目次と前回の記事
これまでに作成したモジュール
以下のリンクから、これまでに作成したモジュールを見ることができます。
| リンク | 説明 |
|---|---|
| marubatsu.py | Marubatsu、Marubatsu_GUI クラスの定義 |
| ai.py | AI に関する関数 |
| test.py | テストに関する関数 |
| util.py | ユーティリティ関数の定義。現在は gui_play のみ定義されている |
| tree.py | ゲーム木に関する Node、Mbtree クラスの定義 |
| gui.py | GUI に関する処理を行う基底クラスとなる GUI クラスの定義 |
AI の一覧とこれまでに作成したデータファイルについては、下記の記事を参照して下さい。
置換表付き αβ 法の枝狩りの効率の確認
αβ 法で用いる置換表 としては、前回の記事で紹介した ミニマックス値の下界と上界を記録する手法が一般的 だと思います。以後はそのような置換表を利用した αβ 法のことを「置換表付き αβ 法」と表記することにします。
前回の記事では置換表付き αβ 法の枝狩りの効率の検証を行っていなかったので、その検証を行うことにします。
計算したノードの数と枝狩りが行われた数の計算方法
これまでは、ミニマックス法や αβ 法で評価値を計算する際に 計算したノードの数 や、枝狩りが行なわれたノードの数 を Mbtree クラスの calc_score_by_ab メソッドを実行して計算していました。同様の方法で置換表付き αβ 法で計算したノードの数や、枝狩りが行なわれたノードの数を確認するためには、calc_score_by_ab を置換表付き αβ 法の処理を 行うことができるように修正する必要 がありますが、実はもっと簡単に計算を行うことができます。その方法について少し考えてみて下さい。
計算が行われたノードの数の確認方法とその問題点
ai_mmbfs、ai_abs、ai_abs_tt2 などの、ミニマックス法や αβ 法で評価値を計算する AI の関数では、評価値を計算する際に 計算を行なったノードの数を count という変数で数えており、キーワード引数に debug=True を記述して呼び出すことで、計算を行なったノードの数を表示 するようになっているので、これを利用することができます。
例えば前回の記事で実装した置換表付き αβ 法で着手を選択する ai_abs_tt2 の場合は、下記の実行結果の count = 772 のように計算を行なったノードの数が表示されます。
from marubatsu import Marubatsu
from ai import ai_abs_tt2
mb = Marubatsu()
ai_abs_tt2(mb, debug=True)
実行結果
Start ai_by_score
Turn o
...
...
...
legal_moves [(0, 0), (1, 0), (2, 0), (0, 1), (1, 1), (2, 1), (0, 2), (1, 2), (2, 2)]
====================
move (0, 0)
Turn x
O..
...
...
count = 772
score 0 best score -inf
UPDATE
best score 0
best moves [(0, 0)]
====================
move (1, 0)
Turn x
.O.
...
...
count = 786
略
ただし、上記の実行結果からわかるように、実際には count = 772、count = 786 のように、複数の count が表示 されます。このようなことが起きる理由は、ai_abs_tt2 などの、@ai_by_score という デコレータ式によって機能を拡張 した AI の関数が、以下のようなアルゴリズムで着手を選択しているからです。なお、デコレータ式による AI の関数の定義について忘れた方は以前の記事を復習して下さい。
-
@ai_by_scoreによってラップされる 機能が拡張される前の関数 は、指定した局面の評価値 を計算して 返り値として返す という処理を行う -
@ai_by_scoreは、ラップする関数を利用して 指定された局面の全ての子ノードの評価値を計算 し、子ノードの評価値が最も高い合法手 の中から ランダムに着手を選択 するという処理を行う - 従って、指定したノードの 全ての子ノードに対して 置換表付き αβ 法の 処理が行われ、それぞれの子ノードの評価値を計算する際に 計算したノードの数が順番に表示 される。上記の実行結果の場合は、以下のように count が表示される
- 最初の count = 772 その上に表示される (0, 0) を着手した局面 の評価値を計算した際に 計算されたノードの数 を表す
- 次の count = 786 はその上に表示される (1, 0) を着手した局面 の評価値を計算した際に 計算されたノードの数 を表す
@ai_by_score によって 機能が拡張される前 の ai_abs_tt2 を 呼び出すことができれば、指定した局面の 評価値を置換表付き αβ 法で計算した際に 計算されたノードの数だけを表示 することができますが、残念ながら以前の記事で説明したように、デコレータ式が適用された関数 は、デコレータ式によって 機能が拡張される前のラップされた関数を呼び出すことができなくなります。この問題を解決する方法について少し考えてみて下さい。
ai_by_score の修正
この問題を解決する方法の一つに、ai_by_score 内で定義された ラッパー関数 に、True を代入した場合に ラップする関数を呼び出す処理 を行うという 仮引数を追加する という方法があります。具体的には、仮引数 calc_score を追加 し、True が代入されいてた場合は 指定された局面(mborig)の評価値を計算(calculate score)して返す ように修正します。下記は、そのように ai_by_score を修正したプログラムです。
-
7 行目:ラッパー関数の仮引数にデフォルト値が
Falseに設定されたデフォルト引数calc_scoreを追加する -
8、9 行目:関数のブロックの最初で
calc_scoreがTrueの場合にmb_origの局面の評価値を計算して返すように修正する
1 from ai import dprint
2 from copy import deepcopy
3 from functools import wraps
4
5 def ai_by_score(eval_func):
6 @wraps(eval_func)
7 def wrapper(mb_orig, debug=False, *args, rand=True, analyze=False, calc_score=False, **kwargs):
8 if calc_score:
9 return eval_func(mb_orig, debug, *args, **kwargs)
元と同じなので省略
行番号のないプログラム
from ai import dprint
from copy import deepcopy
from functools import wraps
def ai_by_score(eval_func):
@wraps(eval_func)
def wrapper(mb_orig, debug=False, *args, rand=True, analyze=False, calc_score=False, **kwargs):
if calc_score:
return eval_func(mb_orig, debug, *args, **kwargs)
dprint(debug, "Start ai_by_score")
dprint(debug, mb_orig)
legal_moves = mb_orig.calc_legal_moves()
dprint(debug, "legal_moves", legal_moves)
best_score = float("-inf")
best_moves = []
if analyze:
score_by_move = {}
for move in legal_moves:
dprint(debug, "=" * 20)
dprint(debug, "move", move)
mb = deepcopy(mb_orig)
x, y = move
mb.move(x, y)
dprint(debug, mb)
score = eval_func(mb, debug, *args, **kwargs)
dprint(debug, "score", score, "best score", best_score)
if analyze:
score_by_move[move] = score
if best_score < score:
best_score = score
best_moves = [move]
dprint(debug, "UPDATE")
dprint(debug, " best score", best_score)
dprint(debug, " best moves", best_moves)
elif best_score == score:
best_moves.append(move)
dprint(debug, "APPEND")
dprint(debug, " best moves", best_moves)
dprint(debug, "=" * 20)
dprint(debug, "Finished")
dprint(debug, "best score", best_score)
dprint(debug, "best moves", best_moves)
if analyze:
return {
"candidate": best_moves,
"score_by_move": score_by_move,
}
elif rand:
return choice(best_moves)
else:
return best_moves[0]
return wrapper
修正箇所
from ai import dprint
from copy import deepcopy
from functools import wraps
def ai_by_score(eval_func):
@wraps(eval_func)
- def wrapper(mb_orig, debug=False, *args, rand=True, analyze=False, **kwargs):
+ def wrapper(mb_orig, debug=False, *args, rand=True, analyze=False, calc_score=False, **kwargs):
+ if calc_score:
+ return eval_func(mb_orig, debug, *args, **kwargs)
元と同じなので省略
様々な AI での計算したノード数の確認
次に、上記で修正した ai_by_score が正しく動作するか どうかを、様々な AI の関数 でルートノードの評価値を計算した際に 計算されたノードの数の表示が、以前の記事で calc_score_by_ab で計算した値と等しくなるか どうかで 確認する ことにします。
ただし、現状の ai.py は ai_by_score の内容が更新されていない ので、from ai import ai_abs_tt2 のように ai.py から AI の関数をインポートした場合 は、修正前の ai_by_score が適用されてしまう のでうまくいきません。そこで、本記事では ai.py の中で、ai_by_score の部分だけを今回の記事で修正した内容に更新 した ai2.py というファイルを用意し、ai2.py から AI の関数をインポートする ことにします。なお、ai_by_score の修正は次回の記事以降の ai.py には反映するので、ai2.py を用意するのは今回の記事のみです。
下記のプログラムで、以下のそれぞれの場合でルートノードの評価値を計算した際に計算されるノード数を表示します。
- 置換表を利用しないミニマックス法(
ai_mmdfs) - 置換表を利用したミニマックス法(
ai_mmdfs_tt) - 置換表を利用しない αβ 法(
ai_abs) - 局面と α 値と β 値の初期値をキーとした置換表を利用する αβ 法(
ai_abs_tt) - 置換表付き αβ 法(
ai_abs_tt2)
from ai2 import ai_mmdfs, ai_mmdfs_tt, ai_abs, ai_abs_tt, ai_abs_tt2
ai_mmdfs(mb, calc_score=True, debug=True)
ai_mmdfs_tt(mb, calc_score=True, debug=True)
ai_abs(mb, calc_score=True, debug=True)
ai_abs_tt(mb, calc_score=True, debug=True)
ai_abs_tt2(mb, calc_score=True, debug=True)
実行結果
count = 549946
count = 2271
count = 18297
count = 1718
count = 1208
0
実行結果から、最初の 4 つの場合 で計算されたノードの数が、以前の記事で calc_score_by_ab で計算した値と 同じであることが確認 できました1。
また、今回の記事で実装した 置換表付き αβ 法 の ai_abs_tt2 は、下記のように 枝狩りの効率が向上 していることが確認できます。
- 置換表を利用したミニマックス法の
ai_mmdfs_ttと比べて 計算するノードの数が 約半分になっている - 局面と α 値と β 値の初期値をキーとした置換表を利用する αβ 法の
ai_abs_ttと比べて 計算するノードの数が 約 2/3 になっている
枝狩りが行われた数などの確認
上記の count は計算されたノードの数を表しており、calc_score_by_ab のように 枝狩りが行なわれたノードの数 や、計算が行われたノードの割合 は 計算されていません。ただし、以下の理由から ai_by_score を修正して、枝狩りが行なわれた数や計算が行われたノードの割合を 計算するようにするべきではありません。また、ai_by_score を修正しなくても、枝狩りが行われたノードの数などを 計算することは可能 です。どのようにして計算すればよいかについて少し考えてみて下さい。
- 枝狩りの処理 は必要のない処理を省略することで、評価値を計算する 処理を高速化することが目的 である
- 枝狩りが行われたノードの数を数えるという処理は、評価値の計算を行う際には必要のない処理 であり、その処理を行うことで その分だけ処理に時間がかかってしまう ため、枝狩りの目的に反する
枝狩りが行われた数と計算が行われたノードの割合は、下記の方法で簡単に計算することができます。
-
置換表を利用しないミニマックス法 では 枝狩りは行なわれない ので、
ai_mmdfsで評価値の計算を行うことで ノードの総数がわかる - ノードの総数から、計算されたノードの数を 引き算する ことで 枝狩りされたノードの数を計算できる
-
例えば置換表付き αβ 法 の場合は、
ai_abs_tt2で count = 1208 と表示されるので 枝狩りされたノードの数 は 549946 - 1208 = 548738 であり、計算されたノードの割合 は 1208 / 548738 = 約 0.2 % であることが計算できる
なお、今回の記事では calc_score_by_ab を修正しませんでしたが、calc_score_by_ab は 評価値を計算する手順を Mbtree_Anim で視覚化するためのデータを計算する という目的があるので、次回の記事で calc_score_by_ab が置換表付き αβ 法で評価値を計算できるように修正する予定です。
置換表付き αβ 法の枝狩りの効率化
前回の記事の最後で言及しましたが、現状の ai_abs_tt2 には 効率が悪い点 があります。問題は 置換表に 計算した ミニマックス値の下界と上界のデータを記録する処理 にあるので、どのような問題があるかについて少し考えてみて下さい。
置換表へのデータの記録の処理の問題点
ai_abs_tt2 では、以下のような手順で処理が行われます。なお、前回の記事と同様に、ノードの局面の ミニマックス値が取りうる範囲 のことを「評価値の範囲」、ミニマックス値の 下界 と 上界 のことを単に「下界」と「上界」と表記することにします。また、下記の処理について忘れた方は前回の記事を復習して下さい。
- リーフノードの場合は勝敗結果から 評価値を計算して返す
- 置換表にノードの評価値の範囲が記録されていた場合は下記の処理を行う
- 下界と上界が等しい場合は正確なミニマックス値が記録されているのでその値をこのノードの 評価値として返す
- 評価値の範囲がこのノードの fail low の範囲に完全に含まれる場合は上界をこのノードの 評価値として返す
- 評価値の範囲がこのノードの fail high の範囲に完全に含まれる場合は下界をこのノードの 評価値として返す
- そうでない場合は評価値の範囲と exact value の範囲(α 値と β 値の初期値の範囲)のうち重なる部分が範囲となるように α 値と β 値の初期値を更新し、3 の処理を行う
- 子ノードの評価値を計算することで、このノードの評価値を計算する
- 計算した評価値から求められたこのノードの評価値の範囲を置換表に記録する
上記の太字の部分 が、ai_abs_tt2 の処理の途中で return 文によって 評価値を返り値として返す という処理を意味しています。従って、上記の 手順 4 で評価値の範囲を 置換表に記録する処理 は、以下の 2 種類の場合で実行 されます。
- そのノードの評価値の範囲が 置換表に記録されていなかった場合
- そのノードの評価値の範囲が 置換表に記録されているが、上記の 手順 2-1 ~ 2-3 の条件を満たさなかった場合
前者の、そのノードの情報が 置換表に記録されていなかった場合 は 手順 4 の処理を行っても特に 問題はありません が、後者の場合には 置換表に記録する評価値の範囲 が、計算によって求められた評価値の範囲よりも広くなる 可能性あります。
問題が発生する具体例
わかりづらいと思いますので、そのようなことが起きる具体例を挙げて説明します。
あるノード $N$ の評価値を置換表付き αβ 法で計算する際に、置換表に記録されていた ミニマックス値の 下界が 負の無限大、上界が 3、α 値と β 値の初期値 が -1 と 1 であったとします。下図はそのことを図にしたもので、赤い矢印 が置換表に記録されていたノード $N$ の 評価値の範囲 を表しています。なお、図の記号は前回の記事と同様に、下界(lower bound)を頭文字を取って $l$、上界(upper bound)を $u$、α 値と β 値の初期値をそれぞれ $α$、$β$ と表記することにします。

上図からわかるように赤い矢印の 評価値の範囲 は先程の 手順 2-1 ~ 2-3 のいずれも満たさない ので、手順 3 で 子ノードの評価値から このノードの評価値を計算する必要 があります。なお、手順 2-4 では、評価値の範囲が exact value の範囲をすべて含んでいる ので、α 値と β 値の初期値 は -1 と 1 のまま 変更しません。
その後 手順 3 で このノードの評価値として 2 が計算された場合 のことを考えることにします。また、以後は 手順 3 で計算された評価値(score)のことを $s$ という記号で表記 することにします。
$s = 2$ は 下図のように fail high の範囲内 なので $N$ の局面の 評価値の範囲 は下図の 緑の矢印の範囲 である 2 以上 となります。従って、手順 4 では置換表にこのノードのミニマックス値の 下界と上界 として 2 と 正の無限大 が記録されることになりますが、これはおかしくないでしょうか?何がおかしいかについて少し考えてみて下さい。
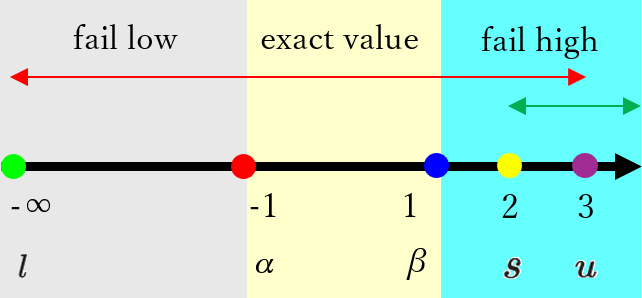
おかしな点は以下の通りです。
- 置換表に記録されていた このノードの 評価値の範囲 は上図の 赤い矢印の範囲 である
- このノードの評価値を計算した結果、このノードの 評価値の範囲 が上図の 緑色の範囲であることがわかった
- 従って、このノードの評価値の範囲 は 赤い矢印と緑の矢印 の 両方の範囲を含む 必要があり、その範囲は下図の 紫の矢印の範囲 である 2 以上 3 以下 であることがわかる
- それにも関わらず、手順 4 では置換表に 2 以上 3 以下の 紫の矢印の範囲よりも広い範囲 である、緑の矢印の範囲が記録されてしまう

置換表に記録する下界と上界 は、上図の紫の矢印の範囲を見れば 2 と 3 であることがわかりますが、それらを 計算によって求める必要 があります。どのような計算を行えば良いかについて少し考えてみて下さい。
置換表に記録する下界と上界の計算方法
置換表に記録する下界と上界 は、赤い矢印と緑の矢印の範囲で 共通する範囲の下界と上界 です。上図から、その 下界 は 赤い矢印の範囲の下界 と、緑の矢印の範囲の下界 のうち 大きいほう であることがわかります。同様に上界は赤い矢印の範囲の上界と、緑の矢印の範囲の上界のうち小さいほうになります。従って、置換表に記録する下界と上界 は下記のように計算することができます。
-
下界 を以下の 最大値 とする。上図の場合は負の無限大と 2 の最大値なので 2 となる
- 置換表に記録されていた下界(上図の赤い矢印の左端の値)である $l$
- このノードの評価値の計算によって求められた下界(上図の緑の矢印の左端の値)
-
上界 を以下の 最小値 とする。上図の場合は 3 と正の無限大の最小値なので 3 となる
- 置換表に記録されていた上界(上図の赤い矢印の右端の値)である $u$
- このノードの評価値の計算によって求められた上界(上図の緑の矢印の右端の値)
従って、$s$ によって計算される 評価値の範囲の 下界と上界がわかれば 置換表に記録する下界と上界を計算することができます。慣れている人はこの時点で置換表に記録する下界と上界を計算する処理を行うプログラムを記述できるかもしれませんが、慣れていない人 は前回の記事と同様に 場合分けを行う と良いでしょう。具体的には $s$ が fail low、exact value、fail high の それぞれの場合 について考えます。
fail low の場合
fail low の場合は、$s$ によって計算される緑の矢印の評価値の範囲の 下界は負の無限大、上界は $s$ と計算されます。従って、置換表に記録する下界と上界 は下記のように計算することができます。
-
下界 は $l$ と負の無限大の 最大値 となるので、下記の理由から $l$ を記録すればよい
- $l$ が負の無限大の場合は どちらも負の無限大 になるので、最大値は $l$ と同じ負の無限大 になる
- $l$ が負の無限大でなければ、最大値は $l$ になる
-
上界 は $u$ と $s$ の 最小値 を記録すればよい。ただし、下記の理由から $s < u$ という性質が満たされる ので、$s$ を記録すればよい
- $u ≦ α$ という条件が満たされる と先程の「置換表に記録されていた評価値の範囲がこのノードの fail low の範囲に完全に含まれる場合は上界をこのノードの評価値として返す」という手順 2-2 によって処理が終了してしまうので 手順 4 の処理が行われなくなる ため、$u ≦ α$ という条件は満たされない。従って $α < u$ である
- $s$ は fail low なので $s ≦ α$ という条件が満たされる
- $s ≦ α$ と $α < u$ から、$s < u$ である
exact value の場合
exact value の場合は $s$ には 正確なミニマックス値 が求められます。特定の値と、範囲のある値の 共通する範囲 は 特定の値になる ので、置換表の下界と上界 には $s$ を記録 します。
fail high の場合
fail high の場合は、下界は $s$、上界は正の無限大 と計算されます。fail low の場合と同様の理由 から、置換表に記録する下界と上界は以下のようになります。
- 下界 は $l$ と $s$ の最大値である。fail low と同様の理由から $l < s$ が満たされるので、$s$ を記録すればよい
- 上界 は $u$ と 正の無限大の最小値となる。fail low と同様の理由で $u$ を記録すればよい
上記をまとめた表
上記の説明を表にまとめると以下のようになります。下記の表では $a$ と $b$ の最小値を $min(a, b)$、最大値を $max(a, b)$ と表記しています。
| fail low | exact value | fail high | |
|---|---|---|---|
| 置換表に記録されていた下界 | $l$ | $l$ | $l$ |
| $s$ によって求められた下界 | $-∞$ | $s$ | $s$ |
| 置換表に記録する下界 | $max(l, -∞) = l$ | $s$ | $max(l, s) = s$ |
| 置換表に記録されていた上界 | $u$ | $u$ | $u$ |
| $s$ によって求められた上界 | $s$ | $s$ | $∞$ |
| 置換表に記録する上界 | $min(u, s) = s$ | $s$ | $min(u, ∞) = u$ |
上記の表から 置換表に記録する下界と上界 のみを取り出すと以下の表のようになります。
| fail low | exact value | fail high | |
|---|---|---|---|
| 置換表に記録する下界 | $l$ | $s$ | $s$ |
| 置換表に記録する上界 | $s$ | $s$ | $u$ |
置換表にノードの情報が記録されていない場合の処理との統合
上記の表は、置換表に評価値の範囲が記録されている場合 に行う処理です。置換表に評価値の範囲が 記録されていない場合 は、前回の記事で説明したように 下記の表の処理を行う ので、置換表にノードの情報が 記録されている場合とされていない場合 で 異なる処理を行う ようなプログラムを記述する必要があると思った人がいるかもしれません。しかし、工夫をすること で上記の表と、下記の表の処理を うまく統合することができます。どのようにすれば良いかについて少し考えてみて下さい。
| fail low | exact value | fail high | |
|---|---|---|---|
| 置換表に記録する下界 | $-∞$ | $s$ | $s$ |
| 置換表に記録する上界 | $s$ | $s$ | $∞$ |
先程の表と上記の表の 違い は、$l$ が $-∞$ である点と、$u$ が $∞$ である 点だけです。従って、置換表に評価値の範囲が 記録されていない場合 は $l = -∞$、$u = ∞$ とする ことで置換表に評価値の範囲が 記録されている場合と同じ方法 で計算を行うことができます。
このことは言葉で説明することもできます。置換表に 評価値の範囲が記録されていない ということは、そのノードの評価値の範囲が 全くわかっていない という事を意味するので、評価値の範囲は 負の無限大から正の無限大まで のすべての実数の範囲と 考えることができます。従って、そのような場合は評価値の範囲として 下界を負の無限大、上界を正の無限大 とみなすことができます。
上記をまとめると以下のようになります。
置換表付き αβ 法では、置換表を更新する処理は以下のように行う。
- 置換表に評価値の範囲が 記録されている場合 は $l$ と $u$ を 置換表に記録されていた下界と上界の値 とする
- 置換表に評価値の範囲が 記録されていない場合 は $l$ と $u$ を 負の無限大と正の無限大 とする
- 置換表に記録する上界と下界を下記の表のように計算する
| fail low | exact value | fail high | |
|---|---|---|---|
| 置換表に記録する下界 | $l$ | $s$ | $s$ |
| 置換表に記録する上界 | $s$ | $s$ | $u$ |
ai_abs_tt3 の定義
上記のように置換表にデータを記録する処理を行う ai_abs_tt3 は、ai_abs_tt2 を修正して下記のプログラムのように定義することができます。
-
2 行目:関数名を
ai_abs_tt3に修正した - 8 ~ 10 行目:置換表に評価値の範囲が 記録されていない場合 に下界と上界を記録する変数に 負の無限大と正の無限大を代入 するように修正する
-
12 ~ 18 行目:先程の表に従って置換表に記録する下界と上界の値を計算する。修正前のプログラムでは fail low の場合に
lower_boundに負の無限大を 12 行目の下で代入していたが、置換表に評価値の範囲が記録されている場合は 7 行目で、記録されていない場合は 9 行目でlower_boundに下界の値を代入する処理が行なわれるようになるので 12 行目の下にあったlower_boundに値を代入する処理は削除した。18 行目の下にあった fail high の場合のupper_boundに正の無限大を代入する処理も同様の理由で削除した
1 @ai_by_score
2 def ai_abs_tt3(mb, debug=False, shortest_victory=False):
3 count = 0
4 def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
5 boardtxt = mborig.board_to_str()
6 if boardtxt in tt:
7 lower_bound, upper_bound = tt[boardtxt]
元と同じなので省略
8 else:
9 lower_bound = float("-inf")
10 upper_bound = float("inf")
元と同じなので省略
11 boardtxtlist = calc_same_boardtexts(mborig)
12 if score <= alphaorig:
13 upper_bound = score
14 elif score < betaorig:
15 lower_bound = score
16 upper_bound = score
17 else:
18 lower_bound = score
19 for boardtxt in boardtxtlist:
20 tt[boardtxt] = (lower_bound, upper_bound)
21 return score
元と同じなので省略
行番号のないプログラム
@ai_by_score
def ai_abs_tt3(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return (11 - mborig.move_count) / 2 if shortest_victory else 1
elif mborig.status == Marubatsu.CROSS:
return (mborig.move_count - 10) / 2 if shortest_victory else -1
elif mborig.status == Marubatsu.DRAW:
return 0
boardtxt = mborig.board_to_str()
if boardtxt in tt:
lower_bound, upper_bound = tt[boardtxt]
if lower_bound == upper_bound:
return lower_bound
elif upper_bound <= alpha:
return upper_bound
elif beta <= lower_bound:
return lower_bound
else:
alpha = min(alpha, lower_bound)
beta = max(beta, upper_bound)
else:
lower_bound = float("-inf")
upper_bound = float("inf")
alphaorig = alpha
betaorig = beta
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
score = float("-inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = max(score, ab_search(mb, tt, alpha, beta))
if score >= beta:
break
alpha = max(alpha, score)
else:
score = float("inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = min(score, ab_search(mb, tt, alpha, beta))
if score <= alpha:
break
beta = min(beta, score)
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(mborig)
if score <= alphaorig:
upper_bound = score
elif score < betaorig:
lower_bound = score
upper_bound = score
else:
lower_bound = score
for boardtxt in boardtxtlist:
tt[boardtxt] = (lower_bound, upper_bound)
return score
score = ab_search(mb, {})
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
修正箇所
@ai_by_score
-def ai_abs_tt2(mb, debug=False, shortest_victory=False):
+def ai_abs_tt3(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
boardtxt = mborig.board_to_str()
if boardtxt in tt:
lower_bound, upper_bound = tt[boardtxt]
元と同じなので省略
+ else:
+ lower_bound = float("-inf")
+ upper_bound = float("inf")
元と同じなので省略
boardtxtlist = calc_same_boardtexts(mborig)
if score <= alphaorig:
- lower_bound = float("-inf")
upper_bound = score
elif score < betaorig:
lower_bound = score
upper_bound = score
else:
lower_bound = score
- upper_bound = float("inf")
for boardtxt in boardtxtlist:
tt[boardtxt] = (lower_bound, upper_bound)
return score
元と同じなので省略
ai_abs_tt3 が強解決の AI であることの確認
上記で定義した ai_abs_tt3 が強解決の AI であることを下記のプログラムで確認すると、実行結果のように 強解決の AI であることが確認 できました。
from util import Check_solved
Check_solved.is_strongly_solved(ai_abs_tt3)
実行結果
100%|██████████| 431/431 [00:03<00:00, 130.48it/s]
431/431 100.00%
(True, [])
枝狩りの効率の確認
下記のプログラムで ai_abs_tt3 でルートノードの評価値を計算した際に 計算されたノードの数を表示 すると、ai_abs_tt2 の場合の 1208 と比べて 約 3 % ほど減っており、より多くの枝狩りを行うことができるようになった ことが確認できます。
〇× ゲームのゲーム木の場合 は 枝狩りの効率はほとんど上昇しません が、他のゲーム のゲーム木の場合では もっと枝狩りの効率が上がる場合がある ようです。
ai_abs_tt3(mb, calc_score=True, debug=True)
実行結果
count = 1173
0
評価値の最小値の最大値を利用した改良
以前の記事と以前の記事で ルートノードの α 値と β 値の初期値 を 評価値の最小値と最大値に設定 することで 枝狩りの効率を上げる という方法を説明したので、その方法で置換表付き αβ 法による着手を行う ai_abs_tt4 を下記のプログラムのように定義する事にします。
その際に、評価値の範囲が置換表に 記録されていなかった場合 の 下界と上界 を 評価値の最小値と最大値に設定 することができます。
- 10、11 行目:評価値の最小値と最大値を計算して変数に代入する
- 13 行目:α 値と β 値の初期値を評価値の最小値と最大値に設定してルートノードの評価値を計算するように修正する
- 8、9 行目:ノードの情報が置換表に 記録されていない場合の下界と上界 を 評価値の最小値と最大値 に修正する
1 @ai_by_score
2 def ai_abs_tt4(mb, debug=False, shortest_victory=False):
3 count = 0
4 def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
5 if boardtxt in tt:
6 lower_bound, upper_bound = tt[boardtxt]
元と同じなので省略
7 else:
8 lower_bound = min_score
9 upper_bound = max_score
元と同じなので省略
10 min_score = -2 if shortest_victory else -1
11 max_score = 3 if shortest_victory else 1
12
13 score = ab_search(mb, {}, alpha=min_score, beta=max_score)
14 dprint(debug, "count =", count)
15 if mb.turn == Marubatsu.CIRCLE:
16 score *= -1
17 return score
行番号のないプログラム
@ai_by_score
def ai_abs_tt4(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return (11 - mborig.move_count) / 2 if shortest_victory else 1
elif mborig.status == Marubatsu.CROSS:
return (mborig.move_count - 10) / 2 if shortest_victory else -1
elif mborig.status == Marubatsu.DRAW:
return 0
boardtxt = mborig.board_to_str()
if boardtxt in tt:
lower_bound, upper_bound = tt[boardtxt]
if lower_bound == upper_bound:
return lower_bound
elif upper_bound <= alpha:
return upper_bound
elif beta <= lower_bound:
return lower_bound
else:
alpha = min(alpha, lower_bound)
beta = max(beta, upper_bound)
else:
lower_bound = min_score
upper_bound = max_score
alphaorig = alpha
betaorig = beta
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
score = float("-inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = max(score, ab_search(mb, tt, alpha, beta))
if score >= beta:
break
alpha = max(alpha, score)
else:
score = float("inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = min(score, ab_search(mb, tt, alpha, beta))
if score <= alpha:
break
beta = min(beta, score)
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(mborig)
if score <= alphaorig:
upper_bound = score
elif score < betaorig:
lower_bound = score
upper_bound = score
else:
lower_bound = score
for boardtxt in boardtxtlist:
tt[boardtxt] = (lower_bound, upper_bound)
return score
min_score = -2 if shortest_victory else -1
max_score = 3 if shortest_victory else 1
score = ab_search(mb, {}, alpha=min_score, beta=max_score)
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
修正箇所
@ai_by_score
def ai_abs_tt4(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
if boardtxt in tt:
lower_bound, upper_bound = tt[boardtxt]
元と同じなので省略
else:
lower_bound = min_score
upper_bound = max_score
元と同じなので省略
min_score = -2 if shortest_victory else -1
max_score = 3 if shortest_victory else 1
score = ab_search(mb, {}, alpha=min_score, beta=max_score)
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
max node の場合に評価値を計算する変数 score の初期値を下記のプログラムのように評価値の最小値に変更することもできます2が、変更してもしなくても 計算される結果は変わらない ので本記事では変更しないことにします。変更したい人は自由に変更して下さい。
if mborig.turn == Marubatsu.CIRCLE:
score = min_score
修正箇所
if mborig.turn == Marubatsu.CIRCLE:
- score = float("-inf")
+ score = min_score
ai_abs_tt4 が強解決の AI であることの確認
上記で定義した ai_abs_tt4 が強解決の AI であることを下記のプログラムで確認すると、実行結果のように 強解決の AI である ことが確認できました。
Check_solved.is_strongly_solved(ai_abs_tt4)
実行結果
100%|██████████| 431/431 [00:02<00:00, 202.14it/s]
431/431 100.00%
(True, [])
枝狩りの効率の確認
下記のプログラムで ai_abs_tt4 でルートノードの評価値を計算した際に 計算されたノードの数 を表示すると、ai_abs_tt3 の場合の 1173 の 約 70 % となっていることから、枝狩りの効率がかなり上昇する ことが確認できました。
ai_abs_tt4(mb, calc_score=True, debug=True)
実行結果
count = 832
0
今回の記事のまとめ
今回の記事では、置換表付き αβ 法 での 置換表への下界と上界の記録処理を改良 しました。また、置換表付き αβ 法でも α 値と β 値の初期値 を 評価値の最小値と最大値とする ことで、枝狩りの効率を上げることができる ことを確認しました。
本記事で入力したプログラム
| リンク | 説明 |
|---|---|
| marubatsu.ipynb | 本記事で入力して実行した JupyterLab のファイル |
| ai.py | 本記事で更新した ai_new.py |
次回の記事