はじめに
本記事は、AIエージェントと Oracle AWR シリーズの続編です。
前回の記事「AIエージェントと Oracle AWR — 大きな結果セットをコーディングエージェントに渡したいときの TIPS」では、AWR レポートのような長大な結果セットを扱う際に、SQLcl MCP Server 経由ではなく SQLcl CLI のラッパースクリプト(sqlspool.sh)を使ってファイルに直接書き出す方法をご紹介しました。
今回は、AWR レポート取得の一連の手順を Cline の Workflow として定義し、再現性のある定型作業に仕上げた内容をご紹介します。
この記事の内容は私個人の経験・見解であり所属する企業・団体・組織を代表するものではありません。
アーキテクチャ概要
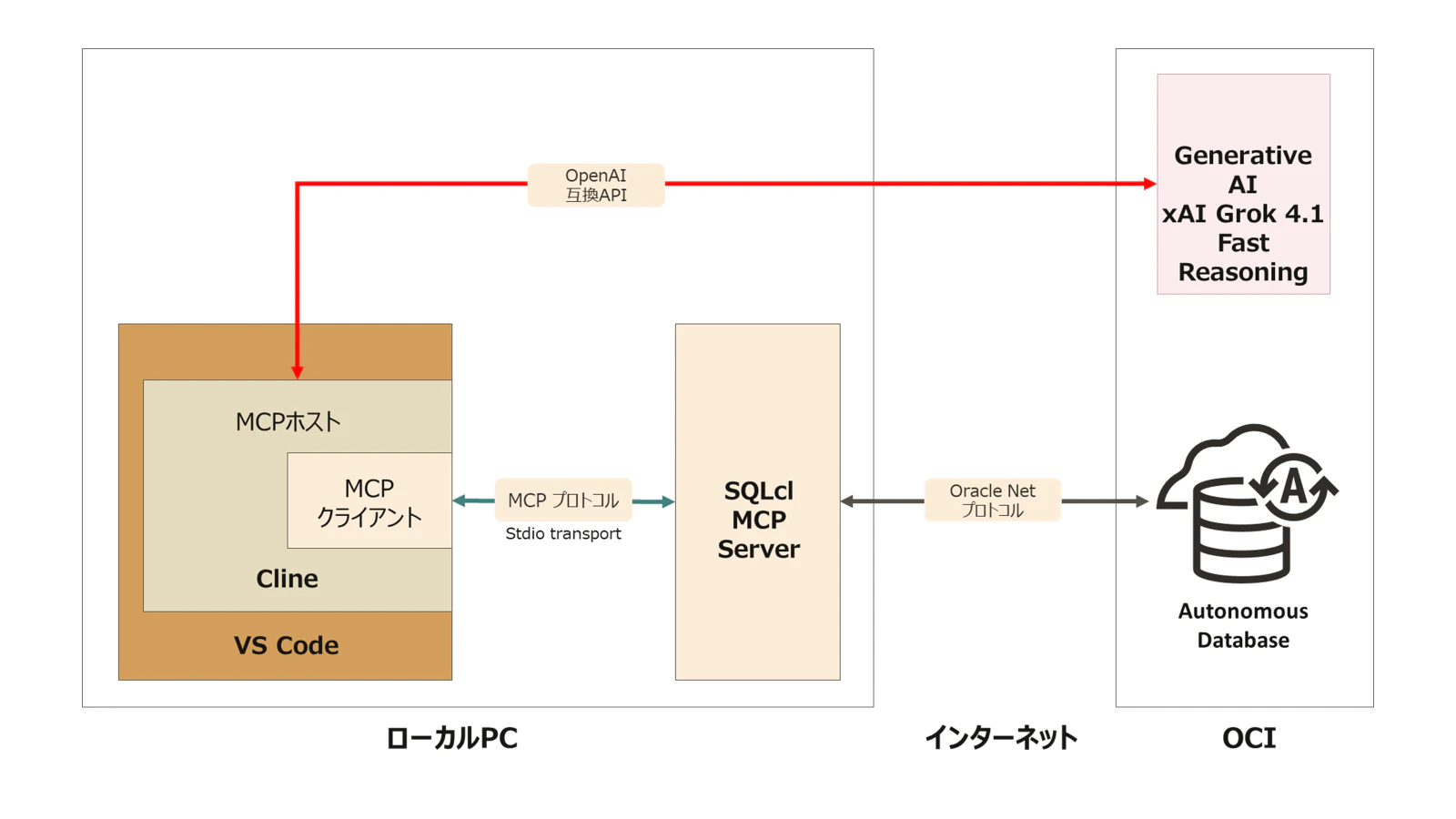
Cline とは?
Cline は、VS Code の拡張機能として動作する AI 駆動開発アシスタントです。Claude、GPT-4、その他の大規模言語モデル(LLM)を活用して、コーディング、デバッグ、ドキュメント作成などの開発タスクを自動化・支援します。最大の特徴は、ファイルの読み書きやターミナルコマンドの実行など、開発環境に直接アクセスして作業を実行できる点です。また、MCP(Model Context Protocol)サーバーと連携することで、データベースや外部サービスとのインテグレーションも可能になります。
OCI Generative AI とは?
OCI(Oracle Cloud Infrastructure)Generative AI は、Oracle が提供するマネージド生成 AI サービスです。このサービスでは、Meta の Llama モデルや Cohere のモデル、そして最新では xAI の Grok 4 モデルなど、さまざまな先進的な生成 AI モデルを API 経由で利用できます。エンタープライズグレードのセキュリティとプライバシー保護機能を備えており、データは Oracle のセキュアなインフラストラクチャ内で処理されます。REST API や SDK を通じてアクセスでき、テキスト生成、VQA(Visual Question Answering)、要約、分類、埋め込み生成などの AI タスクを実行できます。
OCI 生成AIサービス(Generative AI Service)の利用方法には以下のようなものがあります。
- OCI SDK を使う方法
- OCI OpenAI-Compatible SDKs を使う方法
- OpenAI API と OCI Generative AI API Keys を使う方法
- LiteLLM などの Gateway(Proxy)を経由する方法
この記事では、「OpenAI API と OCI Generative AI API Keys を使う方法」で、Cline から OCI 生成AIサービス(Generative AI Service)の xai.grok-4-1-fast-reasoning モデルを呼びだしています。
OpenAI API と OCI Generative AI API Keys を使う方法については下記のブログでご紹介しています。
SQLcl MCP サーバーとは?
Oracle Database のコマンドラインインターフェース (CLI) の Oracle SQLcl が MCPサーバーとして動作するようになりました。SQLcl は、sql コマンドに -mcp オプションを付けて起動すると STDIO トランスポートで MCP クライアントと通信する MCP サーバーになり、データベース操作をツールとして公開します。
Using the Oracle SQLcl MCP Server
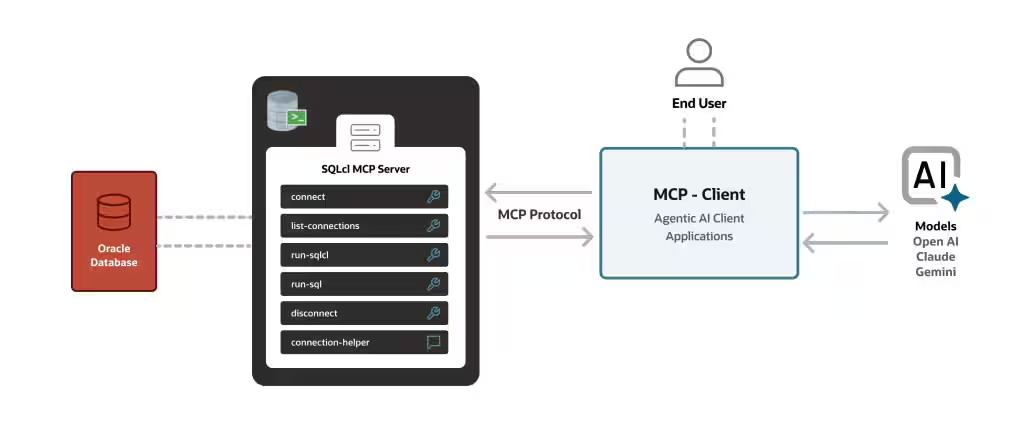
上図は、Introducing MCP Server for Oracle Databaseより引用
利用可能なツールは、7つあります。
| ツール名 | 概要 |
|---|---|
| list-connections | 保存されているデータベース接続の一覧を取得します |
| connect | 指定された接続を使ってデータベースへ接続します |
| disconnect | データベース接続を切断します |
| run-sqlcl | SQLclコマンドを実行します |
| run-sql | SQLクエリを実行します |
| schema-information | 接続しているスキーマの情報を取得します |
| run-sql-async | SQLクエリを非同期に実行します |
なお、MCPとは何かについては下記の記事でご紹介しておりますのでよろしければお立ち寄りください。
Cline Workflow とは
Cline には、定型的なタスクを決められた手順で実行する Workflow を定義する機能があります。Workflow を使うと、エージェントが自律的に判断しながらも、あらかじめ定めたステップに沿って作業を進めてくれます。
これまでの記事では、AWR レポートの生成を Cline の Rules や Skills に従ってエージェントに任せていました。Rules や Skills はエージェントの「知識」や「制約」を定義するものですが、Workflow はそれらを前提としたうえで「手順」そのものを定義するものです。
AWR レポートの取得は、接続先の選択、分析対象期間の確認、スナップショット ID の特定、レポートの生成といった一連のステップから成る定型作業です。これを Workflow として定義しておくことで、毎回同じ品質の手順で作業を再現できるようになります。
前提条件
本記事で紹介する Workflow を利用するには、以下の環境とファイルが整っていることが前提となります。
Oracle SQLcl MCP サーバーの設定
Cline に Oracle SQLcl MCP サーバーが設定されている必要があります。SQLcl MCP サーバーは、SQLcl を -mcp オプション付きで起動することで STDIO トランスポートの MCP サーバーとして動作し、データベース操作をツールとして AI エージェントから利用できるようにするものです。環境構築の詳細は OCI Windows 環境にコーディングAIエージェント Cline とMCPサーバーによるAWRレポート生成・分析システムを構築する手順(Part-1〜3) をご参照ください。
Cline Rules の設定
前回の記事「AIエージェントと Oracle AWR — 大きな結果セットをコーディングエージェントに渡したいときの TIPS」で紹介した Cline Rules(rule4awr.md)が設定されている必要があります。この Rules には、ORA エラー発生時の対処フロー、メタデータの事前確認ルール、CDB/PDB 環境でのビュー選択ルールなどが含まれています。
sqlspool.sh と sqlspool.md の配置
同じく前回の記事で紹介した SQLcl CLI のラッパースクリプト sqlspool.sh と、その使い方を記述した sqlspool.md がワークスペースに配置されている必要があります。
データベースへのアクセス方法の使い分け
この Workflow では、データベースへのアクセスに 2 つの経路 を使い分けます。
-
Oracle SQLcl MCP サーバーのツール群 — 接続の確立、スナップショット ID の検索など、通常のクエリ実行にはこちらを使います。Cline はMCP サーバーのツール(
list-connections、connect、run-sqlclなど)を呼び出して操作を行います。 -
sqlspool.sh(CLI スクリプト) — AWR レポートの生成のように結果セットが長大になる場合に限り、SQLcl CLI を直接呼び出す
sqlspool.shを使います。これは、MCP Server 経由では LLM の tool calling を介してファイルに書き出す必要があり、データの欠落やファイル書き込みの失敗が発生しうるためです。sqlspool.shを使えば、SQLcl プロセスがファイルに直接書き込むため、LLM のトークン制限に影響されることなく完全なレポートを取得できます。
つまり、基本的にはデータベースアクセスが SQLcl MCP サーバー経由で行われ、AWR レポートのように結果セットが大きい場合に限り CLI スクリプトに切り替わるという構成です。
このような使い分けをする理由は、ブログ「AIエージェントと Oracle AWR — 大きな結果セットをコーディングエージェントに渡したいときの TIPS」をご参照ください。
シーケンス図(スクリプト使用)の画像
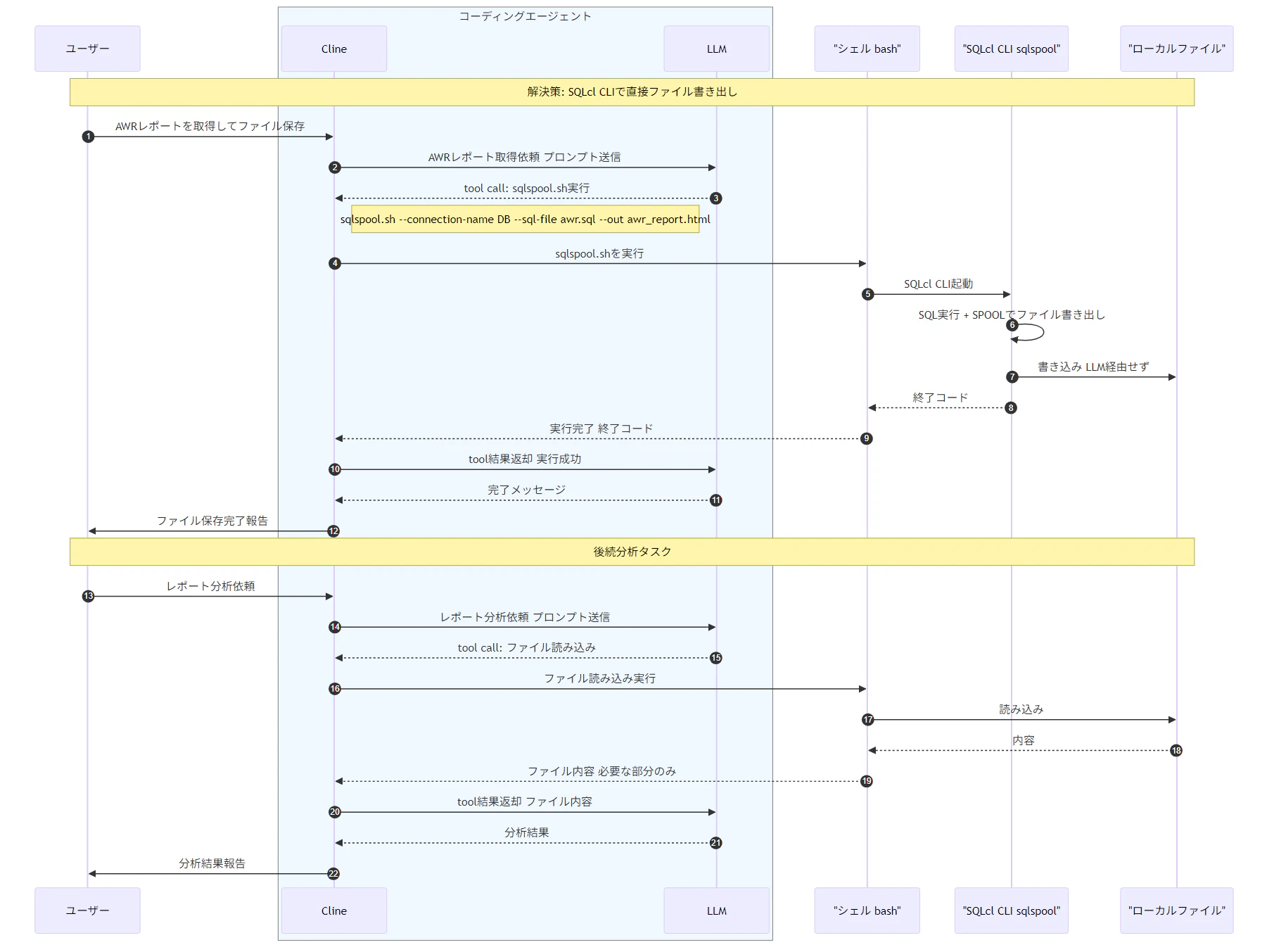
Workflow の定義
Workflow の全体構成
今回作成した Workflow は、以下の 6 つのステップで構成されています。
| ステップ | 内容 |
|---|---|
| STEP-1 | データベースへ接続 |
| STEP-2 | 分析対象期間を確認 |
| STEP-3 | スナップショット ID を特定 |
| STEP-4 | AWR レポート生成対象のスナップショットペアを確認 |
| STEP-5 | AWR レポートを生成 |
| STEP-6 | 結果の提示 |
各ステップでは、エージェントがユーザーに確認を取りながら進行します。SQL の実行前には必ずその目的を明示するルールも組み込んでいます。
Workflow の詳細
STEP-1 データベースへ接続
MCP サーバーのツールで利用可能なデータベース接続の一覧を取得し、ユーザーに選択肢として提示します。ユーザーが接続先を選択すると、エージェントがその接続を確立します。
STEP-2 分析対象期間を確認
ユーザーに対して、AWR レポートを生成したい時間帯を入力してもらいます。当日であれば hh:mm - hh:mm の形式で、日をまたぐ場合は YY/MM/DD hh:mm - YY/MM/DD hh:mm の形式を想定しています。時刻はすべて日本時間(JST)で扱います。
STEP-3 スナップショット ID を特定
指定された分析対象期間に含まれるスナップショットを検索します。前後に 10 分程度の余裕を持たせて検索することで、境界付近のスナップショットを取りこぼさないようにしています。見つかったスナップショットはID とその時刻範囲をユーザーに提示します。
STEP-4 AWR レポート生成対象のスナップショットペアを確認
特定されたスナップショット ID 群から、AWR レポート生成の対象となりうるペアをすべて提示し、ユーザーに選択してもらいます。選択肢のフォーマットは次のとおりです。
開始SNAP_ID - 終了SNAP_ID(開始SNAP終了時刻 - 終了SNAP終了時刻)
STEP-5 AWR レポートを生成
選択されたスナップショットペアに基づいて AWR レポートを生成します。このステップでは、結果セットが長大になるため、MCP サーバーのツールではなく sqlspool.sh を使ってレポートをファイルに直接書き出します。
STEP-6 結果の提示
最後に、以下の情報をユーザーに提示してタスクを完了します。
- AWR レポートの対象期間(開始スナップショットの終了時刻 - 終了スナップショットの終了時刻)
- 開始スナップショット ID(開始時刻 - 終了時刻)
- 終了スナップショット ID(開始時刻 - 終了時刻)
- AWR レポート生成に使用した SQL ファイルの名前
- AWR レポートを保存したファイルの名前
SQL 実行時の目的明示ルール
この Workflow には、SELECT を含むすべての SQL 実行の前に「この SQL で何を知りたいのか・達成したいのか」を 1〜2 文で明示するルールを組み込んでいます。これは、SQL の内容そのものではなく、ビジネス的・運用的な意図を説明するものです。
悪い例として「スナップショットテーブルを SELECT します」のように SQL の動作をそのまま述べるだけでは意図が伝わりません。良い例としては「指定された時刻に最も近いスナップショット ID を特定し、その時点の状態を後続の調査で参照できるようにするための SELECT を実行します」のように、なぜその SQL を実行するのかの目的を述べます。
時刻のタイムゾーンに関するルール
ユーザーへ提示する時刻、およびユーザーが入力する時刻のタイムゾーンは、ユーザーが明示的に別のタイムゾーンを指定しない限り、すべて日本時間(JST)として扱います。
Workflow ファイルの全文
以下が、今回作成した Cline Workflow の定義ファイルの全文です。
# AWRレポートを生成するワークフロー
## ルール
### SELECT を含むすべての SQL で目的を明示するルール
- MUST: `run_sql` / `run_sqlcl` でどのような SQL を実行する場合でも、
実行前に「この SQL で何を知りたいのか/達成したいのか」を 1〜2 文で明示すること。
- この「目的」は、SQL の内容そのものではなく、ビジネス的・運用的な意図を書く:
- 悪い例 (意図が不十分):
- 「スナップショットテーブルを SELECT します。」
- 良い例 (意図が明確):
- 「指定された時刻に最も近いスナップショット ID を特定し、
その時点の状態を後続の調査で参照できるようにするための SELECT を実行します。」
#### 目的の説明 + SQL 例 (SELECT)
```assistant_thought
ユーザーは、特定時刻に対応するスナップショット ID を知りたい。
そのために snapshots テーブルから最も近い時刻の行を 1 件取得する SELECT を実行する。
まず目的を説明してから、SQL を実行してよいか確認する。
これから「指定された時刻に最も近いスナップショット ID を特定する」ための SQL を実行します。
この ID は、当該時刻時点の状態を後続の調査や比較に使うことを目的としています。
実行しようとしている SQL の概要は次のとおりです。
- 対象テーブル: `snapshots`
- 目的: 指定された時刻に最も近いスナップショット ID を 1 件取得
- 主な条件: `snapshot_time` と指定時刻の差が最小の行を ORDER BY + LIMIT で取得
```
<ask_followup_question>
{
"question": "上記の目的のために、該当スナップショット ID を取得する SELECT を `run_sqlcl` で実行してもよいですか?",
"options": [
"はい、実行してよい",
"クエリ内容を先に詳しく確認したい"
]
}
</ask_followup_question>
ユーザーが「はい、実行してよい」を選んだ場合のみ、実際の SQL を run_sql / run_sqlcl で実行する:
<call_mcp_tool>
{
"server_name": "sqlcl",
"tool_name": "run_sqlcl",
"arguments": {
"sql": "SELECT snapshot_id FROM snapshots
WHERE snapshot_time <= :target_time
ORDER BY snapshot_time DESC
FETCH FIRST 1 ROW ONLY"
}
}
</call_mcp_tool>
### 時刻のタイムゾーンに関するルール
- MUST: ユーザーへ提示する時刻のタイムゾーンは必ず日本時間(JST)です
- MUST: ユーザーが入力する時刻のタイムゾーンは、ユーザーが明示的に指定しない限り日本時間(JST)です
- MUST: タイムスタンプを TO_CHAR でフォーマットする際には、`AT TIME ZONE` を使用します
- TO_CHAR の例
```sql
TO_CHAR(END_INTERVAL_TIME_TZ AT TIME ZONE 'Asia/Tokyo', 'YYYY/MM/DD HH24:MI') AS END_TIME_JST
```
## STEP
### STEP-1 データベースへ接続
- データベース接続の一覧をユーザーへ提示して、その中から使用するデータベース接続を選択させます
- 選択肢には、接続名だけを表示して、接続文字列などの詳細は表示しません
### STEP-2 分析対象期間を確認
ユーザーにどの時間帯のスナップショット間のAWRレポートを生成したいのかを確認します
ー 分析対象時間帯を当日であれば、 hh:mm - hh:mm の形式で、当日でないか、日をまたぐ場合は、 YY/MM/DD hh:mm - YY/MM/DD hh:mm の形式で日本時間でユーザーへ入力させます。選択肢は不要。
### STEP-3 スナップショットID を特定
スナップショットの生成が完了した時刻が、分析対象期間に含まれるスナップショットIDを特定します。期間は、前後に10分程度余裕を見て幅広く検索してください。
ペアは箇条書きで提示します。
ユーザーへ提示するフォーマット例:
- 当日以外、もしくは、日をまたぐ場合
SNAP_ID 1234: 2026/3/1 23:00 - 2026/3/2 01:00
- 当日の場合
SNAP_ID 1234: 2026/3/1 11:00 - 12:00
### STEP-4 AWRレポートを生成するスナップショットのペアを確認
特定したスナップショットID群からAWRレポート生成の対象となりうるペアをすべて提示して、ユーザーに選択させます
選択肢に表示するペアのフォーマット:
開始SNAP_ID - 終了SNAP_ID(開始SNAP終了時刻 終了SNAP終了時刻 )
### STEP-5 AWRレポート生成
### STEP-6 結果の提示
以下の情報を箇条書きで提示
- AWRレポートの対象期間(開始スナップショットの終了時刻 - 終了スナップショットの終了時刻)
- 開始スナップショットID(開始時刻 - 終了時刻)
- 終了スナップショットID(開始時刻 - 終了時刻)
- AWRレポート生成に使用したSQLファイルの名前
- AWRレポートを保存したファイルの名前
Workflow の設定方法
Cline で Workflow を設定する手順は以下のとおりです。
- Cline の画面下部にある天秤ばかりのアイコンをクリック
- 「Workflows」タブを選択
- ワークフロー名を入力して「+」をクリック
- エディターが開くので、上記の Workflow 定義を入力
- エディターを閉じる
設定した Workflow は、Cline のタスク入力欄で @ を入力すると表示される一覧から選択して実行できます。
実行例
実際に Workflow を実行した様子をご紹介します。
Workflow の起動
Cline のタスク入力欄で /(スラッシュ) を入力し、作成した AWR レポート取得 Workflow を選択して実行を開始します。
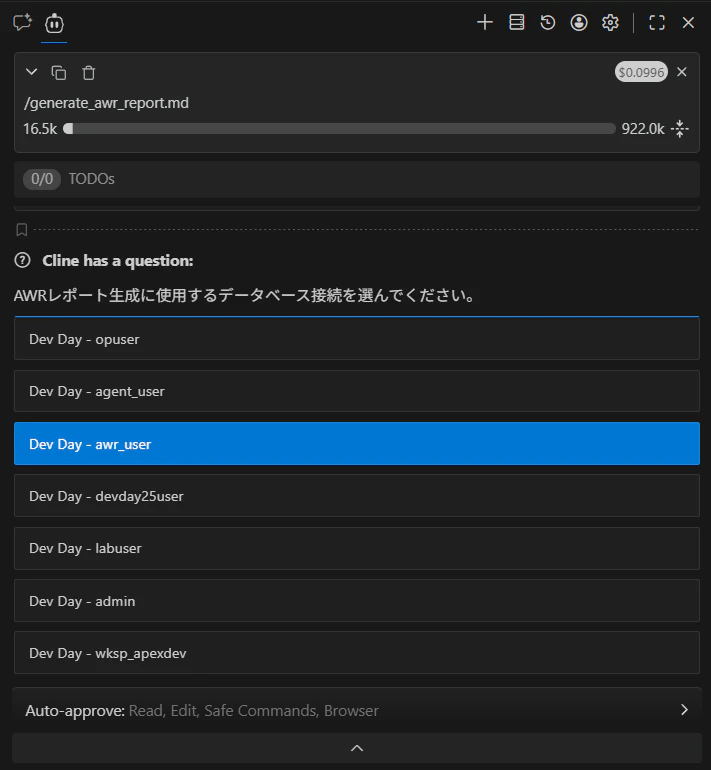
STEP-1 データベース接続の選択
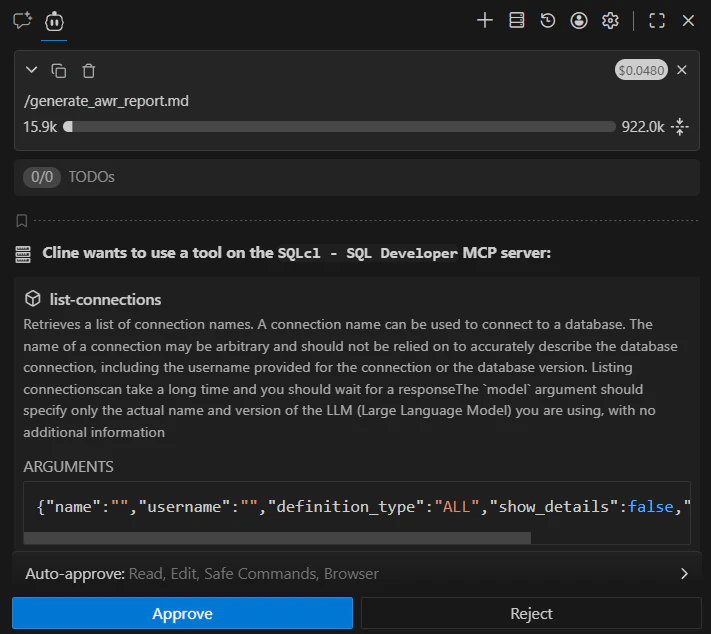
エージェントが MCP サーバーのツールを使って利用可能な接続一覧を取得し、選択肢として提示します。
STEP-2 分析対象期間の入力
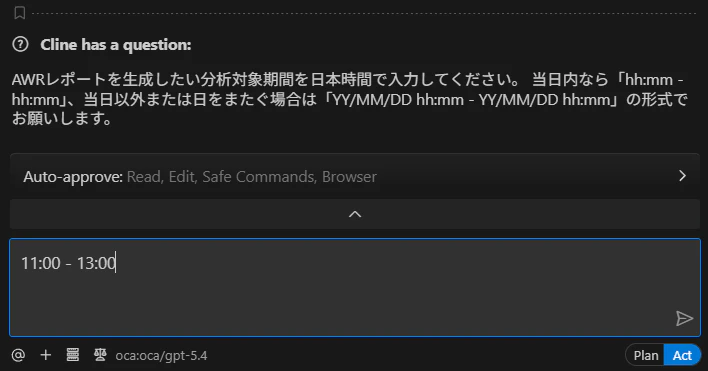
ユーザーに分析対象の時間帯を日本時間で入力するように促します。
STEP-3 スナップショット ID の特定
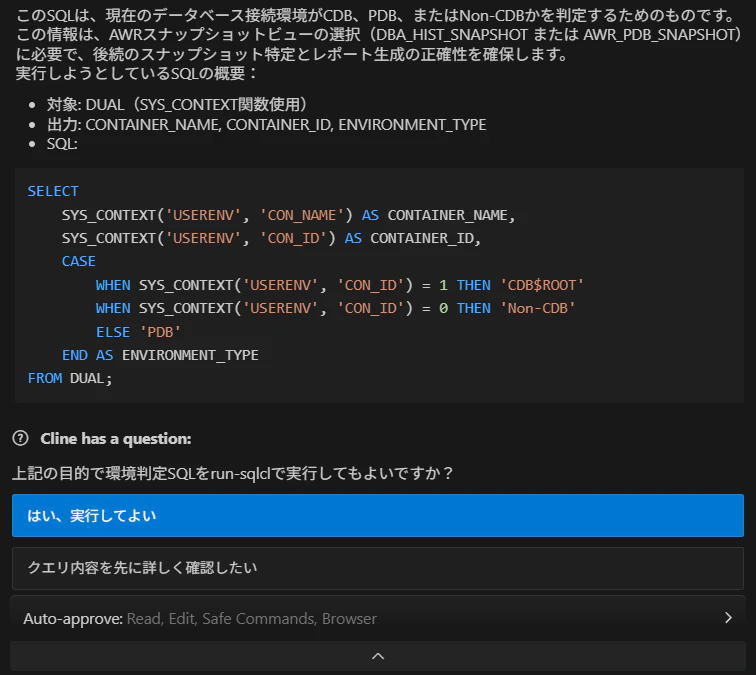
エージェントが SQL の実行目的を明示したうえで、指定期間のスナップショットを検索し、結果を一覧で提示します。
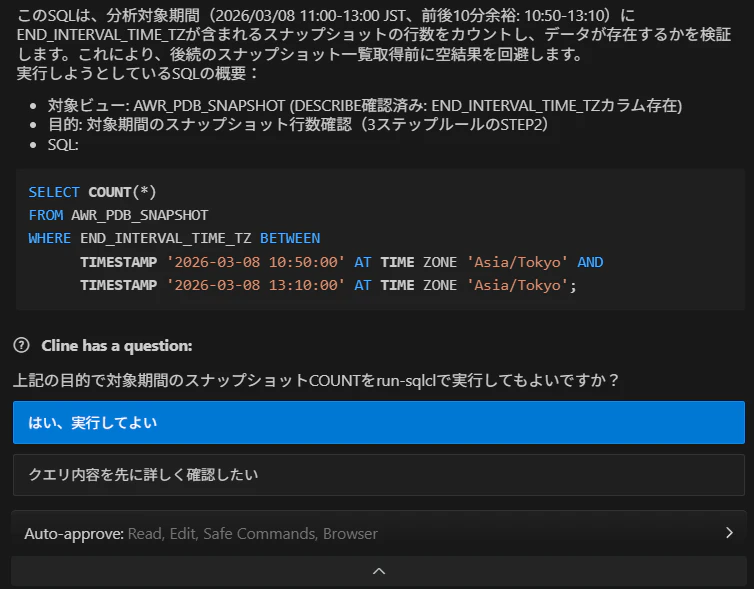
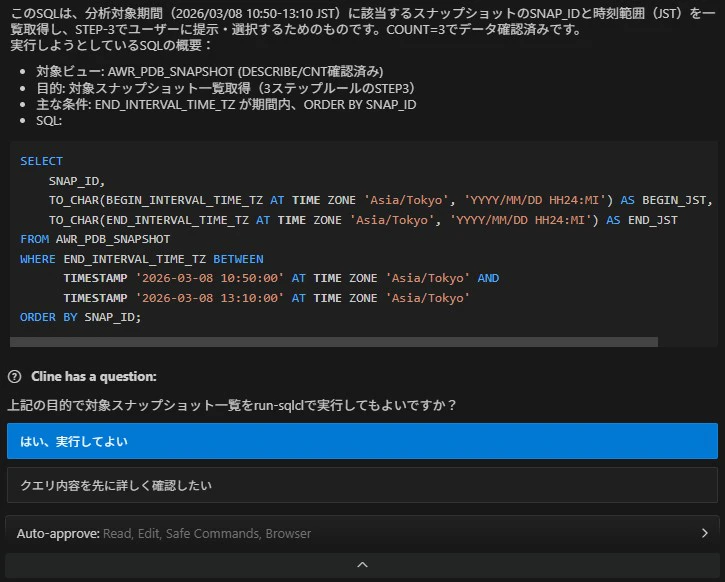
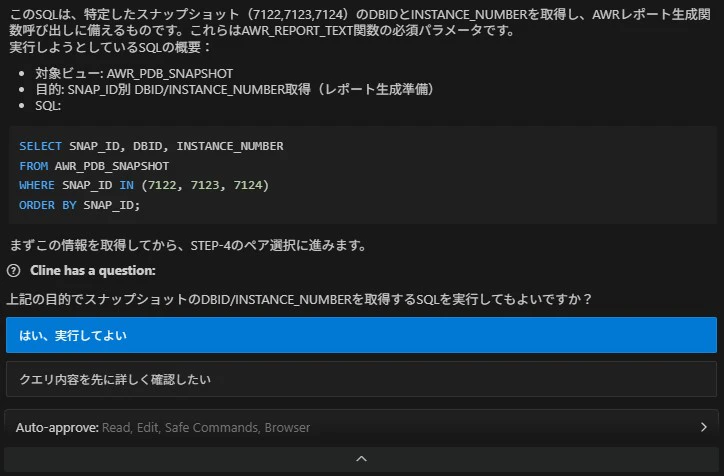
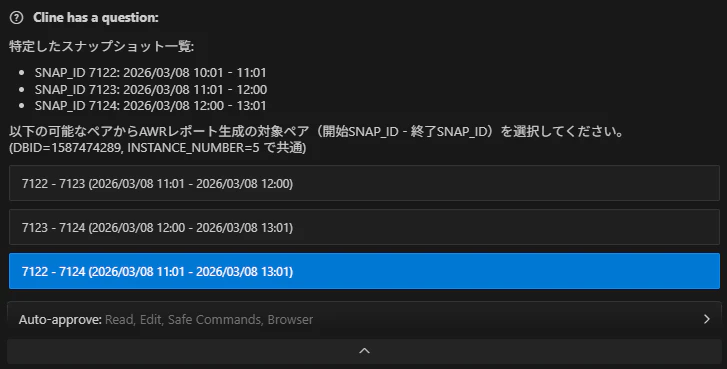
STEP-4 スナップショットペアの選択
対象となるペアが選択肢として提示され、ユーザーが生成対象を選択します。
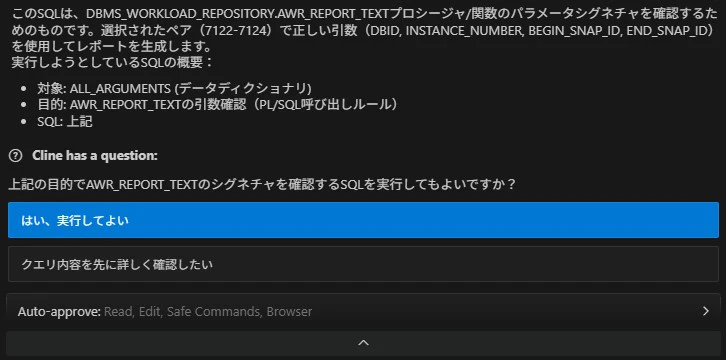
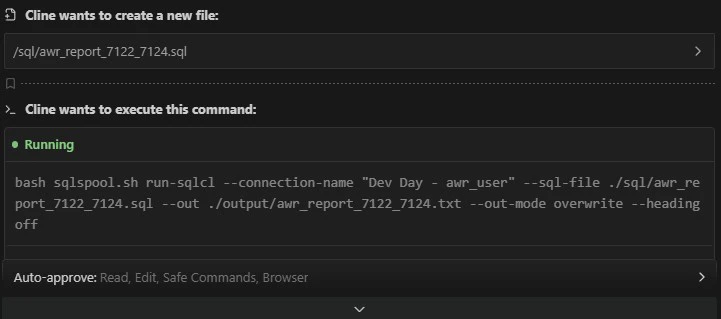
STEP-5 AWR レポートの生成
エージェントが sqlspool.sh を使って AWR レポートをファイルに書き出します。MCP サーバー経由ではなく CLI スクリプトを使うことで、長大なレポートも完全な形で取得できます。
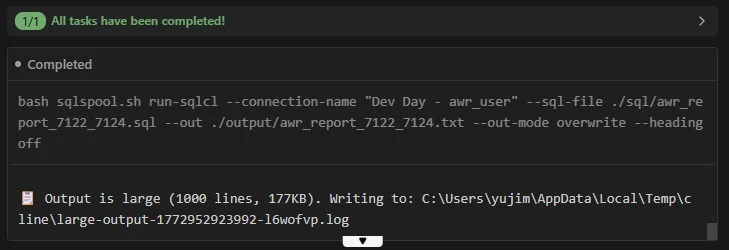
STEP-6 結果の提示
生成が完了すると、対象期間、スナップショット ID、使用した SQL ファイル名、保存先のファイル名が一覧で提示されます。
エディター領域に表示された AWRレポート
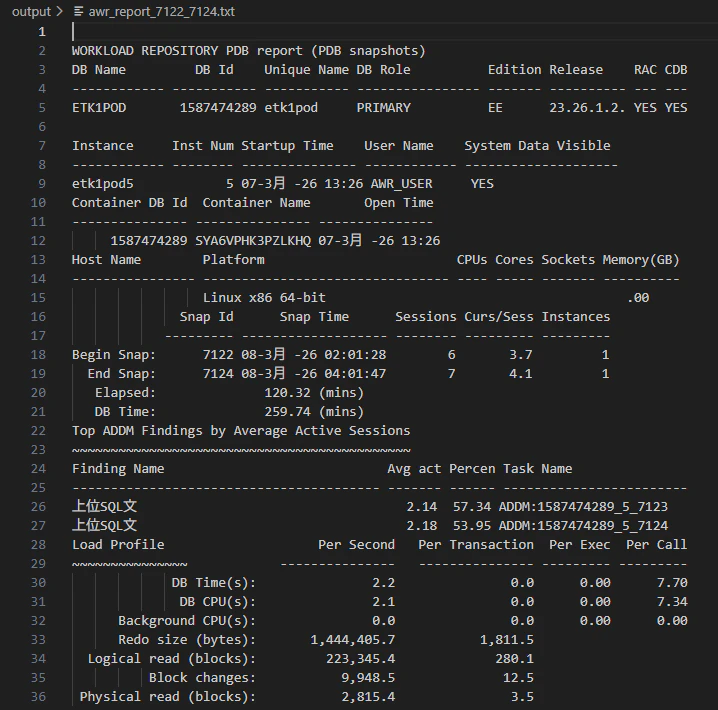
Workflow 化のメリット
手順の再現性
Workflow として定義しておくことで、誰が実行しても同じステップで AWR レポートを取得できます。エージェントが自律的に判断する余地を残しつつも、手順の骨格はぶれません。
確認ポイントの標準化
各ステップでユーザーへの確認が組み込まれているため、誤った期間やスナップショットでレポートを生成してしまうリスクが低減します。
MCP サーバーと CLI の適切な使い分け
通常のクエリは MCP サーバーのツールで実行し、結果セットが大きい AWR レポートの生成だけを CLI スクリプトに切り替えるという使い分けが Workflow に組み込まれています。これにより、利便性と信頼性を両立できます。
SQL 実行目的の可視化
SQL を実行する前にその目的を明示するルールにより、エージェントが何をしようとしているのかがユーザーにとって常に分かりやすくなっています。DBA 作業の監査やレビューの観点でも有用です。
まとめ
本記事では、Oracle AWR レポートの取得手順を Cline の Workflow として定義し、MCP サーバーと CLI スクリプトを適切に使い分ける構成をご紹介しました。
ポイントをまとめると以下のとおりです。
- 通常のデータベースアクセスは Oracle SQLcl MCP サーバーのツール群で行い、AWR レポートのように結果セットが大きい場合だけ CLI スクリプト(
sqlspool.sh)に切り替える - Workflow として手順を定義することで、再現性のある定型作業としてAWR レポート取得を実行できる
- SQL 実行前の目的明示ルールにより、エージェントの行動がユーザーにとって透明になる
- Rules、Skills、Workflow を組み合わせることで、エージェントの制約・知識・手順を体系的に管理できる
DBA の日常業務には、AWR レポートの取得に限らず、定型的な手順で進める作業が数多くあります。そうした作業を Workflow として整備していくことで、AI エージェントをより実践的な DBA のアシスタントとして活用できるようになるのではないでしょうか。
関連記事
- AIエージェントと MCPサーバーで Oracle AWR レポートを生成・分析してみよう
- OCI Windows 環境にコーディングAIエージェント Cline とMCPサーバーによるAWRレポート生成・分析システムを構築する手順(Part-1)
- OCI Windows 環境にコーディングAIエージェント Cline とMCPサーバーによるAWRレポート生成・分析システムを構築する手順(Part-2)
- OCI Windows 環境にコーディングAIエージェント Cline とMCPサーバーによるAWRレポート生成・分析システムを構築する手順(Part-3)
- コーディング・エージェント Cline の Skills を試してみた
- AIエージェントと Oracle AWR — 大きな結果セットをコーディングエージェントに渡したいときの TIPS