本記事の要約
- ディープラーニングモデルは動作が重いという課題があります。
- 処理速度やメモリ使用量を改善するモデル軽量化ツールPCASを紹介します。
- 当該ツールのインストール方法を解説します。
はじめに
ディープラーニング(DL)モデルは、認識性能が高い反面、高い演算能力やメモリー使用量が求められます。エッジデバイスなどの処理能力の限られる実行環境では、動作が遅かったり、そもそもメモリー不足で搭載できない、などの問題が生じがちです。そこで、モデルの軽量化(最適化)を検討することで問題解決が期待できます。
そもそも、なぜDLモデルの処理は重いと一般に認識されているのでしょうか?その要因の一つとして、DLをユーザーの独自データセットに適用する場合に、まず代表的なモデル(VGG-16やResNet-50など)から試してみることが多く、それらのモデルを動かしてみると処理が重かった、ということが経験的にあると思います。
確かに代表的なモデルはベンチマークスコアが高く、高い認識精度が得られる可能性が高いです。しかし、それらのモデルはベンチマーク用のデータセットで良好なスコアが出るように設計されたものであり、ユーザーが適用したい独自データセットを考慮して設計されたものではありません。
一般に、ベンチマーク用のデータセットは大規模なものが多く(例えば、画像分類問題において頻出の ImageNet ベンチマークは、約120万枚の学習用画像を使用して1000クラスの分類問題を解きます)、それに合わせて大規模に設計されているモデルも多いです。
したがって、ユーザーが適用したいデータセットがベンチマークよりも小規模であったり、解きたい問題の難易度が易しいものであれば、それら代表的なモデルは冗長な要素を多分に含んでいる可能性があり、最適化の余地があると言えます。
モデルの軽量化は、そのようなモデル規模のミスマッチを解消し、ユーザーの独自データセットに適したサイズに軽量化したり、あるいは認識精度を多少犠牲にして、より軽量なモデルを生成したりといった、処理性能のチューニングを可能にします。
モデル軽量化ツールPCAS とは?
2022年4月現在、AIエッジユーザーサイト上でOKIが提供している PyTorch で記述されたDLモデル用の軽量化ツールで、以下のような特徴があります。
-
モデルプルーニング技術PCAS1をベースとした独自の軽量化アルゴリズムを搭載
- モデルプルーニングとは、DLモデル内に存在する不必要な演算を特定・削減し、推論を高速化する技術です。
- 従来のモデルプルーニング手法で必要だったモデル分析作業(層毎の削減率の決定)が不要なため、適用に際して軽量化に関する知識をユーザーに要求しません。
-
モデルのスクラッチ学習と軽量化を簡単作業で実行可能
- モデル軽量化の適用には、通常、大幅なコード修正が必要ですが、本ツールは Pytorch Lightning をベースとしたカスタム可能な学習・軽量化スキームを構築しているため、学習と軽量化をほぼコード修正無しで実行可能です。
-
その他のオープンソースライブラリと連携可能
- PyTorchで実装された画像分類・物体検出・セマンティックセグメンテーション用のモデルを扱う強力なオープンソースを利用したモデル軽量化が可能で、多様な種類のモデルに対応しています(プリセットモデルが多数使用可能)。2
-
最適な軽量化を実現するためのオプション機能を複数実装
- 軽量化後に高い精度維持が期待できる「段階的な軽量化」や、モデルの分岐構造に対する「分岐最適化」、主にCPU上での演算実行時の高速化が期待できる「量子化学習」など、軽量化手法のオプション機能を複数用意しており、設定次第で更なる軽量化効果が狙えます。
- OpenVINO(ONNX経由)に対応
以下は利用イメージです。
- モデル学習が可能な計算機環境・学習データ・(学習済みモデル4)を用意します。
- 諸設定を行った上で軽量化ツールを実行し、軽量化済みモデルパラメータ(ONNXファイル)を生成します。
- ONNXファイルをOpenVINOのIR形式に変換し、推論エンジンとしてAIエッジデバイス上にデプロイします。

環境構築・インストール手順
モデル軽量化ツールPCASのインストールには、Dockerによるインストール と、マニュアル操作によるインストール の2通りの方法があります(詳細はツール付属ドキュメントを参照)。どちらの方法でも問題ありませんが、環境依存問題の少ないDockerによるインストールを推奨します。今回は、Dockerを使用した環境構築の手順について解説します。
- 計算機環境としてGPUを少なくとも1枚以上搭載した学習用PC(OSはUbuntu18.04を推奨)を用意し、Docker及びnvidia-docker をインストールします。
-
AIエッジユーザーサイト にログインし、「左側ドキュメントタブ>ソフトウェア>お試し版」から、OKIモデル軽量化PCASツール本体(ZIPファイル)を入手します。※試用期限は版数により異なります。
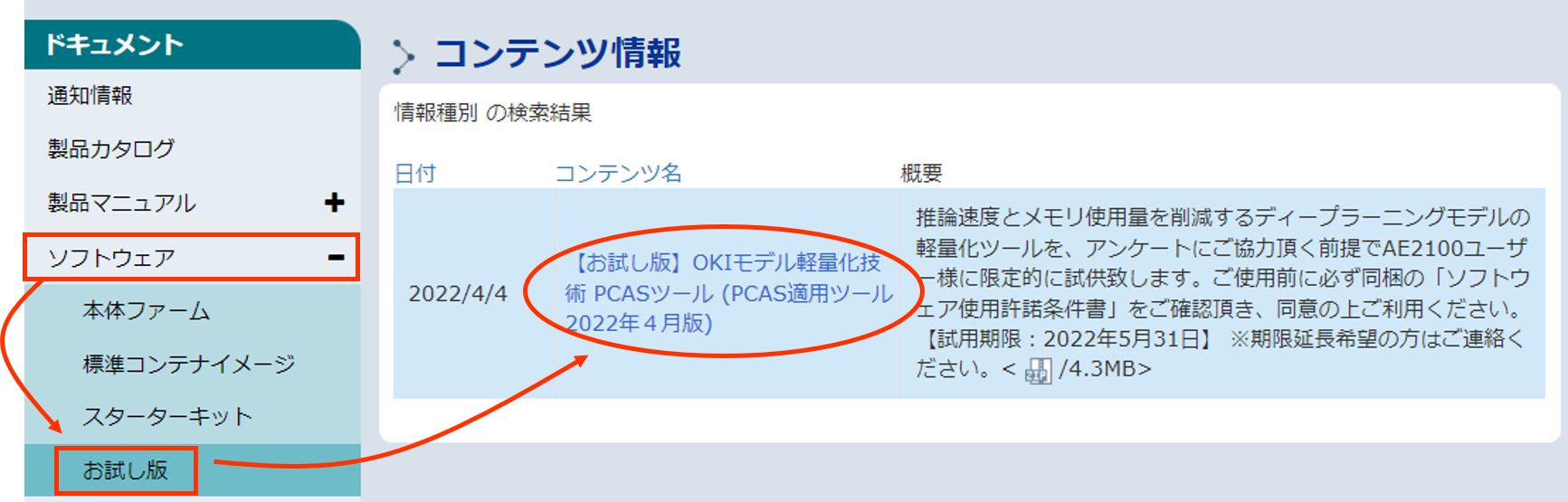
- ZIPファイルを展開後、Dockerファイルが
pcas/Docker/dockerfileにあるので、以下コマンドでDockerビルドします。
# Proxy設定が不要な場合のコマンド例
cd pcas
docker build -t pcas_tool Docker/.
# Proxy設定が必要な場合のコマンド例
cd pcas
export http_proxy=http://ID:PASS@your.proxy.server:port
docker build \
--build-arg http_proxy=$http_proxy \
--build-arg https_proxy=$http_proxy \
--build-arg HTTP_PROXY=$http_proxy \
--build-arg HTTPS_PROXY=$http_proxy \
-t pcas_tool Docker/.
続いて、作成したDockerイメージpcas_toolからコンテナを生成します。ここで、ツール本体のpcasディレクトリ(ツール同梱のexamplesソースコードを利用するために必要)、学習データを格納するdataディレクトリ、軽量化結果を保存するresultディレクトリをホストPCのボリュームと紐付けています。コンテナ内で使用するメモリサイズ(--shm-size)は、実行環境に応じて変更してください。
docker run \
--name pcas_tool \
--runtime=nvidia \
-v /path/to/pcas:/pcas \
-v /path/to/data:/data \
-v /path/to/result:/result \
-e PYTHONPATH=/pcas \
--shm-size=50g \
--workdir /pcas \
-it pcas_tool
以上で、pcas_toolコンテナの生成が完了し、モデル軽量化ツールPCASが実行可能な環境が整いました。
まとめ
本記事では、ディープラーニングモデルの軽量化の意義とモデル軽量化ツールPCASを紹介し、そのDockerによるインストール方法を説明しました。次回は、本ツールを使って実際に画像分類モデルを軽量化する例を解説したいと思います。
⇒ ディープラーニングモデルの軽量化ツールPCASの使い方 (2) ー画像分類モデルの軽量化編ー
-
K. Yamamoto and K. Maeno, PCAS: Pruning Channels with Attention Statistics for Deep Network Compression, British Machine Vision Conference (BMVC), 2019. https://arxiv.org/abs/1806.05382 ↩
-
Pytorch Lightningの基本機能を用いてユーザー側でモデルや損失関数を定義すれば、その他の独自タスクへの適用も可能です。 ↩
-
IR形式のモデルは、AE2100上のCPUやMyriadXで効率的に動作可能な形態です。 ↩
-
プリセットモデルを利用する場合(スクラッチ学習からツール上で行う場合)は、学習済みモデルの用意は不要です。 ↩