目次と前回の記事
これまでに作成したモジュール
以下のリンクから、これまでに作成したモジュールを見ることができます。
| リンク | 説明 |
|---|---|
| marubatsu.py | Marubatsu、Marubatsu_GUI クラスの定義 |
| ai.py | AI に関する関数 |
| test.py | テストに関する関数 |
| util.py | ユーティリティ関数の定義。現在は gui_play のみ定義されている |
| tree.py | ゲーム木に関する Node、Mbtree クラスの定義 |
| gui.py | GUI に関する処理を行う基底クラスとなる GUI クラスの定義 |
AI の一覧とこれまでに作成したデータファイルについては、下記の記事を参照して下さい。
αβ 法が計算する評価値の意味のおさらいと用語の修正
前回の記事では、αβ 法が計算する評価値 が下記の表の意味を持つことを示しました。
なお、前回の記事では ミニマックス法で計算された評価値 のことを 本当の評価値と表記していました が、その表記はわかりづらい点と ミニマックス値という用語が使われる場合がある ようなので、今回の記事からは ミニマックス値 と表記することにします。また、αβ 法で計算された評価値 のことを αβ 値 と表記することにします。
| $S'_N$ の範囲 | $S_N$ との関係 | 意味 | 用語 |
|---|---|---|---|
| $S'_N ≦ α$ | $S_N ≦ S'_N$ | ミニマックス値は $S'_N$ 以下 ミニマックス値の上界がわかる |
fail low |
| $α < S'_N < β$ | $S_N = S'_N$ | ミニマックス値が求められる | exact value |
| $β ≦ S'_N$ | $S'_N ≦ S_N$ | ミニマックス値は $S'_N$ 以上 ミニマックス値の下界がわかる |
fail high |
なお、上記の表の記号や用語の意味は以下の通りです。下界と上界の詳細については前回の記事を参照して下さい。
| 記号、用語 | 意味 |
|---|---|
| $N$ | αβ 法で評価値を計算するノード |
| α、β | $N$ の評価値を計算する際の α 値と β 値の初期値 |
| $S_N$ | ミニマックス法で計算した $N$ の本当の評価値である ミニマックス値 |
| $S_N'$ | αβ 法で計算した $N$ の αβ 値。ミニマックス値とは異なる場合がある |
| 下界 | ある値がとりうる値の最小値以下の値。英語では lower bound ある値が 少なくとも下界以上の値 であることを意味する 最小値と異なり、ある値が下界の値を実際に取るとは限らない |
| 上界 | ある値がとりうる値の最大値以上の値。英語では upper bound ある値が 少なくとも上界以下の値 であることを意味する 最大値と異なり、ある値が上界の値を実際に取るとは限らない 下界と上界によって ある値が少なくともその範囲内にある ことがわかる |
| fail low | αβ 法で計算された値が α 値の初期値以下 の場合で、ミニマックス値の上界が計算された ことを表す用語1 |
| exact value | αβ 法で計算された値が α 値と β 値の初期値の間 の場合で、ミニマックス値が計算された ことを表す用語2 |
| fail high | αβ 法で計算された値が α 値の初期値以上 の場合で、ミニマックス値の下界が計算された ことを表す用語1 |
下界と上界は最小値、最大値と 混同されやすい ので改めて補足します。
上界は、ある値が 少なくともその値以下である を意味し、最大値と異なり上界以下の値で、実際に取ることはない値が存在する可能性があります。
上界は現実の世界では何らかの値の 正確な最大値や上限がわからない場合 に、少なくともその値以下であるということを示す値として良く使われます。例えば 人間の年齢 の 正確な最大値わかりません が、実際にはあり得ない 200 才のような 年齢を上界 として、少なくとも 200 才以下であると表現する ことがあります3。
α 値と β 値の関係に関する補足
前回の記事で説明し忘れたことがあったことに気づいたので補足します。
上記の表では exact value の範囲を $α < S'_N < β$ と記述していますが、この式は $α < β$ であるという意味を表しているので、この表は $α < β$ という条件が成り立つことを前提 に作られています。α 値と β 値の初期値が等しい場合について考えなくても良いのだろうか と思った人がいるかもしれませんが、下記のような理由から、α 値と β 値の初期値が等しくなることは通常はありません。
- ルートノード の α 値と β 値の初期値 は 通常は $α < β$ という関係がある。その理由についてはこの後で説明する
- max ノードでは α 値は子ノードの評価値が α 値を超えた場合に更新されるが、子ノードの評価値が β 値以上になった時点で β 狩りが行われるので、α 値が β 値以上になった状態で子ノードの評価値が計算されることはない
- min ノードでも同様の理由で、β 値が α 値以下になった状態で子ノードの評価値が計算されることはない
- 従って、ルートノード以外 のノードでも $α < β$ という関係がある
ルートノード の α 値と β 値の初期値 が 通常は $α < β$ となる理由 は以下の通りです。
- αβ 法でルートノードの本当の評価値である ミニマックス値を計算する ためには、評価値の範囲が exact value の範囲に含まれる 必要がある。従って、ルートノードの α 値と β 値の初期値の範囲 は 評価値の最小値から最大値の範囲を含む 必要がある
- ルートノードの α 値と β 値の初期値が等しい場合 は、評価値の範囲が特定の値である ことが あらかじめわかっている ということなので、そのような場合はそもそも αβ 法で評価値を計算する必要がない
- 従って、ルートノードでミニマックス値を計算する場合は 通常は α 値と β 値の初期値は異なる値になる ので、$α < β$ である
今回の記事では α 値と β 値の初期値 の間に $α < β$ という関係が成り立つことを前提 に説明を行います。
上記は ルートノードのミニマックス値を計算する という前提での話なので、ルートノードの ミニマックス値を計算する必要がない場合 は、α 値と β 値の初期値を 等しく設定してもかまいません。実際に α 値と β 値の初期値を等しく設定して αβ 法で評価値を計算することがあり、そのような場合のことを null window search と呼びます。null window search の意味や使い方については今後の記事で紹介します。
ミニマックス値の下界と上界を記録する置換表
以前の記事では αβ 法の置換表を表す dict のキーを 局面 と α 値の初期値 と β 値の初期値 を表す tuple とし、そのキーの値にその場合に αβ 法で計算された評価値を記録しましたが、その方法では 置換表による枝狩りの効率が悪い という問題がありました。
枝狩りを効率よく行うため方法として、置換表を表す dict の キーを 局面だけ のデータに戻し、キーの値には αβ 法で計算された ミニマックス値がとりうる範囲を記録 するという方法があります。具体的には置換表のキーの値には αβ 法で計算された評価値 $S_N'$ の値の 分類に応じて、ミニマックス値の 下界 と 上界 を下記の表のように記録します。
| 分類 | 下界 | 上界 | 意味 |
|---|---|---|---|
| fail low | 負の無限大 | $S_N'$ | ミニマックス値は $S_N'$ 以下 |
| exact value | $S_N'$ | $S_N'$ | ミニマックス値は $S_N'$ |
| fali high | $S_N'$ | 正の無限大 | ミニマックス値は $S_N'$ 以上 |
下界と上界の用語の意味から、ミニマックス値 は少なくとも 下界以上 かつ 上界以下 の 範囲の値 になります。そこで、fail low の場合は 下界に負の無限大 を設定することで、ミニマックス値は 上界に記録した $S_N'$ 以下 であるという意味になります。fail high の場合も同様です。exact value の場合は 下界と上界に $S_N'$ を記録する ことで、ミニマックス値 は $S_N'$ 以上 $S_N'$ 以下、すなわち $S_N'$ である ことを表すことになります。
fail low ではミニマックス値がとりうる範囲は少なくとも $S_N'$ 以下なので 数学的 には 下界は存在しません。従って、上記の表のように 負の無限大を下界に設定 するのは 数学的には正しい表現ではありません。
ただし、下界を負の無限大と考える ことで $S_N'$ 以下の範囲 を プログラムでうまく表現できる ので数学的には正しくはありませんが、プログラム ではこのような場合に 下界として負の無限大を設定する ことが良くあります。
なお、評価値の最小値がわかっている場合は下界を負の無限大ではなく、評価値の最小値と設定することもできます。
余談ですが、数学では下界が存在することを、下に有界と表現します。
ai_abs_tt2 の定義
置換表に記録するデータがわかったので、ミニマックス値の下界と上界を範囲を記録する置換表 を利用した αβ 法 で着手を選択する ai_abs_tt2 という AI の関数を定義 を、以前の記事で定義した 3 つのデータをキーとする置換表を利用した αβ 法で着手を選択する AI である ai_abs_tt を修正して定義することにします。
まず、ノードの評価値が確定した際に 置換表にミニマックス値の下界と上界を記録する処理 から実装します。また、ai_abs_tt では max ノードで fail low 場合 の評価値を α 値として計算していましたが、前回の記事で説明したように 子ノードの評価値の最大値 を計算したほうがミニマックス値の上界が小さくなって 範囲が狭くなる ので、そのように修正します。min ノードで fail heigh の場合も同様です。
-
6 行目:関数の名前を
ai_abs_tt2に修正する - 10 ~ 12 行目:置換表に局面のデータが登録されていた場合の処理についてはまだ解説していないので、この部分をコメントにして後から修正することにする
- 13、14 行目:置換表に登録するミニマックス値の下界と上界を計算するためには α 値と β 値の初期値が必要 となるので、それらの値を変数に記録する
-
18、22 行目:元のプログラムでは max ノードの場合は α 値を評価値として計算していたが、子ノードの評価値の最大値を評価値として計算する ように修正するために、18 行目で
scoreという変数を負の無限大で初期化し、22 行目で組み込み関数maxを利用してscoreの値をこれまでに計算した子ノードの評価値の最大値に更新する。なお、25 行目の α 値を更新する所に変更はない が、23 行目と 25 行目の下にあったscoreに α 値を代入する処理は削除する必要がある 点に注意すること - 27、31 行目:min ノードでも同様の修正を行う
- 39 ~ 47 行目:このノードの評価値と α 値と β 値の初期値を比較 し、ミニマックス値 の 下界(lower bound)と 上界 (upper bound)を 先程の表に従って計算 する
-
49、50 行目:置換表の 同一局面を表すキーの値 に
(下界, 上界)という ミニマックス値の下界と上界を表す tuple を代入する
1 from ai import ai_by_score, dprint
2 from marubatsu import Marubatsu
3 from copy import deepcopy
4
5 @ai_by_score
6 def ai_abs_tt2(mb, debug=False, shortest_victory=False):
7 count = 0
8 def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
9 boardtxt = mborig.board_to_str()
10 # key = (boardtxt, alpha, beta)
11 # if key in tt:
12 # return tt[key]
13 alphaorig = alpha
14 betaorig = beta
15
16 legal_moves = mborig.calc_legal_moves()
17 if mborig.turn == Marubatsu.CIRCLE:
18 score = float("-inf")
19 for x, y in legal_moves:
20 mb = deepcopy(mborig)
21 mb.move(x, y)
22 score = max(score, ab_search(mb, tt, alpha, beta))
23 if score >= beta:
24 break
25 alpha = max(alpha, score)
26 else:
27 score = float("inf")
28 for x, y in legal_moves:
29 mb = deepcopy(mborig)
30 mb.move(x, y)
31 score = min(score, ab_search(mb, tt, alpha, beta))
32 if score <= alpha:
33 break
34 beta = min(beta, score)
35
36 from util import calc_same_boardtexts
37
38 boardtxtlist = calc_same_boardtexts(mborig)
39 if score <= alphaorig:
40 lower_bound = float("-inf")
41 upper_bound = score
42 elif score < betaorig:
43 lower_bound = score
44 upper_bound = score
45 else:
46 lower_bound = score
47 upper_bound = float("inf")
48 for boardtxt in boardtxtlist:
49 tt[boardtxt] = (lower_bound, upper_bound)
50 return score
元と同じなので省略
行番号のないプログラム
from ai import ai_by_score, dprint
from marubatsu import Marubatsu
from copy import deepcopy
@ai_by_score
def ai_abs_tt2(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return (11 - mborig.move_count) / 2 if shortest_victory else 1
elif mborig.status == Marubatsu.CROSS:
return (mborig.move_count - 10) / 2 if shortest_victory else -1
elif mborig.status == Marubatsu.DRAW:
return 0
boardtxt = mborig.board_to_str()
# key = (boardtxt, alpha, beta)
# if key in tt:
# return tt[key]
alphaorig = alpha
betaorig = beta
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
score = float("-inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = max(score, ab_search(mb, tt, alpha, beta))
if score >= beta:
break
alpha = max(alpha, score)
else:
score = float("inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = min(score, ab_search(mb, tt, alpha, beta))
if score <= alpha:
break
beta = min(beta, score)
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(mborig)
if score <= alphaorig:
lower_bound = float("-inf")
upper_bound = score
elif score < betaorig:
lower_bound = score
upper_bound = score
else:
lower_bound = score
upper_bound = float("inf")
for boardtxt in boardtxtlist:
tt[boardtxt] = (lower_bound, upper_bound)
return score
score = ab_search(mb, {})
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
修正箇所
from ai import ai_by_score, dprint
from marubatsu import Marubatsu
from copy import deepcopy
@ai_by_score
-def ai_abs_tt(mb, debug=False, shortest_victory=False):
+def ai_abs_tt2(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
boardtxt = mborig.board_to_str()
- key = (boardtxt, alpha, beta)
- if key in tt:
- return tt[key]
+ # key = (boardtxt, alpha, beta)
+ # if key in tt:
+ # return tt[key]
+ alphaorig = alpha
+ betaorig = beta
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
+ score = float("-inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
- score = ab_search(mb, tt, alpha, beta)
+ score = max(score, ab_search(mb, tt, alpha, beta))
if score >= beta:
- alpha = score
break
alpha = max(alpha, score)
- score = alpha
else:
+ score = float("inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
- score = ab_search(mb, tt, alpha, beta)
+ score = min(score, ab_search(mb, tt, alpha, beta))
if score <= alpha:
- beta = score
break
beta = min(beta, score)
- score = beta
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(mborig)
+ if score <= alphaorig:
+ lower_bound = float("-inf")
+ upper_bound = score
+ elif score < betaorig:
+ lower_bound = score
+ upper_bound = score
+ else:
+ lower_bound = score
+ upper_bound = float("inf")
- _, alpha, beta = key
for boardtxt in boardtxtlist:
- tt[(boardtxt, alpha, beta)] = score
+ tt[boardtxt] = (lower_bound, upper_bound)
return score
元と同じなので省略
これまでの記事では下界と上界という用語を使って説明を行っていませんでしたが、プログラムでは 様々なアルゴリズム でを 下界と上界を計算しています。
例えば、ai_abs_tt2 で子ノードの評価値の 最大値を計算 する際に行う下記のアルゴリズムでは、実は 途中の計算 では少なくとも最大値はその値以上であるという 最大値の下界を計算 しており、下界の値を 最大値に近づけていくように更新していく という方法で最大値を計算しています。
- 最大値を計算する変数の 初期値に負の無限大を代入 する
- 子ノードの評価値が その変数より大きい場合 に 変数の値を更新する
局面の情報が置換表に登録されている場合の処理
次に、局面のミニマックス値の下界と上界が 置換表に登録されている場合 の ノードの処理を記述 する必要があります。なお、「局面のミニマックス値の下界と上界」という表記は長いので以後は「評価値の範囲」と表記することにします。また、「ミニマックス値の上界」と「ミニマックス値の下界」を単に「上界」や「下界」と表記することにします。
具体的には、下記のプログラムの 5 行目の if 文のブロックの部分を記述します。
1 @ai_by_score
2 def ai_abs_tt2(mb, debug=False, shortest_victory=False):
省略
3 boardtxt = mborig.board_to_str()
4 if boardtxt in tt:
5 置換表にこのノードの評価値の範囲が登録されている場合の処理
省略
下界と上界が等しい場合
下界と上界が等しい場合 は、その局面の ミニマックス値そのもの が置換表に記録されているという意味を表すので、その場合は下記のプログラムのように 下界(上界でも良い)の値をそのノードの 評価値として返す という処理を行います。
具体的には下記のプログラムのように記述します。
- 2 行目:置換表からその局面の下界と上界のデータを取り出す
- 3、4 行目:下界と上界が等しい場合は下界を評価値として返す
1 if boardtxt in tt:
2 lower_bound, upper_bound = tt[boardtxt]
3 if lower_bound == upper_bound:
4 return lower_bound
下界と上界が等しくない場合の考え方
下界と上界が 等しくない場合 は、下界、上界、そのノードの α 値の初期値、β 値の初期値 という 4 つの値の大小関係 によって 行う処理が変化する ので、その 大小関係の場合分け を行い、それぞれの場合について行う処理を検討 する必要があります。どのような場合分けがあるかについて少し考えてみて下さい。
このような場合分けの計算に慣れている人は、本記事で行うような詳細な場合分けを行なわなくても、どのような処理を記述すれば良いかを頭の中だけで考えることができるかもしれませんが、慣れないうちは難しいと思います。頭の中だけで考えることが難しいと思った方はこの後で説明するような 場合分けを紙などに書いて整理することで行う処理を検討する ことをお勧めします。
表記を簡潔にするために 下界(lower bound)を頭文字を取って $l$、上界(upper bound)を $u$、α 値の初期値を $α$、β 値の初期値を $β$ と表記することにします。
検討の前提条件
場合分けを行う際の 前提 として先程説明したように α 値と β 値の間 には $α < β$ という関係 があります。また、下界と上界の間 には $l ≦ u$ という関係がありますが、下界と上界が等しい場合については既に検討済 なので、$l < u$ の場合について考える 必要があります。
検討の 前提条件 として 下記の 2 つの式が成り立つ
- $α < β$
- $l < u$
α、β、l の関係の場合分け
$α$、$β$、$l$、$u$ の 4 つの値の場合分けをいきなり行う のは慣れていても 難しい と思いますので、最初に $α$、$β$、$l$ の 3 つの値の関係の場合分けを行い、その後で $u$ を追加 するという手順で場合分けを行うと良いでしょう。
$α < β$ という条件が成り立つので、$α$、$β$、$l$ の関係は以下の 5 通りの場合分け を行うことができます。
- $l < α < β$
- $l = α < β$
- $α < l < β$
- $α < β = l$
- $α < β < l$
頭の中だけで上記の場合分けの式を思い浮かべるのが難しいと思った方は、下図のような図を書いて 緑色の $l$ を表す点 を 左から右にずらしていく と、以下のような 5 つの場合に分けられることがわかると思います。それを数式で表したのが 上の 5 つの場合分けの式です。なお、$α$ の点が $β$ の点より左にあるのは $α < β$ という前提条件があるからです
- 緑色の点が赤い点より左にある
- 緑色の点が赤い点と重なる
- 緑色の点が赤い点と青い点の間にある
- 緑色の点が青い点と重なる
- 緑色の点が青色の点の右にある

α、β、l、u の関係の場合分け
次に、上記のそれぞれの場合について、$u$ を加えた関係の場合分け を行ない、それぞれの場合 について 行う処理を考える ことにします。
この時点で場合分けが多くて大変だと思っている人がいるかもしれませんが、作業を行っているうちに 法則が見えてくる 場合が良くあります。そのような場合は、途中で残りの場合分けの検討を省略する ことできます。
l < α < β の場合
$l < u$ であることから $l < α < β$ の場合に $u$ を加えると、以下の 5 通りに場合分けを行う ことができます。
- $l < u < α < β$
- $l < u = α < β$
- $l < α < u < β$
- $l < α < β = u$
- $l < α < β < u$
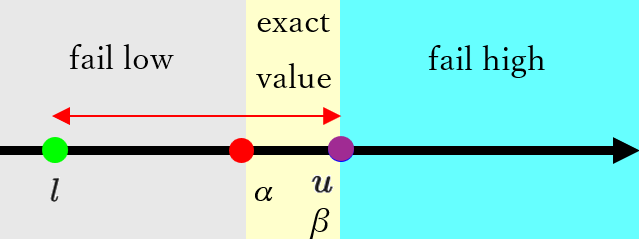
下図は最初の $l < u < α < β$ の場合を図にしたものです。下図では 赤い矢印の範囲 が 評価値の範囲、灰色 で塗りつぶされた範囲が fail low、薄黄色 で塗りつぶされた範囲が exact value、水色 で塗りつぶされた範囲が fail high を表します。ただし、赤い矢印の範囲は両端の値を含み、fail low の範囲は α を含み、fail high の範囲は β を 含みます。

上図では、赤い矢印 の 評価値の範囲 が すべて fail low の範囲に含まれる ことから、このノードの評価値は fail low になることが確定 します。αβ 法 では fail low の場合は α 値以下のどのような評価値を計算 しても ルートノードの評価値の計算に影響を与えない ので、このノードの評価値として fail low になる値を返してもかまいません。また、fail low で計算される評価値は、ミニマックス値の上界 を意味するので、この場合は置換表に記録されていた ミニマックス値の上界を表す $u$ を返り値として返せば良い ことになります。
置換表に記録されていない値を利用せずに、通常の場合と同様に 子ノードの評価値からノードの評価値を計算した場合 は、fail low の評価値として $u$ 以下の値が計算 されます。従って、置換表を利用 した場合は 枝狩りの効率が高くなる という利点がある反面、利用しない場合と比較して fail low で計算される ミニマックス値の範囲が広く、精度が低くなる場合がある という欠点が生じます。ただし、このような欠点があっても、ルートノードの評価値は正しく計算される のでこの欠点は大きな問題ではありません。
$l < u = α < β$ の場合は上図で $u$ と $α$ が重なる ことになりますが、fail low の範囲に $α$ は含まれる ので、その場合でも このノードは fail low になることが 確定します。従ってこの場合も上記と同様に、上界を表す $u$ を返り値として返せば良い ことになります。
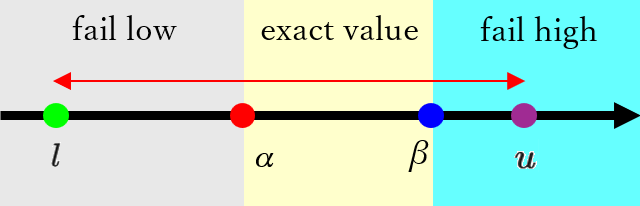
$l < α < u < β$ の場合は下図のように 赤い矢印の範囲 は、fail low と exact value の 両方の範囲に重なっています。従って、このノードの ミニマックス値 は fail low と exact value の いずれかの値 になりますが、exact value の評価値は 必ず正しく計算する必要がある ため、置換表に記録されている 範囲がある評価値 から、このノードの評価値を計算することはできません。従って、通常の場合と同様に 子ノードの評価値からこのノードの評価値を計算する必要 があります。その際に 枝狩りが行われやすくなるような工夫 を行なうことができます。どのような工夫を行なうことができるかについて少し考えてみて下さい。

具体的には下記のような理由から、下図のように β 値の初期値を $u$ に変更して exact value の範囲を縮小 することが出来ます。αβ 法では、ノードの種類によって α 値以下または β 値以上の評価値が計算された場合に枝狩りを行うので、exact value の範囲 を下図のように 縮小する ことで、枝狩りの効率を上げる ことが出来ます。
- 上図の 赤い矢印 は、このノードの ミニマックス値のとりうる範囲 を表している
- 従って、exact value の範囲の中 で、赤い矢印の範囲に含まれていない $u$ から $β$ の範囲 の値が、このノードの評価値として 計算されることは決してない
- そのため、下図のように β 値を $u$ に変更 して exact value の範囲を縮小 しても αβ 法の評価値を 正しく計算することができる
上記の説明の中の下記の点について疑問に思った方はいないでしょうか?
- $β$ を $u$ に変更する前の 2 つ上の図 では $u$ は exact value の範囲内 にある
- fail high は $β$ を含む ので、$β$ を $u$ に変更した後の 上図 では $u$ が fail high の範囲に変化 している
- $u$ は赤い矢印の範囲に含まれる ので、このノードでは $u$ が評価値として計算される可能性がある
- その場合は 計算された評価値の意味 が、$β$ を $u$ に 変更する前と後で は以下のように 変化してしまう という問題が発生する
- 変更する前 は $u$ は exact value なので ミニマックス値が計算 される
- 変更した後 は $u$ は fail high なので ミニマックス値の下界が計算 される
一見すると 修正前と後で異なる意味の評価値が計算される ので問題があるように見えるかもしれませんが、実際にはこのことは問題ではありません。その理由は、以下の通りです。
- β 値を $u$ に変更するという処理は、このノードの評価値の計算を行う際に行う処理 である
- 従って、親ノード でこのノードの評価値の計算を開始する際の α 値と β 値は変更されない
- そのため、このノードの評価値として $u$ が fail high として計算されても、その評価値を受け取った 親ノードでは $l < α < u < β$ のまま 変化していない ので $β$ を $u$ に変更しない場合と同様に exact value とみなされる
$l < α < β = u$(図は省略します) と $l < α < β < u$ の場合は、下図のように赤い矢印の 評価値の範囲 は、fail low、exact value、fail high の 全ての範囲にまたがっています。この場合は 工夫のしようがない ので、α 値と β 値を変更せずに 通常の場合と同様の方法で子ノードの評価値からこのノードの評価値を計算する必要があります。
上記をまとめると以下の表のようになります。それぞれの列の意味は以下の通りです。
- fl、ev、fh:評価値の範囲 がそれぞれ、fail low、exact value、fail high の範囲を 含む場合は 〇、含まない場合は × と表記する
- 評価値:このノードの評価値
- α 値、β 値:このノードの評価値を子ノードの評価値から計算する際に α 値または β 値の初期値を変更する場合の値。空欄の場合は変更しないことを表す
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $l < u < α < β$ | 〇 | × | × | $u$ | ||
| $l < u = α < β$ | 〇 | × | × | $u$ | ||
| $l < α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l < α < β = u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $l < α < β < u$ | 〇 | 〇 | 〇 | 子ノードから計算 |
上記の 1、2 行目と 4、5 行目の 関係より右の列の内容はすべて同じ なので、上記の表を下記の表のように まとめることができます。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $l < u ≦ α < β$ | 〇 | × | × | $u$ | ||
| $l < α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l < α < β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 |
上記は A、B、C を条件式とした場合に、and 演算と or 演算に対して下記の 分配法則 が成り立つことを利用しています。
(A and C) or (B and C)
という条件が成り立つときに下記の条件が成り立つ。逆に、下記の条件が成り立つときにも上記の条件が成り立つ。
(A or B) and C
なお、分配法則は下記のように、足し算と掛け算でも成り立ちます。
$(x + y) × z$ という式は常には $x × z + y × z$ と同じである
ピンとこない人がいるかもしれませんので、少し長くなりますが参考までに先程の表の 1 行目と 2 行目がまとめられることを分配法則を使って示します。既にピンと来ている人は下記の説明を読むとかえってわからなくなるかもしれないので、下記のような式の羅列を見るのがうんざりする人は読み飛ばしても構いません。
先程の表では 下記の 2 つの いずれかの関係が成り立つ ときに同じ結果になります。
- $l < u < α < β$
- $l < u = α < β$
そのことを 1 つの式で表すと下記のようになります。
($l$ < $u$ < $α$ < $β$) or ($l$ < $u$ = $α$ < $β$)
上記の式は下記のように書き換えることができます。
(($l$ < $u$) and ($u$ < $α$) and ($α$ < $β$)) or (($l$ < $u$) and ($u$ = $α$) and ($α$ < $β$))
and でつなげた式は順番を入れ替えることができる(交換法則と呼びます)ので上記の式は下記のように書き換えることができます。
(($u$ < $α$) and ($l$ < $u$) and ($α$ < $β$)) or (($u$ = $α$) and ($l$ < $u$) and ($α$ < $β$))
上記の式を下記の表の記号で置き換えると以下のようになります。
(A and C) or (B and C)
| 記号 | 式 |
|---|---|
| A | $u$ < $α$ |
| B | $u$ = $α$ |
| C | ($l$ < $u$) and ($α$ < $β$) |
分配法則から上記の式は下記の式に書き換えることができます。
(A or B) and C
A と B を元に戻すと以下の式になります。
(($u$ < $α$) or ($u$ = $α$)) and C
上記の式は以下のように書き換えることができます。
($u$ ≦ $α$) and C
C を元の式に戻し、and の順番を入れ替える以下のようになります。
($l$ < $u$) and ($u$ ≦ $α$) and ($α$ < $β$)
and を取り払うと先程まとめた下記の式になります。
$l < u ≦ α < β$
参考までに分配法則の wikipedia のリンクを下記に示します。
評価値の範囲が置換表に記録されている場合に行う処理の考察
上記では評価値の範囲が fail low に完全に含まれる場合の処理を考察しましたが、評価値の範囲が fail high に完全に含まれる場合 も 同様の考察 を行うことができます。また、先程の図から、評価値の範囲が exact value に含まれる場合 は、評価値の範囲と exact value の範囲のうち、共通する範囲 を α 値と β 値の初期値として更新 して、子ノードから評価値を計算 すれば良いことがわかります。
上記をまとめると、ノードの 評価値の範囲が置換表に記録されている場合に行う処理 は、以下のようになります。
- 評価値の範囲が fail low のみ の場合は置換表に記録された ミニマックス値の上界 である $u$ を評価値として返す
- 評価値の範囲が fail high のみ の場合は置換表に記録された ミニマックス値の下界 である $l$ を評価値として返す
- 上記のいずれでもない場合は、評価値の範囲が 正確な評価値を計算する 必要がある exact value の範囲を含む ので、置換表に記録 された評価値の範囲を そのまま利用することはできない。評価値の範囲と exact value の範囲のうち、共通する範囲 を α 値と β 値の初期値として更新 して、子ノードから評価値を計算 する
本記事では上記をもとに、残りの場合で行う処理を検証 することで、$α$、$β$、$l$、$u$ の関係から、どのような処理を行えば良いかを調べることにします。
数学が得意な方は、上記から $α$、$β$、$l$、$u$ の関係を表す式 を使って下記のような処理を行えば良いのではないかと考えた人がいるかもしれません。
- $u ≦ α$ の場合に fail low になり、$u$ を評価値として返す
- $β ≦ l$ の場合に fail high になり、$l$ を評価値として返す
- 上記以外の場合では exact value が含まれるので $α$ と $β$ を以下のように変更して子ノードから評価値を計算する
- $α < l$ の場合は $α$ を $l$ に変更する
- $u < β$ の場合は $β$ を $u$ に変更する
上記は正しいですが、一見すると正しそうに見える 思いついた法則が実際には正しくない場合が良くある ので 思いついた法則が正しいかどうか を何らかの方法で 検証することを怠らないで下さい。検証を怠ったせいで、プログラムに思わぬバグが発生 することは 良くある事 です。
本記事では行ないませんが、上記が正しいことを証明するのはそれほど難しくはないので興味がある方は証明にチャレンジしてみて下さい。なお、本記事で行うように、地道にすべての場合を確認する ことで行う処理を求めるのも、数学的な証明方法の一つ です。
l = α < β の場合
$l = α < β$ の場合に $u$ を加えると、以下の 3 通りに場合分けを行う ことができます。
- $l = α < u < β$
- $l = α < β = u$
- $l = α < β < u$
先程と同じ要領で上記を表にまとめると下記の表のようになります。$α$ は fail low、$β$ は fail high に 含まれる点に注意 して下さい。わかりづらいと思った方はまとめる際に先ほどのような図を書くと良いでしょう。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $l = α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l = α < β = u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $l = α < β < u$ | 〇 | 〇 | 〇 | 子ノードから計算 |
先程と同様に、上記の表は下記の表のようにまとめることができます。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $l = α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l = α < β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 |
α < l < β の場合
$α < l < β$ の場合に $u$ を加えると、以下の 3 通りに場合分けを行う ことができます。
- $α < l < u < β$
- $α < l < β = u$
- $α < l < β < u$
先程と同じ要領で上記を表にまとめると下記の表のようになります。$α < l < u < β$ の場合は 評価値の範囲 は exact value の範囲内に完全に収まります が、exact value は ミニマックス値を計算する必要がある ので子ノードから評価値を計算する必要があります。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $α < l < u < β$ | × | 〇 | × | 子ノードから計算 | $l$ に変更 | $u$ に変更 |
| $α < l < β ≦ u$ | × | 〇 | 〇 | 子ノードから計算 | $l$ に変更 |
α < β = l の場合
$α < β = l$ の場合に $u$ を加えると、$l < u$ なので下記の 1 つの場合のみが存在 します。
- $α < β = l < u$
先程と同じ要領で上記を表にまとめると下記の表のようになります。評価値の範囲が β 値以上になる ので、このノードは fail high になります。従ってこのノードの 評価値は $l$ と計算すればよい ことがわかります。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $α < β = l < u$ | × | × | 〇 | $l$ |
α < β < l の場合
$α < β < l$ の場合に $u$ を加えると、$l < u$ なので下記の 1 つの場合のみが存在 します。
- $α < β < l < u$
先程と同じ要領で上記を表にまとめると下記の表のようになります。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $α < β < l < u$ | × | × | 〇 | $l$ |
評価値の範囲が置換表に登録されている場合の処理のまとめ
すべての場合で行う処理がわかったので、評価値の範囲が置換表に登録されている場合に 行う処理をまとめる ことにします。
表の整理
現状ではそれぞれの場合の表がばらばらになっているので 一つの表にまとめる 必要があります。下記は、上記の表をまとめた表ですが、行数が多くてわかりづらい ので 整理する ことにします。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $l < u ≦ α < β$ | 〇 | × | × | $u$ | ||
| $l < α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l < α < β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $l = α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l = α < β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $α < l < u < β$ | × | 〇 | × | 子ノードから計算 | $l$ に変更 | $u$ に変更 |
| $α < l < β ≦ u$ | × | 〇 | 〇 | 子ノードから計算 | $l$ に変更 | |
| $α < β = l < u$ | × | × | 〇 | $l$ | ||
| $α < β < l < u$ | × | × | 〇 | $l$ |
まず、関係より右の列が同じ行 を まとめて整理する ことにします。そのために、上記の表で関係より右の列が 同じ行が並ぶように並べ替える と下記の表のようになります。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $l < u ≦ α < β$ | 〇 | × | × | $u$ | ||
| $l < α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l = α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l < α < β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $l = α < β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $α < l < u < β$ | × | 〇 | × | 子ノードから計算 | $l$ に変更 | $u$ に変更 |
| $α < l < β ≦ u$ | × | 〇 | 〇 | 子ノードから計算 | $l$ に変更 | |
| $α < β = l < u$ | × | × | 〇 | $l$ | ||
| $α < β < l < u$ | × | × | 〇 | $l$ |
上記の表で、関係より右の列が同じ行をまとめる と下記の表のようになります。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $l < u ≦ α < β$ | 〇 | × | × | $u$ | ||
| $l ≦ α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l ≦ α < β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $α < l < u < β$ | × | 〇 | × | 子ノードから計算 | $l$ に変更 | $u$ に変更 |
| $α < l < β ≦ u$ | × | 〇 | 〇 | 子ノードから計算 | $l$ に変更 | |
| $α < β ≦ l < u$ | × | × | 〇 | $l$ |
$l < u ≦ α < β$ は「$l < u$ なおかつ $u ≦ α$ なおかつ $α < β$」という意味の式です。この 3 つの式の中で $l < u$ と $α < β$ は 必ず成り立つ という前提があるため 取り除くことができる ので、この式は $u ≦ α$ という式で置き換えるこ とができます。他の関係の式 も同様に $l < u$ と $α < β$ という条件を取り除く と上記の表は下記の表のようになります。
| 関係 | fl | ev | fh | 評価値 | α 値 | β 値 |
|---|---|---|---|---|---|---|
| $u ≦ α$ | 〇 | × | × | $u$ | ||
| $l ≦ α < u < β$ | 〇 | 〇 | × | 子ノードから計算 | $u$ に変更 | |
| $l ≦ α$ なおかつ $β ≦ u$ | 〇 | 〇 | 〇 | 子ノードから計算 | ||
| $α < l$ なおかつ $u < β$ | × | 〇 | × | 子ノードから計算 | $l$ に変更 | $u$ に変更 |
| $α < l < β ≦ u$ | × | 〇 | 〇 | 子ノードから計算 | $l$ に変更 | |
| $β ≦ l$ | × | × | 〇 | $l$ |
fail low、fail high の場合の処理の記述
上記の表から、以下の事がわかります。
- $u ≦ α$ の場合に fail low になり、$u$ を評価値として返す
- $β ≦ l$ の場合に fail high になり、$l$ を評価値として返す
- 上記以外の場合では exact value が含まれる ので $α$ と $β$ を 必要に応じて変更 して 子ノードから評価値を計算 する
上記の処理を プログラムで記述 すると下記のようになります。
- 3、4 行目:$u ≦ α$ の場合に評価値として $u$ を計算する
- 5、6 行目:$β ≦ l$ の場合に評価値として $l$ を計算する
- 7、8 行目:上記のいずれでもない場合に α 値と β 値を更新する処理を記述する。また、8 行目の処理の中で return 文を記述しない ようにすることで、この後 で 更新された α 値と β 値を使って 子ノードの評価値からこのノードの評価値を計算する処理が行われる
1 if boardtxt in tt:
2 lower_bound, upper_bound = tt[boardtxt]
3 if upper_bound <= alpha:
4 return upper_bound
5 elif beta <= lower_bound:
6 return lower_bound
7 else:
8 必要に応じて α 値と β 値を更新する処理を記述する
exact value が含まれる場合の処理の記述
上記の 8 行目で行う処理を記述するため には、どのような場合に α 値と β 値をどのように更新すればよいかを明確にする 必要があります。そこで、まず、α 値の更新に関して検証する ことにします。
上記の 8 行目は子ノードの評価値を計算する場合の処理なので、先程の表から「子ノードから計算」が表記された行を 取り出す必要 があります。また、α 値を更新する条件について知りたい ので、「関係」、「評価値」、「α 値」の 列のみを取り出した表を作る と下記の表のようになります。
| 関係 | 評価値 | α 値 |
|---|---|---|
| $l ≦ α < u < β$ | 子ノードから計算 | |
| $l ≦ α$ なおかつ $β ≦ u$ | 子ノードから計算 | |
| $α < l$ なおかつ $u < β$ | 子ノードから計算 | $l$ に変更 |
| $α < l < β ≦ u$ | 子ノードから計算 | $l$ に変更 |
上記の 8 行目は $u ≦ α$ でも、$β ≦ l$ でもない場合に実行される ので、$u > α$、$β > l$ という条件は必ず満たされます。従って、上記の表の 「関係」の式からそれらの条件を取り除く と下記の表のようになります。
| 関係 | 評価値 | α 値 |
|---|---|---|
| $l ≦ α$ なおかつ $u < β$ | 子ノードから計算 | |
| $l ≦ α$ なおかつ $β ≦ u$ | 子ノードから計算 | |
| $α < l$ なおかつ $u < β$ | 子ノードから計算 | $l$ に変更 |
| $α < l$ なおかつ $β ≦ u$ | 子ノードから計算 | $l$ に変更 |
$u < β$ または $β ≦ u$ という条件は 常に成り立つ ので、上記の表は以下の表のようにまとめることができます。
| 関係 | 評価値 | α 値 |
|---|---|---|
| $l ≦ α$ | 子ノードから計算 | |
| $α < l$ | 子ノードから計算 | $l$ に変更 |
従って、α 値は $α < l$ の場合に $l$ に更新する必要がある ことがわかりました。この処理は組み込み関数 max を利用して下記のプログラムのように記述することができます。
alpha = max(alpha, lower_bound)
上記と同様の手順で「関係」、「評価値」、「β 値」の列のみを取り出した表を作ってまとめると下記の表のようになります。
| 関係 | 評価値 | β 値 |
|---|---|---|
| $β ≦ u$ | 子ノードから計算 | |
| $u < β$ | 子ノードから計算 | $u$ に変更 |
従って、β 値は $u < β$ の場合に $u$ に更新する必要がある ことがわかりました。この処理は組み込み関数 min を利用して下記のプログラムのように記述することができます。
beta = min(beta, upper_bound)
ai_abs_tt2 の修正
上記から、評価値の範囲が置換表に登録されている場合のノードの処理が下記のようになることがわかります。これは先程のノートで推測した処理と同じです。
- $u ≦ α$ の場合に fail low になり、$u$ を評価値として返す
- $β ≦ l$ の場合に fail high になり、$l$ を評価値として返す
- 上記以外の場合では exact value が含まれる ので $α$ と $β$ を以下のように変更 して 子ノードから評価値を計算する
- $α < l$ の場合は $α$ を $l$ に変更する
- $u < β$ の場合は $β$ を $u$ に変更する
下記は、上記の処理を行うように ai_abs_tt2 を修正したプログラムです。
- 4、5 行目:ノードの局面の情報が置換表に登録されているかどうかをチェックする
- 6 行目:置換表からその局面のミニマックス値の下界と上界を取り出す
- 7 ~ 12 行目:上記の 1、2 の場合の評価値を返す
-
13 ~ 15 行目:上記の 3 の場合に組み込み関数
minとmaxを利用して α 値と β 値を変更する。この場合は 17、18 行目で変数に記録する α 値と β 値の初期値はここで変更された値になる
1 @ai_by_score
2 def ai_abs_tt2(mb, debug=False, shortest_victory=False):
元と同じなので省略
3 def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
4 boardtxt = mborig.board_to_str()
5 if boardtxt in tt:
6 lower_bound, upper_bound = tt[boardtxt]
7 if lower_bound == upper_bound:
8 return lower_bound
9 elif upper_bound <= alpha:
10 return upper_bound
11 elif beta <= lower_bound:
12 return lower_bound
13 else:
14 alpha = min(alpha, lower_bound)
15 beta = max(beta, upper_bound)
16
17 alphaorig = alpha
18 betaorig = beta
元と同じなので省略
行番号のないプログラム
@ai_by_score
def ai_abs_tt2(mb, debug=False, shortest_victory=False):
count = 0
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
nonlocal count
count += 1
if mborig.status == Marubatsu.CIRCLE:
return (11 - mborig.move_count) / 2 if shortest_victory else 1
elif mborig.status == Marubatsu.CROSS:
return (mborig.move_count - 10) / 2 if shortest_victory else -1
elif mborig.status == Marubatsu.DRAW:
return 0
boardtxt = mborig.board_to_str()
if boardtxt in tt:
lower_bound, upper_bound = tt[boardtxt]
if lower_bound == upper_bound:
return lower_bound
elif upper_bound <= alpha:
return upper_bound
elif beta <= lower_bound:
return lower_bound
else:
alpha = min(alpha, lower_bound)
beta = max(beta, upper_bound)
alphaorig = alpha
betaorig = beta
legal_moves = mborig.calc_legal_moves()
if mborig.turn == Marubatsu.CIRCLE:
score = float("-inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = max(score, ab_search(mb, tt, alpha, beta))
if score >= beta:
break
alpha = max(alpha, score)
else:
score = float("inf")
for x, y in legal_moves:
mb = deepcopy(mborig)
mb.move(x, y)
score = min(score, ab_search(mb, tt, alpha, beta))
if score <= alpha:
break
beta = min(beta, score)
from util import calc_same_boardtexts
boardtxtlist = calc_same_boardtexts(mborig)
if score <= alphaorig:
lower_bound = float("-inf")
upper_bound = score
elif score < betaorig:
lower_bound = score
upper_bound = score
else:
lower_bound = score
upper_bound = float("inf")
for boardtxt in boardtxtlist:
tt[boardtxt] = (lower_bound, upper_bound)
return score
score = ab_search(mb, {})
dprint(debug, "count =", count)
if mb.turn == Marubatsu.CIRCLE:
score *= -1
return score
修正箇所
@ai_by_score
def ai_abs_tt2(mb, debug=False, shortest_victory=False):
元と同じなので省略
def ab_search(mborig, tt, alpha=float("-inf"), beta=float("inf")):
元と同じなので省略
boardtxt = mborig.board_to_str()
- # key = (boardtxt, alpha, beta)
- # if key in tt:
- # return tt[key]
+ if boardtxt in tt:
+ lower_bound, upper_bound = tt[boardtxt]
+ if lower_bound == upper_bound:
+ return lower_bound
+ elif upper_bound <= alpha:
+ return upper_bound
+ elif beta <= lower_bound:
+ return lower_bound
+ else:
+ alpha = min(alpha, lower_bound)
+ beta = max(beta, upper_bound)
alphaorig = alpha
betaorig = beta
元と同じなので省略
わかりやすさを重視して本記事では修正しませんが、上記の 7、8 行目と 11、12 行目はどちらも lower_bound を返り値として返すので、下記のプログラムの 1、2 行目のようにまとめることができます。
1 if lower_bound == upper_bound or beta <= lower_bound:
2 return lower_bound
3 elif upper_bound <= alpha:
4 return upper_bound
5 else:
6 alpha = min(alpha, lower_bound)
7 beta = max(beta, upper_bound)
修正箇所
- if lower_bound == upper_bound:
+ if lower_bound == upper_bound or beta <= lower_bound:
return lower_bound
elif upper_bound <= alpha:
return upper_bound
+ elif beta <= lower_bound:
+ return lower_bound
else:
alpha = min(alpha, lower_bound)
beta = max(beta, upper_bound)
ai_abs_tt2 が強解決の AI であることの確認
ai_abs_tt2 が強解決の AI であることを、Check_Solved を利用して下記のプログラムで確認すると、実行結果から 強解決の AI であることが確認できました。
from util import Check_solved
Check_solved.is_strongly_solved(ai_abs_tt2)
実行結果
100%|██████████| 431/431 [00:02<00:00, 158.86it/s]
431/431 100.00%
(True, [])
記事が長くなったので、ai_abs_tt2 による 枝狩りの効率 については 次回の記事で確認する ことにします。
今回の記事のまとめ
今回の記事では、ノードの ミニマックス値の下界と上界を記録する置換表 を利用した αβ 法の実装 を行い、その方法で作成した AI が 強解決の AI である ことを示しました。次回の記事でこの方法によって枝狩りの効率が改善されたことを確認します。
実は 今回の記事で実装した ai_abs_tt2 には 効率が悪い点 が 1 つあり、その問題を修正することで枝狩りの効率をさらに向上することができます。どのような問題があるかについて余裕がある方は考えてみて下さい。
本記事で入力したプログラム
| リンク | 説明 |
|---|---|
| marubatsu.ipynb | 本記事で入力して実行した JupyterLab のファイル |
| ai.py | 本記事で更新した ai_new.py |
次回の記事