目次と前回の記事
これまでに作成したモジュール
以下のリンクから、これまでに作成したモジュールを見ることができます。
| リンク | 説明 |
|---|---|
| marubatsu.py | Marubatsu、Marubatsu_GUI クラスの定義 |
| ai.py | AI に関する関数 |
| test.py | テストに関する関数 |
| util.py | ユーティリティ関数の定義。現在は gui_play のみ定義されている |
| tree.py | ゲーム木に関する Node、Mbtree クラスの定義 |
| gui.py | GUI に関する処理を行う基底クラスとなる GUI クラスの定義 |
AI の一覧とこれまでに作成したデータファイルについては、下記の記事を参照して下さい。
置換表を利用した αβ 法の実装
前回の記事では calc_score_by_ab に仮引数 minimax を追加して ミニマックス法でも評価値を計算できる ようにしました。また、仮引数 use_tt を追加して 置換表(transposition table)を利用してミニマックス法で評価値を計算 できるようにしました。
具体的には、置換表を利用したミニマックス法では以下の処理を行います。
- ミニマックス法でノードの評価値を計算した際に、その局面の評価値を置換表に登録する
- ノードの評価値を計算する際に、その局面の評価値が置換表に登録されている場合 は 子孫ノードの評価値の計算 を 枝狩りして省略 し、置換表に登録された評価値をそのノードの評価値とする
ただし、上記の 置換表の処理 は、ミニマックス法では利用できますが、αβ 法ではそのままでは利用することはできません。
下記のプログラムのように calc_score_by_ab を呼び出す際に、キーワード引数 minimax=False1 と use_tt=True を記述することで、置換表を利用した αβ 法 で評価値を計算できると思った人がいるかもしれません2が、実際には 正しく評価値を計算できていません。今回の記事ではその理由と、修正方法について説明します。
from tree import Mbtree
mbtree = Mbtree.load("../data/abtree_root")
mbtree.calc_score_by_ab(mbtree.root, use_tt=True, debug=True)
実行結果
ミニマックス法で計算したか False
計算したノードの数 999
枝狩りしたノードの数 548947
合計 549946
割合 0.2%
評価値が正しく計算できていないことの検証
上記の calc_score_ab の処理で 評価値が正しく計算できているかどうかを検証 するために、calc_score_by_ab と同じ方法 で 置換表を利用した αβ 法 によって着手を選択する AI の関数を定義 し、Check_solved クラスの is_strongly_solved メソッドを利用してその AI が 強解決であるかどうかを確認 することにします。
AI の名前は ai_abs_tt とし、αβ 法によって着手を選択する ai_abs を修正 して下記のプログラムのように定義します。なお、修正の方法 は前回の記事でミニマックス法で着手を選択する ai_mmdfs を置換表を利用したミニマックス法で着手を選択する ai_mmdfs_tt に修正した方法と ほぼ同じ です。
-
6 行目:最短の勝利を優先する評価値を計算できるように、デフォルト値を
Falseとする仮引数shortest_victoryを追加する -
8、27、37 行目:ノードの評価値を計算する
ab_searchに、置換表のデータを代入する仮引数ttを追加し、子ノードの評価値を計算するためにab_searchを再帰呼び出しする際の実引数に置換表のデータを表すttを記述する -
11 ~ 16 行目:ゲームの決着がついた場合の評価値を計算する。前回の記事 で定義した
ai_mmdfs_ttの 11 ~ 16 行目と同じ -
18 ~ 20 行目:局面を表す文字列を計算し、置換表に登録されている場合はその評価値を返すように修正する。これも
ai_mmdfs_ttの 18 ~ 20 行目と同じ -
29、30、39、40 行目:元のプログラムでは α 狩りや β 狩りを計算した際に return 文で評価値をすぐに返していたが、置換表に評価値を登録する処理を 46 ~ 48 行目でまとめて行う ことが出来るようにするために、評価値を α 値または β 値に代入 して break 文で繰り返し処理を抜ける ようにする。なお、
calc_score_by_abでも同様の処理を行っている -
32、42行目:元のプログラムではノードの評価値が確定した際に return 文で評価値を返していたが、置換表に評価値を登録する処理 を 46 ~ 48 行目で まとめて行うことが出来るようにする ために ローカル変数
scoreに評価値を代入 し、return 文を削除 する -
44 行目:tree.py にプログラムを記述した際に 循環インポートによるエラーを避ける ため、
calc_same_boardtextのインポートをここに記述する -
46 ~ 48 行目:この局面のすべての同一局面の評価値を置換表に登録する。
ai_mmdfs_ttの 32 ~ 34 行目と同じ - 49 行目:評価値を返り値として返すように修正する
-
51 行目:最初に
ab_searchを呼び出す際に、置換表として空の dict を実引数に記述する ように修正する
1 from ai import dprint, ai_by_score
2 from marubatsu import Marubatsu
3 from copy import deepcopy
4
5 @ai_by_score
6 def ai_abs_tt(mb, debug=False, shortest_victory=False):
7 count = 0
8 def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
9 nonlocal count
10 count += 1
11 if mborig.status == Marubatsu.CIRCLE:
12 return (11 - mborig.move_count) / 2 if shortest_victory else 1
13 elif mborig.status == Marubatsu.CROSS:
14 return (mborig.move_count - 10) / 2 if shortest_victory else -1
15 elif mborig.status == Marubatsu.DRAW:
16 return 0
17
18 boardtxt = mborig.board_to_str()
19 if boardtxt in tt:
20 return tt[boardtxt]
21
22 legal_moves = mborig.calc_legal_moves()
23 if mborig.turn == Marubatsu.CIRCLE:
24 for x, y in legal_moves:
25 mb = deepcopy(mborig)
26 mb.move(x, y)
27 score = ab_search(mb, tt, alpha, beta)
28 if score >= beta:
29 alpha = score
30 break
31 alpha = max(alpha, score)
32 score = alpha
33 else:
34 for x, y in legal_moves:
35 mb = deepcopy(mborig)
36 mb.move(x, y)
37 score = ab_search(mb, tt, alpha, beta)
38 if score <= alpha:
39 beta = score
40 break
41 beta = min(beta, score)
42 score = beta
43
44 from util import calc_same_boardtexts
45
46 boardtxtlist = calc_same_boardtexts(mborig)
47 for boardtxt in boardtxtlist:
48 tt[boardtxt] = score
49 return score
50
51 score = ab_search(mb, {})
52 dprint(debug, "count =", count)
53 if mb.turn == Marubatsu.CIRCLE:
54 score *= -1
55 return score
行番号のないプログラム
from ai import dprint, ai_by_score
from marubatsu import Marubatsu
from copy import deepcopy
@ai_by_score
def ai_abs_tt(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return (11 - mborig.move_count) / 2 if shortest_victory else 1
elif mborig.status == Marubatsu.CROSS:
return (mborig.move_count - 10) / 2 if shortest_victory else -1
elif mborig.status == Marubatsu.DRAW:
return 0
boardtxt = mborig.board_to_str()
if boardtxt in tt:
return tt[boardtxt]
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = ab_search(mb, tt, alpha, beta)
if score >= beta:
alpha = score
break
alpha = max(alpha, score)
score = alpha
else:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = ab_search(mb, tt, alpha, beta)
if score <= alpha:
beta = score
break
beta = min(beta, score)
score = beta
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(mborig)
for boardtxt in boardtxtlist:
tt[boardtxt] = score
return score
score = ab_search(mb, {})
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
修正箇所
from ai import dprint, ai_by_score
from marubatsu import Marubatsu
from copy import deepcopy
@ai_by_score
-def ai_abs_tt(mb, debug=False):
+def ai_abs_tt(mb, debug=False, shortest_victory=False):
count = 0
- def ab_search(mborig, alpha=float("-inf"), beta=float("inf")):
+ def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return (11 - mborig.move_count) / 2 if shortest_victory else 1
elif mborig.status == Marubatsu.CROSS:
return (mborig.move_count - 10) / 2 if shortest_victory else -1
elif mborig.status == Marubatsu.DRAW:
return 0
+ boardtxt = mborig.board_to_str()
+ if boardtxt in tt:
+ return tt[boardtxt]
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
- score = ab_search(mb, alpha, beta)
+ score = ab_search(mb, tt, alpha, beta)
if score >= beta:
- return score
+ alpha = score
+ break
alpha = max(alpha, score)
- return alpha
+ score = alpha
else:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
- score = ab_search(mb, alpha, beta)
+ score = ab_search(mb, tt, alpha, beta)
if score <= alpha:
- return score
+ beta = score
+ break
beta = min(beta, score)
- return score
+ score = beta
+ from util import calc_same_boardtexts
+ boardtxtlist = calc_same_boardtexts(mborig)
+ for boardtxt in boardtxtlist:
+ tt[boardtxt] = score
+ return score
- score = ab_search(mb)
+ score = ab_search(mb, {})
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
上記のプログラムを定義後に、下記のプログラムで ai_abs_tt が強解決の AI であるかを確認 すると、実行結果のように 最後に False が表示 されることから ai_abs_tt が 強解決の AI ではない ことが確認できます。また、最善手を着手する局面 の割合が 95.82%、最善手を着手しない局面 が 431 - 413 = 18 ある 事がわかります。
従って、αβ 法で置換表を利用する際 に、ミニマックス法と同じ方法で処理を行うことができない ことが確認できました。
実行結果
from util import Check_solved
result, incorrectlist = Check_solved.is_strongly_solved(ai_abs_tt)
実行結果
100%|██████████| 431/431 [00:03<00:00, 132.59it/s]
413/431 95.82%
False
ai_abs_tt が強解決の AI でない原因の検証
ai_abs_tt が 強解決の AI でない原因 を以前の記事と同様の方法で検証することにします。
まず、下記のプログラムで ai_abs_tt が 最善手を着手しない局面 について、その 局面、候補手の一覧、最善手の一覧 を表示します。下記のプログラムの意味について忘れた方は以前の記事を復習して下さい。なお、以前の記事では最善手を着手しない局面の一覧の中の最初の局面のみ表示しましたが、下記のプログラムではすべての局面を表示しています。また、下記の実行結果には 18 種類の局面の中の最初の 3 つのみを表記しました。
for mb, candidate, bestmoves in incorrectlist:
print(mb)
print("candidate", candidate)
print("bestmoves", bestmoves)
実行結果
Turn x
O..
...
...
candidate {(0, 1), (1, 2), (2, 1), (1, 1), (2, 0), (0, 2), (2, 2), (1, 0)}
bestmoves {(1, 1)}
Turn x
oxO
...
...
candidate {(0, 1), (1, 2), (2, 1), (1, 1), (0, 2), (2, 2)}
bestmoves {(1, 1)}
Turn o
ox.
o.X
...
candidate {(2, 2), (1, 1), (2, 0), (0, 2)}
bestmoves {(1, 1), (2, 2), (0, 2)}
略
検証する局面の選択と最善手でない着手が選択されることの確認
上記の最初の 2 つの局面は、候補手の一覧と最善手の一覧が大きく異なっているため 検証しづらい ので、候補手の一覧と最善手の一覧が 1 つだけ異なる下記の 3 つ目の局面に対して検証を行う ことにします。次の 〇 の手番で (2, 0) に 〇 が着手を行うと 〇 の勝利になる ので、この局面は 〇 の必勝の局面 です。
Turn o
ox.
o.X
...
この局面での ai_abs_tt の候補手の一覧と最善手の一覧 は下記のようになっているので、ai_abs_tt はこの局面に対して (2, 0) という 間違った着手を選択する可能性がある ことが確認できます。
- 候補手の一覧:(2, 2)、(1, 1)、(2, 0)、(0, 2)
- 最善手の一覧:(1, 1)、(2, 2)、(0, 2)
まず、(2, 0) が最善手でないことを検証 することにします。
(0, 2) に 〇 が着手を行うと下記の局面になります。
Turn x
oxO
o.x
...
この局面では × は (0, 2) に着手を行わないと次の 〇 の手番で敗北するので、× の最善手は (0, 2) になります。下記は (0, 2) に × が着手を行った局面です。
Turn o
oxo
o.x
X..
特に難しくはないので詳細は省略しますが、この局面で 〇 と × が最善手を着手し続ける と 引き分け になります。必勝の局面であるにもかかわらず 先程の局面で (2, 0) に着手を行うと 引き分けの局面になる ことから、(2, 0) は最善手ではない ことが確認できました。
先程の局面で すぐに勝利しない (1, 1) などが 最善手 の中に入っているのは、先程 Check_solved で ai_abs_tt を検証した際に仮引数 shortest_victory にデフォルト値である False が代入されたから です。その場合は、最短の勝利を考慮しない ので、すぐに勝利しない合法手も最善手として計算されます。(1, 1) に着手を行うとすぐに勝利することはできませんが、下記のように (2, 0) と (2, 2) の 2 箇所に勝利できるマスがあり、次の × の着手で × が勝利できないので (1, 1) は最善手です。
Turn x
ox.
oOx
...
詳細は省略しますが、最善手の一覧のにある (2, 2) も最善手です。
検証する局面を表すノードの計算
局面を表す Node クラスのインスタンスには 合法手をキー とし、キーの値にその 合法手を着手した局面 を表す dict が代入された chilnode_by_move 属性があります。検証する局面 は (0, 0)、(1, 0)、(0, 1)、(2, 1) の順で着手が行われた局面なので、下記のプログラムで ルートノードからこの局面のノードを計算 することができます3。また、実行結果から検証する局面を表すノードが計算されたことが確認できます。
node = mbtree.root.children_by_move[(0, 0)].children_by_move[(1, 0)].children_by_move[(0, 1)].children_by_move[(2, 1)]
print(node.mb)
実行結果
Turn o
ox.
o.X
...
ai_abs_tt が選択する着手の確認
次に、下記のプログラムで ai_abs_tt がこの局面に対して選択する 合法手の一覧 を表示します。実行結果から、確かに ai_abs_tt はこの局面に対して、(2, 0)、(1, 1)、(0, 2)、(2, 2) の 4 つの合法手を選択 することが確認できました。また、ai_abs_tt がこの 4 つの合法手を着手した局面に 1 という評価値を、残りの (1, 2) に着手した局面に 0 という評価値を計算したことも確認できます。
ai_abs_tt(node.mb, analyze=True)
実行結果
{'candidate': [(2, 0), (1, 1), (0, 2), (2, 2)],
'score_by_move': {(2, 0): 1, (1, 1): 1, (0, 2): 1, (1, 2): 0, (2, 2): 1}}
ai_abs_tt が最善手でない合法手を選択する原因の検証
次に、ai_abs_tt がこの局面でが 最善手でない (2, 0) という合法手を選択する原因 について検証することにします。どのように検証すればよいかについて少し考えてみて下さい。
その検証は、置換表を利用した αβ 法でこの局面の 評価値を計算する過程を Mbtree_Anim で確認 することで行うことが出来ます。まず、下記のプログラムで先程計算した このノードに対して calc_score_by_ab を実行して 置換表を利用した αβ 法で評価値を計算 する処理を行い、Mbtree_Anim を利用してその 計算の過程を確認 します。実行結果のように、最初のフレームに このノードが赤い枠で囲まれたゲーム木の部分木 が表示されます。
以後は、検証する赤枠のノードを $N$ と表記 することにします。また、実際の Mbtree_Anim の実行結果には表示されませんが、わかりやすさを重視して実行結果の図のように 部分木の図に $N$ などの表記を行う ことにします。
from tree import Mbtree_Anim
mbtree.calc_score_by_ab(node, use_tt=True)
Mbtree_Anim(mbtree, isscore=True)
実行結果

上図では $N$ の 最初の子ノード がこの AI が選択する可能性がある 最善手ではない (2, 0) に着手を行った子ノードです。この子(child)ノードを以後は $C$ と表記 することにします。
下段の > をクリックして $C$ の評価値が確定 した 123 フレーム目を表示すると、下図のように $C$ の評価値が 1 と計算された ことが確認できます。先程検証したように $N$ の局面で (2, 0) に着手を行うと引き分けの局面になる ので 正しくは 0 と計算される必要があります。従って、下図から $C$ の評価値の計算が間違っている ことが確認できます。
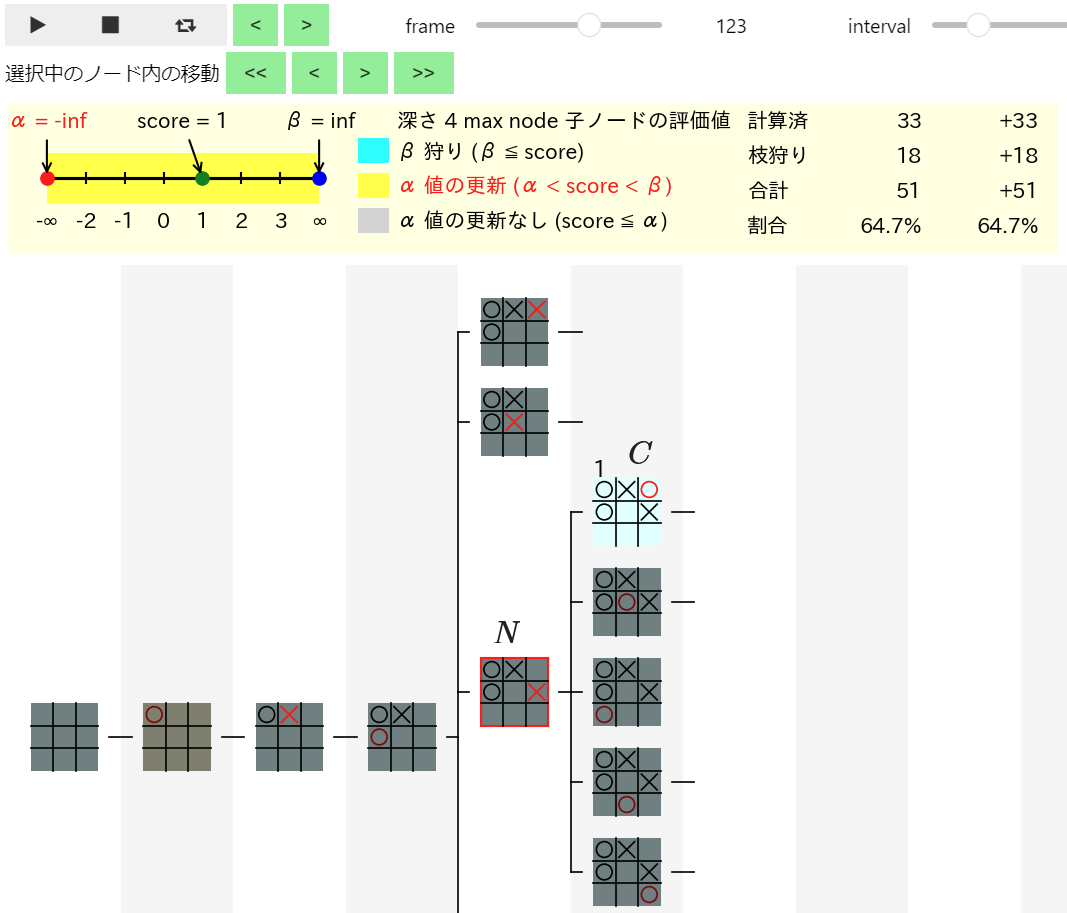
$C$ の評価値の計算が間違って行われる理由を検証するために、以下の操作を行って $C$ の評価値がどのように計算されるか を確認します。Mbtree_Anim で様々な情報を確認するための操作方法について忘れた方は以前の記事を復習して下さい。
- 下段の < をクリックして 最初のフレームに戻る
- 上段の > をクリックして $C$ の計算を開始するフレームに移動 する
- 下段の >> をクリックして $C$ の すべての子ノードの評価値が計算 されて $C$ の評価値が確定した フレームに移動 する
下図は上記の操作を行った結果表示される 122 フレーム目の図です。なお、$C$ の局面で × が (0, 2) に着手 を行った $C$ の 2 つ目の子ノード の事を、$N$ の孫(grandchild)ノードであることから $G$ と表記 することにします。
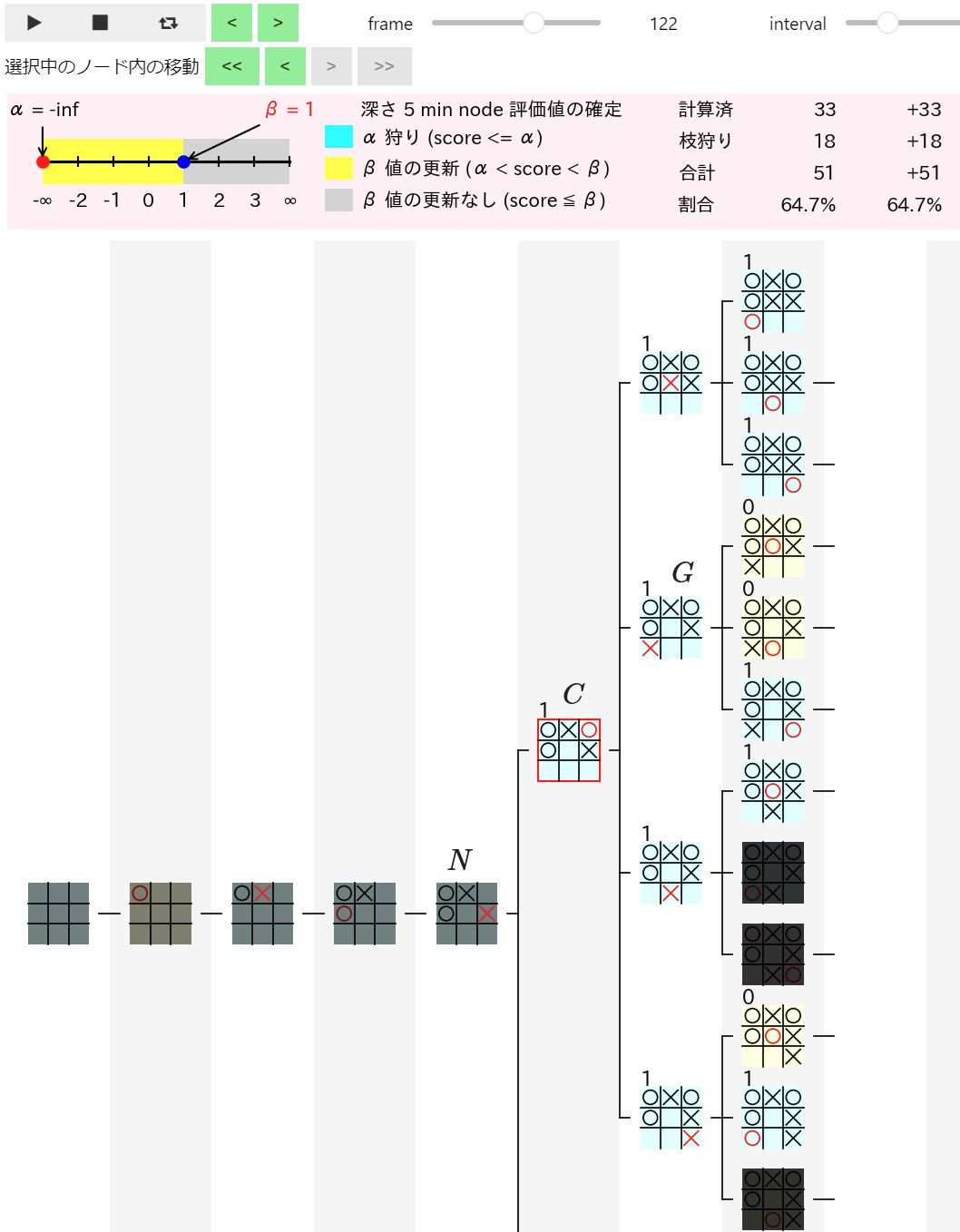
上図から以下の事がわかります。
- $C$ の 4 つの子ノードのうち、× が (0, 2) に着手を行った $G$ 以外の子ノード は、その次に 〇 が (2, 0) に着手を行えば 〇 が勝利する ので 評価値は 1 である
- 上図ではそれらの子ノードの評価値に 1 が表示されているので、それらの子ノードの評価値は正しく計算されている ことが確認できる
- $G$ の局面 は先程検証したように 引き分けの局面 であるので 評価値は 0 である が、上図では評価値として 間違った 1 が計算されている
$G$ の評価値が正しく 0 と計算 されれば、$C$ は min ノードなので $C$ の評価値も正しく 0 と計算される ようになります。従って、$C$ の評価値が間違って計算される理由 は $G$ の評価値が間違って計算されることである ことがわかりました。
$G$ の評価値が間違って計算が行われる理由を検証するために、以下の操作を行って $G$ の評価値がどのように計算されるか を確認します。
- 下段の << をクリックして $C$ の計算を開始するフレームに移動 する
- 下段の > をクリックして $G$ の 前の子ノードの評価値が計算されたフレームに移動 する
- 上段の > を 2 回クリックして $G$ の計算を開始するフレームに移動 する
- 下段の >> をクリックして $G$ の すべての子ノードの評価値が計算 されて $G$ の評価値が確定した フレームに移動 する
下図は上記の操作を行った結果表示される 82 フレーム目の図です。なお、$G$ の局面で 〇 が (2, 2) に着手 を行った $G$ の 3 つ目の子ノード の事を、$G$ の次のアルファベットを使って $H$ と表記 することにします4。また、$H$ の最初の子ノードを $H$ の次のアルファベットを使って $I$ と表記することにします。

上図から以下の事がわかります。
- $G$ は max ノードで、3 つの子ノードの評価値が 0、0、1 と計算されている。従って、$H$ の評価値が 1 と計算されたことによって $G$ の評価値が 1 と計算される
- $H$ は min ノードで、2 つの子ノードの評価値が 1、1 と計算されているため評価値が 1 と計算される
- $I$ の局面は次の 〇 の (1, 2) への着手で 引き分けになる ので 評価値は 0 になるはず であるが、評価値として 1 が計算 されている点が 間違っている
- $H$ の 2 つ目の子ノード は次の 〇 の (1, 1) への着手で 〇 の勝利になるので、評価値が 1 と計算されるのは正しい
- $I$ の評価値が正しく 0 と計算されれば、その祖先ノードの $H$、$G$、$C$ の評価値が正しく 0 と計算される ようになる。従って、$C$ の評価値が間違って 1 と計算される原因 は $I$ の評価値が間違って計算されること である
$I$ の評価値が間違って計算が行われる理由を検証するために、以下の操作を行って $I$ の評価値がどのように計算されるか を確認します。
- 下段の << をクリックして $G$ の計算を開始するフレームに移動 する
- 下段の > を 2 回クリックして $H$ の 前の子ノードの評価値が計算されたフレームに移動 する
- 上段の > を 2 回クリックして $H$ の計算を開始するフレームに移動 する
- 上段の > を 1 回クリックして $I$ の計算を開始するフレームに移動 する
下図は上記の操作を行った結果表示される 69 フレーム目の図です。

上図は 薄緑色で表示 され、赤字で「置換表による置換」と表示 されることから、$I$ の局面の評価値が置換表に登録 されており、その評価値が 1 である ことが確認できます。このことから、$I$ の評価値が間違って 1 と計算される原因 が 置換表に $I$ の局面の評価値が 1 と登録されている ことであることが確認できました。
置換表に間違った評価値が登録される原因の確認
上図で $I$ の局面の評価値が置換表に登録されている ということは、上図の 69 フレーム目よりも前 に、$I$ と同じ局面の評価値が計算された ことを意味します。そこで、下記の操作を行うことで、$I$ と同じ局面が計算されたフレームを探す ことにします。
- IntSlider をドラッグして最初の 0 フレーム目に移動する
- 上段の > ボタンをクリックして 1 フレームずつ表示を確認 して探す5
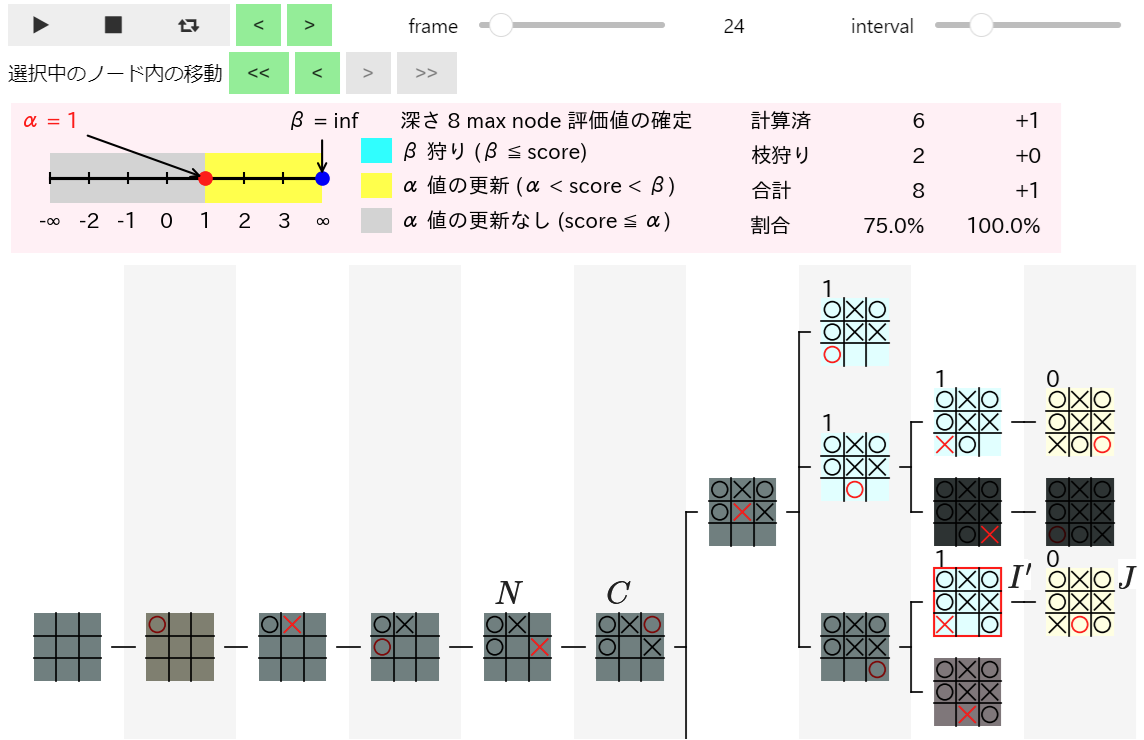
下図は上記の操作で $I$ と同じ局面のノード の 子ノードの評価値の計算 が行われた 22 フレーム目を表示した際の図です。以後は下図の赤枠の $I$ と同じ局面のノードを $I'$、その子ノードを $J$ と表記 することにします。
$J$ は引き分けの局面 なので 評価値が 0 と計算 されていますが、$I'$ は max ノード でこのフレームでの α 値が 1 であるため 赤字で「α 値の更新なし」が表示 され、このノードの評価値を表す α 値は 1 のまま更新されない ことになります。

実際にこの 2 フレーム後の下図では $I'$ の評価値が α 値である 1 と計算 され、その評価値が置換表に登録 された結果 $I'$ と同じ局面の $I$ の評価値が 1 と計算される ことになります。
バグの原因と修正
以前の記事で説明したように、αβ 法 では ルートノード以外のノードの評価値が正しく計算されない場合 があります。具体的には max ノード では 下記の場合に評価値が正しく計算されません6。min ノードの場合の説明は同様なので省略します。
- 全ての子ノードの評価値 がこのノードの評価値を計算する際の α 値の初期値より小さい場合 は、実際の評価値よりも大きな α 値 が評価値として計算される
- β 値より大きな評価値 の 子ノードが見つかった時点 で β 狩りを行い、残りの子ノードの評価値の計算を省略する ので、省略された子ノードの中にそれよりも大きな評価値を持つノードが存在する場合は 本当の評価値より小さな評価値 が計算される
上記のように、αβ 法 で計算される ノードの評価値 はそのノードの評価値を計算する際の α 値と β 値の初期値によって影響を受けます。そのため、同じ局面であっても α 値と β 値の初期値が異なっている場合 は 異なる評価値が計算される場合があります。
上記をまとめると以下のようになります。
αβ 法 では α 値と β 値の初期値が異なる場合 は、同じ局面であっても異なる評価値が計算される場合がある。そのため、αβ 法では 局面と評価値を対応させた置換表 を 利用することはできない。
実際に同じ局面である $I$ と $I'$ の評価値を計算する際の α 値 と β 値の初期値を比べてみると、下図の $I$ の計算を開始する直前 の 68 フレーム目7から $I$ を計算する際の α 値の初期値は 0、β 値の初期値は 1 であることがわかります。

一方、下図の $I'$ の計算を開始する の 22 フレーム目から α 値の初期値は 1、β 値の初期値は 正の無限大 となっており、$I$` と $I'$ では α 値と β 値の初期値が異なる ことがわかります。
$I$ と $I'$ は同じ局面 なので、同じ子ノードを持ちます。また、子ノードとしてはどちらも 引き分け になる 評価値が 0 の子ノードを一つだけ持ちます。
$I'$ の評価値 は α 値が 1 の状態で計算 されたので 子ノードの評価値が 0 であっても 1 と計算 されましたが、$I$ の評価値 は α 値が 0 の状態で計算 するため、子ノードの評価値が 0 の場合 に $I'$ のように 1 と計算することはできません。
上記から、バグの原因が α 値と β 値の初期値が異なる同じ局面のノード に対して、局面と評価値を対応させた置換表 を使って 評価値を計算した ことであることがわかりました。
このバグを修正する方法について少し考えてみて下さい。
3 つのデータをキーとする置換表を利用した修正方法
αβ 法 での評価値の計算方法から、局面 と α 値の初期値 と β 値の初期値 の 3 つがすべて等しい場合 は 同じ評価値が計算される ことがわかります。従って、置換表の dict のキー を局面だけのデータから 局面 と α 値の初期値 と β 値の初期値 に変更し、その 3 つが全て一致する場合に置換表を利用 するように修正するという方法が考えられるでしょう。
実はこの方法は 効率が悪い方法 なので、置換表を利用した αβ 法の処理で実際に利用されることはまずありません。ただし、この方法は 直観的にわかりやすい ので今回の記事ではこの方法でバグを修正することにします。より効率的な方法については次回の記事で説明します。
下記はそのように ai_abs_tt を修正したプログラムです。なお、置換表の dict のキー としては、(局面の情報, α 値の初期値, β 値の初期値) という tuple を採用 しました。
-
4 ~ 6 行目:このノードを表すキー として
(局面の情報, α 値の初期値, β 値の初期値)を表す tuple を計算 して ローカル変数keyに代入 する。そのキーが置換表に登録されている場合に置換表に登録された評価値をこのノードの評価値として返すように修正する -
8 ~ 10 行目:α 値と β 値 はこのノードの評価値を計算する際に 更新されている可能性がある。それらの初期値 は 4 行目で
keyに代入した ので 8 行目で それらを取り出し、10 行目で 同一局面のキーを計算 して 同一局面の評価値を置換表に登録 するように修正する
1 @ai_by_score
2 def ai_abs_tt(mb, debug=False, shortest_victory=False):
元と同じなので省略
3 boardtxt = mborig.board_to_str()
4 key = (boardtxt, alpha, beta)
5 if key in tt:
6 return tt[key]
元と同じなので省略
7 boardtxtlist = calc_same_boardtexts(mborig)
8 _, alpha, beta = key
9 for boardtxt in boardtxtlist:
10 tt[(boardtxt, alpha, beta)] = score
11 return score
元と同じなので省略
行番号のないプログラム
@ai_by_score
def ai_abs_tt(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return (11 - mborig.move_count) / 2 if shortest_victory else 1
elif mborig.status == Marubatsu.CROSS:
return (mborig.move_count - 10) / 2 if shortest_victory else -1
elif mborig.status == Marubatsu.DRAW:
return 0
boardtxt = mborig.board_to_str()
key = (boardtxt, alpha, beta)
if key in tt:
return tt[key]
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = ab_search(mb, tt, alpha, beta)
if score >= beta:
alpha = score
break
alpha = max(alpha, score)
score = alpha
else:
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = ab_search(mb, tt, alpha, beta)
if score <= alpha:
beta = score
break
beta = min(beta, score)
score = beta
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(mborig)
_, alpha, beta = key
for boardtxt in boardtxtlist:
tt[(boardtxt, alpha, beta)] = score
return score
score = ab_search(mb, {})
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
修正箇所
@ai_by_score
def ai_abs_tt(mb, debug=False, shortest_victory=False):
元と同じなので省略
boardtxt = mborig.board_to_str()
- if boardtxt in tt:
+ key = (boardtxt, alpha, beta)
+ if key in tt:
- return tt[boardtxt]
+ return tt[key]
元と同じなので省略
boardtxtlist = calc_same_boardtexts(mborig)
+ _, alpha, beta = key
for boardtxt in boardtxtlist:
- tt[boardtxt] = score
+ tt[(boardtxt, alpha, beta)] = score
return score
元と同じなので省略
上記の修正後に下記のプログラムを実行すると、実行結果から ai_abs_tt が強解決の AI になった ことが確認できます。
result, incorrectlist = Check_solved.is_strongly_solved(ai_abs_tt)
print(result)
実行結果
100%|██████████| 431/431 [00:03<00:00, 121.32it/s]
431/431 100.00%
True
また、下記のプログラムで 最短の勝利を優先する評価値を計算する場合 も ai_abs_tt が強解決の AI であることが確認できます。
result, incorrectlist = Check_solved.is_strongly_solved(ai_abs_tt,
params={"shortest_victory": True})
print(result)
実行結果
100%|██████████| 431/431 [00:04<00:00, 99.99it/s]
431/431 100.00%
True
Mbtree クラスの calc_score_by_ab の修正
置換表を利用した αβ 法の効率を確認 するために、calc_score_by_ab の処理を下記のプログラムのように修正します。修正内容は上記の ai_abs_tt の修正とほぼ同じ です。
なお、calc_score_by_ab で ミニマックス法で評価値を計算する際 には、α 値と β 値の初期値を必ず負の無限大と正の無限大にしてから計算を行っている ので、置換表に登録する際の キーはどの局面でも (局面の情報, 負の無限大, 正の無限大) という tuple になります。従って上記の修正を行っても 置換表を利用したミニマックス法の評価値を正しく計算できます。
-
8 ~ 10 行目:返り値を返さずに評価値を
node.scoreに代入する点を除くとai_abs_ttの 4 ~ 6 行目の修正と同じ -
15 ~ 17 行目:
scoreがnode.scoreになっている点を除くとai_abs_ttの 8 ~ 10 行目の修正と同じ
1 def calc_score_by_ab(self, abroot, debug=False, minimax=False, init_ab=False, use_tt=False):
元と同じなので省略
2 def calc_ab_score(node, tt, alpha=float("-inf"), beta=float("inf")):
3 if minimax:
4 alpha = float("-inf")
5 beta = float("inf")
6 if use_tt:
7 boardtxt = node.mb.board_to_str()
8 key = (boardtxt, alpha, beta)
9 if key in tt:
10 node.score = tt[key]
元と同じなので省略
11 if use_tt:
12 from util import calc_same_boardtexts
13
14 boardtxtlist = calc_same_boardtexts(node.mb)
15 _, alpha, beta = key
16 for boardtxt in boardtxtlist:
17 tt[(boardtxt, alpha, beta)] = node.score
18 return node.score
元と同じなので省略
19
20 Mbtree.calc_score_by_ab = calc_score_by_ab
行番号のないプログラム
def calc_score_by_ab(self, abroot, debug=False, minimax=False, init_ab=False, use_tt=False):
def assign_pruned_index(node, index):
node.pruned_index = index
self.num_pruned += 1
for childnode in node.children:
assign_pruned_index(childnode, index)
def calc_ab_score(node, tt, alpha=float("-inf"), beta=float("inf")):
if minimax:
alpha = float("-inf")
beta = float("inf")
if use_tt:
boardtxt = node.mb.board_to_str()
key = (boardtxt, alpha, beta)
if key in tt:
node.score = tt[key]
if node.mb.turn == Marubatsu.CIRCLE:
alpha = node.score
else:
beta = node.score
self.nodelist_by_score.append(node)
self.num_calculated += 1
for childnode in node.children:
assign_pruned_index(childnode, len(self.nodelist_by_score) - 1)
self.ablist_by_score.append((alpha, beta, None, "tt",
self.num_calculated, self.num_pruned))
node.score_index = len(self.nodelist_by_score) - 1
return node.score
self.nodelist_by_score.append(node)
self.ablist_by_score.append((alpha, beta, None, "start",
self.num_calculated, self.num_pruned))
if node.mb.status != Marubatsu.PLAYING:
self.calc_score_of_node(node)
if node.mb.turn == Marubatsu.CIRCLE:
alpha = node.score
else:
beta = node.score
else:
if node.mb.turn == Marubatsu.CIRCLE:
for childnode in node.children:
score = calc_ab_score(childnode, tt, alpha, beta)
self.nodelist_by_score.append(node)
self.ablist_by_score.append((alpha, beta, score, "score",
self.num_calculated, self.num_pruned))
if score > alpha:
alpha = score
self.nodelist_by_score.append(node)
if score >= beta:
index = node.children.index(childnode)
for prunednode in node.children[index + 1:]:
assign_pruned_index(prunednode, len(self.nodelist_by_score) - 1)
self.ablist_by_score.append((alpha, beta, None, "update",
self.num_calculated, self.num_pruned))
if score >= beta:
break
node.score = alpha
else:
for childnode in node.children:
score = calc_ab_score(childnode, tt, alpha, beta)
self.nodelist_by_score.append(node)
self.ablist_by_score.append((alpha, beta, score, "score",
self.num_calculated, self.num_pruned))
if score < beta:
beta = score
self.nodelist_by_score.append(node)
if score <= alpha:
index = node.children.index(childnode)
for prunednode in node.children[index + 1:]:
assign_pruned_index(prunednode, len(self.nodelist_by_score) - 1)
self.ablist_by_score.append((alpha, beta, None, "update",
self.num_calculated, self.num_pruned))
if score <= alpha:
break
node.score = beta
self.nodelist_by_score.append(node)
self.num_calculated += 1
self.ablist_by_score.append((alpha, beta, None, "end",
self.num_calculated, self.num_pruned))
node.score_index = len(self.nodelist_by_score) - 1
if use_tt:
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(node.mb)
_, alpha, beta = key
for boardtxt in boardtxtlist:
tt[(boardtxt, alpha, beta)] = node.score
return node.score
from ai import dprint
for node in self.nodelist:
node.score_index = float("inf")
node.pruned_index = float("inf")
self.nodelist_by_score = []
self.ablist_by_score = []
self.num_calculated = 0
self.num_pruned = 0
if init_ab:
alpha = -2 if self.shortest_victory else -1
beta = 3 if self.shortest_victory else 1
else:
alpha = float("-inf")
beta = float("inf")
calc_ab_score(abroot, {}, alpha, beta)
total_nodenum = self.num_pruned + self.num_calculated
ratio = self.num_calculated / total_nodenum * 100
dprint(debug, "ミニマックス法で計算したか", minimax)
dprint(debug, "計算したノードの数", self.num_calculated)
dprint(debug, "枝狩りしたノードの数", self.num_pruned)
dprint(debug, "合計", total_nodenum)
dprint(debug, f"割合 {ratio:.1f}%")
Mbtree.calc_score_by_ab = calc_score_by_ab
修正箇所
def calc_score_by_ab(self, abroot, debug=False, minimax=False, init_ab=False, use_tt=False):
元と同じなので省略
def calc_ab_score(node, tt, alpha=float("-inf"), beta=float("inf")):
if minimax:
alpha = float("-inf")
beta = float("inf")
if use_tt:
boardtxt = node.mb.board_to_str()
- if boardtxt in tt:
+ key = (boardtxt, alpha, beta)
+ if key in tt:
- node.score = tt[boardtxt]
+ node.score = tt[key]
元と同じなので省略
if use_tt:
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(node.mb)
+ _, alpha, beta = key
for boardtxt in boardtxtlist:
- tt[boardtxt] = node.score
+ tt[(boardtxt, alpha, beta)] = node.score
return node.score
元と同じなので省略
Mbtree.calc_score_by_ab = calc_score_by_ab
上記の修正後に下記のプログラムを実行して、先程のノード $N$ の評価値を計算し、Mbtree_Anim で表示することにします。
mbtree.calc_score_by_ab(node, use_tt=True)
Mbtree_Anim(mbtree, isscore=True)
実行後に下段の >> ボタンをクリックすると、下図のように $C$ のノードの評価値が正しく 0 と計算される ようになったことが確認できます。

また、$I$ のノードの評価値の計算が開始 された下図の 67 フレーム目は 背景が白色で表示 されており、置換表が利用されなくなった ことが確認できます。

また、$I$ のノードの評価値が確定 した下図の 71 フレーム目では $I$ の評価値が正しく 0 と計算されるようになった ことが確認できます。
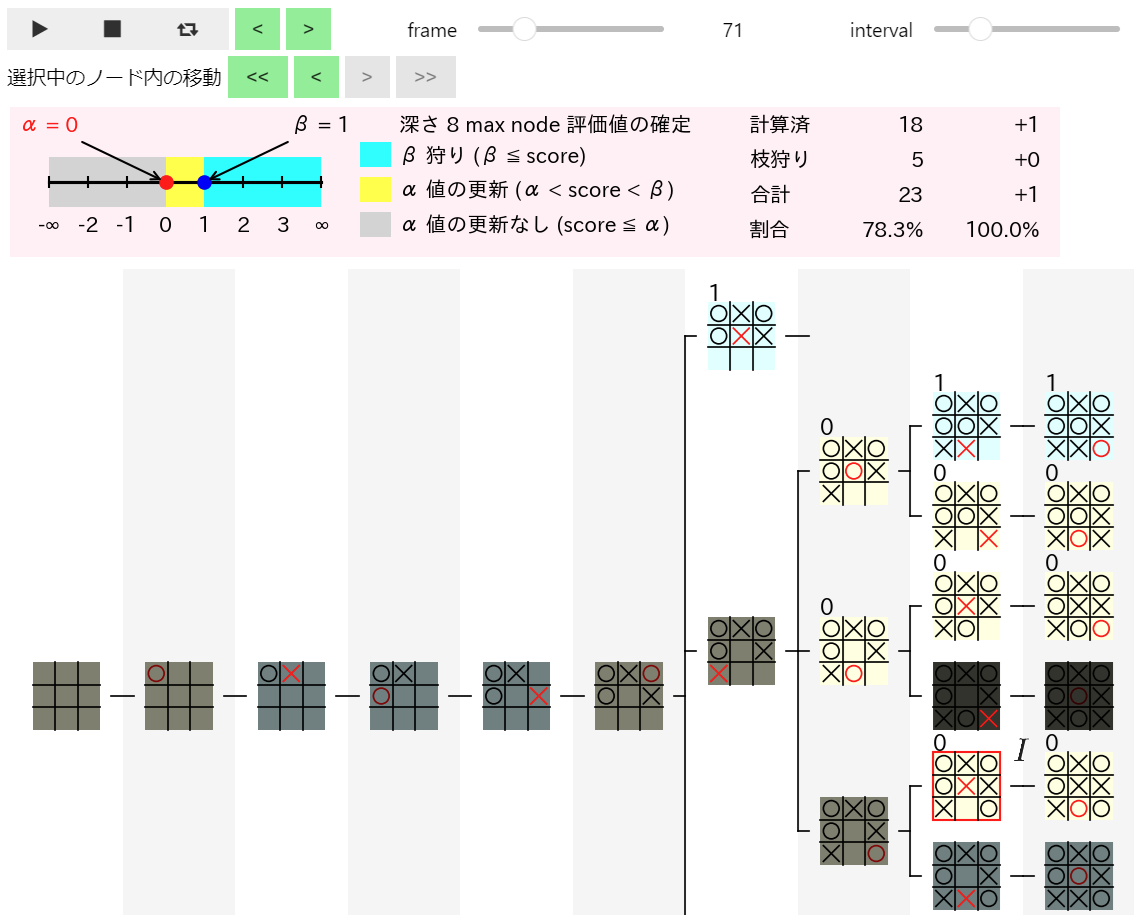
一方、α 値と β 値の初期値が同じ同一局面 を探したところ、下図の 132 フレーム目と 241 フレーム目の赤枠の同一局面のノードが見つかりました。 2 つのノードの α 値と β 値の初期値はどちらも α 値が 1、β 値が正の無限大 となっており、241 フレーム目の図の背景色が薄緑色 になっていることから、実際に置換表による枝狩りが行われた ことが確認できます。


3 つのデータをキーとした置換表を利用した αβ 法の効率
局面と α 値と β 値の初期値をキー とした置換表を利用した αβ 法の 効率を確認する ために、下記のプログラムで ミニマックス法と αβ 法の両方 で 置換表を利用する場合としない場合 の評価値の計算を calc_score_by_ab で計算して 比較します。なお、見やすいようにそれぞれの結果の間に print() で空行を表示するという工夫を行ないました。
print("ミニマックス法で置換表を利用しない")
mbtree.calc_score_by_ab(mbtree.root, minimax=True, debug=True)
print()
print("ミニマックス法で置換表を利用する")
mbtree.calc_score_by_ab(mbtree.root, minimax=True, use_tt=True, debug=True)
print()
print("αβ 法で置換表を利用しない")
mbtree.calc_score_by_ab(mbtree.root, debug=True)
print()
print("αβ 法で置換表を利用する")
mbtree.calc_score_by_ab(mbtree.root, use_tt=True, debug=True)
実行結果
ミニマックス法で置換表を利用しない
ミニマックス法で計算したか True
計算したノードの数 549946
枝狩りしたノードの数 0
合計 549946
割合 100.0%
ミニマックス法で置換表を利用する
ミニマックス法で計算したか True
計算したノードの数 2271
枝狩りしたノードの数 547675
合計 549946
割合 0.4%
αβ 法で置換表を利用しない
ミニマックス法で計算したか False
計算したノードの数 18297
枝狩りしたノードの数 531649
合計 549946
割合 3.3%
αβ 法で置換表を利用する
ミニマックス法で計算したか False
計算したノードの数 1718
枝狩りしたノードの数 548228
合計 549946
割合 0.3%
下記は上記の結果を表にまとめたものです。上段が計算したノードの数、下段が割合を表します。この結果の内、今回の記事で新しく実装した 置換表を利用した αβ 法以外の結果 は、これまでの記事での結果と同じ値が表示 されているので、今回の修正を行ってもそれらの計算を正しく行うことが出来る ことが確認できました。
| ミニマックス法 | αβ 法 | |
|---|---|---|
| 置換表の利用なし | 549946 100.0 % |
18297 3.3 % |
| 置換表の利用あり | 2271 0.4% |
1718 0.3 % |
上記の表から、αβ 法 の場合は 置換表を利用してもあまり大きな効果が得られていない ことがわかります。その理由は、同一局面で α 値と β 値の初期値が一致するノードの数があまり多くない ことが原因です。
そのことは、下記のプログラムで最短の勝利を優先する評価値を計算した場合で上記と同じ処理を実行することで確認することが出来ます。
mbtree_sv = Mbtree.load("../data/abtree_sv_root")
print("ミニマックス法で置換表を利用しない")
mbtree_sv.calc_score_by_ab(mbtree_sv.root, minimax=True, debug=True)
print()
print("ミニマックス法で置換表を利用する")
mbtree_sv.calc_score_by_ab(mbtree_sv.root, minimax=True, use_tt=True, debug=True)
print()
print("αβ 法で置換表を利用しない")
mbtree_sv.calc_score_by_ab(mbtree_sv.root, debug=True)
print()
print("αβ 法で置換表を利用する")
mbtree_sv.calc_score_by_ab(mbtree_sv.root, use_tt=True, debug=True)
実行結果
ミニマックス法で置換表を利用しない
ミニマックス法で計算したか True
計算したノードの数 549946
枝狩りしたノードの数 0
合計 549946
割合 100.0%
ミニマックス法で置換表を利用する
ミニマックス法で計算したか True
計算したノードの数 2271
枝狩りしたノードの数 547675
合計 549946
割合 0.4%
αβ 法で置換表を利用しない
ミニマックス法で計算したか False
計算したノードの数 20866
枝狩りしたノードの数 529080
合計 549946
割合 3.8%
αβ 法で置換表を利用する
ミニマックス法で計算したか False
計算したノードの数 2583
枝狩りしたノードの数 547363
合計 549946
割合 0.5%
下記は上記の結果を表にまとめたものです。この結果から、置換表を利用した場合 はミニマックス法より、αβ 法のほうが効率が悪くなってしまう ことがわかります。
| ミニマックス法 | αβ 法 | |
|---|---|---|
| 置換表の利用なし | 549946 100.0 % |
20866 3.8 % |
| 置換表の利用あり | 2271 0.4% |
2583 0.3 % |
このようなことが起きる理由は以下の通りです。
-
最短の勝利を優先しない場合
- 評価値の種類 が -1、0、1 の 3 種類しかない
- そのため、α 値と β 値の初期値の組み合わせが少ない
- そのため、同一局面で α 値と β 値の初期値が同じノード が 比較的多く存在 する
-
最短の勝利を優先する場合
- 評価値の種類 が -2 ~ 3 の 6 種類もある
- そのため、α 値と β 値の初期値の組み合わせが多い
- そのため、同一局面で α 値と β 値の初期値が同じノード が あまり多く存在しない
このように、局面と α 値と β 値の初期値をキー とした置換表では、α 値と β 値の組み合わせが多くなる と置換表を利用できるノードの数が少なくなるため、置換表による枝狩りの効率が悪くなる という問題があります。また、これまでの例では評価値を整数の値として計算しましたが、評価値を実数で計算 するような場合は α 値と β 値の組み合わせが無数になり、置換表による 枝狩りがほとんど行われなくなる こともあります。
従って、置換表を利用した αβ 法の処理を行う場合は、次回の記事で説明する もっと効率のよい方法 を取る必要があります。余裕がある方はその方法について考えてみて下さい。
今回の記事のまとめ
今回の記事では置換表を利用した αβ 法の処理のバグの検証と、局面 と α 値の初期値 と β 値の初期値という 3 つの値をキーとした置換表の実装方法について紹介しました。
ただし、この実装方法は枝狩りの効率が良くないので、次回の記事ではもっと効率の良い置換表の実装方法について説明します。
本記事で入力したプログラム
| リンク | 説明 |
|---|---|
| marubatsu.ipynb | 本記事で入力して実行した JupyterLab のファイル |
| tree.py | 本記事で更新した tree_new.py |
| ai.py | 本記事で更新した ai_new.py |
次回の記事
-
仮引数
minimaxはデフォルト値がFalseのデフォルト引数なのでこのキーワード引数を記述する必要はありませんが、ミニマックス法を利用していないことを明確にするために記述しています。以後の記事ではminimax=Falseは省略することにします ↩ -
実は恥ずかしながら筆者も昔 αβ 法をしっかりと理解していなかったため、置換表を利用した αβ 法のプログラムを、この間違った方法で記述してしまったことがあります ↩
-
別の順でこの局面になるように着手を行っても構いません ↩
-
ひ孫は英語で great grandchild ですが、$GG$ という表記は長いので 1 文字の $H$ としました ↩
-
$I$ の評価値を計算したフレームが 69 と小さいので先頭から順番に探していますが、$I$ のフレームが大きい場合は $N$ から $I$ と同じ局面になるような着手を辿って探したほうが良いでしょう ↩
-
置換表で評価値が計算されるノード は、最初のフレームで α 値または β 値が更新されるようにした ため、α 値と β 値の初期値を知るため には、その直前のフレームを表示する必要 があります。この点はわかりづらいので次回の記事で修正することにします ↩