本記事は、ディープラーニングモデルの軽量化ツールPCASの使い方 (4) ー画像分類ライブラリtimmとの連携編ー の続編です。
前回の記事では、モデル軽量化ツールPCAS(以下、PCASツール)と画像分類ライブラリtimmの実装を利用し、MobileNetV2モデルの軽量化とそのパフォーマンス評価を行いました。
今回は、PCASツールと物体検出ライブラリの YOLOX1 を利用して、物体検出モデルの軽量化と、エッジコンピューターであるAE2100上での推論速度の実測評価を行いたいと思います。
本記事の要約
- PCASツールと物体検出ライブラリYOLOXの連携方法を解説します。
- 駐車場の監視画像データセット「PKLot」を例題に、「YOLOX-Sモデル」を学習・軽量化します。
- AE2100での実測評価では、モデルサイズを約1/8倍に削減しつつ、CPU利用で約3.8倍、VPU利用で約2.4倍の高速化効果を確認しました。
データセットの準備(PKLot Dataset)
今回は例題として、駐車場の監視画像データセットの PKLot Dataset2 を利用して、駐車スペースに車両が停められているかどうかを判定する物体検出モデルの学習と軽量化をしたいと思います。
PKLotデータセットには、監視カメラ映像のフレームから抽出された12,416枚の駐車場の画像が含まれています。晴れの日、曇りの日、雨の日の画像があり、駐車スペースは占有(Occupied)か空き(Empty)かのラベルが付けられています。

まずは、PKLotデータセットをダウンロードして、以下のようなディレクトリ構造で格納しておきます。なお、PKLotデータセットのアノテーションはCOCO形式です。
/path/to/pklot_dataset/
├── annotations # アノテーションファイルを含むディレクトリ
| ├── pklot_train.json # 学習用アノテーションファイル(COCO形式)
| └── pklot_valid.json # 評価用アノテーションファイル(COCO形式)
├── train # 学習用の画像ファイルを含むディレクトリ
| ├── XXX.jpg
| ...
└── valid # 評価用の画像ファイルを含むディレクトリ
├── YYY.jpg
...
※ アノテーションファイルを含むディレクトリの名称は"annotations"とする必要がありますのでご注意ください。
YOLOXライブラリとの連携
PCASツール上で YOLOX を利用するには、エントリーポイント3としてexamples/detection/train_meg.pyを使用します。まず、物体検出(detection)に関して、現在PCASツール上に登録されていて利用可能なデータセットとモデルを確認します。
データセットとモデルの登録情報は、それぞれ--show_datasetsと--show_modelsのコマンドで確認可能です。
> python examples/detection/train_meg.py --show_datasets --show_models
Registered datasets:
['coco_yolox_mmdet',
'voc_ssd_mmdet',
'coco_meg',
'voc_meg']
Registered models:
['yolov3_meg',
'yoloxs_meg',
'yoloxm_meg',
'yoloxl_meg',
'yoloxx_meg',
'yolox_s_mmdet',
'ssd300_mmdet']
上記の例は表示の一部省略していますが、名称が*_megとなっているものがYOLOXライブラリに対応しているものです。今回は、COCO形式のアノテーションファイルを使用するのでデータセットにはcoco_megを使用します。なお、VOC形式の場合はvoc_megが利用できます。次に、モデルに関しては、YOLOX-Sモデルを示すyoloxs_megを使用することにします。
物体検出モデルの学習と軽量化
YOLOX-Sモデルのスクラッチ学習と軽量化は、例えば以下のコマンドで実行できます。
python examples/detection/train_meg.py \
--data_dir /path/to/pklot_dataset \
--train_ann pklot_train.json \
--val_ann pklot_valid.json \
--train_dirname train \
--val_dirname valid \
--input_size 512 512 \
--test_size 512 512 \
--dataset coco_meg \
--num_classes 3 \
--in_size 512 \
--model yoloxs_meg \
--enable_mixup False \
--mosaic_scale 0.5 1.5 \
--random_size 10 20 \
--mode train \
--devices 4 \
--max_epochs 200 \
--batch_size 16 \
--learning_rate 0.01 \
--att_lr_ratio 0.2 \
--finetune_lr_ratio 0.1 \
--pcas_max_iters 11 \
--pcas_sampler False \
--outdir /result/pklot
引数が多く感じられるかもしれませんが、それぞれ一般的なディープラーニングフレームワークの学習においても使用される、基本的な要素で構成されています。
まずは、データセットの設定に関する引数です。
-
--data_dirは、用意したPKLotデータセットのディレクトリパスを指定します。 -
--train_annは、学習用アノテーションのファイル名を指定します。 -
--val_annは、評価用アノテーションのファイル名を指定します。 -
--train_dirnameは、学習用画像ファイルのディレクトリ名を指定します。 -
--val_dirnameは、評価用画像ファイルのディレクトリ名を指定します。 -
--input_sizeは、入力画像の幅と高さの大きさを指定します。 -
--test_sizeは、評価時に使用する画像サイズを指定します。 -
--datasetは、上記で確認した、PCASツールに登録済みのデータセット名称を指定します。
次に、モデルの設定に関する引数です。
-
--num_classesは、分類したいクラス数を指定します。- 今回はOccupiedとEmptyの2種類ですが、アノテーションファイル記述の都合で3種としています。
-
--in_sizeは、PCASツール内で軽量化時に使用するダミー画像のサイズを指定します。- 基本的には、--input_sizeと同じ大きさの値を指定すれば問題ありません。
-
--modelは、上記で確認した、PCASツールに登録済みのモデル名称を指定します。
続いて、データ拡張の設定に関する引数です。YOLOXライブラリが含むデータ拡張手法が利用できます。
-
--enable_mixupは、Mixupを有効化するかどうかを'True'か'False'で指定します。 -
--mosaic_scaleは、モザイクデータ拡張を使用する時(デフォルトで有効)の入力画像の拡大率を(最小値, 最大値)で指定します。 -
--random_sizeは、 マルチスケール学習で使用する入力画像の拡大率を指定します。
その他は、学習と軽量化の設定に関する引数です。
-
--modeは、PCASツールの軽量化ループの開始モード4を指定します。- 今回は乱数で初期化した重みから学習を始める(スクラッチ学習)ので、'train'を指定します。
-
--devicesは、学習に使用するGPUデバイスの数を指定します。今回は4個のGPUを使用します。 -
--max_epochsは、最大エポック数を指定します。 -
--batch_sizeは、バッチサイズを指定します。- ※ GPUを複数使用する場合のバッチサイズは、「devices * batch_size」となります。
-
--learning_rateは、学習率を指定します。 -
--att_lr_ratioは、アテンションモード4 における学習率に対する乗数です。- 当該モードの学習率は「learning_rate * att_lr_ratio」となります。
-
--finetune_lr_ratioは、ファインチューニングモード4 における学習率に対する乗数です。- 当該モードの学習率は「learning_rate * finetune_lr_ratio」となります。
-
--pcas_max_itersは、PCASのループ回数4です。- 11回としましたが、最初の1回はスクラッチ学習なので、軽量化は10回に分けて段階的に実行されます。
-
--pcas_samplerは、モデルの分岐構造においてプルーニング対象層を増やすオプションです。- 今回は使用しない設定(False)としています。
-
--outdirは、学習結果の出力先ディレクトリパスを指定します。
過去記事 (第2回:スクラッチ学習と軽量化を実行する) と同様に、コマンド実行すると以下のようにPytorch Lightningの学習プロセスが開始されますので、学習と軽量化が全て完了するまで待機します。完了までの時間は、データセット規模やモデル規模、計算機の性能等に依存しますのでご注意ください。
-------- PCAS Iteration: 0 --------
===== PCAS_MODE: (Re-)Train (Iter: 0) =====
Generating prune_config.. (this may take a few minutes)
Prune_config was generated (/result/pklot/yoloxs_meg-20220921-001738/prune_config.yaml).
From next time on, you can shortcut the conversion process by giving the prune_config.yaml as '--prune_config'.
PCAS WARNING: --checkpoint file was not found. Continue processing without loading the file.
... 以下省略
学習の進捗状況は、コンソール出力やファイル出力、あるいはTensorboardで確認可能です。例えば、Tensorboardで確認する場合、引数--outdirで指定した出力ディレクトリパスを対象として、以下のようにtensorboardを実行します。(※ Tensorboard環境はPCASを実行しているコンテナ以外で別途用意が必要です)
> tensorboard --logdir /result/pklot --bind_all
実行後、ブラウザから損失関数の値や学習率、精度指標などがグラフで確認可能です。
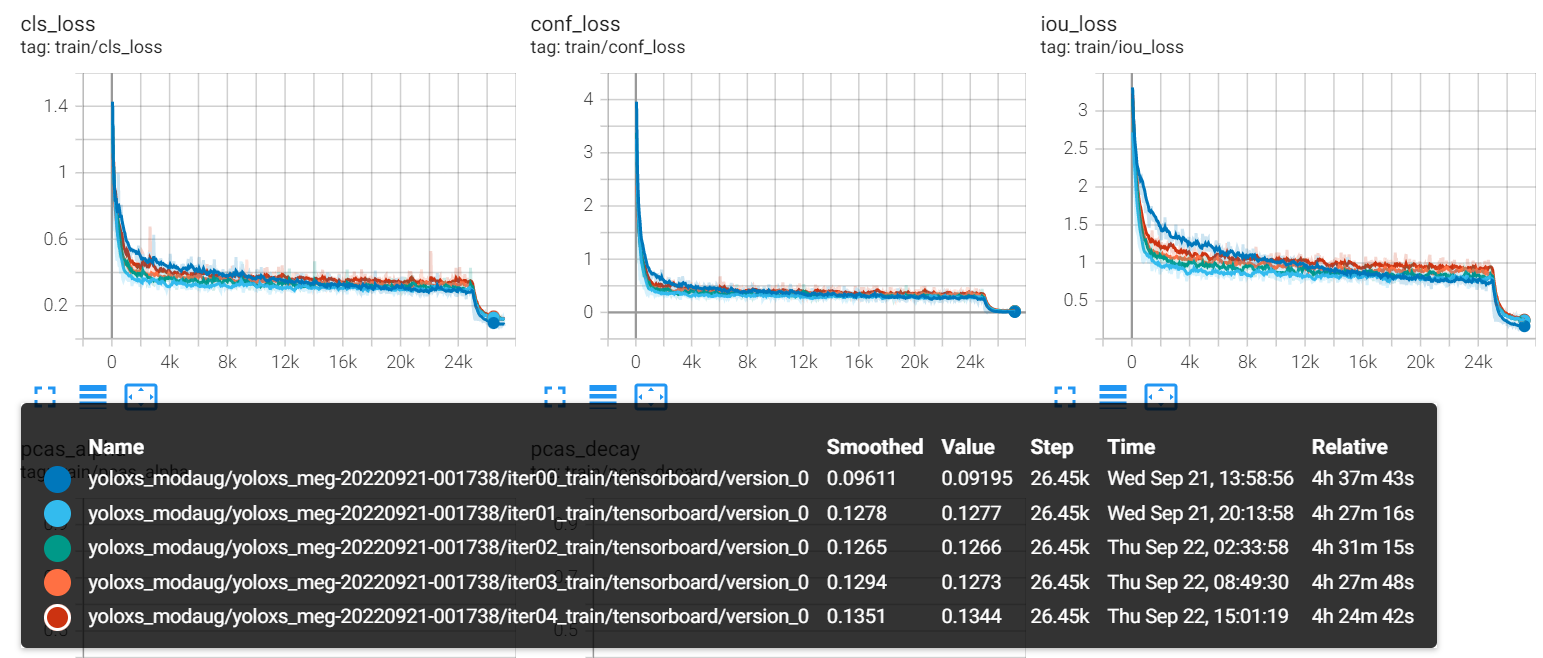
軽量化結果を確認する
軽量化したモデルについて、浮動小数点演算回数(FLOPs)とパラメータ数に対する精度指標(AP50, mAP)の関係をグラフ化します。手順の詳細は、過去記事 (第2回:軽量化結果を確認する) にて紹介しています。
AP50やmAPは、物体検出モデルの評価に使用される一般的な精度指標です。AP50は推定されたバウンディングボックスの正解との重複率(IoU)が50%以上のものを検出成功とみなす場合の平均適合率(AP)で、mAPはステップサイズを0.05とした時の0.5から0.95までのIoUで求めたAPの平均値を表現しています。
学習結果のサマリーとして出力されるpcas_summary.yamlを用いて、次のコードで軽量化結果をグラフ化します。
import yaml
import matplotlib.pyplot as plt
""" YAMLファイルの読み込み """
with open('pcas_summary.yaml', 'r') as file:
pcas_summary = yaml.load(file, Loader=yaml.FullLoader)
""" 精度指標(ap50, map)・浮動小数点演算回数(flops)・パラメータ数(params)の抽出 """
ap50, map, flops, params = {}, {}, {}, {}
for k in pcas_summary.keys():
if 'train' in k:
ap50[k] = pcas_summary[k]['val/AP@0.5']
map[k] = pcas_summary[k]['val/AP@0.5:0.95']
if 'prune' in k:
if len(flops) == 0:
flops['iter00_train'] = pcas_summary[k]['flops_origin_[M]']
flops[k] = pcas_summary[k]['flops_pruned_[M]']
if len(params) == 0:
params['iter00_train'] = pcas_summary[k]['params_origin_[M]']
params[k] = pcas_summary[k]['params_pruned_[M]']
""" プロット """
plt.figure(figsize=(7,6))
plt.subplot(2,2,1); plt.plot(flops.values(), ap50.values(), 'bo-')
plt.xlabel('FLOPs [M]'); plt.ylabel('AP50'); plt.grid()
plt.subplot(2,2,2); plt.plot(params.values(), ap50.values(), 'go-')
plt.xlabel('Params [M]'); plt.ylabel('AP50'); plt.grid()
plt.subplot(2,2,3); plt.plot(flops.values(), map.values(), 'bo-')
plt.xlabel('FLOPs [M]'); plt.ylabel('mAP'); plt.grid()
plt.subplot(2,2,4); plt.plot(params.values(), map.values(), 'go-')
plt.xlabel('Params [M]'); plt.ylabel('mAP'); plt.grid()
plt.tight_layout()
plt.show()
今回は、以下のような結果が得られました。グラフにおけるデータ点ひとつひとつが軽量化されたモデルを表しています。
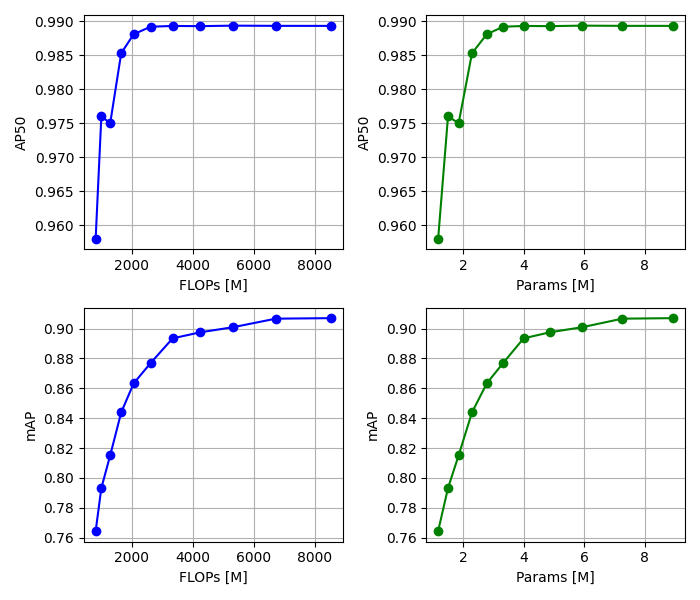
AP50は、パラメータ数が3.31Mのモデルまではほぼ変化が無く、それ以降で大きく変化する傾向が見られました。一方、mAPはAP50よりもシビアな指標のため、軽量化を進める度に徐々に低下する様子が観察できます。※ 単位のMは、Millionの略で$10^6$を示します。
次に、検出結果の可視化を行います。可視化には、ONNX Runtime と YOLOXライブラリ の機能を利用します。まず、軽量化した全てのモデルを以下のコマンドでONNX形式に一括変換します。
※ ONNX形式への変換の詳細は 過去記事 (第3回:PyTorchモデルをONNX形式に変換する) に記載があります。
python examples/utils/ckpt2onnx.py \
--input_dir /result/pklot/yoloxs_meg-20220921-001738 \
--entrypoint examples/detection/train_meg.py \
--in_ch 3 \
--in_size 512
実行後に以下のメッセージが表示されて完了です。
All models are converted into ONNX! (/result/pklot/yoloxs_meg-20220921-001738/onnx)
生成されたONNXファイルを使った検出結果の可視化を、以下のコードで実行します。
import cv2
import numpy as np
import matplotlib.pyplot as plt
import onnxruntime
from yolox.data.data_augment import preproc as preprocess
from yolox.utils import multiclass_nms, vis, demo_postprocess
image_path = '*.jpg' # 画像データパス
model_path = '*.onnx' # ONNXモデルパス
input_shape = (512, 512) # 画像サイズ
# 前処理
input_shape = tuple(map(int, input_shape.split(',')))
origin_img = cv2.imread(image_path)
img, ratio = preprocess(origin_img, input_shape)
# 推論実行
session = onnxruntime.InferenceSession(model_path)
ort_inputs = {session.get_inputs()[0].name: img[None, :, :, :]}
output = session.run(None, ort_inputs)
# 後処理
predictions = demo_postprocess(output[0], input_shape)[0]
boxes = predictions[:, :4]
scores = predictions[:, 4:5] * predictions[:, 5:]
boxes_xyxy = np.ones_like(boxes)
boxes_xyxy[:, 0] = boxes[:, 0] - boxes[:, 2]/2.
boxes_xyxy[:, 1] = boxes[:, 1] - boxes[:, 3]/2.
boxes_xyxy[:, 2] = boxes[:, 0] + boxes[:, 2]/2.
boxes_xyxy[:, 3] = boxes[:, 1] + boxes[:, 3]/2.
boxes_xyxy /= ratio
dets = multiclass_nms(boxes_xyxy, scores, nms_thr=0.45, score_thr=0.1)
# 結果表示
if dets is not None:
final_boxes, final_scores, final_cls_inds = dets[:, :4], dets[:, 4], dets[:, 5]
origin_img = vis(origin_img, final_boxes, final_scores, final_cls_inds,
conf=0.3, class_names=("", "Empty", "Occupied"))
plt.imshow(origin_img)
plt.show()


1枚目が中程度の軽量化を行ったモデル(パラメータ数が3.31M)で、2枚目が最も軽量化を行ったモデル(パラメータ数が1.16M)です。この評価画像に対しては、両モデルとも駐車スペースの位置とクラスをほぼ同等に推定できています。差分としては、クラス判別の確率値が2枚目の方が全体的に低くなっている(≒劣化している)ことが確認できます。
AE2100(CPU/VPU) 上で推論速度を計測する
続いて、AE2100上でYOLOX-Sモデルを動作させ、推論性能を実測評価したいと思います。評価のための推論エンジンとしては、OpenVINO を使用します。まずは、ONNX形式のモデルをOpenVINO形式(IR形式)に変換する必要があります。
※ 本記事では、AE2100の環境構築方法については解説していませんが、AE2100付属のマニュアル(「AE2100 シリーズ SDK 取扱説明書 ― 共通編 ― 」)を参考にセットアップをお願いします。なお、AIエッジユーザーサイトにて、OpenVINOがインストール済みのAE2100用コンテナイメージが提供されていますので、そちらを利用すると簡単です。
モデル変換をするには、まずIntel OpenVINO Toolkitを入手・インストールして、次の"mo"コマンドでModel Optimizerを実行します。"--data_type FP16"でビット精度を16ビット浮動小数点に指定しています。
> mo --input_model iterXX_train_epochYYY.onnx --input_shape "[1,3,512,512]" --mean_values "[0.485,0.456,0.406]" --scale_values "[0.229,0.224,0.225]" --data_type FP16
実行後、ONNXファイルと同じディレクトリに拡張子が .xml, .bin, .mapping の3つのモデルファイルが出力されますので、それらをAE2100に転送した後、OpenVINO Tookitに同梱の Benchmark Python Tool を使用して、モデルの推論速度を計測します。
> python3 benchmark_app.py -m iterXX_train_epochYYY.xml -d CPU -nireq 2 -niter 100
Count: 100 iterations
Duration: 151141.08 ms
Latency: 3021.70 ms
Throughput: 0.66 FPS
"-m"でモデルファイル(.xml)を指定し、"-d"で使用デバイスを指定しています。CPUで実行する場合はCPUを、AIアクセラレータチップ MyriadX (VPU) を使用して実行する場合はHDDLを指定します。"-nireq 2"で2つの推論の非同期実行を、"-niter 100"で100回の推論実行を指定します。
さて、軽量化レベル(圧縮率)の異なるYOLOX-Sモデルについて、それぞれ推論速度(FPS: Frame Per Second)を計測したところ、以下の結果となりました。
| 軽量化レベル5 (圧縮率) | AP50 | mAP | FPS (CPU) | FPS (VPU) | モデルサイズ |
|---|---|---|---|---|---|
| Original (0%) | 98.9% | 90.7% | 0.66 | 11.70 | 17.44MB |
| Iter01 (15%) | 98.9% | 90.1% | 0.77 | 13.49 | 14.15MB |
| Iter02 (28%) | 98.9% | 90.1% | 0.91 | 15.39 | 11.58MB |
| Iter03 (39%) | 98.9% | 89.7% | 1.07 | 16.69 | 9.46MB |
| Iter04 (48%) | 98.9% | 89.3% | 1.28 | 18.66 | 7.78MB |
| Iter05 (56%) | 98.9% | 87.7% | 1.47 | 20.64 | 6.46MB |
| Iter06 (62%) | 98.8% | 86.3% | 1.70 | 22.84 | 5.40MB |
| Iter07 (68%) | 98.5% | 84.4% | 1.86 | 24.24 | 4.45MB |
| Iter08 (73%) | 97.5% | 81.5% | 2.08 | 25.81 | 3.59MB |
| Iter09 (77%) | 97.6% | 79.3% | 2.36 | 27.01 | 2.90MB |
| Iter10 (80%) | 95.8% | 76.4% | 2.50 | 28.16 | 2.27MB |
CPUでの推論実行では、モデル軽量化により 最大で 約3.8倍 の高速化ができ、最大時のAP50の劣化は3.1%、mAPの劣化は14.3%でした。モデルサイズの観点では、約1/8倍 となりました。また、VPUでの軽量化による高速化効果は 最大で 約2.4倍 でした。
PCASツールで軽量化したモデルは、CPUとVPUのいずれの場合においても、その適用により高速化とモデルサイズ削減の効果が得られることを確認できました。
まとめ
本記事では、駐車場の監視画像データセット「PKLot」を題材に、車両の駐車場状況を認識する物体検出モデルYOLOX-Sを、物体検出ライブラリのYOLOXを利用して、PCASツールでスクラッチ学習から軽量化までをワンストップで実行し、軽量化結果の確認とAE2100 (CPU/VPU) 上での推論速度の実測評価を行いました。
本記事のバックナンバー:
ディープラーニングモデルの軽量化ツールPCASの使い方 (1) ーインストール編ー
ディープラーニングモデルの軽量化ツールPCASの使い方 (2) ー画像分類モデルの軽量化編ー
ディープラーニングモデルの軽量化ツールPCASの使い方 (3) ーモデル変換と性能評価 (CPU/VPU) 編ー
ディープラーニングモデルの軽量化ツールPCASの使い方 (4) ー画像分類ライブラリtimmとの連携編ー
-
Ge, Z., Liu, S., Wang, F., Li, Z., & Sun, J. (2021). Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430. ↩
-
Almeida, P., Oliveira, L. S., Silva Jr, E., Britto Jr, A., Koerich, A., PKLot – A robust dataset for parking lot classification, Expert Systems with Applications, 42(11):4937-4949, 2015. ↩
-
エントリーポイントや実行コードの構成については、過去記事 (第2回:実行コードの構成) をご参照ください。 ↩
-
詳細は、 過去記事 (第2回:軽量化処理の流れ) をご参照ください。 ↩ ↩2 ↩3 ↩4
-
軽量化レベルを"IterXX"と呼び、XXには軽量化処理のループ回数が入ります。XXが大きくなるほど軽量化されたモデルとなります。圧縮率は、モデル全体のチャネル数に対する削減比率を表すもの(値が大きいほど削減量が多い)で、今回の軽量化処理ループ1回におけるチャネル削減率を$c$、プルーニングを行った回数を$n$とすると、$1−(1−c)^n$ で計算されます。今回のケースでは、デフォルト値である $c=0.15$(引数
--comp_rateで指定可能) を使用しています。 ↩