はじめに
以前の記事 AIエージェントと MCPサーバーで Oracle AWR レポートを生成・分析してみよう と Cline の Agent Skills を AWR レポート生成・分析に使ってみた では、Cline + SQLcl MCP Server を使って Oracle の AWR レポートを生成・分析する方法をご紹介しました。
ところが、実際に使ってみると「AWR レポートが途中で切れて保存されている」「ファイル書き込みがそもそも失敗する」といった現象が発生することがあります。本記事ではその原因と対策についてご説明します。
コーディングエージェントがファイルを読み書きするしくみ
Cline をはじめとする多くのコーディングエージェントは、ファイルの読み書きを LLM の tool calling(function calling)によってツールを呼び出すアーキテクチャになっています。ファイルの内容を LLM に見せるときも、ファイルに書き込むときも、LLM がツールを呼び出して実行する、というのが基本的な流れです。
通常の用途ではこれで問題ありません。しかし、一度に大量のデータを書き出そうとすると話が変わってきます。
具体的には次のような問題が起きます。
- 大きなデータを書き出す際、先頭部分だけが書き出されて残りが欠落する
- tool calling 自体に失敗してファイルが作られない
- Cline が LiteLLM 経由などで独自の XML ベースの tool calling を使っている場合は、XML のフォーマットが途中で壊れ、Cline がツールを起動できなくなる
Cline の API Provider として、OpenAI Comaptible を指定した場合のように標準的な JSON ベースの tool calling であっても、大きなペイロードを一発で返そうとしたときの不安定さは同じです。
SQLcl MCP Server と大きな結果セット
SQLcl MCP Server のツールには、自身でファイルに書き込む機能がありません。
そのため、大量の結果セットを受け取ってファイルに保存したい場合の流れはこうなります。
- Cline が SQLcl MCP Server のツールを呼び出してクエリを実行する
- 結果セットが MCP Server から Cline に返ってくる
- Cline がその内容を LLM 経由でファイル書き込みツールに渡す
ステップ 3 がまさに「LLM の tool calling による大量データの書き込み」です。AWR レポートでは、数十万文字規模になることもあり、ここで前述の問題が発生する可能性が高くなります。
シーケンス図(問題発生時)の画像
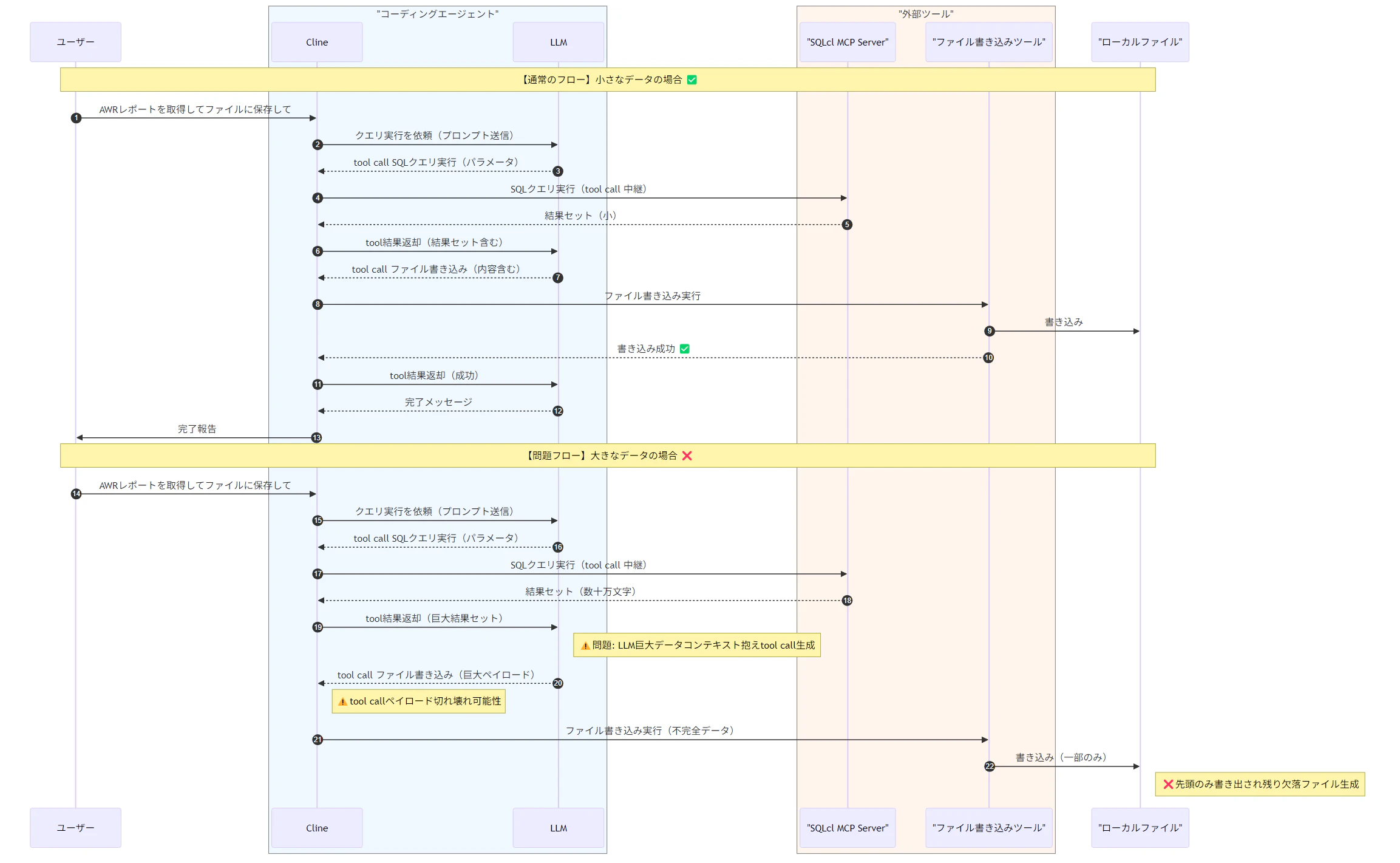
解決策:SQLcl の CLI を直接使う(ラッパースクリプト推奨)
解決策はシンプルです。大きな結果セットを受け取る場合には、SQLcl MCP Server を経由せず、SQLcl の CLI 自体を直接使ってファイルに書き出してしまうことです。
SQLcl の SPOOL コマンドを使えば、SQL の実行結果をそのままローカルファイルに保存できます。ファイルへの書き込みは SQLcl プロセスが直接行うため、LLM の tool calling を介しません。
この処理をコーディングエージェントから呼び出しやすくするために、sqlspool.sh というラッパースクリプトを作りました。もちろん、LLMが持つ、SQLcl に関する知識に期待して CLIそのものを Cline から呼び出しても良いのですが CLI の呼び出しで試行錯誤する確率を下げるためにラッパースクリプトを用意しておくことをお勧めします。
シーケンス図(スクリプト使用)の画像
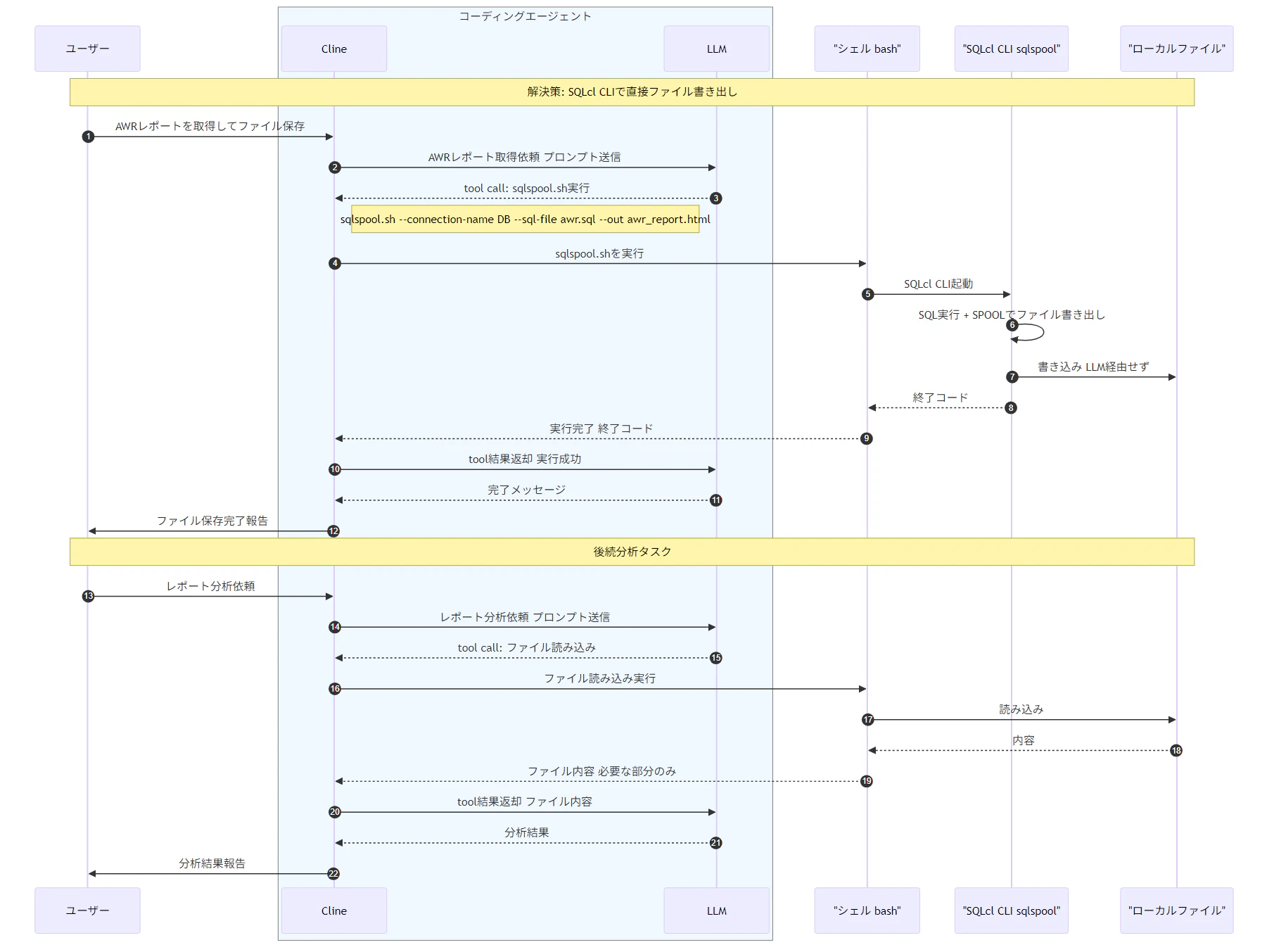
SQLcl CLI のラッパースクリプト sqlspool.sh の概要
sqlspool.sh は SQLcl の sql コマンドをラップする bash スクリプトです。主に以下の用途を想定しています。
- 保存済み接続名(
connect -name <saved-connection>)で接続して SQL を実行する - 長大な出力(AWR レポートなど)を
SPOOLでローカルファイルに保存する - 出力ファイルが既に存在する場合の挙動を overwrite / append / error で制御する
sql コマンドが PATH に存在する必要はありません。VSCode の SQL Developer 拡張機能(oracle.sql-developer-*)に同梱されている Java と SQLcl を自動的に検出して使用します。
sqlspool.sh の使い方
これは、LLMが知っていれば良いこと(後述の sqlspool.md を LLM に読んでもらいます)ですがブラックボックスにしないために少しご説明します。
接続一覧の確認
./sqlspool.sh list-connection
内部で connmgr list を実行し、保存済みの接続名一覧を表示します。
SQL を引数で渡して結果を STDOUT に出力
./sqlspool.sh run-sqlcl --connection-name MYDB --sql "select sysdate from dual;"
SQL ファイルを実行してファイルに保存(上書き)
./sqlspool.sh run-sqlcl --connection-name MYDB \
--sql-file ./awr.sql \
--out ./awr_report.html \
--out-mode overwrite
既存ファイルがあったらエラーにする
./sqlspool.sh run-sqlcl --connection-name MYDB \
--sql-file ./awr.sql \
--out ./awr_report.html \
--out-mode error
--out-mode error を指定すると、同名のファイルがすでに存在する場合は実行せずにエラー終了します。誤って上書きしたくないケースで役立ちます。
追記(append)
./sqlspool.sh run-sqlcl --connection-name MYDB \
--sql "select * from v\$version;" \
--out ./out.txt \
--out-mode append
Cline に sqlspool.sh を使わせるには
スクリプトと説明の配置
VS Code で開いているフォルダー(ワークスペース)に、sqlspool.sh と sqlspool.md を配置(全文は後で出て来ます)
Cline のルールの変更
sqlspool.sh をコーディングエージェントが適切なタイミングで使ってくれるよう、Cline の Rules(または、Workflow、 Skills)に以下のようなルールを記載しておくことが重要です。
前回の記事でご紹介した Cline Rules に、次のようなルールを追加しています。
- AWR レポートを取得する場合は、SQLcl MCP Server のツールは使用せず、
sqlspool.shでファイルへ書き出す - 500 行を超える結果セットが予想される場合も同様に
sqlspool.shを使用する - 書き出したファイルを読み込んで分析に利用する
このようなルールを記述しておくことで、Cline はレポート取得タスクを開始すると自律的に sqlspool.sh を呼び出し、結果をファイルに保存してから分析に移るようになります。また、後続のタスクでAWRレポートなどの結果セットが必要になれば再度データベースへアクセスするのではなく、ローカルに保存したファイルを読み出すことができます。
AWR レポート生成で使う Cline Rules の抜粋
Cline Rules のうち、sqlspool.sh に関連する部分はこのようになります。
### [IMPORTANT] 500行を超える結果セットの処理
- MCP Server のツールは使用しない
- `sqlspool.sh` スクリプトで、ファイルへ出力する
- `sqlspool.sh` スクリプトの利用方法は、sqlspool.md を参照する
- 一旦、ファイルへ書き出した上で、ファイルを読み込んで必要な情報を取得する
### [IMPORTANT] AWRレポート取得の場合も結果セットが長大なため `sqlspool.sh` スクリプトを使用してファイルへ書き出す
このようにルールを記述しておくと、Cline は AWR レポートの取得タスクが発生したタイミングで自律的に sqlspool.sh を使うようになります。
Cline のルール
修正したルールの全文
# Cline Rules for Oracle AWR
## [CRITICAL] ORA-00904 (invalid identifier) 発生時の強制プロトコル
このセクションは全ルールより優先される。違反は許容されない。
### 強制フロー
```
[TRIGGER] ORA-00904 または "invalid identifier" エラーが発生
|
v
[STOP] 次のクエリ実行を禁止。修正したSQLをすぐに実行してはならない。
|
v
[REQUIRED] DESCRIBE <エラーが発生したテーブル/ビュー> を実行
|
v
[REQUIRED] カラム一覧を確認し、存在するカラムのみでSQLを再構築
|
v
[REQUIRED] 修正理由を説明してから、修正したSQLを実行
```
### 禁止行動
以下の行動は絶対に禁止する:
- DESCRIBEを実行せずにカラム名を変更・削除して再試行すること
- 「おそらくこのカラム名だろう」という推測での修正
- エラーメッセージだけを見て修正を試みること
- DESCRIBEの結果を確認せずに次のクエリを発行すること
### 必須行動
以下の行動は必ず実行する:
- DESCRIBE または `SELECT column_name FROM all_tab_columns WHERE table_name = '...'` を実行してカラム一覧を取得
- 取得したカラム一覧と照合してからSQLを修正
- 確認結果を応答に含める(例:「DESCRIBEの結果、SNAP_IDカラムは存在しませんでした。利用可能なカラムは...」)
### 具体例
[FORBIDDEN] 誤った対応:
```
1. SELECT SNAP_ID, OBJECT_NAME FROM DBA_HIST_SQL_PLAN ...
→ エラー: ORA-00904: SNAP_ID: invalid identifier
2. [DESCRIBEを実行しない] ← ルール違反
3. SELECT OBJECT_NAME FROM DBA_HIST_SQL_PLAN ... を再試行
```
[CORRECT] 正しい対応:
```
1. SELECT SNAP_ID, OBJECT_NAME FROM DBA_HIST_SQL_PLAN ...
→ エラー: ORA-00904: SNAP_ID: invalid identifier
2. DESCRIBE DBA_HIST_SQL_PLAN を実行 ← 必須ステップ
3. [結果を確認: SNAP_IDは存在しない。存在するカラム: DBID, SQL_ID, PLAN_HASH_VALUE, ID, OPERATION, ...]
4. ユーザーに報告:「DESCRIBEの結果、SNAP_IDカラムは存在しません。利用可能なカラムは...」
5. 存在するカラムのみを使用して修正したSQLを実行
```
---
## [CRITICAL] Actモードでのツール実行
- Actモードでは必ず1つ以上のツールを呼び出す(例外なし)
- 質問・確認が必要な場合: `ask_followup_question` ツールを使用
- 作業完了時: `attempt_completion` を呼び出す
- 確認だけの応答(ツールを使わない応答)は禁止
---
## [CRITICAL] SQLエラー発生後の共通ルール
### 禁止事項
- 同じクエリを繰り返し実行すること
- 原因を特定せずに単純にSQLを書き換えること
- メタデータを確認せずに修正を試みること
### 必須事項
- エラー発生後は、まずメタデータを確認する(DESCRIBE、データディクショナリ参照)
- エラーメッセージから根本原因を特定してから次のアクションを決定する
- 3回同じエラーが発生したら、アプローチを根本的に変更する
### エラー種別ごとの対処
ORA-00904 (invalid identifier):
→ 上記の「強制プロトコル」に従う
ORA-00942 (table or view does not exist):
→ `SELECT table_name FROM user_tables WHERE table_name LIKE '%キーワード%'` でテーブル存在確認
→ `SELECT owner, table_name FROM all_tables WHERE table_name = '...'` でスキーマ所有者を確認
→ ユーザーに報告
---
## 進捗管理
- `task_progress` を使って、常に「現在何をしていて、次に何をするか」を明示
- 長時間タスクの場合: 定期的にTODOリストを更新し、進捗を記録
---
## ユーザーとのコミュニケーション
### 不明点の確認
- タスクの目的や環境設定が不明確な場合は、推測で進めず `ask_followup_question` を使用してユーザーに確認
- タスクが空または不明確な場合は、まず確認する
### エラー報告
エラーが発生した場合は、`ask_followup_question` を使用してユーザーにエラーの状況と対策案を提示:
- エラーの種類(ORA-XXXXX, MCPエラーなど)
- 発生した状況(どのツール、どのSQL)
- 次に試みる対策
### タスクが中断された場合の再開
ユーザーへの質問ではなくツールで環境を確認:
- データベースの接続状態、利用可能なデータベース接続
- TODOリスト(進捗確認)
---
## URLの提示をしない
URLを参考リンクとして出力しない。
---
## MCPツール実行の基本原則
### 基本方針
- すべてのデータベースクエリはMCPツールを通じて実行する
- MCPツールのレスポンスは、正常に返された場合のみ事実として扱う
- 事前知識やコンテキストに基づいて、出力を推測、仮定、捏造してはならない
- MCPツールのレスポンスが空の場合も出力を推測、仮定、捏造してはならない
### MCPサーバーの正確な利用
- MCPサーバーの名称は必ず正確なサーバー名を使用する
- 推測や略称は絶対に使わない
- 初回接続時は必ずサーバー名を確認してからtoolを呼び出す
[FORBIDDEN] サーバー名の省略:
- 本当のサーバー名が `SQLcl - SQL Developer` であるとき、`SQLcl` と省略することは禁止
### SQLcl - SQL Developer MCPサーバーのルール
- SQLクエリ実行には `run-sqlcl` を使用する
- `run-sqlcl` は、sqlcl コマンドに加えて、SQLクエリーも実行できる
- `run-sql` の使用は禁止
- `DESCRIBE` などの sqlcl コマンドを `run-sql`で実行すると "SP2-0565: 識別子が不正です。" などのエラーとなるので、確実に `run-sqlcl` を使用する
[FORBIDDEN] 以下のコマンドはMCPツールでエラーとなる:
- SET PAGESIZE
- SET LINESIZE
- SET COLSEP
- SET SQLFORMAT
- SPOOL
### ツール実行が失敗、タイムアウト、またはデータが返されない場合
- 結果が取得できなかったことをユーザーに明示的に伝える
- 結果を補完、推定、推測しようとしてはならない
- 再試行するか、クエリを修正するか、追加情報を提供するかをユーザーに確認する
- ツールの結果が部分的な場合は、ユーザーに確認されるまで信頼性がないものとして扱う
### JSONパラメータのフォーマット
- パラメータは必ず有効なJSON形式で記述
- 特殊文字(`\n`, `"`, `'` など)は適切にエスケープ
- 複雑なSQLを渡す場合は、JSON文字列として適切にエンコード
- JSON形式の後に通常のテキストやXMLタグなどを出力しない
---
## データベースクエリのワークフロー
### 接続とセッションの管理
1. 利用可能な接続のリストの事前確認: データベース操作を伴うタスクでは、まずツールで利用可能な接続を確認
2. 使用する接続をユーザーに確認: 接続のリストを `ask_followup_question` ツールのオプションとしてユーザーに提示
3. 接続確立: ツールで接続を確立
4. 接続エラー後の対応: `Connection closed` などのエラーが発生した場合は、利用可能な接続のリストをツールで再確認してから再接続
### メタデータの事前確認
ORA-00942やORA-00904エラーを回避するため、クエリを実行する前に以下を確認する:
テーブルやビューの一覧の取得:
- データベースオブジェクトのリストを取得するツールがあれば使用
- 無い場合は `SELECT table_name FROM user_tables` などを実行
[REQUIRED] テーブルやビューの構造の確認:
- データベースオブジェクトの詳細を取得するツールがあれば使用
- 無い場合は `DESCRIBE table_name` を実行、または `SELECT * FROM all_tab_columns WHERE table_name = 'TABLE_NAME'` を実行
- スキーマの所有者の確認
### 3ステップ実行ルール
すべてのSQLクエリリクエストはこのワークフローに従う。いかなるステップもスキップしてはならない。
| ステップ | アクション | 目的 |
|----------|------------|------|
| 1 | DESCRIBE | スキーマ確認 |
| 2 | SELECT COUNT(*) | 行数の検証 |
| 3 | 実際のクエリ | ユーザーの元のリクエストを実行 |
[WARNING] ステップ3は必須。DESCRIBEとSELECT COUNT(*)は準備ステップに過ぎず、実際のクエリの代わりにはならない。
#### ステップ1: スキーマ確認(DESCRIBE)
- 現在のセッションで初めて登場するテーブル名、ビュー名については、まず `DESCRIBE` を実行してテーブルやビューの構造を確認
- カラム定義を確認してから、実際のSQLクエリを構築
- 自然言語だけでカラム名やデータ型を仮定してはならない
- `DESCRIBE` が失敗した場合やテーブルが存在しない場合は、推測せずにユーザーに確認
#### ステップ2: 行数の検証(COUNT)
- 実際のクエリと同じテーブル、ビュー、WHERE句を使用した `SELECT COUNT(*)` クエリを実行
#### ステップ3: 実際のクエリを実行
[REQUIRED] ステップ1と2を完了した後、ユーザーがリクエストした元のSQLクエリを必ず実行する。
[REQUIRED] SQLがステップ1で確認したテーブル構造、カラム名、データ型に基づいていることを確認する。
- このステップの実際のツール出力のみに基づいて結果を報告する
### 100行を超える結果セットの処理
- データ全体をそのまま出力することは避ける
- 要約を提供する: 集計統計、上位Nレコード、またはサマリーテーブル
### [IMPORTANT]500行を超える結果セットの処理
- MCP Server のツールは使用しない
- `sqlspool.sh` スクリプトで、ファイルへ出力する
- `sqlspool.sh` スクリプトの利用方法は、sqlspool.md を参照する
- 一旦、ファイルへ書き出した上で、ファイルを読み込んで必要な情報を取得する
### [IMPORTANT]AWRレポート取得の場合も結果セットが長大なため `sqlspool.sh` スクリプトを使用してファイルへ書き出す
### タイムゾーンに関する注意事項
- ユーザーが提供する時刻情報は特別な指定がない限り日本時間(JST)とみなす
- テーブルやビューのタイムスタンプ型のカラムにタイムゾーンを保持した型(TIMESTAMP WITH TIME ZONE)がある場合には、それを使用する
- カラムにタイムゾーンを保持した型(TIMESTAMP WITH TIME ZONE)がない場合は、カラムデータはデータベースタイムゾーンで保存されているものとして、セッションタイムゾーンに正しく変換する
---
## Oracleデータディクショナリの使用
- どのデータディクショナリビューが利用可能かを推測してはならない
- まず `DICTIONARY` ビューをクエリする:
```sql
SELECT table_name, comments FROM DICTIONARY ORDER BY table_name;
```
- 実際にアクセス可能なビューのみを選択する
- ディクショナリビューについても3ステップワークフローに従う
- 必要なビューがDICTIONARYに表示されない場合は、ユーザーにその制限を説明する
---
## PL/SQLパッケージ・プロシージャ呼び出しのルール
PL/SQLパッケージのプロシージャ/ファンクションを呼び出す前に、必ずシグネチャを確認する。
### シグネチャ確認方法
```sql
SELECT argument_name, position, data_type, defaulted, in_out
FROM all_arguments
WHERE package_name = 'PACKAGE_NAME'
AND object_name = 'PROCEDURE_NAME'
ORDER BY position;
```
### 禁止事項
- パラメータの推測: 事前知識やドキュメントの記憶に基づいてパラメータを推測してはならない
- 存在確認なしの呼び出し: シグネチャを確認せずにPL/SQLプロシージャを実行してはならない
- 「便利そうな」パラメータの追加: データディクショナリで確認できたパラメータのみを使用する
### 正しいフロー例
```
ユーザー: "ジョブを停止して"
1. 実行: DBMS_SCHEDULER について ALL_ARGUMENTS をクエリ
2. 確認: STOP_JOB のパラメータは job_name, force, commit_semantics のみ
3. 実行: BEGIN DBMS_SCHEDULER.STOP_JOB('JOB_NAME', force => TRUE); END;
```
### 誤ったフロー例
```
ユーザー: "ジョブを停止して"
1. スキップ: シグネチャ確認なし ← ルール違反
2. 実行: BEGIN DBMS_SCHEDULER.STOP_JOB('JOB_NAME', force => TRUE, timeout => 300); END;
↑ timeout は存在しないパラメータ(PLS-00306 エラー)
```
---
## [CRITICAL] CDB/PDB環境でのAWR関連ビュー選択ルール
このルールは、AWRレポート生成だけでなく、AWR関連データを直接クエリするすべての場面に適用される。
### 適用範囲
以下のいずれかに該当する場合、このルールを適用する:
- AWRレポートを生成する場合
- AWR関連のパフォーマンス統計を取得する場合(例:バッファキャッシュヒット率、I/O統計、待機イベントなど)
- DBA_HIST_* または AWR_PDB_* ビューを使用する場合
### CDB/PDB環境の判定(必須)
[REQUIRED] AWR関連のビューを使用する前に、必ず以下のクエリで環境を判定する:
```sql
SELECT
SYS_CONTEXT('USERENV', 'CON_NAME') AS CONTAINER_NAME,
SYS_CONTEXT('USERENV', 'CON_ID') AS CONTAINER_ID,
CASE
WHEN SYS_CONTEXT('USERENV', 'CON_ID') = 1 THEN 'CDB$ROOT'
WHEN SYS_CONTEXT('USERENV', 'CON_ID') = 0 THEN 'Non-CDB'
ELSE 'PDB'
END AS ENVIRONMENT_TYPE
FROM DUAL;
```
### ビュー選択マッピング
| 環境タイプ | スナップショットビュー | 統計ビュー | SQLSTATビュー | 他のAWRビュー |
|------------|------------------------|------------|---------------|---------------|
| Non-CDB (CON_ID=0) | DBA_HIST_SNAPSHOT | DBA_HIST_SYSSTAT | DBA_HIST_SQLSTAT | DBA_HIST_* |
| CDB$ROOT (CON_ID=1) | DBA_HIST_SNAPSHOT | DBA_HIST_SYSSTAT | DBA_HIST_SQLSTAT | DBA_HIST_* |
| PDB (CON_ID>=2) | AWR_PDB_SNAPSHOT | AWR_PDB_SYSSTAT | AWR_PDB_SQLSTAT | AWR_PDB_* |
### 強制ルール
[REQUIRED] PDB環境(CON_ID >= 2)では、以下のビューマッピングを必ず適用する:
| CDB/Non-CDBビュー | PDB環境での対応ビュー |
|-------------------|----------------------|
| DBA_HIST_SNAPSHOT | AWR_PDB_SNAPSHOT |
| DBA_HIST_SYSSTAT | AWR_PDB_SYSSTAT |
| DBA_HIST_SQLSTAT | AWR_PDB_SQLSTAT |
| DBA_HIST_SQLTEXT | AWR_PDB_SQLTEXT |
| DBA_HIST_SQL_PLAN | AWR_PDB_SQL_PLAN |
| DBA_HIST_ACTIVE_SESS_HISTORY | AWR_PDB_ACTIVE_SESS_HISTORY |
| DBA_HIST_SYSTEM_EVENT | AWR_PDB_SYSTEM_EVENT |
| DBA_HIST_SYS_TIME_MODEL | AWR_PDB_SYS_TIME_MODEL |
[FORBIDDEN] PDB環境で DBA_HIST_* ビューを使用すること(CDBレベルのデータが返されるため不正確)
### 検証フロー
```
[TRIGGER] AWR関連のクエリ実行リクエスト
|
v
[STEP 1] CDB/PDB環境を判定(SYS_CONTEXTで確認)
|
v
[STEP 2] 環境に応じたビューを選択
|
+---> CON_ID = 0 または CON_ID = 1
| |
| v
| DBA_HIST_* ビューを使用
|
+---> CON_ID >= 2 (PDB)
|
v
[REQUIRED] AWR_PDB_* ビューを使用
[FORBIDDEN] DBA_HIST_* ビューの使用
|
v
[STEP 3] 選択したビューでDESCRIBEを実行(3ステップ実行ルールに従う)
|
v
[STEP 4] クエリを実行
```
### 正しい例と誤った例
#### 例1: バッファキャッシュヒット率の計算
[FORBIDDEN] PDB環境での誤った対応:
```sql
-- 環境判定: CON_ID = 747 (PDB)
-- 誤り: DBA_HIST_SYSSTATを使用
SELECT STAT_NAME, VALUE
FROM DBA_HIST_SYSSTAT
WHERE STAT_NAME IN ('db block gets', 'consistent gets', 'physical reads');
```
[CORRECT] PDB環境での正しい対応:
```sql
-- 環境判定: CON_ID = 747 (PDB)
-- 正しい: AWR_PDB_SYSSTATを使用
SELECT STAT_NAME, VALUE
FROM AWR_PDB_SYSSTAT
WHERE STAT_NAME IN ('db block gets', 'consistent gets', 'physical reads');
```
#### 例2: SQL実行統計の取得
[FORBIDDEN] PDB環境での誤った対応:
```sql
-- 環境判定: CON_ID = 747 (PDB)
SELECT SQL_ID, EXECUTIONS, ELAPSED_TIME
FROM DBA_HIST_SQLSTAT; -- 誤り
```
[CORRECT] PDB環境での正しい対応:
```sql
-- 環境判定: CON_ID = 747 (PDB)
SELECT SQL_ID, EXECUTIONS, ELAPSED_TIME
FROM AWR_PDB_SQLSTAT; -- 正しい
```
### 一貫性チェック
[REQUIRED] 計画策定時と実行時のビュー選択が一貫していることを確認する:
- 計画で「AWR_PDB_SNAPSHOT」を使用すると決定した場合、統計ビューも「AWR_PDB_SYSSTAT」を使用すること
- 計画で「DBA_HIST_SNAPSHOT」と「AWR_PDB_SYSSTAT」を混在させることは禁止
---
## AWRレポート関数(DBMS_WORKLOAD_REPOSITORY)使用時のルール
注意: AWR関連ビューを直接クエリする場合は「CDB/PDB環境でのAWR関連ビュー選択ルール」セクションを参照すること。
### CDB/PDB環境の判定
[REQUIRED] AWRレポートを生成する前に、まず現在の接続環境がCDBかPDBかを確認する:
```sql
SELECT
SYS_CONTEXT('USERENV', 'CON_NAME') AS CONTAINER_NAME,
SYS_CONTEXT('USERENV', 'CON_ID') AS CONTAINER_ID,
CASE
WHEN SYS_CONTEXT('USERENV', 'CON_ID') = 1 THEN 'CDB$ROOT'
WHEN SYS_CONTEXT('USERENV', 'CON_ID') = 0 THEN 'Non-CDB'
ELSE 'PDB'
END AS ENVIRONMENT_TYPE
FROM DUAL;
```
### 環境に応じたDBIDとスナップショットの確認
#### CDB$ROOT または Non-CDB の場合
CDB$ROOTまたはNon-CDB環境では、`DBA_HIST_SNAPSHOT` と `GV$INSTANCE` を使用する:
```sql
SELECT
S.DBID,
I.INSTANCE_NUMBER,
S.SNAP_ID,
S.BEGIN_INTERVAL_TIME,
S.END_INTERVAL_TIME
FROM
DBA_HIST_SNAPSHOT S,
GV$INSTANCE I
WHERE
S.INSTANCE_NUMBER = I.INSTANCE_NUMBER
AND S.END_INTERVAL_TIME >= SYSTIMESTAMP - INTERVAL '24' HOUR
AND S.END_INTERVAL_TIME < SYSTIMESTAMP
ORDER BY
S.SNAP_ID;
```
#### PDB の場合
[FORBIDDEN] PDB環境では `V$DATABASE` からDBIDを取得すること(CDBのDBIDが返されるため)
[REQUIRED] PDB環境では、`AWR_PDB_SNAPSHOT` と `GV$INSTANCE` をジョインして確認する:
```sql
SELECT
A.DBID,
I.INSTANCE_NUMBER,
A.SNAP_ID,
A.BEGIN_INTERVAL_TIME_TZ,
A.END_INTERVAL_TIME_TZ
FROM
AWR_PDB_SNAPSHOT A,
GV$INSTANCE I
WHERE
A.INSTANCE_NUMBER = I.INSTANCE_NUMBER
AND A.END_INTERVAL_TIME_TZ >= SYSTIMESTAMP - INTERVAL '24' HOUR
AND A.END_INTERVAL_TIME_TZ < SYSTIMESTAMP
ORDER BY
A.SNAP_ID;
```
### AWRレポート関数の使用
- 特段の必要性がなければ、テキスト形式のAWRレポート関数を使用
- AWRレポート関数はテーブル関数である
- シグネチャはALL_ARGUMENTSを確認する
```sql
SELECT OUTPUT
FROM TABLE(DBMS_WORKLOAD_REPOSITORY.AWR_REPORT_TEXT(DBID, INSTANCE_NUMBER, SNAP_ID_START, SNAP_ID_END));
```
### 判定フローのまとめ
```
[START] AWRレポート生成リクエスト
|
v
[STEP 1] CDB/PDB環境を判定(SYS_CONTEXTで確認)
|
+---> CON_ID = 0 (Non-CDB) または CON_ID = 1 (CDB$ROOT)
| |
| v
| DBA_HIST_SNAPSHOT を使用
| DBMS_WORKLOAD_REPOSITORY.AWR_REPORT_TEXT を使用
|
+---> CON_ID >= 2 (PDB)
|
v
AWR_PDB_SNAPSHOT を使用
DBMS_WORKLOAD_REPOSITORY.AWR_REPORT_TEXT を使用
```
### AWRレポートのファイル出力時の注意
[REQUIRED] AWRレポートを `sqlspool.sh` でファイルに出力する場合、
`--heading off` オプションを指定すること。
AWRテキストレポートは自己整形済みドキュメントであり、
カラムヘッダー(OUTPUT)と区切り線は不要なノイズとなる。
```bash
bash sqlspool.sh run-sqlcl --connection-name MYDB \
--sql-file ./awr_report.sql \
--out ./awr.txt \
--out-mode overwrite \
--heading off
```
---
## ハルシネーション防止の検証
### レスポンス前チェックリスト
クエリ結果をユーザーに提供する前に、以下のすべてを確認する:
| チェック | 質問 |
|----------|------|
| [ ] | 実際のクエリを実行したか(DESCRIBEやCOUNTだけではなく)? |
| [ ] | 実際のツール出力から結果を報告しているか(仮定ではなく)? |
| [ ] | ツールが失敗した、または何も返さなかった場合、その事実を明確に述べているか? |
| [ ] | ORA-00904発生時はDESCRIBEを実行してからSQLを修正したか? |
すべてのチェックを確認できない場合、クエリ結果を提供してはならない。
### よくある間違いパターン
[FORBIDDEN] 誤ったパターン:
1. DESCRIBEを実行
2. COUNT(*)を実行
3. 実際のクエリをスキップ ← ルール違反
4. スキーマ/カウント情報に基づいて結果を捏造または仮定
[CORRECT] 正しいパターン:
1. DESCRIBEを実行
2. COUNT(*)を実行
3. 実際のクエリを実行 ← 必須
4. 実際のツール出力からのみ結果を報告
### ツール失敗時の正しい応答
```
「ツールの実行がタイムアウトしました。結果を取得できませんでした。
再実行しますか?または条件を変更しますか?」
```
### ツール失敗時の誤った応答
[FORBIDDEN] 以下のような応答は禁止:
```
「ツールはおそらくAWRデータのサマリーを返したと思われます。」
```
2026/3/1 改定(ターミナルにおける日本語文字化け対処)
sqlspool.sh のコード
以下が sqlspool.sh の全体です。
sqlspool.sh の全文
#!/usr/bin/env bash
# sqlspool.sh - SQLcl(sql) wrapper
#
# Features:
# - list-connection: print saved connections using `connmgr list`
# - run-sqlcl: run SQL text or SQL file with `connect -name` and optional spool
# - out-mode: overwrite|append|error
set -euo pipefail
SCRIPT_NAME="${0##*/}"
die() {
echo "${SCRIPT_NAME}: $*" >&2
exit 2
}
BASE_DIR="$HOME/.vscode/extensions"
[[ -d "$BASE_DIR" ]] || die "BASE_DIR not found: $BASE_DIR"
LATEST_DEV_DIR=$(cd "$BASE_DIR" && ls -d oracle.sql-developer-* 2>/dev/null | sort -V | tail -1)
[[ -n "$LATEST_DEV_DIR" ]] || die "No oracle.sql-developer-* directory found"
SQLCL_PATH="$BASE_DIR/$LATEST_DEV_DIR/dbtools/sqlcl/bin/sql.exe"
JAVA_PATH="$BASE_DIR/$LATEST_DEV_DIR/dbtools/jdk/bin/java.exe"
DBTOOLS_DIR_POSIX="$BASE_DIR/$LATEST_DEV_DIR/dbtools"
usage() {
cat <<'USAGE'
Usage:
sqlspool.sh --help
sqlspool.sh list-connection
sqlspool.sh run-sqlcl --connection-name <name> [--sql <text>] [--sql-file <path>]
[--out <file>] [--out-mode overwrite|append|error] [--debug]
Subcommands:
list-connection
Prints saved connections by running: sql /nolog + connmgr list
run-sqlcl
Runs SQL via SQLcl (sql) using: connect -name <saved-connection>
Options (run-sqlcl):
--connection-name, -c Saved connection name (required)
--sql SQL text to execute (optional)
--sql-file SQL script file path to execute (optional)
--out, -o Output file path (optional). If omitted, prints to STDOUT.
--out-mode overwrite|append|error (default: overwrite)
--heading on|off (default: on). AWR reports should use "off".
--debug Keep temp driver.sql and print its path
Exit codes:
0 success
2 invalid arguments
3 missing input file
4 out-mode=error and output file exists
10 sqlcl execution failed (connect/SQL error etc.)
USAGE
}
need_cmd() {
command -v "$1" >/dev/null 2>&1 || { echo "${SCRIPT_NAME}: '$1' not found in PATH" >&2; exit 2; }
}
mktemp_compat() {
mktemp "$@"
}
is_msys_like() {
case "$(uname -s 2>/dev/null || true)" in
MINGW*|MSYS*|CYGWIN*) return 0 ;;
*) return 1 ;;
esac
}
to_native_path() {
local p="$1"
if is_msys_like && command -v cygpath >/dev/null 2>&1; then
cygpath -w "$p"
else
printf '%s' "$p"
fi
}
DBTOOLS_DIR_WIN="$(to_native_path "$DBTOOLS_DIR_POSIX")"
LAUNCH_PATHS_WIN="$DBTOOLS_DIR_WIN\\launch;$DBTOOLS_DIR_WIN\\sqlcl\\launch"
sqlcl_default_sets() {
cat <<'SQL'
set echo off
set feedback off
set verify off
set heading on
set pagesize 50000
set linesize 32767
set long 10000000
set longchunksize 10000000
set trimspool on
set tab off
SQL
}
run_sqlcl_script() {
local driver_sql="$1"
local driver_native
driver_native="$(to_native_path "$driver_sql")"
local rc=0
# Windows コンソールのコードページを UTF-8 に設定
if is_msys_like; then
chcp.com 65001 >/dev/null 2>&1 || true
fi
set +e
MSYS2_ARG_CONV_EXCL='*' "$JAVA_PATH" \
-Djava.net.useSystemProxies=true \
-Duser.language=ja \
-Dfile.encoding=UTF-8 \
-Dstdout.encoding=UTF-8 \
-Dstderr.encoding=UTF-8 \
-p "$LAUNCH_PATHS_WIN" \
--add-modules ALL-DEFAULT \
--add-opens java.prefs/java.util.prefs=oracle.dbtools.win32 \
--add-opens jdk.security.auth/com.sun.security.auth.module=oracle.dbtools.win32 \
-m com.oracle.dbtools.launch \
sql \
/nolog "@${driver_native}" \
2>&1
rc=$?
set -e
return "$rc"
}
cmd_list_connection() {
[[ ! -f "$JAVA_PATH" ]] && die "Java not found at expected path: $JAVA_PATH"
[[ ! -d "$DBTOOLS_DIR_POSIX/launch" ]] && die "dbtools launch dir not found: $DBTOOLS_DIR_POSIX/launch"
[[ ! -d "$DBTOOLS_DIR_POSIX/sqlcl/launch" ]] && die "sqlcl launch dir not found: $DBTOOLS_DIR_POSIX/sqlcl/launch"
local driver
driver="$(mktemp_compat -t sqlspool_list_XXXXXX.sql)"
trap "rm -f '$driver'" EXIT
cat >"$driver" <<'SQL'
set echo off
set feedback off
set verify off
set heading off
set pagesize 0
set linesize 32767
connmgr list
exit
SQL
run_sqlcl_script "$driver"
}
cmd_run_sqlcl() {
[[ ! -f "$JAVA_PATH" ]] && die "Java not found at expected path: $JAVA_PATH"
[[ ! -d "$DBTOOLS_DIR_POSIX/launch" ]] && die "dbtools launch dir not found: $DBTOOLS_DIR_POSIX/launch"
[[ ! -d "$DBTOOLS_DIR_POSIX/sqlcl/launch" ]] && die "sqlcl launch dir not found: $DBTOOLS_DIR_POSIX/sqlcl/launch"
local conn_name=""
local sql_text=""
local sql_file=""
local out_file=""
local out_mode="overwrite"
local heading="on"
local debug="false"
while [[ $# -gt 0 ]]; do
case "$1" in
--connection-name|-c)
[[ $# -ge 2 ]] || die "--connection-name requires a value"
conn_name="$2"; shift 2 ;;
--sql)
[[ $# -ge 2 ]] || die "--sql requires a value"
sql_text="$2"; shift 2 ;;
--sql-file)
[[ $# -ge 2 ]] || die "--sql-file requires a value"
sql_file="$2"; shift 2 ;;
--out|-o)
[[ $# -ge 2 ]] || die "--out requires a value"
out_file="$2"; shift 2 ;;
--out-mode)
[[ $# -ge 2 ]] || die "--out-mode requires a value"
out_mode="$2"; shift 2 ;;
--heading)
[[ $# -ge 2 ]] || die "--heading requires a value"
heading="$2"; shift 2 ;;
--debug)
debug="true"; shift ;;
--help|-h)
usage; exit 0 ;;
*)
die "unknown option: $1" ;;
esac
done
[[ -n "$conn_name" ]] || die "--connection-name is required"
if [[ -z "$sql_text" && -z "$sql_file" ]]; then
die "either --sql or --sql-file is required"
fi
if [[ -n "$sql_file" && ! -f "$sql_file" ]]; then
echo "${SCRIPT_NAME}: sql file not found: $sql_file" >&2
exit 3
fi
case "$out_mode" in
overwrite|append|error) ;;
*) die "invalid --out-mode: $out_mode" ;;
esac
if [[ -n "$out_file" ]]; then
local out_dir
out_dir="$(cd "$(dirname "$out_file")" 2>/dev/null && pwd || true)"
[[ -n "$out_dir" ]] || die "output directory does not exist: $(dirname "$out_file")"
if [[ "$out_mode" == "error" && -e "$out_file" ]]; then
echo "${SCRIPT_NAME}: output file already exists (out-mode=error): $out_file" >&2
exit 4
fi
fi
local sql_file_native=""
local out_file_native=""
if [[ -n "$sql_file" ]]; then
sql_file_native="$(to_native_path "$sql_file")"
fi
if [[ -n "$out_file" ]]; then
out_file_native="$(to_native_path "$out_file")"
fi
local driver
driver="$(mktemp_compat -t sqlspool_run_XXXXXX.sql)"
if [[ "$debug" != "true" ]]; then
trap "rm -f '$driver'" EXIT
else
echo "${SCRIPT_NAME}: debug: driver sql: $driver" >&2
fi
{
echo "whenever sqlerror exit sql.sqlcode"
echo "connect -name \"${conn_name}\""
sqlcl_default_sets
echo "set heading ${heading}"
if [[ -n "$out_file" ]]; then
case "$out_mode" in
overwrite|error)
echo "spool \"${out_file_native}\"" ;;
append)
echo "spool \"${out_file_native}\" append" ;;
esac
fi
if [[ -n "$sql_file" ]]; then
echo "@\"${sql_file_native}\""
fi
if [[ -n "$sql_text" ]]; then
echo "$sql_text"
fi
if [[ -n "$out_file" ]]; then
echo "spool off"
fi
echo "exit sql.sqlcode"
} >"$driver"
if ! run_sqlcl_script "$driver"; then
echo "${SCRIPT_NAME}: sqlcl execution failed" >&2
exit 10
fi
}
main() {
if [[ $# -lt 1 ]]; then
usage
exit 2
fi
local sub="$1"; shift
case "$sub" in
--help|-h|help)
usage
exit 0
;;
list-connection)
cmd_list_connection
;;
run-sqlcl)
cmd_run_sqlcl "$@"
;;
*)
die "unknown subcommand: $sub"
;;
esac
}
main "$@"
sqlspool.md (LLMに読んでもらう sqlspool.sh の説明)
sqlspool.md の全文
# sqlspool.sh
SQLcl の `sql` コマンドをラップする bash スクリプトです。
## 目的
- **保存済み接続名**(`connect -name <saved-connection>`)で接続して実行
- **長大な出力**(AWRレポート等)を `spool` でファイルへ保存
- 出力ファイルが同名の場合の挙動を制御(overwrite / append / error)
## 依存
- Bash (Git Bash / MSYS2 等)
- VSCode の拡張機能フォルダ `~/.vscode/extensions` 配下に `oracle.sql-developer-*` が存在すること
- `sqlspool.sh` は `oracle.sql-developer-*` の **最新フォルダ**を自動選択し、同梱されている Java/SQLcl を利用します
- `sql` コマンドが PATH に存在する必要はありません
## 備考(起動方式)
`sqlspool.sh` は VSCode の SQL Developer 拡張機能に同梱されている `java.exe` を使い、
`com.oracle.dbtools.launch`(launch モジュール)経由で SQLcl を起動します。
そのため、Java の起動引数(`--add-opens` 等)は拡張機能の MCP サーバー設定と同等のものを使用します。
## オプション詳細
`bash sqlspool.sh --help` を参照。
## 使い方
### 接続一覧
```bash
bash sqlspool.sh list-connection
```
内部では `connmgr list` を呼びます。
### SQL実行(STDOUTへ)
```bash
bash sqlspool.sh run-sqlcl --connection-name MYDB --sql "select sysdate from dual;"
```
### SQLファイル実行(ファイルへspool)
```bash
bash sqlspool.sh run-sqlcl --connection-name MYDB --sql-file ./script.sql --out ./out.txt --out-mode overwrite
```
### 追記(append)
```bash
bash sqlspool.sh run-sqlcl --connection-name MYDB --sql 'select * from v$version;' --out ./out.txt --out-mode append
```
### 既存ファイルがあったらエラー(error)
```bash
bash sqlspool.sh run-sqlcl --connection-name MYDB --sql-file ./awr.sql --out ./awr.html --out-mode error
```
## AWRレポート用途のヒント
- AWR生成スクリプトは環境によって対話入力が必要な場合があります。
- `sqlspool.sh` は巨大出力向けに `set long/linesize/trimspool` 等を既定で設定しています。
2026/3/1 改定(MSYS2/MinGW 環境の自動パス変換 (Posix-to-Windows path conversion) による起動失敗へ対処)
まとめ
LLM の tool calling は非常に便利ですが、一度に大量のデータを渡すことは想定されていません。AWR レポートのような長大な出力を扱う場合には、LLM を経由させずにプロセスが直接ファイルへ書き込める SQLcl の CLI を使うのが確実です。
sqlspool.sh はその橋渡しをするシンプルなスクリプトです。Cline の Rules(または Skills)と組み合わせることで、エージェントが自律的に適切な方法を選択してAWRレポートを保存・分析することができます。
また、Cline の Workflows と組み合わせることで、データベースへの接続や対象スナップショットのぺアの選定、AWRレポートの生成・保存までを一貫して行うワークフローを構築することができます。
具体的なワークフローの定義は下記のブログで公開しています。