はじめに
画像の中の数字を読み取る必要がでてきたので、いろいろなページを参考にさせていただき、実施しましたのでそれをまとめます。(手書きもPCなどからの印字も)
画像を読み取る方法
次の2つを試してみる。
- Pythonライブラリの「tesseract」を使用してみる。
- Google Cloud Vision API を使用してみる。(APIキーの取得が必要)
方法1. Pythonライブラリの「tesseract」
-
インストール:
pip install pytesseract -
Tesseract-OCRのダウンロードとインストール
https://github.com/tesseract-ocr/tesseract/wiki
https://sourceforge.net/projects/tesseract-ocr-alt/
(Windows環境: tesseract-ocr-setup-3.02.02 を使用)
numGet.py
import pytesseract
from PIL import Image
url_img = './test.png'
img = Image.open(url_img)
number = pytesseract.image_to_string(img)
print(number)
これを実行すると、下記のようなエラーが発生した。
NotFoundErrorエラー
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your path
Tesseract-OCRを認識していないので、pytesseract.py を直接修正する方法をとる。(tesseract_cmdにインストール先のexeファイルを指定する。windows環境であれば、ダブルバッシュとする)
pytesseract.py
# tesseract_cmd = 'tesseract'
tesseract_cmd = 'C:\\Program Files (x86)\\Tesseract-OCR\\tesseract.exe'
<テストを実施>
読み込む画像1

テスト結果
$python numGet.py
1042090
→うまくいった
読み込む画像2(手書き)
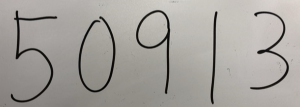
テスト結果
$python numGet.py
→手書きは読み取れなかった
方法2. Google Cloud Vision API
Google Cloud Vision APIで光学式文字認識(Qiita)
を参考にさせていただき、テストしました。(というかそのままです)
gooleclouldvision.py
import requests
import base64
import json
GOOGLE_CLOUD_VISION_API_URL = 'https://vision.googleapis.com/v1/images:annotate?key='
API_KEY = 'APIキーを設定する'
# APIを呼び、認識結果をjson型で返す
def request_cloud_vison_api(image_base64):
api_url = GOOGLE_CLOUD_VISION_API_URL + API_KEY
req_body = json.dumps({
'requests': [{
'image': {
# jsonに変換するためにstring型に変換する
'content': image_base64.decode('utf-8')
},
'features': [{
# ここを変更することで分析内容を変更できる
'type': 'TEXT_DETECTION',
'maxResults': 10,
}]
}]
})
res = requests.post(api_url, data=req_body)
return res.json()
# 画像読み込み
def img_to_base64(filepath):
with open(filepath, 'rb') as img:
img_byte = img.read()
return base64.b64encode(img_byte)
# 文字認識させたい画像を設定
img_base64 = img_to_base64('./test.png')
result = request_cloud_vison_api(img_base64)
# 認識した文字を出力
text_r = result["responses"][0]["textAnnotations"][1]["description"]
print(text_r)
<テストを実施>
テスト結果1→うまくいった
$python gooleclouldvision.py
1042090
テスト結果2(手書き)→今度は手書きでも読み取れました
$python gooleclouldvision.py
50913
まとめ
- 画像の中の数字を読み取る方法を確認できました。
- tesseractは手書き数字には対応できないことが体感できました。
- Google Cloud Vision APIは、かなりよい精度がでることが体感できました。