本記事は、ディープラーニングモデルの軽量化ツールPCASの使い方 (1) ーインストール編ー の続編です。
前回の記事でモデル軽量化ツールPCAS(以下、PCASツール)の実行環境を整えたので、今回は実際に画像分類モデルの軽量化を行っていきたいと思います。
本記事の要約
- PCASツールの構成と基本的な処理の流れを解説します。
- ユーザーの独自データセットや独自モデルなどを扱う方法を解説します。
- 「CIFAR10 + VGG10」の例題を通じて、軽量化結果の確認方法を紹介します。
はじめに
具体的な実行例に入る前に、まずPCASツールにおける軽量化処理の流れと、軽量化の実行コード構成について解説したいと思います。
軽量化処理の流れ
PCASツールにおける軽量化処理では、ディープラーニング(DL)モデル内に存在する不必要な演算を特定・削減し、推論を高速化するプルーニング技術を適用します。実態としては、以下の図のようなループ構造で適用します。
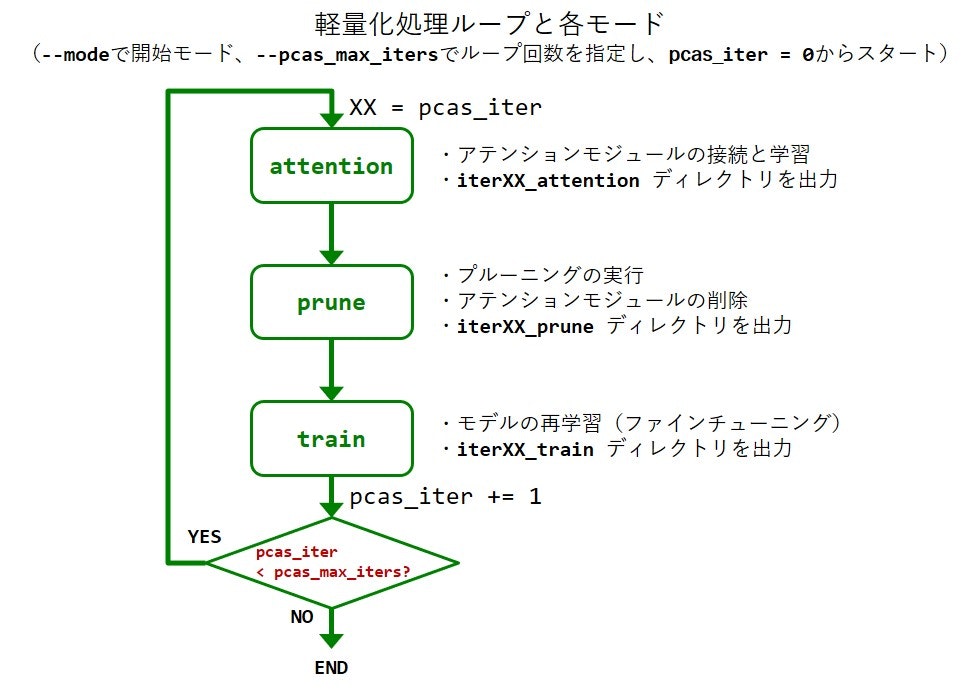
このループ構造の中には3つの実行モードがあり、それぞれ以下の役割があります。
| モード名 | 概要 |
|---|---|
| アテンション(attention) | PCASツールの軽量化アルゴリズムに必要な機能1で、軽量化対象モデルに含まれる重みフィルタの重要度を推定します。 |
| プルーニング(prune) | アテンションモードで得られた重要度を元に、モデルの軽量化を実行します。 |
| ファインチューニング(train) | プルーニングモードで軽量化されたモデルは精度劣化が生じているため、学習で認識精度を回復させます。 |
3つの実行モードには順序関係があり、「ファインチューニング」の後に「アテンション」に繋がるループ構造となっています。このような構造は、軽量化後の認識精度の維持に役立つ段階的なプルーニング(脚注2)を実行するために構成されます。
典型的には、ユーザーの手元に学習済みモデルパラメータがある場合は「アテンション」モードからループを開始し、学習済みモデルパラメータが無い場合は「ファインチューニング」モードからループを開始します(初回のファインチューニングモードがスクラッチ学習として機能します)。
実行コードの構成
PCASツールに同梱の、軽量化の実行コードを含むディレクトリexamplesは、以下の構造となっています。
examples
├── classification
├── detection
├── segmentation
:
└── utils
画像分類モデルを扱うclassificationや物体検出モデルを扱うdetectionなど、サブディレクトリはタスク別に分かれています。ただし、utilsは、各タスク共通で使用するソースコードを含んでいます。さらに、サブディレクトリの下位は以下の構成で共通しています。
classification, detection, segmentation, etc.
├── datasets
├── models
├── pl_modules
└── train_XXX.py
3つのディレクトリdatasets, models, pl_modulesの中には、それぞれ、データローダー ・モデル・Pytorch Lightning (PL) モジュール3を実装したPythonファイルが含まれます。そのいずれも PyTorch あるいは Pytorch Lightning の基本機能を使用して作成可能なものであり、ユーザーは自由に改変したり、独自実装を追加することができます。
train_XXX.pyは、軽量化実行のエントリーポイントとなる実行ファイルです。XXXには、オープンソース・ライブラリの略称が入り、PCASツールと対応ライブラリを併用する場合に使用します。例えば、2022年5月現在の対応ライブラリは以下の通りです。※下記ライブラリの中にはPCASツールが未サポートのモデルも含まれます。
| エントリーポイント | 対応ライブラリ(略称) | 対応タスク |
|---|---|---|
| train_plain.py | - | Classification |
| train_timm.py | pytorch-image-models (timm) | Classification |
| train_meg.py | YOLOX (meg) | Detection |
| train_mmdet.py | MMDetection (mmdet) | Detection |
| train_smp.py | segmentation_models.pytorch (smp) | Semantic Segmentation |
train_plain.pyのみ、Pytorch Lightning の基本機能のみで動作する形態となっています。
画像分類モデルの軽量化
それでは、最も単純な軽量化の実行コードであるtrain_plain.pyを使用して、画像分類モデルの軽量化を行います。前回の記事で構築したコンテナ環境に入り、実行コードを含むディレクトリ/pcasがPYTHONPATHに設定されていることを確認します。※ もし設定されていなければ、export PYTHONPATH=$PYTHONPATH:/pcasで追加をお願いします。
> echo $PYTHONPATH
/pcas
今回はシンプルな例題として、10クラスの画像認識が行えるCIFAR10データセットに対して、10個の畳み込み層で構成されるVGG10モデルをスクラッチ学習して軽量化したいと思います。
ユーザーが独自に用意したデータセットやモデルをPCASツールで使用するためには、事前に 簡単な登録作業 が必要となります。
データセットの準備(CIFAR10)
例えば、examples/classification/datasetsの中に、"my_cifar10.py"と名付けたPythonファイルを作成し、以下のようにデータローダーを生成する関数my_cifar10(args)を定義して、デコレータ@register_datasetを付与します。これでデータセットの登録作業は完了です3。
""" in examples/classification/datasets/my_cifar10.py """
from torch.utils.data import DataLoader
from torchvision.datasets.cifar import CIFAR10
from torchvision import transforms
from examples.utils.registry import register_dataset
@register_dataset # データセットをキーワード"my_cifar10"としてPCASツールに登録
def my_cifar10(args):
# 学習用データローダーの準備
trans_train = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32, 4),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
train_data = CIFAR10(args.data_dir, train=True, download=True, transform=trans_train)
train_loader = DataLoader(train_data, batch_size=args.batch_size, shuffle=True)
# 評価用データローダーの準備
trans_val = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
val_data = CIFAR10(args.data_dir, train=False, download=True, transform=trans_val)
val_loader = DataLoader(val_data, batch_size=args.batch_size, shuffle=False)
return train_loader, val_loader
なお、生成関数my_cifar10(args)の引数argsにはtrain_plain.pyの中で定義されたAugumentParserが渡されるため、それを修正することでユーザーは独自の引数を与えることができます。上記では、CIFAR10データセットのルートディレクトリ(args.data_dir)の指定に使用しています。
この例のデータセットでは、説明を簡単にするためにデータセットクラスに"torchvision.datasets.cifar.CIFAR10"を使用していますが、ユーザーが独自データセットを使用する場合は、例えば ImageFolder 等を使用して構築します。
モデルの準備(VGG10)
モデルの登録もデータセットの登録と同様です。例えば、examples/classification/modelsの中に、"my_vgg10.py"と名付けたPythonファイルを作成し、以下のようにモデルを生成する関数my_vgg10(args)を定義して、デコレータ@register_modelを付与することで完了します3。
""" in examples/classification/models/my_vgg10.py """
import torch
import torch.nn as nn
from examples.utils.registry import register_model
class VGG10(nn.Module):
def __init__(self, num_classes=10):
super(VGG10, self).__init__()
cfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512]
in_channels = 3
layers = []
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
layers += [
nn.Conv2d(in_channels, v,
kernel_size=3, padding=1, stride=1, bias=False),
nn.BatchNorm2d(v),
nn.ReLU(inplace=True)
]
in_channels = v
layers += [nn.Conv2d(cfg[-1], num_classes,
kernel_size=3, padding=1, stride=1, bias=False)]
self.features = nn.Sequential(*layers)
def forward(self, x):
return torch.mean(self.features(x), dim=(-1, -2))
@register_model # モデルをキーワード"my_vgg10"としてPCASツールに登録
def my_vgg10(args):
return VGG10(num_classes=args.num_classes)
データセットと同様に、生成関数my_vgg10(args)の引数argsもtrain_plain.pyの中で定義されたArgumentParserです。上記では、出力クラス数(args.num_classes)の指定に使用しています。
スクラッチ学習と軽量化を実行する
以上の準備で、ユーザーが用意したデータセットmy_cifar10とモデルmy_vgg10がPCASツールで使用可能となりました。それでは、コマンドラインからツールを実行します。
例えば、以下コマンドを実行するとPCASツールは、スクラッチ学習(脚注4)と軽量化を行います。
cd /pcas
python examples/classification/train_plain.py \
--outdir /result/cifar10_vgg10 \
--data_dir /data/cifar-10-batches-py \
--dataset my_cifar10 \
--model my_vgg10 \
--max_epochs 200 \
--devices 1 \
--learning_rate 0.1 \
--batch_size 128 \
--pcas_max_iters 8 \
--mode train \
--finetune_lr_ratio 0.3
上記の例における引数の意味は以下の通りです。学習を伴うため引数の数は多く、上記以外にも複数のオプションがあります(詳細はツール付属ドキュメント、あるいは定義されたArgumentParserのヘルプを参照)。
| 引数例 | 意味 |
|---|---|
| --outdir /result/my_cifar10_vgg10 | 出力ディレクトリを指定(ディレクトリが存在しなければ自動で生成) |
| --data_dir /data/cifar-10-batches-py | CIFAR10データセットを配置したディレクトリを指定 |
| --dataset my_cifar10 | 登録されたキーワード"my_cifar10"に紐づくデータセットを指定 |
| --model my_vgg10 | 登録されたキーワード"my_vgg10"に紐づくモデルを指定 |
| --max_epochs 200 | 最大エポック数を200に指定(Pytorch Lightningの引数を流用) |
| --devices 1 | 使用GPU数を1に指定(Pytorch Lightningの引数を流用) |
| --learning_rate 0.1 | 学習率を0.1に指定 |
| --batch_size 128 | バッチサイズを128に指定 |
| --pcas_max_iters 5 | 軽量化処理の流れで解説した軽量化処理のループ回数を8に指定 |
| --mode train | 開始モードをtrainに指定 |
| --finetune_lr_ratio 0.3 | ファインチューニングモードの学習率を0.03に指定 5 |
上記コマンドを実行すると、以下のようにスクラッチ学習(ファインチューニングモード)から開始されます。
> python examples/classification/train_plain.py ..引数省略..
-------- PCAS Iteration: 0 --------
===== PCAS_MODE: (Re-)Train (Iter: 0) =====
Generating prune_config.. (this may take a few minutes)
PCAS converter: 97%|################################################################ | 33/34 [00:00<00:00, 216.70it/s]
Prune_config was generated (/result/my_cifar10_vgg10/my_vgg10-20220509-084713/prune_config.yaml).
From next time on, you can shortcut the conversion process by giving the prune_config.yaml as '--prune_config'.
~~~~~~~~~~~~~~~ 省略 ~~~~~~~~~~~~~~~
| Name | Type | Params
---------------------------------------
0 | backbone | VGG10 | 7.1 M
1 | train_acc | Accuracy | 0
2 | val_acc | Accuracy | 0
---------------------------------------
7.1 M Trainable params
0 Non-trainable params
7.1 M Total params
14.187 Total estimated model params size (MB)
Epoch 0: 85%|███████████████████████████████████████████████████▋ | 398/470 [00:18<00:03, 21.47it/s, loss=1.67]
PCASツールは、プルーニング・可能な層を特定するために"PCAS converter"というモデル解析プロセスを学習開始前に実行します。巨大なモデルほど解析に時間が掛かりますが、解析後に生成される"prune_config.yaml"を使用することで次回以降の実行を省略可能です。
スクラッチ学習(ファインチューニングモード)が完了すると、次にアテンションモードが自動実行されます。
-------- PCAS Iteration: 1 --------
===== PCAS_MODE: Attention (Iter: 1) =====
~~~~~~~~~~~~~~~ 省略 ~~~~~~~~~~~~~~~
| Name | Type | Params
---------------------------------------
0 | backbone | VGG10 | 7.6 M
1 | train_acc | Accuracy | 0
2 | val_acc | Accuracy | 0
---------------------------------------
501 K Trainable params
7.1 M Non-trainable params
7.6 M Total params
15.190 Total estimated model params size (MB)
Epoch 0: 83%|████████████████████████████▎ | 391/470 [00:24<00:04, 15.85it/s, loss=0.00352, train/pcas_alpha=0.783]
アテンションモードでは、0エポック目のログに表示されているtrain/pcas_alpha=0.783のように、PCASツールの独自パラメータpcas_alphaが計測されます。アテンションモードの目的のひとつは、pcas_alphaの値(初期値は1.0)が0.4~0.6程度に減少するようにアテンションモジュール1を学習することです。
アテンションモードの完了後は、プルーニングモードに移行します。学習の完了したアテンションモジュールは、モデル内に存在するニューロンの重要度を上手く推定できるようになり、プルーニング処理の中で冗長な演算の削減に役立てられます。
===== PCAS_MODE: Prune (Iter: 1) =====
PCAS INFO: Loaded prune_config overwrites 'use_sampler' (False -> True).
PCAS INFO: Loaded prune_config overwrites 'share_attention' (False -> True).
Checked pcas_alpha == 0.41240489
Estimated global threshold == 0.96770611
Pruning was completed (and the attention modules were removed).
---------- Pruning Summary ----------
001, features.3 : 64 --> 59 ( 7.81 % drop)
002, features.7 : 64 --> 54 (15.62 % drop)
003, features.10: 128 --> 119 ( 7.03 % drop)
004, features.14: 128 --> 98 (23.44 % drop)
005, features.17: 256 --> 253 ( 1.17 % drop)
006, features.21: 256 --> 232 ( 9.38 % drop)
007, features.24: 512 --> 512 ( 0.00 % drop)
008, features.28: 512 --> 460 (10.16 % drop)
009, features.31: 512 --> 280 (45.31 % drop)
Channel compression ratio (rate) difference:
15.0 % (user setting) --> 15.0 % (actual)
Computational burden difference (including activations):
FLOPs: 219.88 M --> 177.28 M ( 19.37 % drop)
Params: 7.09 M --> 5.32 M ( 24.98 % drop)
Pruning Summary 以下で、今回のプルーニング結果を確認することができます。例えば、入力層から2個目の畳み込み層features.3の入力チャネル数は、64個から59個に約8%削減されたことがわかります。
モデル全体としては、ユーザーが与えた削減率15%(今回は--comp_rate 0.15のデフォルト値を使用)を満たすように最適化されています。また、"Computational burden difference" の項目で浮動小数点演算回数(FLOPs)とパラメータ数(Params)の変化も確認可能です。※ 単位Mは、Million $(\times 10^6)$を意味します。
プルーニングモードの完了後は、再びファインチューニングモードに移行し、モデルの認識精度を回復させます。
===== PCAS_MODE: (Re-)Train (Iter: 1) =====
~~~~~~~~~~~~~~~ 省略 ~~~~~~~~~~~~~~~
| Name | Type | Params
---------------------------------------
0 | backbone | VGG10 | 5.3 M
1 | train_acc | Accuracy | 0
2 | val_acc | Accuracy | 0
---------------------------------------
5.3 M Trainable params
0 Non-trainable params
5.3 M Total params
10.643 Total estimated model params size (MB)
Epoch 0: 83%|█████████████████████████████████████████████████▉ | 391/470 [00:20<00:04, 19.05it/s, loss=0.315]
以降は、--pcas_max_itersで指定した回数分、軽量化処理がループ実行されます。
軽量化結果を確認する
PCASツールの実行完了後、以下のディレクトリ構成でファイルが出力されます(出力ディレクトリ内に、モデル名+日付時刻のディレクトリが生成されます)。ディレクトリiterXXのXXには二桁の数値が入り、軽量化処理ループにおけるループ回数を示しています。
/result/my_cifar10_vgg10/my_vgg10-20220509-084713
├── iterXX_attention
├── iterXX_prune
├── iterXX_train
├── console.log
├── pcas_summary.yaml
└── prune_config.yaml
この中で、pcas_summary.yamlが軽量化結果のサマリーになります。その実態は、実行済みの各ループについて、Pytorch Lightningの機能で記録したメトリクス(lossやaccuracyなど) と、プルーニングの結果(プルーニングモード実行後のみ)を含むYAMLファイルです。以下に出力例を示します。
""" in /result/my_cifar10_vgg10/my_vgg10-20220509-084713/pcas_summary.yaml """
iter00_train: # ディレクトリ名(ループ回数・モード)
train/accuracy: 0.9999799728393555
train/loss: 0.0005042299744673073
val/accuracy: 0.9320999979972839 # スクラッチ学習の認識精度
val/loss: 0.304877907037735
iter01_attention:
train/accuracy: 0.9998800158500671
train/loss: 4.071593139087781e-05
train/pcas_alpha: 0.40252479910850525
val/accuracy: 0.9325000047683716
val/loss: 0.3587852120399475
iter01_prune:
comp_rate_actual_[%]: '15.0'
comp_rate_setting_[%]: '15.0'
flops_drop_rate_[%]: '17.65'
flops_origin_[M]: 219.875328 # プルーニング前のFLOPs(1回目)
flops_pruned_[M]: 181.070352 # プルーニング後のFLOPs(1回目)
params_drop_rate_[%]: '23.93'
params_origin_[M]: 7.093696 # プルーニング前のパラメータ数(1回目)
params_pruned_[M]: 5.396421 # プルーニング後のパラメータ数(1回目)
iter01_train:
train/accuracy: 1.0
train/loss: 0.01294117420911789
val/accuracy: 0.9319000244140625 # ファインチューニング後の認識精度(1回目)
val/loss: 0.31481751799583435
iter02_attention:
train/accuracy: 0.9999799728393555
train/loss: 0.0003754436911549419
train/pcas_alpha: 0.3985528349876404
val/accuracy: 0.930899977684021
val/loss: 0.3522014319896698
iter02_prune:
comp_rate_actual_[%]: '15.0'
comp_rate_setting_[%]: '15.0'
flops_drop_rate_[%]: '32.45'
flops_origin_[M]: 181.070352 # プルーニング前のFLOPs(2回目)
flops_pruned_[M]: 122.315584 # プルーニング後のFLOPs(2回目)
params_drop_rate_[%]: '27.48'
params_origin_[M]: 5.396421 # プルーニング前のパラメータ数(2回目)
params_pruned_[M]: 3.913645 # プルーニング後のパラメータ数(2回目)
iter02_train:
train/accuracy: 0.9998999834060669
train/loss: 0.0006134867435321212
val/accuracy: 0.9307000041007996 # ファインチューニング後の認識精度(2回目)
val/loss: 0.3378394544124603
~~~~~~~~~~~~~~~ 以下省略 ~~~~~~~~~~~~~~~
最終的な軽量化済みモデルファイルは、iterXX_trainディレクトリの中に含まれるepoch=YYY.ckptとなります。YYYにはエポック数が入り、YYYが最も大きなものが当該モードにおけるベストな軽量化済みモデルファイルとなります。その他の出力ファイルの詳細はツール付属ドキュメントをご参照ください。
pcas_summary.yamlはYAML形式のファイルなので、例えば、以下のコード例のように「認識精度(Accuracy)-浮動小数点演算回数(FLOPs)」や「認識精度(Accuracy)-パラメータ数(Params)」をプロットして軽量化効果を簡単に可視化することができます。
import yaml
import matplotlib.pyplot as plt
""" YAMLファイルの読み込み """
with open('pcas_summary.yaml', 'r') as file:
pcas_summary = yaml.load(file, Loader=yaml.FullLoader)
""" 認識精度(acc)・浮動小数点演算回数(flops)・パラメータ数(params)の抽出 """
acc, flops, params = {}, {}, {}
for k in pcas_summary.keys():
if 'train' in k:
acc[k] = pcas_summary[k]['val/accuracy']
if 'prune' in k:
if len(flops) == 0:
flops['iter00_train'] = pcas_summary[k]['flops_origin_[M]']
flops[k] = pcas_summary[k]['flops_pruned_[M]']
if len(params) == 0:
params['iter00_train'] = pcas_summary[k]['params_origin_[M]']
params[k] = pcas_summary[k]['params_pruned_[M]']
""" プロット """
plt.figure(figsize=(7,3))
plt.subplot(1,2,1); plt.plot(flops.values(), acc.values(), 'bo-')
plt.xlabel('FLOPs [M]'); plt.ylabel('Accuracy'); plt.grid()
plt.subplot(1,2,2); plt.plot(params.values(), acc.values(), 'go-')
plt.xlabel('Params [M]'); plt.ylabel('Accuracy'); plt.grid()
plt.tight_layout()
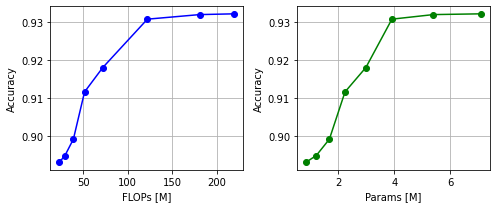
上記の可視化におけるデータ点ひとつひとつが軽量化されたモデルを表すので(※右端はオリジナルのため除く)、ユーザーは認識精度の変化などを考慮して、最終的に採用する軽量化モデルをこの中から決定することができます。
データ・モデル以外のカスタマイズ (補足)
上記では、PLモジュールやOptimizer/Scheduler、Trainerの設定については、全てデフォルト実装のものを使用しましたが、これらもユーザーが自由にカスタマイズ可能です。※ デフォルト実装のご使用で問題ない場合、本セクションは読み飛ばし可能です。
PLモジュールの準備
Pytorch Lightning モジュール6 (PLモジュール)は、Pytorch Lightningの機能を使用可能にするモデルのラッパークラスであり、損失関数の計算や学習・評価時の挙動など様々な処理を平易に記述できます。
データセットやモデルの登録例と同様に、例えば、examples/classification/pl_modulesの中に、"my_classifier.py"と名付けたPythonファイルを作成し、以下のようにモデルを生成する関数my_classifier(args)を定義して、デコレータ@register_pl_moduleを付与することで完了します3。
import pytorch_lightning as pl
from torch.nn import functional as F
from examples.utils.registry import register_pl_module
class MyClassifier(pl.LightningModule):
def __init__(self, args, model, optimizers, schedulers):
super().__init__()
self.optimizers = optimizers if isinstance(optimizers, list) else [optimizers]
self.schedulers = schedulers if isinstance(schedulers, list) else [schedulers]
self.backbone = model
self._args = args
def forward(self, x):
return self.backbone(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x) # 推論の実行
loss = F.cross_entropy(y_hat, y) # 損失関数の計算
self.log('train/loss', loss)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
self.log('val/loss', loss)
def configure_optimizers(self):
return self.optimizers, self.schedulers
@register_pl_module # PLモジュールをキーワード"my_classifier"としてPCASツールに登録
def my_classifier(args, model, optimizer, scheduler):
return MyClassifier(args, model, optimizer, scheduler)
この例では、training_step関数の中でF.cross_entropyを損失関数として使用していますが、ユーザーは自由に改変可能です。
OptimizerとScheduler の修正
Optimzier/Schedulerの設定は、エントリーポイントtrain_plain.py内の関数setup_model(args)で定義しています。デフォルト実装では以下のようにOptimizerにSGD、SchedulerにCosineAnnealingLRを利用しています。こちらもユーザーは自由に改変可能です。
""" in examples/classification/train_plain.py """
from pcas.utils import optim_pcas, att_mode_scheduler
def setup_model(model: torch.nn.Module,
args: Union[Namespace, ArgumentParser]) -> pl.LightningModule:
# optimizer setup
with optim_pcas(args, model) as op: # optimizerの設定はこのwith構文の中で行います。
pg0 = [p for n, p in model.named_parameters() if p.requires_grad and '.bias' in n]
pg1 = [p for n, p in model.named_parameters() if p.requires_grad and '.weight' in n]
optimizer = torch.optim.SGD(pg0, lr=args.learning_rate, nesterov=True, momentum=0.9) # SGD optimizerを利用
optimizer.add_param_group({'params': pg1, 'weight_decay': args.weight_decay})
op.send(optimizer) # optimizerに軽量化用設定を追加
del pg0, pg1
if 'attention' in args.mode:
# アテンションモードでは必ずatt_mode_schedulerを使用します。
lr_scheduler = att_mode_scheduler(optimizer)
else:
assert args.max_epochs is not None
# ファインチューニングモードでCosineAnnealingLR schedulerを利用
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, args.max_epochs)
# convert the model to the pytorch-lightning module
model = PL_MODULE[args.pl_module](args, model, optimizer, lr_scheduler)
return model
ただし、Optimizerの設定はoptim_pcas関数のwith構文の中で行い、最後にop.send(optimizer)で軽量化処理用の設定をOptimizerに反映する必要がある点にご注意願います。
Trainer の修正
Pytorch Lightningにおける Trainer の設定は、エントリーポイントtrain_plain.py内の関数setup_trainer(args)で定義しています。デフォルト実装は以下の通りです。ユーザ-独自のコールバック関数やロガーの設定は以下を修正することで使用できます。
""" in examples/classification/train_plain.py """
def setup_trainer(args: Union[Namespace, ArgumentParser]) -> pl.Trainer:
# 出力ディレクトリの設定
args.default_root_dir = args.outdir
# ロガーの設定
args.logger = pl.loggers.TensorBoardLogger(args.outdir, name='tensorboard')
# コールバックの設定
args.callbacks = [
pl.callbacks.LearningRateMonitor(logging_interval='epoch'),
pl.callbacks.ModelCheckpoint(dirpath=args.outdir, save_last=True,
save_weights_only=True, save_top_k=3,
monitor='val/accuracy', mode='max')
]
trainer = pl.Trainer().from_argparse_args(args)
return trainer
Tensorboardが利用可能な場合、例えばtensorboard --logdir /result/my_cifar10_vgg10/my_vgg10-20220509-084713 --bind_allのように出力ディレクトリを指定して実行することで全ての段階の軽量化結果のログ確認が可能になります。
まとめ
本記事では、『モデル軽量化ツールPCAS』の構成や処理フロー、また基本的な使用方法としてユーザーの独自データや独自モデル等の登録方法を説明し、「CIFAR10 + VGG10」による例題を通して、軽量化の実行から結果の確認までの一連の流れを解説しました。
今回の軽量化結果の確認では、FLOPsなど理論値との比較のみでデプロイ先のハードウェアとの相性を考慮していませんでしたが、どのモデルを最終的に採用するかに関しては、実測の推論速度の確認も重要となります。次回は、今回作成したVGG10モデルをOpenVINO形式のモデルに変換し、実測評価する方法について紹介する予定です。
⇒ ディープラーニングモデルの軽量化ツールPCASの使い方 (3) ーモデル変換と性能評価 (CPU/VPU) 編ー
本記事のバックナンバー:
ディープラーニングモデルの軽量化ツールPCASの使い方 (1) ーインストール編ー
-
PCASツールの軽量化アルゴリズムでは、軽量化の対象となる畳み込み層/全結合層に、新たなニューラルネットワーク(アテンションモジュール)を挿入し、そのモジュールだけを対象とした学習を実行します。その学習過程において、各モジュールはタスク損失の減少(≒認識精度の向上)に貢献する重みフィルタに対応するニューロンほど高い値を出力するように学習されます。したがって、アテンションモジュールの出力値を観察することで重みフィルタの重要度の推定が可能となります。 ↩ ↩2
-
段階的なプルーニング(Iterative Pruning)とは、目標の圧縮率まで一気にプルーニングする単発的なプルーニング(One-shot Pruning)するのではなく、低い圧縮率でプルーニングとファインチューニングを繰り返し、徐々に軽量化を行う方法です。段階的なプルーニングは単発的なプルーニングよりも比較的適用時間が長く掛かりますが、単発的なプルーニングよりも認識精度の劣化を抑える効果が高いことが知られています。なお、段階的なプルーニングを使う場合、最終的な圧縮率は何回実行したかに依存します。例えば、引数を
--mode attention --pcas_max_iters 3 --comp_rate 0.2と設定した場合は、20%のフィルタ削減を3回行うので $1-(1-0.2)^3 = 48.8\%$ が最終的な圧縮率となります。(--comp_rate Xはプルーニングモード1回の実行における圧縮率を指定しています。) ↩ -
PCASツールは、実行時にデコレータの付与された関数を読み込み、その関数名をキーワードとして登録します。 ↩ ↩2 ↩3 ↩4
-
スクラッチ学習が不要な場合(ユーザーの手元に学習済みモデルがある) は、開始モードを
--mode attentionとして、学習済みモデルファイルを引数--checkpoint pretrained_model.ckptで指定することで、アテンションモードから実行可能です。 ↩ -
0.03は、学習率との乗算(learning_rate * finetune_lr_ratio = 0.1 * 0.3 = 0.03)によって算出されます。スクラッチ学習時(開始モードが train かつ pcas_iter == 0 の場合)の学習率は0.1となります。 ↩
-
PLモジュールは、Pytorch Lightning が提供する LightningModule を指します。PCASツールでは、モデルをPLモジュールと統合して使用します。 ↩