はじめに
各都道府県の美女の画像を学習させて、ある美女がどの都道府県っぽい顔かを出してみました。
環境
- Python3.5
- OpenCV3.1
- TensorFlow1.01
- Windows10 or Ubuntu 16.04
OSは一応WindowsとLinuxの両方で確認していますが、Ubuntuの方はDockerでの確認です。
両OSの違いはファイルパスだけですので、適宜修正して下さい。
実装
1. 美人時計から各都道府県の画像を取得する
まず、各都道府県の女性の画像を取得します。今回は美人時計を利用させてもらいました。
(全都道府県は残念ながらありませんでした)
'''Getter images from bijin watch.'''
import os
import datetime
import time
import random
import urllib.request
AREAS = ['hokkaido',
'aomori',
'iwate',
'sendai', # miyagi
'akita',
#'yamagata', nothing
'fukushima',
'ibaraki',
'tochigi',
'gunma',
'saitama',
'chiba',
'tokyo',
'kanagawa',
'niigata',
#'toyama', nothing
'kanazawa',
'fukui',
'yamanashi',
'nagano',
#'gifu', nothing
'shizuoka',
'nagoya', #aichi
#'mie', nothing
#'shiga', nothing
'kyoto',
'osaka',
'kobe', #hyogo
'nara',
#'wakayama', nothing
'tottori',
#'shimane', nothing
'okayama',
'hiroshima',
'yamaguchi',
'tokushima',
'kagawa',
#'ehime', nothing
#'kochi', nothing
'fukuoka',
'saga',
'nagasaki',
'kumamoto',
#'oita', nothing
'miyazaki',
'kagoshima',
'okinawa',
]
def get_image():
'''
Getter images from bijin watch
'''
for area in AREAS:
dirpath = './bijinwatch' + '/' + area + '/'
if not os.path.exists(dirpath):
os.makedirs(dirpath)
url = 'http://www.bijint.com/assets/pict/' + area + '/pc/'
time_standard = datetime.datetime(2017, 1, 1, 0, 0)
while True:
file_name = time_standard.strftime('%H%M') + '.jpg'
urllib.request.urlretrieve(url + file_name, dirpath + file_name)
print(dirpath + file_name + ' output')
time_standard += datetime.timedelta(minutes=1)
# waiting time (4 - 6 sec)
time.sleep(4 + random.randint(0, 2))
if time_standard.strftime('%H%M') == '0000':
break
if __name__ == '__main__':
get_image()
2. OpenCV で顔領域のトリミング
次に、これらの画像から OpenCV で顔領域を検出し、トリミングを行います。
'''Cut face.'''
import os
import cv2
def main():
'''
Cut face
'''
for srcpath, _, files in os.walk('bijinwatch'):
if len(_):
continue
dstpath = srcpath.replace('bijinwatch', 'faces')
if not os.path.exists(dstpath):
os.makedirs(dstpath)
for filename in files:
if filename.startswith('.'): # Pass .DS_Store
continue
try:
detect_faces(srcpath, dstpath, filename)
except:
continue
def detect_faces(srcpath, dstpath, filename):
cascade = cv2.CascadeClassifier('haarcascade_frontalface_alt2.xml')
image = cv2.imread('{}/{}'.format(srcpath, filename))
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
faces = cascade.detectMultiScale(gray_image)
# Extract when just one face is detected
for i in range(len(faces)):
(x, y, w, h) = faces[i]
image = image[y:y+h, x:x+w]
image = cv2.resize(image, (100, 100))
if i == 0:
cv2.imwrite('{}/{}'.format(dstpath, filename), image)
print('{}/{}'.format(dstpath, filename) + ' output')
else:
cv2.imwrite(dstpath + '/' + str(i) + '_' + filename, image)
print(dstpath + '/' + str(i) + '_' + filename + ' output')
if __name__ == '__main__':
main()
OpenCVでも100%顔検出が出来るわけではないので、1つの画像から複数検出したらそれも残すようにしています。
その為resize時にエラーが出ることがありますが、気にしない。
終わったらfaces/の中身を、顔でないものを**目視で確認(ここ重要)**して削除します。
3. 学習を行い、model.ckptを作る
各都道府県の18:00以降をテストデータとし,それ以外を訓練データとします。訓練データ、テストデータはそれぞれ 31,677 枚、10,710枚となりました。
'''Create model.'''
import os
import random
import numpy as np
import tensorflow as tf
label_dict = {
'hokkaido':0,
'aomori':1,
'iwate':2,
'sendai':3, # miyagi
'akita':4,
#'yamagata':nothing
'fukushima':5,
'ibaraki':6,
'tochigi':7,
'gunma':8,
'saitama':9,
'chiba':10,
'tokyo':11,
'kanagawa':12,
'niigata':13,
#'toyama':nothing
'kanazawa':14,
'fukui':15,
'yamanashi':16,
'nagano':17,
#'gifu':nothing
'shizuoka':18,
'nagoya':19, #aichi
#'mie':nothing
#'shiga':nothing
'kyoto':20,
'osaka':21,
'kobe':22, #hyogo
'nara':23,
#'wakayama':nothing
'tottori':24,
#'shimane':nothing
'okayama':25,
'hiroshima':26,
'yamaguchi':27,
'tokushima':28,
'kagawa':29,
#'ehime':nothing
#'kochi':nothing
'fukuoka':30,
'saga':31,
'nagasaki':32,
'kumamoto':33,
#'oita':nothing
'miyazaki':34,
'kagoshima':35,
'okinawa':36,
}
def load_data(data_type):
filenames, images, labels = [], [], []
walk = list(filter(lambda _:data_type in _[0], os.walk('faces')))
for (root, dirs, files) in walk:
filenames += ['{}/{}'.format(root, _) for _ in files if not _.startswith('.')]
# Shuffle files
random.shuffle(filenames)
# Read, resize, and reshape images
images = map(lambda _: tf.image.decode_jpeg(tf.read_file(_), channels=3), filenames)
images = map(lambda _: tf.image.resize_images(_, [32, 32]), images)
images = list(map(lambda _: tf.reshape(_, [-1]), images))
for filename in filenames:
label = np.zeros(37)
for k, v in label_dict.items():
if k in filename:
label[v] = 1.
labels.append(label)
return images, labels
def get_batch_list(l, batch_size):
# [1, 2, 3, 4, 5,...] -> [[1, 2, 3], [4, 5,..]]
return [np.asarray(l[_:_+batch_size]) for _ in range(0, len(l), batch_size)]
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def inference(images_placeholder, keep_prob):
# Convolution layer
x_image = tf.reshape(images_placeholder, [-1, 32, 32, 3])
W_conv1 = weight_variable([5, 5, 3, 32])
b_conv1 = bias_variable([32])
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
# Pooling layer
h_pool1 = max_pool_2x2(h_conv1)
# Convolution layer
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
# Pooling layer
h_pool2 = max_pool_2x2(h_conv2)
# Full connected layer
W_fc1 = weight_variable([8 * 8 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 8 * 8 * 64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
# Dropout
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
# Full connected layer
W_fc2 = weight_variable([1024,37])
b_fc2 = bias_variable([37])
return tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
def main():
with tf.Graph().as_default():
train_images, train_labels = load_data('train')
test_images, test_labels = load_data('test')
x = tf.placeholder('float', shape=[None, 32 * 32 * 3]) # 32 * 32, 3 channels
y_ = tf.placeholder('float', shape=[None, 37]) # 37 classes
keep_prob = tf.placeholder('float')
y_conv = inference(x, keep_prob)
# Loss function
cross_entropy = -tf.reduce_sum(y_ * tf.log(y_conv))
tf.summary.scalar('cross_entropy', cross_entropy)
# Minimize cross entropy by using SGD
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# Accuracy
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
tf.summary.scalar('accuracy', accuracy)
saver = tf.train.Saver()
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
summary_op = tf.summary.merge_all()
summary_writer = tf.summary.FileWriter('./logs', sess.graph)
batched_train_images = get_batch_list(train_images, 25)
batched_train_labels = get_batch_list(train_labels, 25)
train_images = list(map(lambda _: sess.run(_).astype(np.float32) / 255.0, np.asarray(train_images)))
test_images = list(map(lambda _: sess.run(_).astype(np.float32) / 255.0, np.asarray(test_images)))
train_labels, test_labels = np.asarray(train_labels), np.asarray(test_labels)
# Train
for step, (images, labels) in enumerate(zip(batched_train_images, batched_train_labels)):
images = list(map(lambda _: sess.run(_).astype(np.float32) / 255.0, images))
sess.run(train_step, feed_dict={ x: images, y_: labels, keep_prob: 0.5 })
train_accuracy = accuracy.eval(feed_dict = {
x: train_images, y_: train_labels, keep_prob: 1.0 })
print ('step {}, training accuracy {}'.format(step, train_accuracy))
summary_str = sess.run(summary_op, feed_dict={
x: train_images, y_: train_labels, keep_prob: 1.0 })
summary_writer.add_summary(summary_str, step)
# Test trained model
test_accuracy = accuracy.eval(feed_dict = {
x: test_images, y_: test_labels, keep_prob: 1.0 })
print ('test accuracy {}'.format(test_accuracy))
# Save model
# for Windows
#cwd = os.getcwd()
#save_path = saver.save(sess, cwd + "/model.ckpt")
save_path = saver.save(sess,"model.ckpt")
if __name__ == '__main__':
main()
適合率は 9% くらい・・・失敗した・・・失敗した・・・失敗した・・・失敗した・・・
でも、ち・・・地方とかで合ってたらそれもそれで凄いよねと諦めず次に逝ってみる。
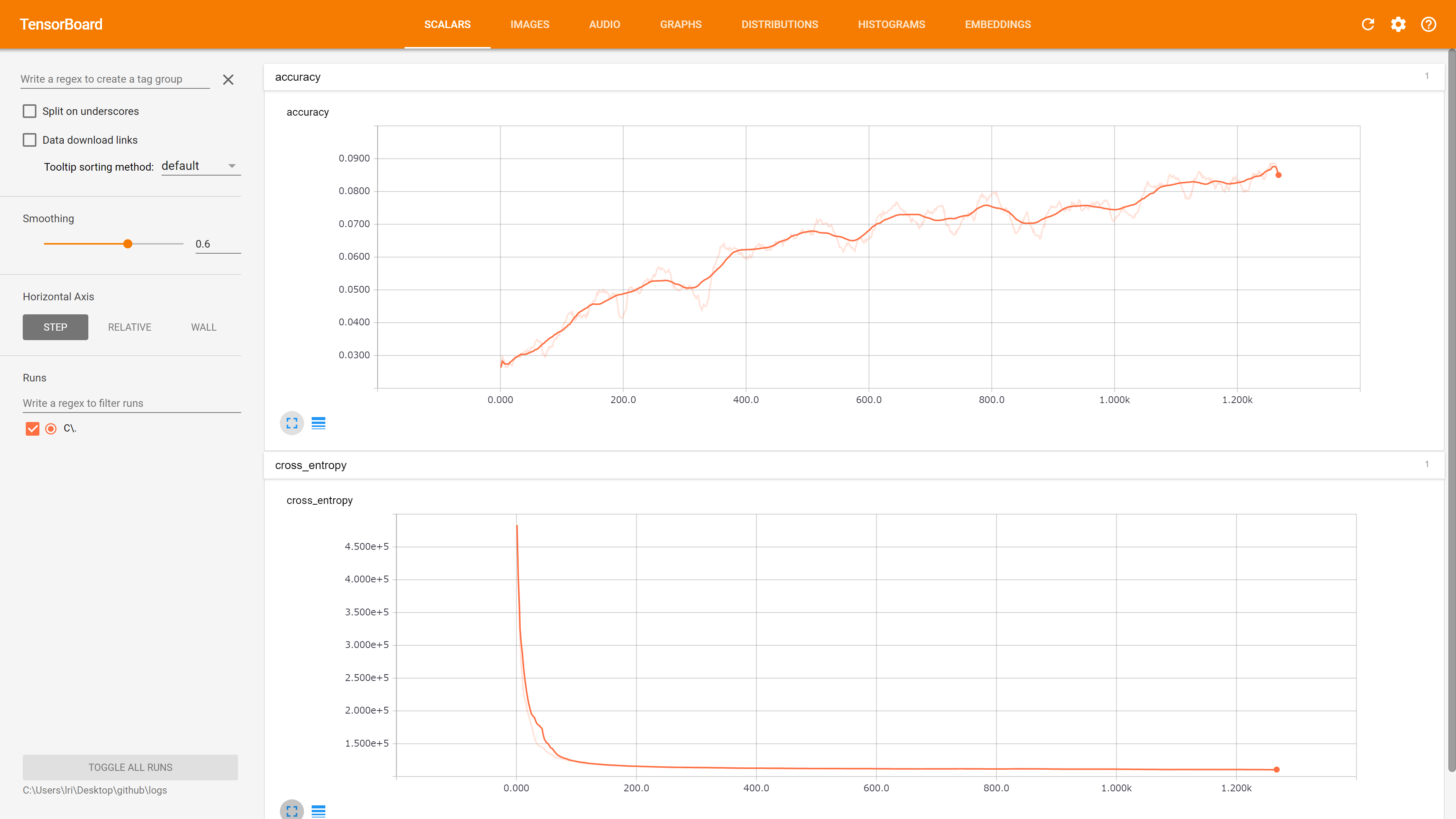
4. 実際に画像の判別をしてみる
前述の「create_model.py」のmainだけを以下の通りに変更して「use_model.py」としました。
そして、facesフォルダの中に「experiment」というフォルダを作成し、対象の顔画像を保存してから実行。
# 略
def main():
with tf.Graph().as_default():
test_images, test_labels = load_data('experiment')
x = tf.placeholder('float', shape=[None, 32 * 32 * 3]) # 32 * 32, 3 channels
y_ = tf.placeholder('float', shape=[None, 37]) # 37 classes
keep_prob = tf.placeholder('float')
y_conv = inference(x, keep_prob)
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
#saver = tf.train.Saver()
# for Windows
cwd = os.getcwd()
#saver = tf.train.import_meta_graph( cwd + '/model.ckpt.meta')
#saver.restore(sess, cwd + '/model.ckpt')
saver.restore(sess, "./model.ckpt")
test_images = list(map(lambda _: sess.run(_).astype(np.float32) / 255.0, np.asarray(test_images)))
print(y_conv.eval(feed_dict={ x: [test_images[0]], keep_prob: 1.0 })[0])
print(np.argmax(y_conv.eval(feed_dict={ x: [test_images[0]], keep_prob: 1.0 })[0]))
まずは我らがガッキーで

# [ 0.01556119 0.03334192 0.03082328 0.02891025 0.03623386 0.02309893
0.0324963 0.02391087 0.02187913 0.03305629 0.013511 0.02423066
0.01981902 0.04509349 0.02271883 0.03959839 0.02083497 0.02280688
0.01850946 0.0305318 0.01612434 0.02407986 0.02972359 0.02024633
0.01983686 0.02154906 0.01731302 0.03387052 0.03141267 0.02629333
0.02803781 0.01046125 0.02469774 0.02441197 0.03926406 0.03156613
0.06414489]
# 36
36...沖縄...合ってる!!
石原さとみさん、出身は東京とのことですが・・・

# [ 0.0141082 0.03094343 0.02688435 0.03384124 0.02399973 0.03008302
0.0176533 0.04882244 0.02148996 0.03244958 0.02117736 0.042867
0.05331976 0.01818123 0.00570239 0.0220525 0.03224532 0.02177371
0.02955816 0.07092561 0.01439794 0.01252615 0.01662285 0.03186775
0.0224861 0.04640146 0.02621422 0.02141088 0.01475729 0.02538937
0.01975698 0.00596274 0.029048 0.02616575 0.01615759 0.02789798
0.0448586 ]
# 19
19...名古屋かー違いますね。
でも、東京は2番目に高いです!!
有村 架純さん、出身は兵庫とのこと

# [ 0.02794396 0.01993513 0.02246254 0.02667207 0.03051521 0.02229821
0.028295 0.03359965 0.03057118 0.01893608 0.02045126 0.03275863
0.0340121 0.03441097 0.01730731 0.02830116 0.01918983 0.03398903
0.02914776 0.03527785 0.02876526 0.02948653 0.03099313 0.01980851
0.0236843 0.0277888 0.01719548 0.02429866 0.03184872 0.02823974
0.0258668 0.02368994 0.02091827 0.03633798 0.02721206 0.03128152
0.02650937]
# 33
33...熊本
ぜんぜん違うというよりは、どの県もそんなに変わらない数値のため、平均顔というやつでしょうか。
参考
FUTURE WORKを見て面白そーと思ったきっかけです。ありがとうございました。
まとめ
うまくいったか微妙ですね。
とりあえず地方単位で区別があるわけではなさそうです。
これを国単位にしたら同じアジア系でも区別が付きそうな気がするけど・・・
今回はここまでにしたいと思います。