201番目から300番目の画像のグループ*/
├ 300-400/ /* 301番目から400番目の画像のグループ*/
├ 400-500/ /* 401番目から500番目の画像のグループ*/
├ SOMETHING(401番目の画像のグループ)/
├ SOUTH(402番目の画像のグループ)/
├ ・
├ ・
├ ・
├ YESTERDAY(499番目の画像のグループ)/ #計500個ある画像のグループから構成されており
└ YOUNG(500番目の画像のグループ)/ #1つのグループにつきそれぞれ以下の3つのフォルダ
├ test/ #testフォルダの中には50個
├ train/ #trainフォルダの中には1000個
└ val/ #valフォルダの中には50個
├ YOUNG_01
├ YOUNG_02
├ ・
├ ・ #testにはvalと同じように50個のフォルダがあり
├ ・ #trainには0001から1000までフォルダがある
├ YOUNG_49
└ YOUNG_50
├ 1.png
├ 2.png
├ ・
├ ・ #そのフォルダのなかにそれぞれ1~29までのpngファイルが保存されている
├ ・ #画像一枚につき平均80KBくらい
├ 28.png
└ 29.png
画像一枚につき80KBとすると
80KB × 29 × (50+1000+50) × 500 ≒ 1.3TB
うまく説明できなくてすみません;;
テストデータと同じ形式で作成した画像を保存したい
例えば、"E:\split\0-100\ABOUT\test\ABOUT_00001\1.png"を
"E:\glad\0-100\ABOUT\test\ABOUT_00001\1.png"に変換したい
解決したいこと
もとのgithubのGLADNet2.0に変更を加えてforループでテストディレクトリの下の階層のなかの画像まで探索できるように変更しました。
また、tf.config.experimental.set_memory_growth(gpu, True)でメモリを使う分だけ割り当てるように設定しました。
しかし、メモリの使用率が漸近的に増えていき、およそ1000個目のフォルダ(1フォルダにつき29枚の画像)でOOMのエラーで落ちてしまいました。どのようにすれば大量のデータにテストをできるようになるのかについてヒントを頂きたいです。
使用したプログラム(main.py)
プログラム全体はgithubにもあげています(https://github.com/yusakuchiba/GLADNet_onlytest.git)
from __future__ import print_function
import os
import argparse
from glob import glob
from PIL import Image
import tensorflow as tf
from model import lowlight_enhance
from utils import *
parser = argparse.ArgumentParser(description='')
parser.add_argument('--use_gpu', dest='use_gpu', type=int, default=1, help='gpu flag, 1 for GPU and 0 for CPU')
parser.add_argument('--gpu_idx', dest='gpu_idx', default="0", help='GPU idx')
parser.add_argument('--gpu_mem', dest='gpu_mem', type=float, default=0.8, help="0 to 1, gpu memory usage")
parser.add_argument('--phase', dest='phase', default='train', help='train or test')
parser.add_argument('--epoch', dest='epoch', type=int, default=50, help='number of total epoches')
parser.add_argument('--batch_size', dest='batch_size', type=int, default=8, help='number of samples in one batch')
parser.add_argument('--patch_size', dest='patch_size', type=int, default=384, help='patch size')
parser.add_argument('--eval_every_epoch', dest='eval_every_epoch', default=1, help='evaluating and saving checkpoints every # epoch')
parser.add_argument('--checkpoint_dir', dest='ckpt_dir', default='./checkpoint', help='directory for checkpoints')
parser.add_argument('--sample_dir', dest='sample_dir', default='./sample', help='directory for evaluating outputs')
parser.add_argument('--save_dir', dest='save_dir', default='./test_results', help='directory for testing outputs')
parser.add_argument('--test_dir', dest='test_dir', default='./data/test/low', help='directory for testing inputs')
args = parser.parse_args()
#save_dir = './test_results'
def lowlight_test(lowlight_enhance):
data_type = ["test","train","val"]
if args.test_dir == None:
print("[!] please provide --test_dir")
exit(0)
if not os.path.exists(args.save_dir):
os.makedirs(args.save_dir)
for word in sorted(os.listdir(args.test_dir)):
#ディレクトリの下の階層を探索するループ
word_dir = os.path.join(args.test_dir,word)
if not os.path.exists(os.path.join(args.save_dir,word)):
os.makedirs(os.path.join(args.save_dir,word))
for dt in data_type:
#ディレクトリの下の階層を探索するループ
dt_dir = os.path.join(word_dir,dt)
if not os.path.exists(os.path.join(args.save_dir,word,dt)):
os.makedirs(os.path.join(args.save_dir,word,dt))
for frame in sorted(os.listdir(dt_dir)):
#ディレクトリの下の階層を探索するループ
frame_dir = os.path.join(dt_dir,frame)
if not os.path.exists(os.path.join(args.save_dir,word,dt,frame)):
os.makedirs(os.path.join(args.save_dir,word,dt,frame))
test_low_data_name = glob(frame_dir + '\*.*')
test_low_data = []
test_high_data = []
save_dir = os.path.join(args.save_dir,word,dt,frame)
for idx in range(len(test_low_data_name)):
[2:])))
if not os.path.exists(os.path.join("E:\split",*(test_low_data_name[idx].split("\\")[2:]))):
#すでに処理済みの画像はリストには入れないように条件分岐
#これによって無駄なメモリの使用を抑えたい
test_low_im = load_images(test_low_data_name[idx])
test_low_data.append(test_low_im)
lowlight_enhance.test(test_low_data, test_high_data, test_low_data_name, save_dir)
def main(_):
if args.use_gpu:
print("[*] GPU\n")
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu_idx
gpus = tf.config.list_physical_devices('GPU')
if gpus:
try:
# Currently, memory growth needs to be the same across GPUs
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
logical_gpus = tf.config.list_logical_devices('GPU')
print(len(gpus), "Physical GPUs,", len(logical_gpus), "Logical GPUs")
except RuntimeError as e:
# Memory growth must be set before GPUs have been initialized
print(e)
gpu_options = tf.compat.v1.GPUOptions(per_process_gpu_memory_fraction=args.gpu_mem)
with tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(gpu_options=gpu_options)) as sess:
model = lowlight_enhance(sess)
if args.phase == 'train':
lowlight_train(model)
elif args.phase == 'test':
lowlight_test(model)
else:
print('[!] Unknown phase')
exit(0)
else:
print("[*] CPU\n")
with tf.compat.v1.Session() as sess:
model = lowlight_enhance(sess)
if args.phase == 'train':
lowlight_train(model)
elif args.phase == 'test':
lowlight_test(model)
else:
print('[!] Unknown phase')
exit(0)
if __name__ == '__main__':
tf.compat.v1.app.run()
使用したプログラム(model.py)
from __future__ import print_function
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import time
import random
from PIL import Image
import tensorflow as tf
import numpy as np
from utils import *
import logging
# ログの設定
logging.basicConfig(
filename='app.log', # ログを保存するファイル名
level=logging.WARN, # ログのレベル (INFO, WARNING, ERROR, DEBUGなど)
format='%(asctime)s - %(levelname)s - %(message)s'
)
def FG(input_im):
with tf.compat.v1.variable_scope('FG'):
input_rs = tf.image.resize(input_im, (96, 96), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
p_conv1 = tf.compat.v1.layers.conv2d(input_rs, 64, 3, 2, padding='same', activation=tf.nn.relu) # 48
p_conv2 = tf.compat.v1.layers.conv2d(p_conv1, 64, 3, 2, padding='same', activation=tf.nn.relu) # 24
p_conv3 = tf.compat.v1.layers.conv2d(p_conv2, 64, 3, 2, padding='same', activation=tf.nn.relu) # 12
p_conv4 = tf.compat.v1.layers.conv2d(p_conv3, 64, 3, 2, padding='same', activation=tf.nn.relu) # 6
p_conv5 = tf.compat.v1.layers.conv2d(p_conv4, 64, 3, 2, padding='same', activation=tf.nn.relu) # 3
p_conv6 = tf.compat.v1.layers.conv2d(p_conv5, 64, 3, 2, padding='same', activation=tf.nn.relu) # 1
p_deconv1 = tf.image.resize(p_conv6, (3, 3), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
p_deconv1 = tf.compat.v1.layers.conv2d(p_deconv1, 64, 3, 1, padding='same', activation=tf.nn.relu)
p_deconv1 = p_deconv1 + p_conv5
p_deconv2 = tf.image.resize(p_deconv1, (6, 6), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
p_deconv2 = tf.compat.v1.layers.conv2d(p_deconv2, 64, 3, 1, padding='same', activation=tf.nn.relu)
p_deconv2 = p_deconv2 + p_conv4
p_deconv3 = tf.image.resize(p_deconv2, (12, 12), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
p_deconv3 = tf.compat.v1.layers.conv2d(p_deconv3, 64, 3, 1, padding='same', activation=tf.nn.relu)
p_deconv3 = p_deconv3 + p_conv3
p_deconv4 = tf.image.resize(p_deconv3, (24, 24), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
p_deconv4 = tf.compat.v1.layers.conv2d(p_deconv4, 64, 3, 1, padding='same', activation=tf.nn.relu)
p_deconv4 = p_deconv4 + p_conv2
p_deconv5 = tf.image.resize(p_deconv4, (48, 48), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
p_deconv5 = tf.compat.v1.layers.conv2d(p_deconv5, 64, 3, 1, padding='same', activation=tf.nn.relu)
p_deconv5 = p_deconv5 + p_conv1
p_deconv6 = tf.image.resize(p_deconv5, (96, 96), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
p_deconv6 = tf.compat.v1.layers.conv2d(p_deconv6, 64, 3, 1, padding='same', activation=tf.nn.relu)
p_output = tf.image.resize(p_deconv6, (tf.shape(input=input_im)[1], tf.shape(input=input_im)[2]), method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
a_input = tf.concat([p_output, input_im], axis=3)
a_conv1 = tf.compat.v1.layers.conv2d(a_input, 128, 3, 1, padding='same', activation=tf.nn.relu)
a_conv2 = tf.compat.v1.layers.conv2d(a_conv1, 128, 3, 1, padding='same', activation=tf.nn.relu)
a_conv3 = tf.compat.v1.layers.conv2d(a_conv2, 128, 3, 1, padding='same', activation=tf.nn.relu)
a_conv4 = tf.compat.v1.layers.conv2d(a_conv3, 128, 3, 1, padding='same', activation=tf.nn.relu)
a_conv5 = tf.compat.v1.layers.conv2d(a_conv4, 3, 3, 1, padding='same', activation=tf.nn.relu)
return a_conv5
class lowlight_enhance(object):
def __init__(self, sess):
self.sess = sess
self.base_lr = 0.001
#self.g_window = self.gaussian_window(self.input_shape[0],self.input_shape[2],0.5)
self.input_low = tf.compat.v1.placeholder(tf.float32, [None, None, None, 3], name='input_low')
self.input_high = tf.compat.v1.placeholder(tf.float32, [None, None, None, 3], name='input_high')
#self.norm_const = self.input_low[2]*self.batch_size
self.output = FG(self.input_low)
self.loss = tf.reduce_mean(input_tensor=tf.abs((self.output - self.input_high) * [[[[0.11448, 0.58661, 0.29891]]]]))
self.global_step = tf.Variable(0, trainable = False)
self.lr = tf.compat.v1.train.exponential_decay(self.base_lr, self.global_step, 100, 0.96)
optimizer = tf.compat.v1.train.AdamOptimizer(self.lr, name='AdamOptimizer')
self.train_op = optimizer.minimize(self.loss, global_step=self.global_step)
self.sess.run(tf.compat.v1.global_variables_initializer())
self.saver = tf.compat.v1.train.Saver()
print("[*] Initialize model successfully...")
def load(self, saver, ckpt_dir):
ckpt = tf.train.get_checkpoint_state(ckpt_dir)
if ckpt and ckpt.model_checkpoint_path:
full_path = tf.train.latest_checkpoint(ckpt_dir)
try:
global_step = int(full_path.split('/')[-1].split('-')[-1])
except ValueError:
global_step = None
saver.restore(self.sess, full_path)
return True, global_step
else:
print("[*] Failed to load model from %s" % ckpt_dir)
return False, 0
def test(self, test_low_data, test_high_data, test_low_data_names, save_dir):
tf.compat.v1.global_variables_initializer().run()
print("[*] Reading checkpoint...")
load_model_status, _ = self.load(self.saver, './model/')
if load_model_status:
print("[*] Load weights successfully...")
pass
print("[*] Testing...")
total_run_time = 0.0
for idx in range(len(test_low_data)):
#print(test_low_data_names[idx])
[_, name] = os.path.split(test_low_data_names[idx])
suffix = name[name.find('.') + 1:]
name = name[:name.find('.')]
if not os.path.exists(os.path.join(save_dir, name +"."+ suffix)):
print("作成中")
input_low_test = np.expand_dims(test_low_data[idx], axis=0)
start_time = time.time()
result = self.sess.run(self.output, feed_dict = {self.input_low: input_low_test})
total_run_time += time.time() - start_time
save_images(os.path.join(save_dir, name +"."+ suffix), result)
発生している問題・エラー
引数を与えて実行します。GPUの使用割合は1(100パーセント)、モードはテストで、テストディレクトリと保存先のディレクトリを引数で渡します。
python main.py --use_gpu=1 --gpu_idx=0 --gpu_mem=1.0 --phase=test --test_dir=E:\split\0-100\ --save_dir=E:\glad\0-100\
E:\split\0-100\ABOUT\train\ABOUT_00949
[*] Reading checkpoint...
INFO:tensorflow:Restoring parameters from ./model/GLADNet
I0109 01:47:21.130590 27548 saver.py:1412] Restoring parameters from ./model/GLADNet
Traceback (most recent call last):
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\client\session.py", line 1377, in _do_call
return fn(*args)
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\client\session.py", line 1360, in _run_fn
return self._call_tf_sessionrun(options, feed_dict, fetch_list,
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\client\session.py", line 1453, in _call_tf_sessionrun
return tf_session.TF_SessionRun_wrapper(self._session, options, feed_dict,
tensorflow.python.framework.errors_impl.ResourceExhaustedError: 2 root error(s) found.
(0) RESOURCE_EXHAUSTED: SameWorkerRecvDone unable to allocate output tensor. Key: /job:localhost/replica:0/task:0/device:CPU:0;0000000000000001;/job:localhost/replica:0/task:0/device:GPU:0;edge_192_save/RestoreV2;0:0
[[{{node save/RestoreV2/_195}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn't available when running in Eager mode.
[[save/RestoreV2/_196]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn't available when running in Eager mode.
(1) RESOURCE_EXHAUSTED: SameWorkerRecvDone unable to allocate output tensor. Key: /job:localhost/replica:0/task:0/device:CPU:0;0000000000000001;/job:localhost/replica:0/task:0/device:GPU:0;edge_192_save/RestoreV2;0:0
[[{{node save/RestoreV2/_195}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn't available when running in Eager mode.
0 successful operations.
0 derived errors ignored.
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\yusak\study\GLADNet\GLADNet2.0\mainmemo.py", line 159, in <module>
tf.compat.v1.app.run()
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\platform\app.py", line 36, in run
_run(main=main, argv=argv, flags_parser=_parse_flags_tolerate_undef)
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\absl\app.py", line 308, in run
_run_main(main, args)
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\absl\app.py", line 254, in _run_main
sys.exit(main(argv))
File "C:\Users\yusak\study\GLADNet\GLADNet2.0\mainmemo.py", line 142, in main
lowlight_test(model)
File "C:\Users\yusak\study\GLADNet\GLADNet2.0\mainmemo.py", line 118, in lowlight_test
lowlight_enhance.test(test_low_data, test_high_data, test_low_data_name, save_dir)
File "C:\Users\yusak\study\GLADNet\GLADNet2.0\model.py", line 104, in test
load_model_status, _ = self.load(self.saver, './model/')
File "C:\Users\yusak\study\GLADNet\GLADNet2.0\model.py", line 94, in load
saver.restore(self.sess, full_path)
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\training\saver.py", line 1417, in restore
sess.run(self.saver_def.restore_op_name,
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\client\session.py", line 967, in run
result = self._run(None, fetches, feed_dict, options_ptr,
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\client\session.py", line 1190, in _run
results = self._do_run(handle, final_targets, final_fetches,
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\client\session.py", line 1370, in _do_run
return self._do_call(_run_fn, feeds, fetches, targets, options,
File "C:\Users\yusak\AppData\Local\Programs\Python\Python310\lib\site-packages\tensorflow\python\client\session.py", line 1396, in _do_call
raise type(e)(node_def, op, message) # pylint: disable=no-value-for-parameter
tensorflow.python.framework.errors_impl.ResourceExhaustedError: Graph execution error:
2 root error(s) found.
(0) RESOURCE_EXHAUSTED: SameWorkerRecvDone unable to allocate output tensor. Key: /job:localhost/replica:0/task:0/device:CPU:0;0000000000000001;/job:localhost/replica:0/task:0/device:GPU:0;edge_192_save/RestoreV2;0:0
[[{{node save/RestoreV2/_195}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn't available when running in Eager mode.
[[save/RestoreV2/_196]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn't available when running in Eager mode.
(1) RESOURCE_EXHAUSTED: SameWorkerRecvDone unable to allocate output tensor. Key: /job:localhost/replica:0/task:0/device:CPU:0;0000000000000001;/job:localhost/replica:0/task:0/device:GPU:0;edge_192_save/RestoreV2;0:0
[[{{node save/RestoreV2/_195}}]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info. This isn't available when running in Eager mode.
0 successful operations.
0 derived errors ignored.
原因?
コードを見る限り、model.pyのsaver.restore(self.sess, full_path)の部分がメモリをあっぱくしているのではないかと思ったが、対策が分からなかった。
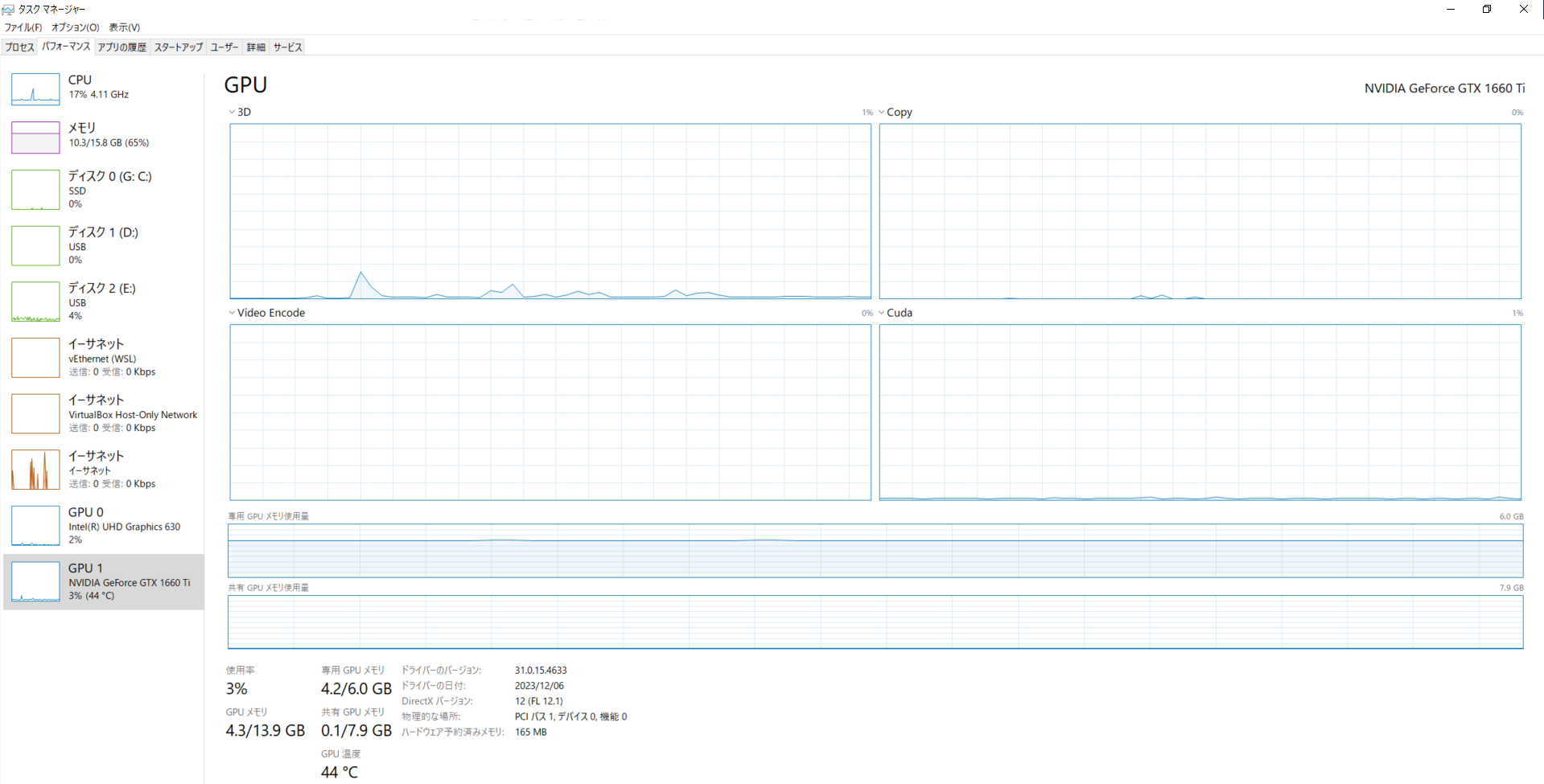
以下の画像のようにメモリ使用率が6GBまで使い切ってくれないのも問題なのかもしれないが直せなかった。